













设置 AWS CLI 和 AWS S3
在开始同步文件到S3之前,您需要正确地设置和配置AWS CLI。如果您是AWS的新手,这可能听起来有些吓人,但只需要几分钟时间。
设置CLI涉及两个主要步骤:安装工具和配置工具。接下来我将介绍这两个步骤。
安装AWS CLI
安装AWS CLI的步骤略有不同,具体取决于您的操作系统。
对于Windows系统:
- 转到 AWS CLI 下载页面
- 下载 Windows 安装程序(64位)
- 运行安装程序并按提示操作
对于 Linux 系统:
通过终端运行以下三个命令:
curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip" unzip awscliv2.zip sudo ./aws/install
对于 macOS 系统:
假设您已安装 Homebrew,请从终端运行此命令:
brew install awscli
如果您没有Homebrew,请改用以下两个命令:
curl "https://awscli.amazonaws.com/AWSCLIV2.pkg" -o "AWSCLIV2.pkg" sudo installer -pkg AWSCLIV2.pkg -target /
您可以在所有操作系统上运行aws --version命令来验证AWS CLI是否已安装。您应该看到以下内容:
图片1 – AWS CLI版本
配置AWS CLI
现在您已经安装了CLI,需要使用您的AWS凭据对其进行配置。
假设您已经拥有AWS账户,请登录并转到IAM服务。在那里,创建一个具有编程访问权限的新用户。您应该为用户分配适当的权限,至少是S3访问权限:
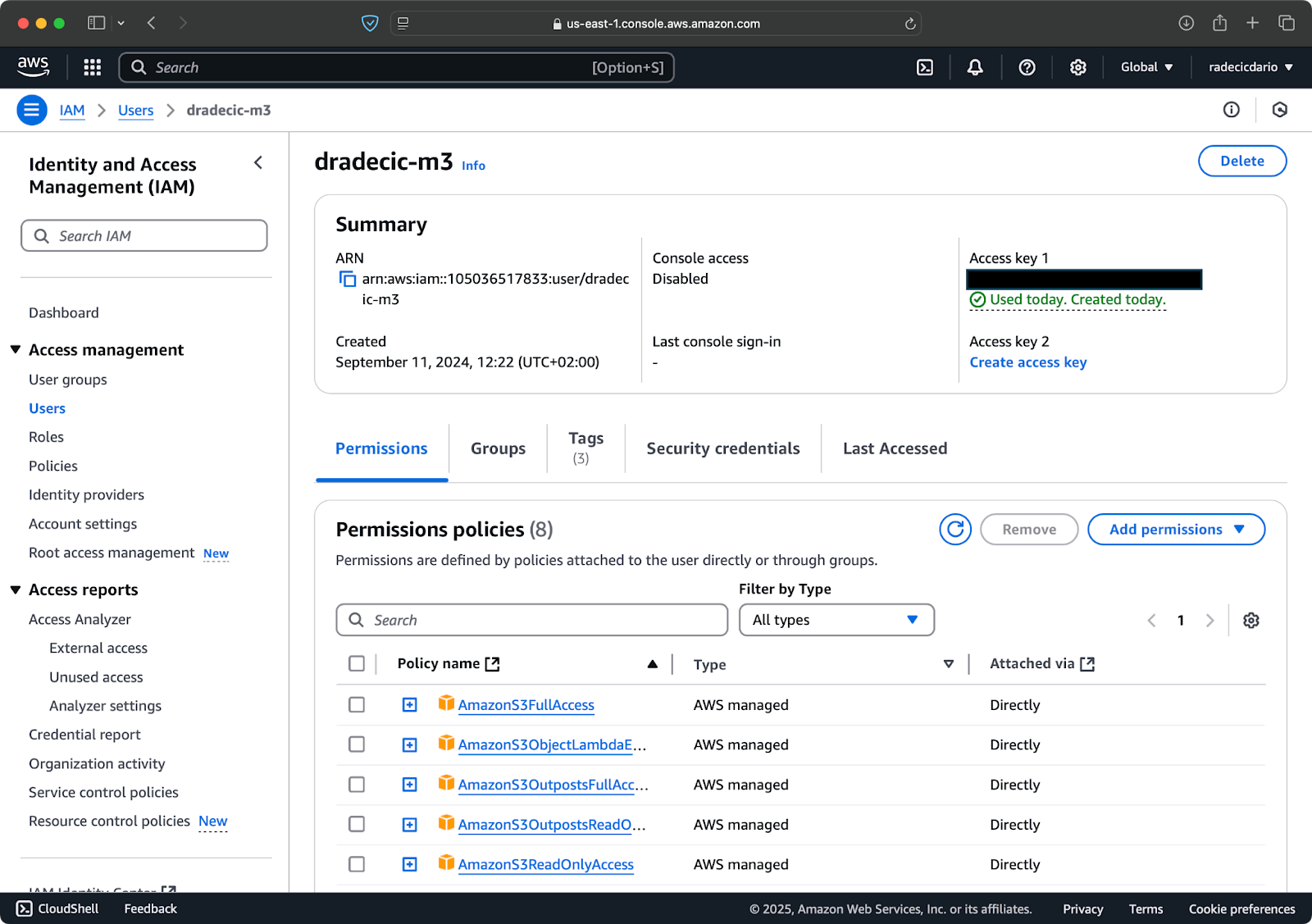
图像 2 – AWS IAM 用户
完成后,转到“安全凭证”以创建新的访问密钥。创建后,您将同时拥有访问密钥 ID和秘密访问密钥。将它们记下来放在安全的地方,因为将来将无法访问它们:
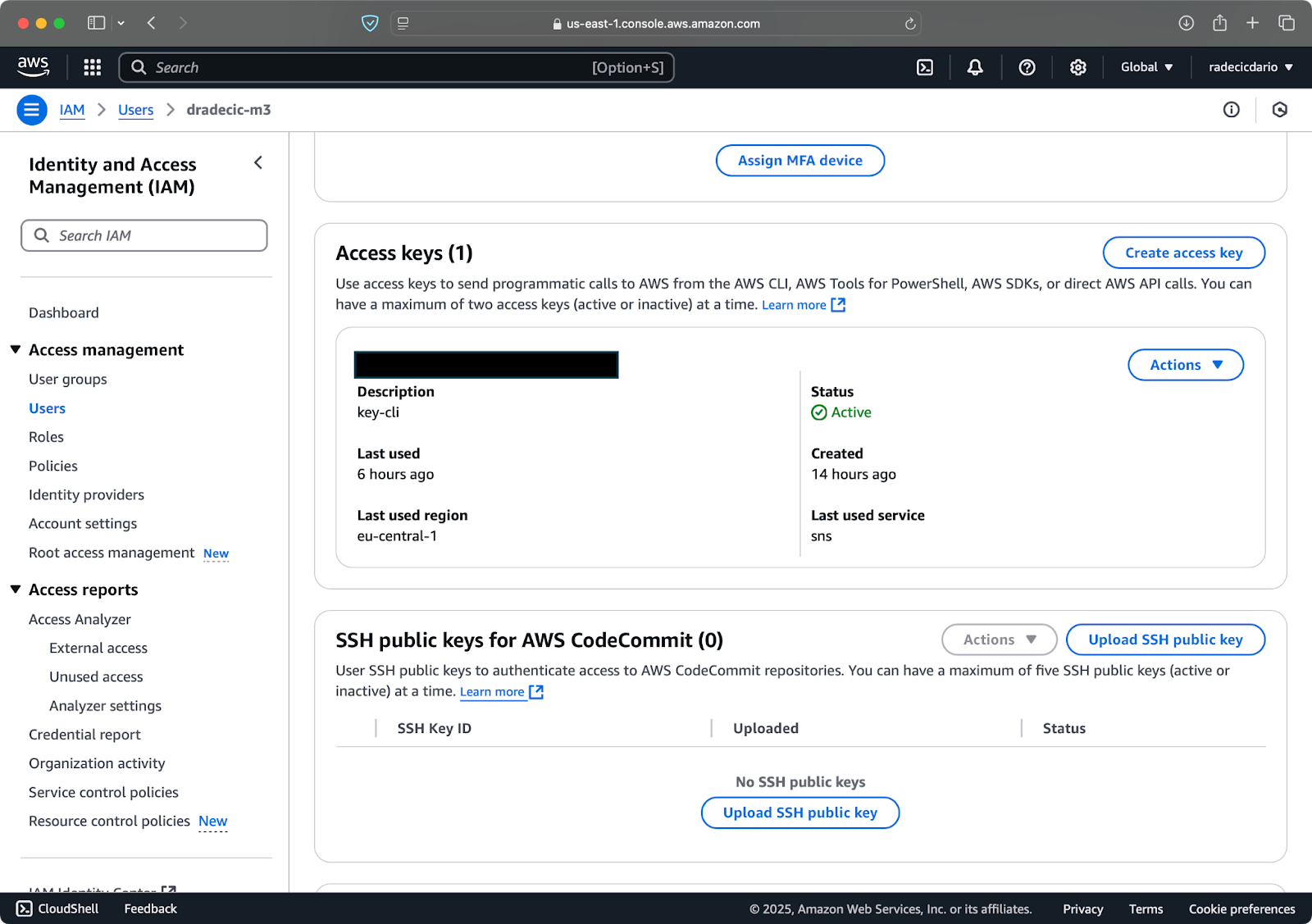
图像 3 – AWS IAM 用户凭证
回到终端,运行aws configure命令。它会提示您输入访问密钥ID、秘密访问密钥、区域(在我的情况下为eu-central-1)和首选输出格式(json):
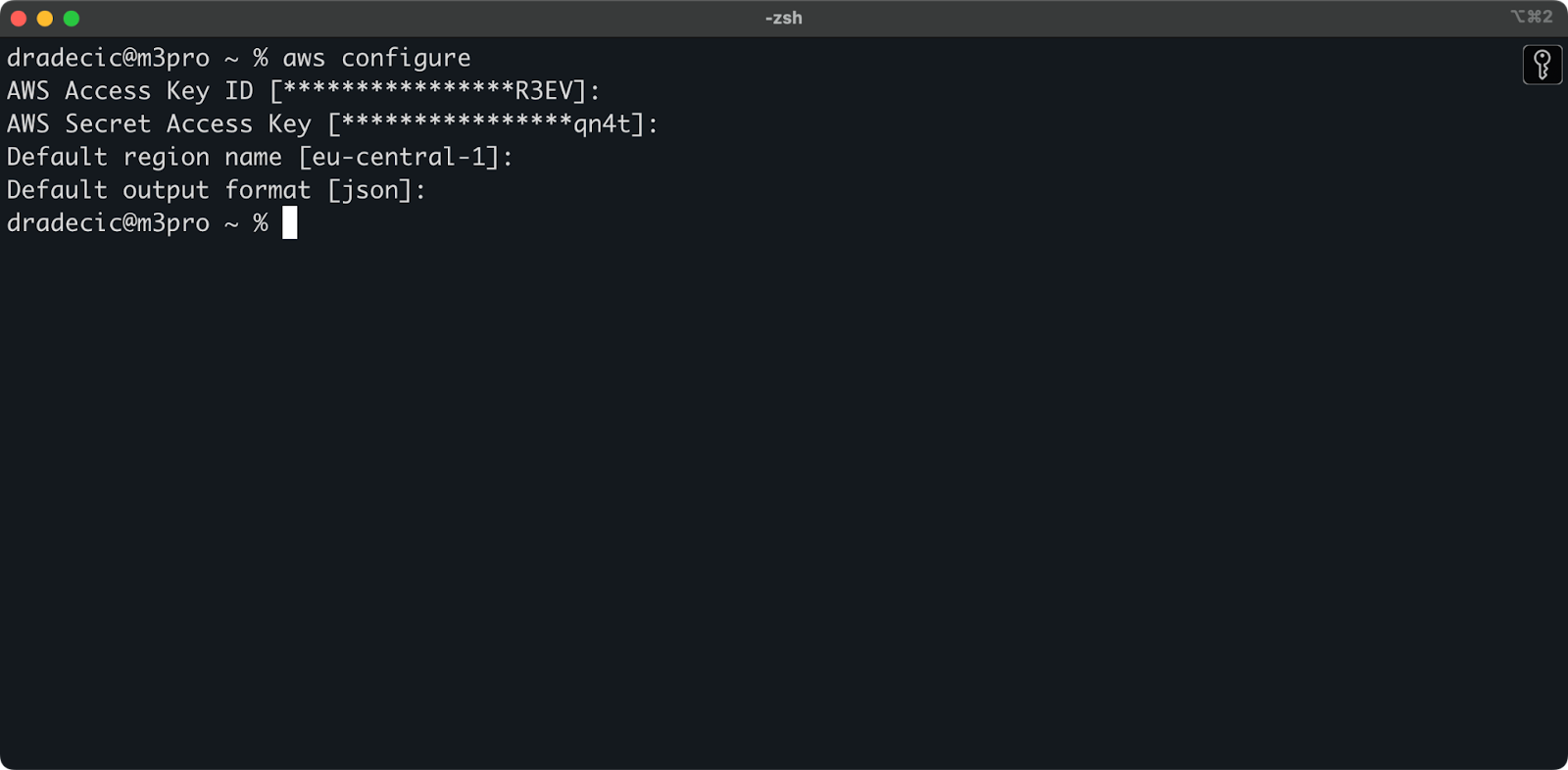
图片 4 – AWS CLI 配置
为了验证您已经成功从CLI连接到AWS账户,请运行以下命令:
aws sts get-caller-identity
您应该看到以下输出:
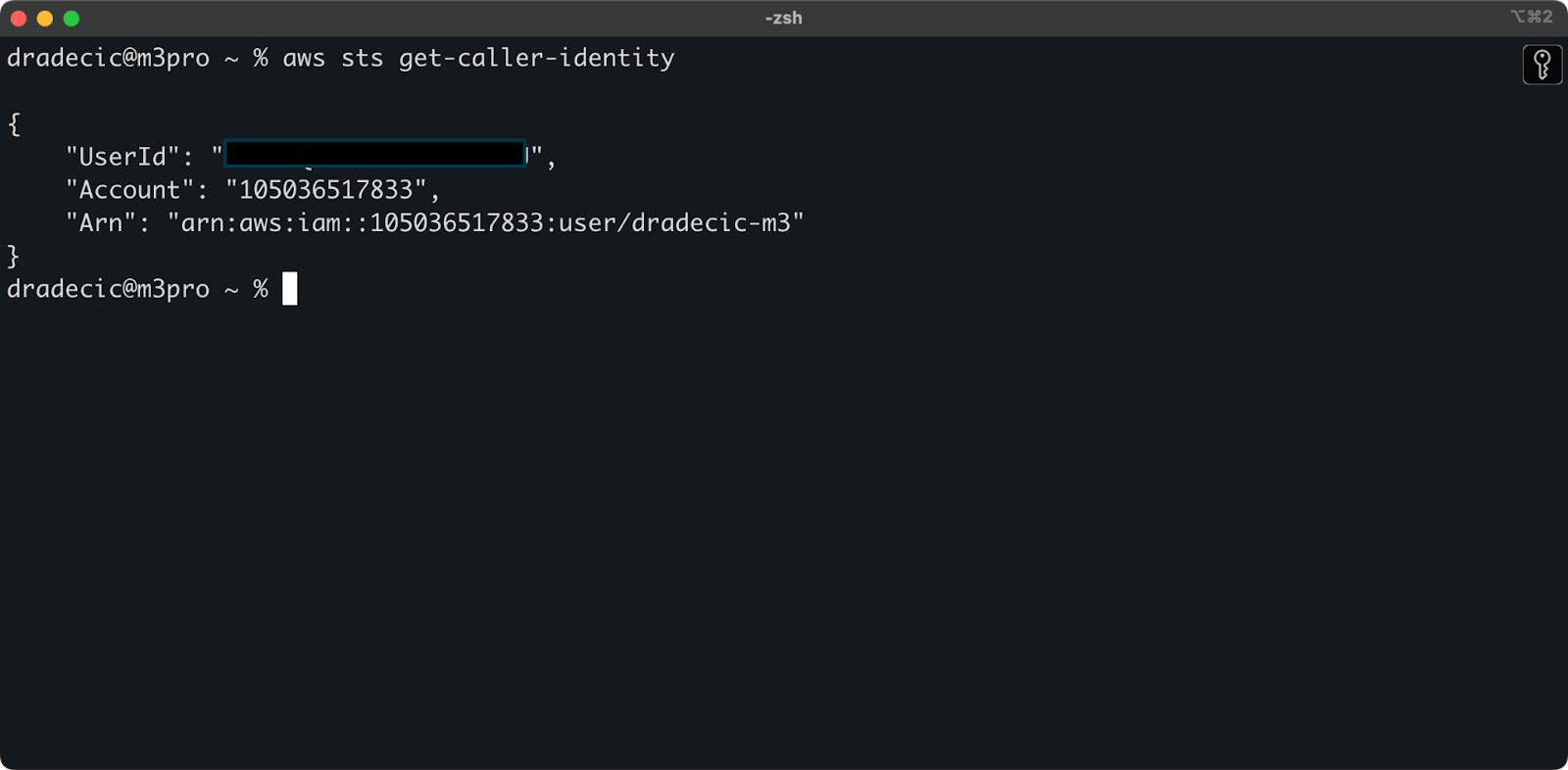
图片 5 – AWS CLI 测试连接命令
就是这样 – 在您开始使用S3同步命令之前,只需要再走一步!
设置一个AWS S3存储桶
最后一步是创建一个 S3 存储桶,用于存储您同步的文件。您可以通过 CLI 或 AWS 管理控制台进行操作。我选择后者,为了增加一些变化。
首先,转到管理控制台中的 S3 服务页面,然后点击“创建存储桶”按钮。在那里,选择一个唯一的存储桶名称(在整个 AWS 范围内全局唯一),然后滚动到底部,点击“创建”按钮:
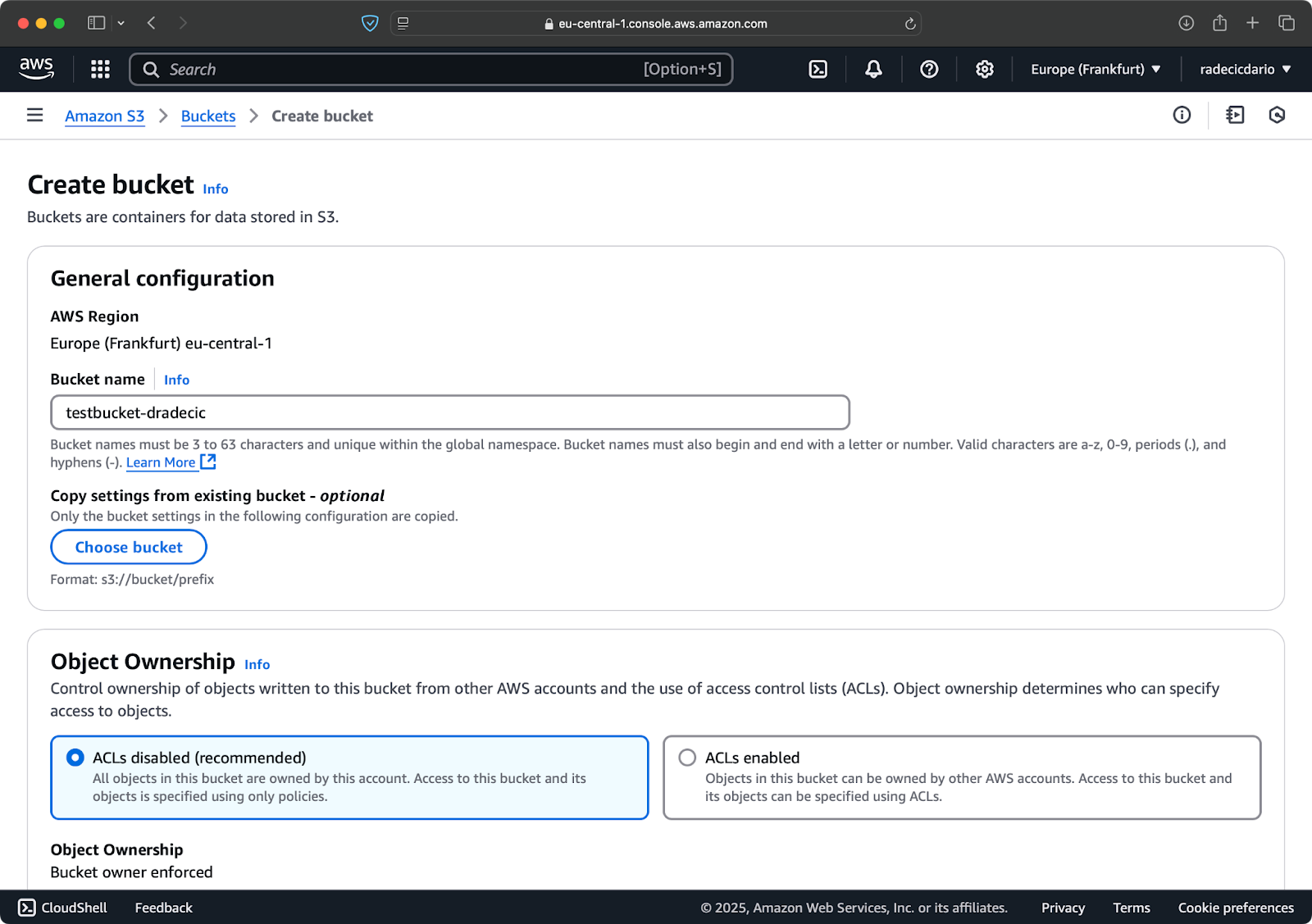
图像 6 – AWS 存储桶创建
存储桶现已创建,您将立即在管理控制台中看到。您还可以通过 CLI 验证它是否已创建:
aws s3 ls
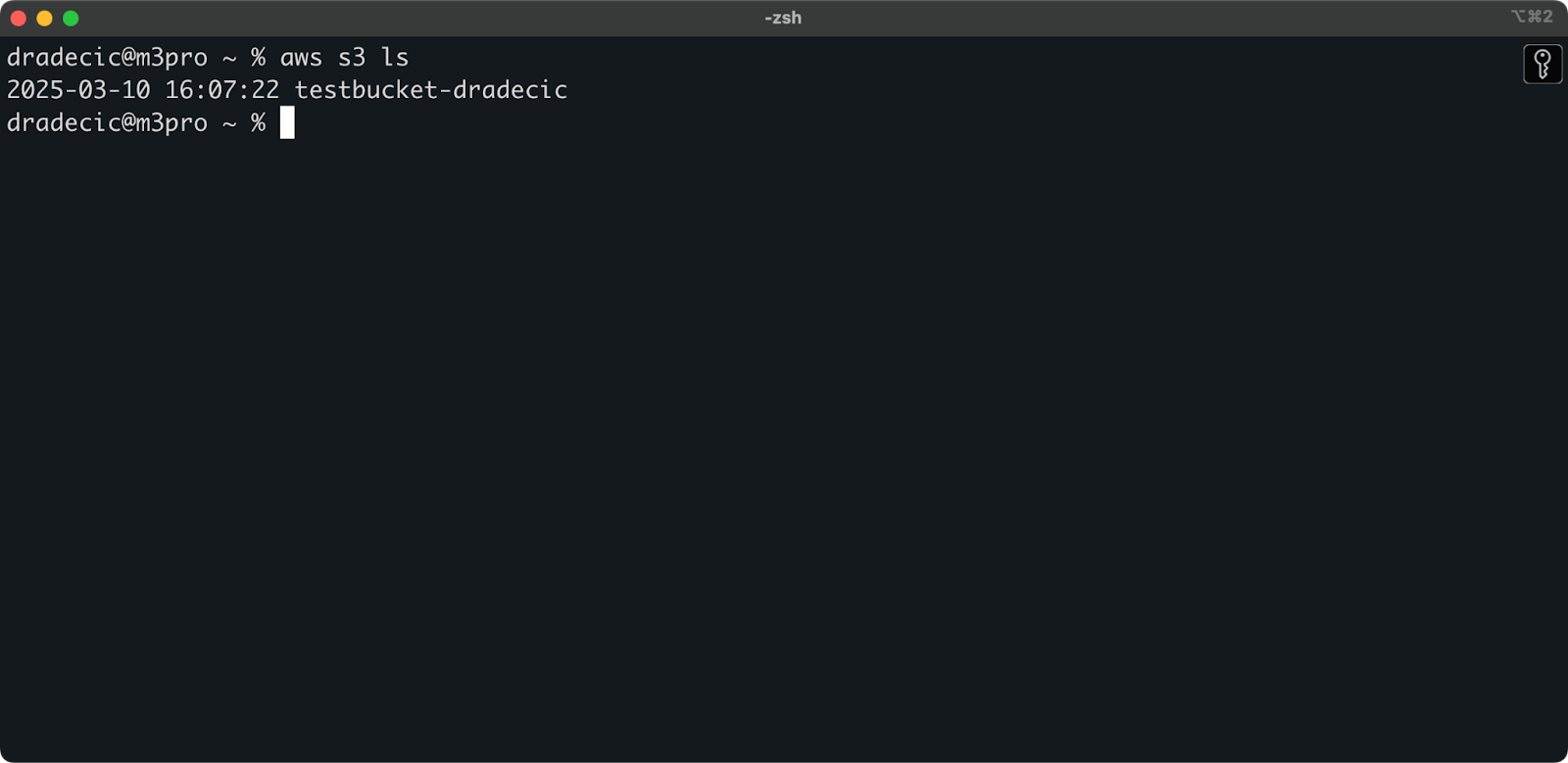
图像 7 – 所有可用的 S3 存储桶
请记住S3 桶默认为私有。如果您计划将桶用于托管公共文件(如网站资产),则需要相应调整桶策略和权限。
现在您已经设置好并准备好开始在本地计算机和AWS S3之间同步文件!
基本的AWS S3同步命令
现在您已经安装、配置了AWS CLI,并准备好一个S3桶,是时候开始同步了! AWS S3同步命令的基本语法非常简单。让我向您展示它是如何工作的。
S3同步命令遵循这个简单的模式:
aws s3 sync <source> <destination> [options]
源和目的地都可以是本地目录路径或S3 URI(以s3://开头)。根据您想要同步的方式,您将以不同的方式安排它们。
从本地同步文件到S3存储桶
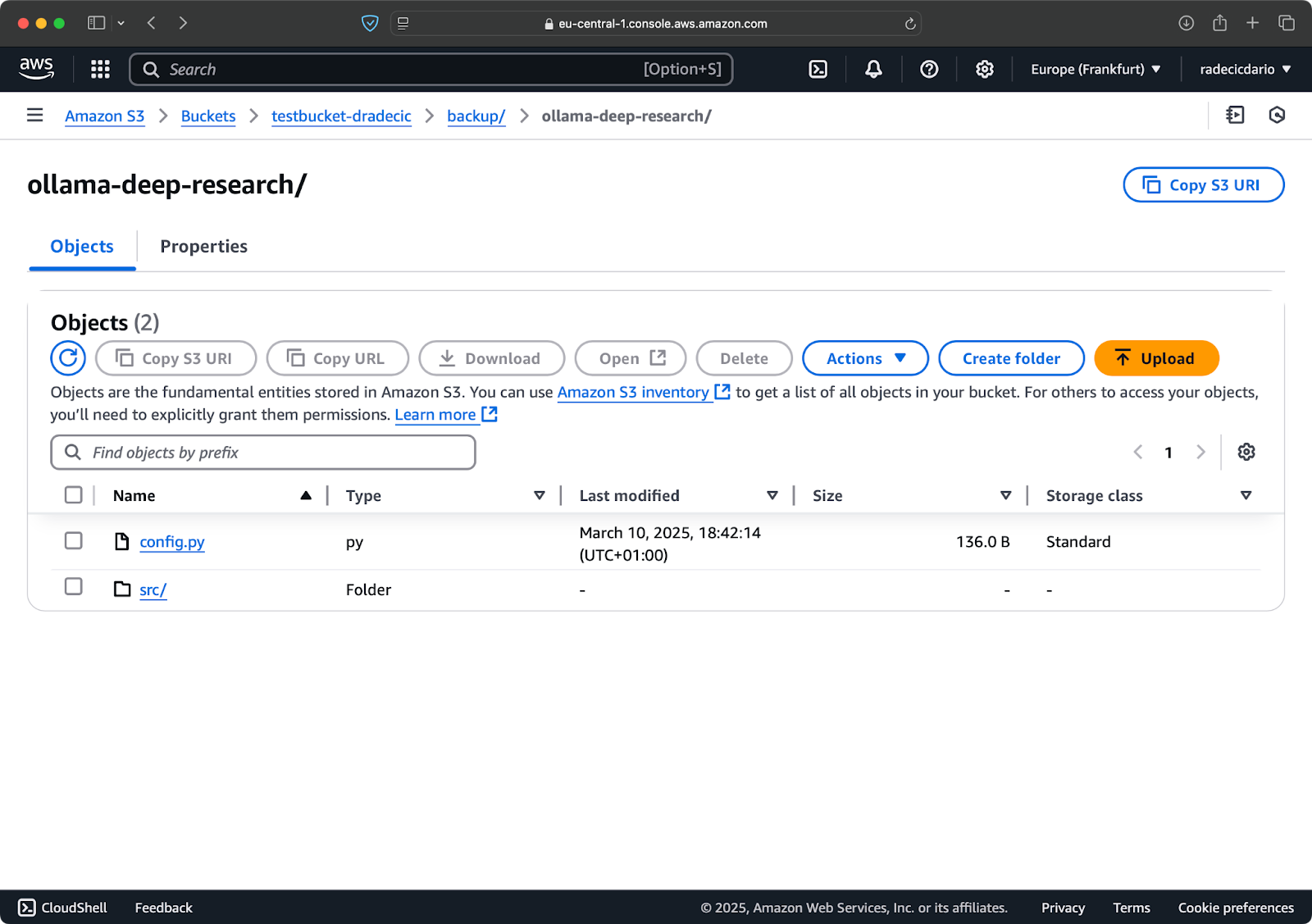
最近我在进行Ollama深度研究。假设这是我想要同步到S3的文件夹。主目录位于Documents文件夹下。看起来是这样的:
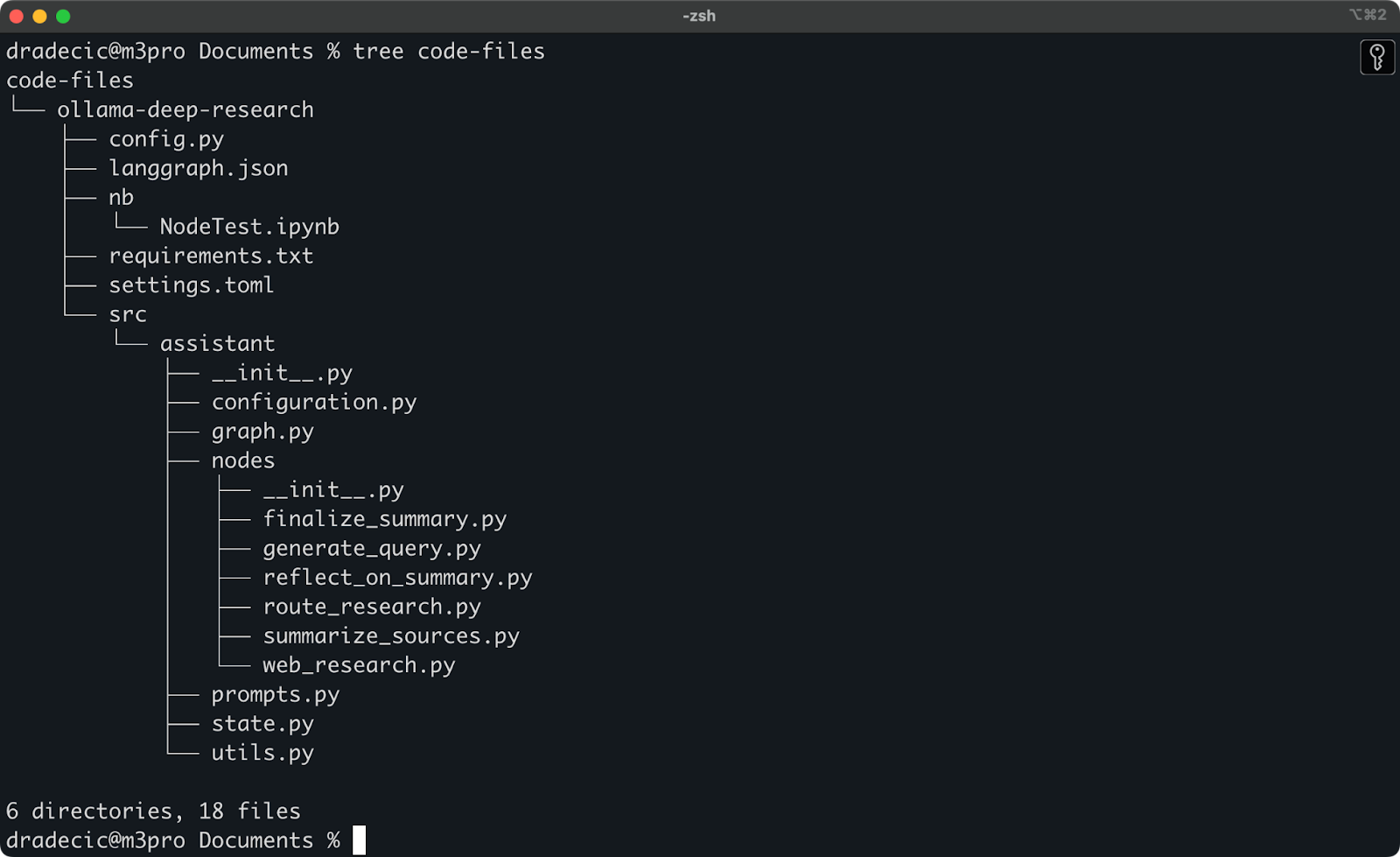
本地文件夹内容
这是我需要运行的命令,将本地code-files文件夹与S3存储桶上的backup文件夹同步:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup
如果backup文件夹在S3存储桶上不存在,它将被自动创建。
以下是您将在控制台上看到的内容:
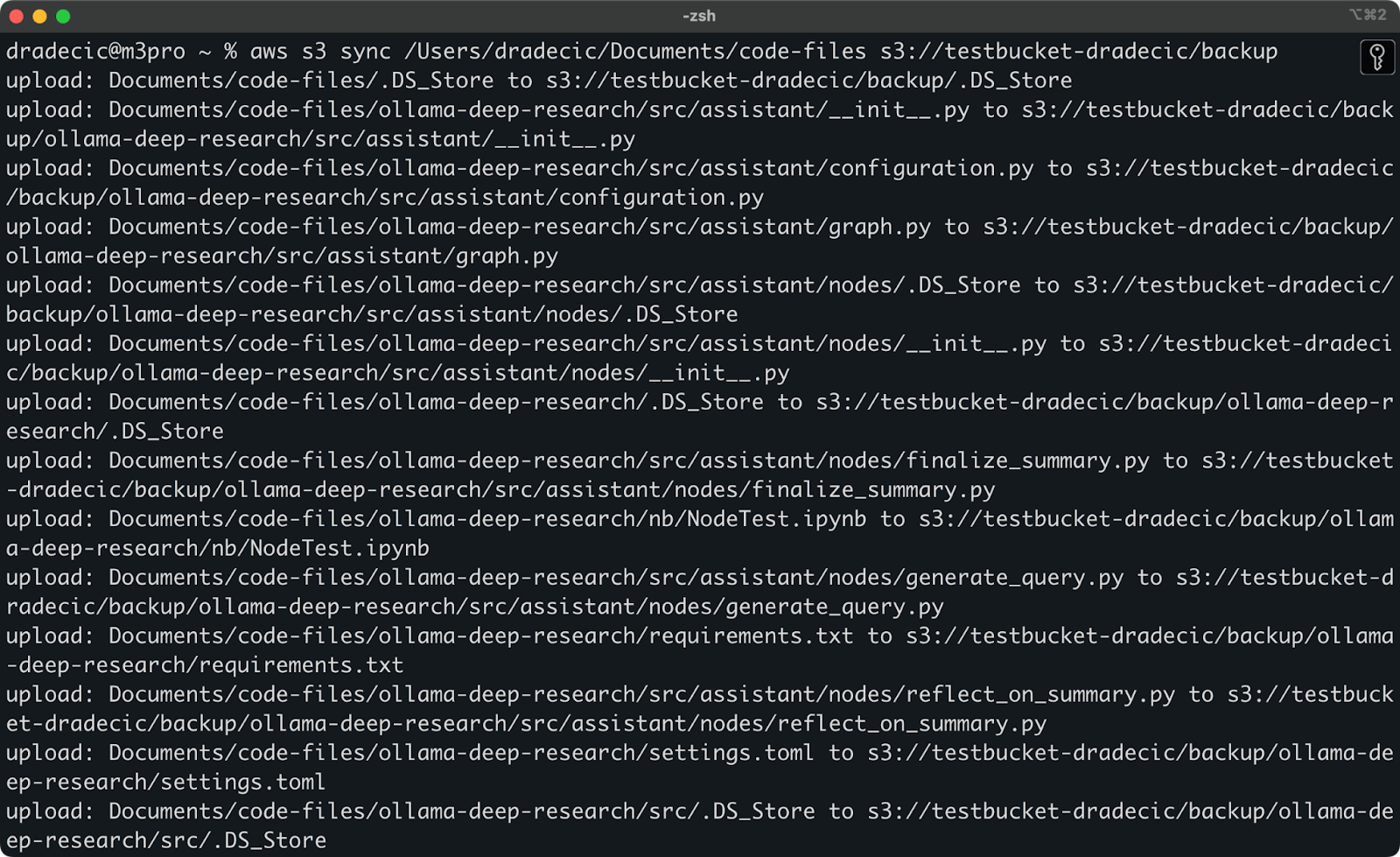
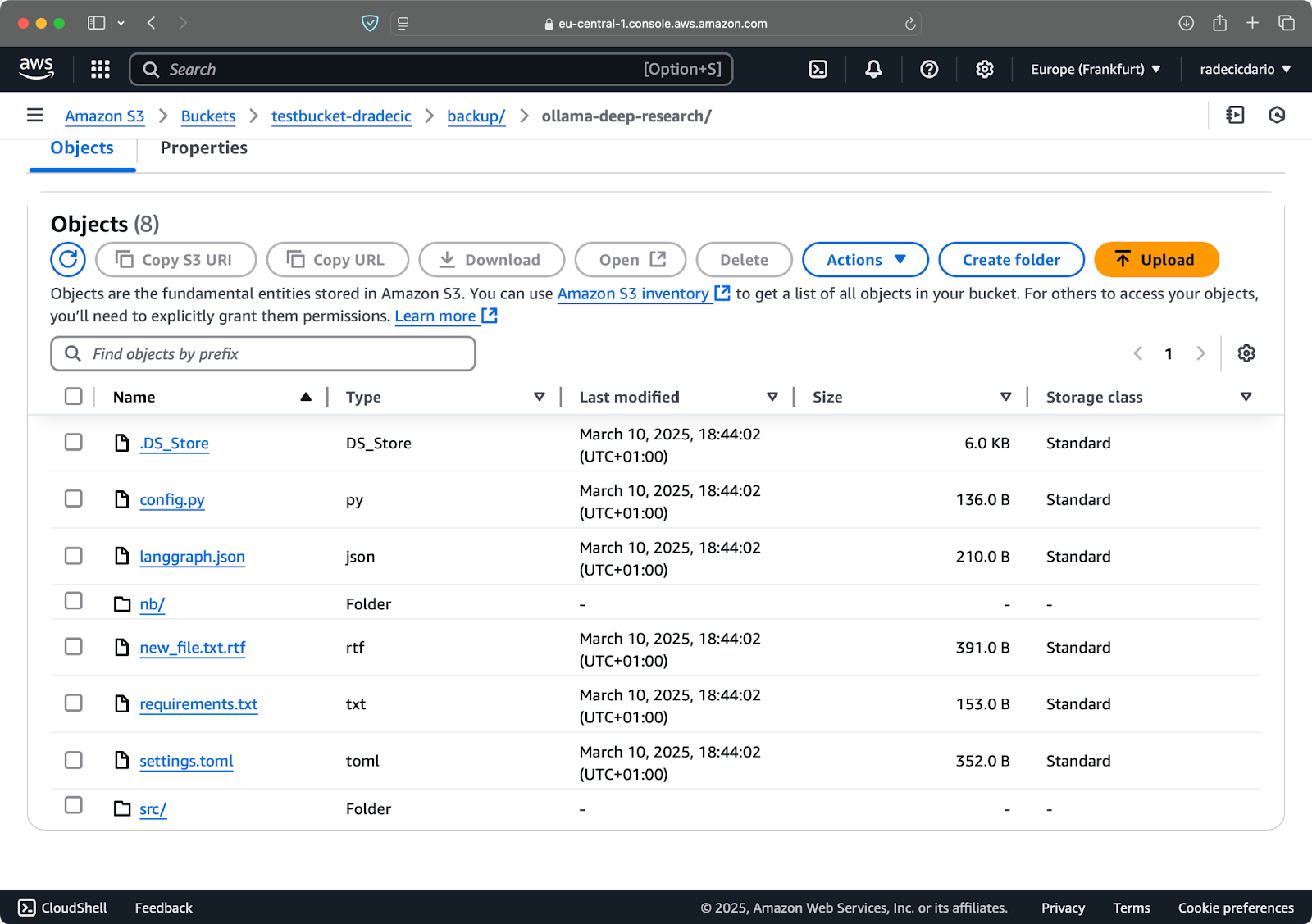
图像 9 – S3同步过程
几秒钟后,本地code-files文件夹的内容将在S3存储桶上可用:
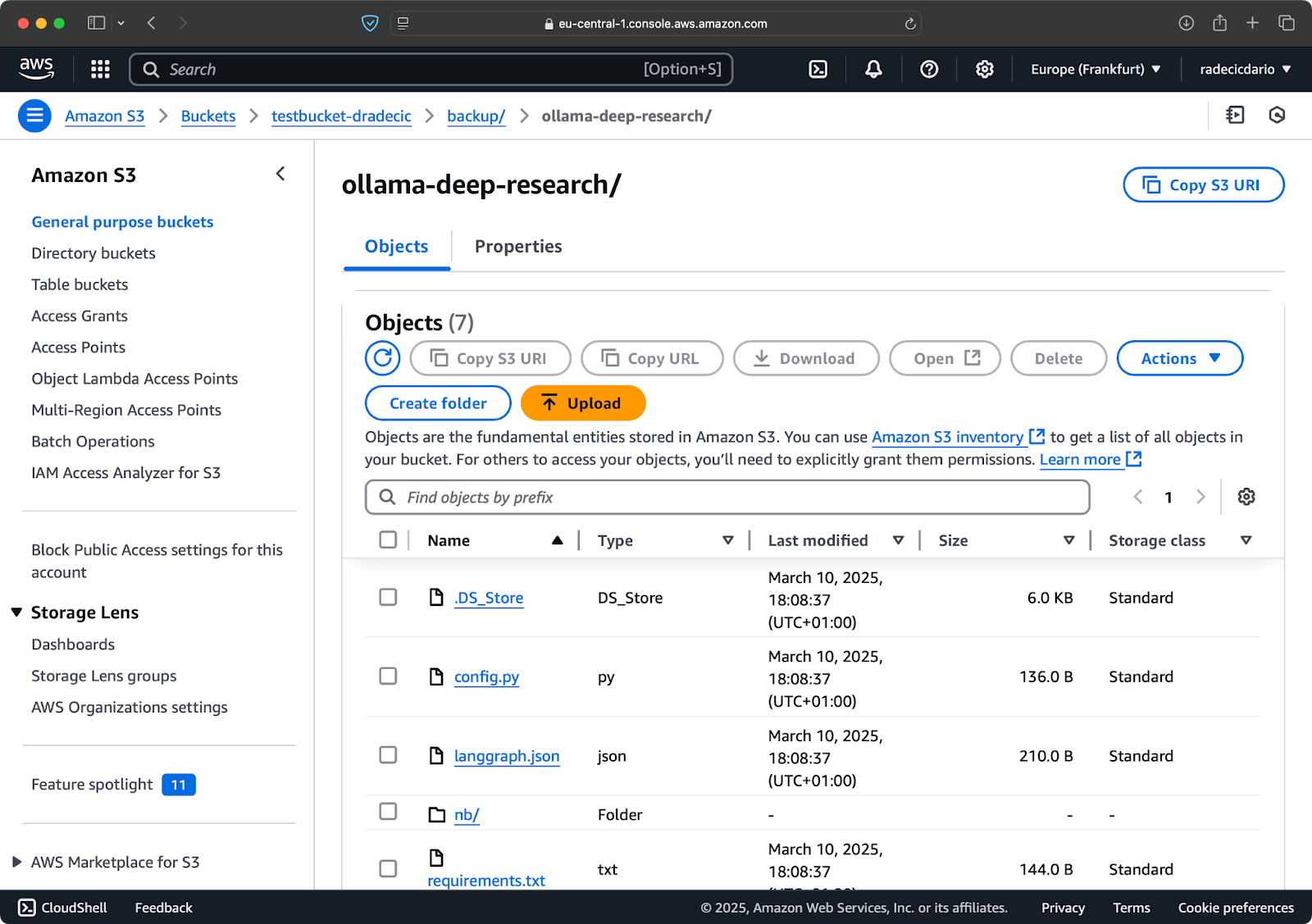
图像 10 – S3存储桶内容
S3同步的美妙之处在于只上传那些在目标位置不存在或者在本地已被修改的文件。如果再次运行相同的命令而没有更改任何内容,你将看不到任何变化!这是因为AWS CLI检测到所有文件已经同步且是最新的。
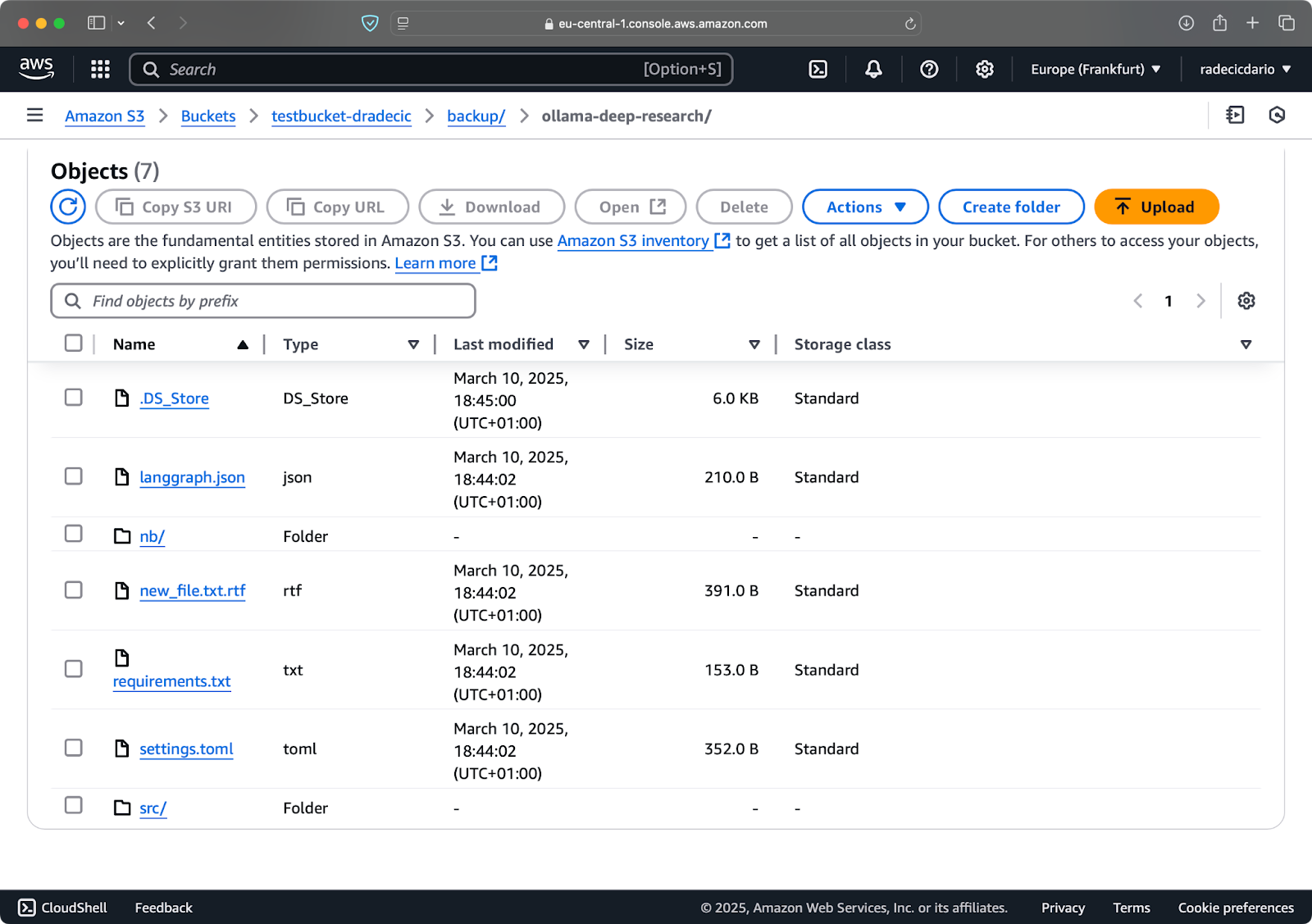
现在,我将做两个小改动 – 创建一个新文件(new_file.txt)并更新一个已有文件(requirements.txt)。当你再次运行同步命令时,只有新的或已修改的文件会被上传:
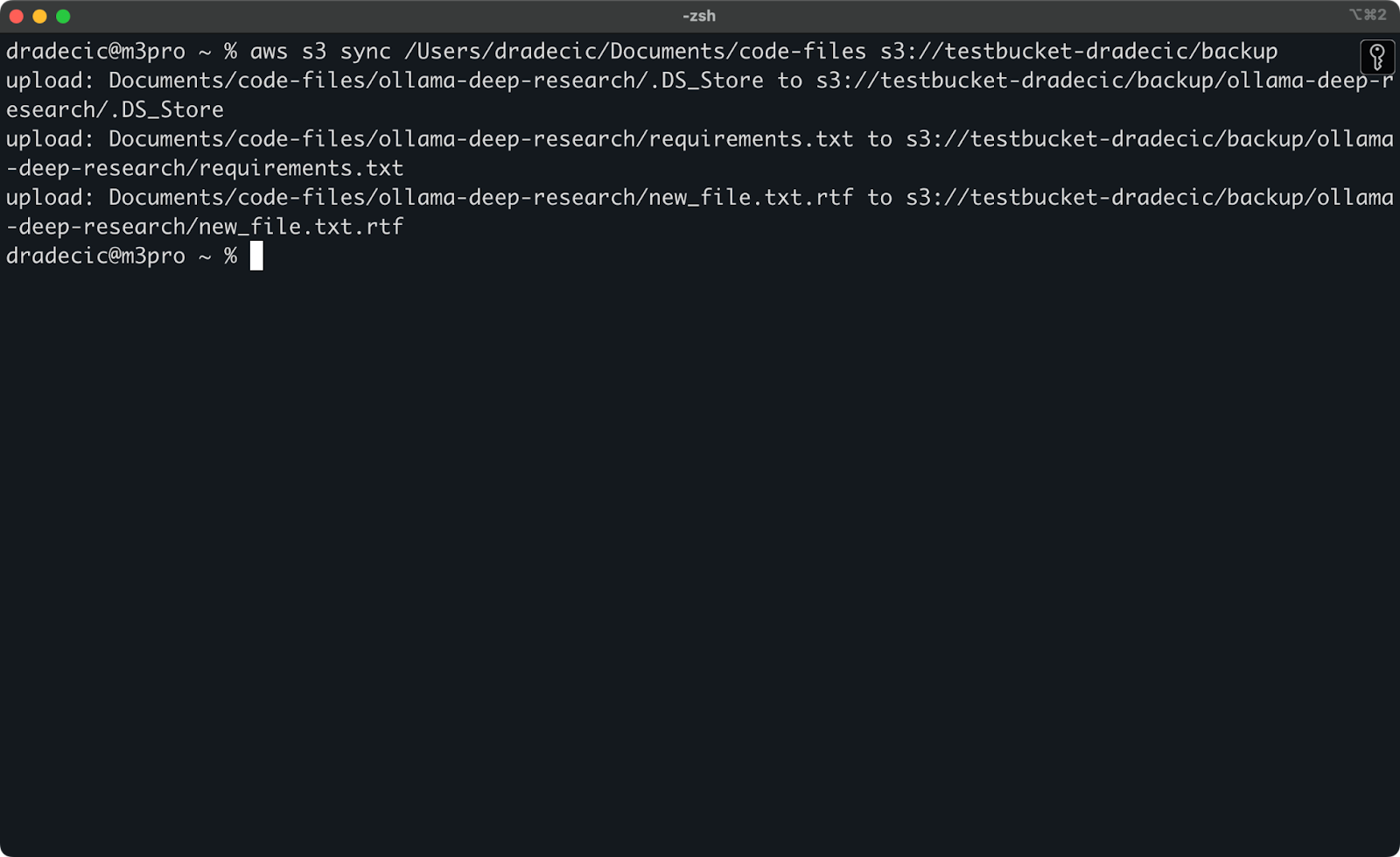
图像11 – S3同步过程(2)
这就是同步本地文件夹到S3时需要了解的全部内容。但如果你想反过来呢?
将文件从S3存储桶同步到本地目录
如果你想将文件从S3存储桶下载到本地计算机,只需调换源和目的地:
aws s3 sync s3://testbucket-dradecic/backup /Users/dradecic/Documents/code-files-from-s3
这个命令将会从你的S3存储桶中的backup文件夹下载所有文件到一个名为code-files-from-s3的本地文件夹。同样,如果本地文件夹不存在,CLI会为你创建它:
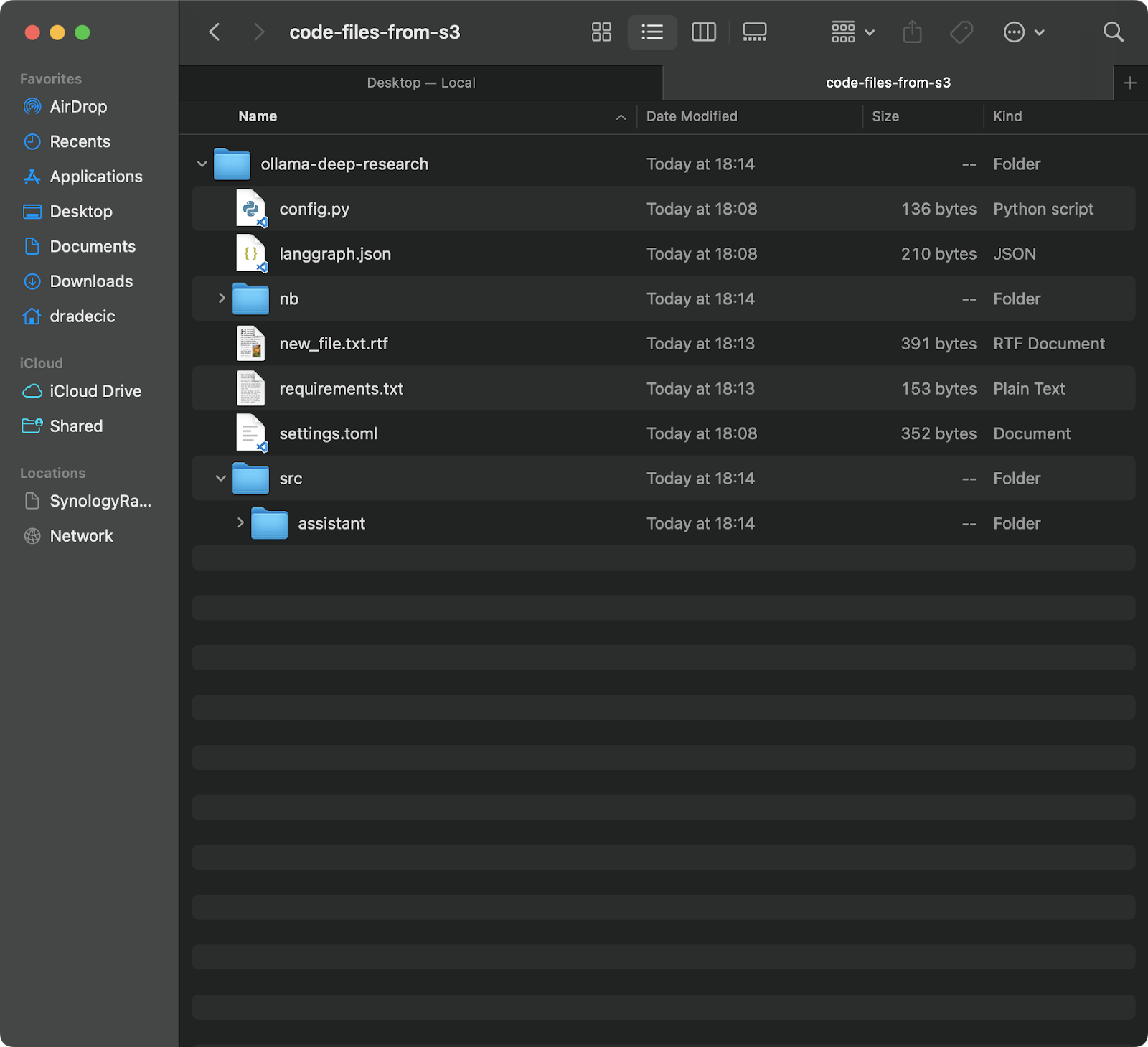
图片12 – S3到本地同步
值得注意的是S3同步不是双向的。它总是从源到目的地,使目的地与源匹配。如果您在本地删除文件然后将其同步到S3,则该文件仍将存在于S3中。同样,如果您在S3中删除文件并从S3同步到本地,则本地文件将保持不变。
如果您希望使目的地与源完全匹配(包括删除),则需要使用--delete标志,我将在高级选项部分介绍。
高级AWS S3同步选项
之前探讨过的基本S3同步命令本身已经很强大,但AWS还为其提供了附加选项,让您对同步过程拥有更多控制。
在本节中,我会向您展示一些您可以添加到基本命令中的最有用的标志。
仅同步新文件或已修改文件
默认情况下,S3同步使用基本比较机制来检查文件大小和修改时间,以确定是否需要同步文件。然而,这种方法可能并不总是能捕捉到所有更改,特别是在处理已修改但大小仍相同的文件时。
为更精确的同步,您可以使用--exact-timestamps标志:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup --exact-timestamps
这将强制S3同步将时间戳的比较精度降低到毫秒。请记住,使用此标志可能会稍微减慢同步过程,因为它需要进行更详细的比较。
排除或包含特定文件
有时,您不希望同步目录中的每个文件。也许您想要排除临时文件、日志或某些文件类型(比如.DS_Store在我的情况下)。这就是--exclude和--include标志派上用场的地方。
但为了阐明一点,假设我想同步我的代码目录,但排除所有Python文件:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup --exclude "*.py"
现在,同步到S3的文件要少得多:
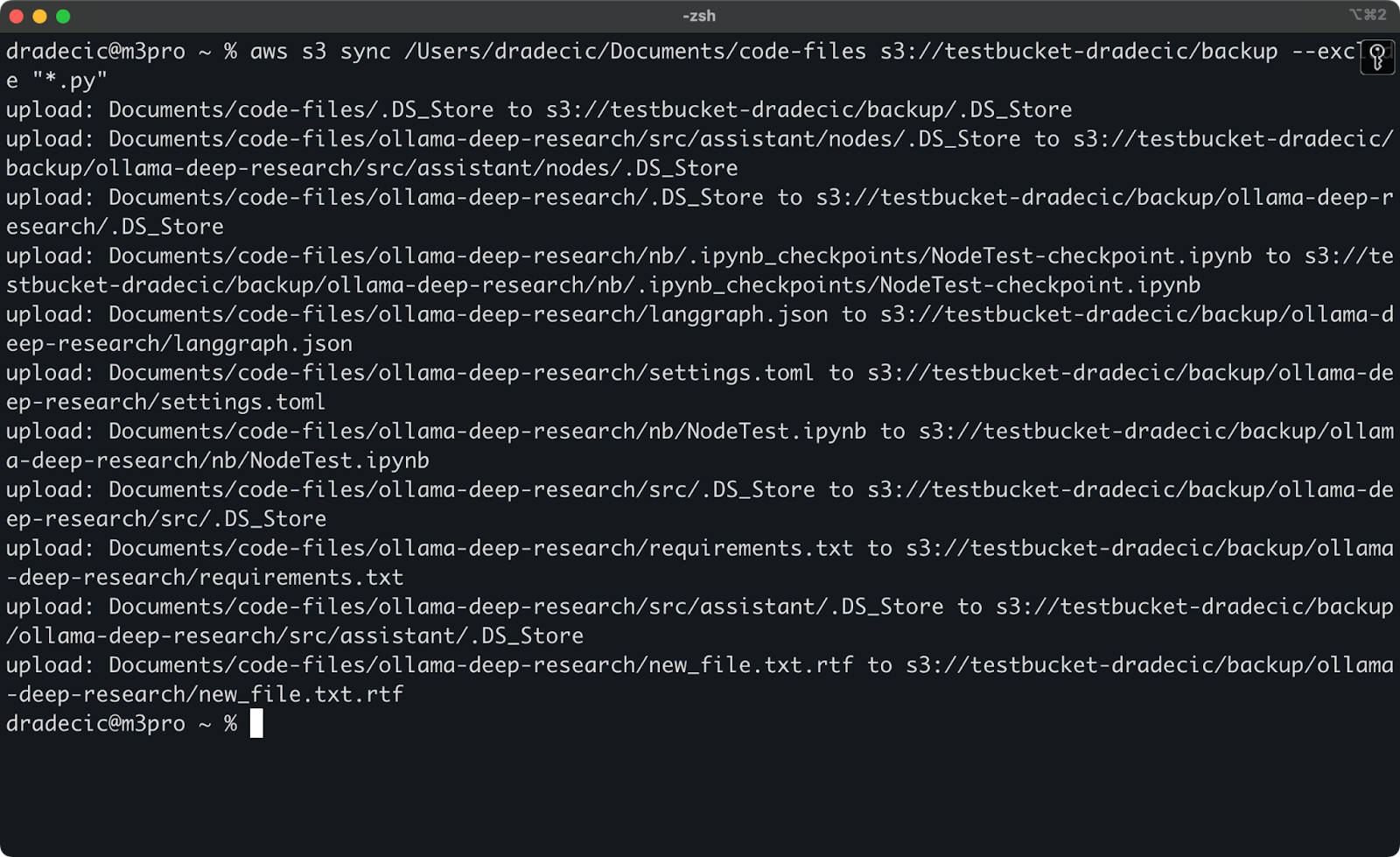
图像13 – 排除Python文件的S3同步
您还可以结合 --exclude 和 --include 来创建更复杂的模式。例如,排除除Python文件外的所有内容:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup --exclude "*" --include "*.py"
模式是按指定顺序进行评估的,所以顺序很重要!当使用这些标志时,您会看到以下内容:
图像14 – 排除和包含标志
现在只有Python文件被同步,重要的配置文件却不见了。
从目的地删除文件
默认情况下,S3同步只会在目标位置添加或更新文件,而不会删除文件。这意味着如果你从源文件中删除了一个文件,同步后它仍然会保留在目标位置。
要使目标位置完全镜像源文件,包括删除文件,请使用--delete标志:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup --delete
第一次运行此命令时,所有本地文件将同步到S3:
图像 15 – 删除标志
这对于保持目录的精确副本特别有用。但要小心 – 如果使用不当,此标志可能导致数据丢失。
假设我从本地文件夹中删除config.py并使用--delete标志运行同步命令:
图像16 – 删除标志(2)
正如您所看到的,该命令不仅同步新文件和修改的文件,还会删除在本地目录中不再存在的文件。
设置干预运行以进行安全同步
最危险的S3同步操作是涉及--delete标志的操作。为了避免意外删除重要文件,您可以使用--dryrun标志来模拟操作,而不会实际进行任何更改:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup --delete --dryrun
为了演示,我已经从本地文件夹中删除了requirements.txt和settings.toml文件,然后执行了以下命令:
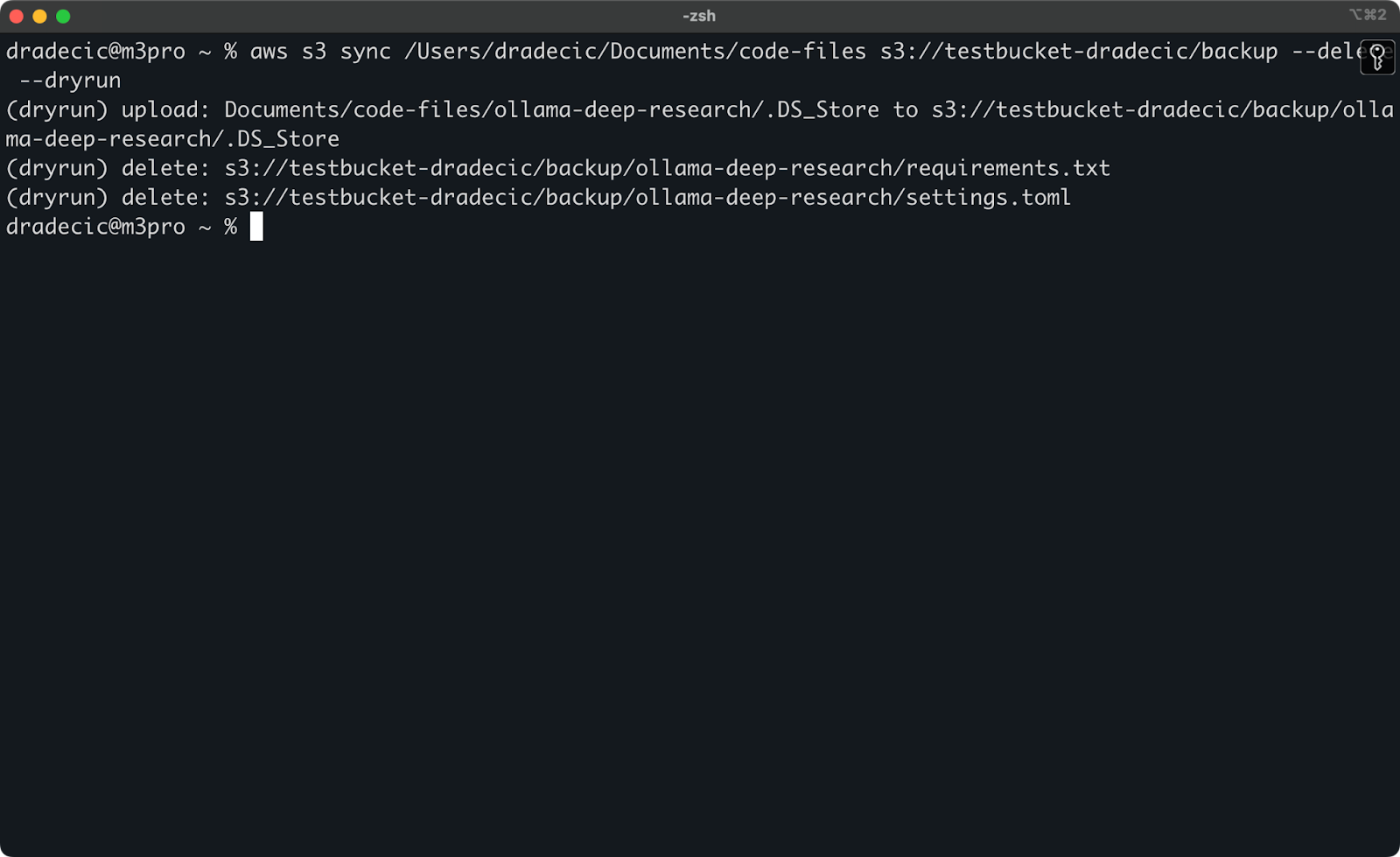
图像17 – 模拟运行
这将准确地显示如果您真的运行命令会发生什么,包括哪些文件将被上传、下载或删除。
我始终建议在执行带有--delete标志的任何S3同步命令之前使用--dryrun,特别是在处理重要数据时。
对于S3同步命令,还有很多其他选项可用,比如--acl用于设置权限,--storage-class用于选择S3存储层级,以及--recursive用于遍历子目录。查看官方AWS CLI文档以获取完整的选项列表。
现在您已经熟悉了基本和高级的S3同步选项,让我们看看如何将这些命令应用于像备份和恢复这样的实际场景。
使用AWS S3同步进行备份和恢复
AWS S3同步最流行的用例之一是备份重要文件并在需要时进行恢复。让我们探讨如何使用同步命令实现简单的备份和恢复策略。
创建到S3的备份
使用S3同步创建备份很简单——只需从本地目录运行同步命令到一个S3存储桶即可。但是,为了进行有效的备份,有一些最佳实践需要遵循。
首先,最好 按日期或版本组织您的备份。以下是一种简单的方法,使用S3路径中的时间戳:
# 创建一个时间戳变量 TIMESTAMP=$(date +%Y-%m-%d-%H-%M-%S) # 运行备份 aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backups/$TIMESTAMP
这将为每个备份创建一个带有类似2025-03-10-18-56-42时间戳的新文件夹。以下是您在S3上将看到的内容:
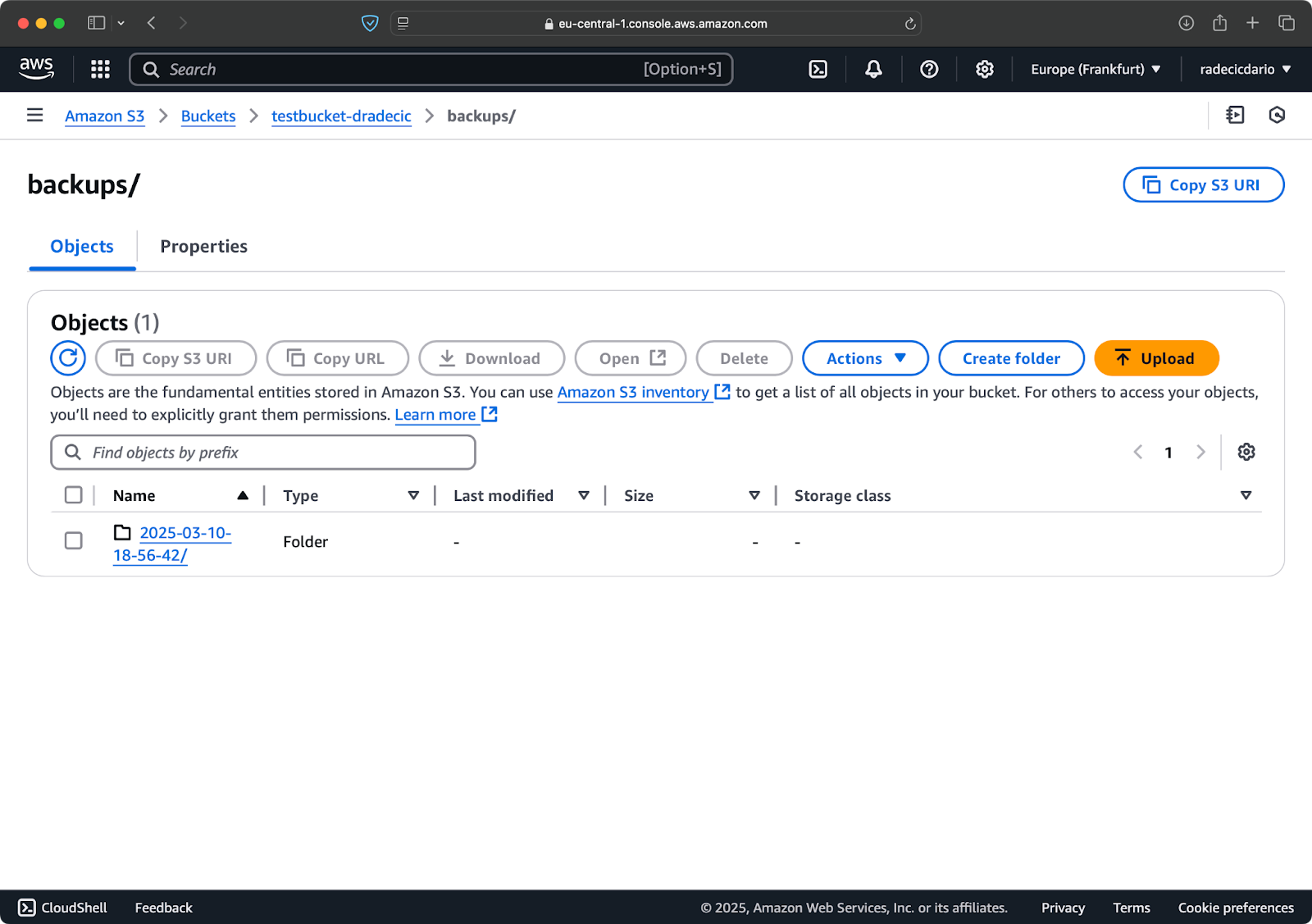
图像18 – 时间戳备份
对于关键数据,您可能希望保留多个备份版本。只需定期运行基于时间戳的备份即可轻松实现。
您还可以使用--storage-class选项指定更 经济实惠的存储类 用于您的备份:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backups/$TIMESTAMP --storage-class STANDARD_IA
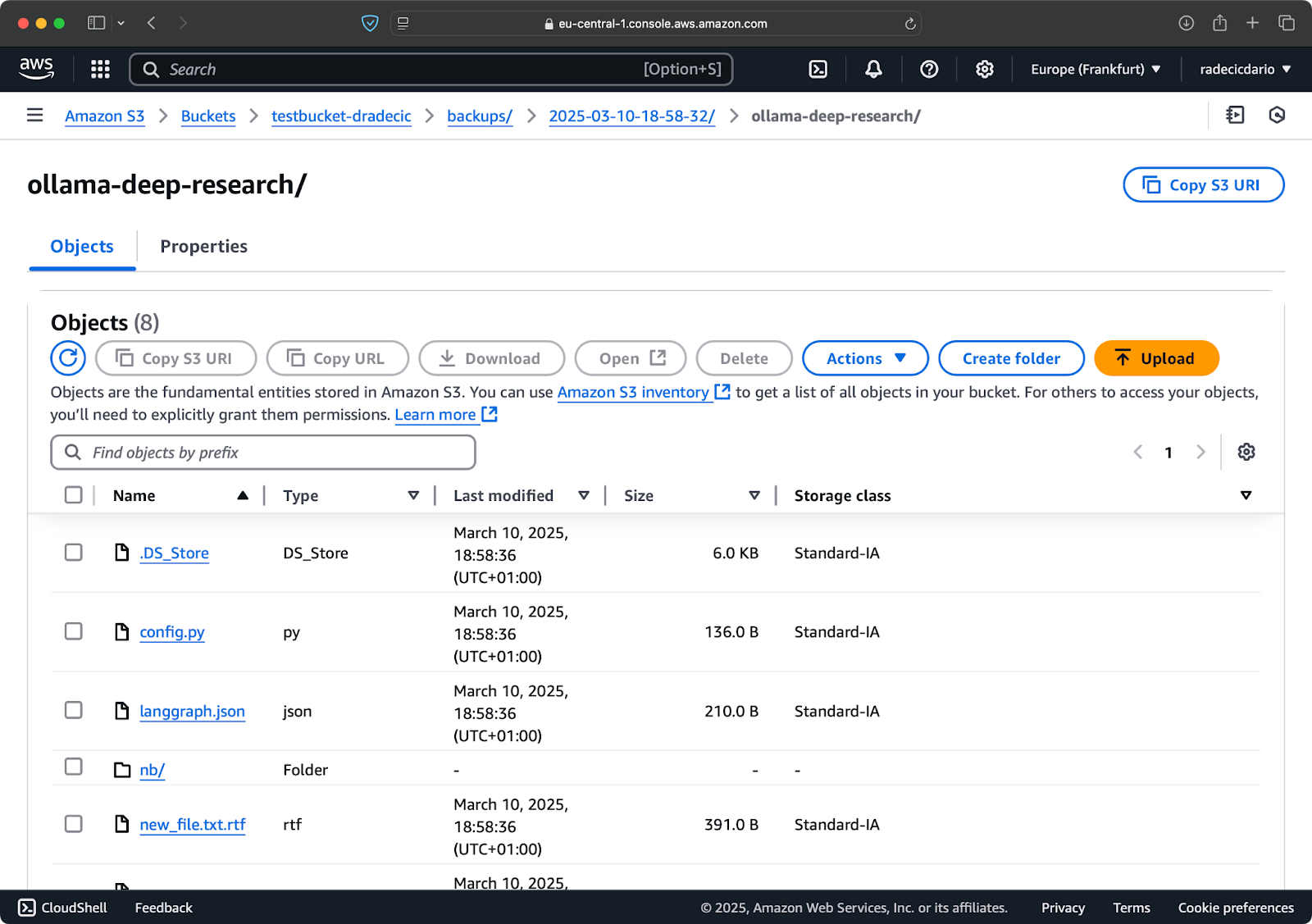
图像19 – 使用自定义存储类备份内容
这使用了S3低频访问存储级别,成本较低但有轻微的检索费用。对于长期归档,您甚至可以使用Glacier存储级别:
aws s3 sync /Users/dradecic/Documents/important-data s3://testbucket-dradecic/backups/$TIMESTAMP --storage-class GLACIER
请记住,从Glacier存储的文件恢复需要几小时,因此不适用于您可能需要快速访问的数据。
从S3恢复文件
从备份中恢复同样简单 – 只需在您的同步命令中反转源和目标:
# 从最近的备份中恢复(假设您知道时间戳) aws s3 sync s3://testbucket-dradecic/backups/2025-03-10-18-56-42 /Users/dradecic/Documents/restored-data
这将从特定备份中下载所有文件到您的本地restored-data目录:
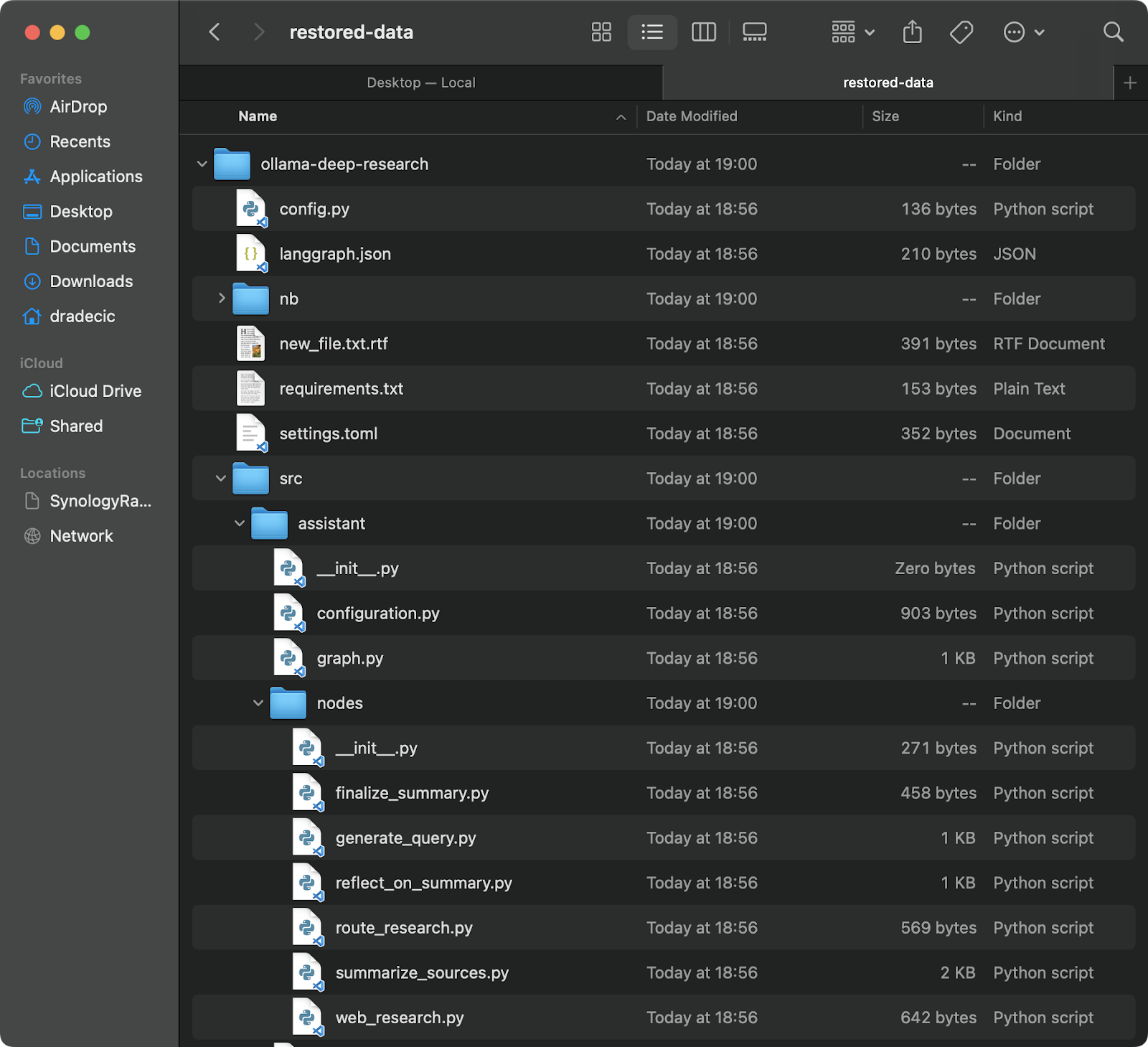
图像20 – 从S3恢复文件
如果您不记得确切的时间戳,您可以首先列出所有备份:
aws s3 ls s3://testbucket-dradecic/backups/
这将显示类似于以下内容:
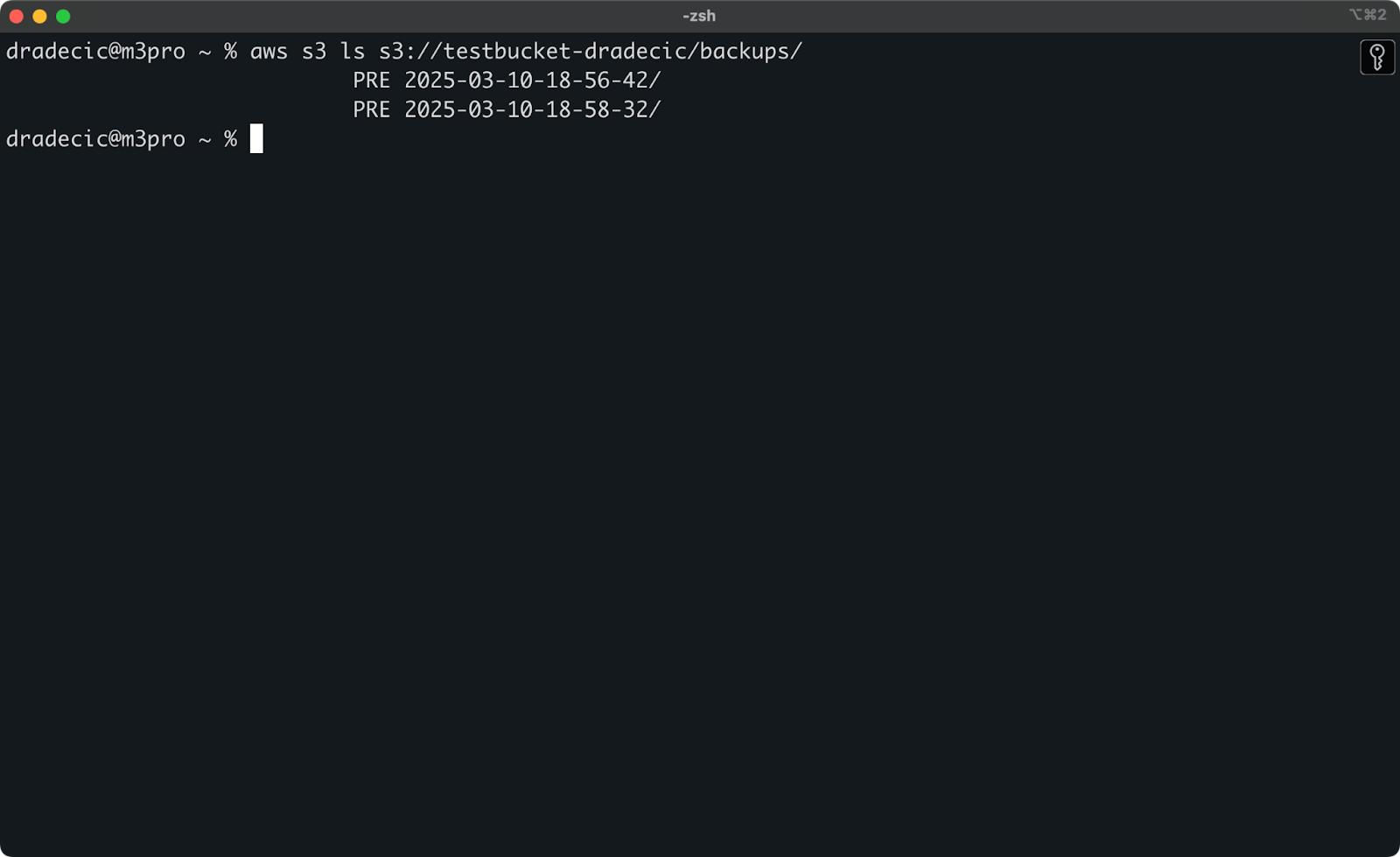
图像21 – 备份列表
您还可以使用我们之前讨论过的排除/包含标志从备份中恢复特定文件或目录:
# 仅恢复配置文件 aws s3 sync s3://testbucket-dradecic/backups/2025-03-10-18-56-42 /Users/dradecic/Documents/restored-configs --exclude "*" --include "*.config" --include "*.toml" --include "*.yaml"
对于关键系统,我建议使用定时任务自动备份(比如在Linux/macOS上使用cron作业或在Windows上使用任务计划程序)。这样可以确保您在不必手动记得备份的情况下持续备份数据。
解决 AWS S3 同步问题
AWS S3 同步是一个可靠的工具,但偶尔可能会遇到问题。不过,大多数错误都是人为造成的。
常见的同步错误
让我们看一下一些常见问题及其解决方案。
- 拒绝访问错误通常意味着您的 IAM 用户没有访问 S3 存储桶或执行特定操作所需的权限。要解决此问题,请尝试以下方法之一:
- 检查您的IAM用户是否具有适当的S3权限(
s3:ListBucket,s3:GetObject,s3:PutObject)。 - 验证存储桶策略没有明确拒绝您的用户访问。
- 如果需要公共操作,请确保存储桶本身没有阻止公共访问。
- 找不到文件或目录错误通常出现在同步命令中指定的源路径不存在时。解决方法很简单 – 仔细检查您的路径并确保它们存在。特别注意存储桶名称或本地目录中的拼写错误。
- 文件大小限制当您想要同步大文件时可能会出现错误。默认情况下,S3同步可以处理最大5GB大小的文件。对于更大的文件,您会看到超时或传输不完整。
- 对于大于5GB的文件,您应该使用
--only-show-errors标志与--size-only标志相结合。这种组合有助于通过最小化输出并仅比较文件大小来进行大文件传输:
aws s3 sync /Users/dradecic/large-files s3://testbucket-dradecic/large-files --only-show-errors --size-only
同步性能优化
如果您的S3同步速度比预期慢,您可以进行一些调整以加快速度。
- 使用并行传输。默认情况下,S3同步使用有限数量的并行操作。您可以通过
--max-concurrent-requests参数来增加这个数量:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup --max-concurrent-requests 20
- 调整块大小。对于大文件,您可以通过调整块大小来优化传输速度。这将大文件分成16MB的块,而不是默认的8MB,对于良好的网络连接速度可能更快:
aws s3 sync /Users/dradecic/large-files s3://testbucket-dradecic/backup --cli-read-timeout 120 --multipart-threshold 64MB --multipart-chunksize 16MB
- 对于脚本使用
--no-progress。如果您正在自动化脚本中运行S3同步,请使用--no-progress标志来减少输出并提高性能:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup --no-progress
- 使用本地端点。如果您的AWS资源位于同一地区,指定区域端点可以减少延迟:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup --endpoint-url https://s3.eu-central-1.amazonaws.com
这些优化可以显著提高同步性能,特别是对于大数据传输或在性能较弱的计算机上运行时。
如果尝试了这些解决方案后仍然遇到问题,AWS CLI具有内置的调试选项。只需在命令中添加--debug,即可查看有关同步过程中发生的详细信息:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup --debug
期望看到大量详细的日志消息,类似于这些:
图像22 – 在调试模式下运行同步
至于解决 AWS S3 同步问题,基本上就是这样。当然,可能会发生其他错误,但在这部分中你将找到解决方案的 99%。
总结 AWS S3 同步
总而言之,AWS S3 同步是一种既简单易用又功能强大的工具。你已经学会了从基本命令到高级选项、备份策略以及故障排除技巧。
对于开发人员、系统管理员或任何与 AWS 工作的人来说,S3 同步命令是一种必不可少的工具 – 它节省时间,减少带宽使用,并确保你的文件在你需要它们的地方。
无论你是在备份关键数据、部署 Web 资产,还是只是保持不同环境同步,AWS S3 同步都使这个过程简单可靠。
熟悉S3同步的最佳方法是开始使用它。尝试使用自己的文件设置简单的同步操作,然后逐渐探索高级选项以满足您的特定需求。
请记住,在处理重要数据时,特别是在使用--delete标志时,始终首先使用--dryrun。最好多花一分钟验证将发生什么,而不是意外删除重要文件。
要了解更多关于AWS的信息,请查看DataCamp提供的这些课程:
您甚至可以使用DataCamp来准备AWS认证考试 – AWS云从业者(CLF-C02)。