













De AWS CLI en AWS S3 instellen
Voordat je bestanden kunt synchroniseren met S3, moet je de AWS CLIl op de juiste manier instellen en configureren. Dit kan intimiderend klinken als je nieuw bent bij AWS, maar het kost slechts een paar minuten.
Het instellen van de CLI omvat twee hoofdstappen: het installeren van de tool en het configureren ervan. Ik zal beide stappen hieronder bespreken.
De AWS CLI installeren
De installatie van de AWS CLI verschilt enigszins afhankelijk van je besturingssysteem.
Voor Windows-systemen:
- Ga naar de AWS CLI downloadpagina
- Download de Windows installer (64-bit)
- Voer de installer uit en volg de instructies
Voor Linux systemen:
Voer de volgende drie commando’s uit in de Terminal:
curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip" unzip awscliv2.zip sudo ./aws/install
Voor macOS systemen:
Als je Homebrew geïnstalleerd hebt, voer dan deze ene regel uit in de Terminal:
brew install awscli
Als je Homebrew niet hebt, kun je in plaats daarvan deze twee commando’s gebruiken:
curl "https://awscli.amazonaws.com/AWSCLIV2.pkg" -o "AWSCLIV2.pkg" sudo installer -pkg AWSCLIV2.pkg -target /
Je kunt het aws --version commando uitvoeren op alle besturingssystemen om te controleren of AWS CLI is geïnstalleerd. Dit is wat je zou moeten zien:
Afbeelding 1 – AWS CLI-versie
Het configureren van de AWS CLI
Nu je de CLI hebt geïnstalleerd, moet je deze configureren met je AWS-inloggegevens.
Als je al een AWS-account hebt, log dan in en ga naar de IAM-service. Maak daar een nieuwe gebruiker met programmatotische toegang. Je moet de juiste machtigingen toewijzen aan de gebruiker, wat minimaal S3-toegang is:
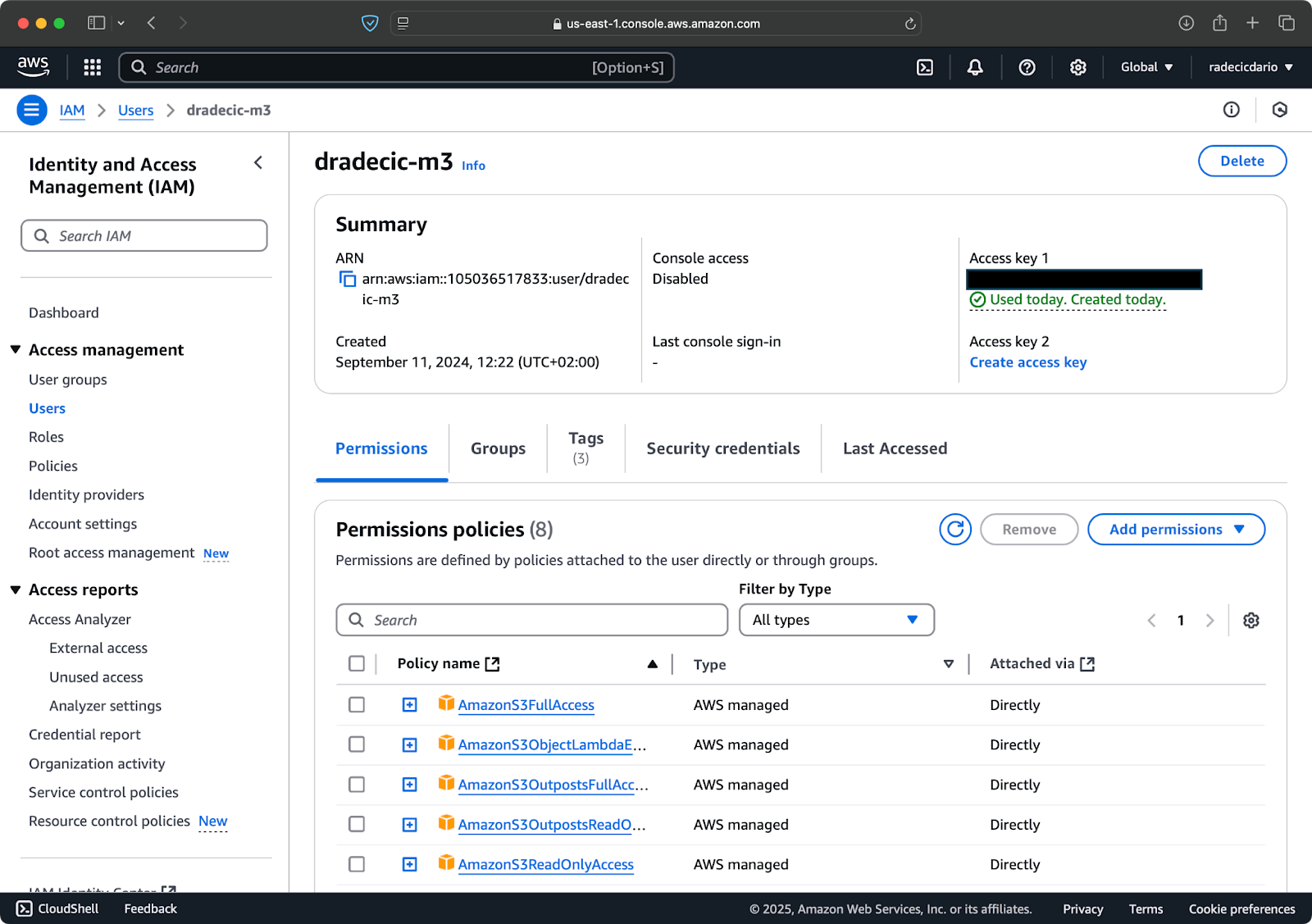
Afbeelding 2 – AWS IAM-gebruiker
Zodra dit is gedaan, ga naar “Beveiligingsreferenties” om een nieuwe toegangssleutel aan te maken. Nadat je deze hebt aangemaakt, krijg je zowel de Toegangssleutel-ID als Geheime toegangssleutel. Schrijf ze ergens veilig op, want je zult ze in de toekomst niet meer kunnen bekijken:
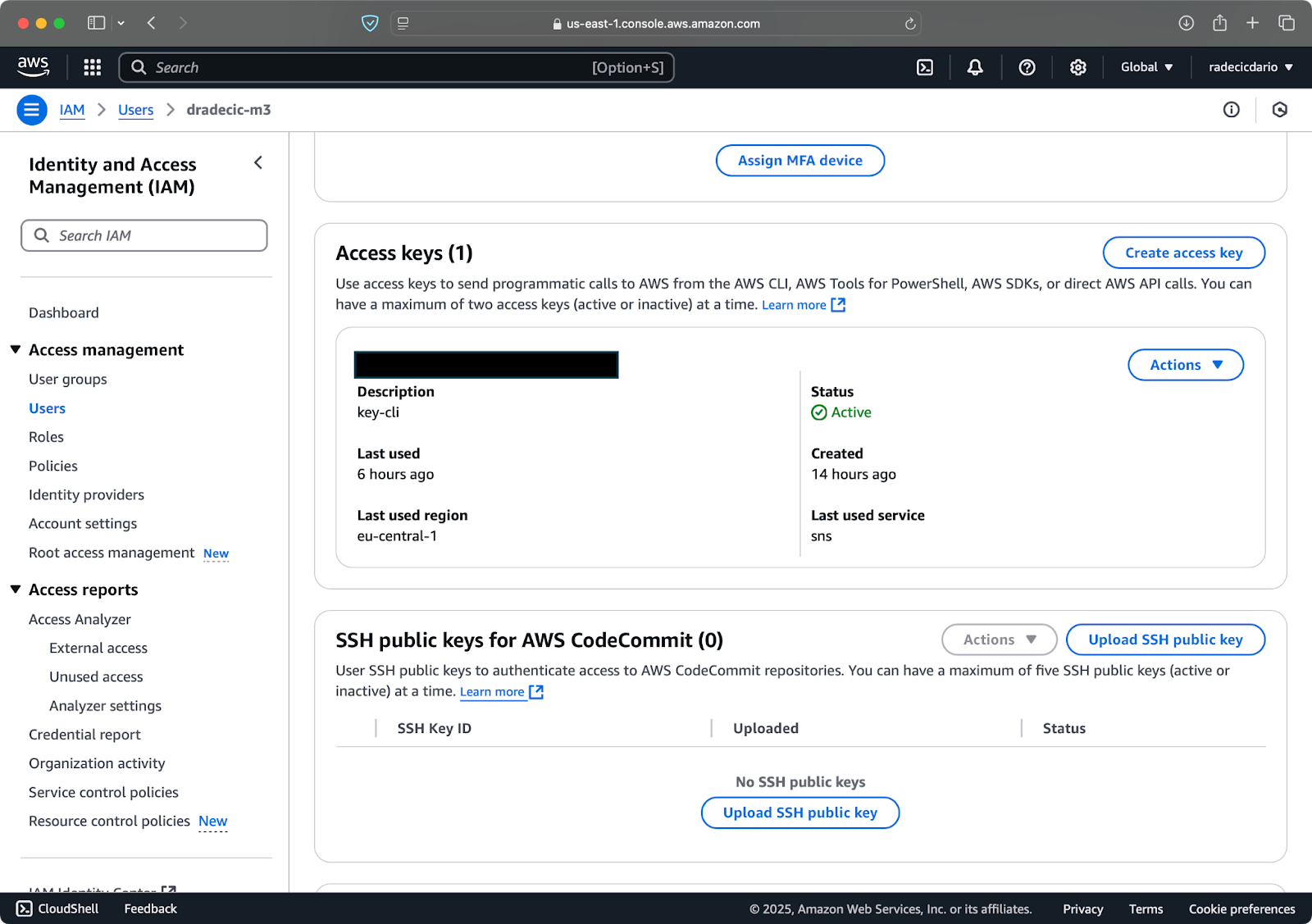
Afbeelding 3 – AWS IAM-gebruikersreferenties
Ga terug naar de Terminal en voer het commando aws configure uit. Het zal je vragen om je Access key ID, Secret access key, regio (eu-central-1 in mijn geval) en voorkeur voor uitvoerformaat (json) in te voeren:
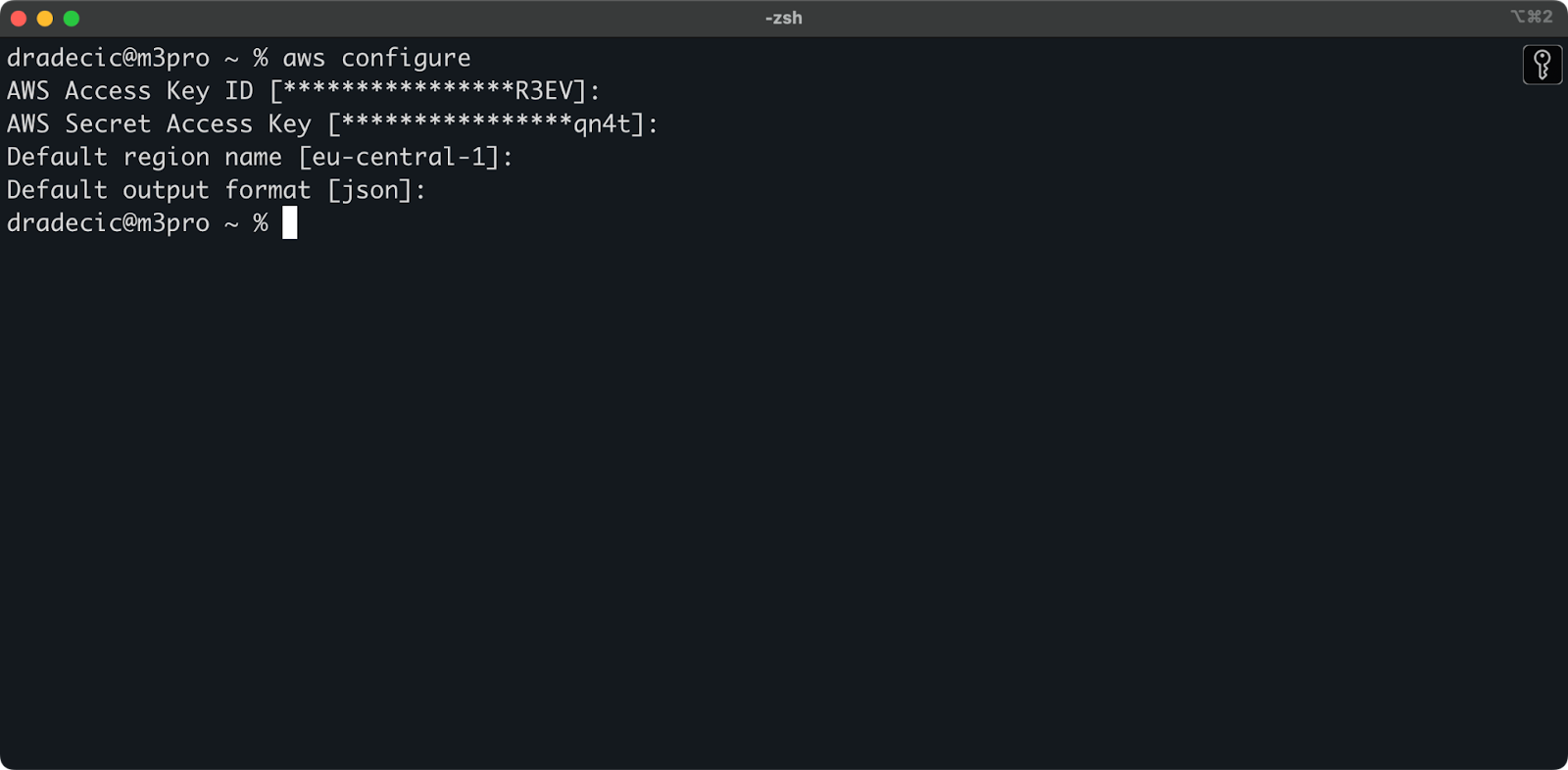
Afbeelding 4 – AWS CLI-configuratie
Om te verifiëren dat je succesvol verbonden bent met je AWS-account vanuit de CLI, voer je het volgende commando uit:
aws sts get-caller-identity
Dit is de uitvoer die je zou moeten zien:
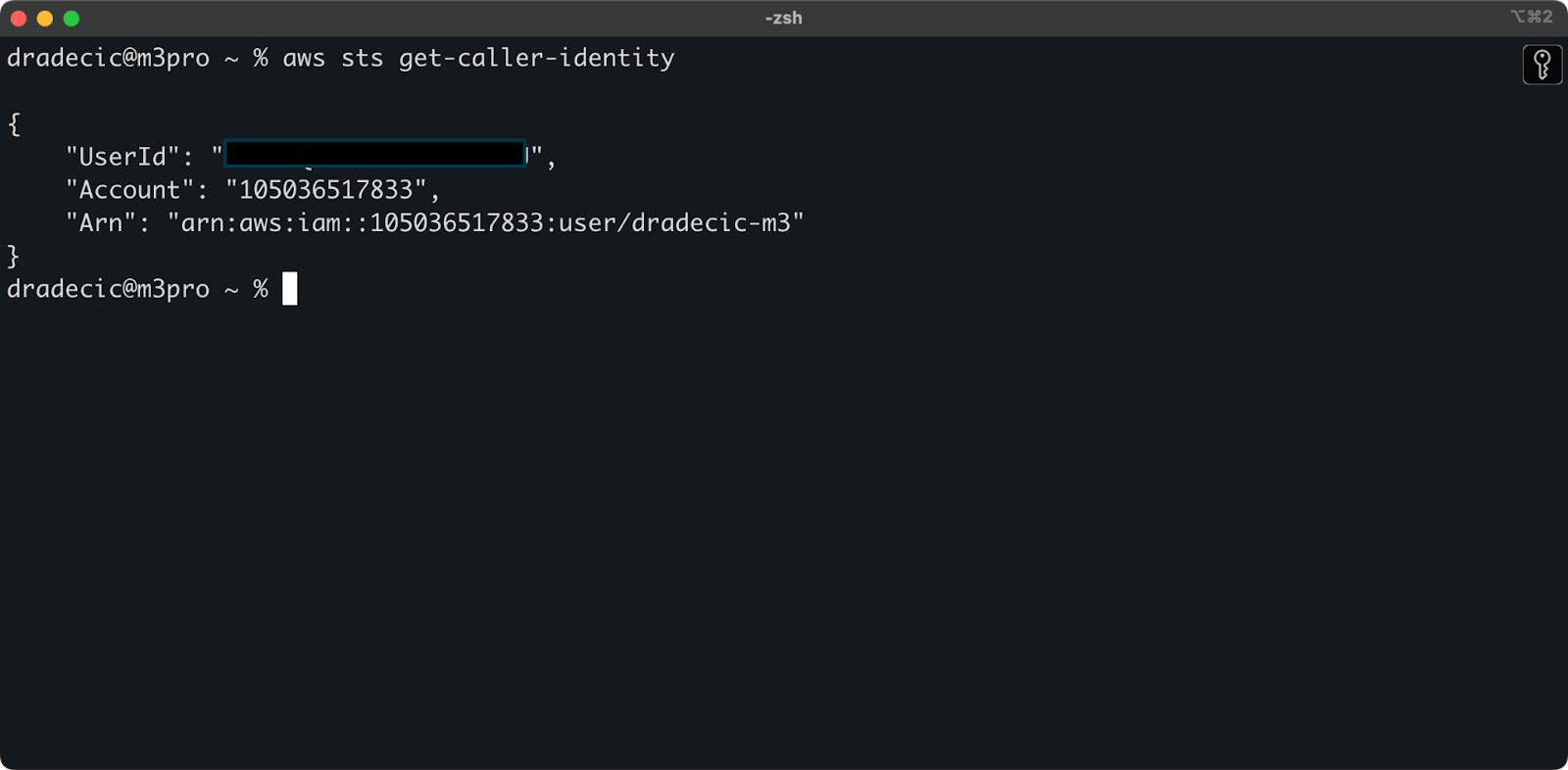
Afbeelding 5 – AWS CLI testverbinding commando
En dat is het – nog maar één stap voordat je kunt beginnen met het gebruik van het S3 sync-commando!
Een AWS S3-bucket instellen
De laatste stap is het maken van een S3-bucket waarin je gesynchroniseerde bestanden worden opgeslagen. Dit kun je doen via de CLI of via de AWS Management Console. Ik kies voor het laatste, gewoon om het wat af te wisselen.
Om te beginnen, ga naar de S3-servicepagina in de Management Console en klik op de knop “Bucket maken”. Kies vervolgens een unieke bucketnaam (uniek wereldwijd over alle AWS) en scroll naar beneden en klik op de knop “Maken”:
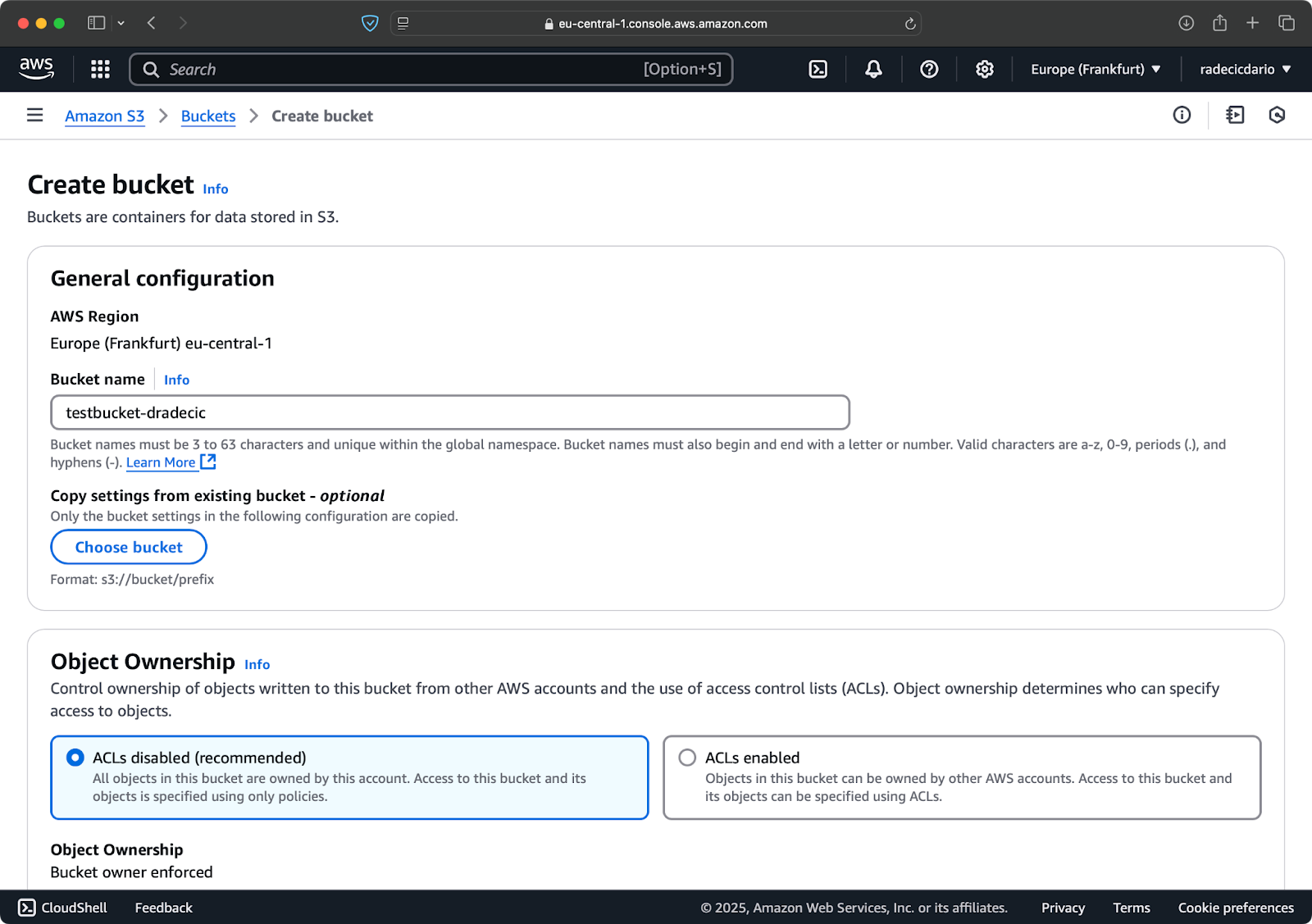
Afbeelding 6 – AWS-bucketcreatie
De bucket is nu aangemaakt en je ziet hem meteen in de beheerconsole. Je kunt ook controleren of hij is aangemaakt via de CLI:
aws s3 ls
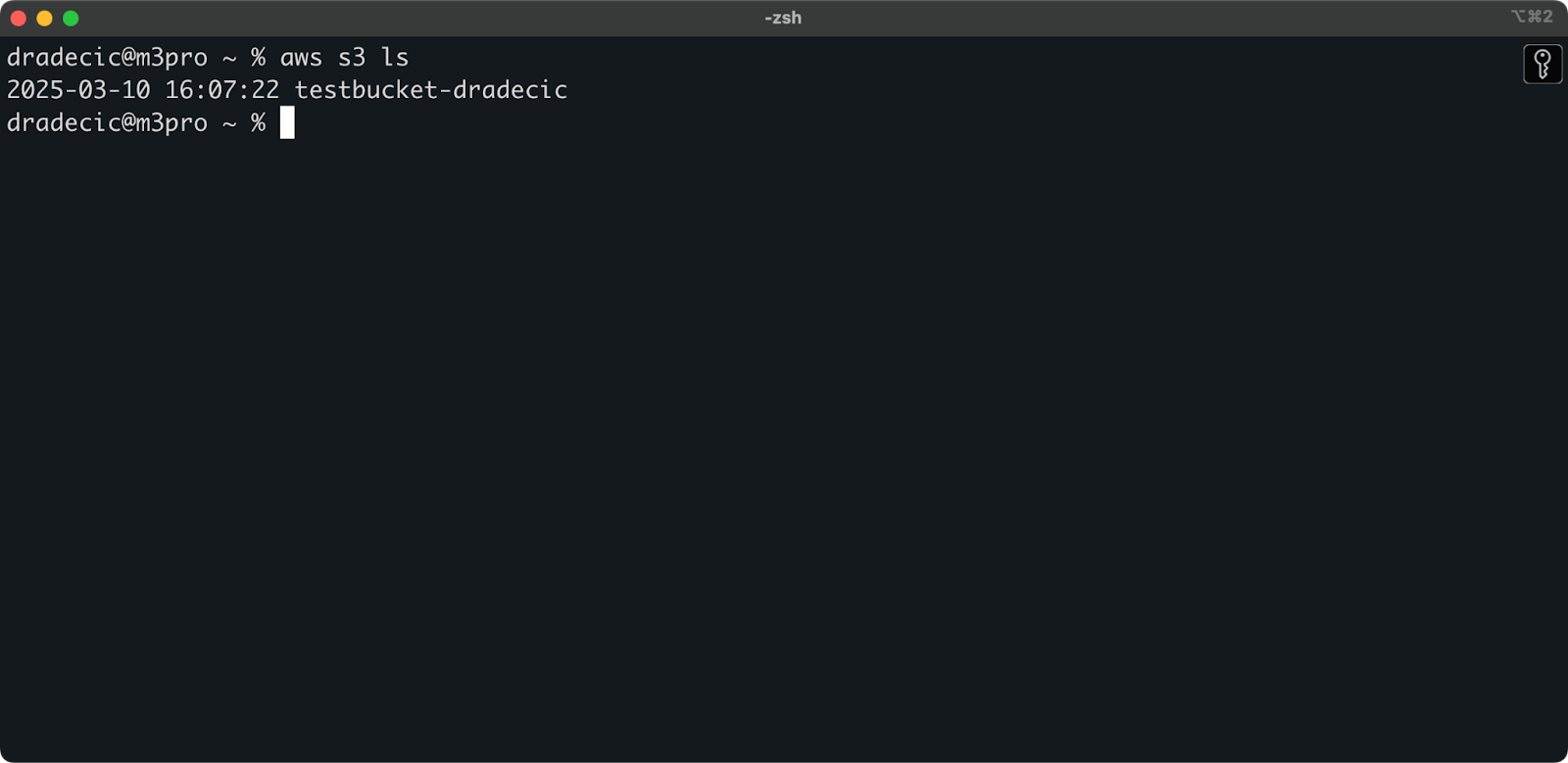
Afbeelding 7 – Alle beschikbare S3-buckets
Houd er rekening mee dat S3-buckets standaard privé zijn. Als je van plan bent de bucket te gebruiken voor het hosten van openbare bestanden (zoals website-assets), moet je de bucketbeleid en machtigingen dienovereenkomstig aanpassen.
Nu ben je helemaal ingesteld en klaar om bestanden te synchroniseren tussen je lokale machine en AWS S3!
Basis AWS S3 Sync Commando
Nu je de AWS CLI hebt geïnstalleerd, geconfigureerd en een S3-bucket klaar hebt staan, is het tijd om te beginnen met synchroniseren! De basis syntaxis voor het AWS S3 sync-commando is vrij eenvoudig. Laat me je laten zien hoe het werkt.
Het S3 sync-commando volgt dit eenvoudige patroon:
aws s3 sync <source> <destination> [options]
Zowel de bron als de bestemming kunnen een lokale map of een S3 URI zijn (beginnend met s3://). Afhankelijk van de manier waarop je wilt synchroniseren, zul je deze anders ordenen.
Bestanden synchroniseren van lokaal naar een S3-bucket
Ik heb onlangs wat gespeeld met diepgaand onderzoek van Ollama. Laten we zeggen dat dat de map is die ik wil synchroniseren met S3. De hoofdmap bevindt zich onder de map Documenten. Dit is hoe het eruitziet:
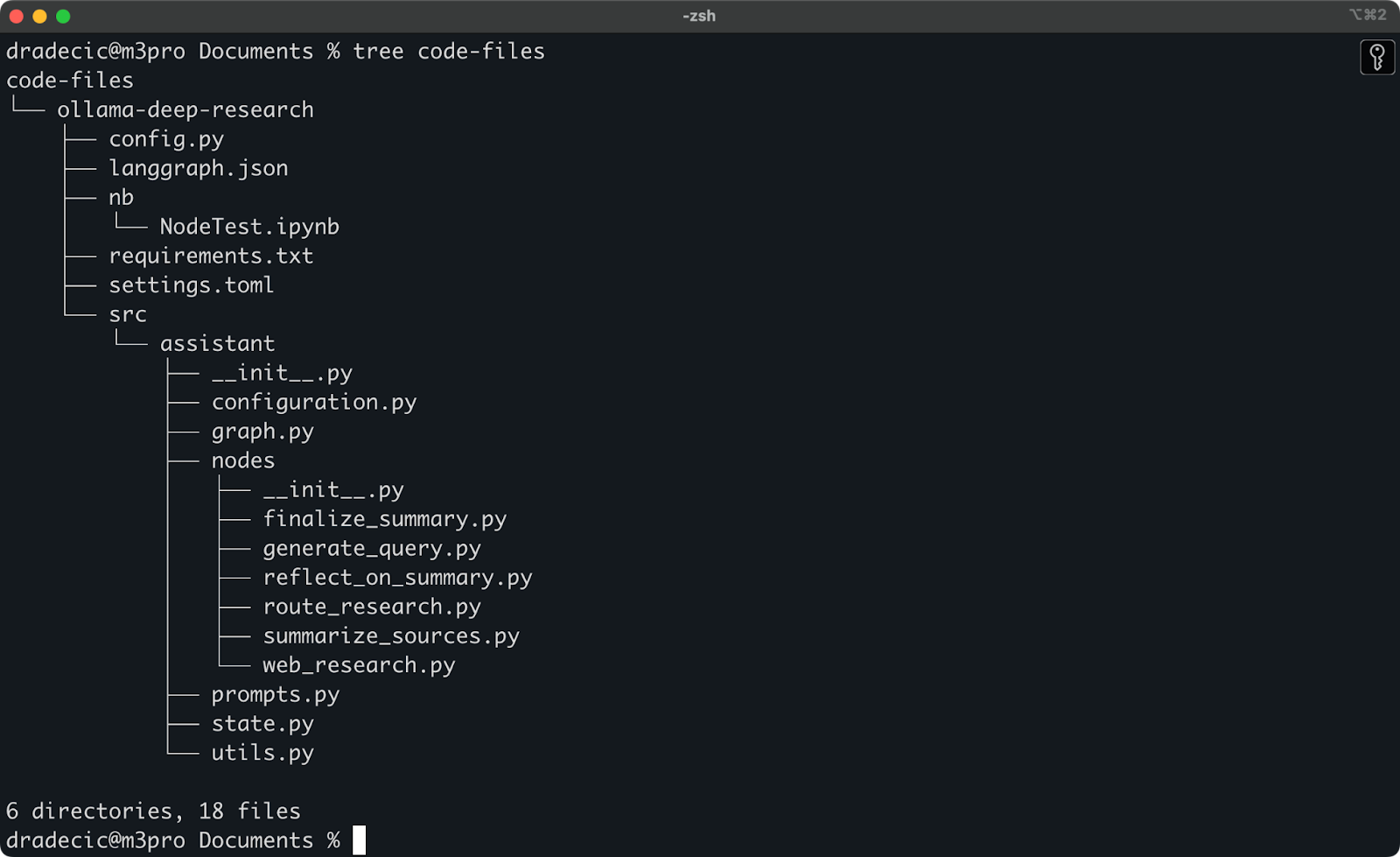
Inhoud van de lokale map
Dit is het commando dat ik moet uitvoeren om de lokale map code-bestanden te synchroniseren met de map backup op de S3-bucket:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup
De map backup op de S3-bucket wordt automatisch aangemaakt als deze niet bestaat.
Dit is wat je op de console zult zien afgedrukt:
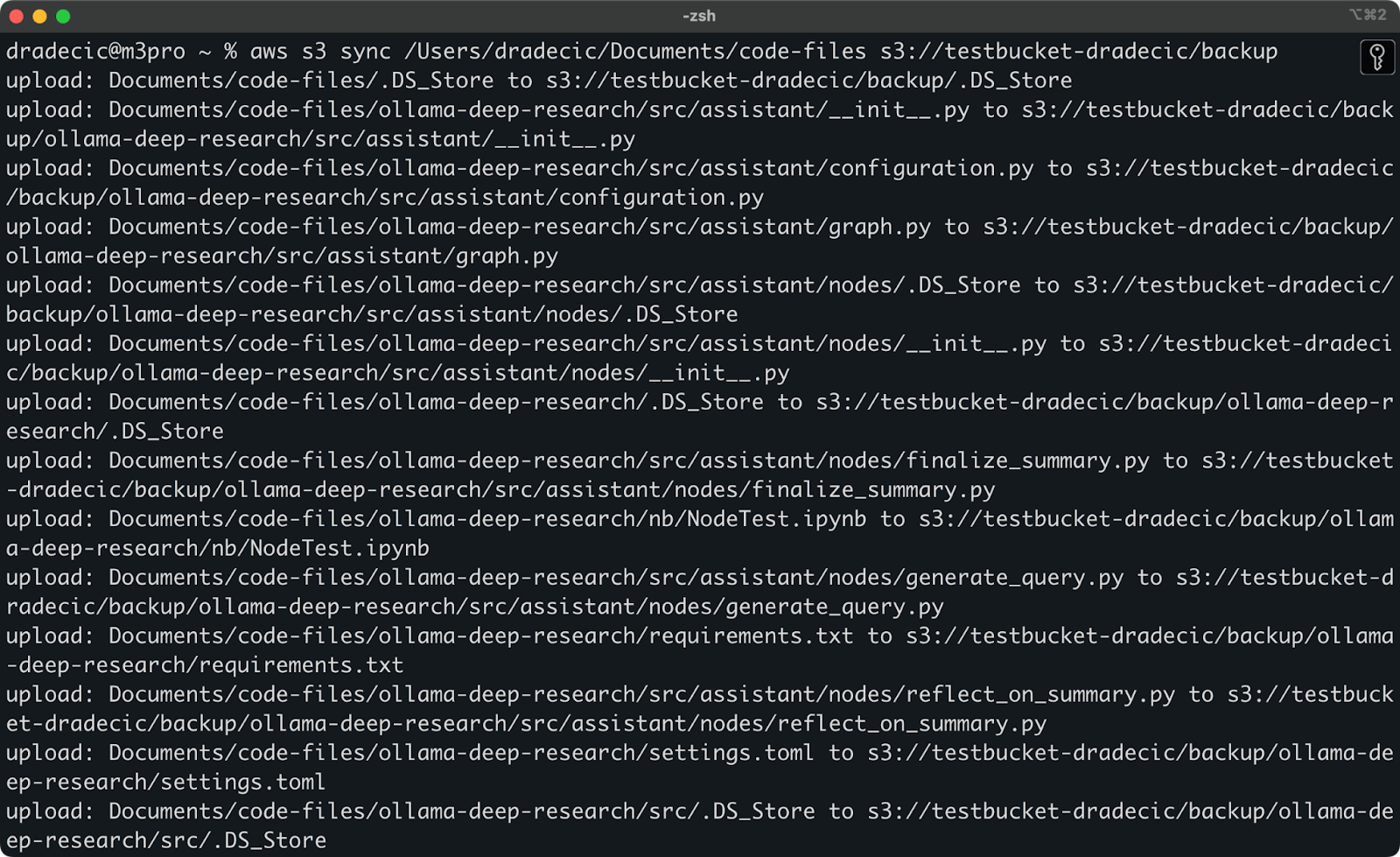
Afbeelding 9 – S3 synchronisatieproces
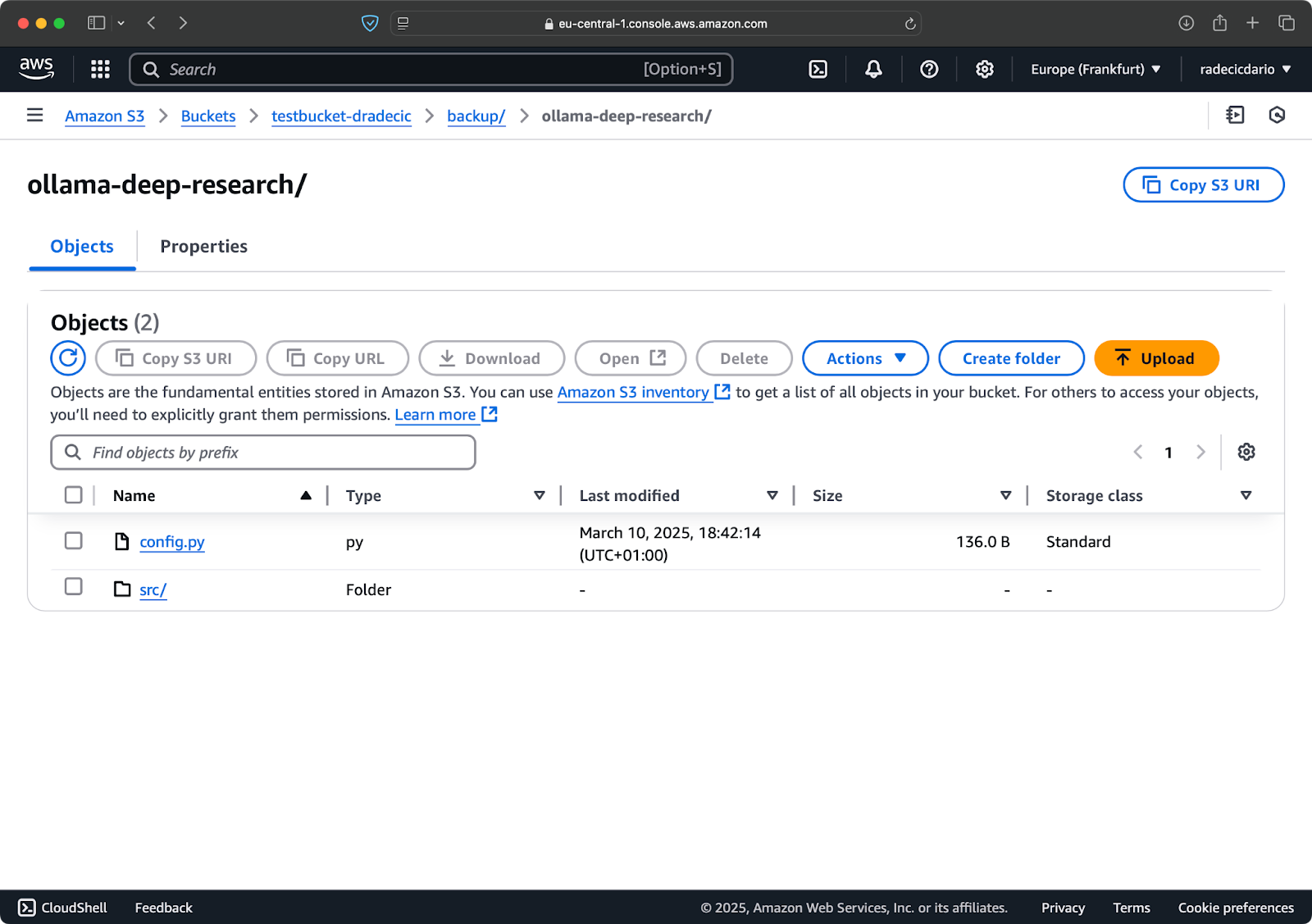
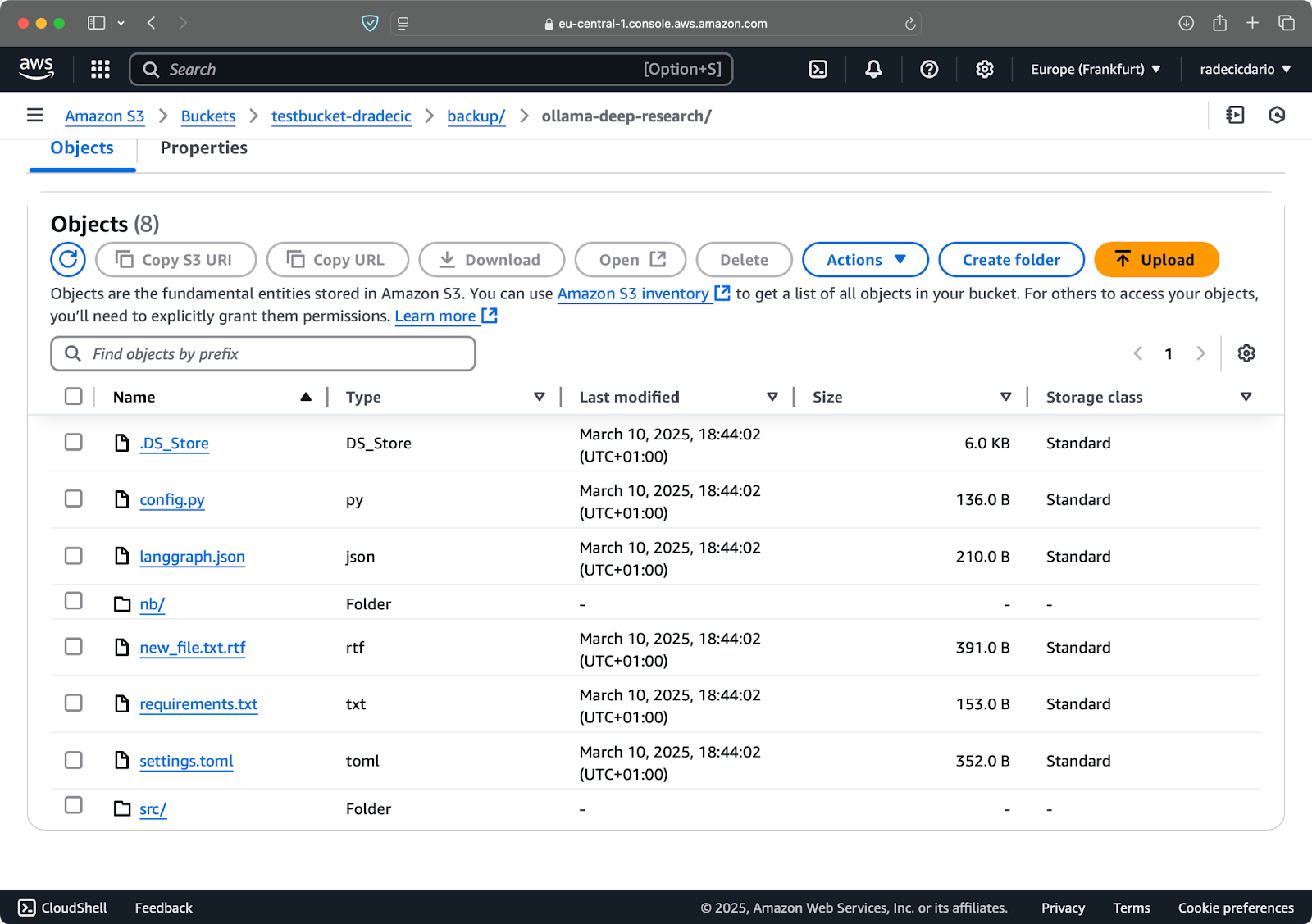
Na een paar seconden zijn de inhoud van de lokale code-bestanden map beschikbaar in de S3-bucket:
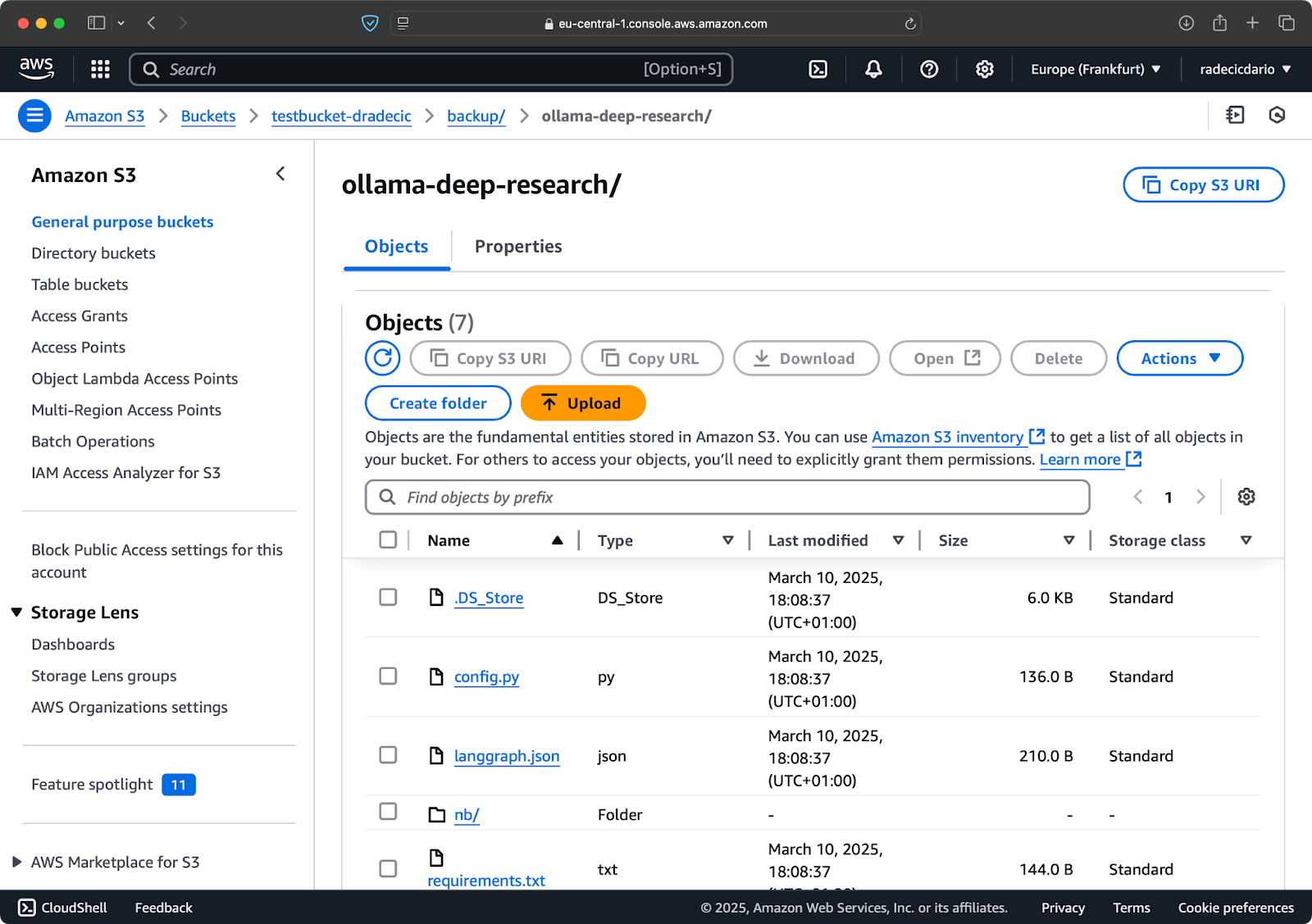
Afbeelding 10 – Inhoud van S3-bucket
De schoonheid van S3-synchronisatie is dat het alleen bestanden uploadt die niet bestaan in de bestemming of lokaal zijn gewijzigd. Als je hetzelfde commando opnieuw uitvoert zonder iets te veranderen, zul je… niets zien! Dat komt omdat AWS CLI heeft gedetecteerd dat alle bestanden al gesynchroniseerd en up-to-date zijn.
Nu zal ik twee kleine wijzigingen aanbrengen – een nieuw bestand maken (new_file.txt) en een bestaand bestand bijwerken (requirements.txt). Wanneer je het synchronisatiecommando opnieuw uitvoert, worden alleen de nieuwe of gewijzigde bestanden geüpload:
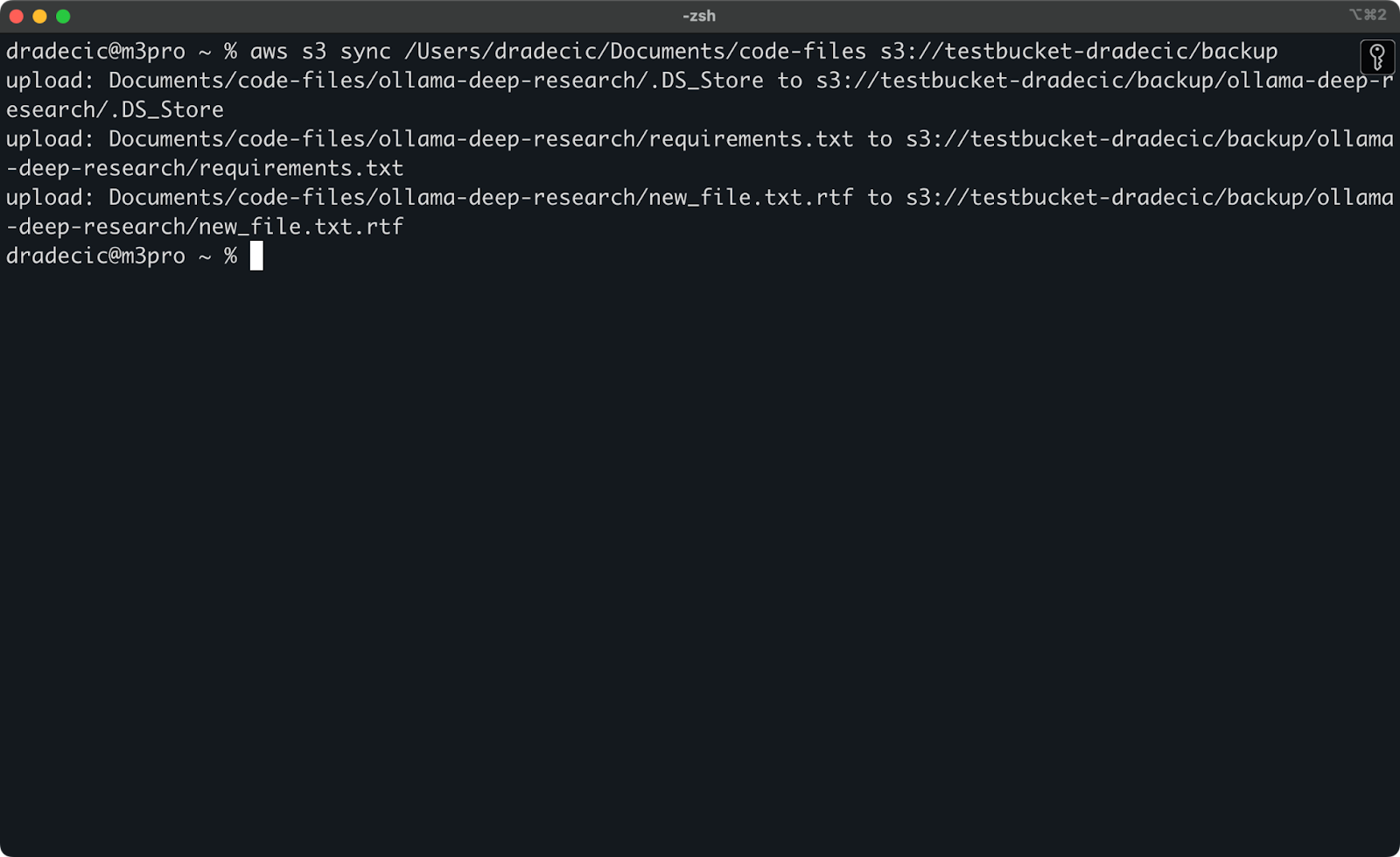
Afbeelding 11 – S3 synchronisatieproces (2)
En dat is alles wat je moet weten bij het synchroniseren van lokale mappen naar S3. Maar wat als je de andere kant op wilt?
Bestanden synchroniseren vanuit de S3-bucket naar een lokale map
Als je bestanden van je S3-bucket naar je lokale machine wilt downloaden, keer dan gewoon de bron en bestemming om:
aws s3 sync s3://testbucket-dradecic/backup /Users/dradecic/Documents/code-files-from-s3
Met dit commando worden alle bestanden uit de map backup in je S3-bucket gedownload naar een lokale map genaamd code-files-from-s3. Als de lokale map weer niet bestaat, zal de CLI deze voor je aanmaken:
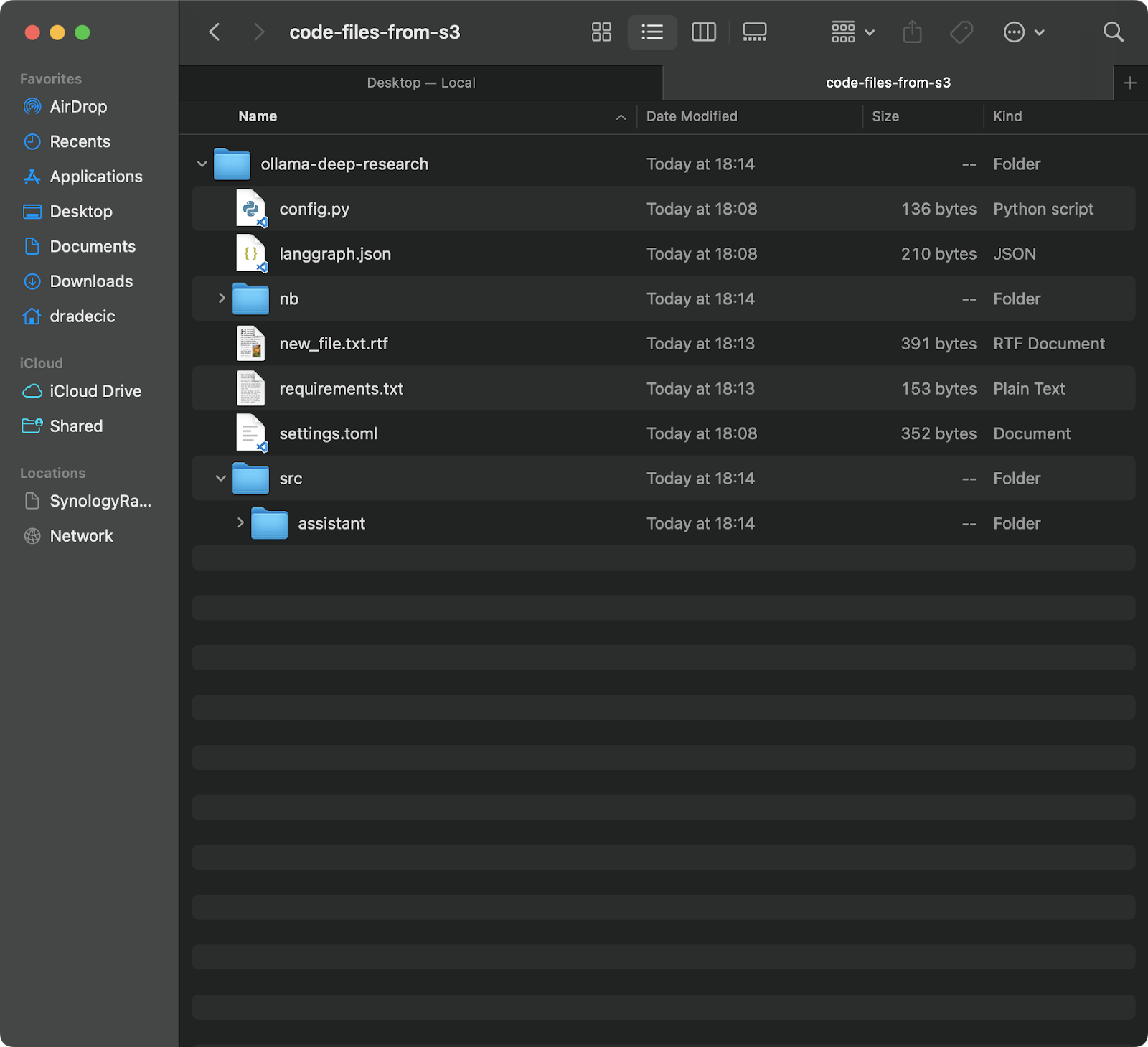
Afbeelding 12 – S3 naar lokale synchronisatie
Het is het vermelden waard dat S3-synchronisatie niet bidirectioneel is. Het gaat altijd van de bron naar de bestemming, waardoor de bestemming overeenkomt met de bron. Als je een bestand lokaal verwijdert en het vervolgens synchroniseert met S3, zal het nog steeds bestaan in S3. Op dezelfde manier, als je een bestand in S3 verwijdert en synchroniseert van S3 naar lokaal, blijft het lokale bestand onaangeroerd.
Als je wilt dat de bestemming exact overeenkomt met de bron (inclusief verwijderingen), moet je de --delete vlag gebruiken, waar ik in de sectie geavanceerde opties op in zal gaan.
Geavanceerde AWS S3-synchronisatieopties
De basis S3-synchronisatieopdracht die eerder is verkend, is op zichzelf al krachtig, maar AWS heeft deze verpakt met aanvullende opties die je meer controle geven over het synchronisatieproces.
In deze sectie zal ik je enkele van de meest handige vlaggen laten zien die je kunt toevoegen aan de basisopdracht.
Synchroniseren van alleen nieuwe of gewijzigde bestanden
Standaard gebruikt S3-synchronisatie een basisvergelijkingsmechanisme dat bestandsgrootte en wijzigingstijd controleert om te bepalen of een bestand gesynchroniseerd moet worden. Deze aanpak kan echter niet altijd alle wijzigingen vastleggen, vooral bij het werken met bestanden die zijn gewijzigd maar dezelfde grootte hebben.
Voor nauwkeurigere synchronisatie kun je de --exacte-timestamps vlag gebruiken:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup --exact-timestamps
Dit dwingt S3 sync om tijdstempels te vergelijken met een precisie tot op de milliseconden. Houd er rekening mee dat het gebruik van deze vlag de sync licht kan vertragen, omdat het meer gedetailleerde vergelijkingen vereist.
Specifieke bestanden uitsluiten of opnemen
Soms wil je niet elk bestand in een directory synchroniseren. Misschien wil je tijdelijke bestanden, logbestanden of bepaalde bestandstypen uitsluiten (zoals .DS_Store in mijn geval). Daar komen de vlaggen --exclude en --include van pas.
Maar om een punt te illustreren, laten we zeggen dat ik mijn code-directory wil synchroniseren maar alle Python-bestanden wil uitsluiten:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup --exclude "*.py"
Nu worden er veel minder bestanden gesynchroniseerd met S3:
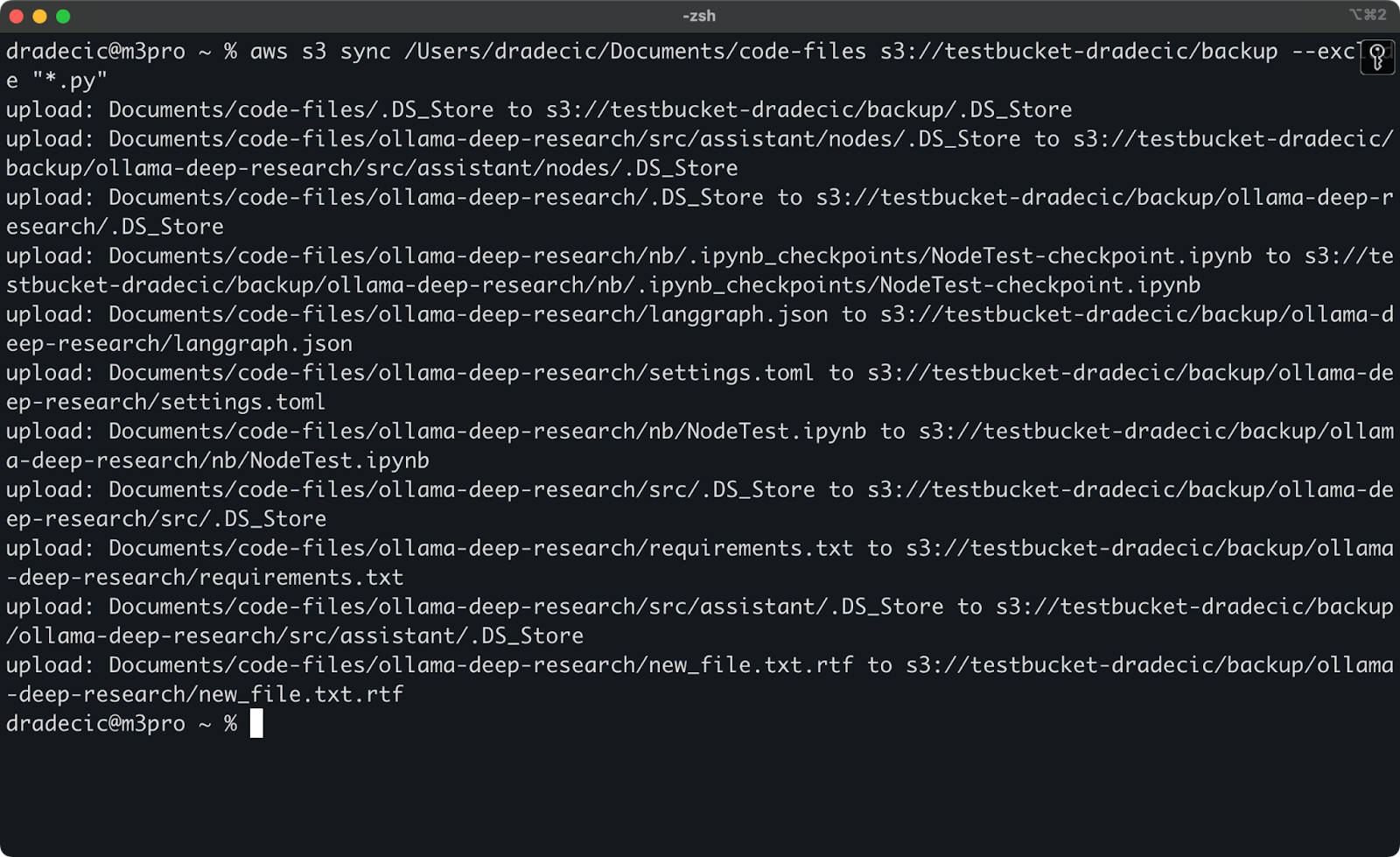
Afbeelding 13 – S3-synchronisatie met uitgesloten Python-bestanden
Je kunt ook --exclude en --include combineren om complexere patronen te creëren. Sluit bijvoorbeeld alles uit behalve Python-bestanden:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup --exclude "*" --include "*.py"
De patronen worden geëvalueerd in de opgegeven volgorde, dus de volgorde is belangrijk! Dit is wat je ziet bij het gebruik van deze vlaggen:
Afbeelding 14 – Uitsluit- en inclusievlaggen
Nu worden alleen de Python-bestanden gesynchroniseerd, en belangrijke configuratiebestanden ontbreken.
Bestanden van de bestemming verwijderen
Standaard voegt S3-sync alleen bestanden toe of bijwerkt deze in de bestemming – het verwijdert ze nooit. Dit betekent dat als je een bestand verwijdert uit de bron, het nog steeds in de bestemming zal blijven na het synchroniseren.
Om de bestemming precies hetzelfde te maken als de bron, inclusief verwijderingen, gebruik de --delete vlag:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup --delete
Als je dit de eerste keer uitvoert, worden alle lokale bestanden gesynchroniseerd met S3:
Afbeelding 15 – Verwijderingsvlag
Dit is bijzonder nuttig voor het behouden van exacte replica’s van mappen. Maar wees voorzichtig – deze vlag kan leiden tot gegevensverlies als deze verkeerd wordt gebruikt.
Laten we zeggen dat ik config.py uit mijn lokale map verwijder en het synchronisatiecommando met de --delete vlag uitvoer:
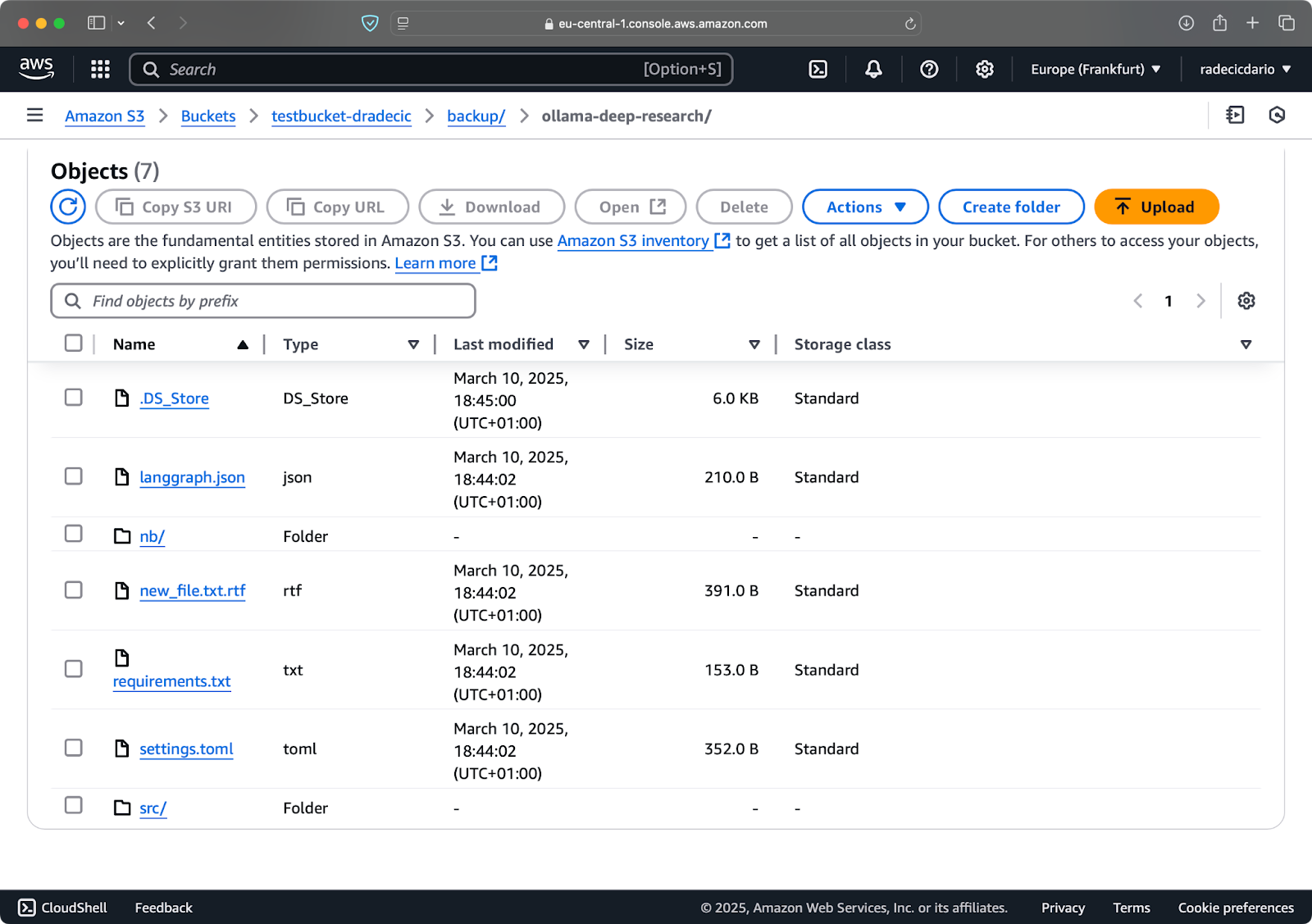
Afbeelding 16 – Verwijder vlag (2)
Zoals je kunt zien, synchroniseert het commando niet alleen nieuwe en gewijzigde bestanden, maar verwijdert het ook bestanden uit de S3-bucket die niet langer in de lokale map bestaan.
Een droge run instellen voor veilige synchronisatie
De meest gevaarlijke S3 synchronisatie-operaties zijn diegene die de --delete vlag gebruiken. Om per ongeluk belangrijke bestanden te verwijderen, kun je de --dryrun vlag gebruiken om de operatie te simuleren zonder daadwerkelijk wijzigingen aan te brengen:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup --delete --dryrun
Ter illustratie, ik heb de requirements.txt en settings.toml bestanden verwijderd uit een lokale map en vervolgens het commando uitgevoerd:
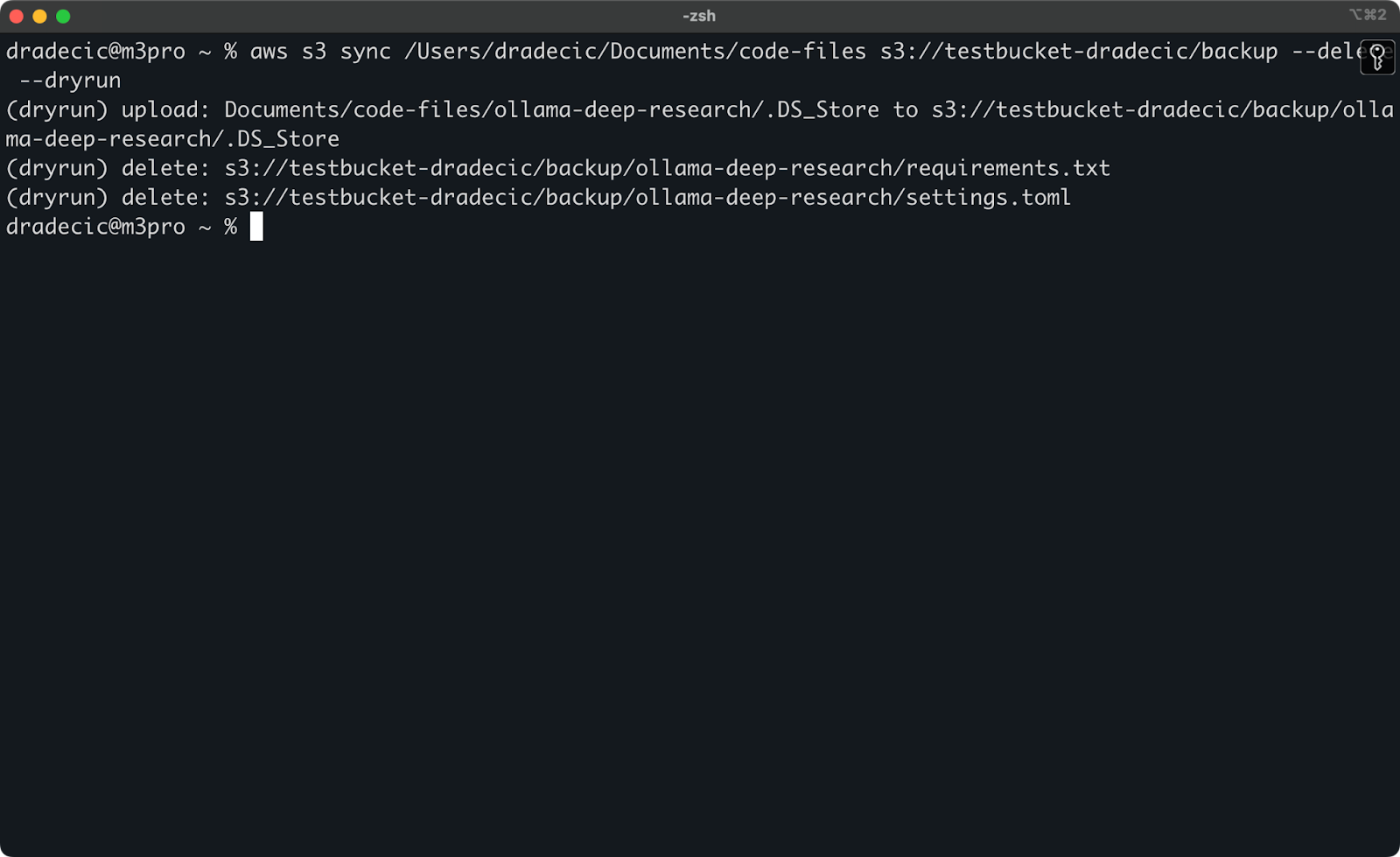
Afbeelding 17 – Droge run
Dit zal je precies laten zien wat er zou gebeuren als je het commando daadwerkelijk uitvoert, inclusief welke bestanden geüpload, gedownload of verwijderd zouden worden.
Ik raad altijd aan om --dryrun te gebruiken voordat je een S3 synchronisatiecommando uitvoert met de --delete vlag, vooral bij het werken met belangrijke gegevens.
Er zijn veel andere opties beschikbaar voor de S3 sync-opdracht, zoals --acl voor het instellen van machtigingen, --storage-class voor het kiezen van de S3 opslagklasse, en --recursive voor het doorlopen van submappen. Bekijk de officiële AWS CLI-documentatie voor een complete lijst van opties.
Nu je bekend bent met de basis- en geavanceerde S3 sync-opties, laten we kijken hoe je deze opdrachten kunt gebruiken voor praktische scenario’s zoals back-ups en herstel.
Gebruik van AWS S3 Sync voor Back-up en Herstel
Een van de meest populaire gebruiksscenario’s voor AWS S3 sync is het maken van back-ups van belangrijke bestanden en het herstellen ervan wanneer dat nodig is. Laten we verkennen hoe je een eenvoudige back-up- en herstelstrategie kunt implementeren met behulp van de sync-opdracht.
Back-ups maken naar S3
Het maken van back-ups met S3 synchronisatie is eenvoudig – je hoeft alleen het synchronisatiecommando uit te voeren vanuit je lokale map naar een S3-bucket. Er zijn echter een paar best practices om te volgen voor effectieve back-ups.
Ten eerste is het een goed idee om je back-ups te organiseren op datum of versie. Hier is een eenvoudige aanpak met behulp van een tijdstempel in het S3-pad:
# Maak een tijdstempel variabele TIMESTAMP=$(date +%Y-%m-%d-%H-%M-%S) # Voer de back-up uit aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backups/$TIMESTAMP
Dit maakt een nieuwe map voor elke back-up met een tijdstempel zoals 2025-03-10-18-56-42. Dit is wat je zult zien op S3:
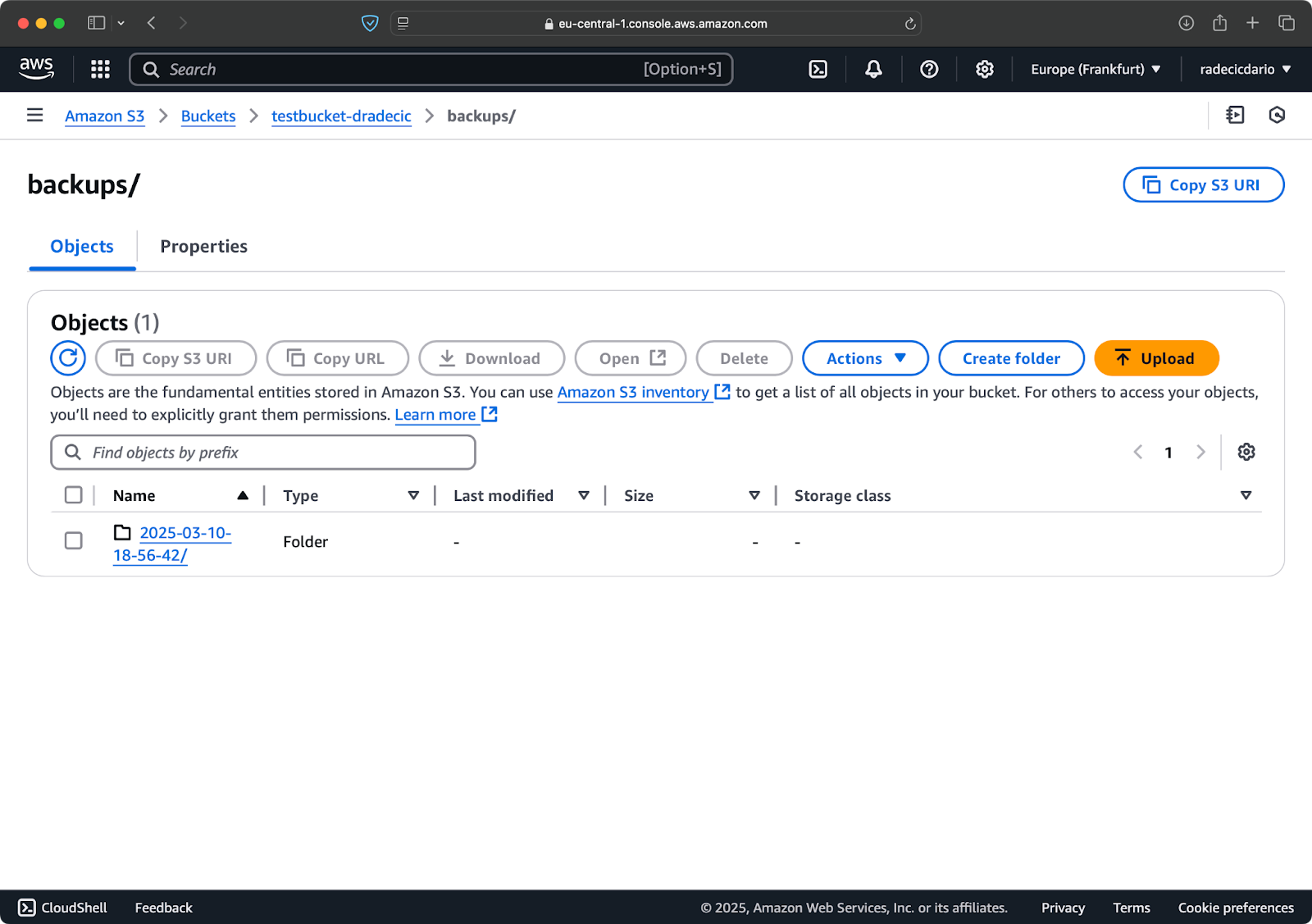
Afbeelding 18 – Tijdsgebonden back-ups
Voor kritieke gegevens wilt u mogelijk meerdere back-upversies bewaren. Dit is eenvoudig te doen door regelmatig een op tijdstempel gebaseerde back-up uit te voeren.
U kunt ook de optie --opslagklasse gebruiken om een meer kosteneffectieve opslagklasse te specificeren voor uw back-ups:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backups/$TIMESTAMP --storage-class STANDARD_IA
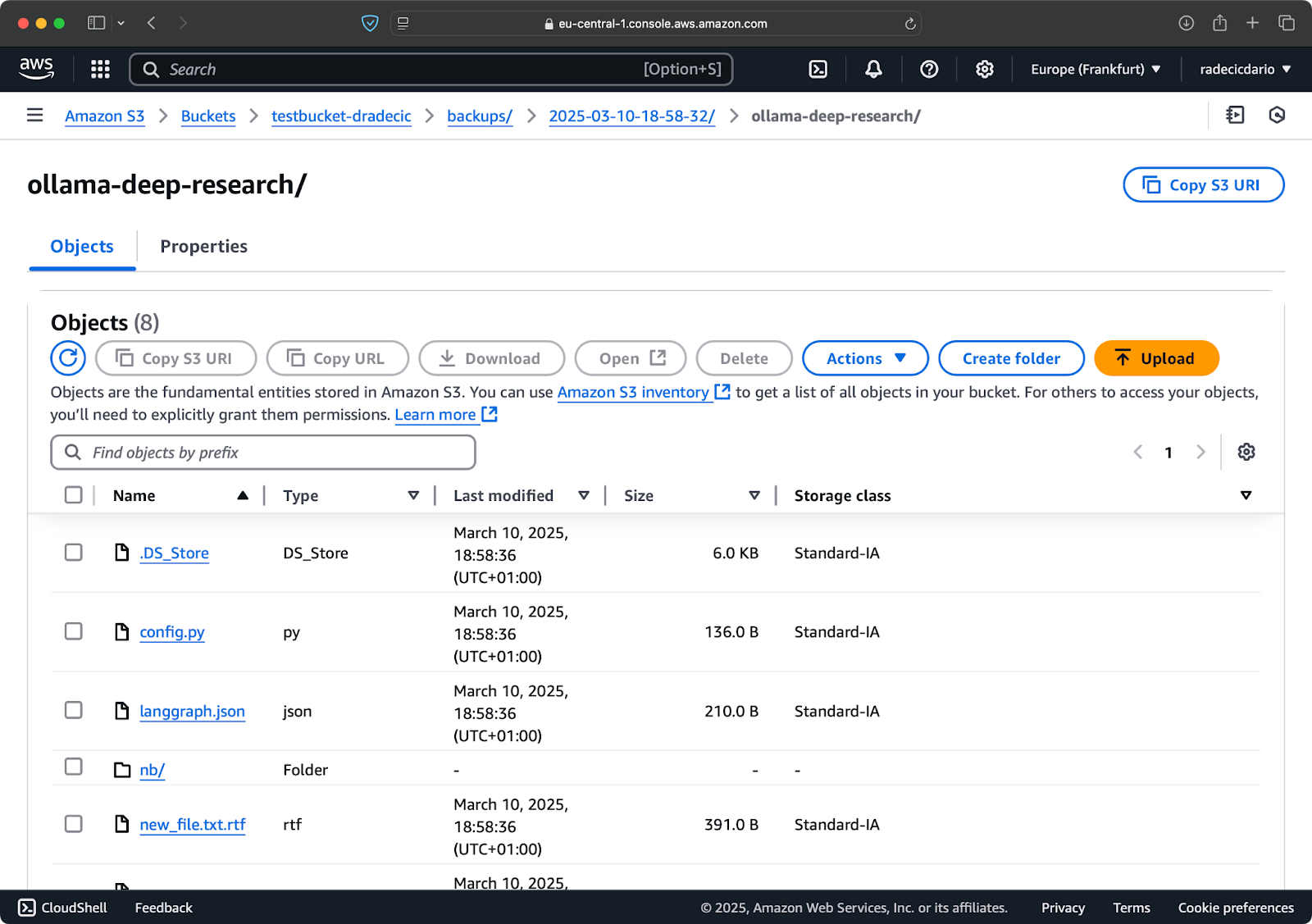
Afbeelding 19 – Back-upinhoud met een aangepaste opslagklasse
Dit maakt gebruik van de S3 Infrequent Access-opslagklasse, die minder kost maar een lichte ophaalvergoeding heeft. Voor langetermijnarchivering kun je zelfs de Glacier-opslagklasse gebruiken:
aws s3 sync /Users/dradecic/Documents/important-data s3://testbucket-dradecic/backups/$TIMESTAMP --storage-class GLACIER
Houd er wel rekening mee dat bestanden die zijn opgeslagen in Glacier uren nodig hebben om op te halen, dus ze zijn niet geschikt voor gegevens die je snel nodig zou kunnen hebben.
Het herstellen van bestanden vanuit S3
Het herstellen van een back-up is net zo eenvoudig – je hoeft alleen de bron en bestemming om te draaien in je synchronisatiecommando:
# Herstel van de meest recente back-up (ervan uitgaande dat je de tijdstempel weet) aws s3 sync s3://testbucket-dradecic/backups/2025-03-10-18-56-42 /Users/dradecic/Documents/restored-data
Dit zal alle bestanden van die specifieke back-up downloaden naar uw lokale herstelde-gegevens map:
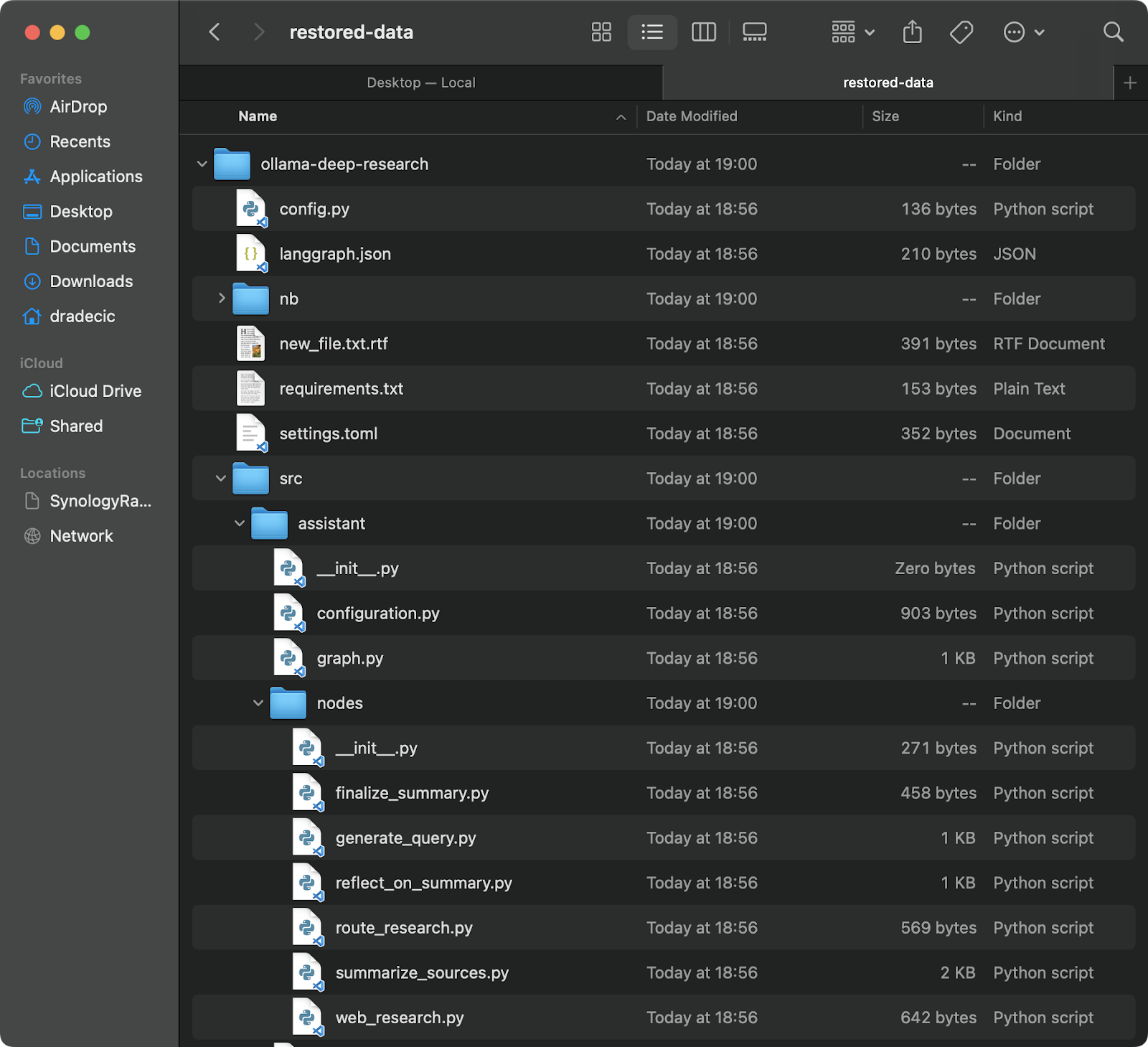
Afbeelding 20 – Bestanden herstellen vanuit S3
Als u het exacte tijdstip niet meer weet, kunt u eerst al uw back-ups weergeven:
aws s3 ls s3://testbucket-dradecic/backups/
Wat u iets soortgelijks zal tonen:
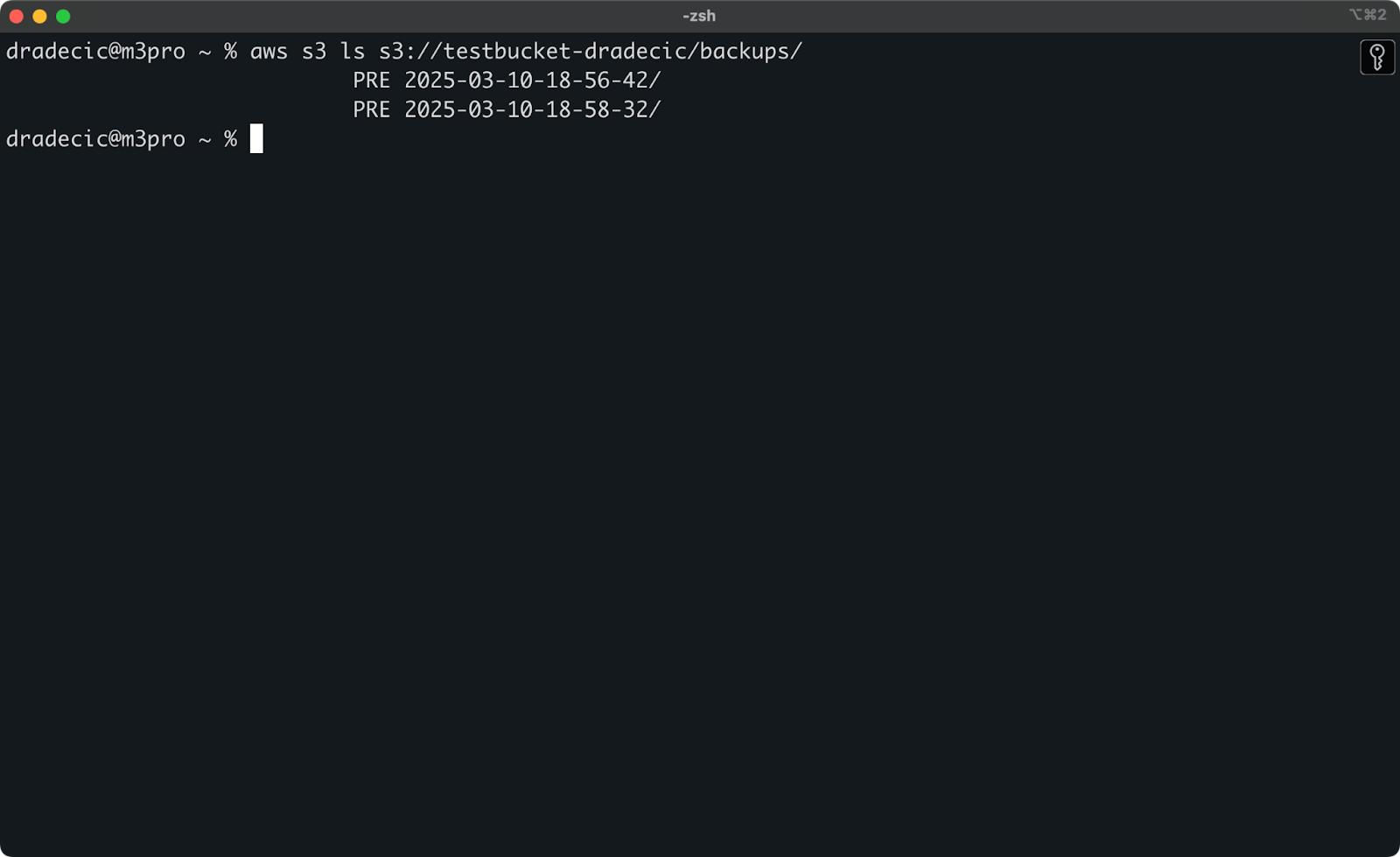
Afbeelding 21 – Lijst met back-ups
U kunt ook specifieke bestanden of mappen herstellen vanuit een back-up met behulp van de uitsluitings-/inclusie-vlaggen die we eerder hebben besproken:
# Herstel alleen de configuratiebestanden aws s3 sync s3://testbucket-dradecic/backups/2025-03-10-18-56-42 /Users/dradecic/Documents/restored-configs --exclude "*" --include "*.config" --include "*.toml" --include "*.yaml"
Voor mission-critical systemen raad ik aan om uw back-ups te automatiseren met geplande taken (zoals cron jobs op Linux/macOS of Taakplanner op Windows). Hiermee zorgt u ervoor dat u consequent een back-up maakt van uw gegevens zonder dat u eraan hoeft te denken om dit handmatig te doen.
Problemen oplossen met AWS S3 Sync
AWS S3 Sync is een betrouwbare tool, maar u kunt af en toe problemen tegenkomen. De meeste fouten die u zult zien, zijn echter menselijke fouten.
Veelvoorkomende synchronisatiefouten
Laten we enkele veelvoorkomende problemen doornemen en hun oplossingen.
- Foutmelding toegang geweigerd betekent meestal dat uw IAM-gebruiker niet over de vereiste rechten beschikt om toegang te krijgen tot de S3-bucket of specifieke bewerkingen uit te voeren. Probeer een van de volgende oplossingen:
- Controleer of uw IAM-gebruiker de juiste S3-machtigingen heeft (
s3:ListBucket,s3:GetObject,s3:PutObject). - Controleer of het bucketbeleid uw gebruiker geen toegang ontzegt.
- Zorg ervoor dat de bucket zelf geen openbare toegang blokkeert als u openbare bewerkingen nodig heeft.
- Geen dergelijk bestand of directory fout verschijnt meestal wanneer het bronpad dat u in het synchronisatiecommando hebt opgegeven niet bestaat. De oplossing is eenvoudig – controleer uw paden en zorg ervoor dat ze bestaan. Let speciaal op typfouten in bucketnamen of lokale directories.
- Bestandsgrootte limiet fouten kunnen optreden wanneer u grote bestanden wilt synchroniseren. Standaard kan S3-synchronisatie bestanden tot 5 GB verwerken. Voor grotere bestanden zult u time-outs of onvolledige overdrachten zien.
- Voor bestanden groter dan 5 GB moet u de vlag
--only-show-errorsgebruiken in combinatie met de vlag--size-only. Deze combinatie helpt bij grote bestandsoverdrachten door de output te minimaliseren en alleen bestandsgroottes te vergelijken:
aws s3 sync /Users/dradecic/large-files s3://testbucket-dradecic/large-files --only-show-errors --size-only
Optimalisatie van synchronisatieprestaties
Als uw S3-synchronisatie trager verloopt dan verwacht, zijn er enkele aanpassingen die u kunt doen om dingen te versnellen.
- Gebruik parallelle overdrachten. Standaard maakt S3-sync gebruik van een beperkt aantal parallelle bewerkingen. U kunt dit verhogen met de parameter
--max-concurrent-requests:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup --max-concurrent-requests 20
- Pas de chunkgrootte aan. Voor grote bestanden kunt u de overdrachtssnelheid optimaliseren door de chunkgrootte aan te passen. Dit verdeelt grote bestanden in 16 MB-chunks in plaats van de standaard 8 MB, wat sneller kan zijn voor goede netwerkverbindingen:
aws s3 sync /Users/dradecic/large-files s3://testbucket-dradecic/backup --cli-read-timeout 120 --multipart-threshold 64MB --multipart-chunksize 16MB
- Gebruik
--geen-voortgangvoor scripts. Als u S3-sync uitvoert in een geautomatiseerd script, gebruik dan de vlag--geen-voortgangom de uitvoer te verminderen en de prestaties te verbeteren:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup --no-progress
- Gebruik lokale eindpunten. Als uw AWS-resources zich in dezelfde regio bevinden, kan het specificeren van het regionale eindpunt de latentie verminderen:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup --endpoint-url https://s3.eu-central-1.amazonaws.com
Deze optimalisaties kunnen de synchronisatieprestaties aanzienlijk verbeteren, vooral bij grote gegevensoverdrachten of bij gebruik op minder krachtige machines.
Als u nog steeds problemen ondervindt na het proberen van deze oplossingen, heeft de AWS CLI een ingebouwde debugoptie. Voeg eenvoudig --debug toe aan uw opdracht om gedetailleerde informatie te zien over wat er gebeurt tijdens het synchronisatieproces:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup --debug
Verwacht veel gedetailleerde logboekberichten te zien, vergelijkbaar met deze:
Afbeelding 22 – Uitvoeren van synchronisatie in debugmodus
En dat is zo’n beetje alles als het gaat om het oplossen van problemen met AWS S3 sync. Natuurlijk zijn er andere fouten die kunnen optreden, maar 99% van de tijd vind je de oplossing in deze sectie.
Samenvatting van AWS S3 Sync
Samenvattend is AWS S3 sync een van die zeldzame tools die zowel eenvoudig te gebruiken als ongelooflijk krachtig zijn. Je hebt alles geleerd, van basiscommando’s tot geavanceerde opties, back-upstrategieën en tips voor probleemoplossing.
Voor ontwikkelaars, systeembeheerders of iedereen die met AWS werkt, is het S3 sync-commando een essentieel hulpmiddel – het bespaart tijd, vermindert het bandgebruik en zorgt ervoor dat je bestanden zijn waar je ze nodig hebt, wanneer je ze nodig hebt.
Of je nu kritieke gegevens veiligstelt, webassets implementeert of gewoon verschillende omgevingen synchroon houdt, AWS S3 sync maakt het proces eenvoudig en betrouwbaar.
De beste manier om vertrouwd te raken met S3-synchronisatie is door het te gaan gebruiken. Probeer een eenvoudige synchronisatie-operatie op te zetten met je eigen bestanden en verken vervolgens geleidelijk de geavanceerde opties om aan je specifieke behoeften te voldoen.
Vergeet niet om altijd eerst --dryrun te gebruiken bij het werken met belangrijke gegevens, vooral bij het gebruik van de --delete vlag. Het is beter om een extra minuut te nemen om te controleren wat er zal gebeuren dan per ongeluk belangrijke bestanden te verwijderen.
Om meer te leren over AWS, bekijk deze cursussen van DataCamp:
- Introductie tot AWS
- AWS Cloud Technologie en Services
- AWS Beveiliging en Kostenbeheer
- Introductie tot AWS Boto in Python
Je kunt zelfs DataCamp gebruiken om je voor te bereiden op AWS-certificeringsexamens – AWS Cloud Practitioner (CLF-C02).