













Einrichten der AWS CLI und AWS S3
Bevor Sie mit dem Synchronisieren von Dateien mit S3 beginnen können, müssen Sie die AWS CLI ordnungsgemäß einrichten und konfigurieren.
Die Einrichtung der CLI umfasst zwei Hauptschritte: das Installieren des Tools und das Konfigurieren. Ich werde beide Schritte im Folgenden erläutern.
Installation der AWS CLI
Die Installation der AWS CLI variiert leicht je nach Betriebssystem.
Für Windows-Systeme:
- Gehe zur AWS CLI Download-Seite
- Lade den Windows-Installer (64-Bit)
- Führe den Installer aus und folge den Anweisungen
Für Linux-Systeme:
Führe die folgenden drei Befehle über das Terminal aus:
curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip" unzip awscliv2.zip sudo ./aws/install
Für macOS-Systeme:
Wenn du Homebrew installiert hast, führe diese eine Zeile im Terminal aus:
brew install awscli
Wenn Sie kein Homebrew haben, verwenden Sie stattdessen diese beiden Befehle:
curl "https://awscli.amazonaws.com/AWSCLIV2.pkg" -o "AWSCLIV2.pkg" sudo installer -pkg AWSCLIV2.pkg -target /
Sie können den Befehl aws --version auf allen Betriebssystemen ausführen, um zu überprüfen, ob AWS CLI installiert ist. Hier ist, was Sie sehen sollten:
Bild 1 – AWS CLI-Version
Konfigurieren der AWS CLI
Jetzt, da Sie die CLI installiert haben, müssen Sie sie mit Ihren AWS-Anmeldeinformationen konfigurieren.
Annehmen, dass Sie bereits ein AWS-Konto haben, melden Sie sich an und gehen Sie zum IAM-Dienst. Erstellen Sie dort einen neuen Benutzer mit programmatischem Zugriff. Sie sollten dem Benutzer die entsprechende Berechtigung zuweisen, was mindestens S3-Zugriff ist:
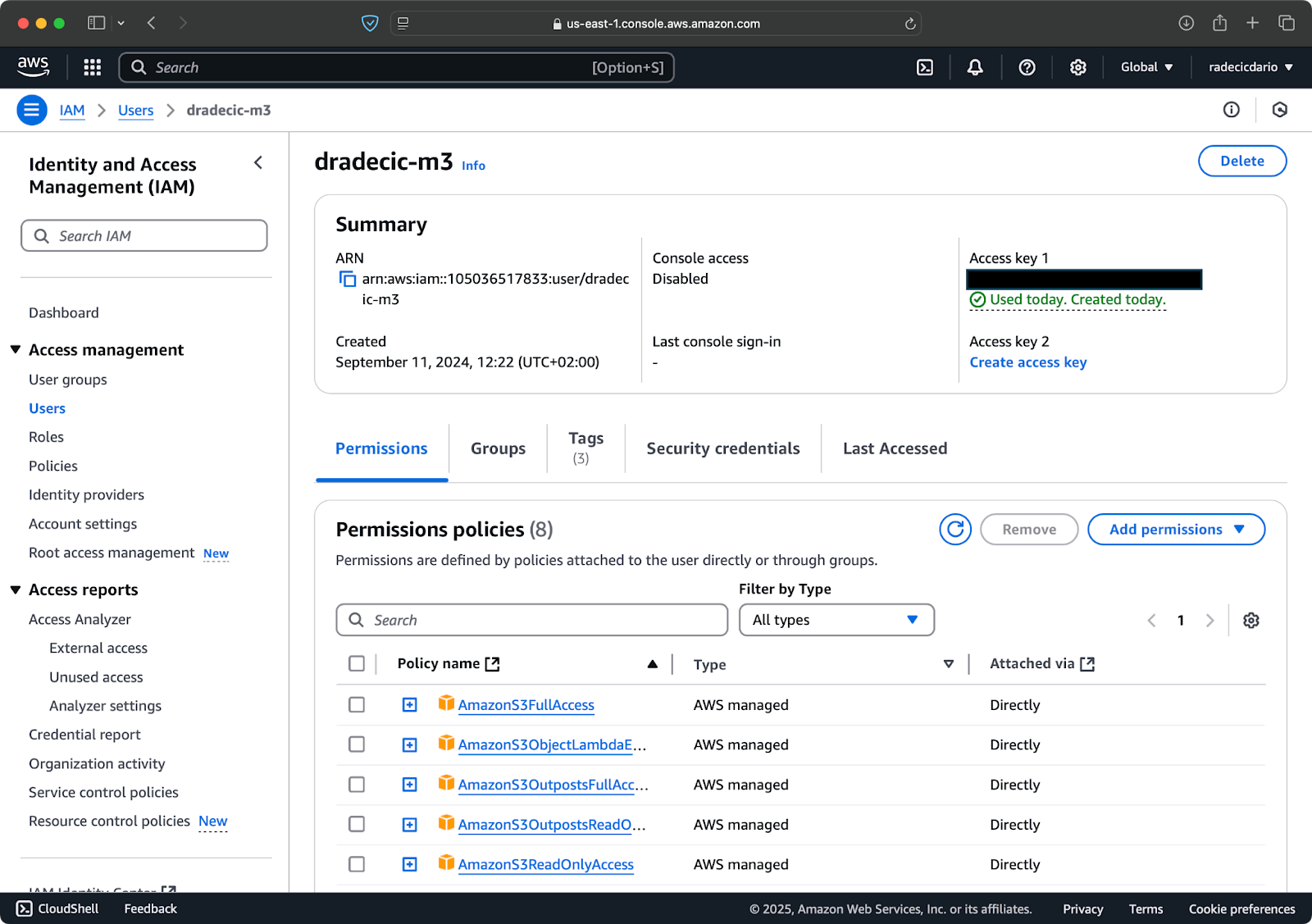
Bild 2 – AWS IAM Benutzer
Sobald dies erledigt ist, gehen Sie zu „Sicherheitsanmeldeinformationen“, um einen neuen Zugriffsschlüssel zu erstellen. Nachdem Sie ihn erstellt haben, haben Sie sowohl die Zugriffsschlüssel-ID als auch den geheimen Zugriffsschlüssel. Notieren Sie sich diese an einem sicheren Ort, da Sie in Zukunft nicht mehr auf sie zugreifen können:
Bild 3 – AWS IAM Benutzeranmeldeinformationen
Gehen Sie zurück ins Terminal und führen Sie den Befehl aws configure aus. Es wird Sie auffordern, Ihre Zugriffsschlüssel-ID, geheimen Zugriffsschlüssel, Region (eu-central-1 in meinem Fall) und bevorzugtes Ausgabeformat (json) einzugeben:
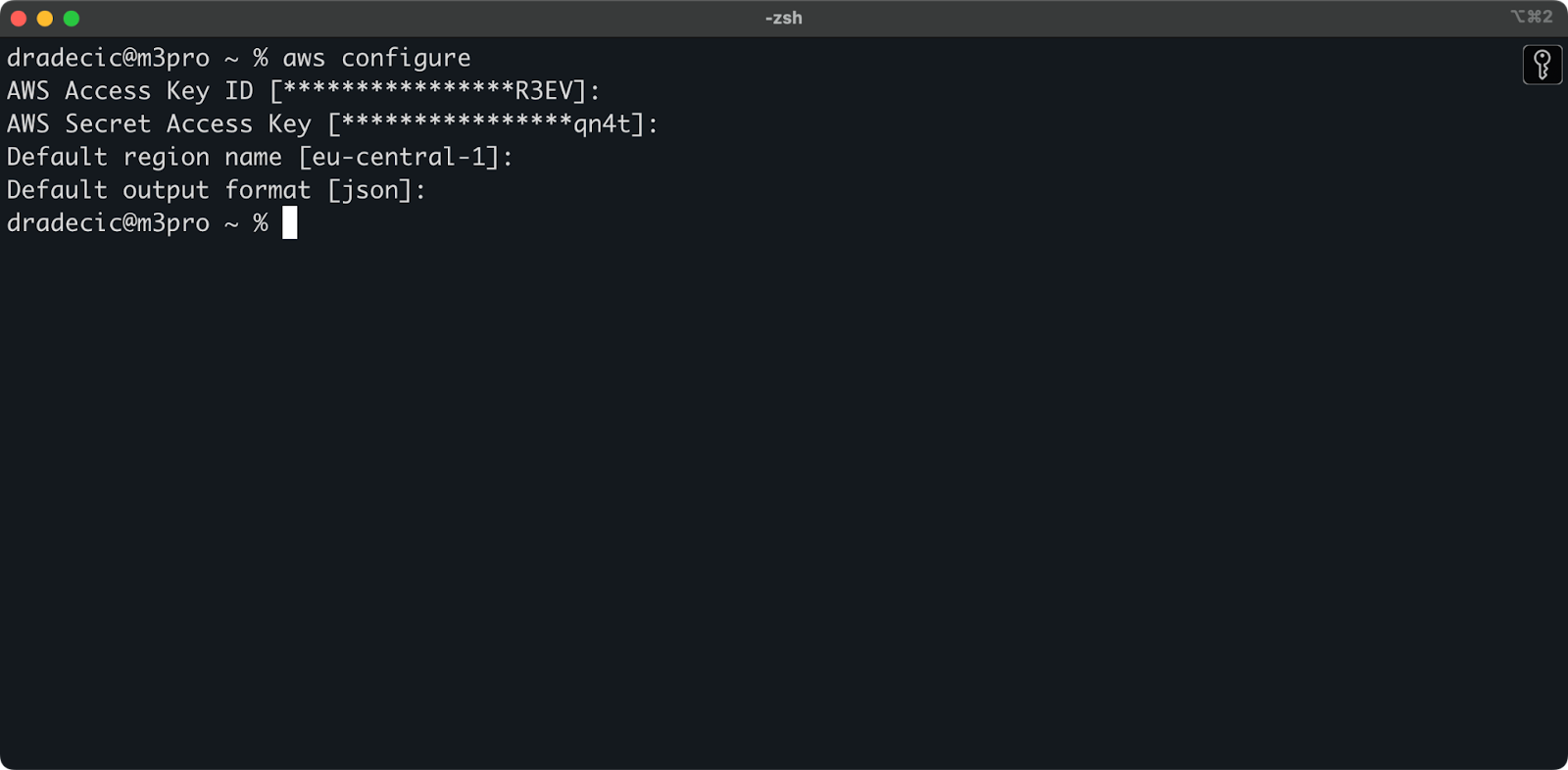
Bild 4 – AWS CLI-Konfiguration
Um zu überprüfen, ob Sie erfolgreich mit Ihrem AWS-Konto von der Befehlszeile aus verbunden sind, führen Sie den folgenden Befehl aus:
aws sts get-caller-identity
Dies ist die Ausgabe, die Sie sehen sollten:
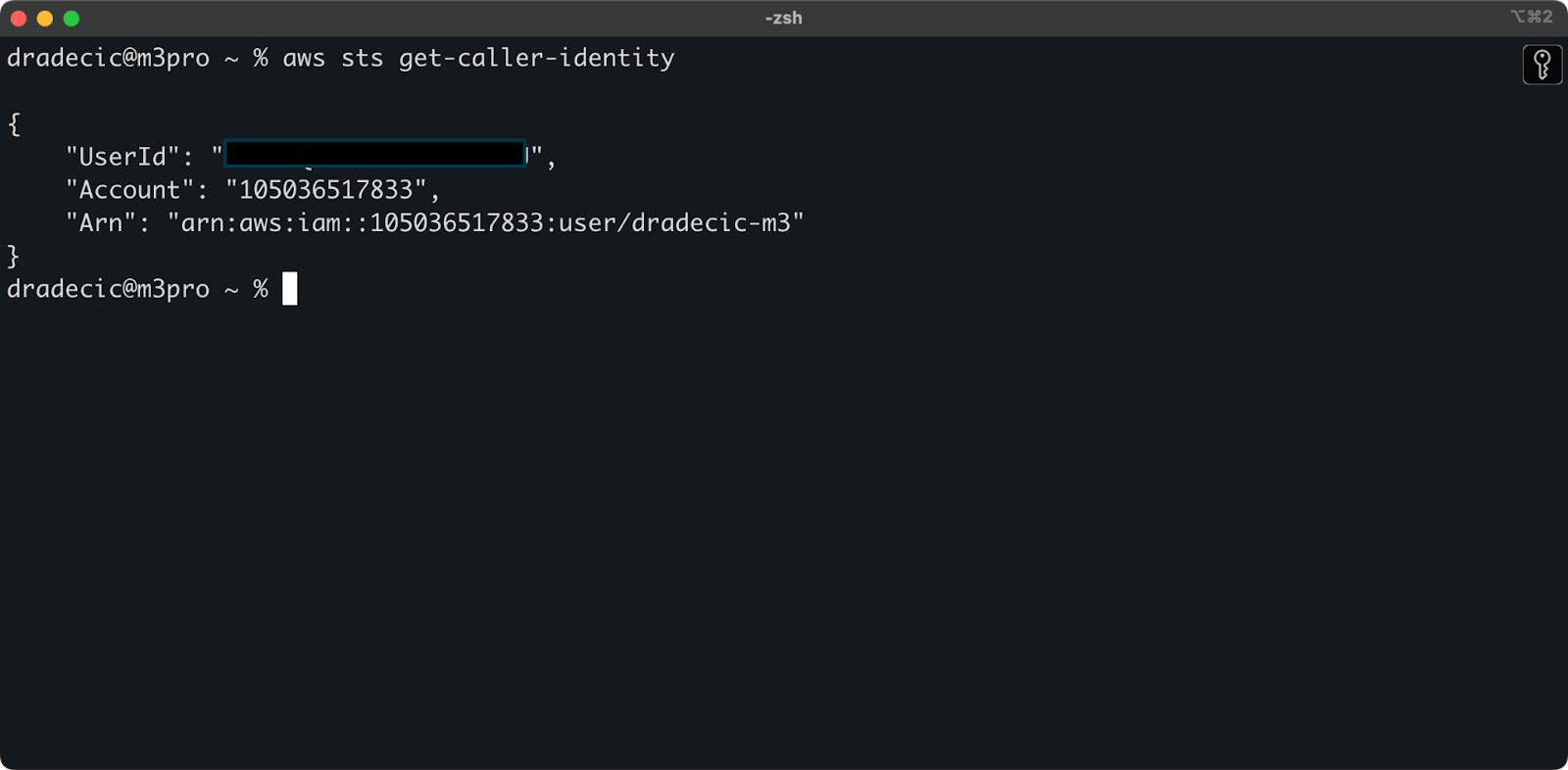
Bild 5 – AWS CLI Testverbindungsbefehl
Und das war’s – nur noch ein Schritt, bevor Sie den S3-Synchronisierungsbefehl verwenden können!
Einrichten eines AWS S3-Buckets
Der letzte Schritt besteht darin, einen S3-Bucket zu erstellen, der Ihre synchronisierten Dateien speichert. Sie können dies über die CLI oder über die AWS Management Console tun. Ich werde Letzteres wählen, um etwas Abwechslung zu bringen.
Um zu beginnen, gehen Sie zur S3-Dienstseite in der Management Console und klicken Sie auf die Schaltfläche „Bucket erstellen“. Wählen Sie dann einen einzigartigen Bucket-Namen (global einzigartig in ganz AWS) und scrollen Sie nach unten, um auf die Schaltfläche „Erstellen“ zu klicken:
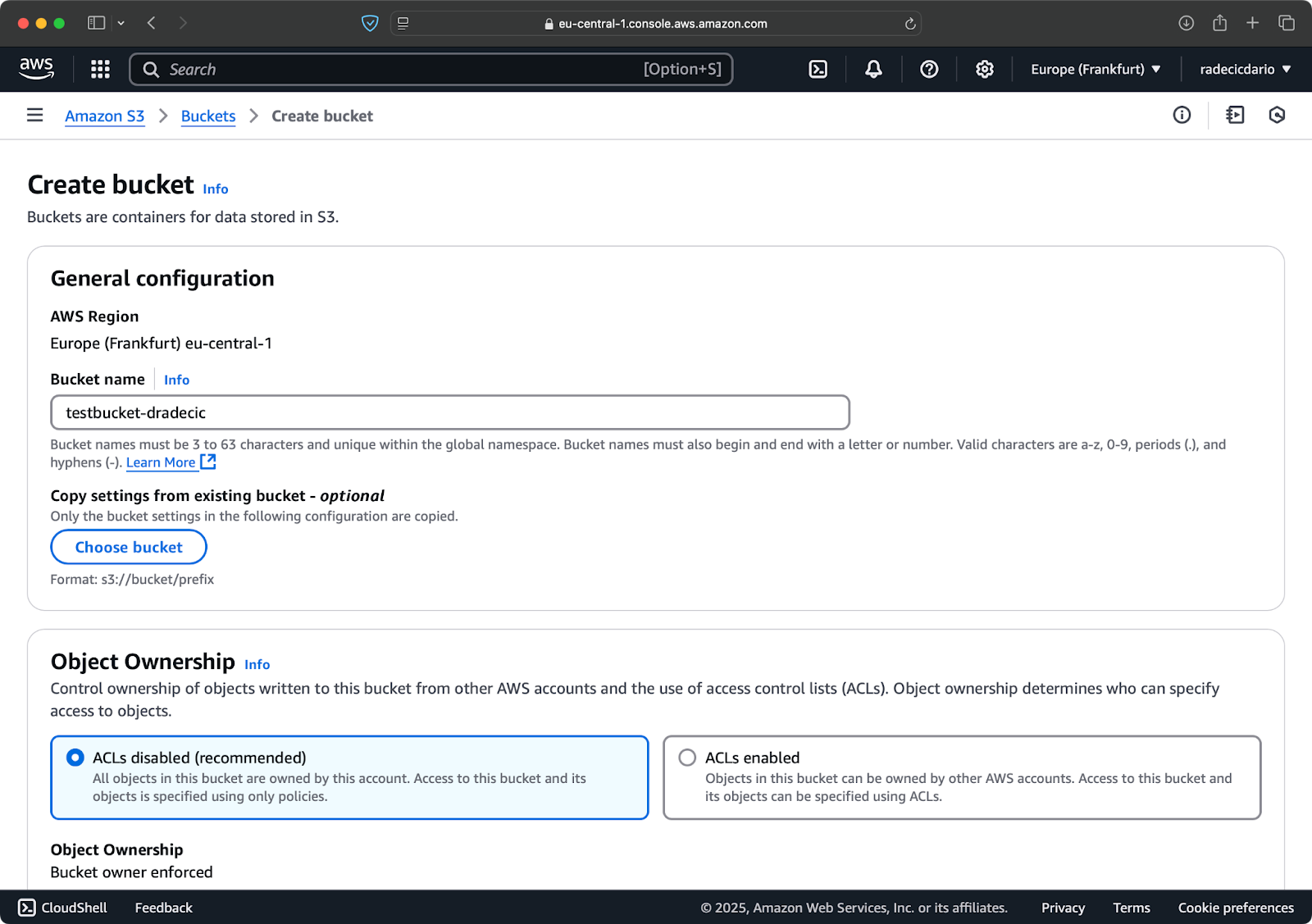
Bild 6 – Erstellung eines AWS Buckets
Der Bucket wurde jetzt erstellt und Sie sehen ihn sofort in der Management Console. Sie können auch überprüfen, ob er über die CLI erstellt wurde:
aws s3 ls
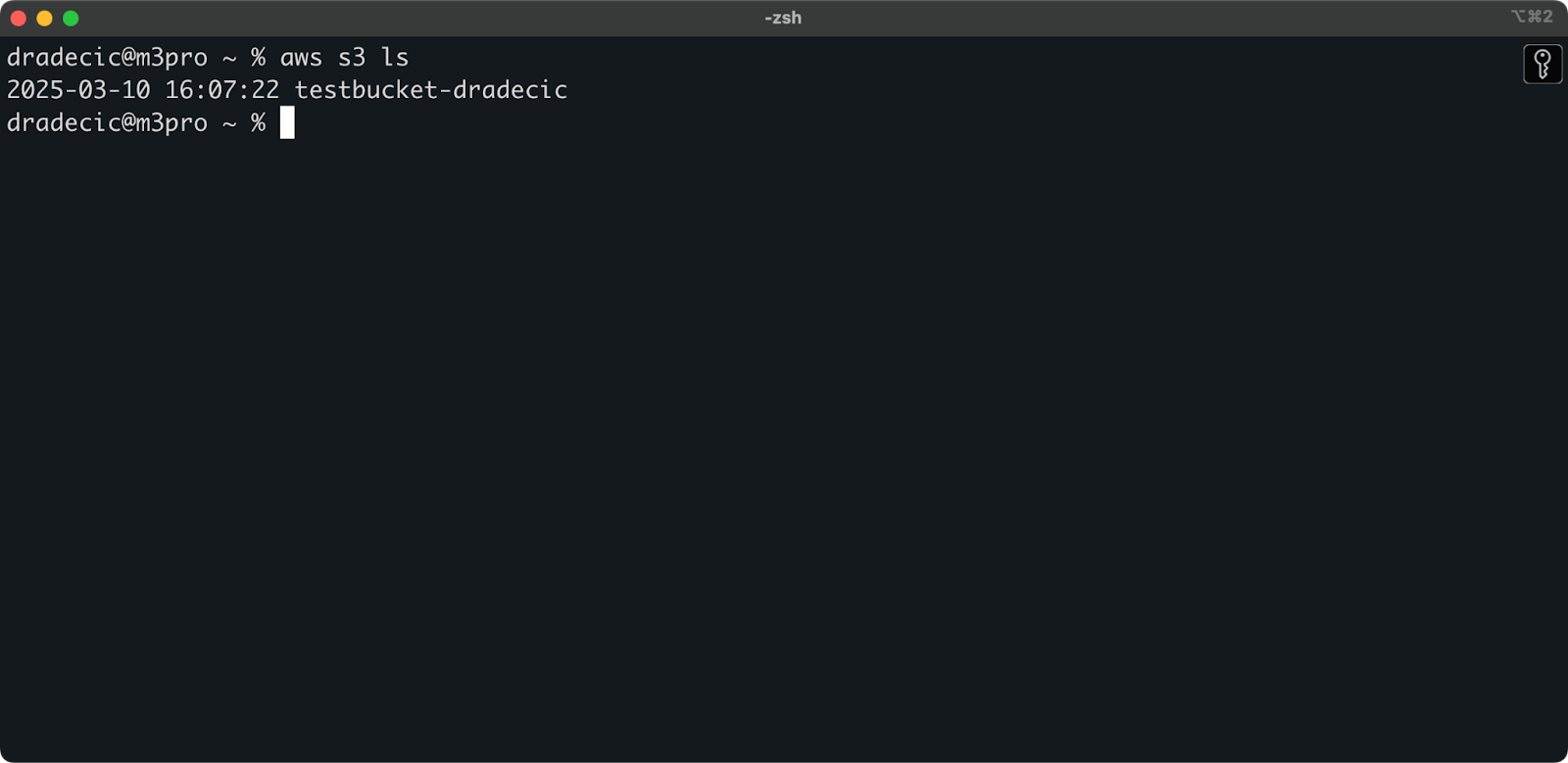
Bild 7 – Alle verfügbaren S3-Buckets
Denken Sie daran, dass S3-Buckets standardmäßig privat sind. Wenn Sie den Bucket für das Hosting öffentlicher Dateien (wie Website-Assets) verwenden möchten, müssen Sie die Bucket-Richtlinien und Berechtigungen entsprechend anpassen.
Jetzt sind Sie bereit und können damit beginnen, Dateien zwischen Ihrem lokalen Rechner und AWS S3 zu synchronisieren!
Grundlegender AWS S3 Sync-Befehl
Jetzt, da Sie die AWS CLI installiert, konfiguriert und einen S3-Bucket bereit haben, ist es an der Zeit, mit der Synchronisierung zu beginnen! Die grundlegende Syntax für den AWS S3 Sync-Befehl ist ziemlich einfach. Lassen Sie mich Ihnen zeigen, wie es funktioniert.
Der S3-Sync-Befehl folgt diesem einfachen Muster:
aws s3 sync <source> <destination> [options]
Der Quell- und Zielort können entweder ein lokaler Verzeichnispfad oder eine S3-URI (beginnend mit s3://) sein. Je nachdem, in welche Richtung Sie synchronisieren möchten, werden Sie diese unterschiedlich anordnen.
Synchronisierung von Dateien von lokal zu einem S3-Bucket
Ich habe kürzlich mit der tiefen Forschung von Ollama experimentiert. Angenommen, das ist der Ordner, den ich mit S3 synchronisieren möchte. Das Hauptverzeichnis befindet sich im Documents-Ordner. So sieht es aus:
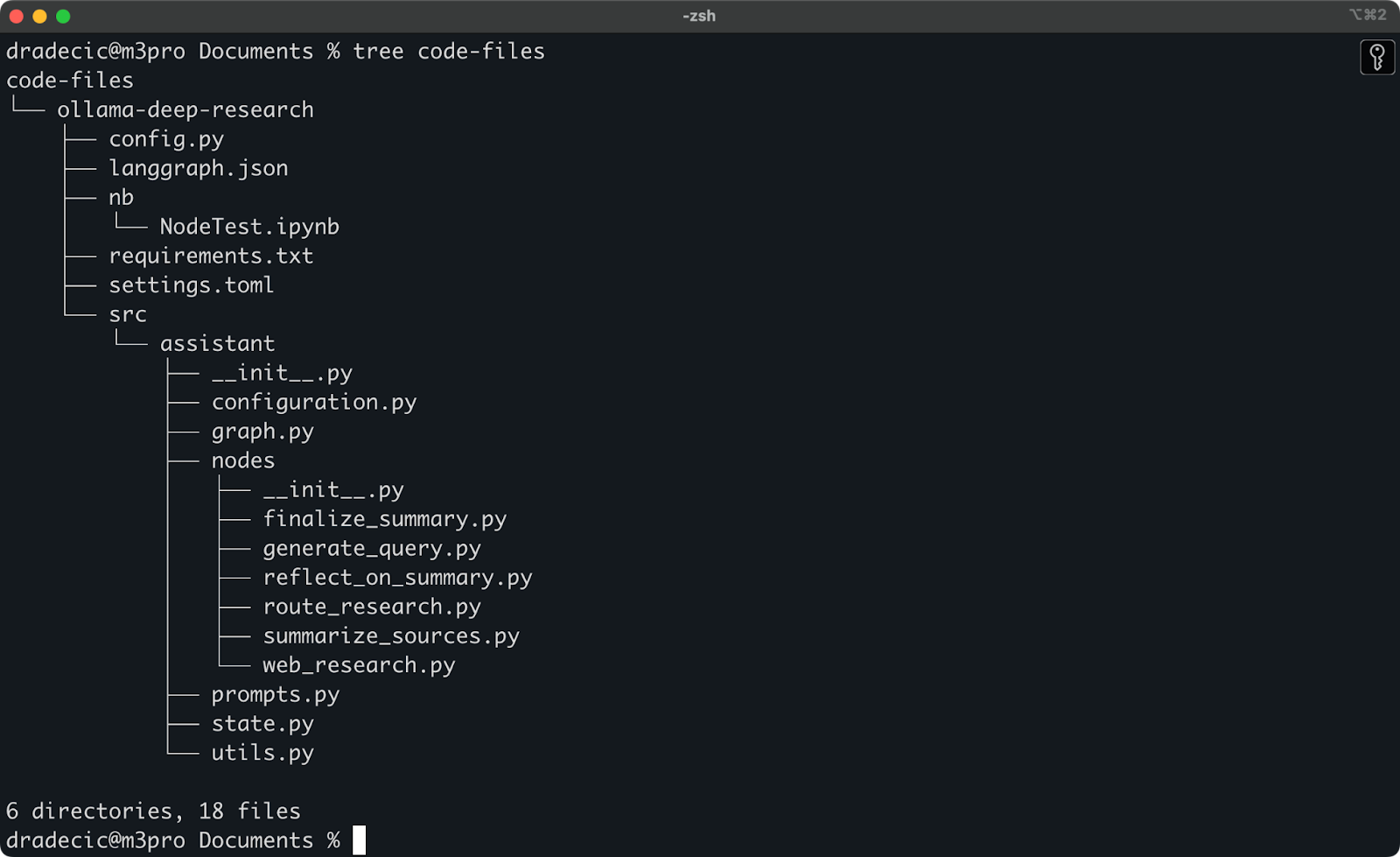
Inhalt des lokalen Ordners
Das ist der Befehl, den ich ausführen muss, um den lokalen code-files-Ordner mit dem backup-Ordner auf dem S3-Bucket zu synchronisieren:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup
Der backup-Ordner auf dem S3-Bucket wird automatisch erstellt, wenn er nicht existiert.
Hier ist, was Sie auf der Konsole sehen werden:
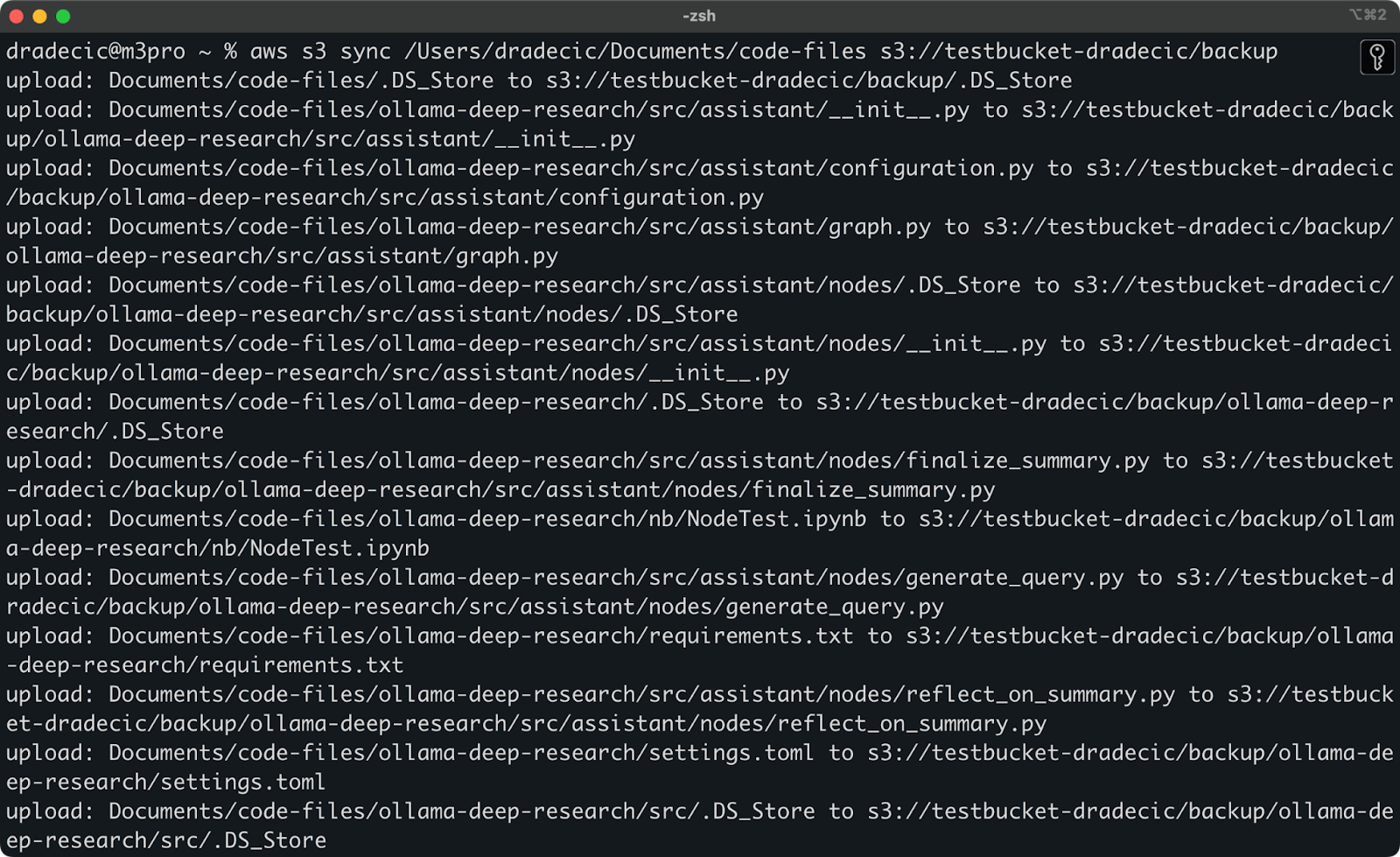
Bild 9 – S3-Synchronisationsprozess
Nach ein paar Sekunden sind die Inhalte des lokalen code-files-Ordners im S3-Bucket verfügbar:
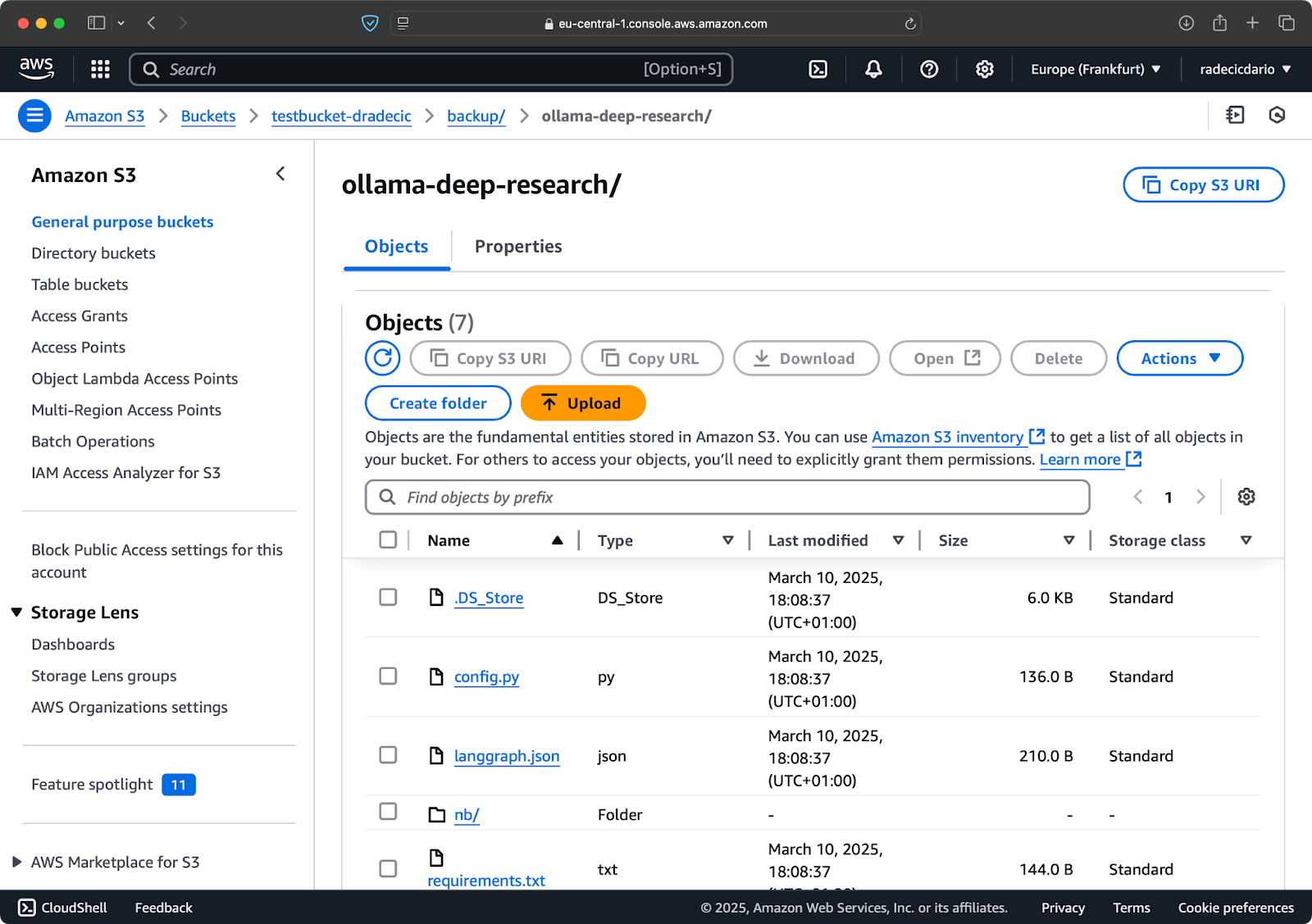
Bild 10 – Inhalt des S3-Buckets
Die Schönheit der S3-Synchronisierung liegt darin, dass sie nur Dateien hochlädt, die im Ziel nicht existieren oder lokal geändert wurden. Wenn Sie denselben Befehl erneut ausführen, ohne etwas zu ändern, sehen Sie… nichts! Das liegt daran, dass die AWS CLI erkannt hat, dass alle Dateien bereits synchronisiert und auf dem neuesten Stand sind.
Jetzt werde ich zwei kleine Änderungen vornehmen – eine neue Datei erstellen (new_file.txt) und eine vorhandene aktualisieren (requirements.txt). Wenn Sie den Synchronisierungsbefehl erneut ausführen, werden nur die neuen oder geänderten Dateien hochgeladen:
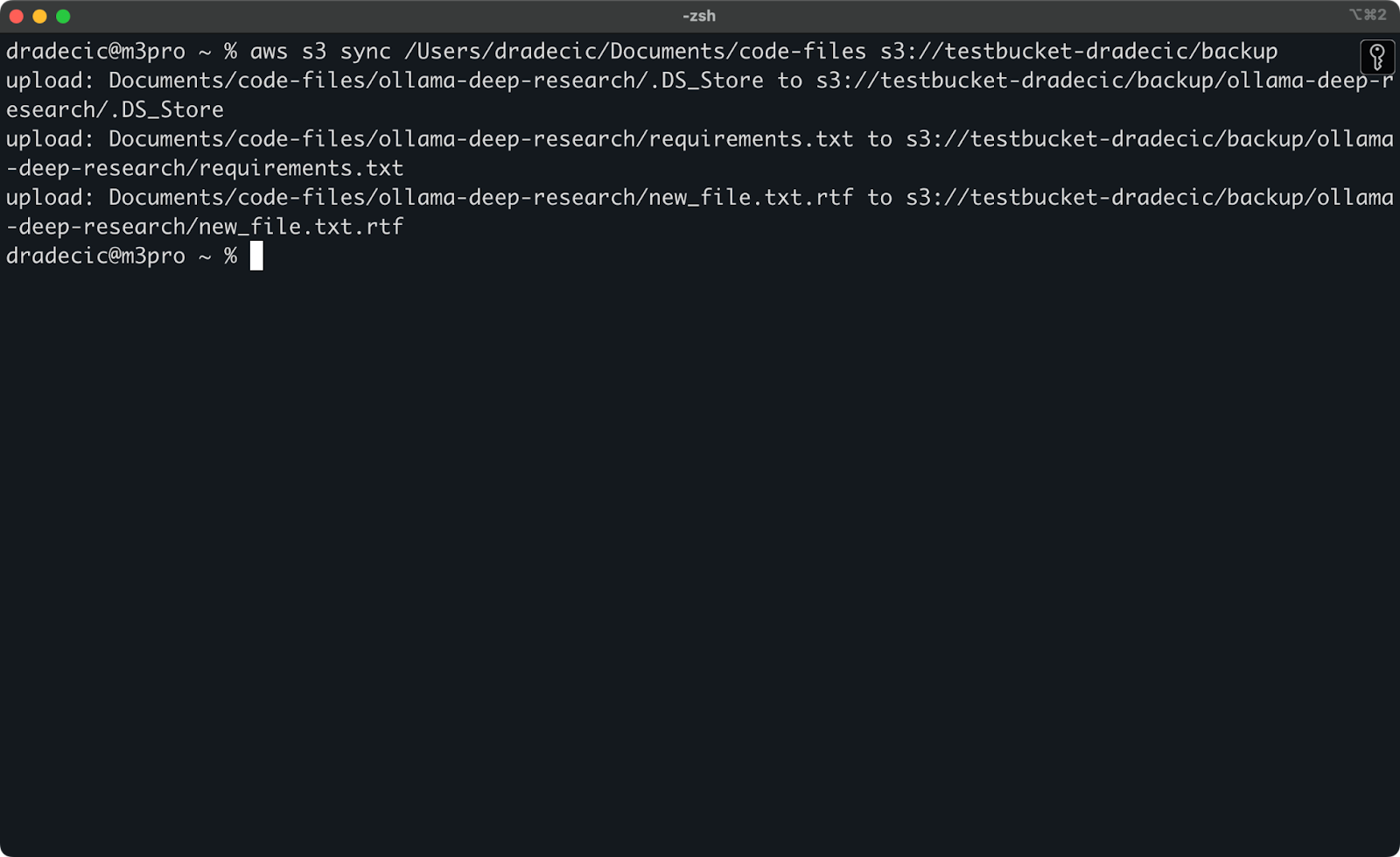
Bild 11 – S3-Synchronisierungsprozess (2)
Und das ist alles, was Sie wissen müssen, wenn Sie lokale Ordner mit S3 synchronisieren. Aber was ist, wenn Sie den umgekehrten Weg gehen möchten?
Synchronisieren von Dateien vom S3-Bucket in ein lokales Verzeichnis
Wenn Sie Dateien von Ihrem S3-Bucket auf Ihren lokalen Rechner herunterladen möchten, tauschen Sie einfach Quelle und Ziel aus:
aws s3 sync s3://testbucket-dradecic/backup /Users/dradecic/Documents/code-files-from-s3
Dieser Befehl lädt alle Dateien aus dem backup-Ordner in Ihrem S3-Bucket in einen lokalen Ordner namens code-files-from-s3 herunter. Wenn der lokale Ordner nicht existiert, erstellt die CLI ihn für Sie:
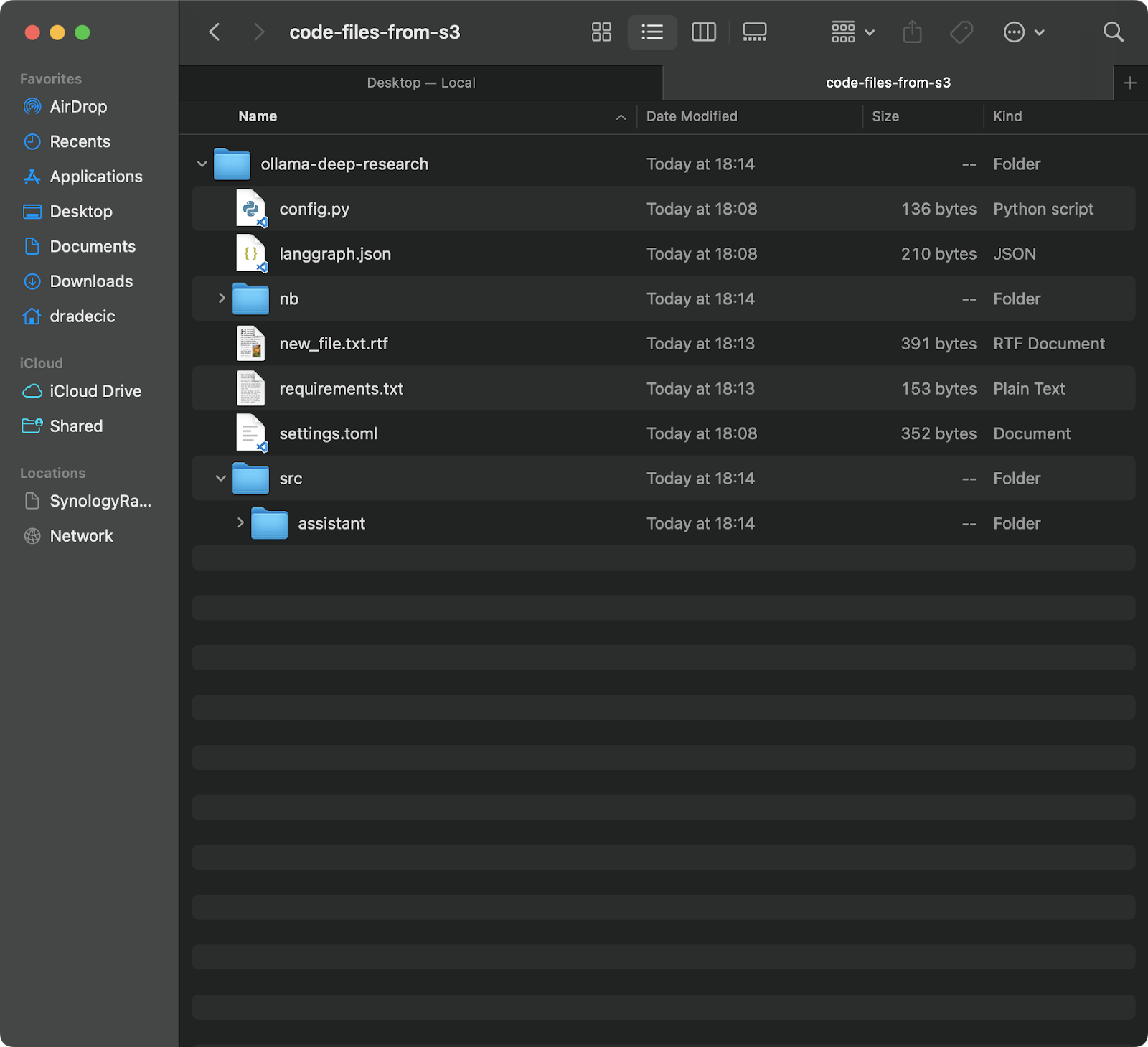
Bild 12 – S3 zu lokal synchronisieren
Es ist erwähnenswert, dass S3-Synchronisierung nicht bidirektional ist. Sie erfolgt immer von der Quelle zum Ziel, wobei das Ziel der Quelle entspricht. Wenn Sie eine Datei lokal löschen und dann mit S3 synchronisieren, bleibt sie weiterhin in S3 vorhanden. Ähnlich, wenn Sie eine Datei in S3 löschen und von S3 lokal synchronisieren, bleibt die lokale Datei unberührt.
Wenn Sie möchten, dass das Ziel genau der Quelle entspricht (einschließlich Löschungen), müssen Sie das --delete-Flag verwenden, das ich im Abschnitt zu den erweiterten Optionen behandeln werde.
Erweiterte AWS S3-Synchronisierungsoptionen
Der zuvor behandelte grundlegende S3-Synchronisierungsbefehl ist allein schon mächtig, aber AWS hat ihn mit zusätzlichen Optionen ausgestattet, die Ihnen mehr Kontrolle über den Synchronisierungsprozess geben.
In diesem Abschnitt zeige ich Ihnen einige der nützlichsten Flags, die Sie zu dem Grundbefehl hinzufügen können.
Nur neue oder geänderte Dateien synchronisieren
Standardmäßig verwendet S3 Sync einen grundlegenden Vergleichsmechanismus, der Dateigröße und Änderungszeit überprüft, um festzustellen, ob eine Datei synchronisiert werden muss. Dieser Ansatz erfasst jedoch möglicherweise nicht immer alle Änderungen, insbesondere bei Dateien, die geändert, aber gleich groß geblieben sind.
Für eine genauere Synchronisierung können Sie das Flag --exact-timestamps verwenden:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup --exact-timestamps
Dies zwingt die S3-Synchronisation, Zeitstempel mit einer Genauigkeit bis zu Millisekunden zu vergleichen. Beachten Sie, dass die Verwendung dieses Flags den Synchronisationsprozess leicht verlangsamen kann, da detailliertere Vergleiche erforderlich sind.verlangsamen den Sync-Prozess leicht, da genauere Vergleiche erforderlich sind.
Ausschluss oder Einbeziehung bestimmter Dateien
Manchmal möchte man nicht alle Dateien in einem Verzeichnis synchronisieren. Vielleicht möchten Sie temporäre Dateien, Protokolle oder bestimmte Dateitypen ausschließen (wie .DS_Store in meinem Fall). Hier kommen die Flags --exclude und --include zum Einsatz.
Aber um einen Punkt zu veranschaulichen, sagen wir, ich möchte mein Code-Verzeichnis synchronisieren, aber alle Python-Dateien ausschließen:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup --exclude "*.py"
Jetzt werden viel weniger Dateien mit S3 synchronisiert:
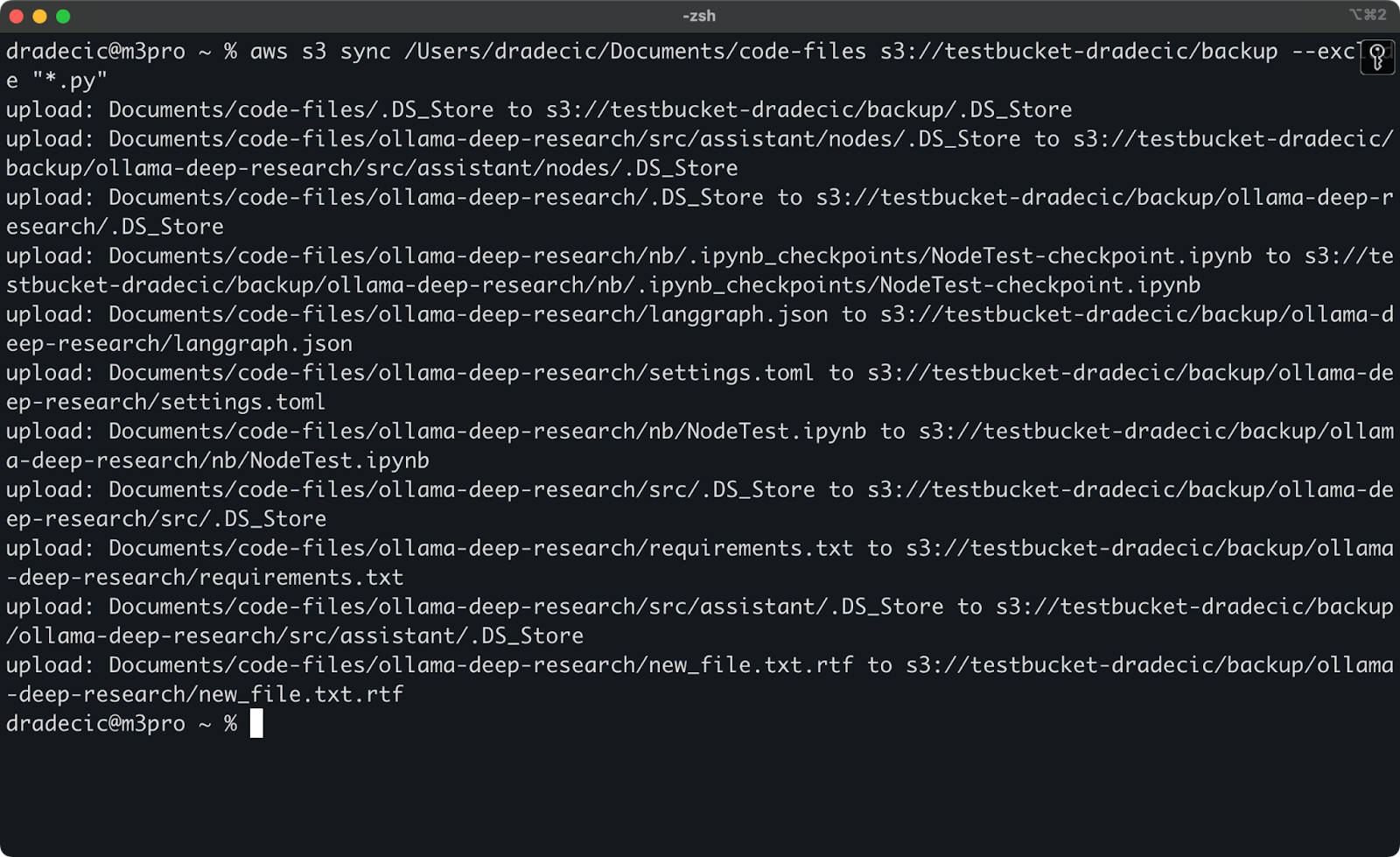
Bild 13 – S3-Synchronisation mit ausgeschlossenen Python-Dateien
Sie können auch --exclude und --include kombinieren, um komplexere Muster zu erstellen. Zum Beispiel, alles außer Python-Dateien ausschließen:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup --exclude "*" --include "*.py"
Die Muster werden in der angegebenen Reihenfolge ausgewertet, daher ist die Reihenfolge wichtig! Das sehen Sie, wenn Sie diese Flags verwenden:
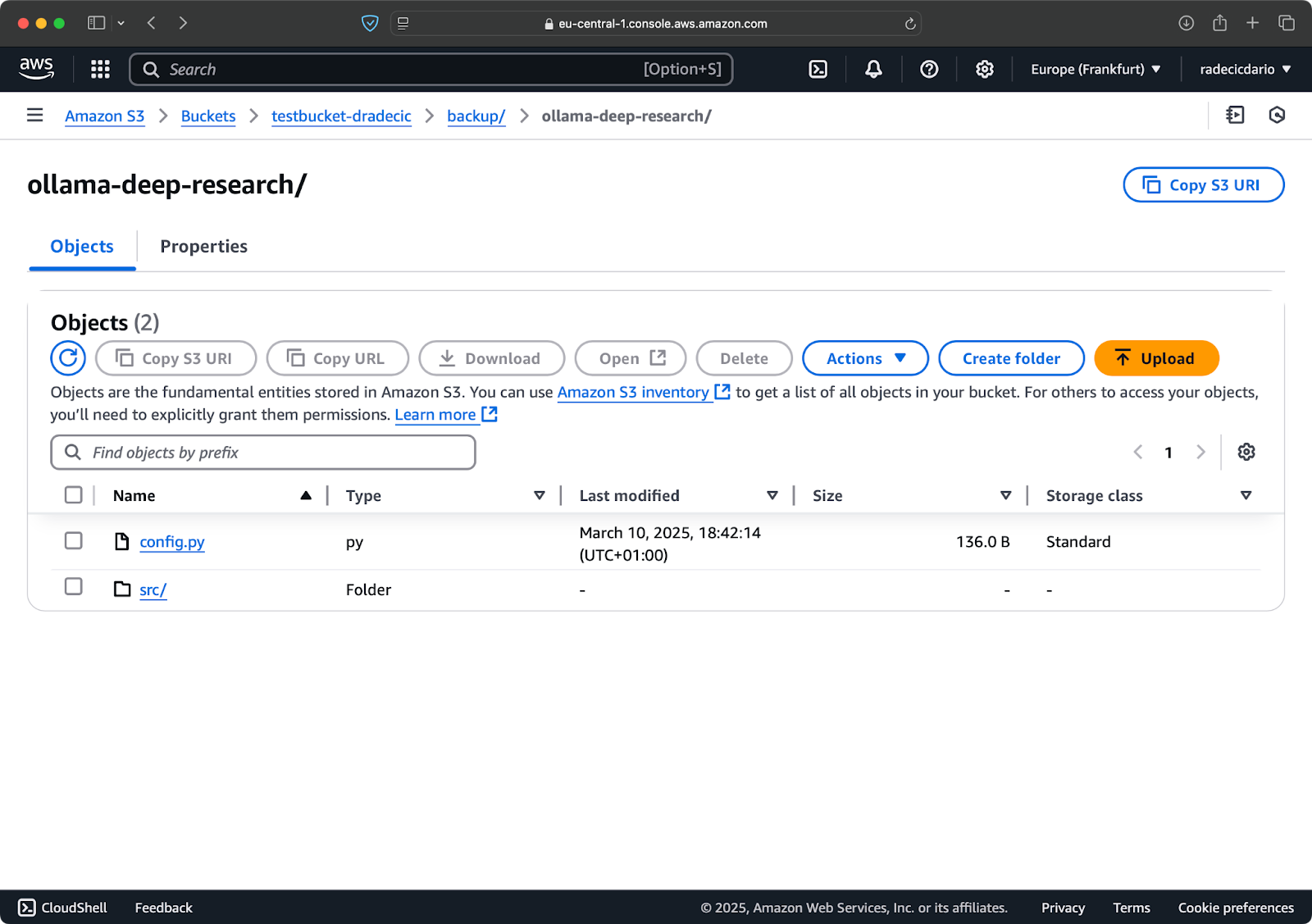
Bild 14 – Ausschluss- und Einschluss-Flags
Jetzt werden nur die Python-Dateien synchronisiert, und wichtige Konfigurationsdateien fehlen.
Dateien vom Ziel löschen
Standardmäßig fügt S3 Sync nur Dateien im Ziel hinzu oder aktualisiert sie – es löscht sie niemals. Das bedeutet, dass, wenn Sie eine Datei aus der Quelle löschen, sie nach dem Synchronisieren weiterhin im Ziel bleibt.
Um das Ziel genau so zu spiegeln wie die Quelle, einschließlich der Löschungen, verwenden Sie das --delete-Flag:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup --delete
Wenn Sie dies zum ersten Mal ausführen, werden alle lokalen Dateien mit S3 synchronisiert:
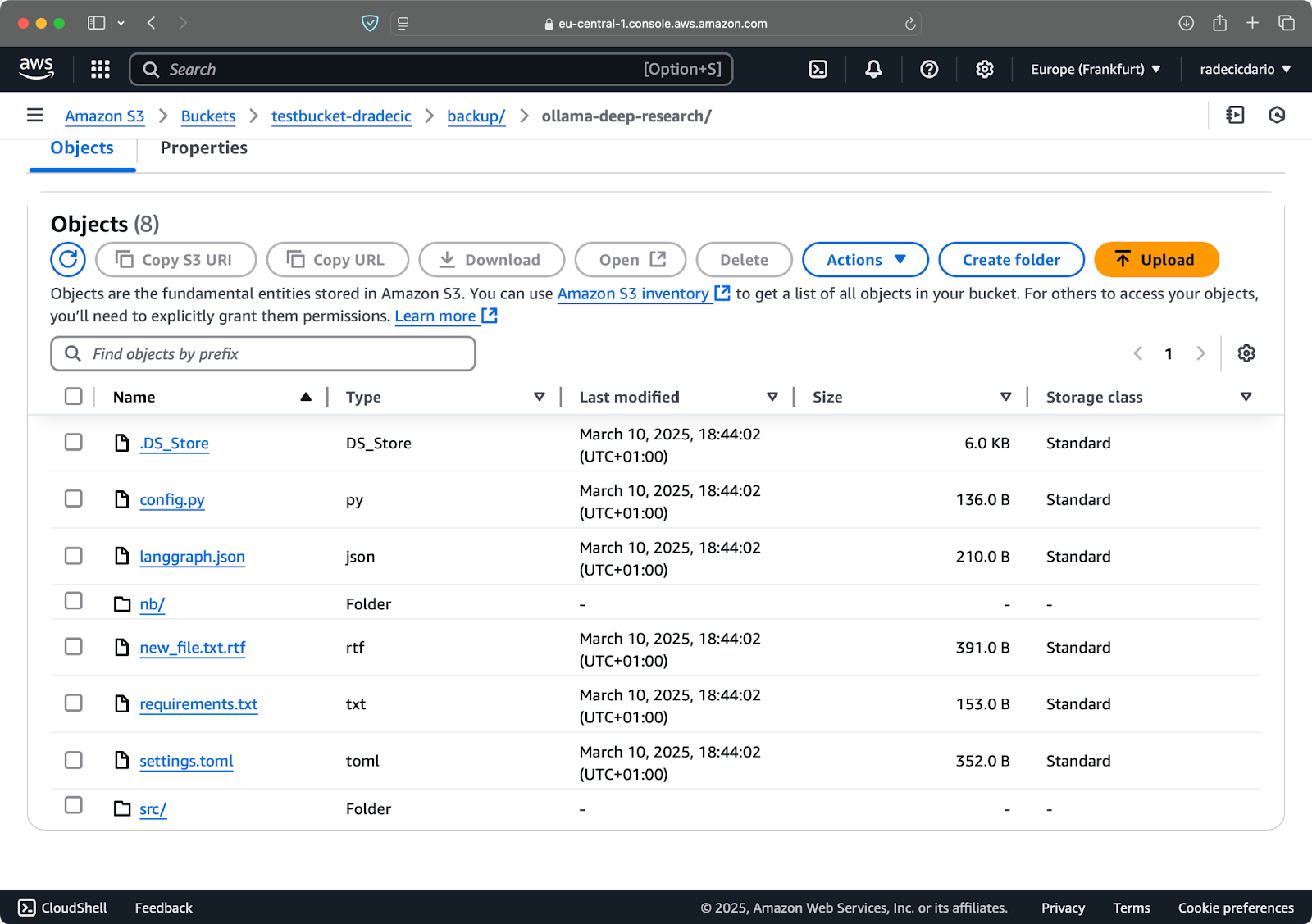
Bild 15 – Lösch-Flag
Dies ist besonders nützlich für die Aufrechterhaltung genauer Kopien von Verzeichnissen. Aber seien Sie vorsichtig – dieses Flag kann zu Datenverlust führen, wenn es falsch verwendet wird.
Sagen wir, ich lösche config.py aus meinem lokalen Ordner und führe den Sync-Befehl mit dem --delete Flag aus:
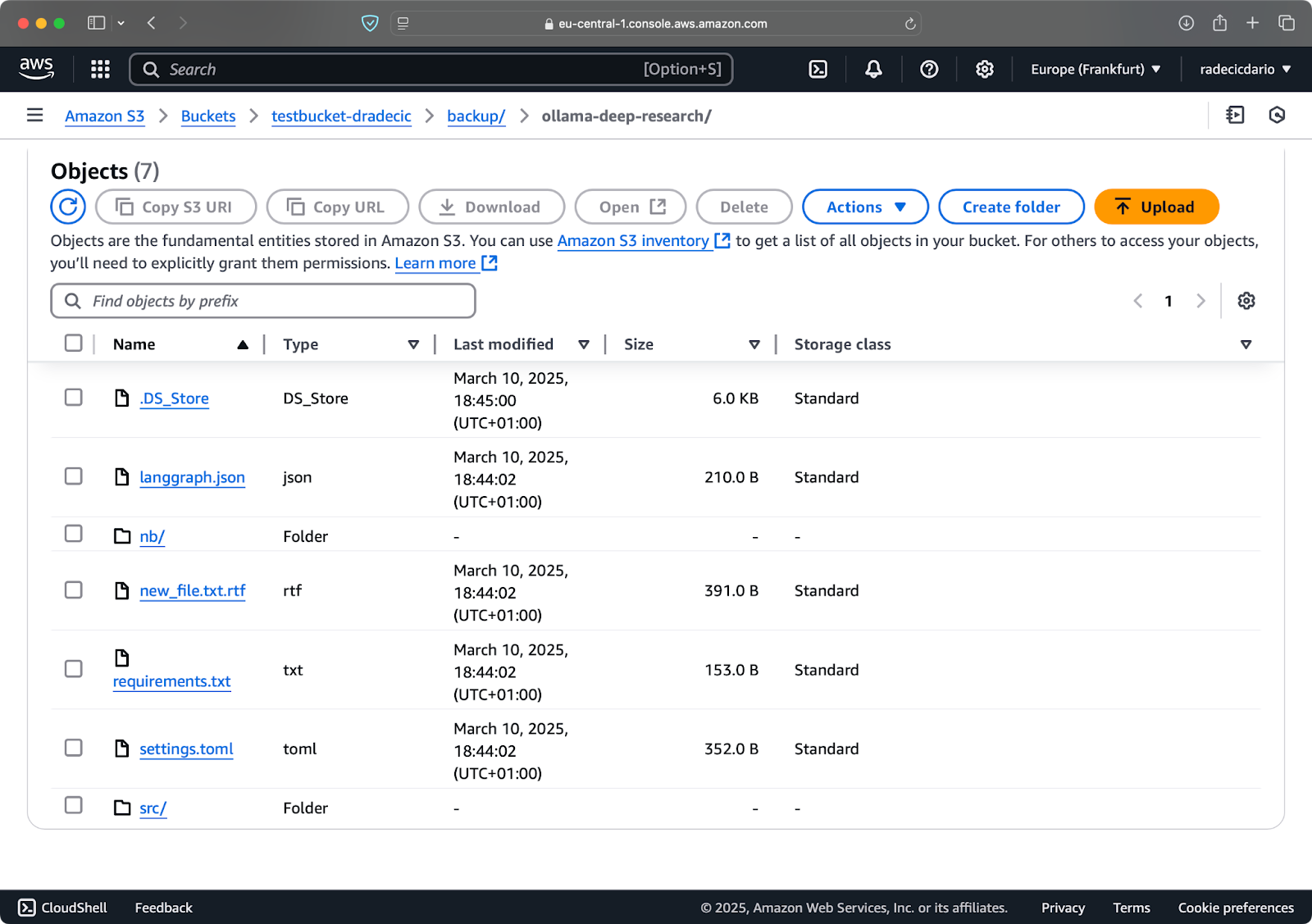
Bild 16 – Lösch-Flag (2)
Wie Sie sehen können, synchronisiert der Befehl nicht nur neue und geänderte Dateien, sondern löscht auch Dateien aus dem S3-Bucket, die im lokalen Verzeichnis nicht mehr vorhanden sind.
Einrichten einer Trockenlauf-Funktion für sichere Synchronisierung
Die gefährlichsten S3-Synchronisierungsvorgänge sind diejenigen, die die --delete-Flagge verwenden. Um zu vermeiden, dass wichtige Dateien versehentlich gelöscht werden, können Sie die --dryrun-Flagge verwenden, um den Vorgang zu simulieren, ohne tatsächlich Änderungen vorzunehmen:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup --delete --dryrun
Zur Demonstration habe ich die Dateien requirements.txt und settings.toml aus einem lokalen Ordner gelöscht und dann den Befehl ausgeführt:
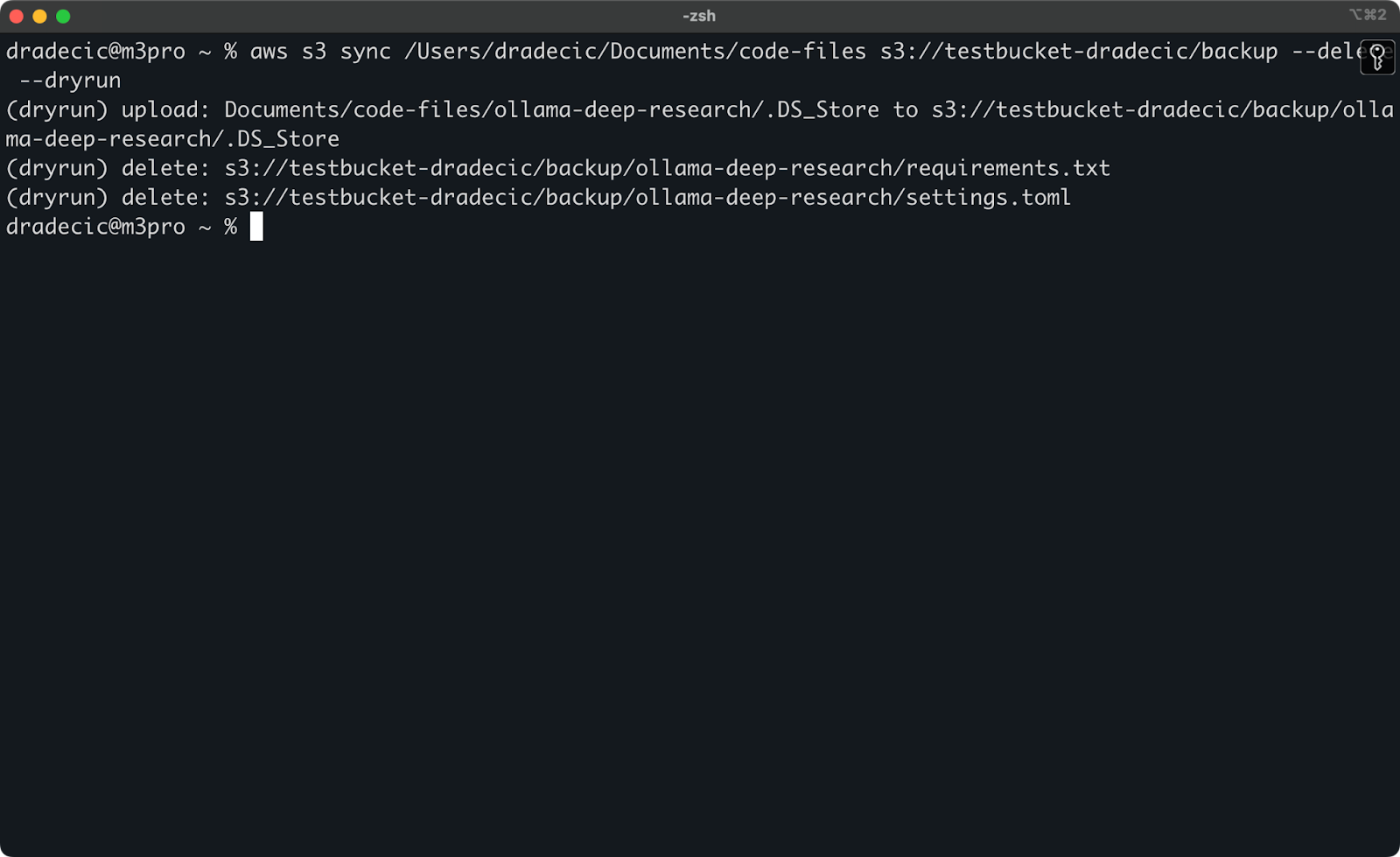
Bild 17 – Trockenlauf
Dies zeigt Ihnen genau, was passieren würde, wenn Sie den Befehl tatsächlich ausführen, einschließlich der hochgeladenen, heruntergeladenen oder gelöschten Dateien.
Ich empfehle immer, --dryrun zu verwenden, bevor Sie einen S3-Synchronisierungsbefehl mit der --delete-Flagge ausführen, insbesondere bei der Arbeit mit wichtigen Daten.
Es gibt viele andere Optionen für den S3-Synchronisationsbefehl, wie --acl zum Festlegen von Berechtigungen, --storage-class zur Auswahl der S3-Speicherklasse und --recursive zum Durchsuchen von Unterverzeichnissen. Schauen Sie sich die offizielle AWS CLI-Dokumentation für eine vollständige Liste der Optionen an.
Jetzt, da Sie mit den grundlegenden und erweiterten S3-Synchronisierungsoptionen vertraut sind, schauen wir uns an, wie Sie diese Befehle für praktische Szenarien wie Backups und Wiederherstellungen verwenden können.
Verwendung von AWS S3 Sync für Backup und Wiederherstellung
Einer der beliebtesten Anwendungsfälle für AWS S3 Sync besteht darin, wichtige Dateien zu sichern und sie bei Bedarf wiederherzustellen. Erfahren Sie, wie Sie eine einfache Backup- und Wiederherstellungsstrategie mithilfe des Sync-Befehls implementieren können.
Erstellen von Backups in S3
Das Erstellen von Backups mit S3-Synchronisierung ist unkompliziert – Sie müssen einfach den Synchronisierungsbefehl von Ihrem lokalen Verzeichnis zu einem S3-Bucket ausführen. Es gibt jedoch einige bewährte Verfahren, die für effektive Backups befolgt werden sollten.
Erstens ist es eine gute Idee, Ihre Backups nach Datum oder Version zu organisieren. Hier ist ein einfacher Ansatz unter Verwendung eines Zeitstempels im S3-Pfad:
# Erstellen einer Zeitstempelvariablen TIMESTAMP=$(date +%Y-%m-%d-%H-%M-%S) # Backup ausführen aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backups/$TIMESTAMP
Dies erstellt für jedes Backup einen neuen Ordner mit einem Zeitstempel wie 2025-03-10-18-56-42. So sieht es auf S3 aus:
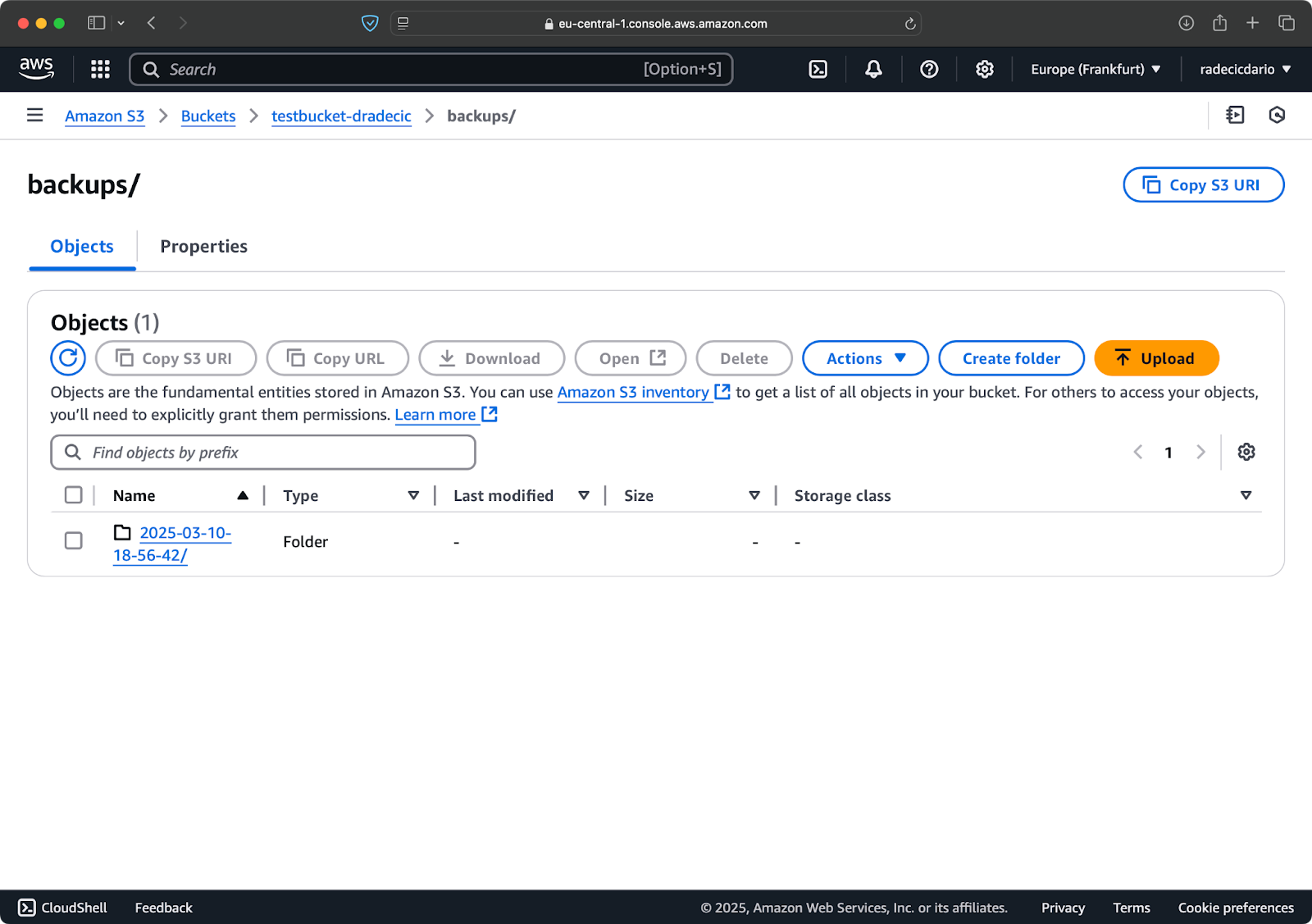
Bild 18 – Zeitstempel-Backups
Für kritische Daten möchten Sie möglicherweise mehrere Backup-Versionen aufbewahren. Dies ist einfach zu bewerkstelligen, indem Sie das zeitstempelbasierte Backup regelmäßig ausführen.
Sie können auch die --storage-class Option verwenden, um eine kosteneffizientere Speicherklasse für Ihre Backups anzugeben:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backups/$TIMESTAMP --storage-class STANDARD_IA
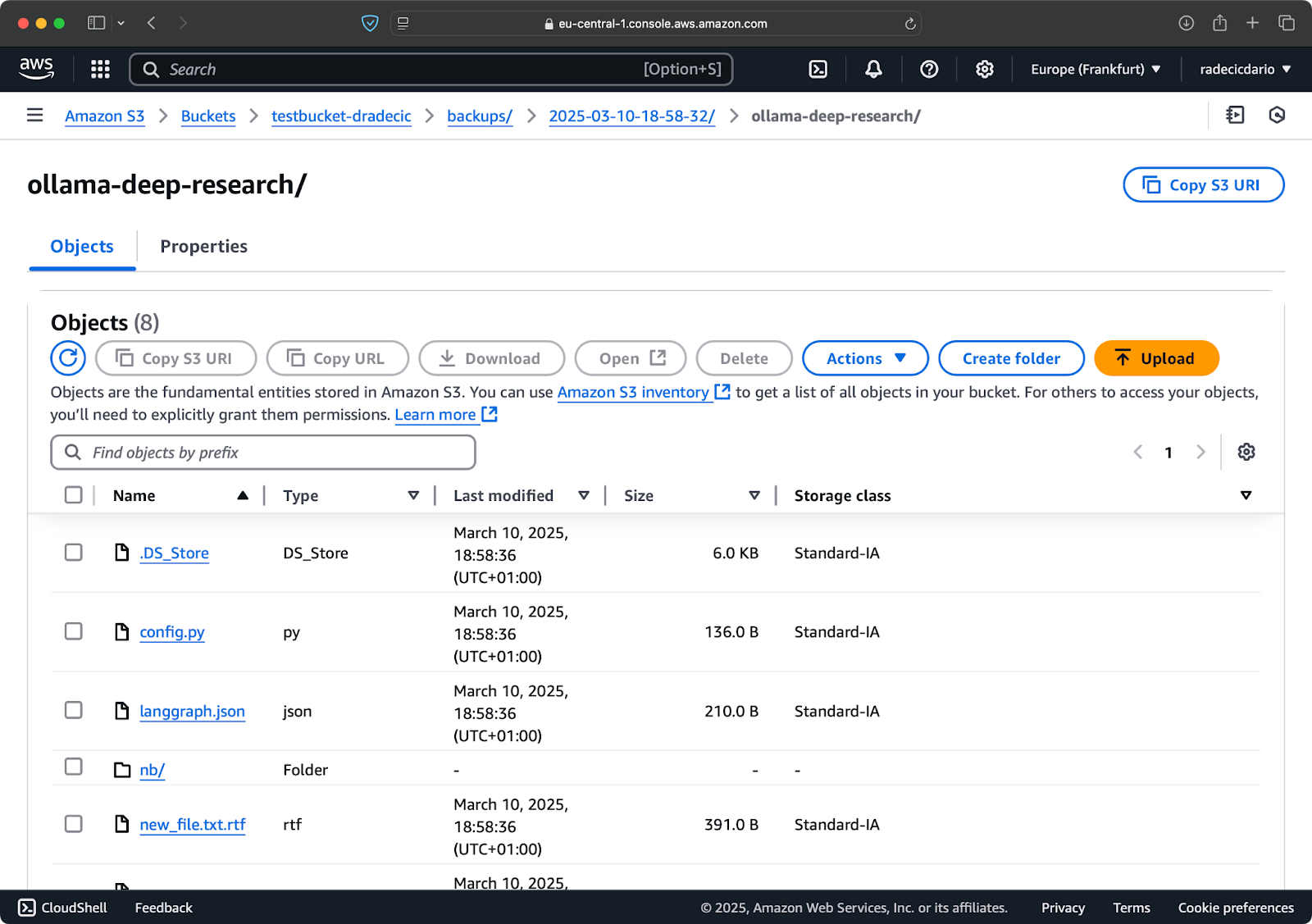
Bild 19 – Backup-Inhalte mit einer benutzerdefinierten Speicherklasse
Dies nutzt die S3 Infrequent Access-Speicherklasse, die weniger kostet, aber eine geringe Abrufgebühr hat. Für die langfristige Archivierung könnten Sie sogar die Glacier-Speicherklasse verwenden:
aws s3 sync /Users/dradecic/Documents/important-data s3://testbucket-dradecic/backups/$TIMESTAMP --storage-class GLACIER
Denken Sie nur daran, dass Dateien, die im Glacier gespeichert sind, Stunden zum Abrufen benötigen, sodass sie sich nicht für Daten eignen, die Sie möglicherweise schnell benötigen.
Wiederherstellung von Dateien aus S3
Die Wiederherstellung aus einem Backup ist ebenso einfach – einfach die Quelle und das Ziel umkehren in Ihrem Synchronisationsbefehl:
# Wiederherstellung aus dem aktuellsten Backup (vorausgesetzt, Sie kennen den Zeitstempel) aws s3 sync s3://testbucket-dradecic/backups/2025-03-10-18-56-42 /Users/dradecic/Documents/restored-data
Dies lädt alle Dateien aus dem spezifischen Backup in Ihr lokales restored-data-Verzeichnis herunter:
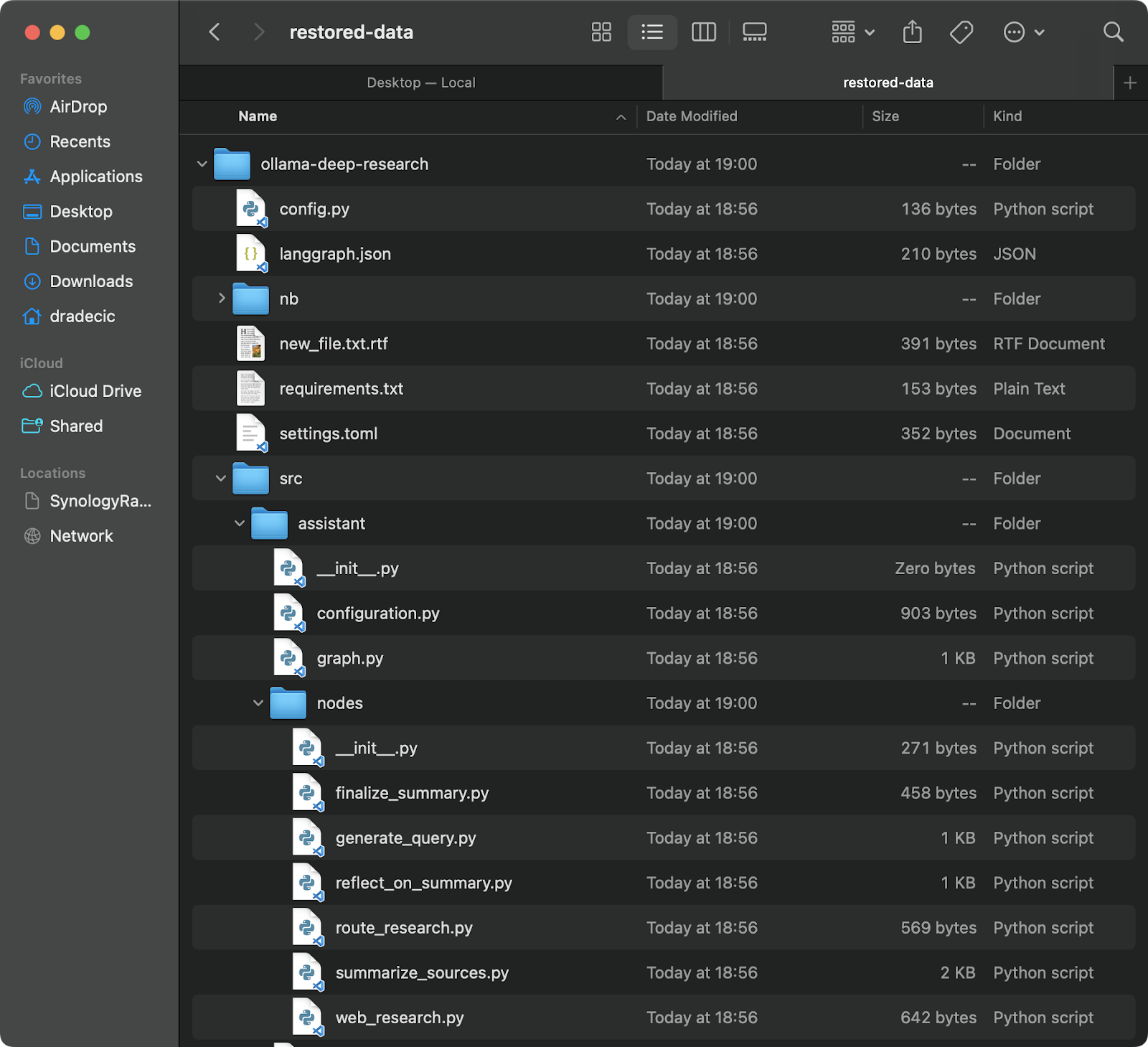
Bild 20 – Wiederherstellen von Dateien aus S3
Wenn Sie den genauen Zeitstempel nicht mehr wissen, können Sie zuerst alle Ihre Backups auflisten:
aws s3 ls s3://testbucket-dradecic/backups/
Was Ihnen etwas Ähnliches wie folgt anzeigen wird:
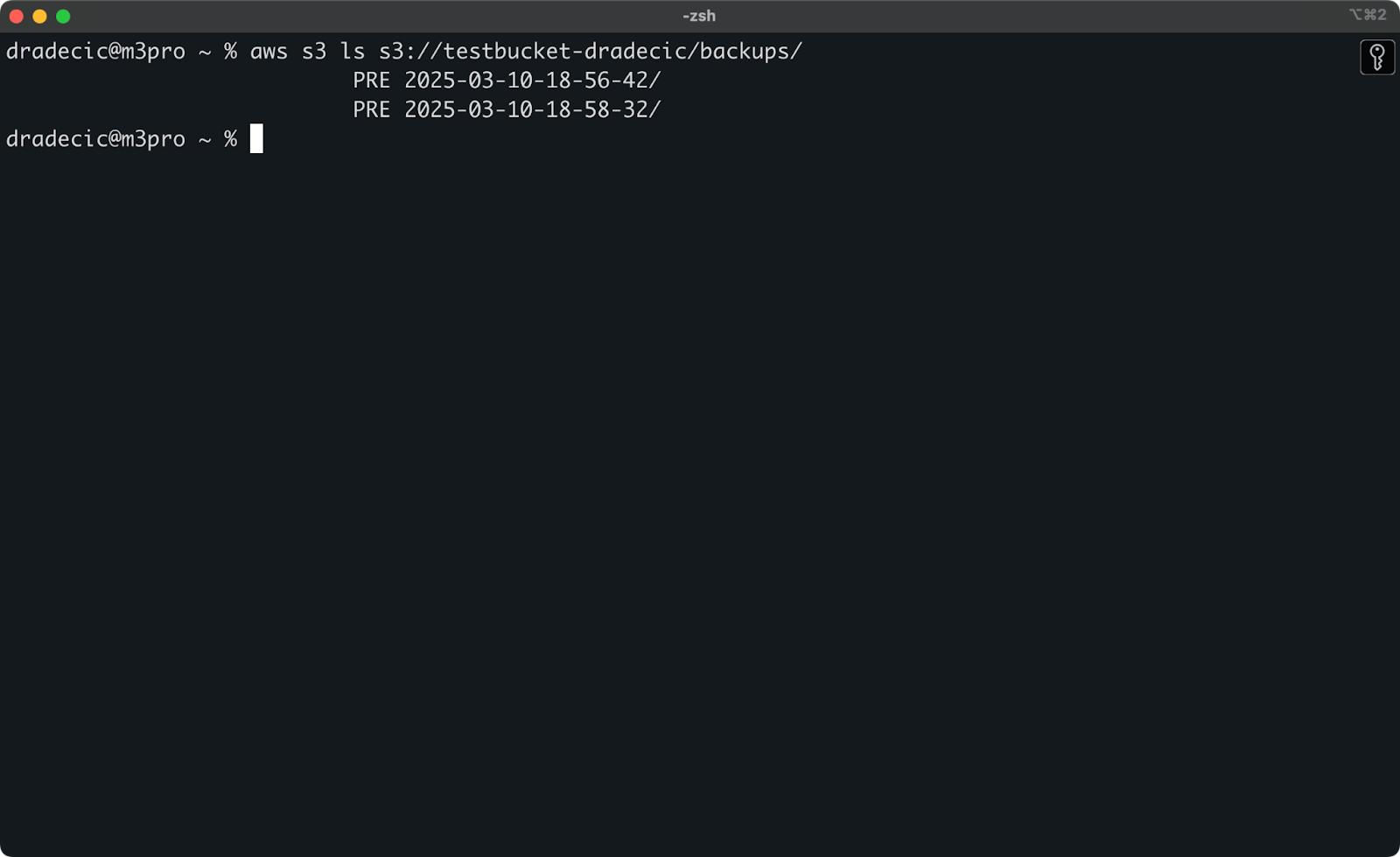
Bild 21 – Liste der Backups
Sie können auch spezifische Dateien oder Verzeichnisse aus einem Backup wiederherstellen, indem Sie die Ausschluss-/Einschluss-Flags verwenden, über die wir zuvor gesprochen haben:
# Stellen Sie nur die Konfigurationsdateien wieder her aws s3 sync s3://testbucket-dradecic/backups/2025-03-10-18-56-42 /Users/dradecic/Documents/restored-configs --exclude "*" --include "*.config" --include "*.toml" --include "*.yaml"
Für mission-kritische Systeme empfehle ich, Ihre Backups mit geplanten Aufgaben zu automatisieren (wie Cron-Jobs auf Linux/macOS oder dem Taskplaner auf Windows). Dadurch stellen Sie sicher, dass Sie Ihre Daten kontinuierlich sichern, ohne sich daran erinnern zu müssen, dies manuell zu tun.
Fehlerbehebung AWS S3 Sync
AWS S3 Sync ist ein zuverlässiges Tool, aber gelegentlich können Probleme auftreten. Die meisten Fehler, die Sie sehen werden, sind jedoch auf menschliche Fehler zurückzuführen.
Gängige Sync-Fehler
Lassen Sie uns einige gängige Probleme und ihre Lösungen durchgehen.
- Zugriffsverweigerungsfehlerbedeutet in der Regel, dass Ihr IAM-Benutzer nicht über die erforderlichen Berechtigungen verfügt, um auf den S3-Bucket zuzugreifen oder bestimmte Operationen durchzuführen. Versuchen Sie zur Behebung eines solchen Fehlers eine der folgenden Lösungen:
- Überprüfen Sie, ob Ihr IAM-Benutzer die entsprechenden S3-Berechtigungen (
s3:ListBucket,s3:GetObject,s3:PutObject) hat. - Stellen Sie sicher, dass die Bucket-Policy Ihrem Benutzer den Zugriff nicht ausdrücklich verweigert.
- Stellen Sie sicher, dass der Bucket selbst den öffentlichen Zugriff nicht blockiert, falls Sie öffentliche Operationen benötigen.
- Fehler: Keine solche Datei oder kein solches Verzeichnis tritt typischerweise auf, wenn der Quellpfad, den Sie im Synchronisationsbefehl angegeben haben, nicht existiert. Die Lösung ist einfach – überprüfen Sie Ihre Pfade und stellen Sie sicher, dass sie existieren. Achten Sie besonders auf Tippfehler in Bucket-Namen oder lokalen Verzeichnissen.
- Dateigrößenbeschränkung Fehler können auftreten, wenn Sie große Dateien synchronisieren möchten. Standardmäßig kann S3-Synchronisierung Dateien bis zu einer Größe von 5 GB verarbeiten. Bei größeren Dateien treten Zeitüberschreitungen oder unvollständige Übertragungen auf.
- Bei Dateien, die größer als 5 GB sind, sollten Sie die Option
--only-show-errorsin Kombination mit der Option--size-onlyverwenden. Diese Kombination hilft bei großen Dateiübertragungen, indem sie die Ausgabe minimiert und nur Dateigrößen vergleicht:
aws s3 sync /Users/dradecic/large-files s3://testbucket-dradecic/large-files --only-show-errors --size-only
Leistungsoptimierung der Synchronisierung
Wenn Ihre S3-Synchronisierung langsamer läuft als erwartet, gibt es einige Anpassungen, die Sie vornehmen können, um die Geschwindigkeit zu erhöhen.
- Verwenden Sie parallele Übertragungen. Standardmäßig verwendet S3 Sync eine begrenzte Anzahl von parallelen Operationen. Sie können dies mit dem Parameter
--max-concurrent-requestserhöhen:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup --max-concurrent-requests 20
- Passen Sie die Chunk-Größe an. Für große Dateien können Sie die Übertragungsgeschwindigkeit optimieren, indem Sie die Chunk-Größe anpassen. Dies teilt große Dateien in 16-MB-Chunks anstelle der standardmäßigen 8 MB auf, was bei guten Netzwerkverbindungen schneller sein kann:
aws s3 sync /Users/dradecic/large-files s3://testbucket-dradecic/backup --cli-read-timeout 120 --multipart-threshold 64MB --multipart-chunksize 16MB
- Verwenden Sie
--no-progressfür Skripte. Wenn Sie S3 Sync in einem automatisierten Skript ausführen, verwenden Sie die Flagge--no-progress, um die Ausgabe zu reduzieren und die Leistung zu verbessern:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup --no-progress
- Verwenden Sie lokale Endpunkte. Wenn sich Ihre AWS-Ressourcen in derselben Region befinden, kann die Angabe des regionalen Endpunkts die Latenz reduzieren:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup --endpoint-url https://s3.eu-central-1.amazonaws.com
Diese Optimierungen können die Synchronisationsleistung erheblich verbessern, insbesondere bei großen Datentransfers oder wenn Sie auf weniger leistungsstarken Maschinen arbeiten.
Wenn Sie nach Ausprobieren dieser Lösungen immer noch Probleme haben, verfügt die AWS CLI über eine integrierte Debugging-Option. Fügen Sie einfach --debug zu Ihrem Befehl hinzu, um detaillierte Informationen darüber zu sehen, was während des Synchronisierungsprozesses passiert:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup --debug
Erwarten Sie viele detaillierte Protokollnachrichten, ähnlich wie diese:
Bild 22 – Ausführen der Synchronisation im Debug-Modus
Und das ist so ziemlich alles, was das Troubleshooting von AWS S3 Sync betrifft. Sicher, es können auch andere Fehler auftreten, aber in 99% der Fälle finden Sie die Lösung in diesem Abschnitt.
Zusammenfassung von AWS S3 Sync
Zusammenfassend ist AWS S3 Sync eines dieser seltenen Tools, das sowohl einfach zu bedienen als auch unglaublich leistungsstark ist. Sie haben alles von grundlegenden Befehlen über erweiterte Optionen, Backup-Strategien und Troubleshooting-Tipps gelernt.
Für Entwickler, Systemadministratoren oder jeden, der mit AWS arbeitet, ist der S3-Sync-Befehl ein unverzichtbares Werkzeug – er spart Zeit, reduziert den Bandbreitenverbrauch und stellt sicher, dass Ihre Dateien dort sind, wo Sie sie brauchen, wann Sie sie brauchen.
Ob Sie kritische Daten sichern, Webinhalte bereitstellen oder einfach verschiedene Umgebungen synchronisieren, macht der AWS S3 Sync-Prozess einfach und zuverlässig.
Der beste Weg, um sich mit S3-Synchronisierung vertraut zu machen, besteht darin, sie einfach zu verwenden. Versuchen Sie, eine einfache Synchronisierungsoperation mit Ihren eigenen Dateien einzurichten, und erkunden Sie dann schrittweise die erweiterten Optionen, um Ihren spezifischen Bedürfnissen gerecht zu werden.
Denken Sie daran, immer zuerst --dryrun zu verwenden, wenn Sie mit wichtigen Daten arbeiten, insbesondere wenn Sie das --delete-Flag verwenden. Es ist besser, eine zusätzliche Minute zu investieren, um zu überprüfen, was passieren wird, als versehentlich wichtige Dateien zu löschen.
Um mehr über AWS zu erfahren, schauen Sie sich diese Kurse von DataCamp an:
- Einführung in AWS
- AWS Cloud-Technologie und -Dienste
- AWS-Sicherheit und Kostenmanagement
- Einführung in AWS Boto in Python
Sie können sogar DataCamp verwenden, um sich auf AWS-Zertifizierungsprüfungen vorzubereiten – AWS Cloud Practitioner (CLF-C02).