













Configurazione della CLI AWS e AWS S3
Prima di poter iniziare a sincronizzare i file con S3, dovrai impostare e configurare correttamente AWS CLI. Questo potrebbe sembrare intimidatorio se sei nuovo di AWS, ma ci vorranno solo un paio di minuti.
Configurare la CLI comporta due passaggi principali: installare lo strumento e configurarlo. Passerò ora ad entrambi i passaggi.
Installazione di AWS CLI
L’installazione di AWS CLI varia leggermente a seconda del sistema operativo in uso.
Per i sistemi Windows:
- Vai alla pagina di download dell’AWS CLI
- Scarica il programma di installazione per Windows (a 64 bit)
- Esegui il programma di installazione e segui le istruzioni
Per i sistemi Linux:
Esegui i seguenti tre comandi tramite il Terminale:
curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip" unzip awscliv2.zip sudo ./aws/install
Per i sistemi macOS:
Assumendo che tu abbia Homebrew installato, esegui questa riga da Terminale:
brew install awscli
Se non hai Homebrew, utilizza invece questi due comandi:
curl "https://awscli.amazonaws.com/AWSCLIV2.pkg" -o "AWSCLIV2.pkg" sudo installer -pkg AWSCLIV2.pkg -target /
Puoi eseguire il comando aws --version su tutti i sistemi operativi per verificare che AWS CLI sia stato installato. Ecco cosa dovresti vedere:
Immagine 1 – Versione AWS CLI
Configurazione AWS CLI
Ora che hai installato la CLI, devi configurarla con le tue credenziali AWS.
Assumendo che tu abbia già un account AWS, accedi e vai al servizio IAM. Una volta lì, crea un nuovo utente con accesso programmato. Dovresti assegnare le autorizzazioni appropriate all’utente, che è l’accesso a S3 come minimo:
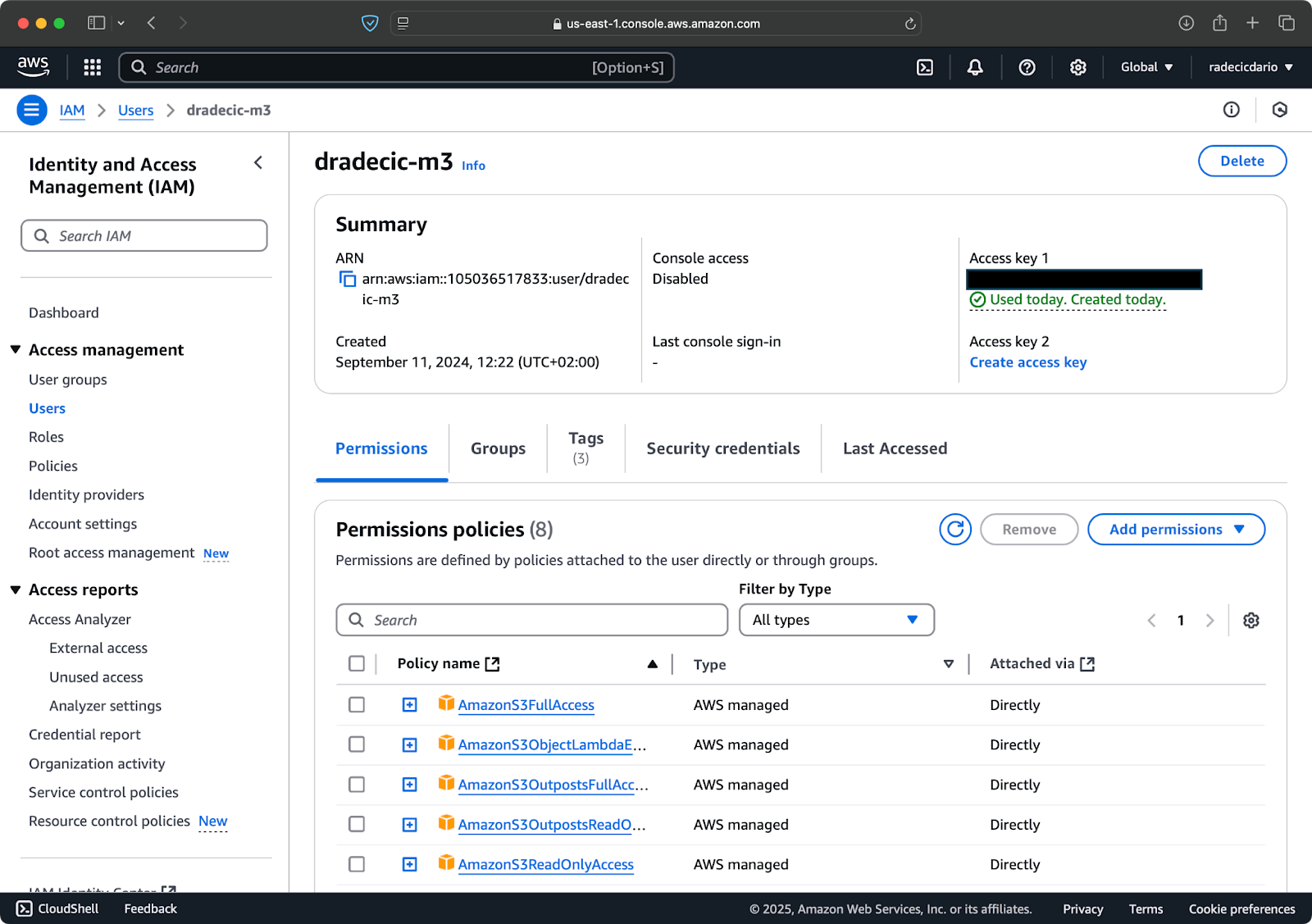
Immagine 2 – Utente AWS IAM
Una volta completato, vai su “Credenziali di sicurezza” per creare una nuova chiave di accesso. Dopo averla creata, avrai sia il ID chiave di accesso che il Chiave di accesso segreta. Annotali in un posto sicuro perché non potrai accedervi in futuro:
Immagine 3 – Credenziali utente AWS IAM
Tornando nel Terminale, eseguire il comando aws configure. Ti verrà chiesto di inserire la tua chiave di accesso ID, la chiave di accesso segreta, la regione (eu-central-1 nel mio caso) e il formato di output preferito (json):
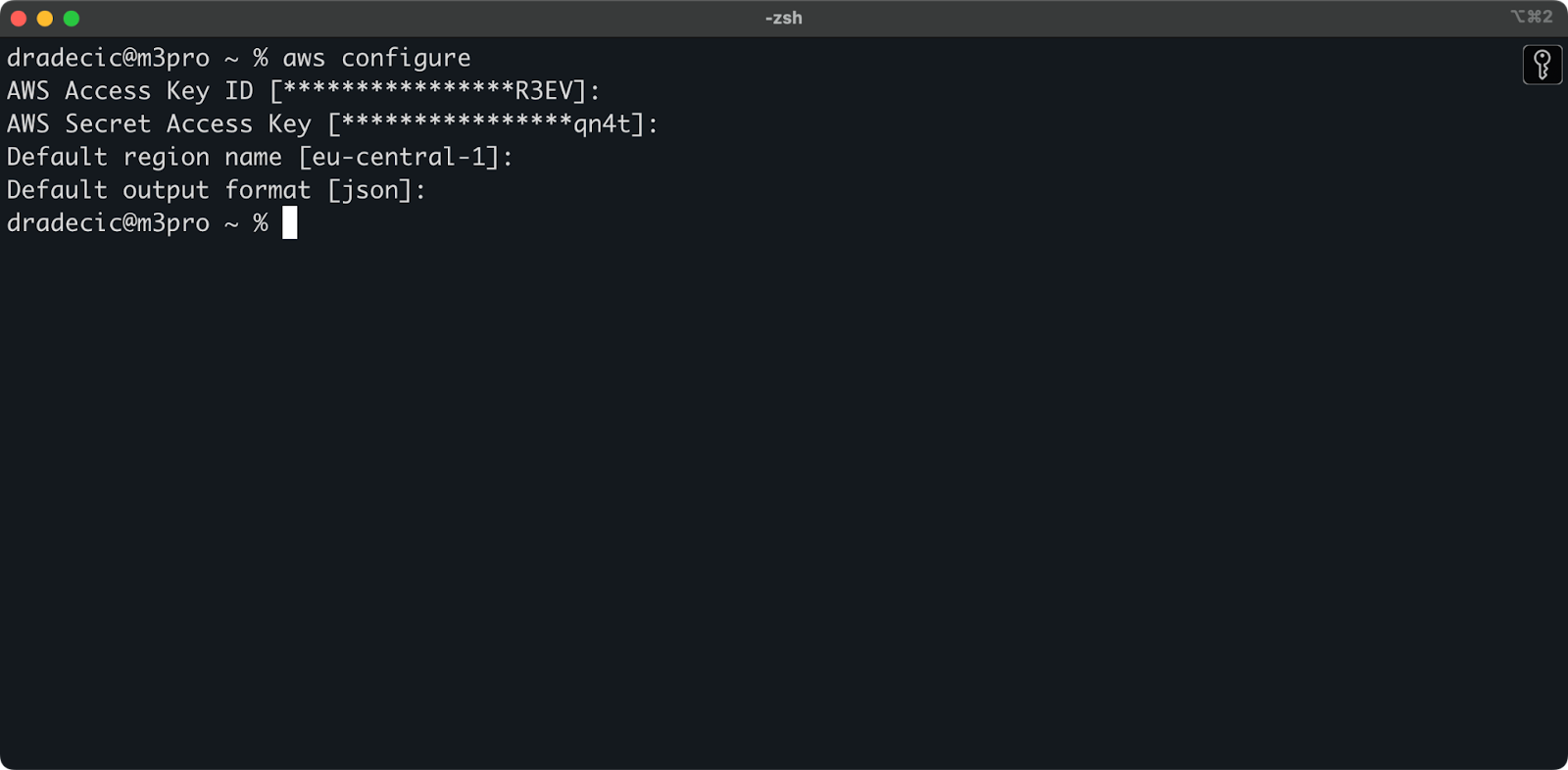
Immagine 4 – Configurazione AWS CLI
Per verificare di essere collegato con successo al tuo account AWS dalla CLI, eseguire il seguente comando:
aws sts get-caller-identity
Questa è l’output che dovresti vedere:
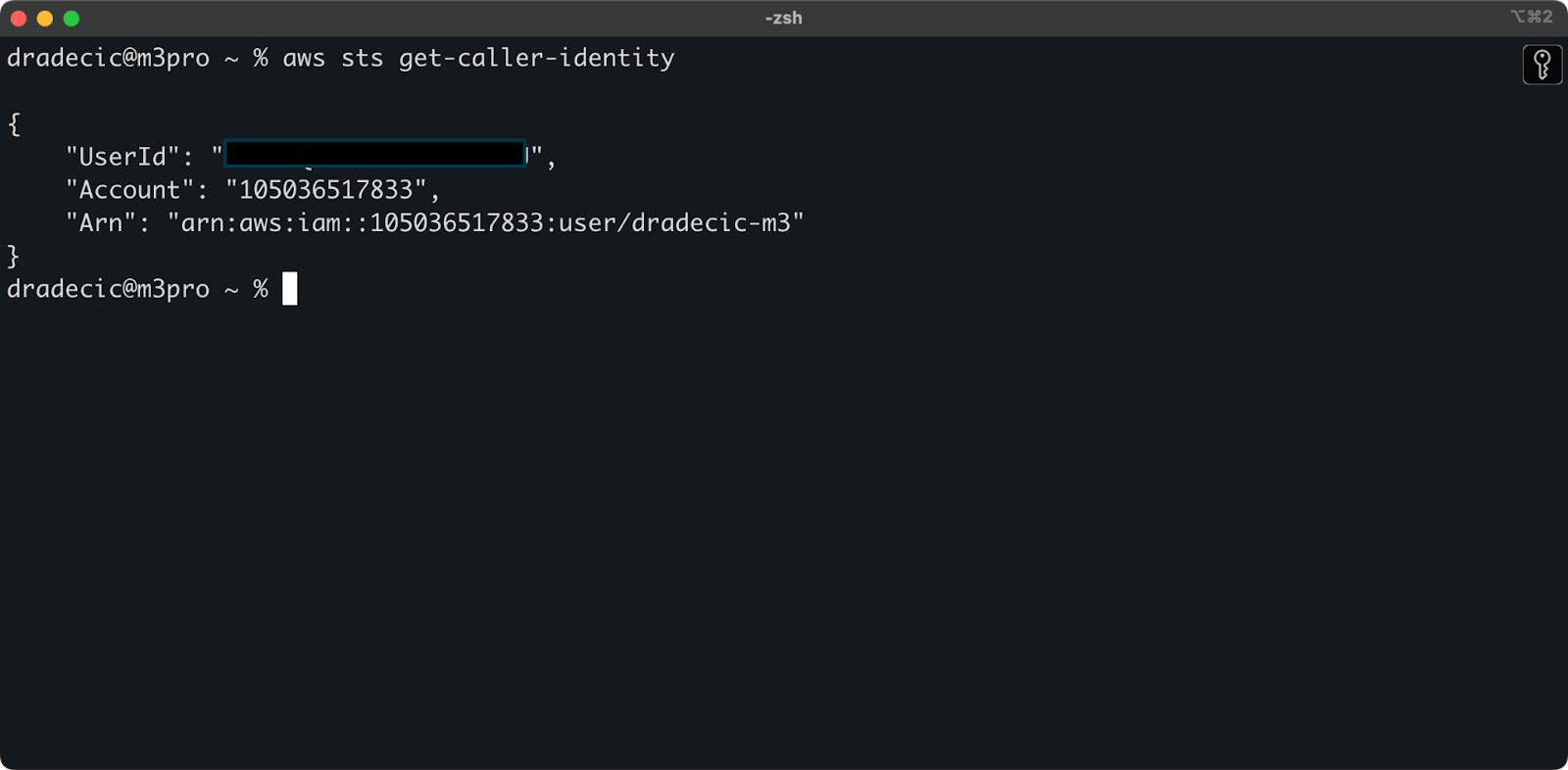
Immagine 5 – Comando di test di connessione AWS CLI
E questo è tutto – solo un altro passaggio prima di poter iniziare ad utilizzare il comando di sincronizzazione S3!
Configurazione di un bucket AWS S3
Il passo finale è creare un bucket S3 che conterrà i file sincronizzati. Puoi farlo da CLI o dalla Console di Gestione di AWS. Opterò per quest’ultima, giusto per cambiare un po’.
Per iniziare, vai alla pagina del servizio S3 nella Console di Gestione e clicca sul pulsante “Crea bucket”. Una volta lì, scegli un nome univoco per il bucket (unico a livello globale in tutto AWS) e poi scorri fino in fondo e clicca sul pulsante “Crea”:
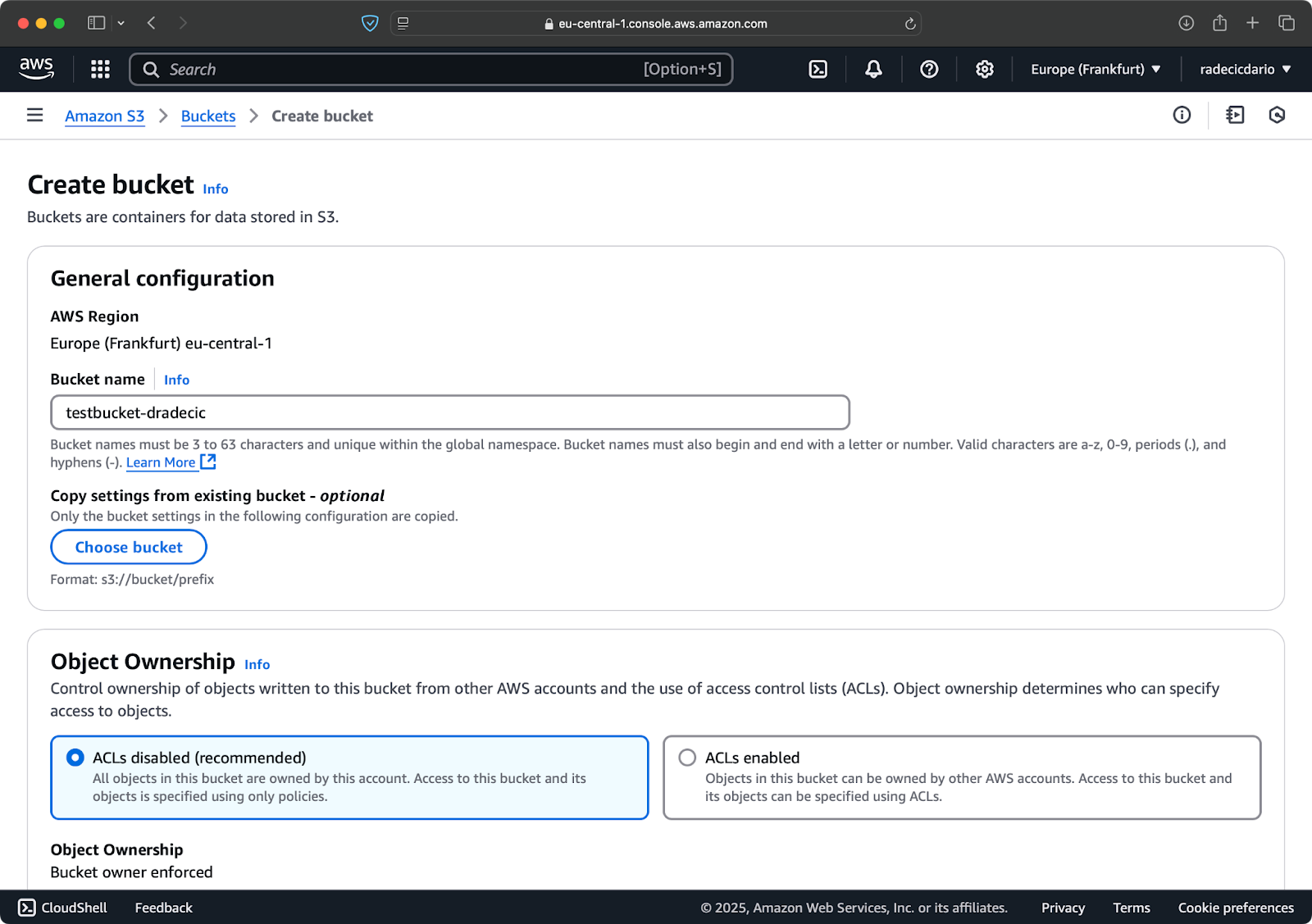
Immagine 6 – Creazione del bucket AWS
Il bucket è stato creato e lo vedrai immediatamente nella console di gestione. Puoi anche verificarne la creazione tramite CLI:
aws s3 ls
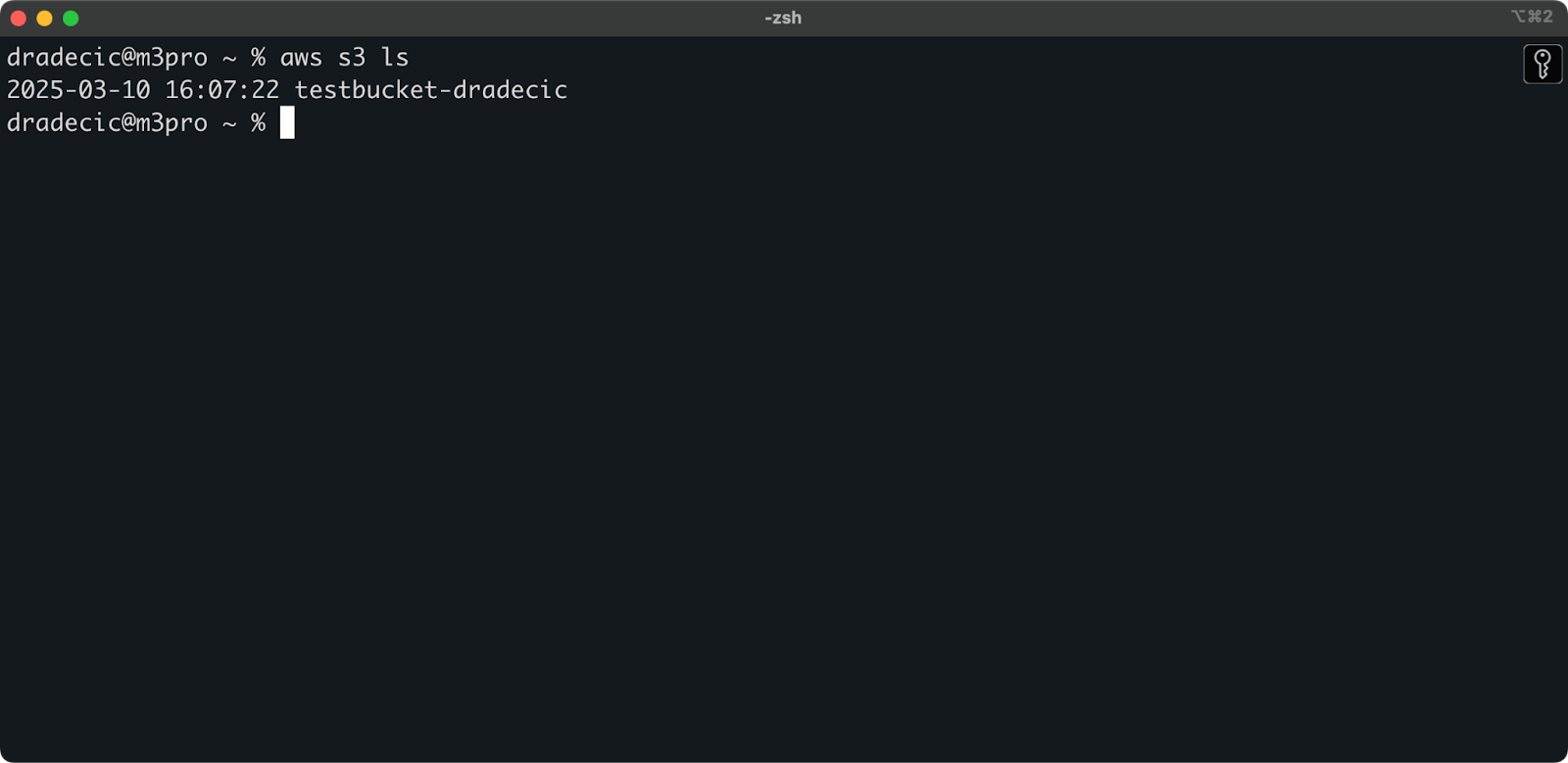
Immagine 7 – Tutti i bucket S3 disponibili
Tieni presente che i bucket S3 sono privati di default. Se prevedi di utilizzare il bucket per ospitare file pubblici (come asset del sito web), dovrai regolare le policy e le autorizzazioni del bucket di conseguenza.
Ora sei pronto e pronto a iniziare a sincronizzare i file tra il tuo computer locale e AWS S3!
Comando di base di sincronizzazione AWS S3
Ora che hai installato e configurato AWS CLI e hai un bucket S3 pronto all’uso, è il momento di iniziare la sincronizzazione! La sintassi di base del comando di sincronizzazione AWS S3 è piuttosto semplice. Ti mostrerò come funziona.
Il comando di sincronizzazione S3 segue questo semplice schema:
aws s3 sync <source> <destination> [options]
Sia la sorgente che la destinazione possono essere sia un percorso di directory locale che un URI S3 (che inizia con s3://). A seconda di quale tipo di sincronizzazione desideri eseguire, disporrai queste informazioni in modo diverso.
Sincronizzazione dei file da locale a un bucket S3
Recentemente stavo sperimentando con la ricerca approfondita di Ollama. Diciamo che quella è la cartella che voglio sincronizzare su S3. La directory principale si trova sotto la cartella Documenti. Ecco com’è strutturata:
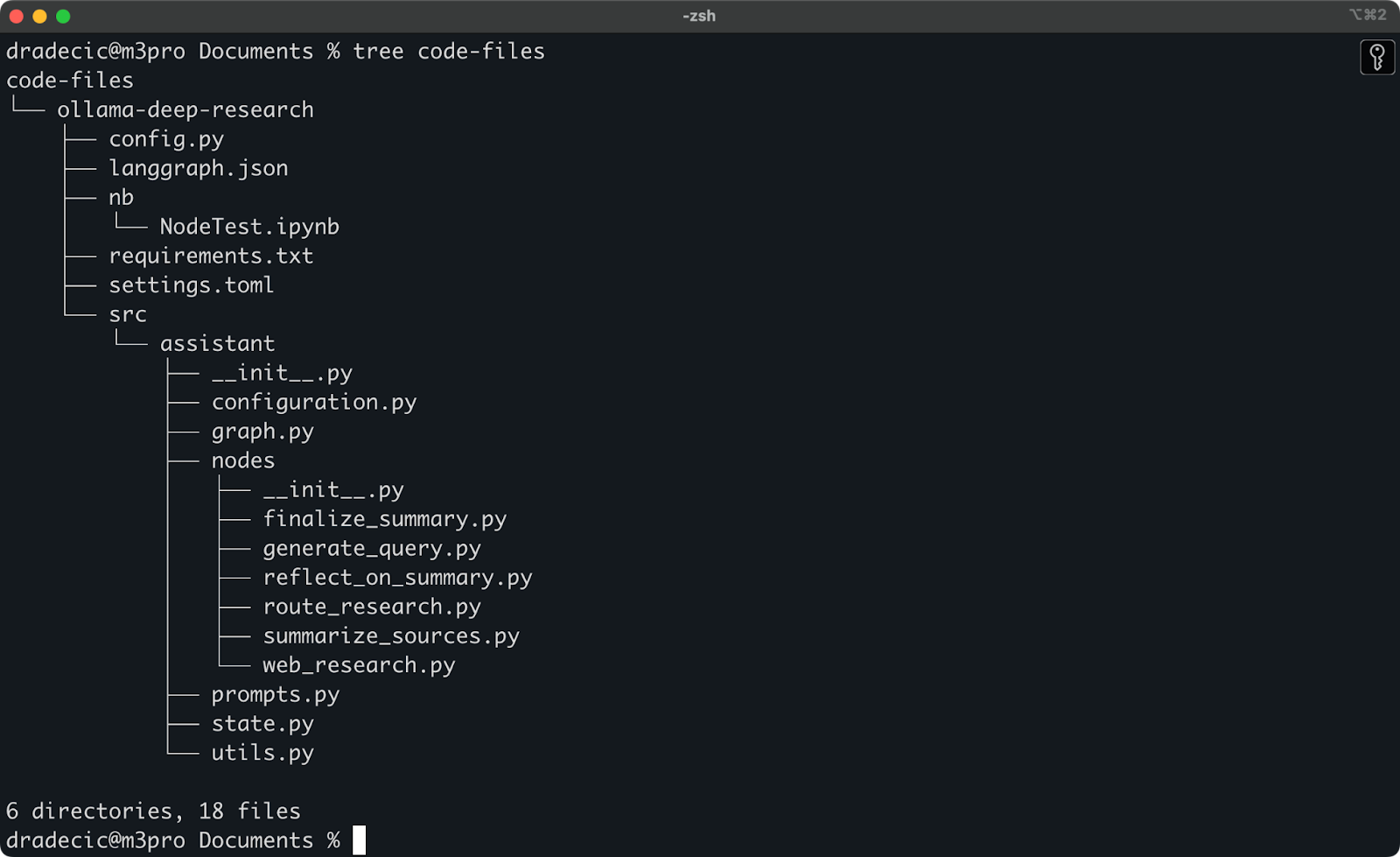
Contenuto della cartella locale
Questo è il comando che devo eseguire per sincronizzare la cartella locale code-files con la cartella backup nel bucket S3:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup
La cartella backup nel bucket S3 verrà creata automaticamente se non esiste.
Ecco cosa vedrai stampato sulla console:
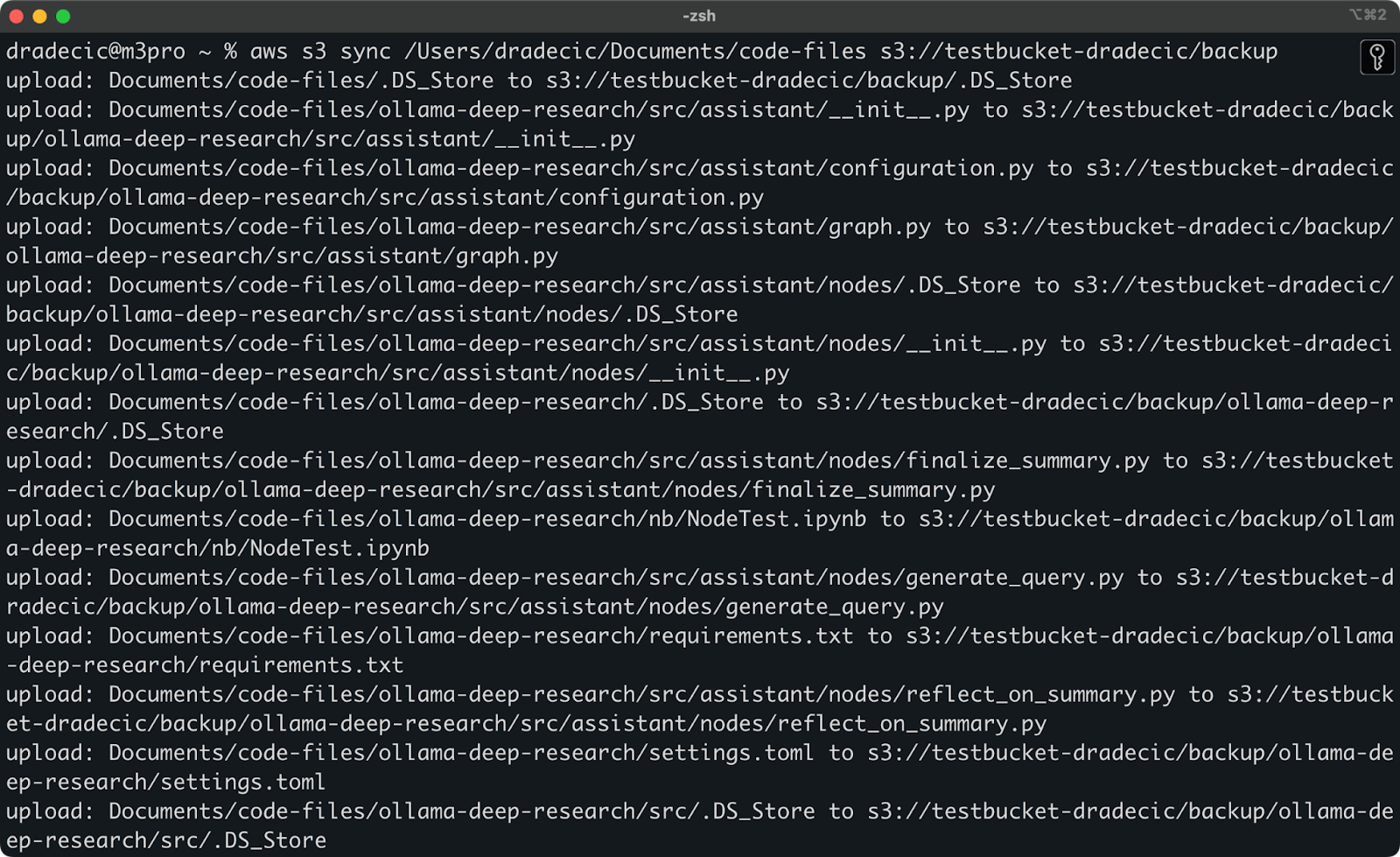
Immagine 9 – processo di sincronizzazione S3
Dopo un paio di secondi, i contenuti della cartella locale code-files sono disponibili nel bucket S3:
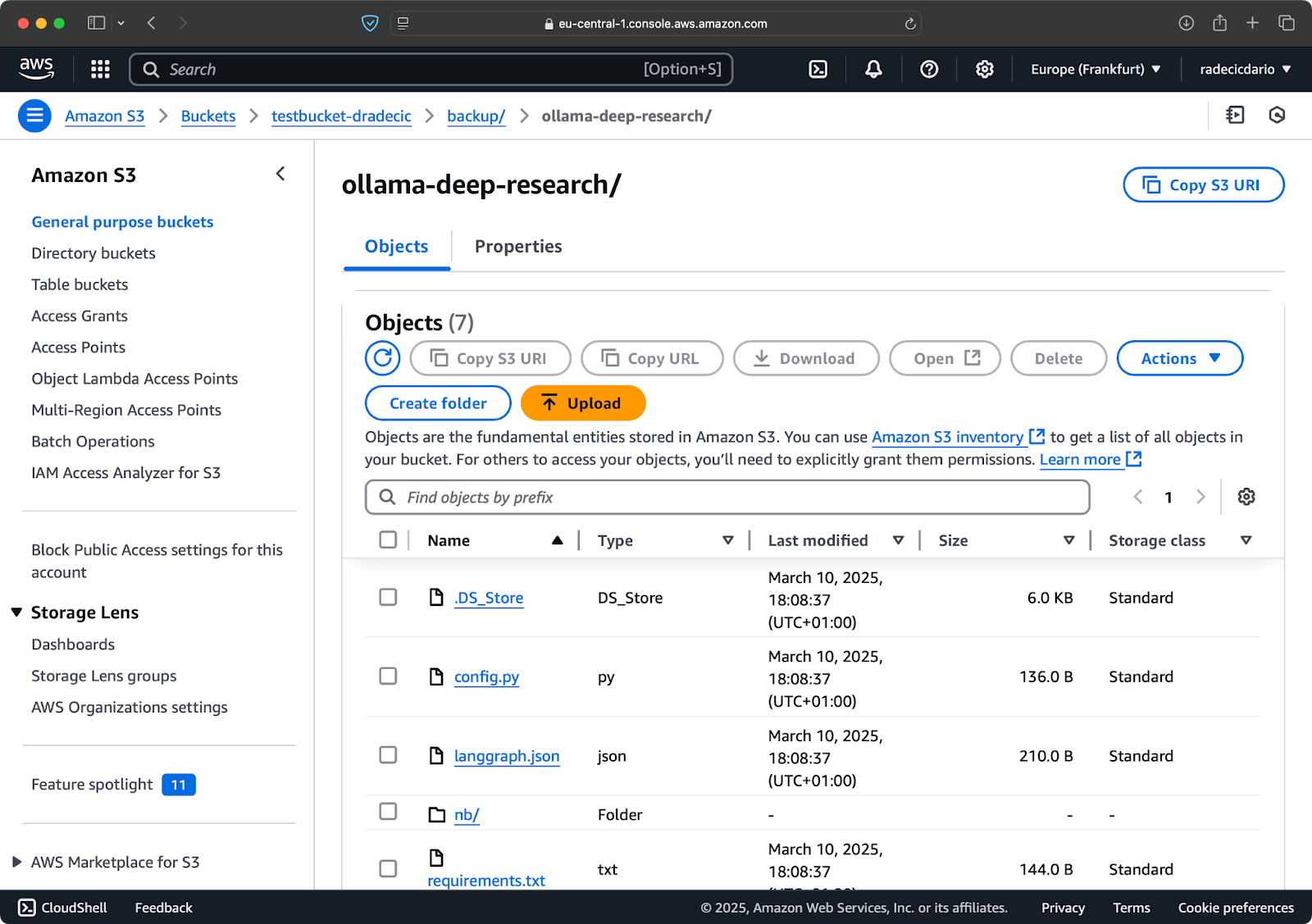
Immagine 10 – contenuti del bucket S3
Il bello della sincronizzazione di S3 è che carica solo i file che non esistono nella destinazione o che sono stati modificati localmente. Se esegui nuovamente lo stesso comando senza cambiare nulla, non vedrai nulla! Questo perché AWS CLI ha rilevato che tutti i file sono già sincronizzati e aggiornati.
Adesso, apporterò due piccole modifiche – creerò un nuovo file (new_file.txt) e aggiornerò uno già esistente (requirements.txt). Quando eseguirai nuovamente il comando di sincronizzazione, verranno caricati solo i file nuovi o modificati:
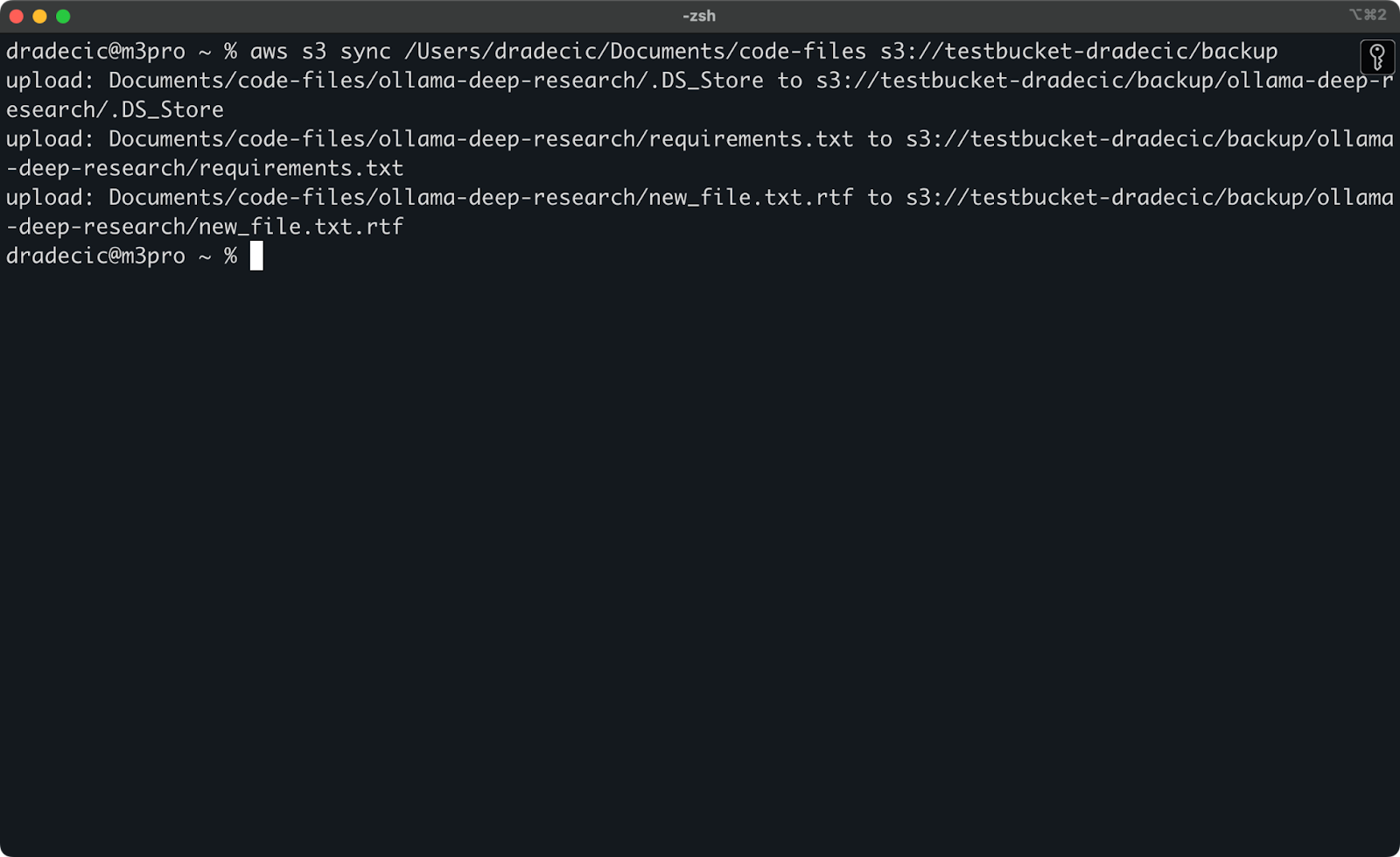
Immagine 11 – Processo di sincronizzazione di S3 (2)
E questo è tutto ciò che devi sapere quando sincronizzi cartelle locali su S3. Ma cosa fare se vuoi fare il contrario?
Sincronizzazione dei file dal bucket S3 a una directory locale
Se vuoi scaricare i file dal tuo bucket S3 al tuo computer locale, basta invertire la sorgente e la destinazione:
aws s3 sync s3://testbucket-dradecic/backup /Users/dradecic/Documents/code-files-from-s3
Questo comando scaricherà tutti i file dalla cartella backup nel tuo bucket S3 in una cartella locale chiamata code-files-from-s3 . Di nuovo, se la cartella locale non esiste, la CLI la creerà per te:
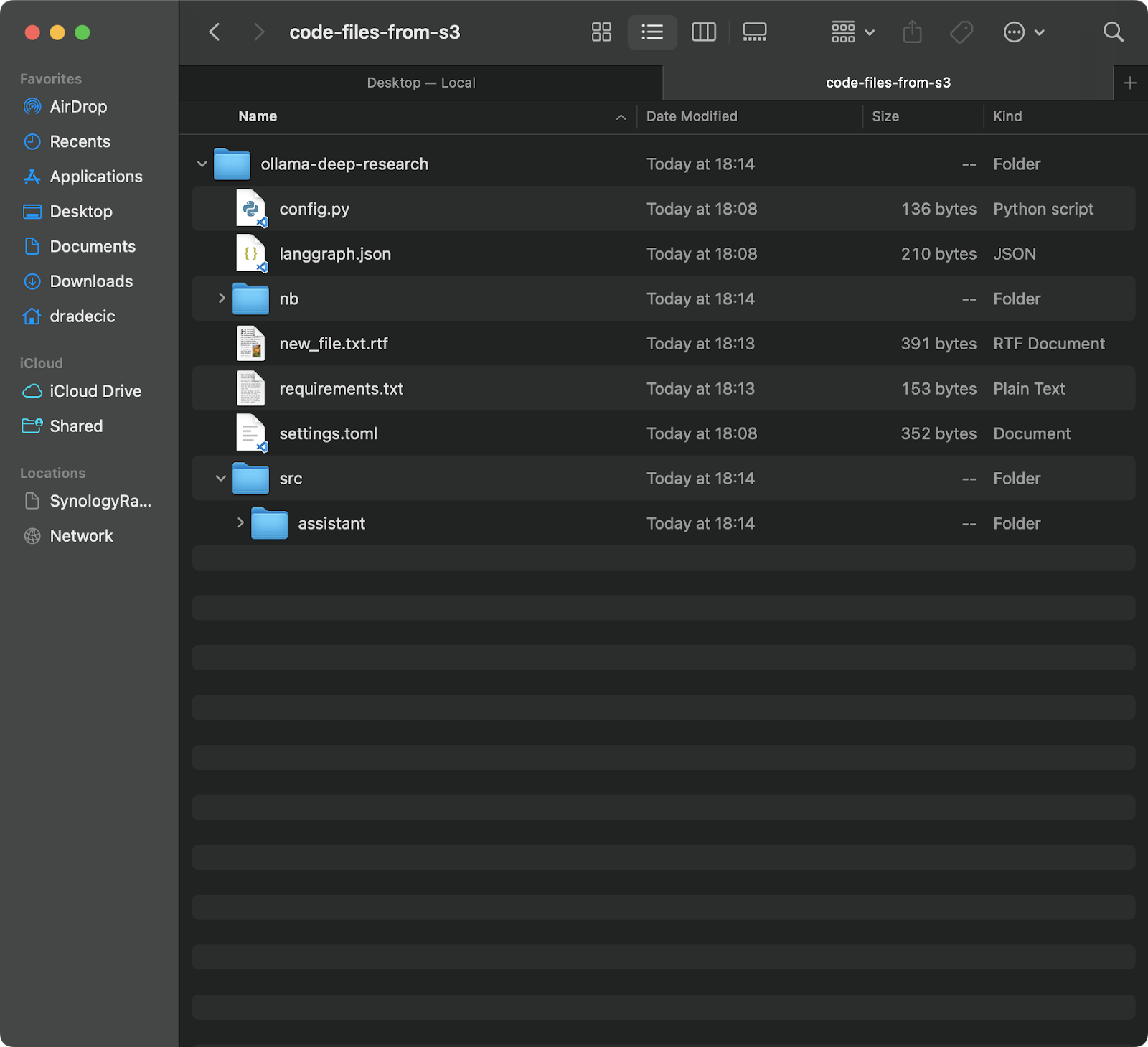
Immagine 12 – S3 per sincronizzazione locale
Vale la pena notare che la sincronizzazione di S3 non è bidirezionale. Va sempre dal origine alla destinazione, facendo corrispondere la destinazione all’origine. Se elimini un file in locale e poi lo sincronizzi su S3, esso esisterà comunque su S3. Allo stesso modo, se elimini un file in S3 e sincronizzi da S3 in locale, il file locale rimarrà intatto.
Se desideri fare in modo che la destinazione corrisponda esattamente all’origine (inclusi gli elementi eliminati), dovrai utilizzare il flag --delete, di cui parlerò nella sezione delle opzioni avanzate.
Opzioni avanzate di sincronizzazione di AWS S3
Il comando di base di sincronizzazione di S3 esplorato in precedenza è potente di per sé, ma AWS lo ha arricchito con opzioni aggiuntive che ti danno maggiore controllo sul processo di sincronizzazione.
In questa sezione, ti mostrerò alcune delle bandiere più utili che puoi aggiungere al comando di base.
Sincronizzazione solo dei file nuovi o modificati
Per impostazione predefinita, la sincronizzazione S3 utilizza un meccanismo di confronto di base che controlla la dimensione del file e il tempo di modifica per determinare se un file deve essere sincronizzato. Tuttavia, questo approccio potrebbe non catturare sempre tutti i cambiamenti, specialmente quando si tratta di file che sono stati modificati ma rimangono della stessa dimensione.
Per una sincronizzazione più precisa, puoi utilizzare la bandiera --exact-timestamps:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup --exact-timestamps
Questo forza la sincronizzazione di S3 a confrontare i timestamp con una precisione fino ai millisecondi. Tieni presente che l’utilizzo di questa flag potrebbe raffrenare leggermente il processo di sincronizzazione poiché richiede confronti più dettagliati.
Escludere o includere file specifici
A volte, non si desidera sincronizzare ogni file in una directory. Forse si desidera escludere file temporanei, file di registro o determinati tipi di file (come ad esempio .DS_Store nel mio caso). Ecco dove entrano in gioco le flag --exclude e --include.
Ma per fare un esempio, diciamo che voglio sincronizzare la mia directory di codice ma escludere tutti i file Python:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup --exclude "*.py"
Adesso molti meno file vengono sincronizzati su S3:
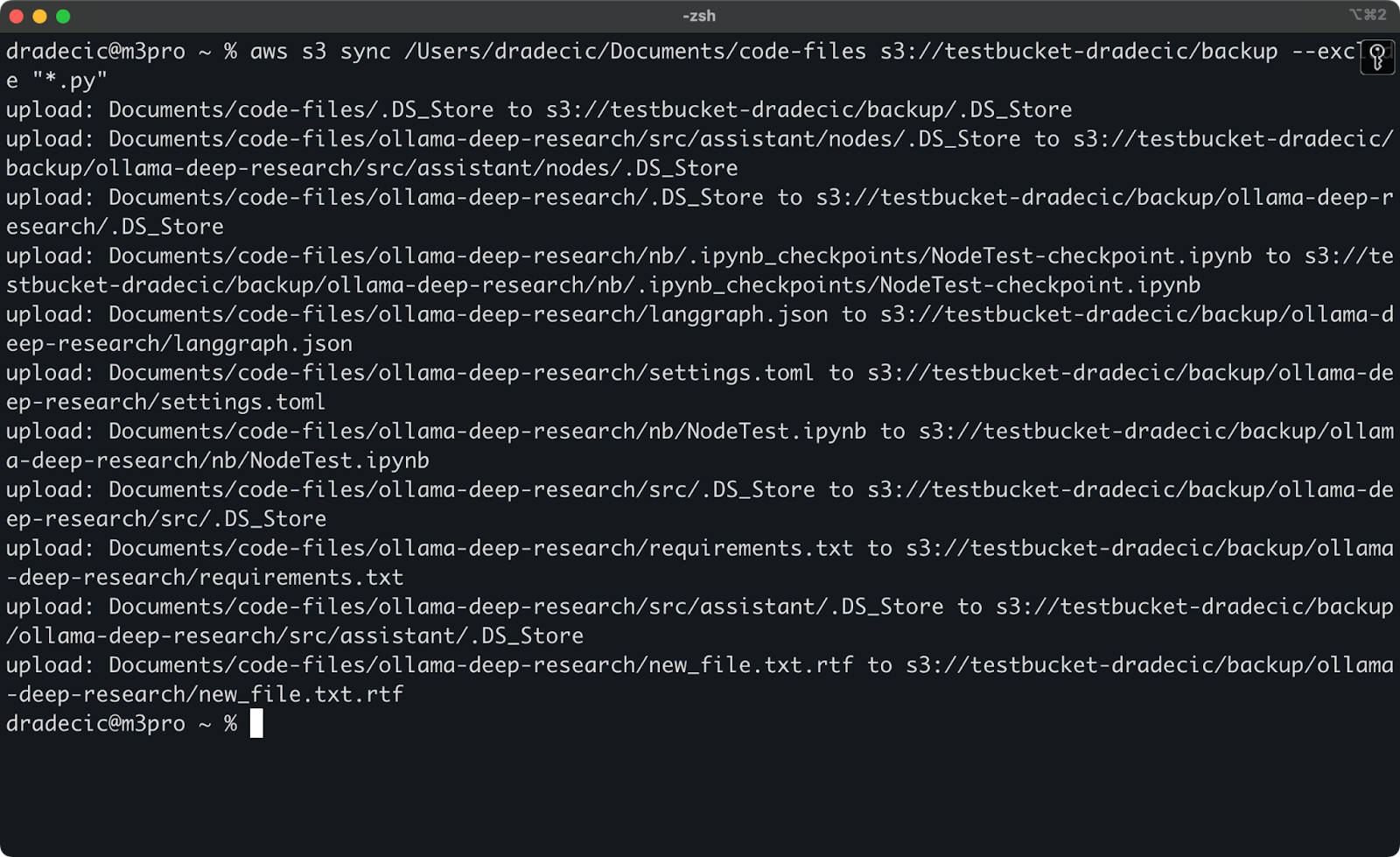
Immagine 13 – Sincronizzazione S3 con esclusione dei file Python
È anche possibile combinare --exclude e --include per creare pattern più complessi. Ad esempio, escludere tutto tranne i file Python:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup --exclude "*" --include "*.py"
I pattern vengono valutati nell’ordine specificato, quindi l’ordine è importante! Ecco cosa vedrai utilizzando questi flag:
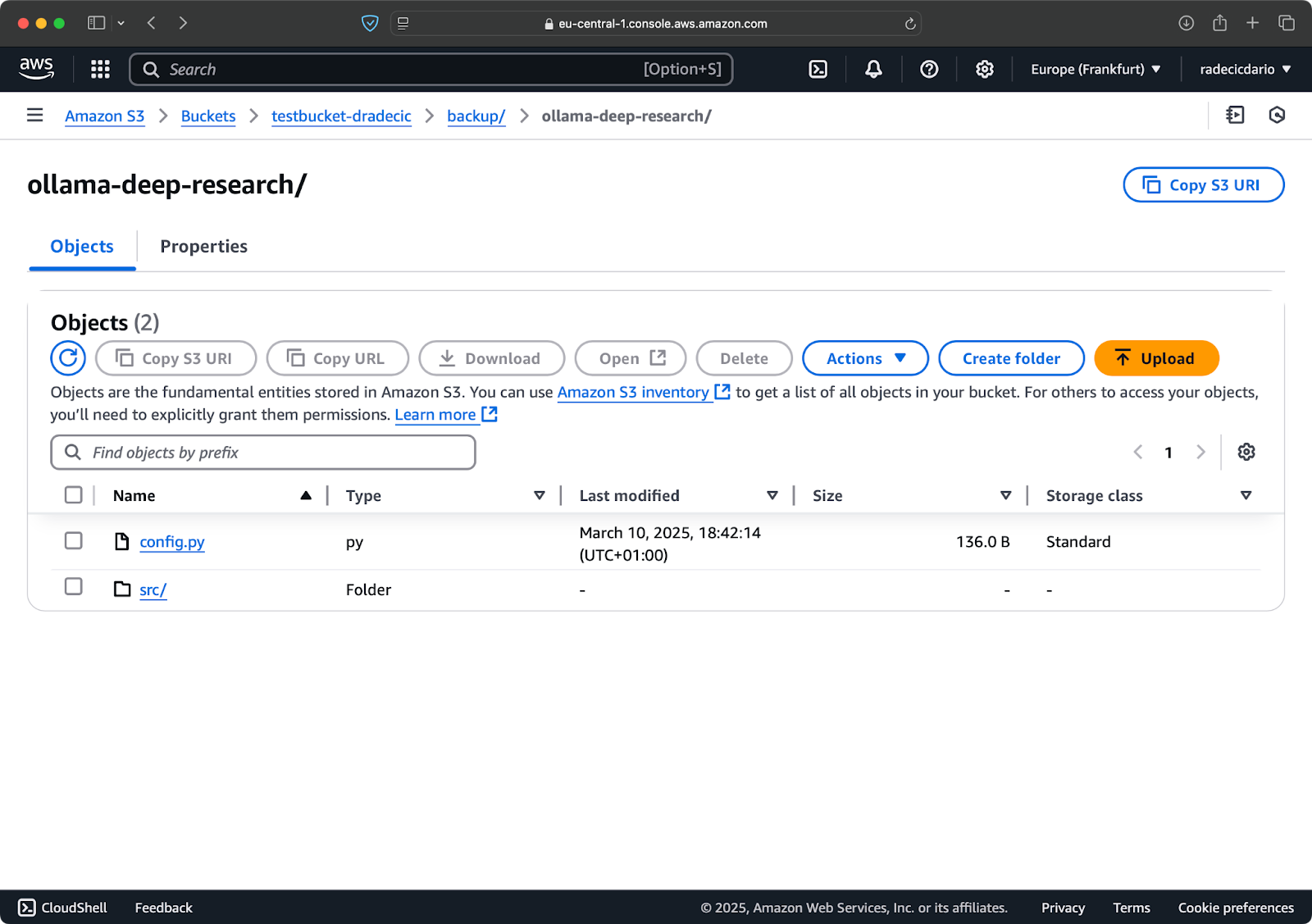
Immagine 14 – Flag di esclusione e inclusione
Adesso solo i file Python sono sincronizzati, e importanti file di configurazione sono mancanti.
Eliminazione file dalla destinazione
Per impostazione predefinita, la sincronizzazione di S3 aggiunge o aggiorna solo i file nella destinazione, non li elimina mai. Ciò significa che se elimini un file dalla sorgente, rimarrà comunque nella destinazione dopo la sincronizzazione.
Per fare in modo che la destinazione sia esattamente speculare alla sorgente, inclusi gli elementi eliminati, utilizza il flag --delete:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup --delete
Se esegui questo per la prima volta, tutti i file locali verranno sincronizzati su S3:
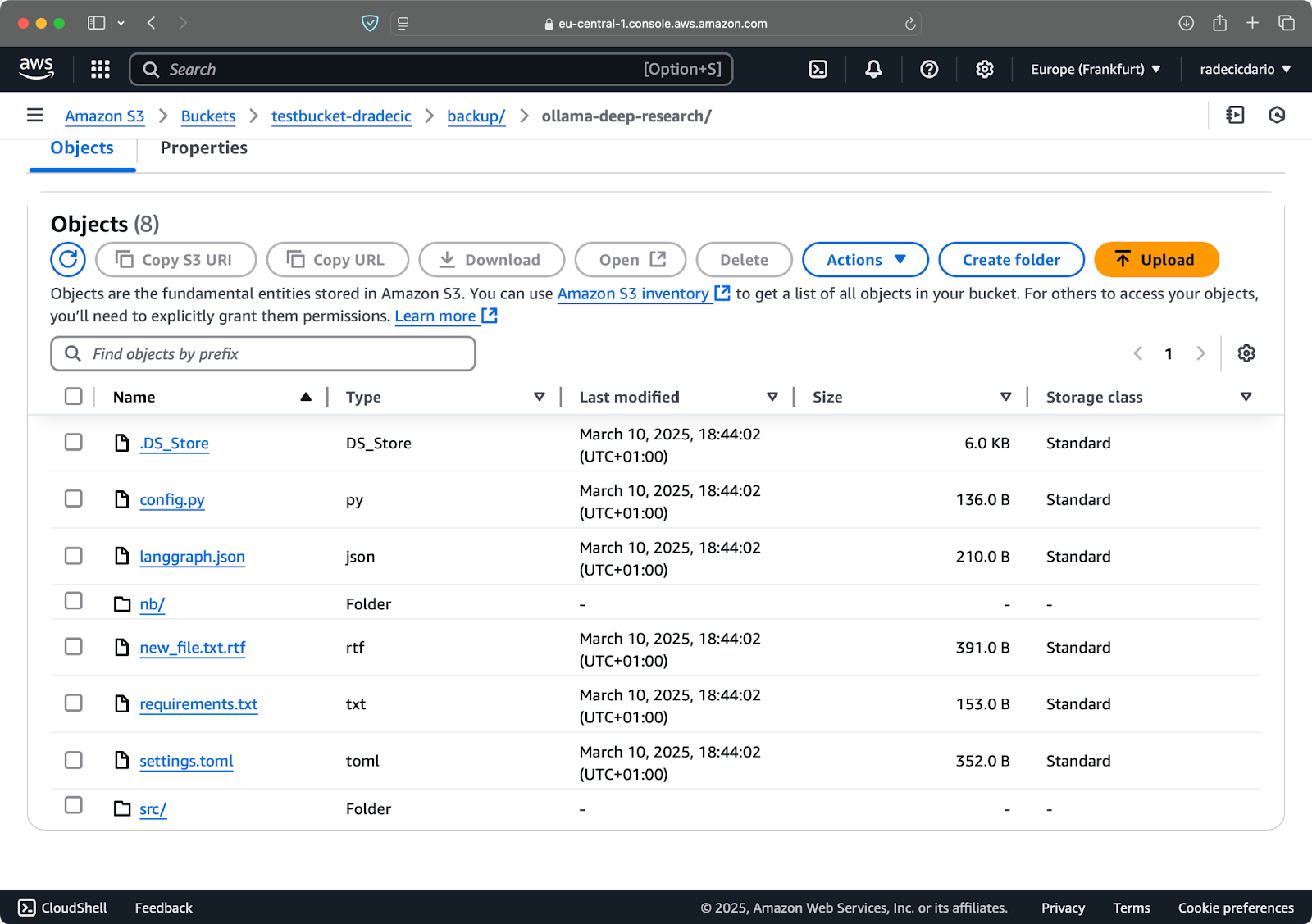
Immagine 15 – Flag Elimina
Questo è particolarmente utile per mantenere repliche esatte delle directory. Ma attenzione: questa opzione può portare alla perdita di dati se usata in modo errato.
Immagina di eliminare config.py dalla tua cartella locale e eseguire il comando di sincronizzazione con l’opzione --delete:
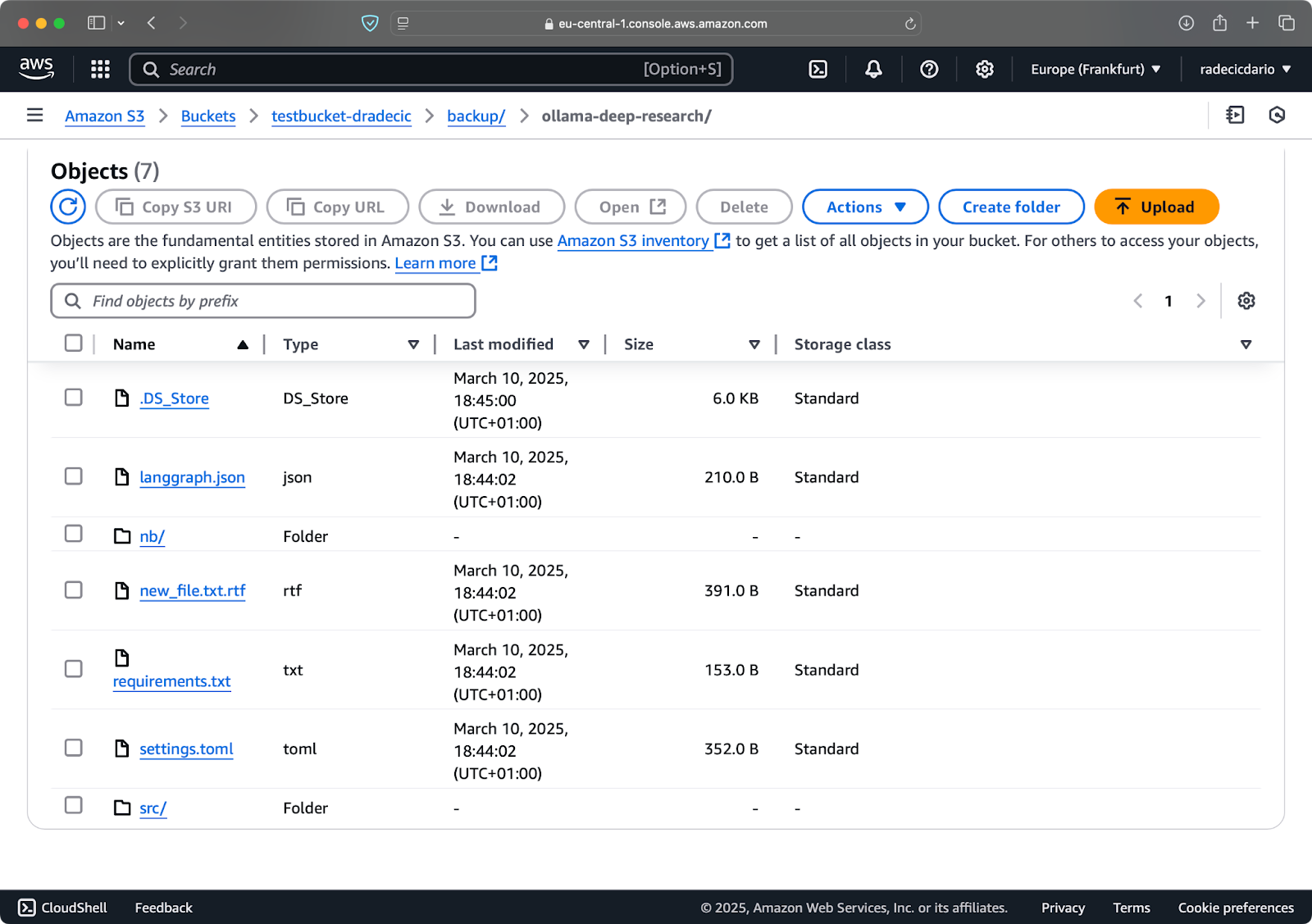
Immagine 16 – Opzione di eliminazione (2)
Come puoi vedere, il comando non solo sincronizza i file nuovi e modificati ma elimina anche i file dal bucket S3 che non esistono più nella directory locale.
Configurazione dell’esecuzione di prova per una sincronizzazione sicura
Le operazioni di sincronizzazione S3 più pericolose sono quelle che coinvolgono il flag --delete. Per evitare di eliminare accidentalmente file importanti, è possibile utilizzare il flag --dryrun per simulare l’operazione senza apportare effettivamente alcuna modifica:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup --delete --dryrun
Per dimostrare, ho eliminato i file requirements.txt e settings.toml da una cartella locale e poi ho eseguito il comando:
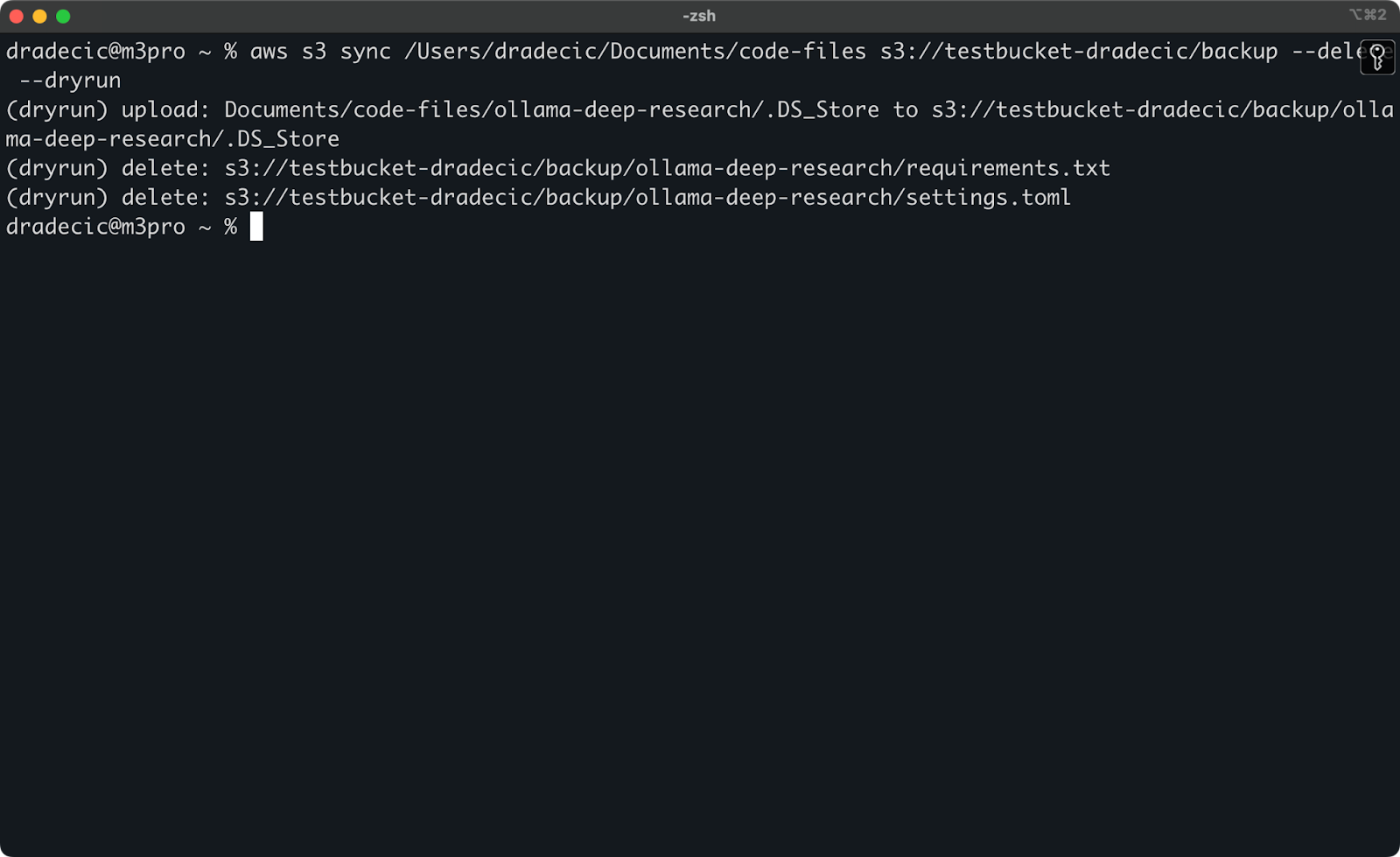
Immagine 17 – Simulazione
Questo ti mostrerà esattamente ciò che accadrebbe se eseguissi il comando per davvero, inclusi i file che verrebbero caricati, scaricati o eliminati.
Consiglio sempre di utilizzare il flag --dryrun prima di eseguire qualsiasi comando di sincronizzazione S3 con il flag --delete, specialmente quando si lavora con dati importanti.
Ci sono molte altre opzioni disponibili per il comando di sincronizzazione S3, come --acl per impostare le autorizzazioni, --storage-class per scegliere il livello di archiviazione S3 e --recursive per attraversare le sottodirectory. Consulta la documentazione ufficiale AWS CLI per un elenco completo delle opzioni.
Ora che conosci le opzioni di sincronizzazione S3 di base e avanzate, vediamo come utilizzare questi comandi per scenari pratici come backup e ripristini.
Utilizzo di AWS S3 Sync per Backup e Ripristino
Uno dei casi d’uso più popolari per la sincronizzazione S3 di AWS è il backup di file importanti e il ripristino quando necessario. Esploriamo come puoi implementare una strategia di backup e ripristino semplice utilizzando il comando di sincronizzazione.
Creazione di backup su S3
Creare backup con S3 sync è semplice: basta eseguire il comando di sincronizzazione dalla directory locale a un bucket S3. Tuttavia, ci sono alcune best practice da seguire per backup efficaci.
Prima di tutto, è una buona idea organizzare i tuoi backup per data o versione. Ecco un approccio semplice utilizzando un timestamp nel percorso S3:
# Crea una variabile timestamp TIMESTAMP=$(date +%Y-%m-%d-%H-%M-%S) # Esegui il backup aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backups/$TIMESTAMP
Questo crea una nuova cartella per ogni backup con un timestamp come 2025-03-10-18-56-42. Ecco cosa vedrai su S3:
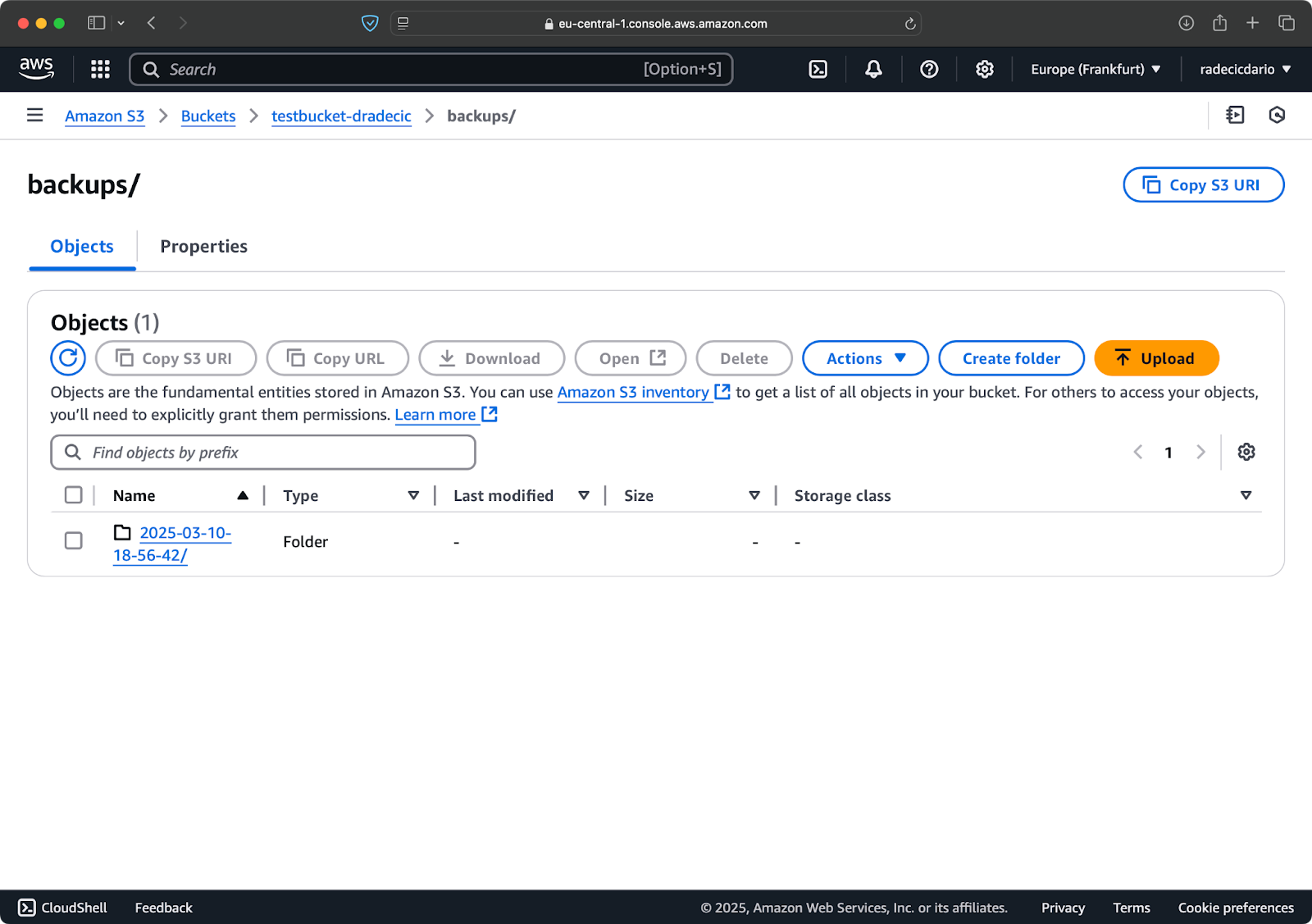
Immagine 18 – Backup con timestamp
Per i dati critici, potresti voler conservare più versioni di backup. È facile farlo eseguendo regolarmente il backup basato sul timestamp.
Puoi anche utilizzare l’opzione --storage-class per specificare una classe di archiviazione più conveniente dal punto di vista dei costi per i tuoi backup:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backups/$TIMESTAMP --storage-class STANDARD_IA
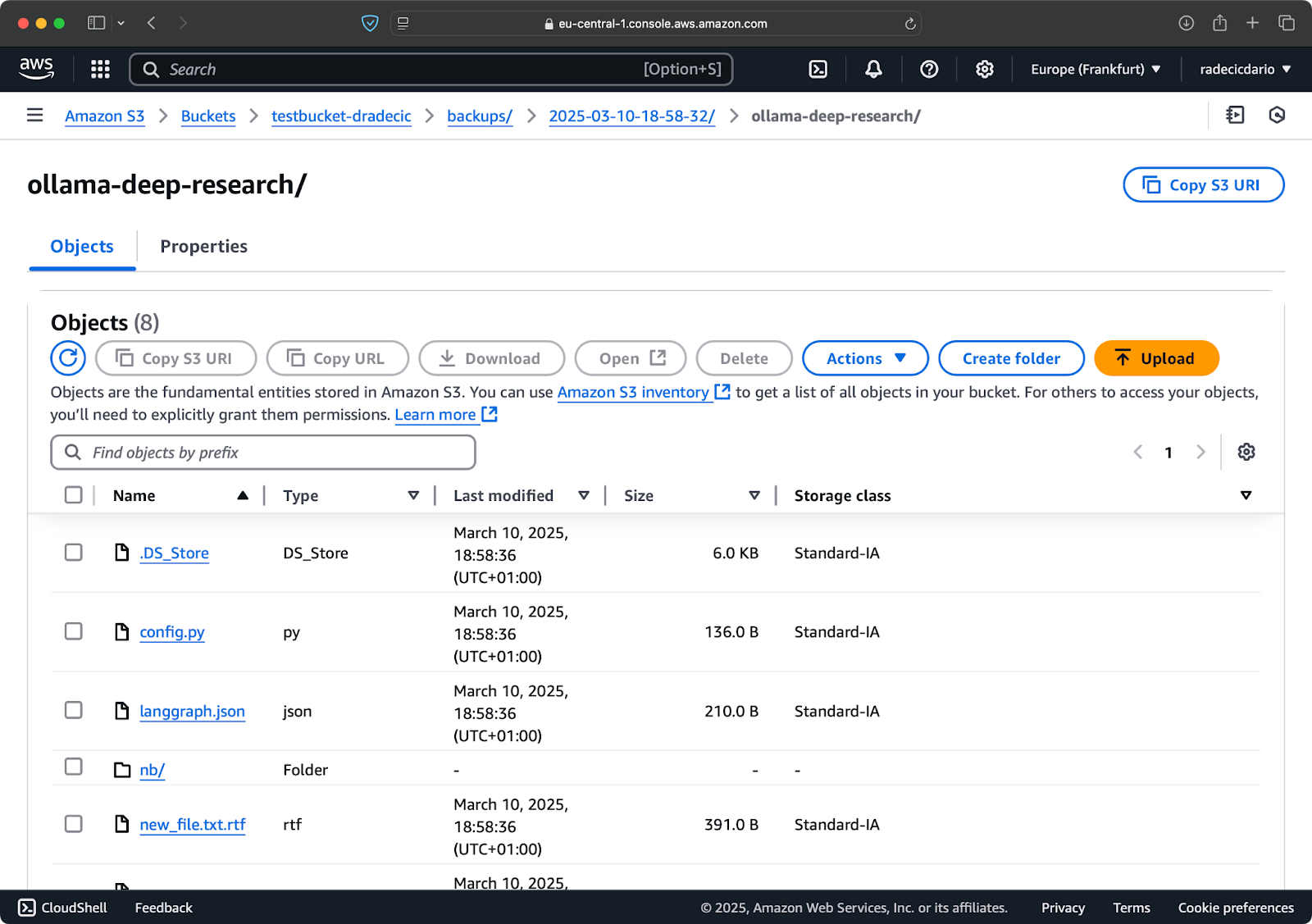
Immagine 19 – Contenuti del backup con una classe di archiviazione personalizzata
Questa utilizza la classe di archiviazione S3 Infrequent Access, che costa meno ma ha un piccolo costo di recupero. Per l’archiviazione a lungo termine, potresti persino utilizzare la classe di archiviazione Glacier:
aws s3 sync /Users/dradecic/Documents/important-data s3://testbucket-dradecic/backups/$TIMESTAMP --storage-class GLACIER
Tieni presente che i file archiviati in Glacier richiedono ore per essere recuperati, quindi non sono adatti per i dati di cui potresti aver bisogno rapidamente.
Ripristino dei file da S3
Il ripristino da un backup è altrettanto semplice – basta invertire la sorgente e la destinazione nel tuo comando di sincronizzazione:
# Ripristina dal backup più recente (supponendo che tu conosca il timestamp) aws s3 sync s3://testbucket-dradecic/backups/2025-03-10-18-56-42 /Users/dradecic/Documents/restored-data
Questo scaricherà tutti i file da quel backup specifico nella tua directory locale restored-data:
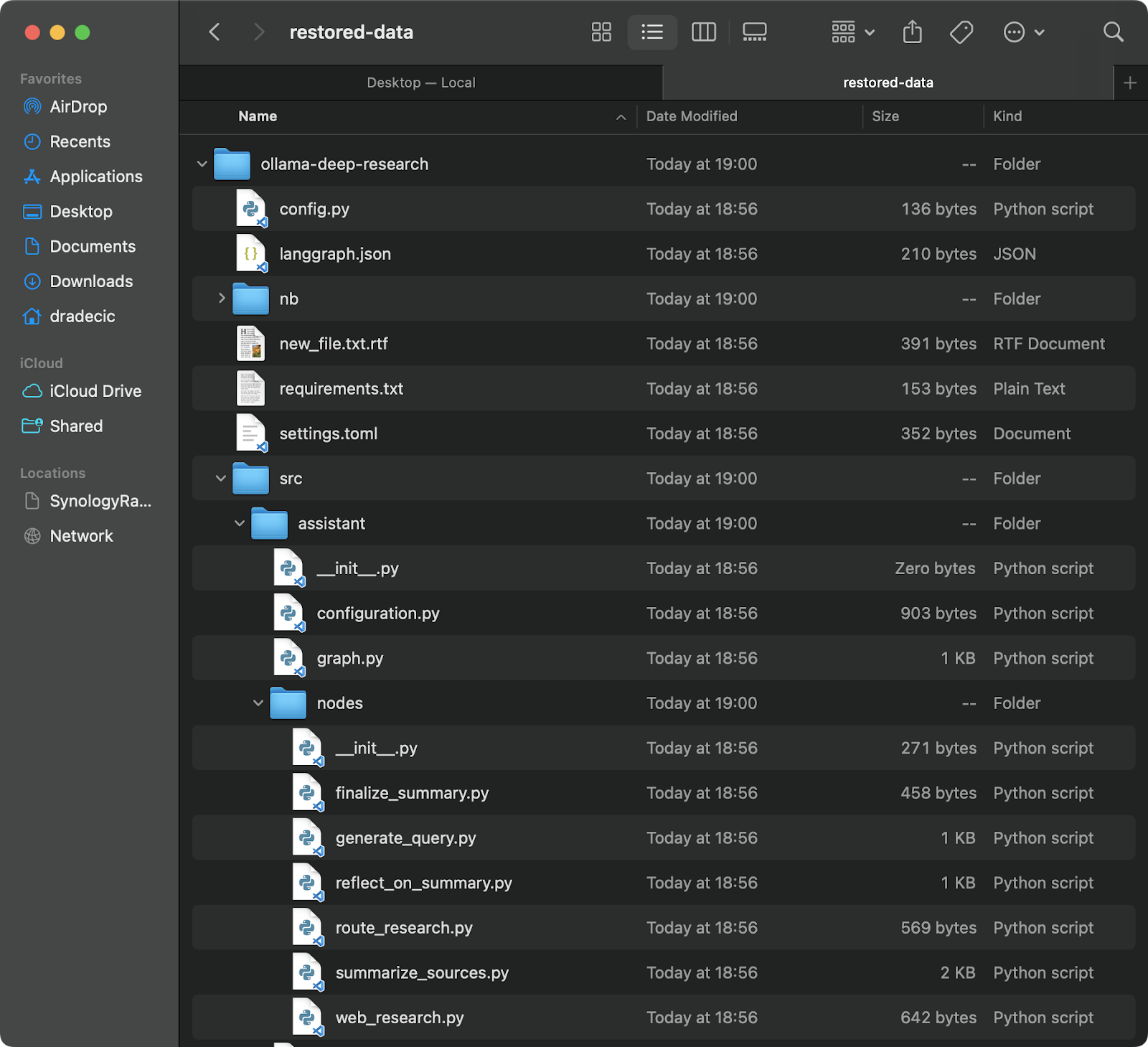
Immagine 20 – Ripristino dei file da S3
Se non ricordi l’orario esatto, puoi elencare prima tutti i tuoi backup:
aws s3 ls s3://testbucket-dradecic/backups/
Il che ti mostrerà qualcosa del genere:
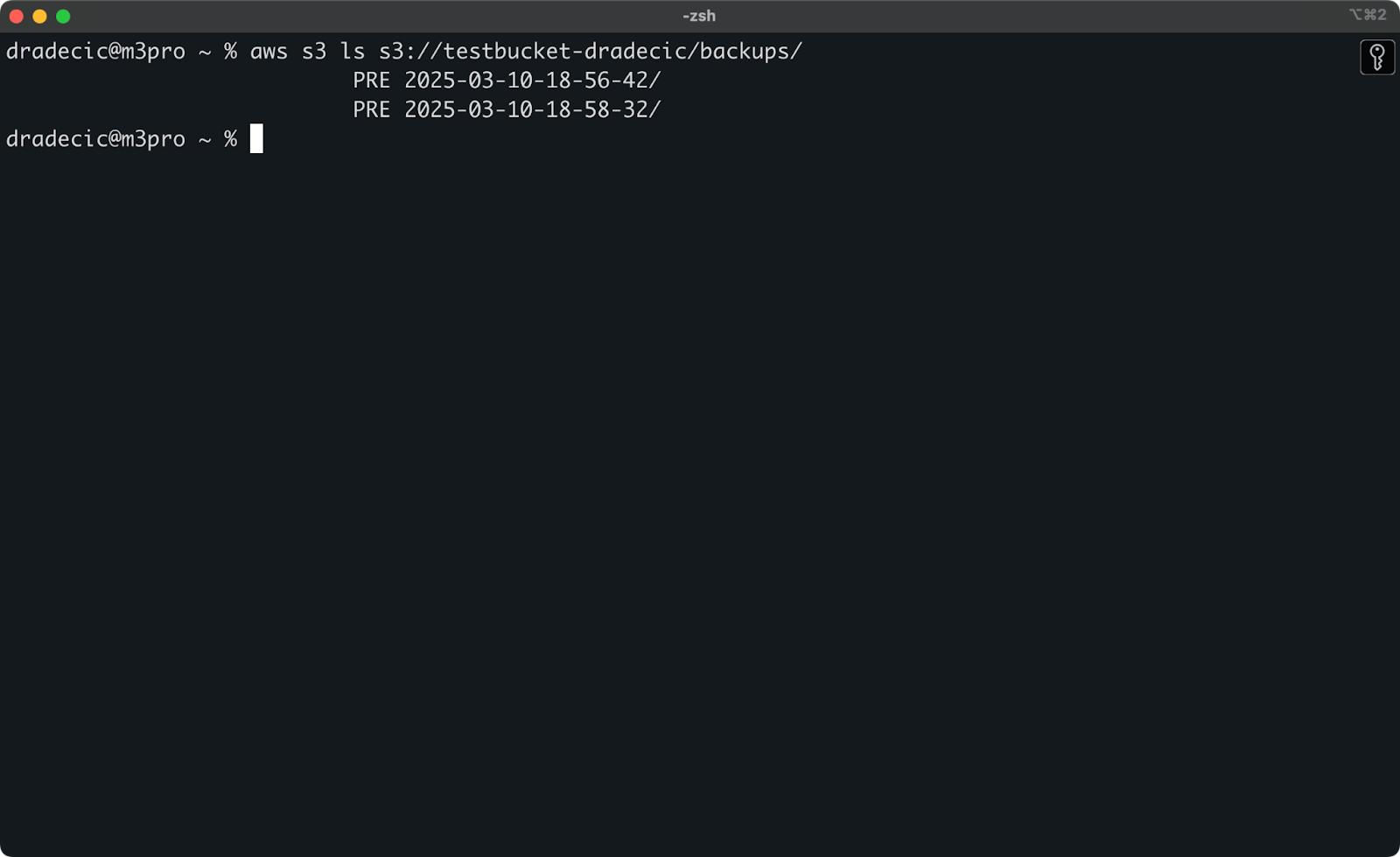
Immagine 21 – Elenco dei backup
Puoi anche ripristinare file o directory specifici da un backup usando i flag di esclusione/inclusione di cui abbiamo discusso in precedenza:
# Ripristina solo i file di configurazione aws s3 sync s3://testbucket-dradecic/backups/2025-03-10-18-56-42 /Users/dradecic/Documents/restored-configs --exclude "*" --include "*.config" --include "*.toml" --include "*.yaml"
Per i sistemi critici per la missione, consiglio di automatizzare i backup con compiti pianificati (come i cron job su Linux/macOS o il Task Scheduler su Windows). In questo modo ti assicuri di eseguire regolarmente il backup dei tuoi dati senza dover ricordare di farlo manualmente.
Soluzione dei problemi di sincronizzazione AWS S3
La sincronizzazione AWS S3 è uno strumento affidabile, ma potresti occasionalmente riscontrare problemi. Tuttavia, la maggior parte degli errori che riscontrerai sono di natura umana.
Errori di sincronizzazione comuni
Esaminiamo alcuni problemi comuni e le relative soluzioni.
- Errore di accesso negato significa di solito che il tuo utente IAM non ha le autorizzazioni necessarie per accedere al bucket S3 o eseguire operazioni specifiche. Per risolvere il problema, prova una delle seguenti soluzioni:
- Verifica che il tuo utente IAM abbia le autorizzazioni S3 appropriate (
s3:ListBucket,s3:GetObject,s3:PutObject). - Verifica che la policy del bucket non neghi esplicitamente l’accesso al tuo utente.
- Assicurati che il bucket stesso non stia bloccando l’accesso pubblico se sono necessarie operazioni pubbliche.
- File o directory non esistenti errore appare tipicamente quando il percorso di origine specificato nel comando di sincronizzazione non esiste. La soluzione è diretta – controlla due volte i tuoi percorsi e assicurati che esistano. Presta particolare attenzione agli errori di battitura nei nomi dei bucket o nelle directory locali.
- Limite di dimensione del file possono verificarsi errori quando si desidera sincronizzare file di grandi dimensioni. Per impostazione predefinita, la sincronizzazione S3 può gestire file fino a 5GB di dimensione. Per file più grandi, si verificheranno timeout o trasferimenti incompleti.
- Per file più grandi di 5GB, dovresti utilizzare il flag
--only-show-errorscombinato con il flag--size-only. Questa combinazione aiuta nei trasferimenti di file di grandi dimensioni minimizzando l’output e confrontando solo le dimensioni dei file:
aws s3 sync /Users/dradecic/large-files s3://testbucket-dradecic/large-files --only-show-errors --size-only
Ottimizzazione delle prestazioni di sincronizzazione
Se la tua sincronizzazione S3 sta funzionando più lentamente del previsto, ci sono alcuni aggiustamenti che puoi fare per velocizzare le cose.
- Usa trasferimenti paralleli. Per impostazione predefinita, la sincronizzazione S3 utilizza un numero limitato di operazioni parallele. Puoi aumentare questo valore con il parametro
--max-concurrent-requests:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup --max-concurrent-requests 20
- Regola la dimensione del chunk. Per file di grandi dimensioni, puoi ottimizzare la velocità di trasferimento regolando la dimensione del chunk. Questo suddivide i file di grandi dimensioni in chunk da 16 MB anziché i 8 MB predefiniti, il che può essere più veloce per buone connessioni di rete:
aws s3 sync /Users/dradecic/large-files s3://testbucket-dradecic/backup --cli-read-timeout 120 --multipart-threshold 64MB --multipart-chunksize 16MB
- Usa
--no-progressper gli script. Se stai eseguendo la sincronizzazione S3 in uno script automatizzato, utilizza il flag--no-progressper ridurre l’output e migliorare le prestazioni:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup --no-progress
- Usa endpoint locali. Se le risorse AWS sono nella stessa regione, specificare l’endpoint regionale può ridurre la latenza:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup --endpoint-url https://s3.eu-central-1.amazonaws.com
Queste ottimizzazioni possono migliorare significativamente le prestazioni di sincronizzazione, specialmente per trasferimenti di dati di grandi dimensioni o quando si eseguono su macchine meno potenti.
Se continui a riscontrare problemi dopo aver provato queste soluzioni, l’AWS CLI ha un’opzione di debug integrata. Aggiungi semplicemente --debug al tuo comando per vedere informazioni dettagliate su ciò che accade durante il processo di sincronizzazione:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup --debug
Prevedi di vedere molti messaggi di log dettagliati, simili a questi:
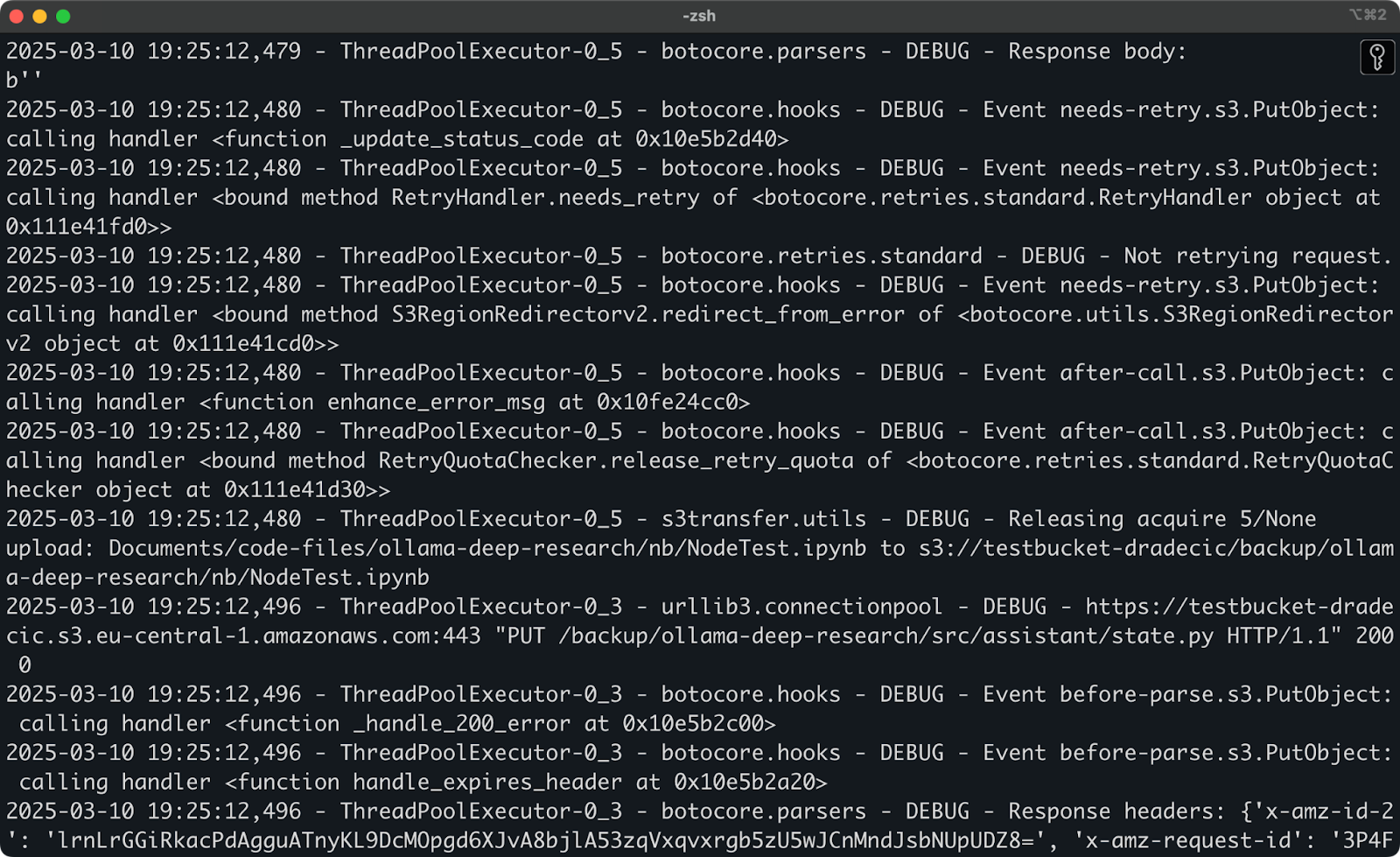
Immagine 22 – Esecuzione della sincronizzazione in modalità di debug
E questo è praticamente tutto per quanto riguarda la risoluzione dei problemi di sincronizzazione di AWS S3. Certo, potrebbero verificarsi altri errori, ma il 99% delle volte troverai la soluzione in questa sezione.
Riassumendo la sincronizzazione di AWS S3
Per riassumere, la sincronizzazione di AWS S3 è uno di quegli strumenti rari che sono sia semplici da usare che incredibilmente potenti. Hai imparato tutto, dai comandi di base alle opzioni avanzate, dalle strategie di backup ai suggerimenti per la risoluzione dei problemi.
Per sviluppatori, amministratori di sistema o chiunque lavori con AWS, il comando di sincronizzazione S3 è uno strumento essenziale: risparmia tempo, riduce l’uso della larghezza di banda e garantisce che i tuoi file siano dove ti servono, quando ti servono.
Che tu stia facendo il backup di dati critici, distribuendo risorse web o semplicemente mantenendo sincronizzati diversi ambienti, la sincronizzazione di AWS S3 rende il processo semplice e affidabile.
Il modo migliore per familiarizzare con la sincronizzazione di S3 è iniziare ad usarla. Prova a configurare un’operazione di sincronizzazione semplice con i tuoi file, poi esplora gradualmente le opzioni avanzate per adattarle alle tue esigenze specifiche.
Ricorda di utilizzare sempre --dryrun prima di lavorare con dati importanti, specialmente quando si utilizza il flag --delete. È meglio dedicare un minuto in più per verificare cosa succederà piuttosto che cancellare accidentalmente file importanti.
Per saperne di più su AWS, dai un’occhiata a questi corsi di DataCamp:
- Introduzione ad AWS
- Tecnologia e Servizi Cloud di AWS
- Sicurezza e Gestione dei Costi di AWS
- Introduzione ad AWS Boto in Python
Puoi anche utilizzare DataCamp per prepararti agli esami di certificazione AWS – AWS Cloud Practitioner (CLF-C02).