













AWS CLI 및 AWS S3 설정하기
S3와 파일을 동기화하기 전에 AWS CLI를 올바르게 설정해야 합니다.이것은 AWS에 새로운 사용자라면 혼란스러울 수 있지만, 몇 분 정도 걸릴 것입니다.
CLI 설정은 두 가지 주요 단계로 구성됩니다: 도구 설치 및 구성. 다음으로 두 단계를 살펴보겠습니다.
CLI 설치
운영 체제에 따라 AWS CLI 설치 방법이 약간 다릅니다.
Windows 시스템의 경우:
- AWS CLI 다운로드 페이지
- Windows 설치 프로그램(64비트)
- 설치 프로그램을 실행하고 안내에 따르세요
리눅스 시스템의 경우:
터미널을 통해 다음 세 명령을 실행하세요:
curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip" unzip awscliv2.zip sudo ./aws/install
macOS 시스템의 경우:
Homebrew가 설치되어 있다고 가정하고 터미널에서 다음 한 줄을 실행하세요:
brew install awscli
Homebrew가 없는 경우, 대신 다음 두 명령어를 사용하세요:
curl "https://awscli.amazonaws.com/AWSCLIV2.pkg" -o "AWSCLIV2.pkg" sudo installer -pkg AWSCLIV2.pkg -target /
모든 운영 체제에서 aws --version 명령어를 실행하여 AWS CLI가 설치되었는지 확인할 수 있습니다. 확인해야 할 내용은 다음과 같습니다:
이미지 1 – AWS CLI 버전
AWS CLI 구성
이제 CLI가 설치되었으므로 AWS 자격 증명으로 구성해야 합니다.
AWS 계정이 이미 있는 것으로 가정하고, IAM 서비스로 로그인하여 이동합니다. 그곳에서 프로그래바닉 액세스를 갖는 새 사용자를 만듭니다. 사용자에게 적절한 권한을 할당해야 합니다. 최소한 S3 액세스 권한을 할당해야 합니다:
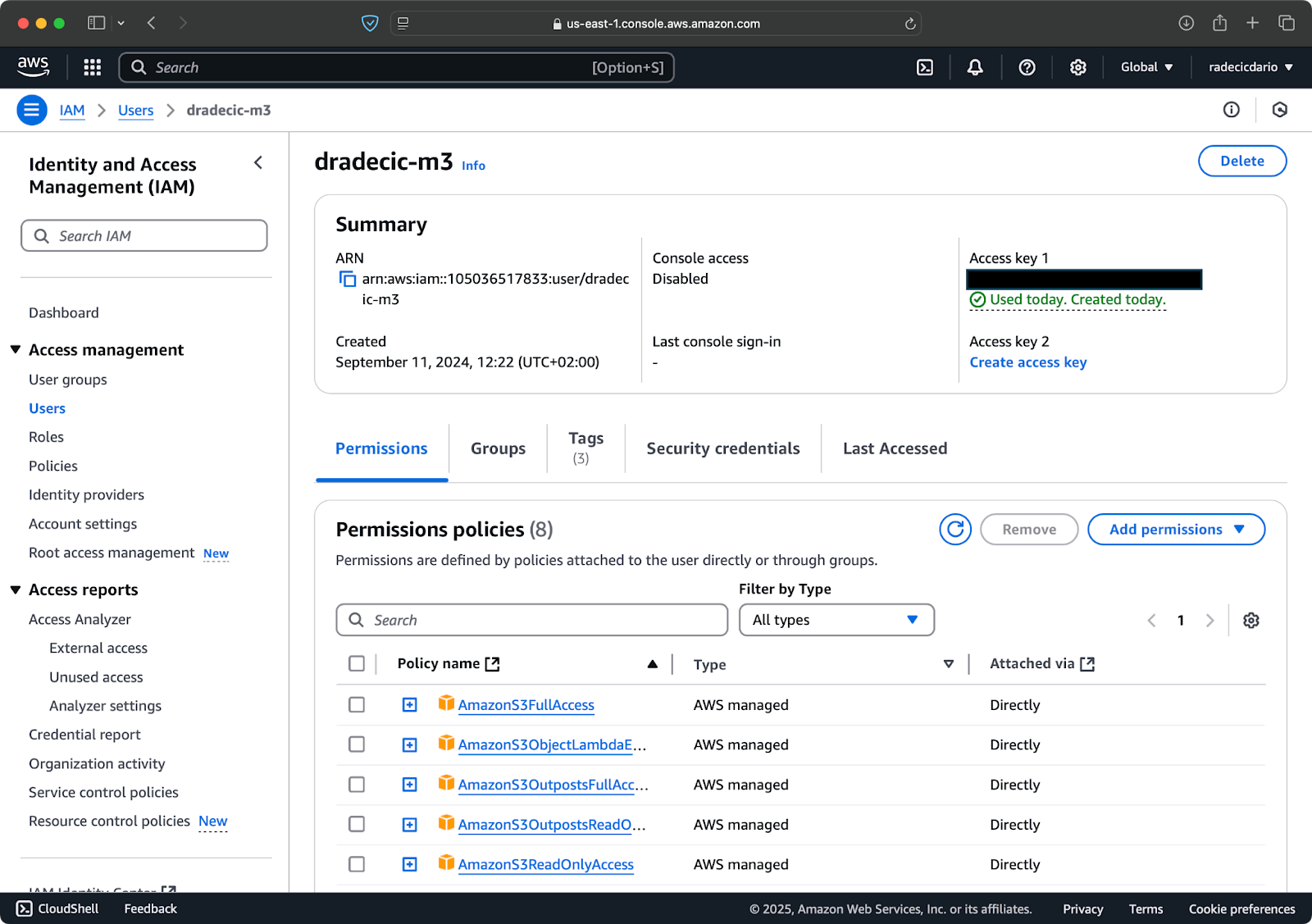
이미지 2 – AWS IAM 사용자
작업을 완료하면 “보안 자격 증명”으로 이동하여 새 액세스 키를 생성하십시오. 생성한 후에는 액세스 키 ID 및 비밀 액세스 키가 모두 제공됩니다. 나중에 액세스할 수 없으므로 안전한 곳에 적어 두십시오:
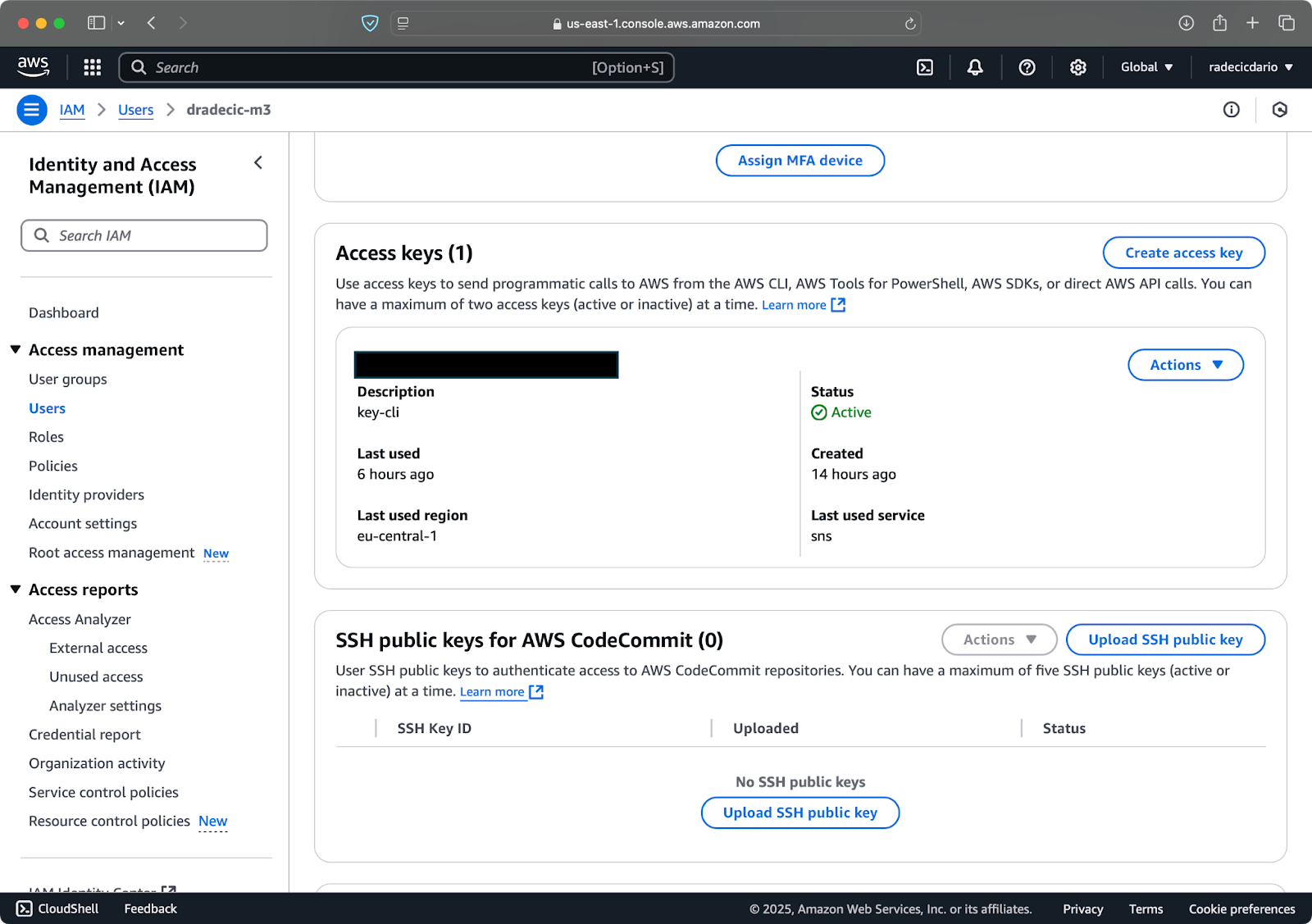
이미지 3 – AWS IAM 사용자 자격 증명
터미널에서 aws configure 명령을 실행하십시오. Access 키 ID, 비밀 액세스 키, 지역 (eu-central-1 이 경우), 및 선호하는 출력 형식 (json)을 입력하라는 메시지가 표시됩니다:
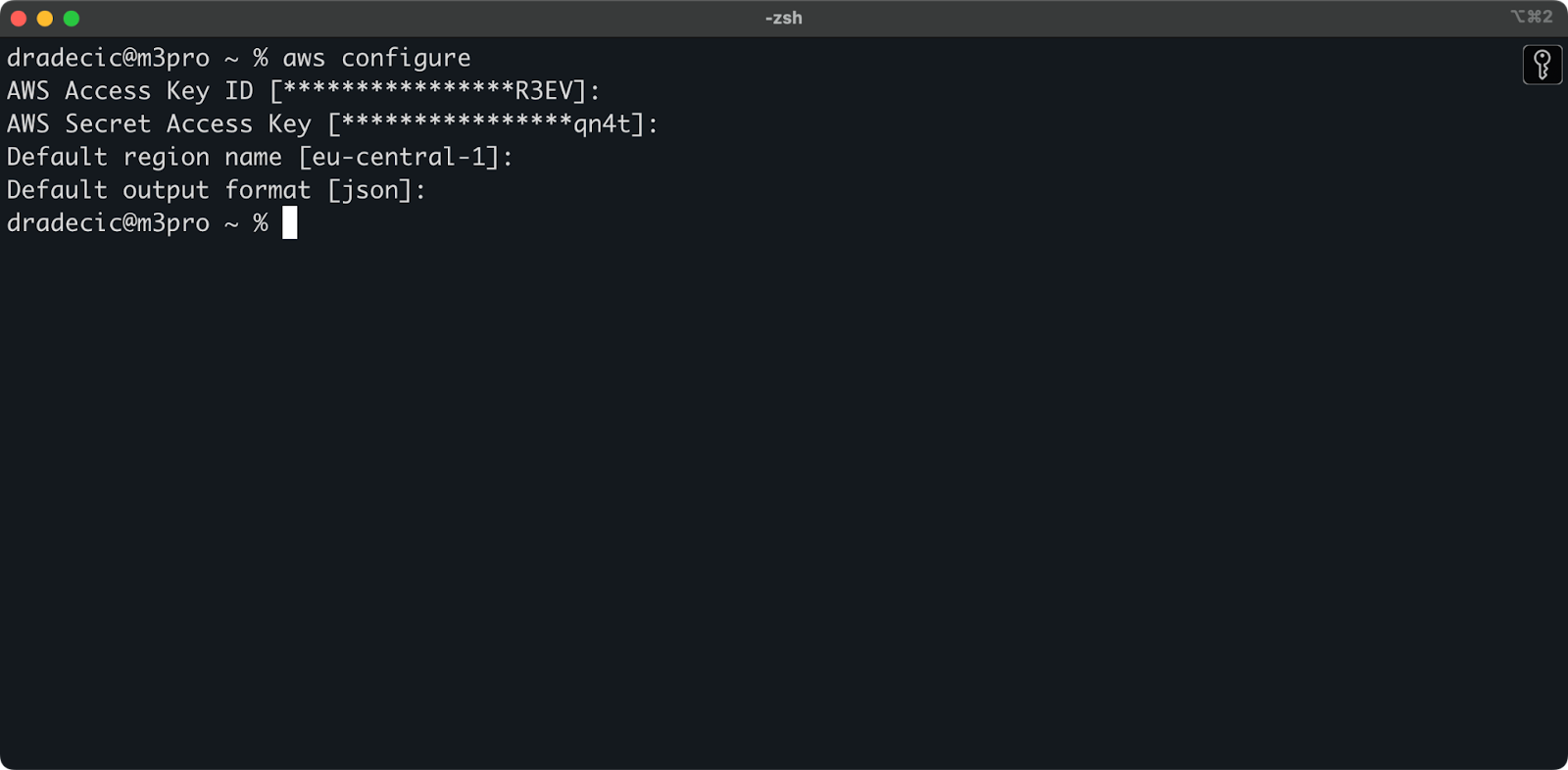
이미지 4 – AWS CLI 구성
CLI에서 AWS 계정에 성공적으로 연결되었는지 확인하려면 다음 명령을 실행하십시오:
aws sts get-caller-identity
다음 출력이 표시되어야 합니다:
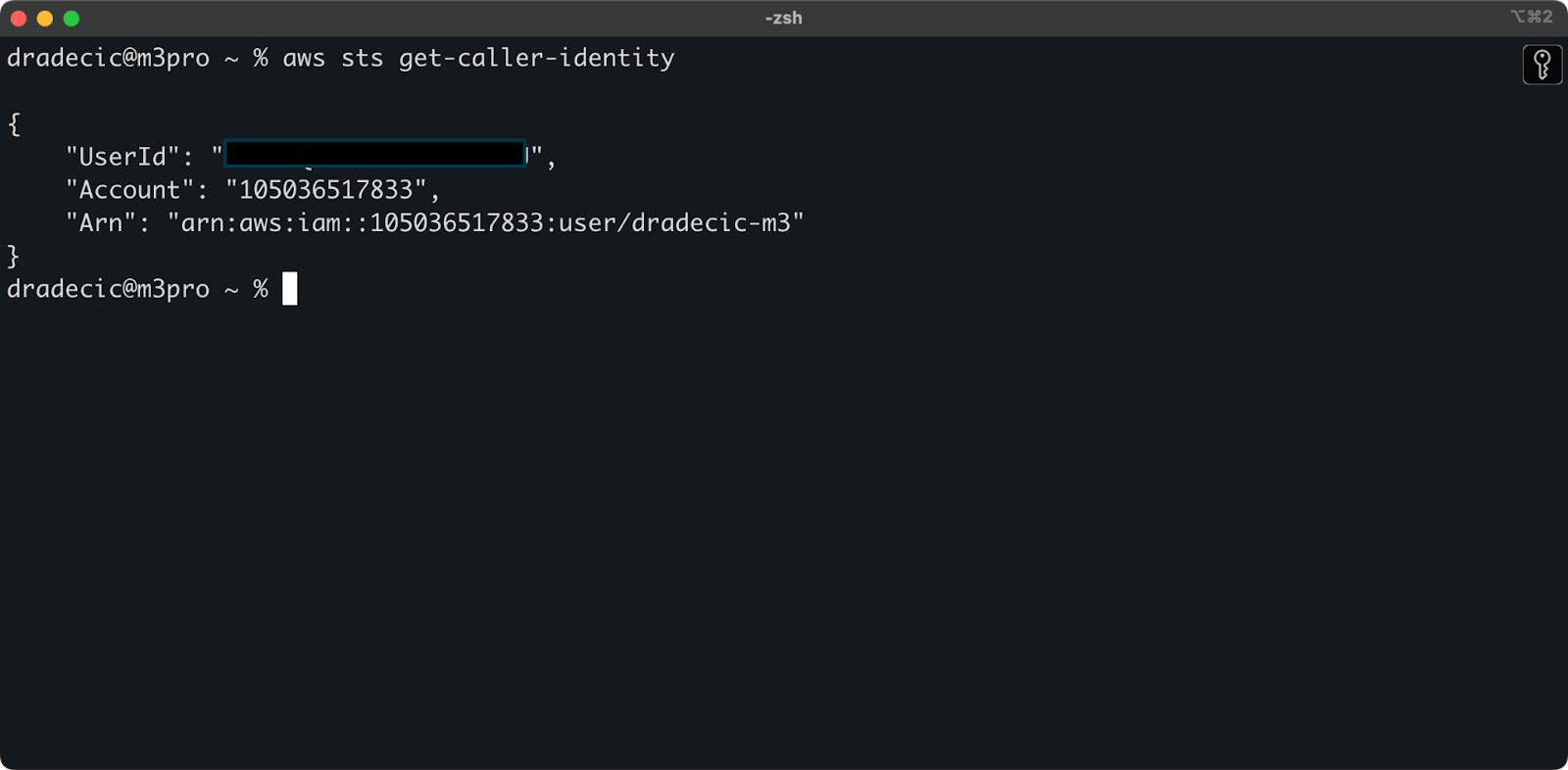
이미지 5 – AWS CLI 연결 테스트 명령
그리고 여기까지입니다 – S3 동기화 명령을 사용하기 전에 한 가지 더해야 할 단계가 있습니다!
AWS S3 버킷 설정하기
최종 단계는 동기화된 파일을 저장할 S3 버킷을 생성하는 것입니다. CLI 또는 AWS 관리 콘솔에서 할 수 있습니다. 저는 후자를 선택할 것이며, 색다른 방식으로 해보겠습니다.
먼저 관리 콘솔의 S3 서비스 페이지로 이동하여 “버킷 생성” 버튼을 클릭하십시오. 거기서 고유한 버킷 이름을 선택하고(전체 AWS에서 전역적으로 고유해야 함) 아래로 스크롤하여 “생성” 버튼을 클릭하십시오:
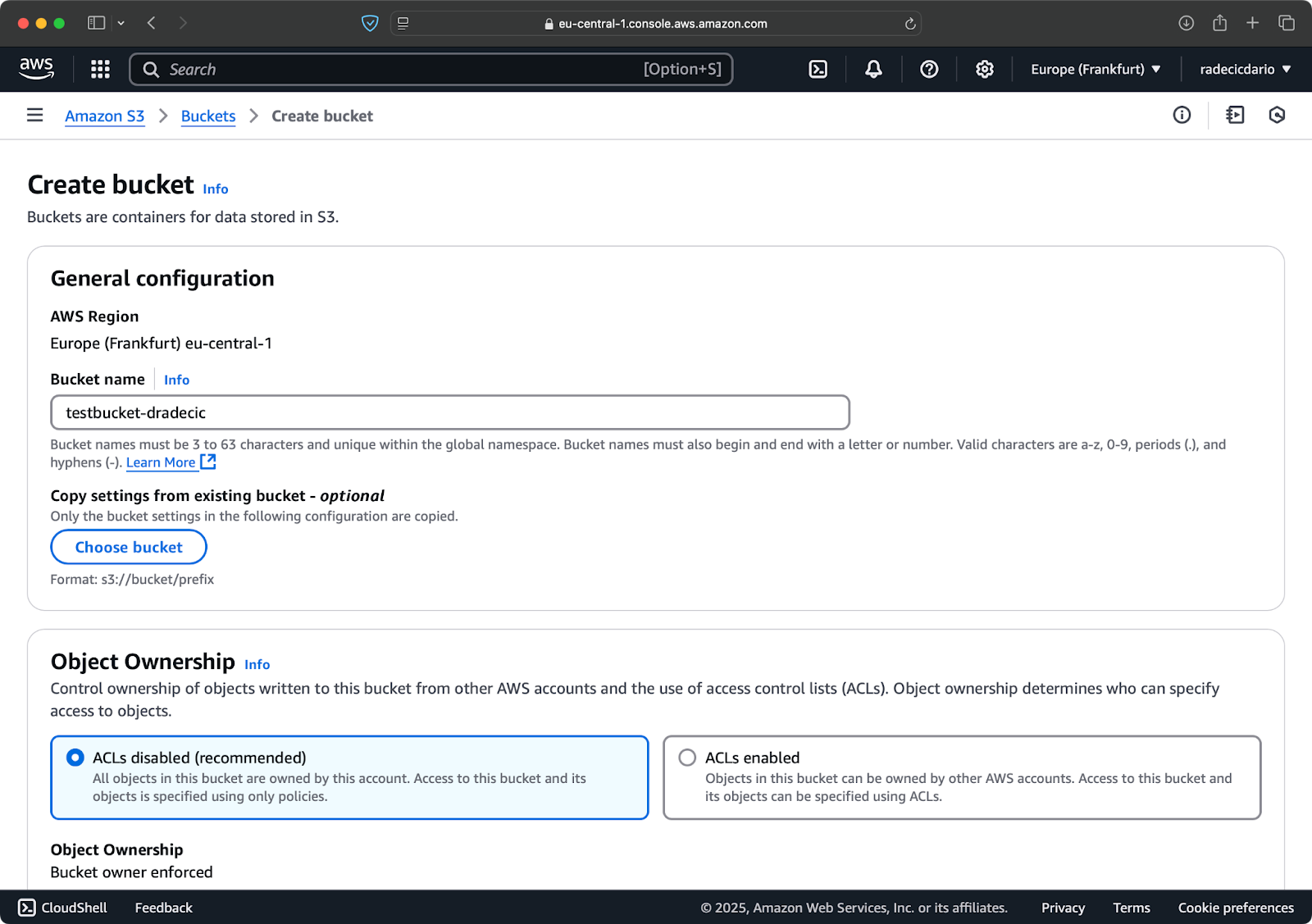
이미지 6 – AWS 버킷 생성
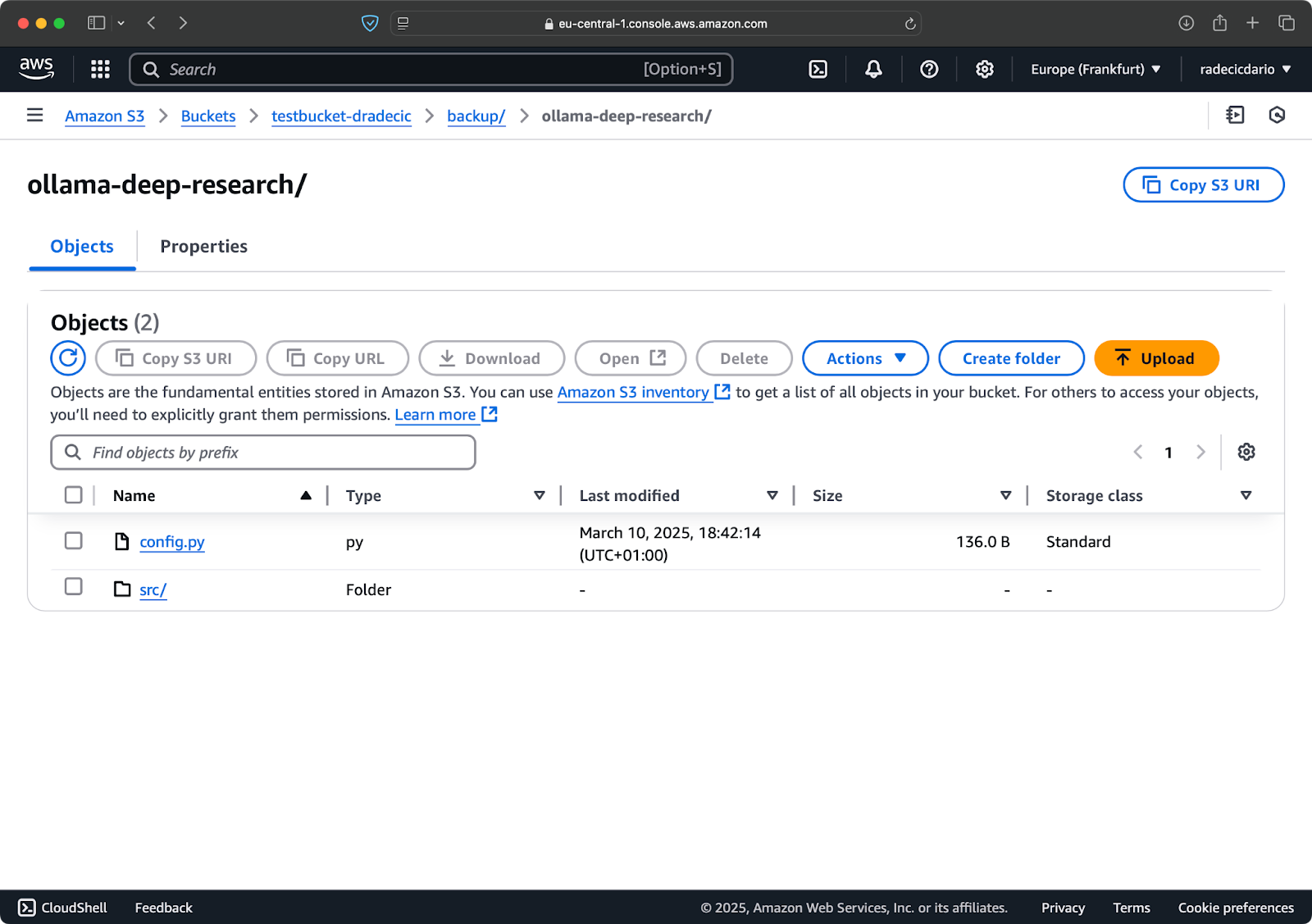
버킷이 이제 생성되었으며 즉시 관리 콘솔에서 확인할 수 있습니다. CLI를 통해 생성되었는지도 확인할 수 있습니다:
aws s3 ls
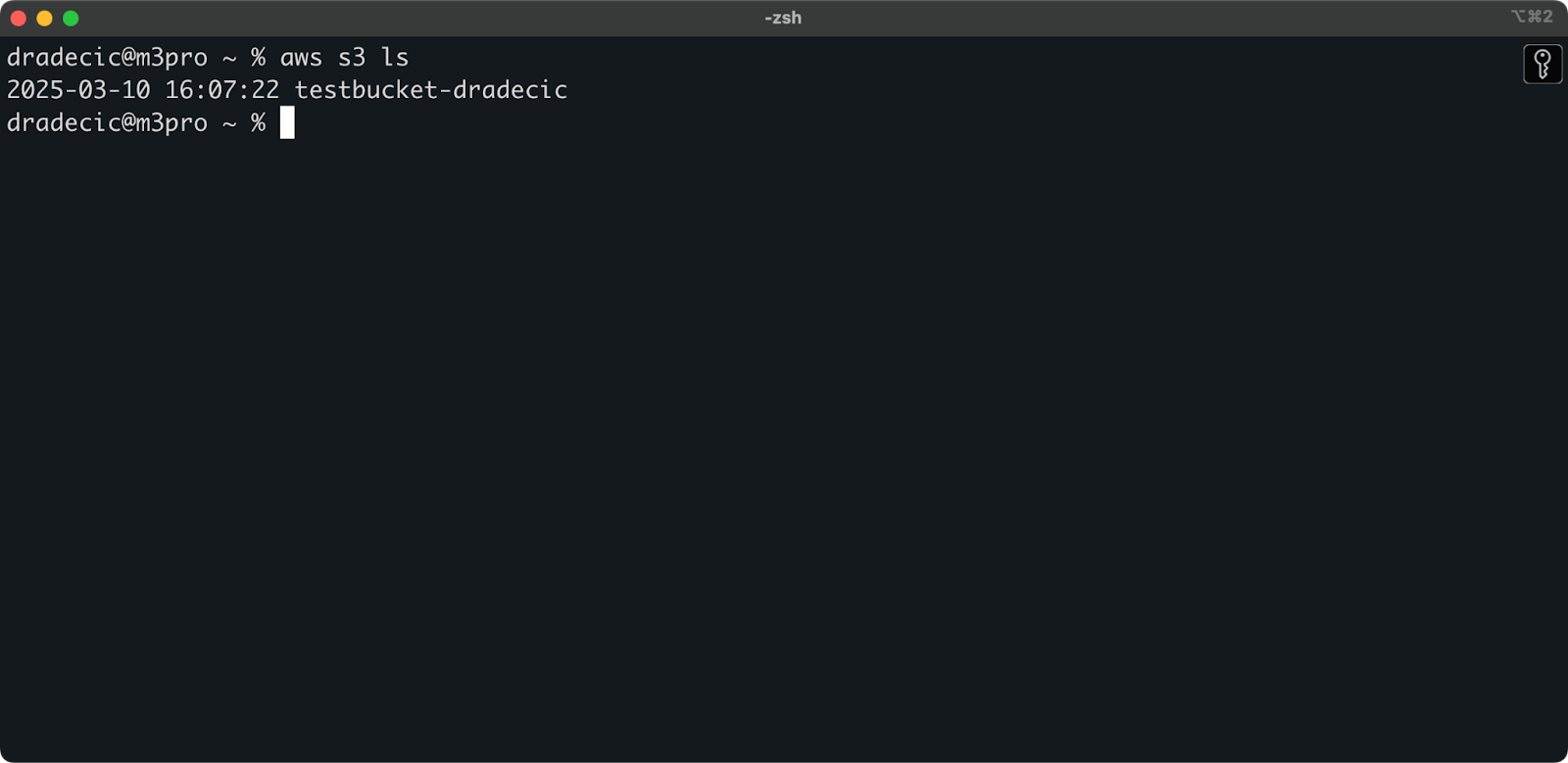
이미지 7 – 모든 사용 가능한 S3 버킷
기억해야 할 점은 S3 버킷은 기본적으로 비공개입니다. 웹 사이트 자산과 같은 공개 파일을 호스팅하기 위해 버킷을 사용하려면 버킷 정책과 권한을 적절하게 조정해야 합니다.
이제 모든 설정이 완료되어 로컬 컴퓨터와 AWS S3 간 파일 동기화를 시작할 준비가 되었습니다!
기본 AWS S3 동기화 명령어
AWS CLI가 설치되고 구성되었으며 S3 버킷이 준비되었다면 동기화를 시작할 때입니다! AWS S3 동기화 명령어의 기본 구문은 매우 간단합니다. 작동 방식을 보여드리죠.
S3 동기화 명령어는 다음과 같은 간단한 패턴을 따릅니다:
aws s3 sync <source> <destination> [options]
원본 및 대상은 로컬 디렉토리 경로 또는 S3 URI( s3://로 시작) 중 어느 것이든 될 수 있습니다. 동기화할 방법에 따라 다르게 배열해야 합니다.
로컬에서 S3 버킷으로 파일 동기화
최근 Ollama deep research를 사용하여 놀고 있었습니다. S3로 동기화하려는 폴더는 이렇습니다. 주 디렉토리는 Documents 폴더 아래에 있습니다. 다음은 실제 모습입니다:
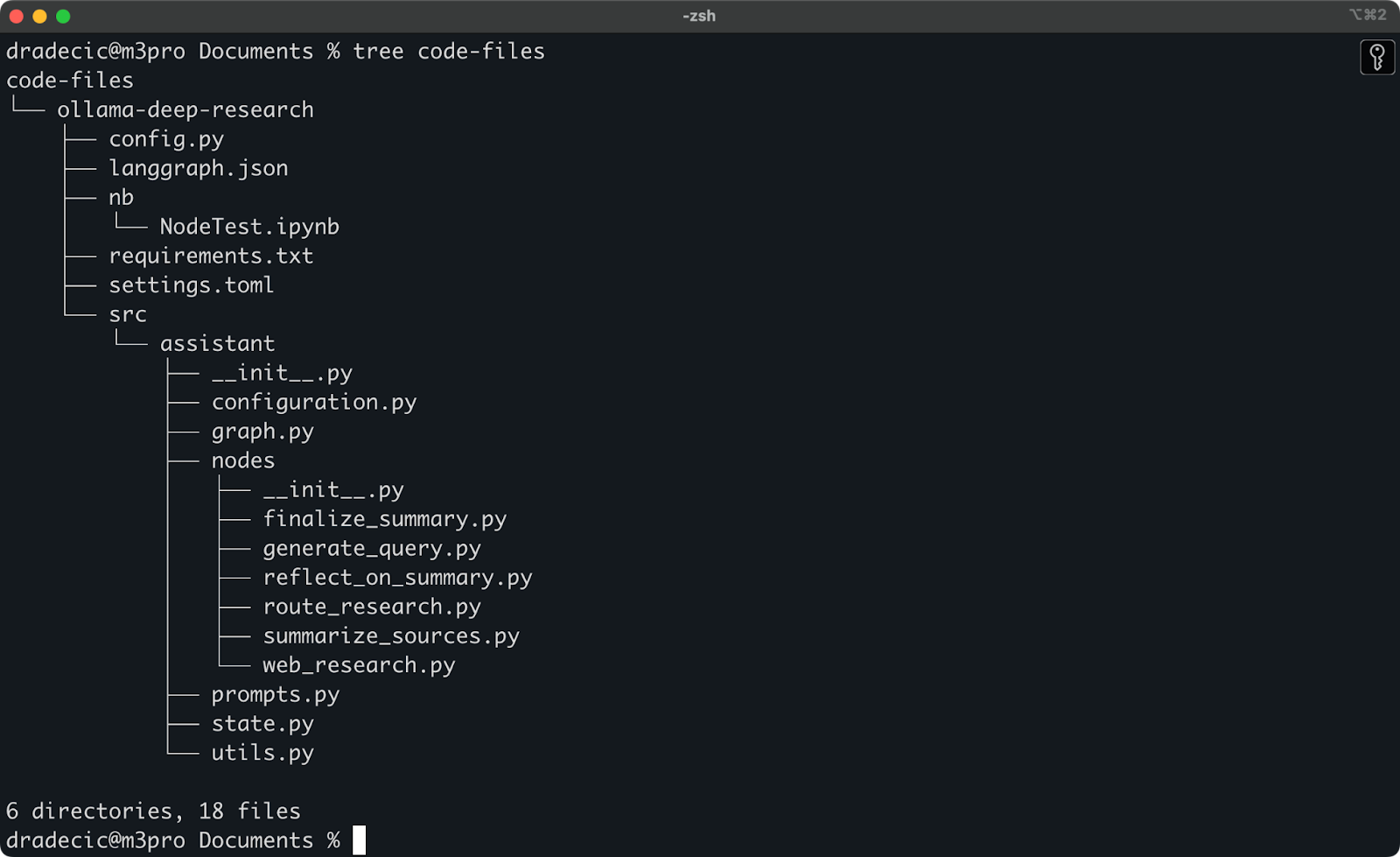
로컬 폴더 내용
로컬 code-files 폴더를 S3 버킷의 backup 폴더와 동기화해야 하는 명령어는 다음과 같습니다:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup
S3 버킷의 backup 폴더는 존재하지 않을 경우 자동으로 생성됩니다.
콘솔에 인쇄된 내용은 다음과 같습니다:
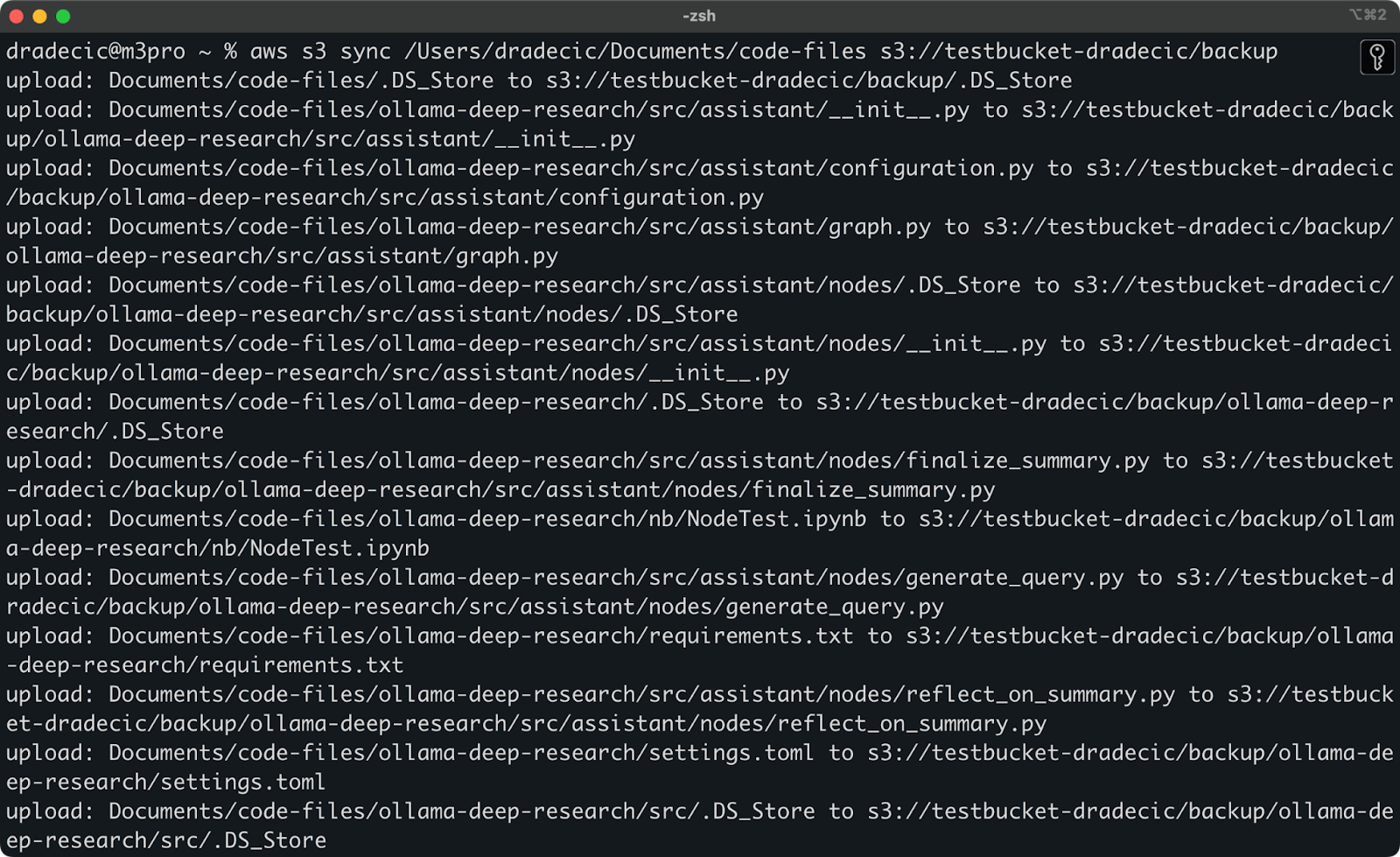
이미지 9 – S3 동기화 프로세스
몇 초 후에 로컬 code-files 폴더의 내용이 S3 버킷에 사용 가능해집니다:
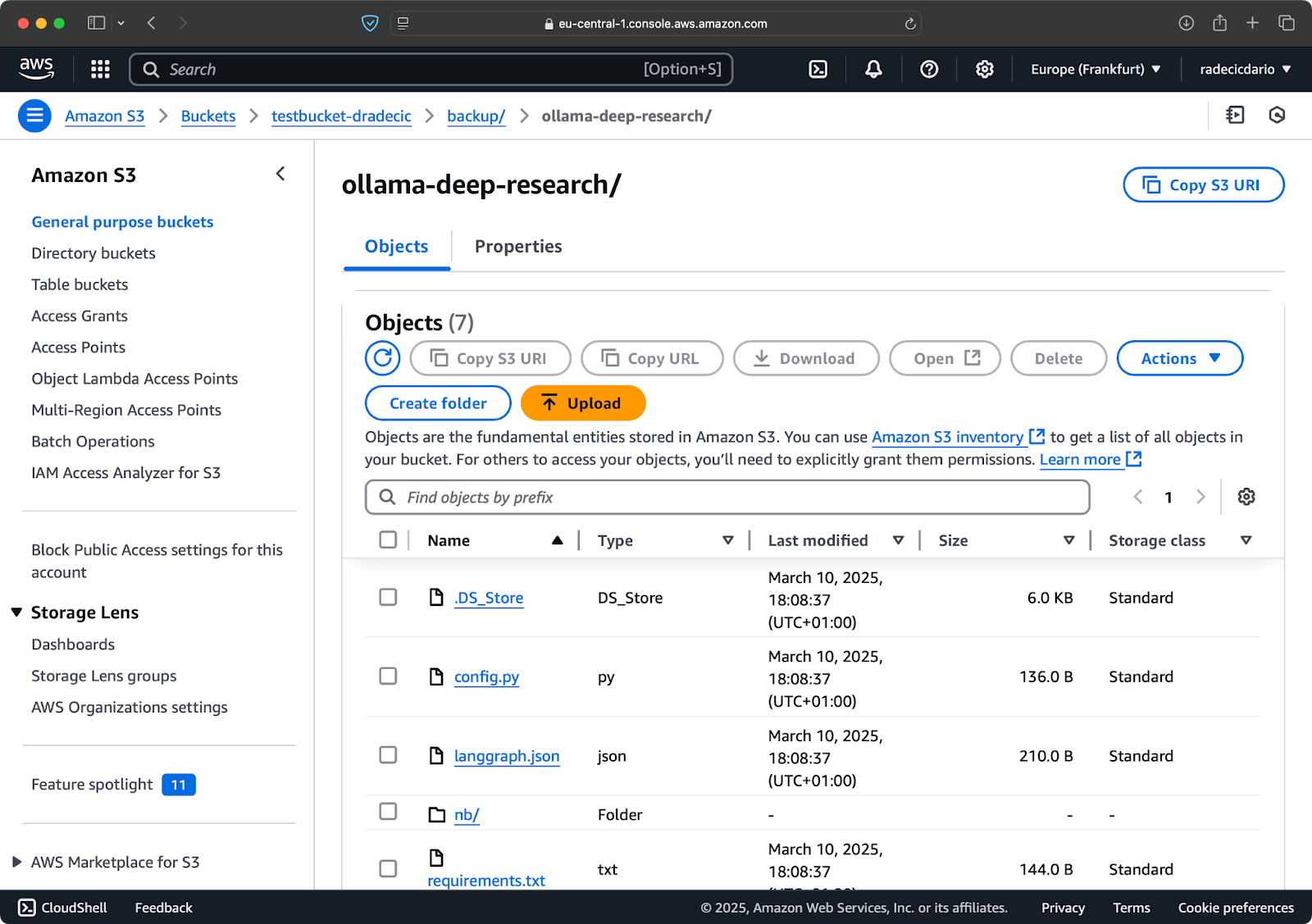
이미지 10 – S3 버킷 내용
S3 동기화의 장점은대상에 존재하지 않거나 로컬에서 수정된 파일만 업로드한다는 것입니다. 동일한 명령을 다시 실행하되 아무것도 변경하지 않으면… 아무것도 표시되지 않을 것입니다! 모든 파일이 이미 동기화되어 최신 상태임을 AWS CLI가 감지했기 때문입니다.
이제 두 가지 작은 변경을 가할 것입니다 – 새 파일 생성 (new_file.txt) 및 기존 파일 업데이트 (requirements.txt). 동기화 명령을 다시 실행하면 새로 만들어진 파일 또는 수정된 파일만 업로드됩니다:
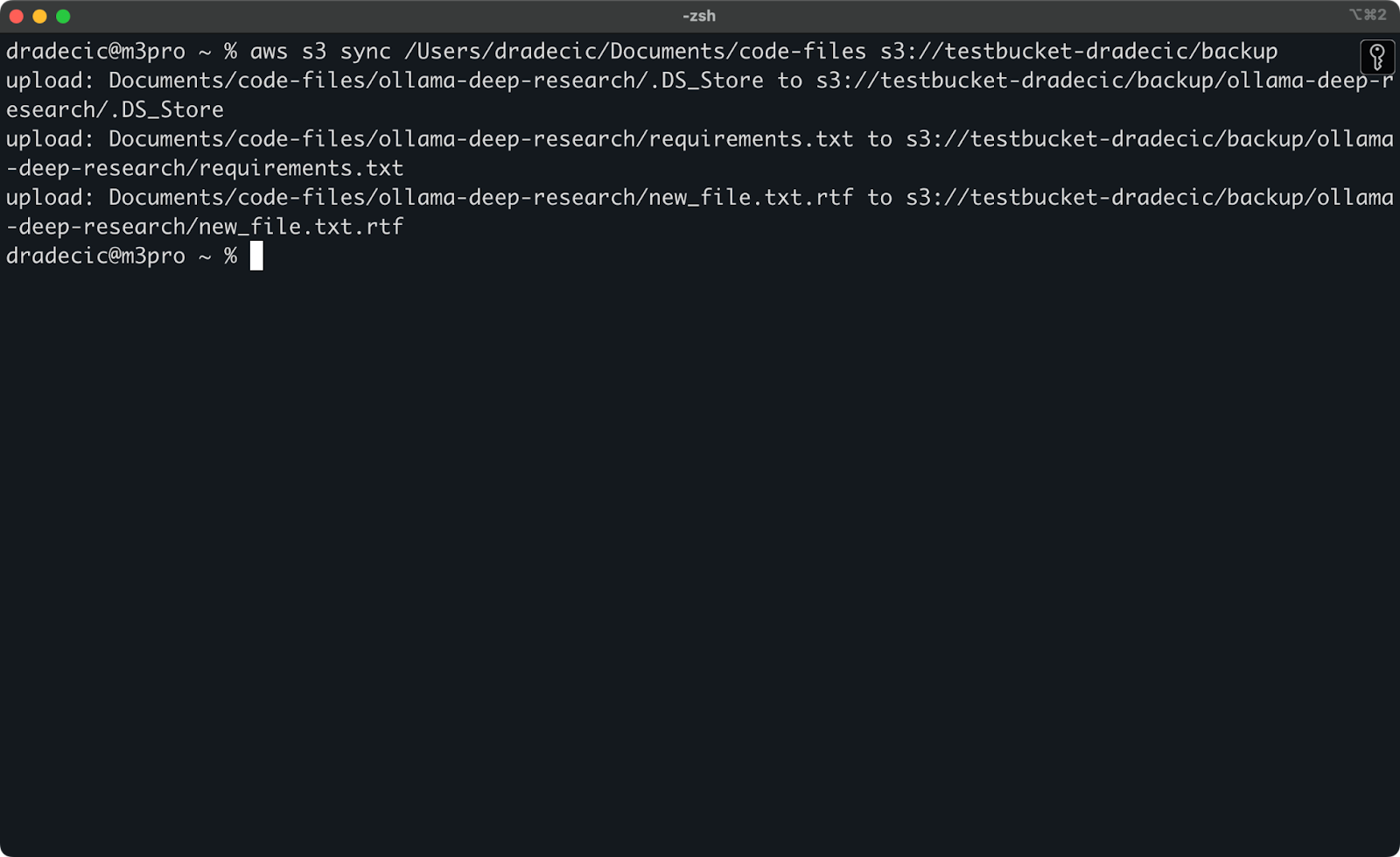
이미지 11 – S3 동기화 프로세스 (2)
로컬 폴더를 S3에 동기화할 때 알아야 할 기본 사항입니다. 그러나 거꾸로 하려면 어떻게 해야 할까요?
S3 버킷에서 로컬 디렉토리로 파일 동기화
S3 버킷에서 로컬 머신으로 파일을 다운로드하려면 소스와 대상을 뒤바꾸면 됩니다:
aws s3 sync s3://testbucket-dradecic/backup /Users/dradecic/Documents/code-files-from-s3
다음 명령은 S3 버킷의 backup 폴더에서 모든 파일을 code-files-from-s3라는 로컬 폴더로 다운로드합니다. 다시 말하지만, 로컬 폴더가 없는 경우 CLI가 대신 생성해줍니다:
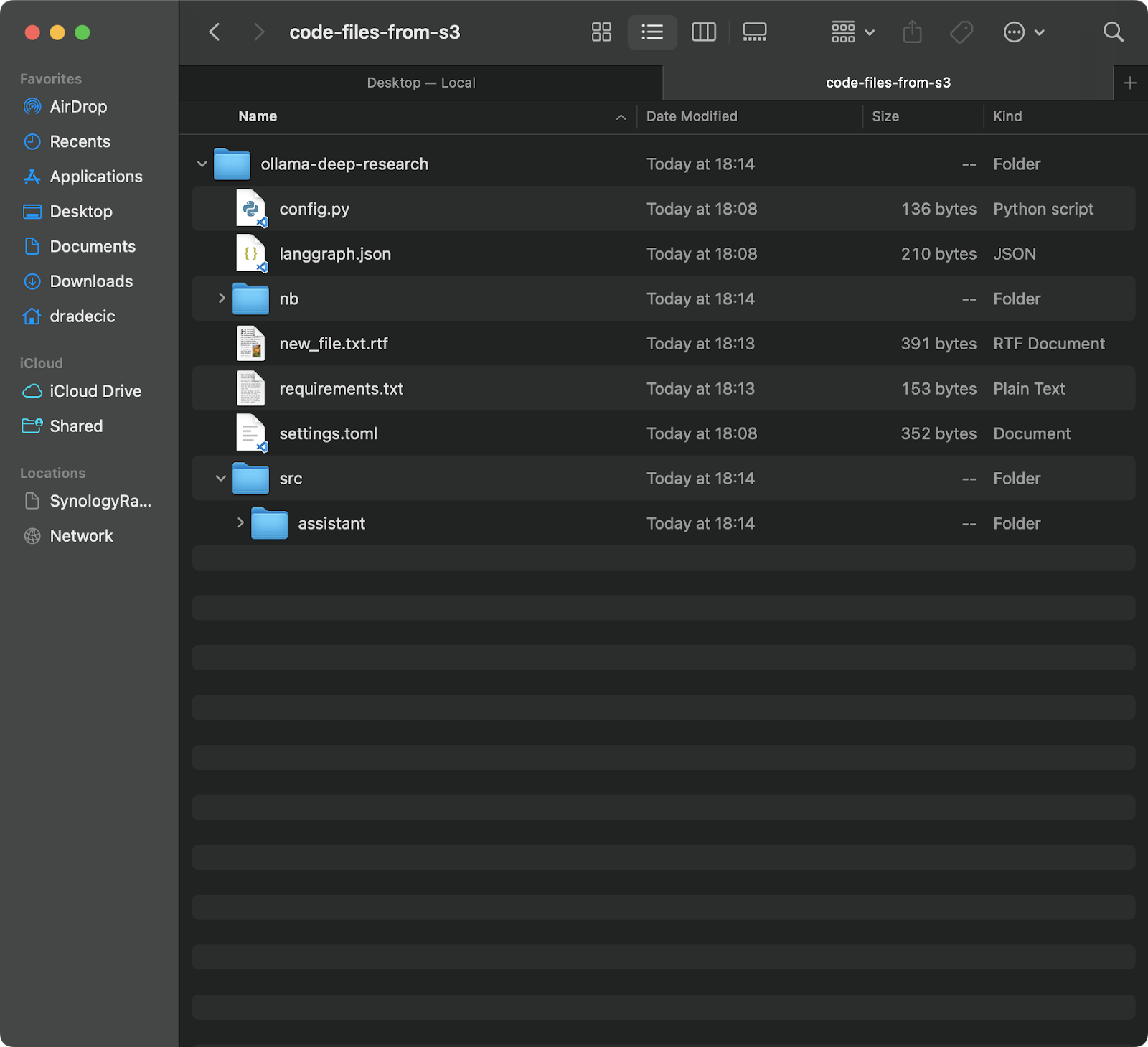
이미지 12 – S3에서 로컬로 동기화
주의할 점은 S3 동기화가 양방향이 아니라는 것입니다. 항상 출발지에서 목적지로 이동하여 목적지를 출발지와 일치하도록 만듭니다. 로컬에서 파일을 삭제한 다음 S3로 동기화하면 S3에는 여전히 존재합니다. 마찬가지로, S3에서 파일을 삭제하고 S3에서 로컬로 동기화하면 로컬 파일은 그대로 유지됩니다.
목적지를 출발지와 정확히 일치하도록 만들려면 (삭제 포함), --delete 플래그를 사용해야 합니다. 이에 대해 나중에 고급 옵션 섹션에서 다룰 것입니다.
고급 AWS S3 동기화 옵션
이전에 살펴본 기본 S3 동기화 명령어는 그 자체로 강력하지만 AWS는 동기화 프로세스에 대해 더 많은 제어권을 부여하는 추가 옵션을 제공했습니다.
이 섹션에서는 기본 명령에 추가할 수 있는 가장 유용한 플래그들을 보여드리겠습니다.
새로 추가하거나 수정된 파일 동기화
기본적으로 S3 동기화는 파일 크기와 수정 시간을 확인하여 파일을 동기화해야 하는지를 결정하는 기본 비교 메커니즘을 사용합니다. 그러나 파일이 수정되었지만 크기는 그대로인 파일과 관련된 변경 사항을 항상 포착하지 못할 수 있습니다.
더 정확한 동기화를 위해 --exact-timestamps 플래그를 사용할 수 있습니다:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup --exact-timestamps
이는 S3 동기화를 밀리초까지의 정밀도로 타임스탬프를 비교하도록 강제합니다. 이 플래그를 사용하는 것은 더 자세한 비교가 필요하기 때문에 동기화 프로세스를 약간 느리게할 수 있음을 염두에 두세요.
특정 파일을 제외하거나 포함하기
가끔은 디렉토리의 모든 파일을 동기화하고 싶지 않을 수 있습니다. 일시 파일, 로그 또는 특정 파일 유형(예: 제 경우의 .DS_Store)을 제외하고 싶을 수도 있습니다. 이때 --exclude 및 --include 플래그가 유용합니다.
그러나 이해를 돕기 위해, 제 코드 디렉토리를 동기화하되 모든 Python 파일을 제외하고 싶다고 가정해 봅시다:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup --exclude "*.py"
이제는 S3로 동기화되는 파일이 훨씬 적습니다:
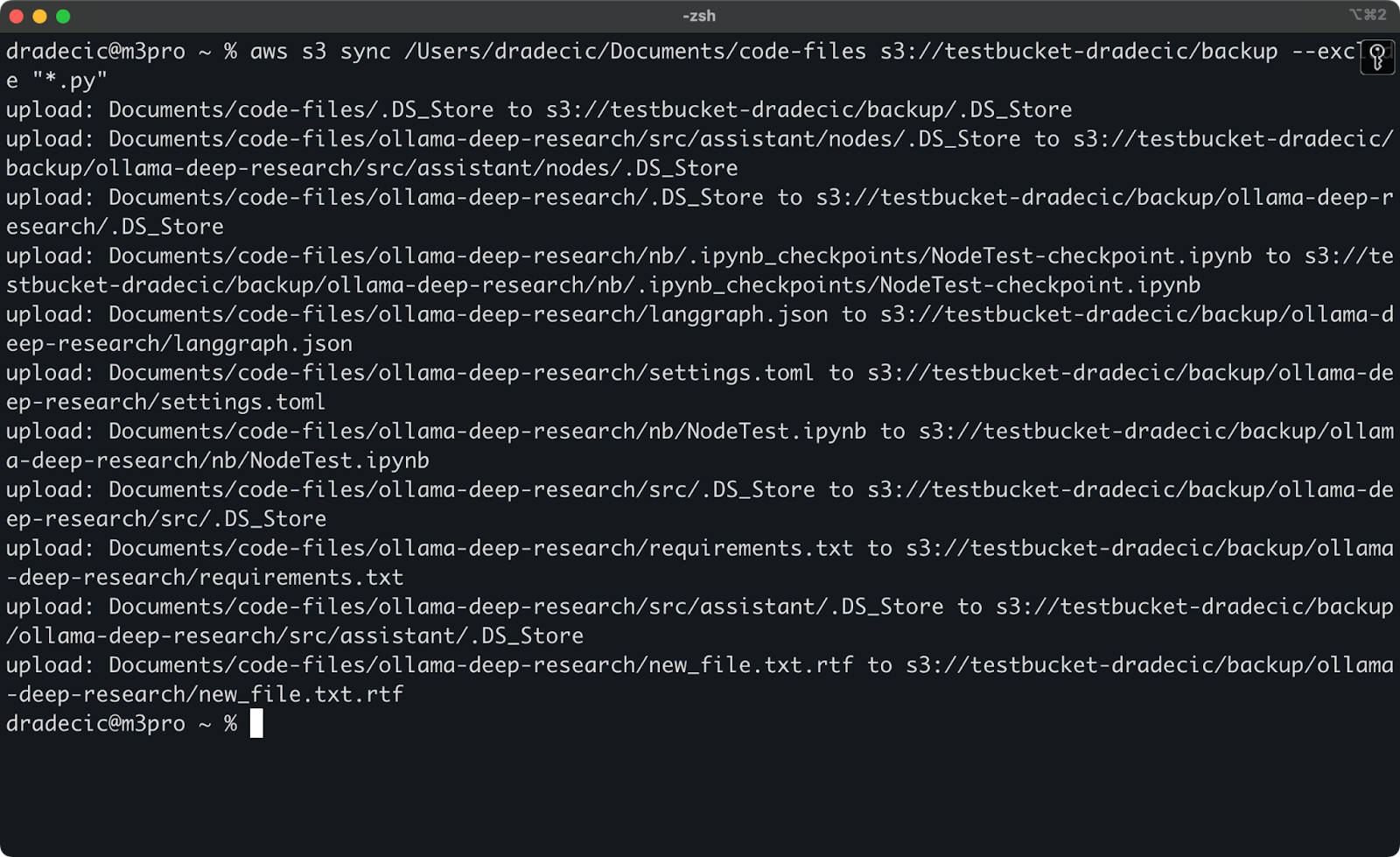
이미지 13 – Python 파일 제외한 S3 동기화
--exclude와 --include를 결합하여 더 복잡한 패턴을 생성할 수도 있습니다. 예를 들어 Python 파일을 제외한 모든 것을 제외할 수 있습니다:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup --exclude "*" --include "*.py"
패턴은 지정된 순서대로 평가되므로 순서가 중요합니다! 이러한 플래그를 사용할 때 볼 수 있는 내용은 다음과 같습니다:
이미지 14 – 제외 및 포함 플래그
이제 Python 파일만 동기화되고 중요한 구성 파일이 누락되었습니다.
대상에서 파일 삭제
기본적으로 S3 동기화는 대상에 파일을 추가하거나 업데이트하지만 삭제하지는 않습니다. 이는 소스에서 파일을 삭제해도 동기화 후에는 대상에 그대로 남아 있다는 것을 의미합니다.
삭제를 포함하여 대상을 정확히 소스와 동일하게 만들려면 --delete 플래그를 사용하세요:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup --delete
이를 처음 실행하면 모든 로컬 파일이 S3로 동기화됩니다:
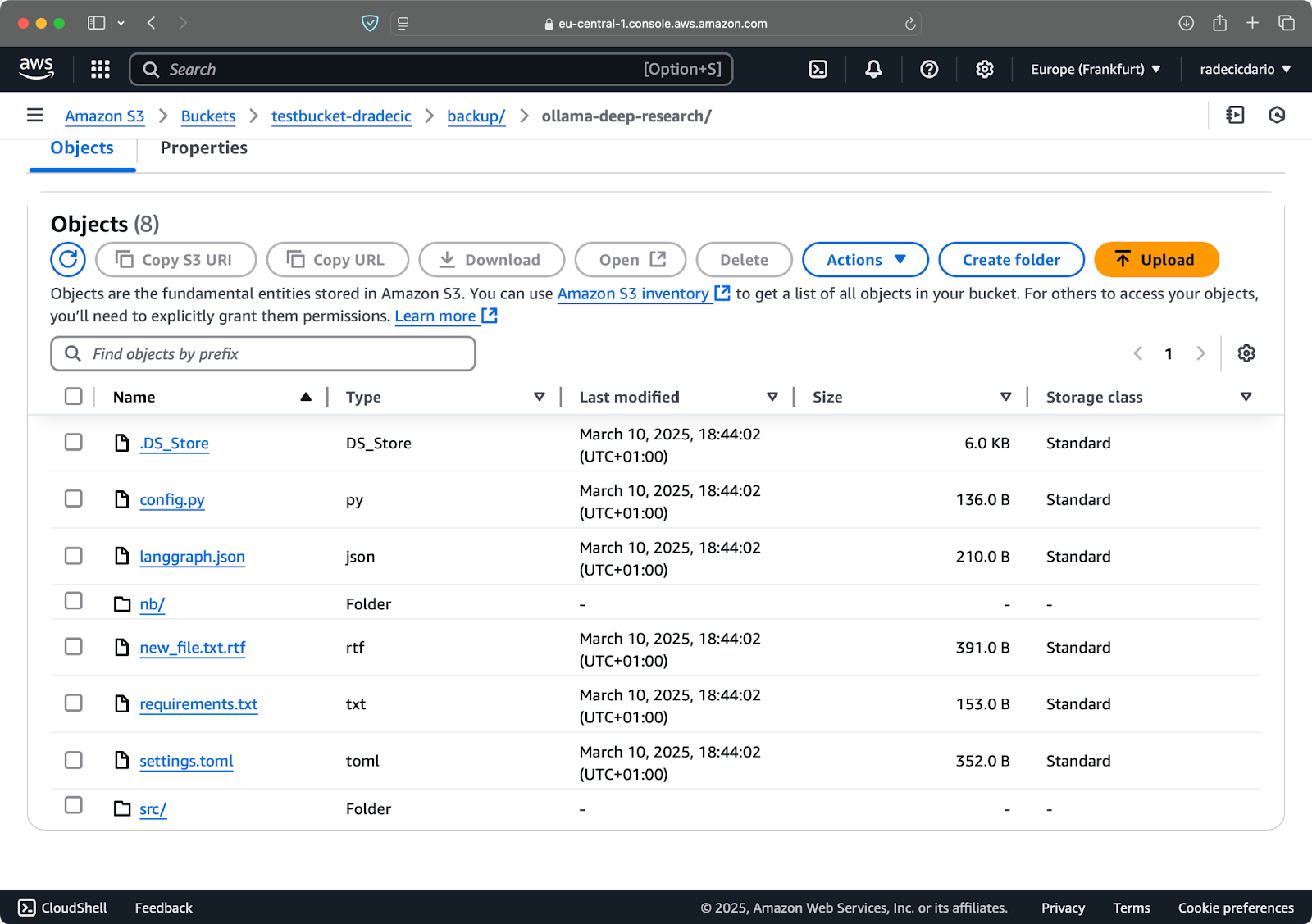
이미지 15 – 삭제 플래그
이 기능은 디렉토리의 정확한 복제본을 유지하는 데 특히 유용합니다. 그러나 조심하세요 – 이 플래그를 잘못 사용하면 데이터 손실로 이어질 수 있습니다.
config.py를 로컬 폴더에서 삭제하고 --delete 플래그와 함께 동기화 명령을 실행한다고 가정해 봅시다:
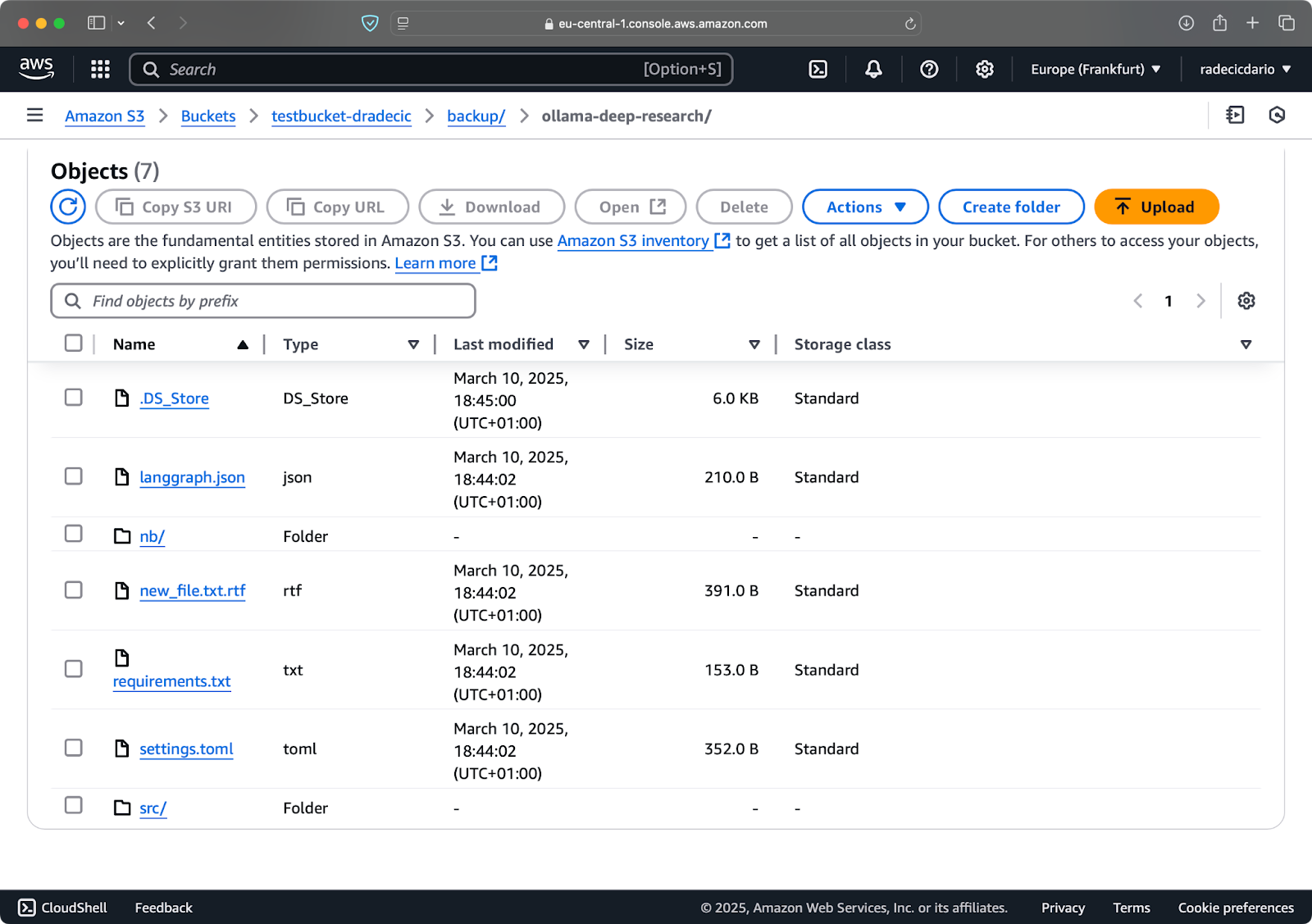
이미지 16 – 삭제 플래그 (2)
보시다시피, 이 명령은 새로운 파일과 수정된 파일을 동기화하는 것뿐만 아니라 더 이상 로컬 디렉토리에 존재하지 않는 파일을 S3 버킷에서도 삭제합니다.
안전한 동기화를 위한 드라이런 설정
가장 위험한 S3 동기화 작업은 --delete 플래그를 사용하는 작업입니다. 중요한 파일을 실수로 삭제하는 것을 피하려면 실제로 어떠한 변경도 가하지 않고 작업을 시뮬레이션하는 --dryrun 플래그를 사용할 수 있습니다:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup --delete --dryrun
예를 들어, 로컬 폴더에서 requirements.txt 및 settings.toml 파일을 삭제하고 다음 명령을 실행했습니다:
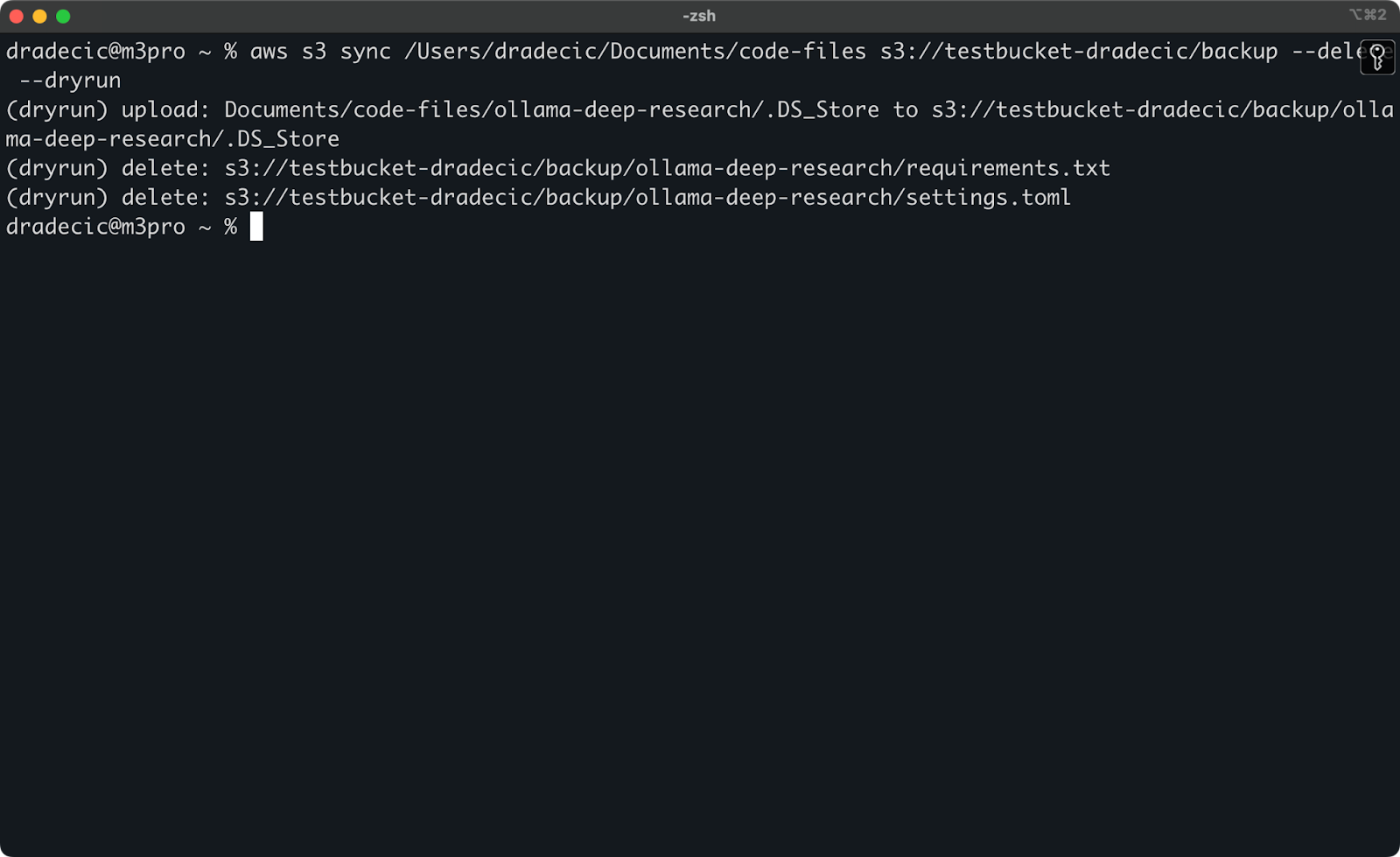
이미지 17 – Dry run
이로써 실제로 명령을 실행했을 때 어떤 일이 발생할지 정확히 보여줍니다. 업로드, 다운로드 또는 삭제될 파일도 포함됩니다.
중요한 데이터를 다룰 때는 특히 --delete 플래그를 사용하는 모든 S3 동기화 명령을 실행하기 전에 항상 --dryrun을 사용하는 것을 권장합니다.
S3 동기화 명령에는 --acl을 사용하여 권한을 설정하는 --storage-class를 선택하는 S3 저장 티어, 그리고 하위 디렉토리를 횡단하는 --recursive와 같은 다른 옵션이 많이 있습니다. 공식 AWS CLI 설명서에서 옵션의 전체 목록을 확인하세요.
기본 및 고급 S3 동기화 옵션에 익숙해졌으므로, 백업 및 복원과 같은 실제 시나리오에 이러한 명령을 사용하는 방법을 살펴봅시다.
AWS S3 백업 및 복원에 대한 S3 동기화 사용
AWS S3 동기화의 가장 인기 있는 사용 사례 중 하나는 중요한 파일을 백업하고 필요할 때 복원하는 것입니다. 동기화 명령을 사용하여 간단한 백업 및 복원 전략을 어떻게 구현할 수 있는지 살펴봅시다.
S3로 백업 생성
S3 동기화로 백업을 만드는 것은 간단합니다. 로컬 디렉토리에서 S3 버킷으로 동기화 명령을 실행하기만 하면 됩니다. 그러나 효과적인 백업을 위해 몇 가지 모범 사례를 따르는 것이 좋습니다.
먼저, 날짜 또는 버전별로 백업을 구성하는 것이 좋습니다. S3 경로에 타임스탬프를 사용하는 간단한 방법은 다음과 같습니다:
# 타임스탬프 변수 생성 TIMESTAMP=$(date +%Y-%m-%d-%H-%M-%S) # 백업 실행 aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backups/$TIMESTAMP
이렇게 하면 각 백업마다 2025-03-10-18-56-42와 같은 타임스탬프가 있는 새 폴더가 생성됩니다. S3에서 확인할 수 있습니다:
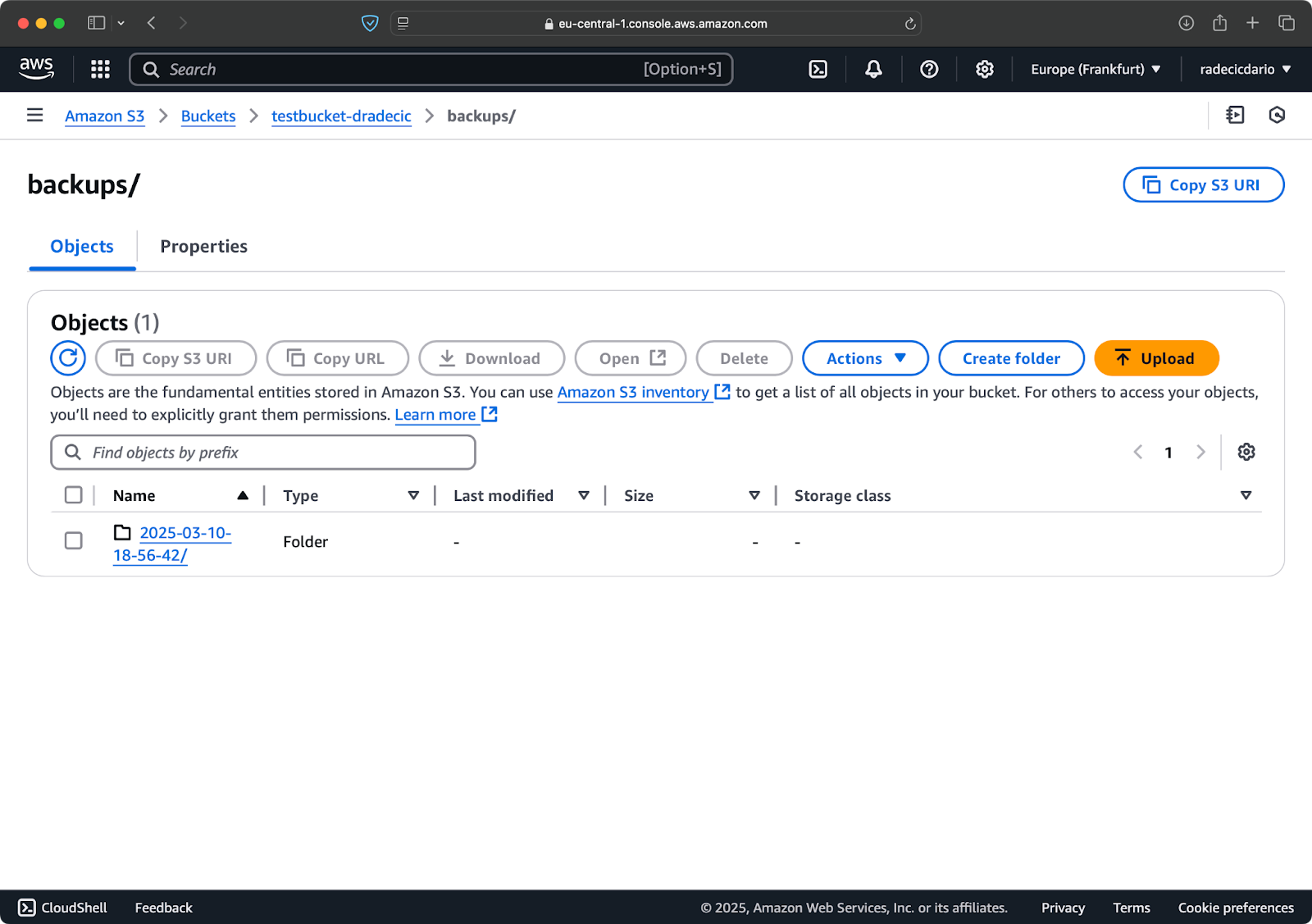
이미지 18 – 타임스탬프가 찍힌 백업
중요한 데이터를 위해 여러 개의 백업 버전을 유지하고 싶을 수 있습니다. 이것은 타임스탬프 기반 백업을 정기적으로 실행함으로써 쉽게 할 수 있습니다.
--storage-class 옵션을 사용하여 백업에 더 비용 효율적인 저장 클래스를 지정할 수도 있습니다:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backups/$TIMESTAMP --storage-class STANDARD_IA
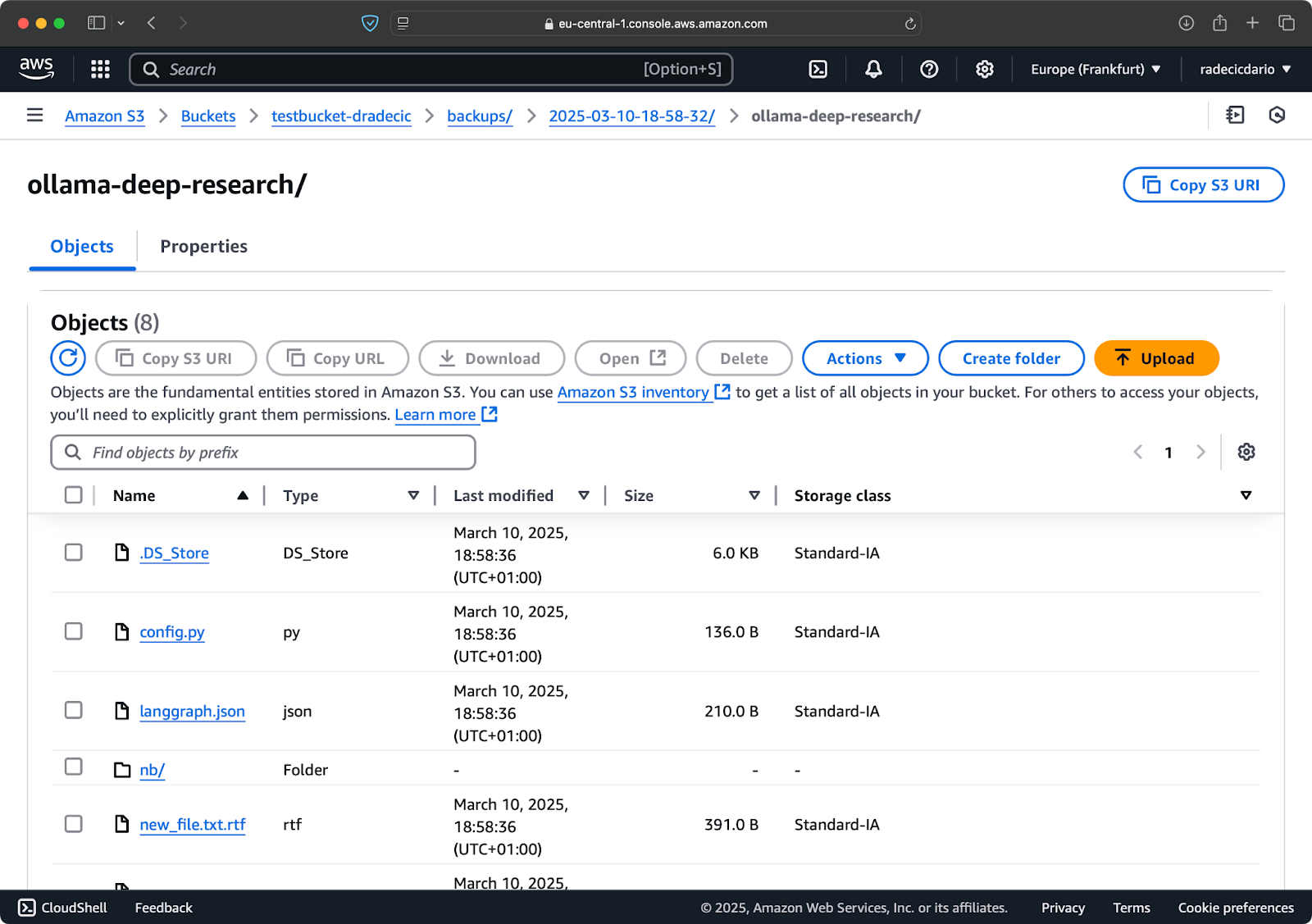
이미지 19 – 사용자 정의 저장 클래스로 백업 콘텐츠
이는 비용이 적게 들지만 약간의 검색 수수료가 있는 S3 저자주기 액세스 저장 클래스를 사용합니다. 장기 보관을 위해 Glacier 저장 클래스를 사용할 수도 있습니다:
aws s3 sync /Users/dradecic/Documents/important-data s3://testbucket-dradecic/backups/$TIMESTAMP --storage-class GLACIER
Glacier에 저장된 파일은 검색하는 데 몇 시간이 걸리므로 신속하게 필요한 데이터에는 적합하지 않습니다.
S3에서 파일 복원
백업에서 복원하는 것도 매우 쉽습니다 – 간단히동기화 명령에서 소스와 대상을 뒤집어주십시오:
# 가장 최근 백업에서 복원(타임스탬프를 알고 있다고 가정) aws s3 sync s3://testbucket-dradecic/backups/2025-03-10-18-56-42 /Users/dradecic/Documents/restored-data
이 명령은 해당 백업에서 모든 파일을 로컬 restored-data 디렉토리로 다운로드합니다:
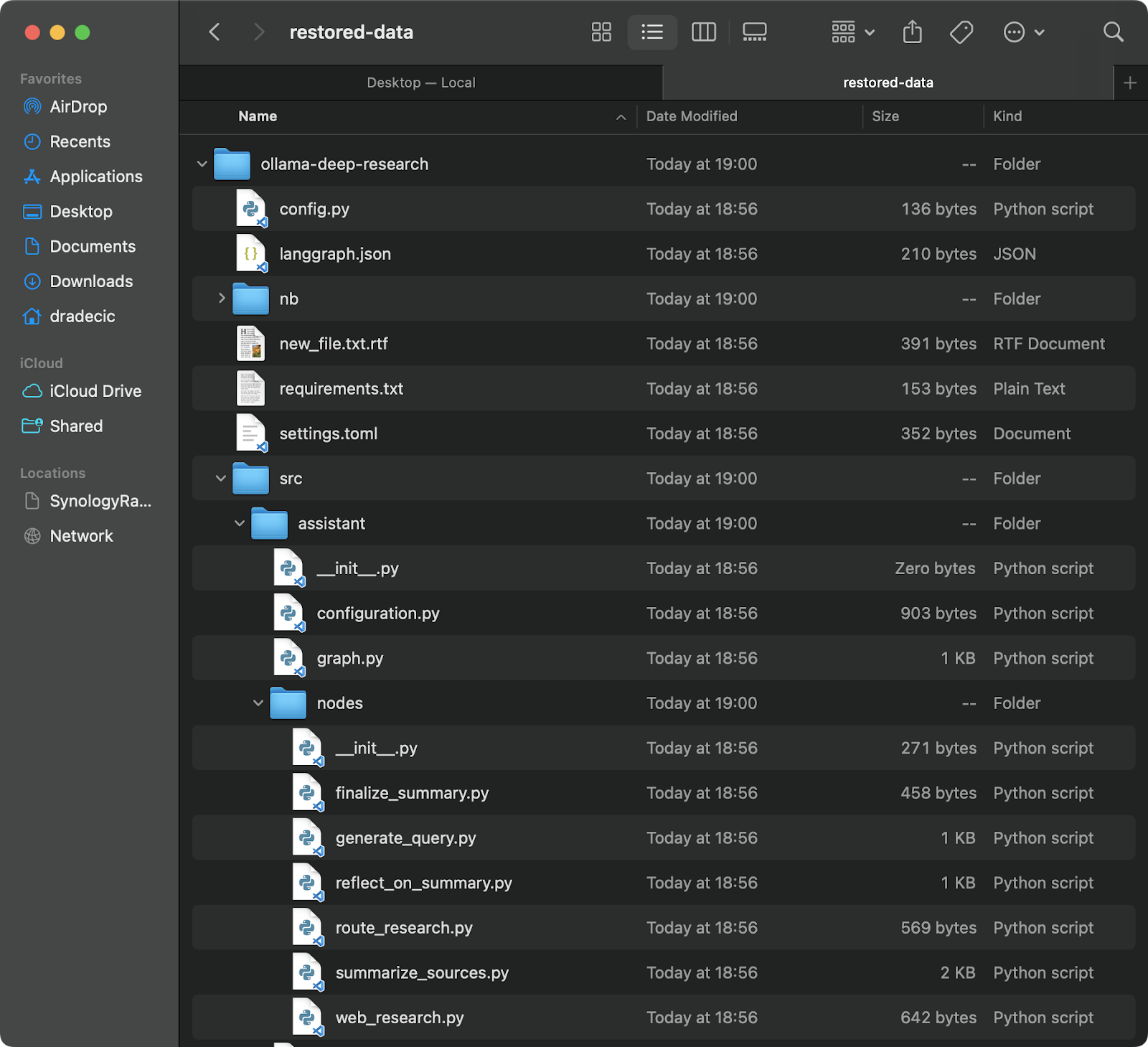
이미지 20 – S3에서 파일 복원하기
정확한 타임스탬프를 기억하지 못하는 경우 먼저 모든 백업을 나열할 수 있습니다:
aws s3 ls s3://testbucket-dradecic/backups/
다음과 같은 내용이 표시됩니다:
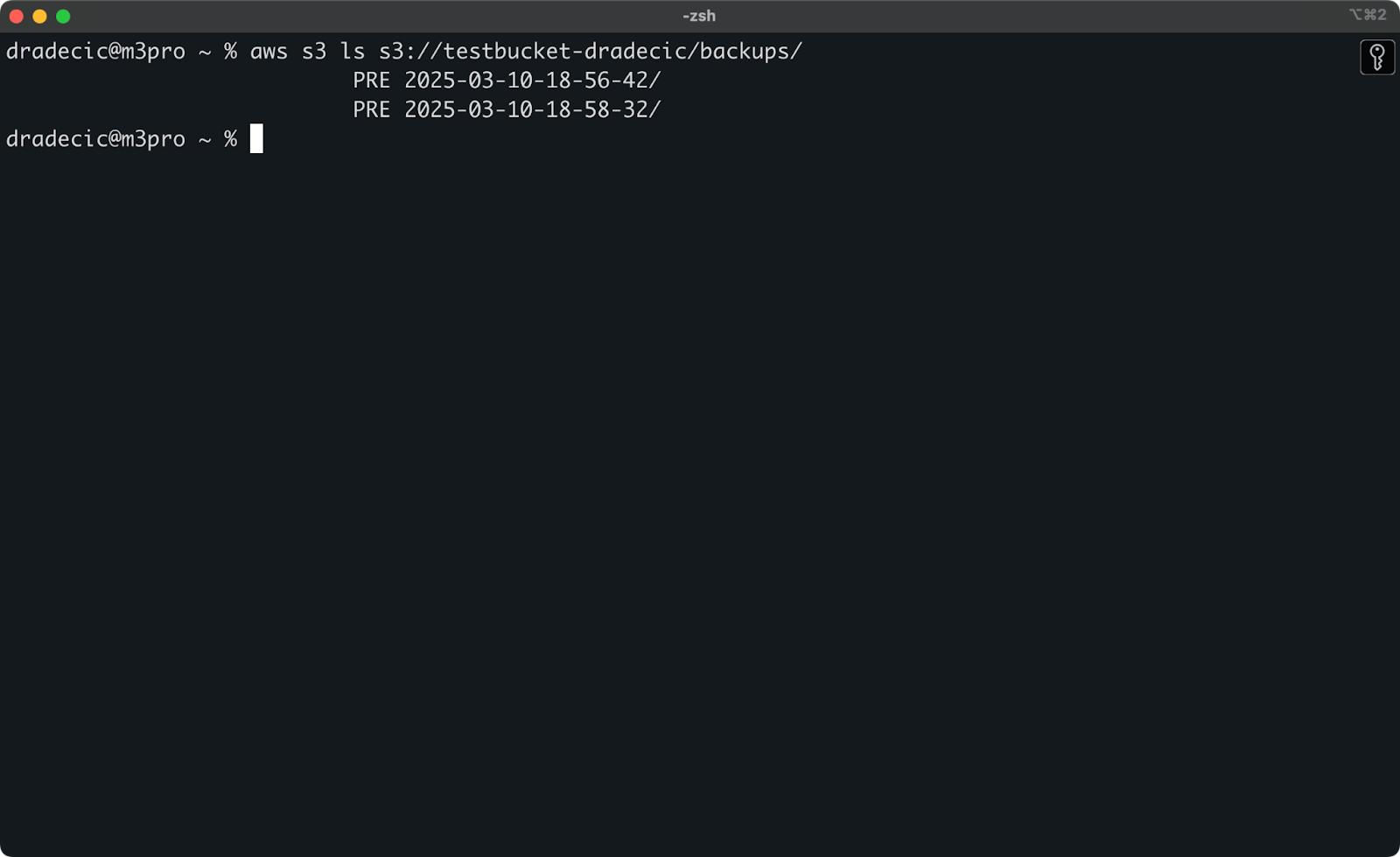
이미지 21 – 백업 목록
이전에 논의한 제외/포함 플래그를 사용하여 특정 파일이나 디렉토리를 백업에서 복원할 수도 있습니다:
# 구성 파일만 복원하기 aws s3 sync s3://testbucket-dradecic/backups/2025-03-10-18-56-42 /Users/dradecic/Documents/restored-configs --exclude "*" --include "*.config" --include "*.toml" --include "*.yaml"
미션 크리티컬 시스템의 경우, Linux/macOS의 cron 작업이나 Windows의 작업 스케줄러와 같은 예약 작업을 사용하여 백업을 자동화하는 것을 권장합니다. 이렇게 하면 수동으로 하는 것을 기억할 필요 없이 데이터를 일관되게 백업할 수 있습니다.
AWS S3 동기화 문제 해결
AWS S3 동기화는 신뢰할 수 있는 도구이지만 가끔 문제가 발생할 수 있습니다. 그럼에도 대부분의 오류는 인적 요인에 기인합니다.
일반적인 동기화 오류
일반적인 문제와 그 해결 방법을 살펴보겠습니다.
- 액세스 거부 오류는 보통 IAM 사용자가 S3 버킷에 액세스하거나 특정 작업을 수행할 필요 권한이 없다는 것을 의미합니다. 이 문제를 해결하려면 다음 중 하나를 시도해보세요:
- IAM 사용자가 적절한 S3 권한(
s3:ListBucket,s3:GetObject,s3:PutObject)을 갖고 있는지 확인하십시오. - 버킷 정책이 사용자 액세스를 명시적으로 거부하지 않았는지 확인하십시오.
- 공개 작업이 필요한 경우 버킷 자체가 공개 액세스를 차단하지 않았는지 확인하십시오.
- 해당 파일 또는 디렉토리가 없음 오류는 일반적으로 동기화 명령어에서 지정한 소스 경로가 존재하지 않을 때 나타납니다. 해결책은 간단합니다 – 경로를 다시 확인하고 존재하는지 확인하십시오. 버킷 이름이나 로컬 디렉토리의 오타에 특히 주의하십시오.
- 파일 크기 제한 큰 파일을 동기화하려고 할 때 오류가 발생할 수 있습니다. 기본적으로 S3 동기화는 최대 5GB 크기의 파일을 처리할 수 있습니다. 더 큰 파일의 경우 타임아웃이나 전송이 불완전할 수 있습니다.
- 5GB보다 큰 파일의 경우
--only-show-errors플래그와--size-only플래그를 함께 사용해야 합니다. 이 조합은 큰 파일 전송 시 출력을 최소화하고 파일 크기만 비교하여 도움이 됩니다:
aws s3 sync /Users/dradecic/large-files s3://testbucket-dradecic/large-files --only-show-errors --size-only
동기화 성능 최적화
S3 동기화가 예상보다 느리게 실행되고 있다면 속도를 높이기 위해 몇 가지 조정을 할 수 있습니다.
- 병렬 전송 사용. 기본적으로 S3 동기화는 제한된 수의 병렬 작업을 사용합니다.
--max-concurrent-requests매개변수를 사용하여 이를 늘릴 수 있습니다:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup --max-concurrent-requests 20
- 덩어리 크기 조정. 큰 파일의 경우 덩어리 크기를 조정하여 전송 속도를 최적화할 수 있습니다. 이는 큰 파일을 기본 8MB 대신 16MB 덩어리로 분할하여 좋은 네트워크 연결에 대해 더 빠를 수 있습니다:
aws s3 sync /Users/dradecic/large-files s3://testbucket-dradecic/backup --cli-read-timeout 120 --multipart-threshold 64MB --multipart-chunksize 16MB
- 스크립트에
--no-progress사용. 자동화된 스크립트에서 S3 동기화를 실행하는 경우 출력을 줄이고 성능을 향상시키기 위해--no-progress플래그를 사용하세요:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup --no-progress
- 로컬 엔드포인트 사용. AWS 리소스가 동일한 지역에 있는 경우 지역 엔드포인트를 지정하면 지연 시간을 줄일 수 있습니다:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup --endpoint-url https://s3.eu-central-1.amazonaws.com
특히 대용량 데이터 전송이나 성능이 낮은 기기에서 실행할 때 이러한 최적화는 동기화 성능을 크게 향상시킬 수 있습니다.
이러한 솔루션을 시도한 후에도 문제가 지속되는 경우 AWS CLI에는 내장된 디버깅 옵션이 있습니다. 동기화 프로세스 중에 무슨 일이 일어나고 있는지에 대한 자세한 정보를 보려면 명령에 --debug를 추가하십시오:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup --debug
다음과 유사한 자세한 로그 메시지가 많이 표시될 것으로 예상됩니다:
이미지 22 – 디버그 모드에서 동기화 실행
그리고 이것이 AWS S3 동기화 문제 해결에 관한 전부입니다. 다른 오류가 발생할 수도 있지만, 99%의 경우, 여기에 해결책을 찾을 수 있을 것입니다.
AWS S3 동기화 요약
요약하면, AWS S3 동기화는 사용하기 간편하면서도 놀라우히 강력한 도구 중 하나입니다. 기본 명령어부터 고급 옵션, 백업 전략 및 문제 해결 팁까지 모든 것을 배웠습니다.
개발자, 시스템 관리자 또는 AWS를 사용하는 모든 사람들에게 S3 동기화 명령어는 필수 도구입니다 – 시간을 절약하고 대역폭 사용량을 줄이며 파일이 필요할 때 필요한 곳에 있도록 보장합니다.
중요한 데이터를 백업하거나 웹 자산을 배포하거나 다른 환경을 동기화하고 있는 경우, AWS S3 동기화는 프로세스를 간편하고 신뢰할 수 있게 만들어 줍니다.
S3 동기화에 익숙해지는 가장 좋은 방법은 사용해 보는 것입니다. 간단한 동기화 작업을 설정해 자신의 파일을 동기화한 후 점차 고급 옵션을 탐색하여 특정 요구에 맞추세요.
중요한 데이터를 다룰 때는 항상 --dryrun을 먼저 사용하고, 특히 --delete 플래그를 사용할 때는 더욱 주의해야 합니다. 발생할 일들을 확인하는 데 추가로 한 분을 쓰는 것이 중요한 파일을 실수로 삭제하는 것보다 나아요.
AWS에 대해 더 알고 싶다면 DataCamp의 다음 강좌를 확인하세요:
DataCamp을 사용하여 AWS 자격증 시험을 준비할 수도 있습니다 – AWS 클라우드 실무자 (CLF-C02).