













התקנת CLI של AWS ו-S3 של AWS
לפני שתוכל להתחיל לסנכרן קבצים עם S3, תצטרך להגדיר ולהגדיר את AWS CLI בצורה תקינה. הדבר עשוי להישמע מאיים אם אתה חדש ב- AWS, אך ייקח רק כמה דקות.
הגדרת ה-CLI כוללת שני שלבים עיקריים: התקנת הכלי והגדרתו. אני אסביר את שני השלבים הללו לאחר מכן.
התקנת ה- AWS CLI
התקנת ה- AWS CLI קצת שונה בהתאם למערכת ההפעלה שלך.
למערכות Windows:
- לך אל עמוד הורדתCLI של AWS
- להוריד את מתקין החלונות (64 ביט)
- להריץ את המתקין ולעקוב אחר ההוראות
עבור מערכות Linux:
להריץ את הפקודות הבאות דרך הטרמינל:
curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip" unzip awscliv2.zip sudo ./aws/install
עבור מערכות macOS:
בהנחה שיש לך Homebrew מותקן, להריץ שורת פקודה זו מהטרמינל:
brew install awscli
אם אין לך Homebrew, תשתמש בשני הפקודות הללו במקום:
curl "https://awscli.amazonaws.com/AWSCLIV2.pkg" -o "AWSCLIV2.pkg" sudo installer -pkg AWSCLIV2.pkg -target /
ניתן להריץ את הפקודה aws --version בכל מערכת הפעלה כדי לוודא שהותקן CLI של AWS. כך תראה את התוצאה הבאה:
תמונה 1 – גרסת AWS CLI
Configuring the AWS CLI
עכשיו שה-CLI מותקן, עליך להגדיר אותו עם פרטי הכניסה שלך ל-AWS.
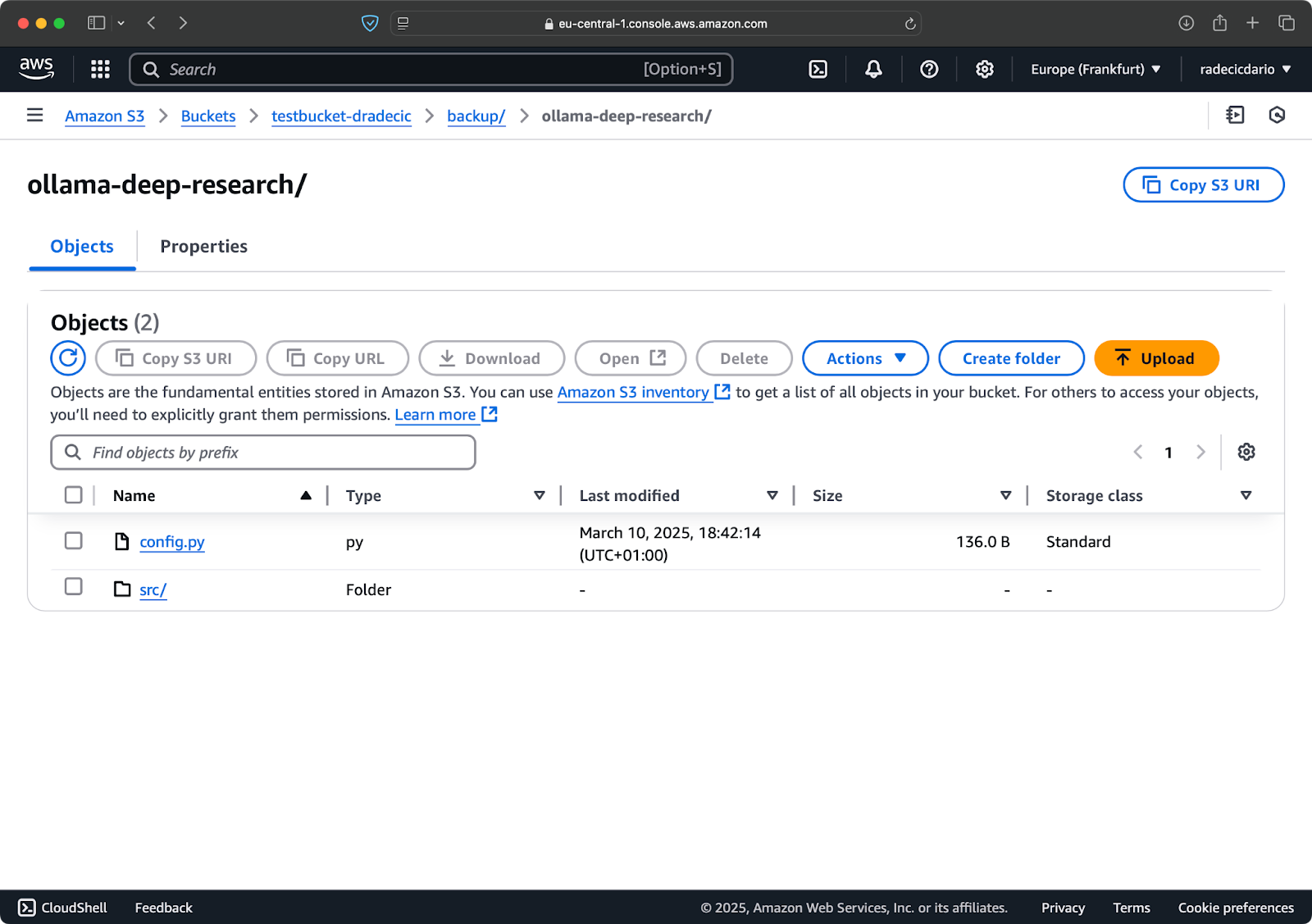
בהנחה שכבר יש לך חשבון AWS, היכנס ועבור לשירות IAM. כאשר אתה שם, צור משתמש חדש עם גישה תכנותית. עליך להקצות את ההרשאה המתאימה למשתמש, שהיא גישה ל-S3 לפחות:
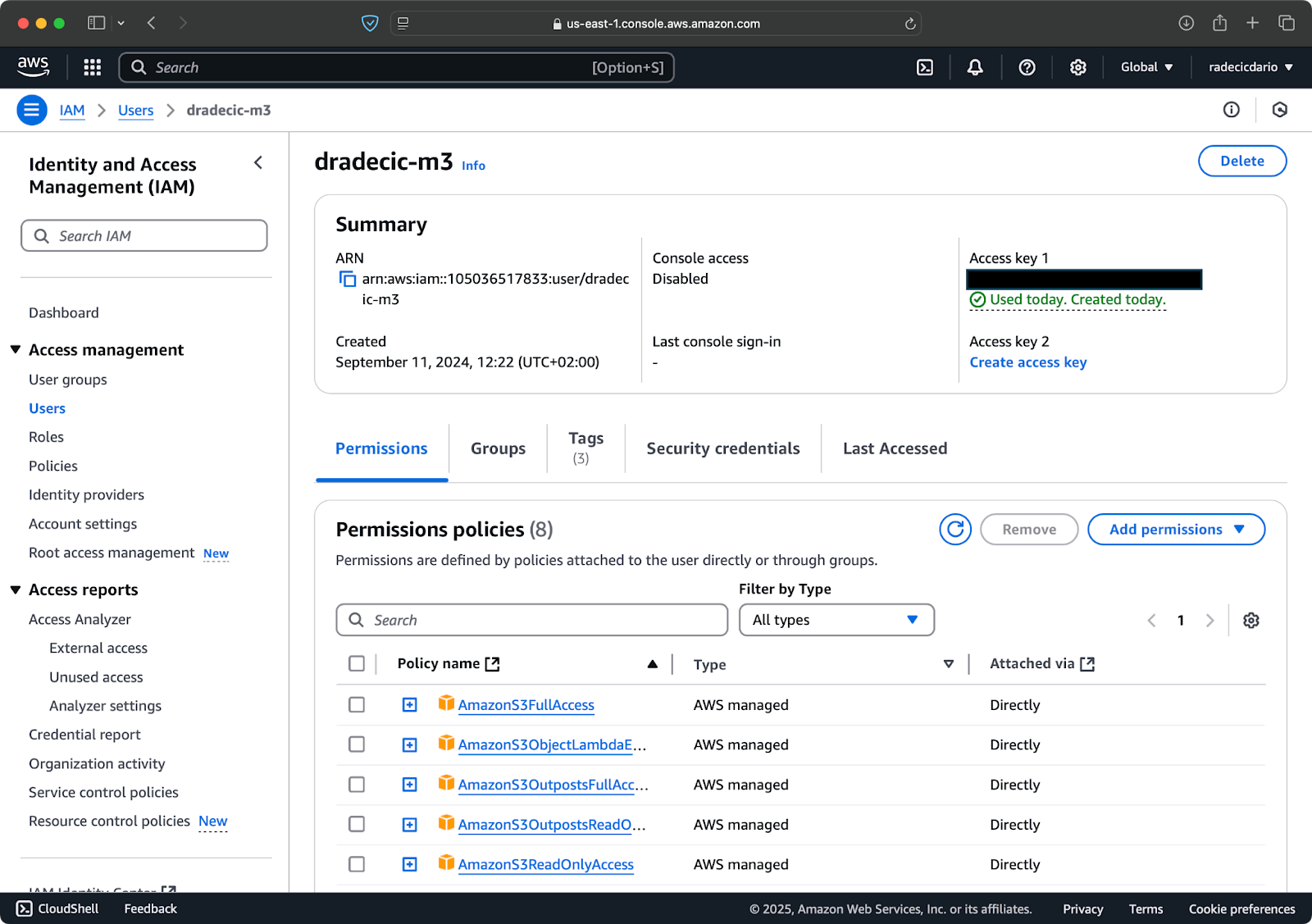
תמונה 2 – משתמש AWS IAM
כשתסיימו, עברו אל "אישורי אבטחה" כדי ליצור מפתח גישה חדש. לאחר היצירה, יהיו לכם כמו כן גם ה מפתח גישה ID וה מפתח גישה סודי. כתבו אותם במקום בטוח מכיוון שלא תוכלו לגשת אליהם בעתיד:
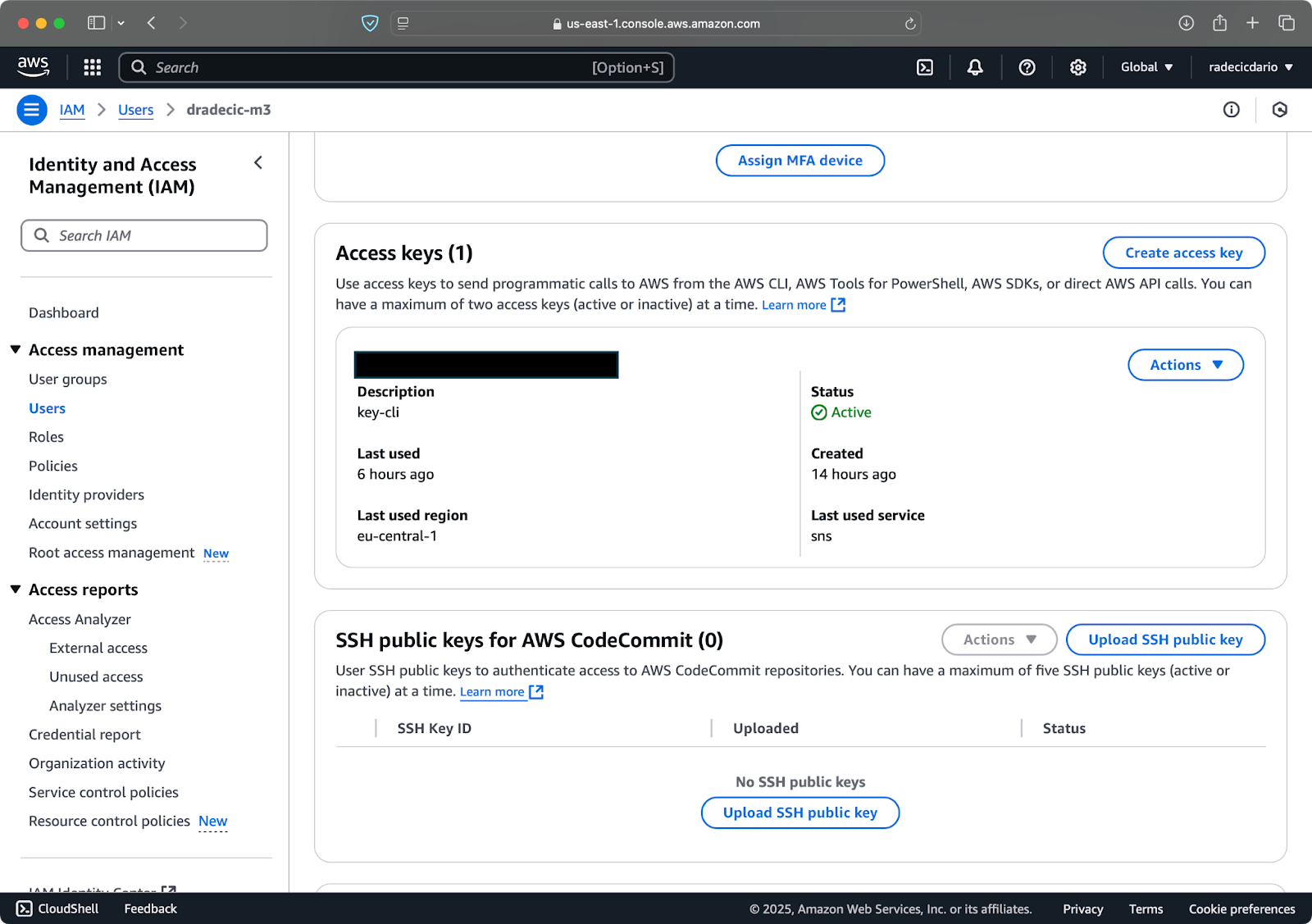
תמונה 3 – אישורי משתמש AWS IAM
בחלון ה-Terminal, הריצו את הפקודה aws configure. היא תבקש מכם להזין את מפתח הגישה שלכם, את מפתח הגישה הסודי, את האזור (במקרה שלי – eu-central-1), ואת תבנית הפלט המועדפת (json):
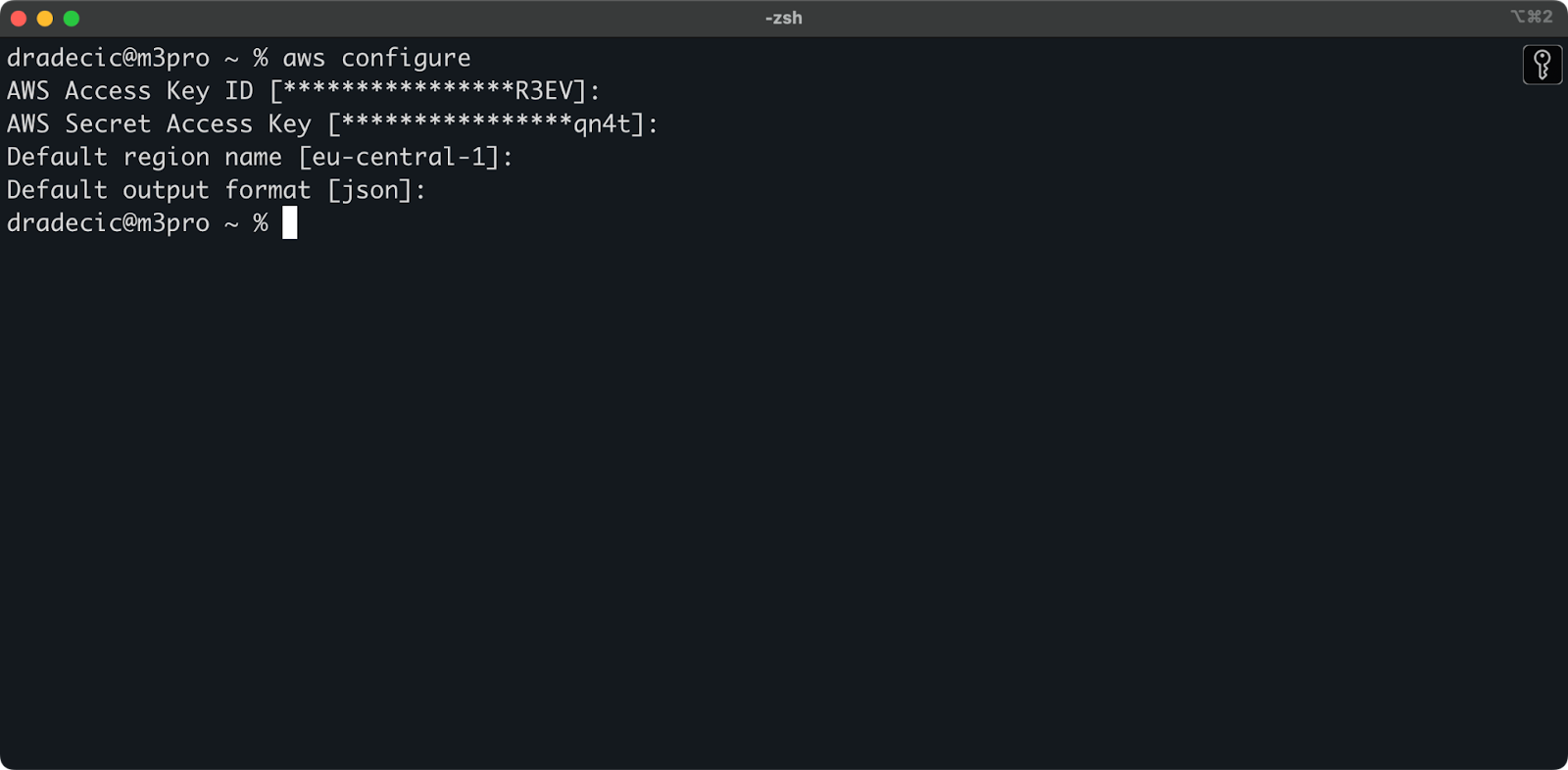
תמונה 4 – הגדרות CLI של AWS
כדי לוודא כי אתם מחוברים בהצלחה לחשבון ה-AWS שלכם מה-CLI, הריצו את הפקודה הבאה:
aws sts get-caller-identity
זהו הפלט שצריך לראות:
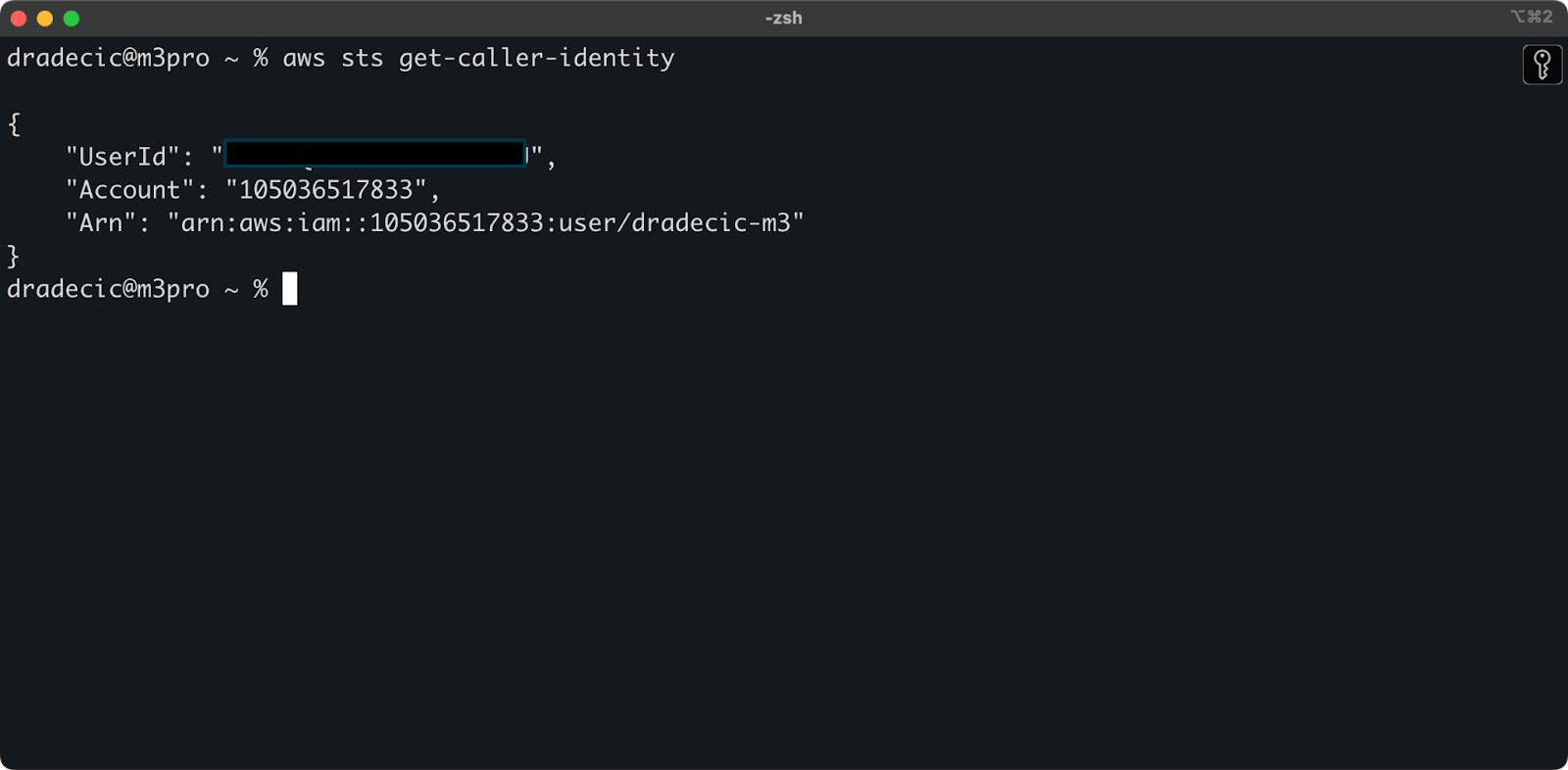
תמונה 5 – פקודת בדיקת חיבור CLI של AWS
וזהו – רק צעד אחד נוסף לפני שתוכלו להתחיל להשתמש בפקודת סנכרון של S3!
התקנת דלפק AWS S3
השלב הסופי הוא ליצור דלי S3 שיכיל את הקבצים שסונכרנו. ניתן לעשות זאת מתוך ה-CLI או מתוך לוח הניהול של AWS. אני אבחר באפשרות השנייה, רק כדי לשנות קצת.
כדי להתחיל, עבור אל עמוד השירות של S3 בלוח הניהול ולחץ על הכפתור "צור דלי". לאחר מכן, בחר שם דלי ייחודי (ייחודי באופן גלובלי בכל ה- AWS) וגלול לתחתית העמוד ולחץ על הכפתור "צור":
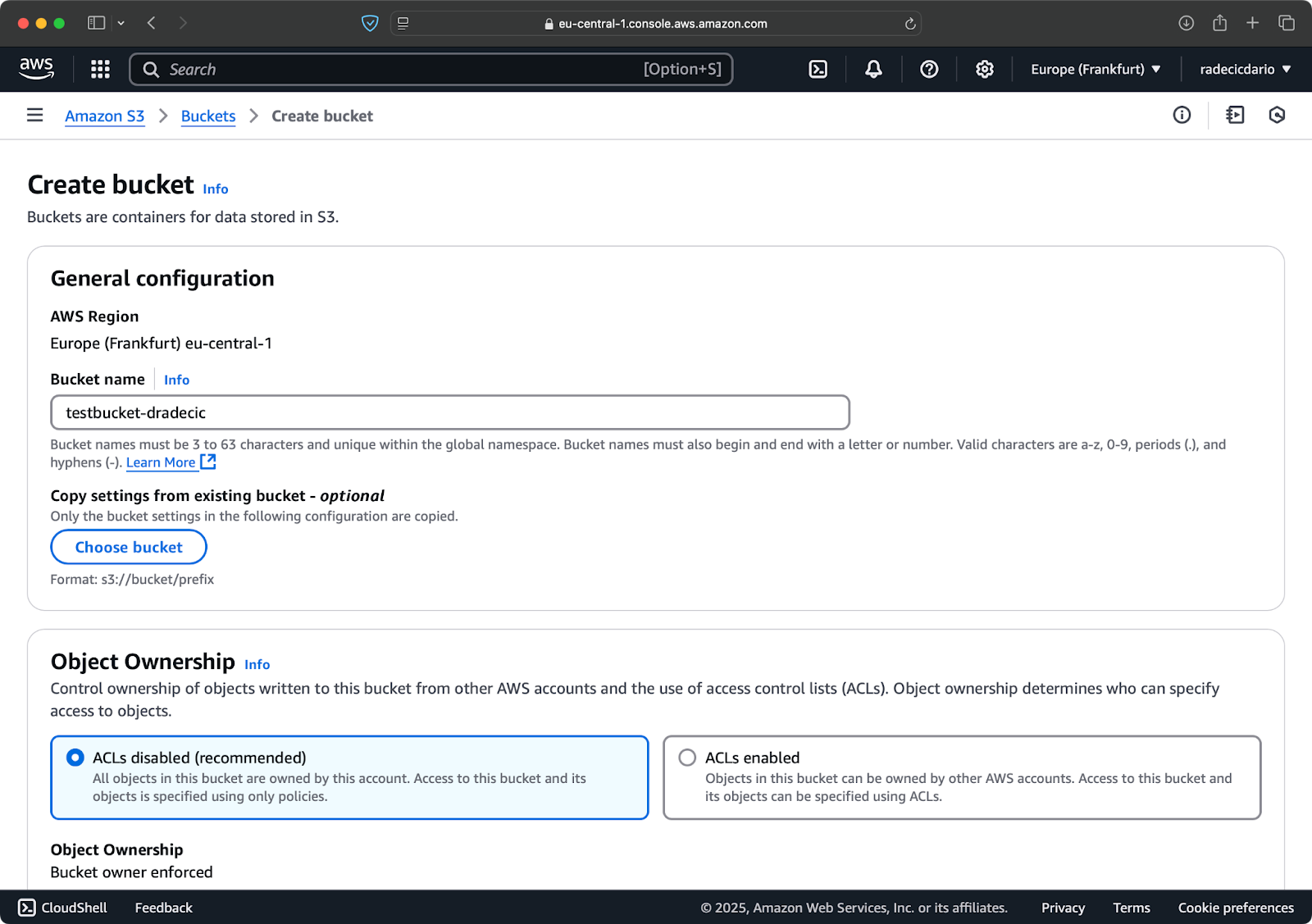
תמונה 6 – יצירת דלי של AWS
הדלי נוצר כעת, ותראה אותו מייד בלוח הניהול. ניתן גם לוודא שהוא נוצר דרך ה-CLI:
aws s3 ls
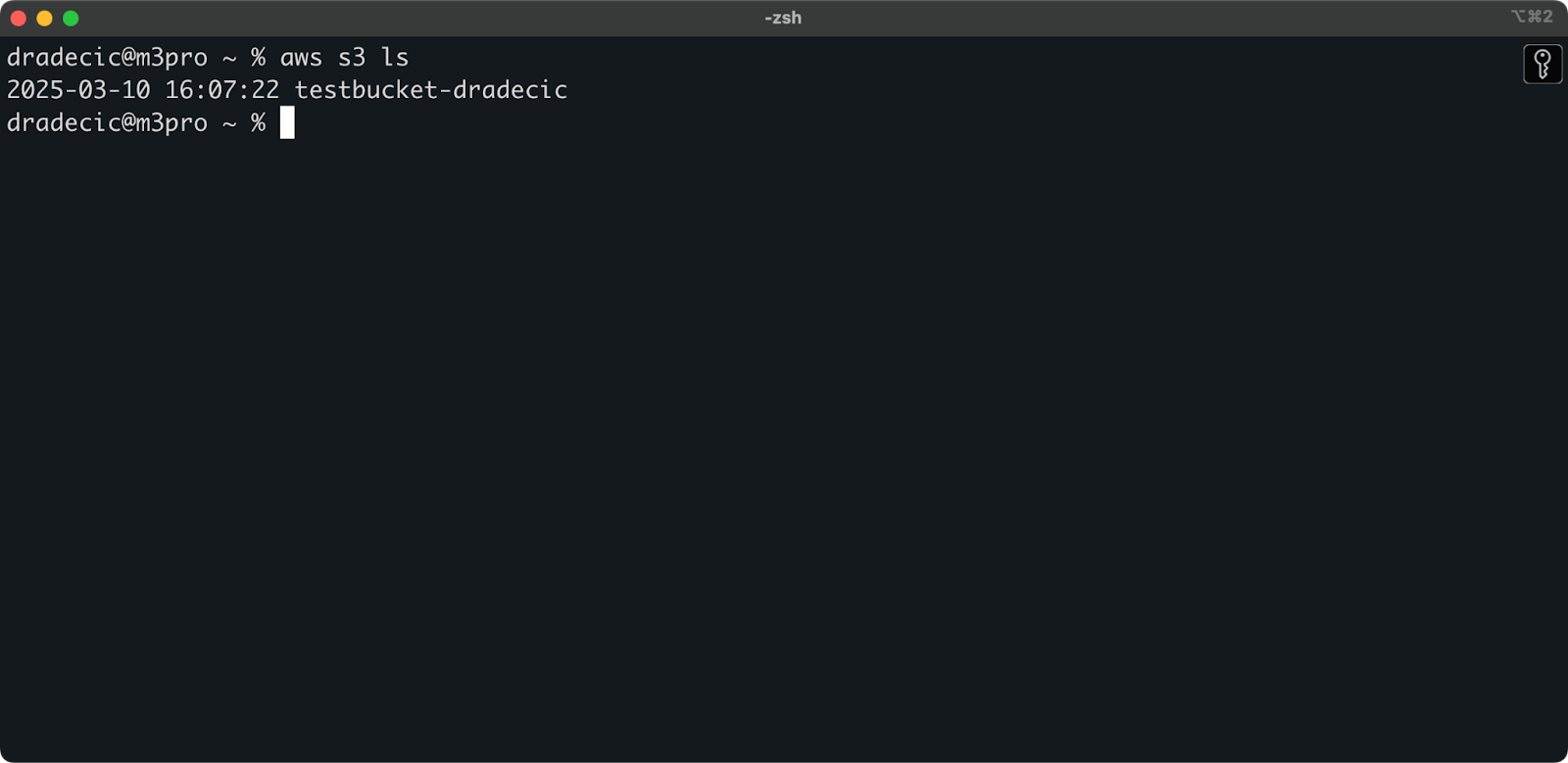
תמונה 7 – כל הדליים הזמינים ב-S3
שמור במחשבה שדלי S3 הם פרטיים כברירת מחדל. אם אתה מתכנן להשתמש בדלי לאחסון קבצים ציבוריים (כמו נכסי אתרים), תצטרך להתאים את המדיניות והרשאות של הדלי בהתאם.
עכשיו אתה מוכן להתחיל לסנכרן קבצים בין המחשב המקומי שלך ל-AWS S3!
פקודת סנכרון בסיסית של AWS S3
עכשיו כשיש לך את AWS CLI מותקן, מוגדר ודלי S3 מוכן, הגיע הזמן להתחיל לסנכרן! הסינטקס הבסיסי לפקודת הסנכרון של AWS S3 הוא די פשוט. תן לי להראות לך איך זה עובד.
פקודת הסנכרון של S3 פועלת לפי תבנית פשוטה זו:
aws s3 sync <source> <destination> [options]
המקור והיעד יכולים להיות הן נתיב לתיקייה מקומית או S3 URI (שמתחיל ב־s3://). בהתאם לדרך בה ברצונך לסנכרן, תסדר את אלו באופן שונה.
סנכרון קבצים ממקומי אל דלת S3
שיחקתי לאחרונה עם מחקר עמוק של Ollama. נניח שזהו התיקייה שברצוני לסנכרן ל־S3. התיקייה הראשית ממוקמת תחת התיקייה Documents. הנה כיצד זה נראה:
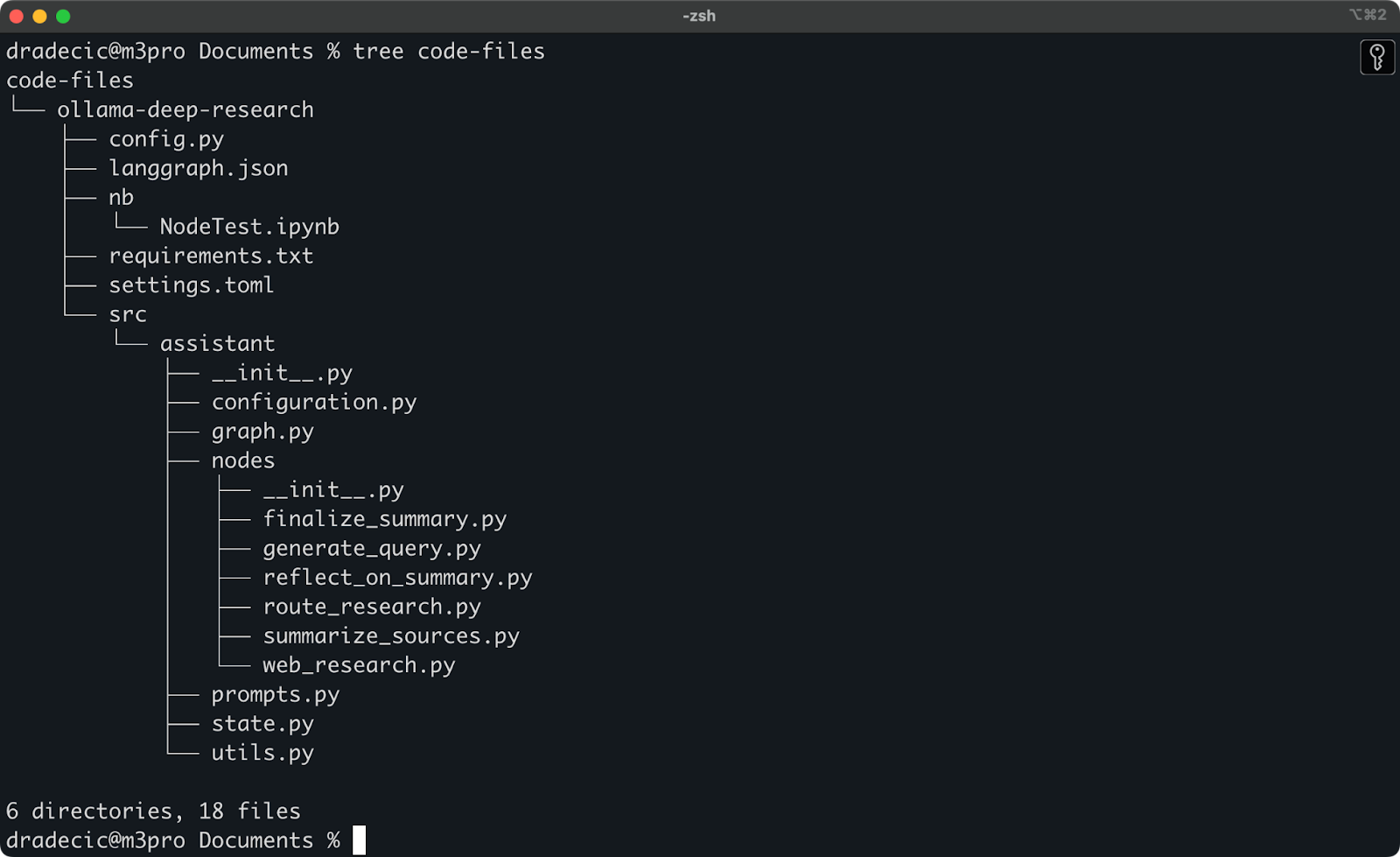
תוכן התיקייה המקומית
זהו הפקודה שעלי להריץ כדי לסנכרן את התיקייה המקומית code-files עם התיקייה backup בדלת ה־S3:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup
התיקייה backup בדלת ה־S3 תיווצר אוטומטית אם היא לא קיימת.
כאן תראה מה שידפיס על המסך:
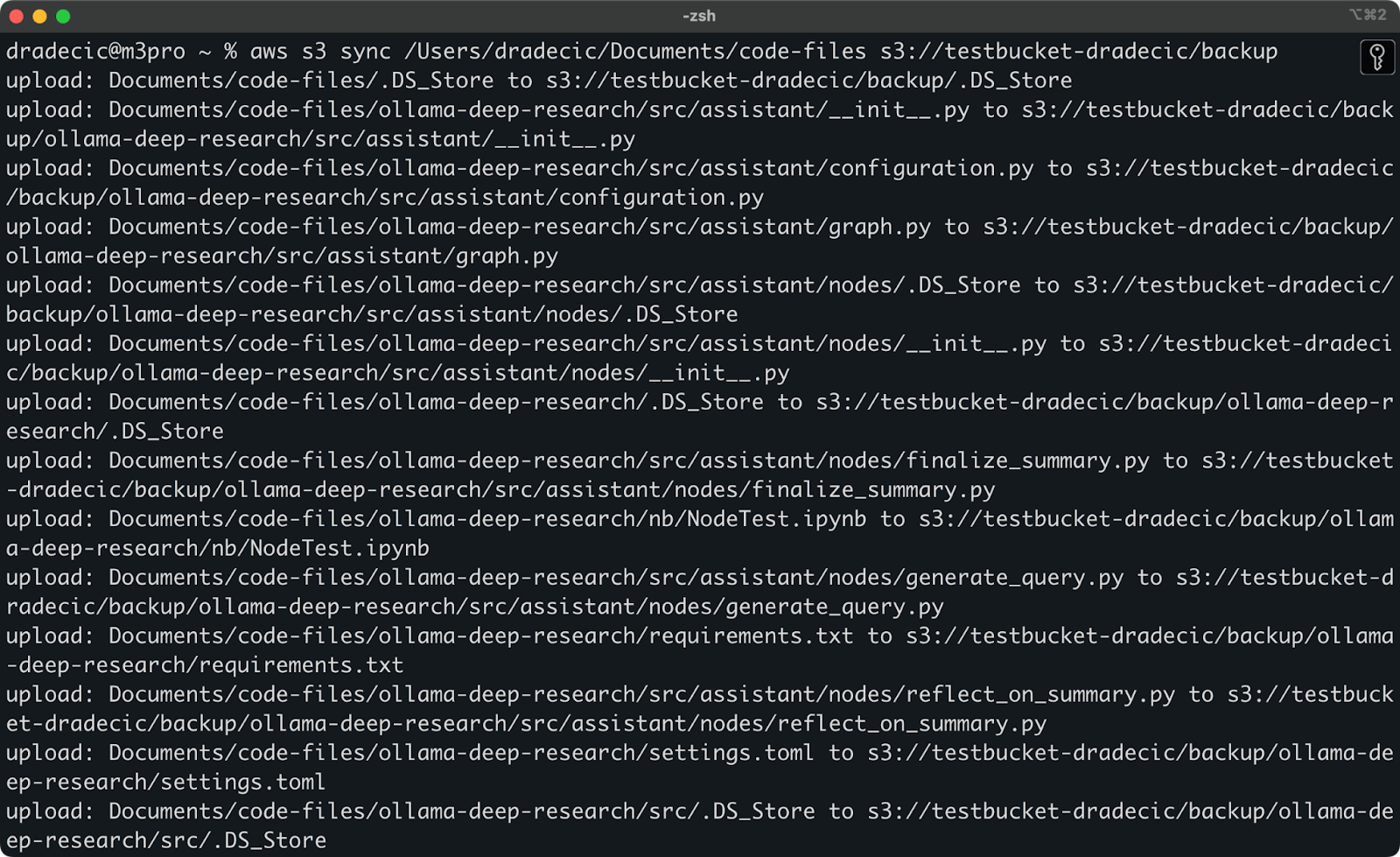
תמונה 9 – תהליך סנכרון S3
לאחר מספר שניות, תוכן התיקייה המקומית code-files זמין בקופסאת ה-S3:
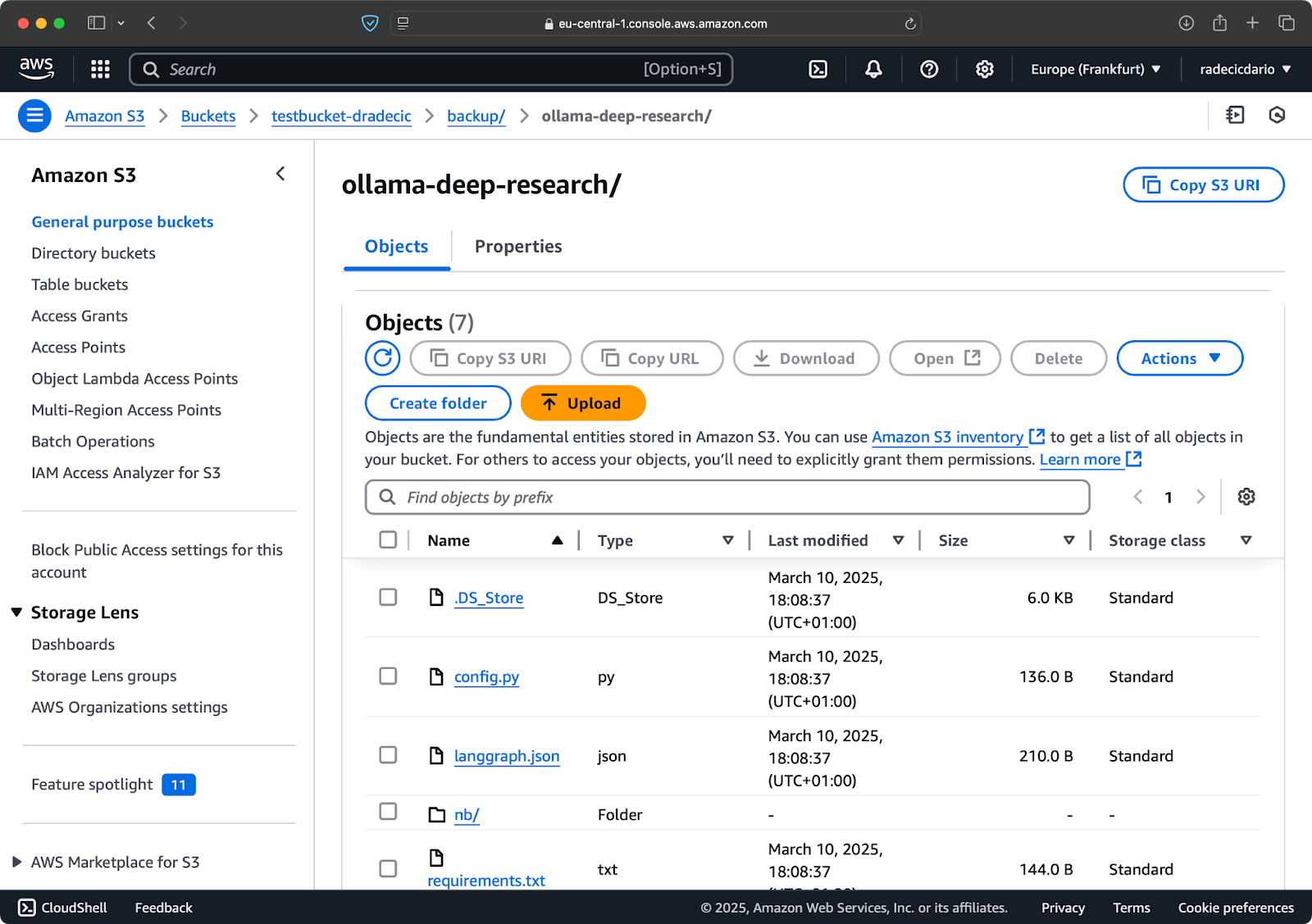
תמונה 10 – תוכן קופסת ה-S3
היופי של סנכרון S3 הוא שהוא מעלה רק קבצים שאינם קיימים ביעד או ששונו מקומית. אם תפעיל את אותה הפקודה שוב מבלי לשנות דבר, תראה… כלום! זאת מכיוון ש-AWS CLI זיהת שכל הקבצים כבר סונכרנו ועדכניים.
עכשיו, אפרסם שני שינויים קטנים – ליצור קובץ חדש (new_file.txt) ולעדכן קיים (requirements.txt). כאשר תפעיל שוב את פקודת הסנכרון, רק הקבצים החדשים או המשונים יועלו:
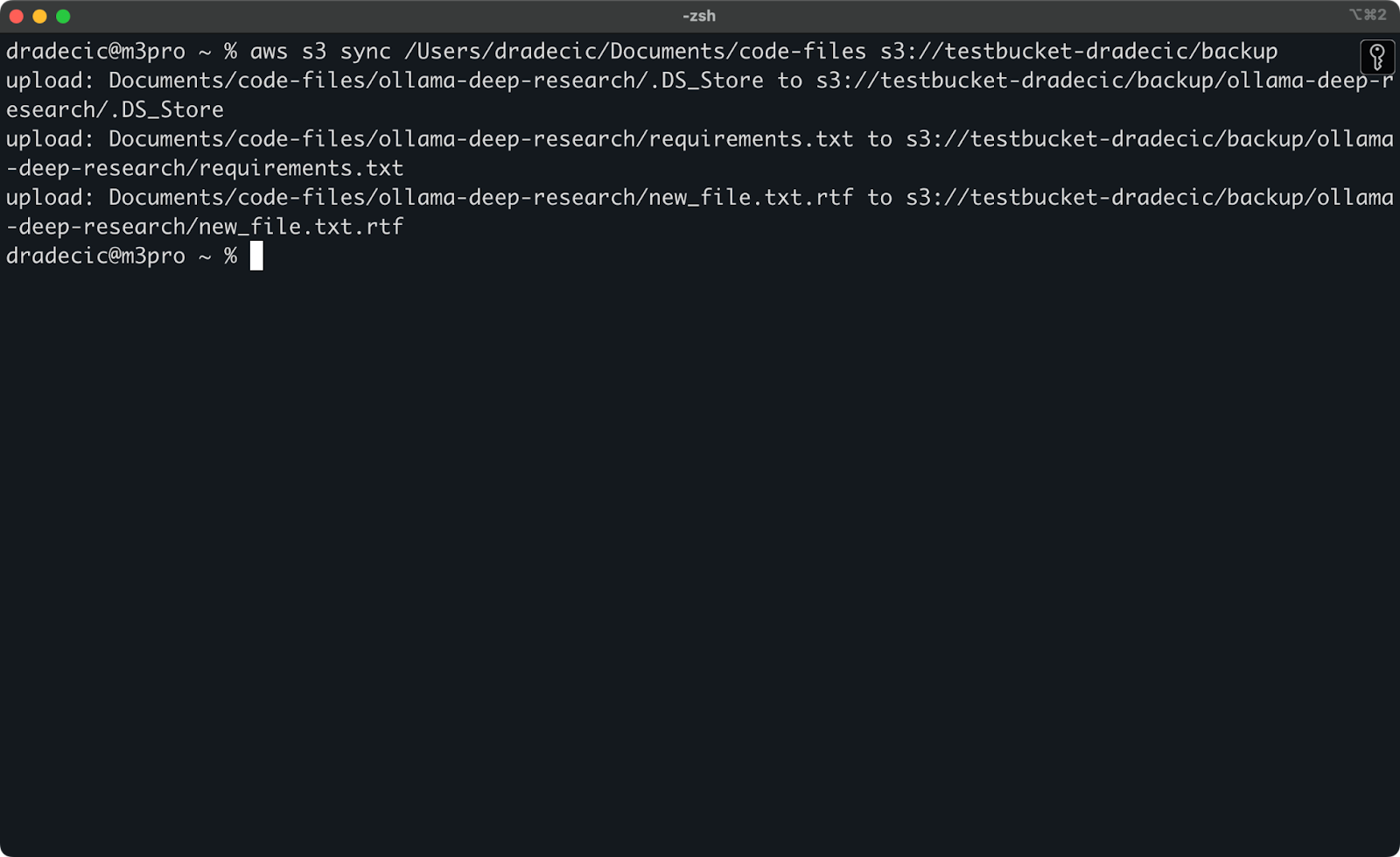
תמונה 11 – תהליך סנכרון S3 (2)
וזהו כל מה שצריך לדעת כאשר מסנכרן תיקיות מקומיות ל־S3. אבל מה אם ברצונך לעבור לדרך ההפוכה?
סנכרון קבצים מדלגי ה־S3 לתיקייה מקומית
אם ברצונך להוריד קבצים מסנכרון ה־S3 שלך למחשב המקומי, פשוט הפוך את המקור והיעד:
aws s3 sync s3://testbucket-dradecic/backup /Users/dradecic/Documents/code-files-from-s3
פקודה זו תוריד את כל הקבצים מתיקיית backup בסל ה־S3 שלך לתיקייה מקומית בשם code-files-from-s3. שוב, אם התיקייה המקומית אינה קיימת, ה־CLI ייצור אותה עבורך:
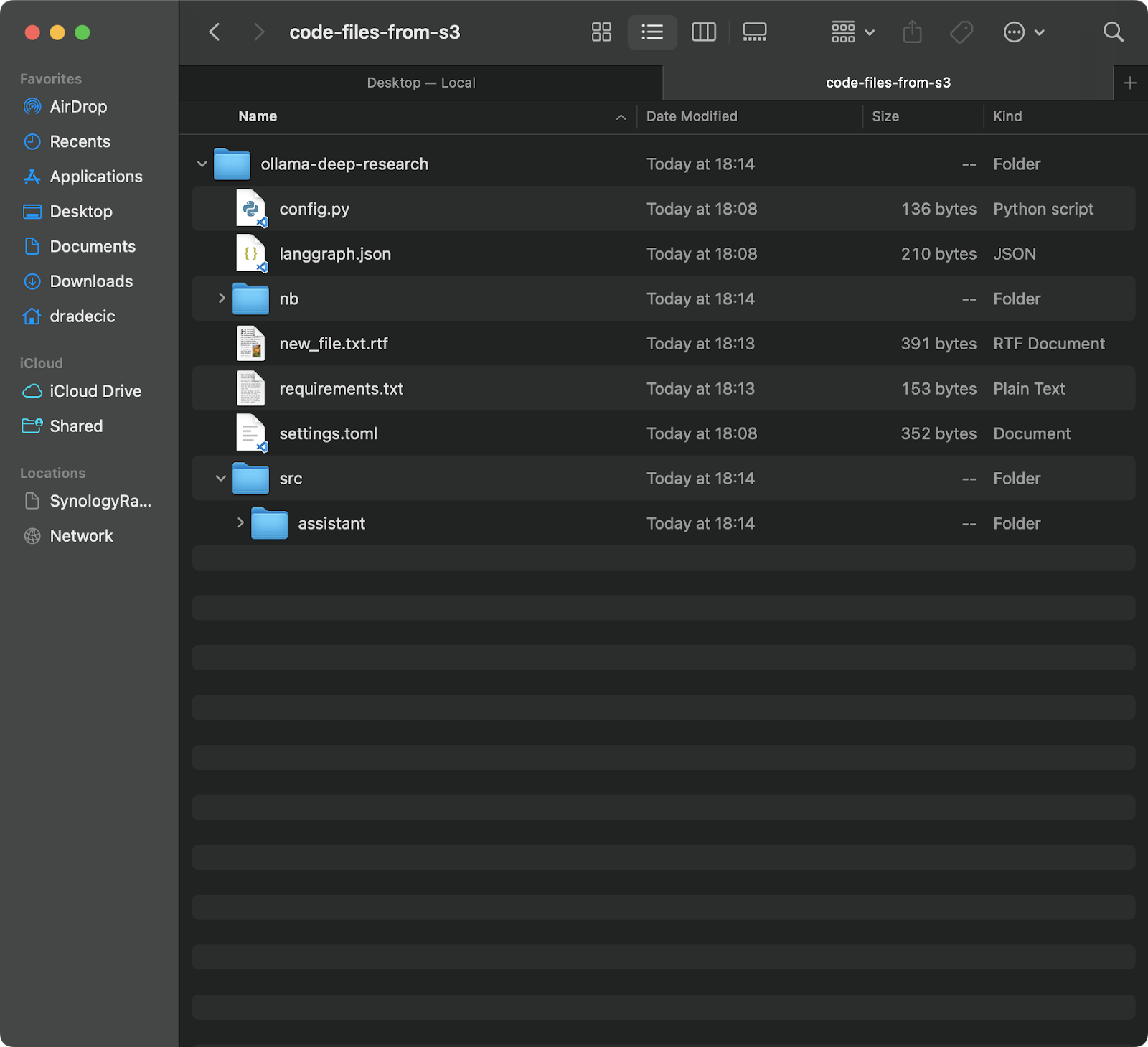
תמונה 12 – סנכרון מ־S3 למקומי
ראוי לציין שסנכרון S3 אינו דו-כיווני. הוא תמיד מתבצע מהמקור ליעד, ומבצע התאמה של היעד למקור. אם תמחוק קובץ במחשב המקומי ולאחר מכן תסנכרן אותו ל-S3, הוא עדיין יתקיים ב-S3. בצורה דומה, אם תמחוק קובץ ב-S3 ותסנכרן מ-S3 למחשב המקומי, הקובץ המקומי יישאר ללא שינוי.
אם ברצונך שהתוצאה תתאים לחלוטין למקור (כולל מחיקות), תצטרך להשתמש בדגל --delete, שאתייחס אליו בסעיף אפשרויות מתקדמות.
אפשרויות סנכרון מתקדמות של AWS S3
פקודת הסנכרון הבסיסית של S3 שנחקרה קודם לכן היא חזקה בזכות עצמה, אך AWS ציידה אותה באפשרויות נוספות שמעניקות לך יותר שליטה על תהליך הסנכרון.
בקטע הזה, אראה לך כמה מהדגלים השימושיים ביותר שאתה יכול להוסיף לפקודה הבסיסית.
סינכרון רק קבצים חדשים או שונוים
כברירת מחדל, סינכרון S3 משתמש במנגנון השוואה בסיסי שבודק את גודל הקובץ וזמן השינוי כדי לקבוע אם קובץ צריך להיות מסונכרן. עם זאת, גישה זו עשויה לא תמיד לתפוס את כל השינויים, במיוחד כאשר מדובר בקבצים ששונו אך נשארו באותו גודל.
לסינכרון מדויק יותר, תוכל להשתמש בדגל --exact-timestamps:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup --exact-timestamps
זה מכריח את סנכרון S3 להשוות חותמות זמן עם דיוק עד למילישניות. יש לזכור ששימוש בדגל הזה עשוי להאט במעט את תהליך הסנכרון מכיוון שהוא דורש השוואות מפורטות יותר.
החרגה או הכללה של קבצים ספציפיים
לפעמים, אינך רוצה לסנכרן כל קובץ בתיקייה. אולי אתה רוצה להחריג קבצים זמניים, לוגים, או סוגי קבצים מסוימים (כגון .DS_Store במקרה שלי). כאן נכנסים לתמונה הדגלים --exclude ו---include.
אבל כדי להמחיש נקודה, נניח שאני רוצה לסנכרן את תיקיית הקוד שלי אבל להחריג את כל קבצי הפייתון:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup --exclude "*.py"
עכשיו, פחות קבצים מסונכרנים ל-S3:
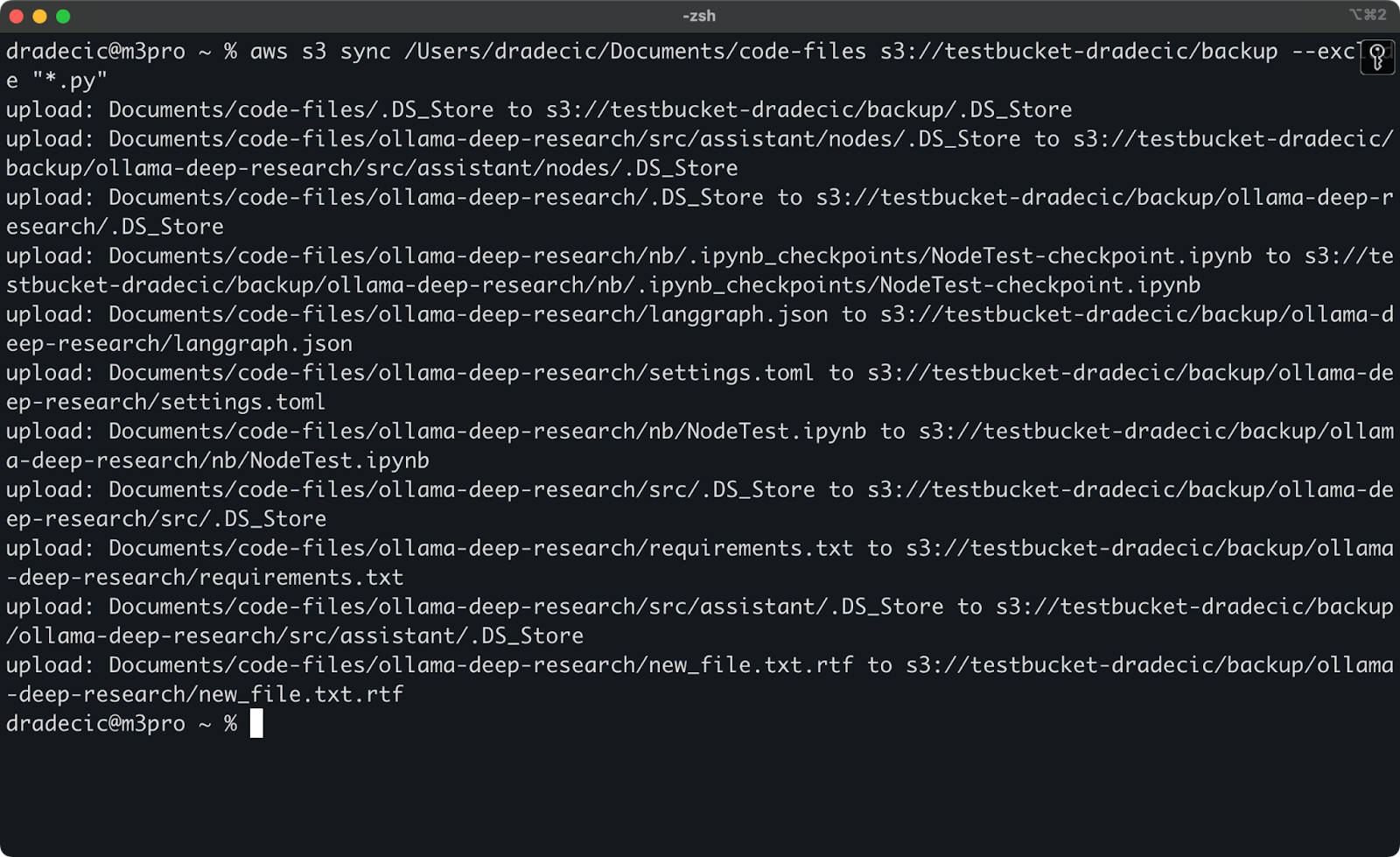
תמונה 13 – סנכרון עם S3 עם קבצי Python מוחלצים
ניתן גם לשלב --exclude ו־--include כדי ליצור תבניות מורכבות יותר. לדוגמה, לא לאפשר כלום פרט לקבצי Python:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup --exclude "*" --include "*.py"
התבניות מוערכות בסדר שצוין, לכן הסדר חשוב! הנה מה שתראו בשימוש בדגלים אלה:
תמונה 14 – דגלי השהייה והכלה
עכשיו רק קבצי ה-Python מסונכרנים, וקבצי תצורה חשובים חסרים.
מחיקת קבצים מהיעד
ברירת מחדל, S3 sync רק מוסיף או מעדכן קבצים ביעד – הוא אף פעם לא מוחק אותם. זה אומר שאם תמחק קובץ מהמקור, הוא עדיין יישאר ביעד לאחר הסנכרון.
כדי לגרום ליעד לשקף בדיוק את המקור, כולל מחיקות, השתמש בדגל --delete:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup --delete
אם תריץ את זה בפעם הראשונה, כל הקבצים המקומיים יסונכרנו ל-S3:
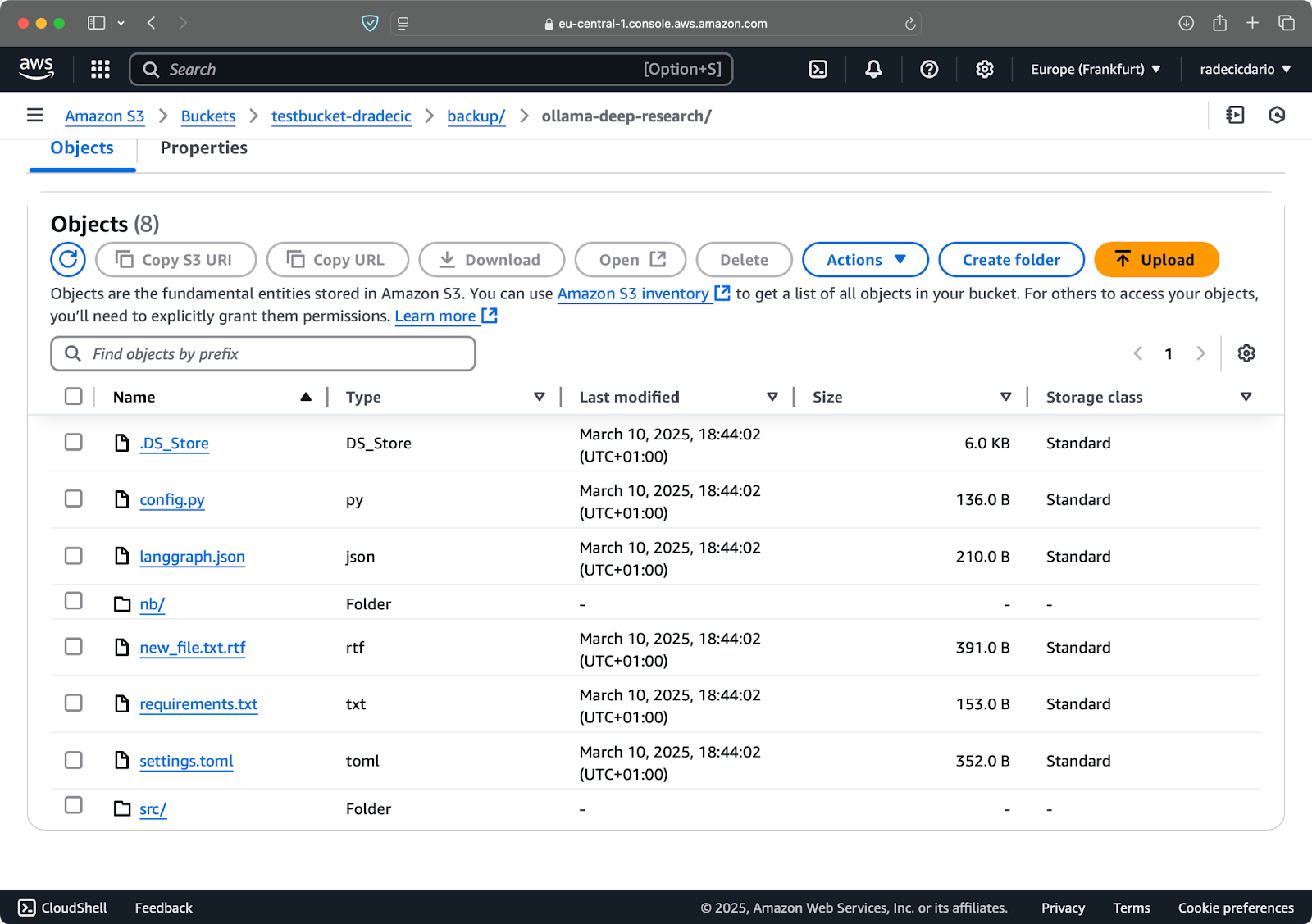
תמונה 15 – דגל מחיקה
זה מועיל במיוחד לשמירהעל דיוק של ספריות. אך היזהרו – דגל זה עשוי לגרום לאובדן נתונים אם יימצא בשימוש לא נכון.
נניח שמחקתי את config.py מהתיקייה המקומית שלי והרצתי את פקודת הסנכרון עם דגל --delete:
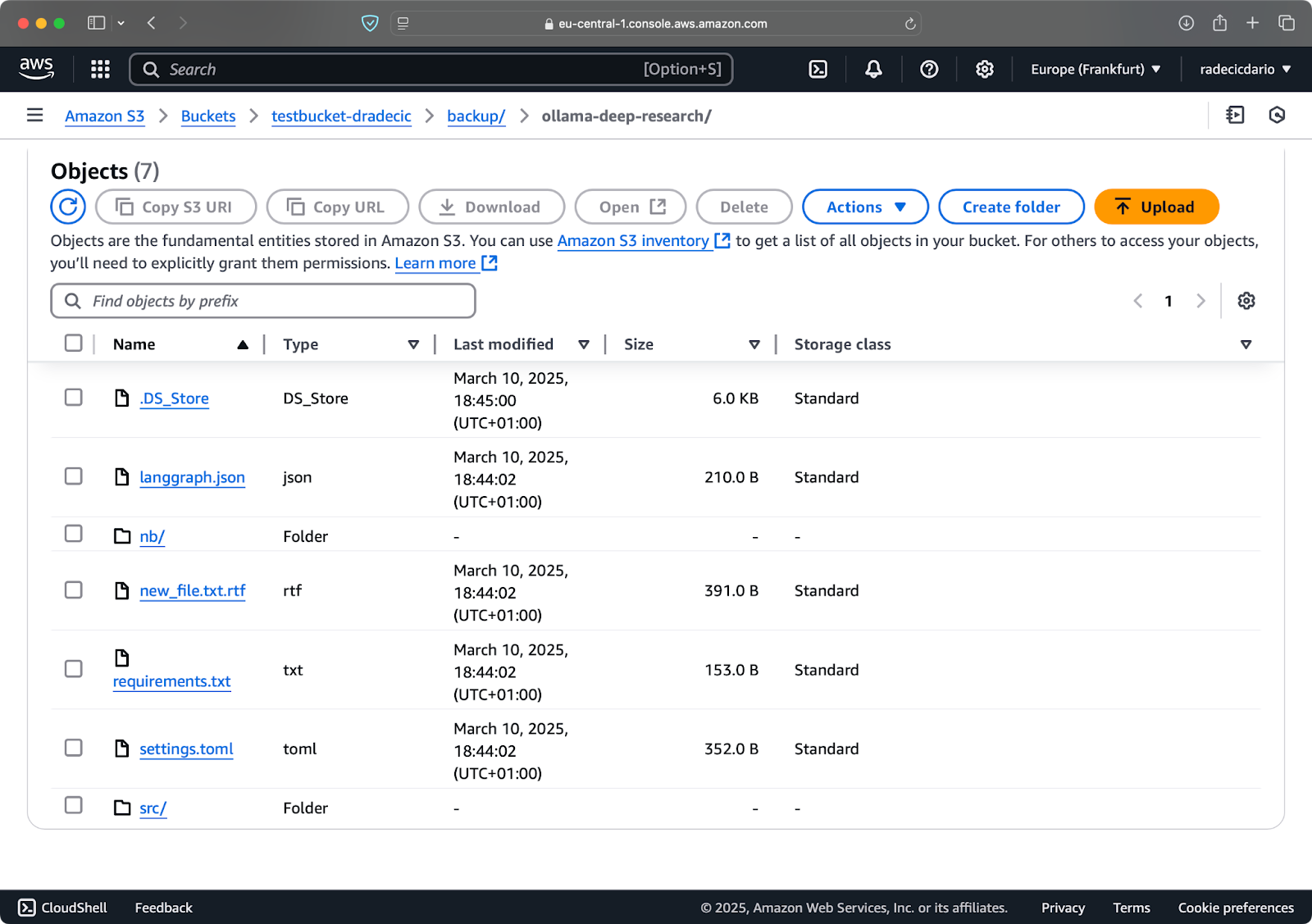
תמונה 16 – דגל מחיקה (2)
כפי שניתן לראות, הפקודה מסנכרנת לא רק קבצים חדשים ומשונים אלא גם מוחקת קבצים מתוך דלפק ה-S3 שכבר אינם קיימים בתיקייה המקומית.
הגדרת ריצת ניסיון עבור סנכרון בטוח
הפעולות המסוכנות ביותר של סנכרון S3 הן אלה הכוללות את הדגל --delete. כדי למנוע מחיקת קבצים חשובים בטעות, ניתן להשתמש בדגל --dryrun כדי לדמות את הפעולה ללא ביצוע שינויים בפועל:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup --delete --dryrun
כדי להדגים, מחקתי את הקבצים requirements.txt ו־settings.toml מתיקייה מקומית ואז ביצעתי את הפקודה:
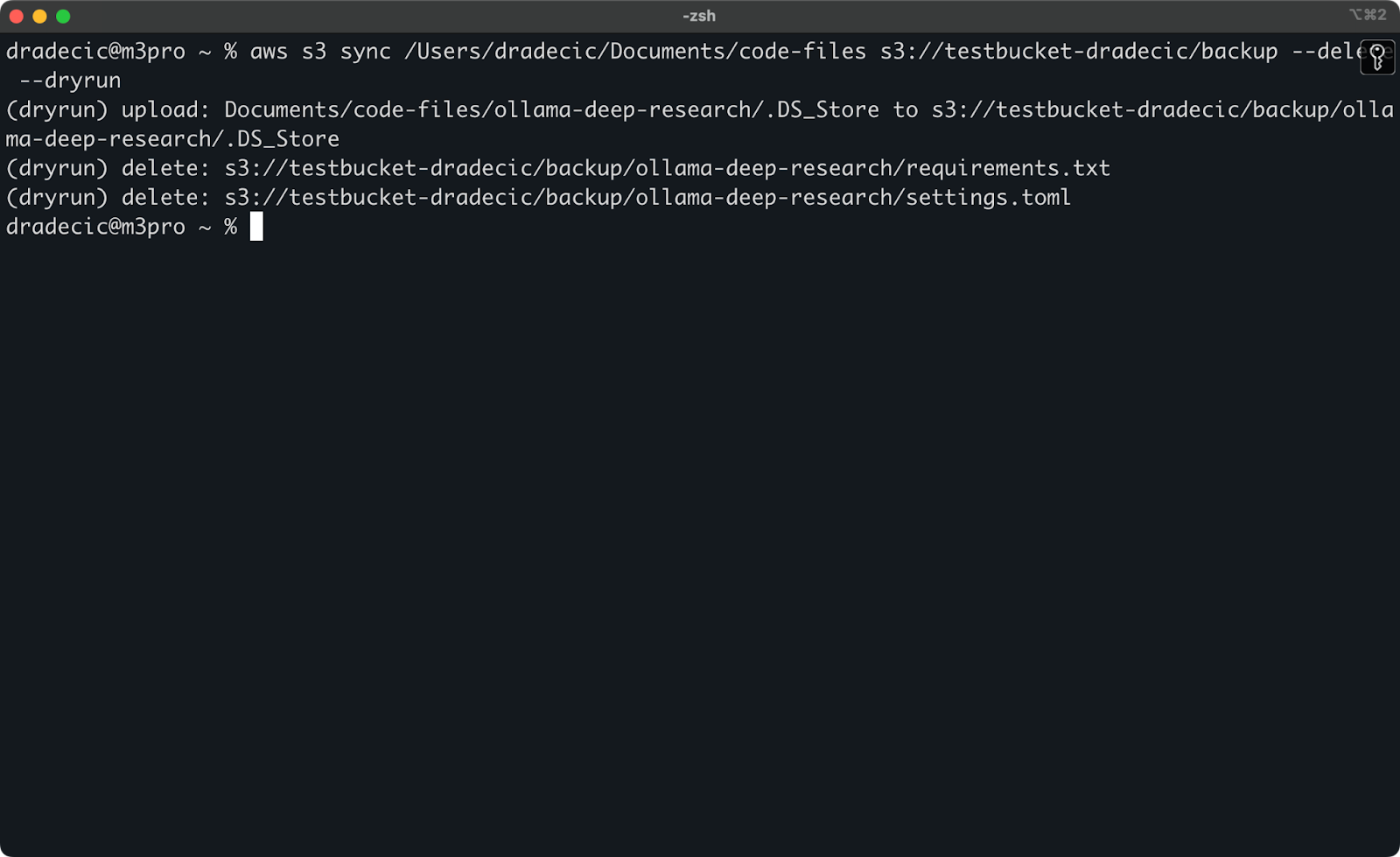
תמונה 17 – Dry run
כך תראה בדיוק מה יקרה אם תבצע את הפקודה בפועל, כולל אילו קבצים יועלו, יורדו או יימחקו.
אני תמיד ממליץ להשתמש ב־--dryrun לפני ביצוע כל פקודת סנכרון S3 עם הדגל --delete, במיוחד כאשר מדובר בנתונים חשובים.
ישנן המון אפשרויות נוספות זמינות עבור פקודת הסנכרון של S3, כמו --acl להגדרת הרשאות, --storage-class לבחירת שכבת אחסון ב-S3, ו־--recursive לעבור על תת־תיקיות. בדוק את מסמכי ה-CLI הרשמיים של AWS עבור רשימה מלאה של האפשרויות.
עכשיו שאתה מכיר את האפשרויות הבסיסיות והמתקדמות של סנכרון S3, בוא נראה כיצד להשתמש בפקודות אלו לתרגולים מעשיים כמו גיבויים ושחזורים.
שימוש ב-S3 Sync של AWS לצורך גיבוי ושחזור
אחת מתקיפות השימוש הפופולריות ביותר עבור הסנכרון של AWS S3 היא גיבוי קבצים חשובים ושחזורם כאשר נדרש. בוא נבדוק כיצד ניתן לממש אסטרטגיה פשוטה לגיבוי ושחזור באמצעות פקודת הסנכרון.
יצירת גיבויים ל-S3
יצירת גיבויים עם S3 sync היא פשוטה – אתה רק צריך להריץ את פקודת הסנכרון מהמדריך המקומי שלך לסל S3. עם זאת, יש כמה נהלים מומלצים לעקוב אחריהם כדי להבטיח גיבויים יעילים.
ראשית, זה רעיון טוב ללארגן את הגיבויים שלך לפי תאריך או גרסה. הנה גישה פשוטה שמשתמשת בחותמת זמן בנתיב S3:
# צור משתנה חותמת זמן TIMESTAMP=$(date +%Y-%m-%d-%H-%M-%S) # הרץ את הגיבוי aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backups/$TIMESTAMP
זה יוצר תיקייה חדשה עבור כל גיבוי עם חותמת זמן כמו 2025-03-10-18-56-42. הנה מה שתראה ב-S3:
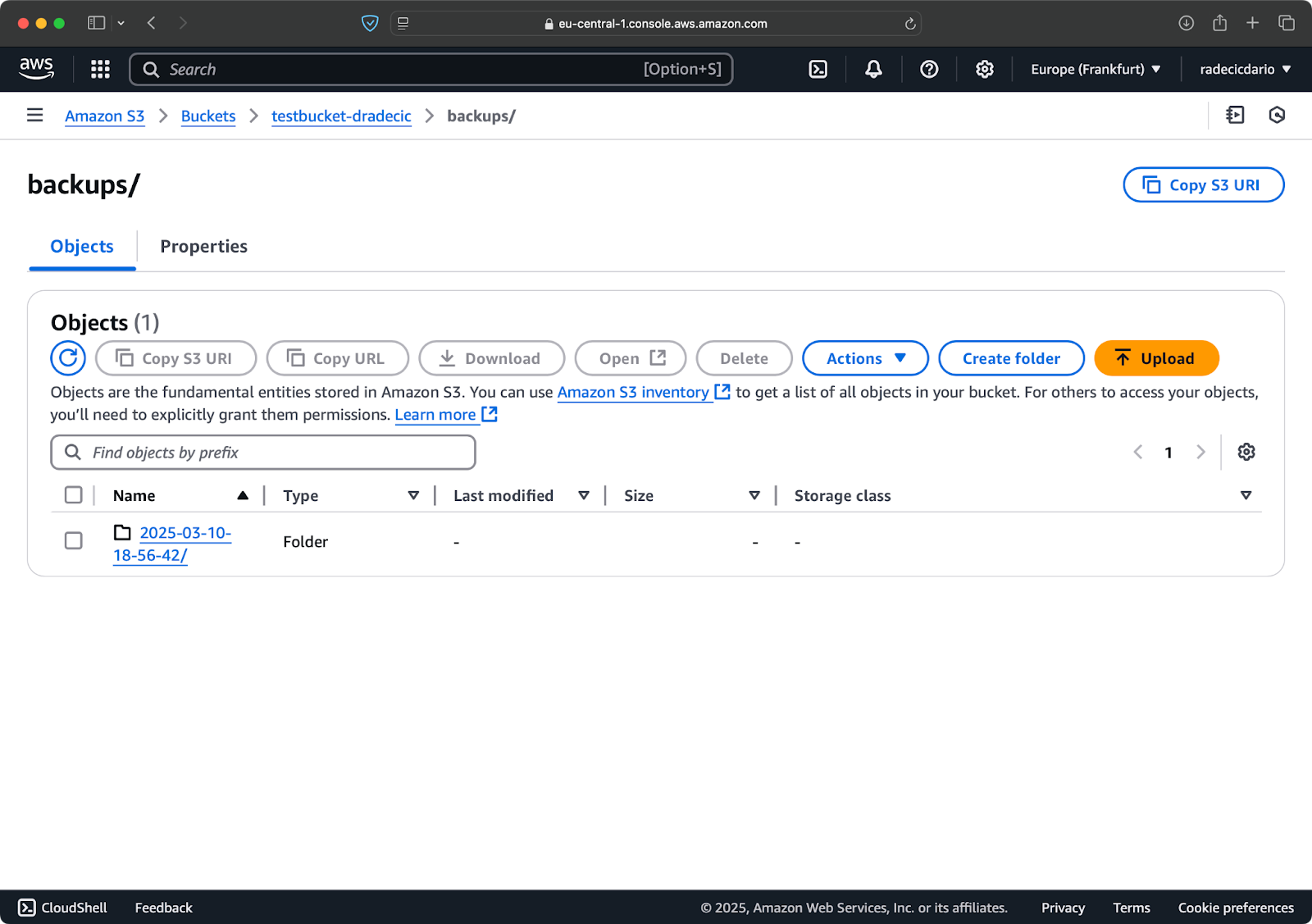
תמונה 18 – גיבויים עם חותמת זמן
לנתונים קריטיים, ייתכן שתרצה לשמור מספר גרסאות גיבוי. זה קל לעשות על ידי הרצת הגיבוי מבוסס החותמת זמן באופן קבוע.
אתה יכול גם להשתמש באפשרות --storage-class כדי לציין כיתה של אחסון שיותר משתלמת עבור הגיבויים שלך:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backups/$TIMESTAMP --storage-class STANDARD_IA
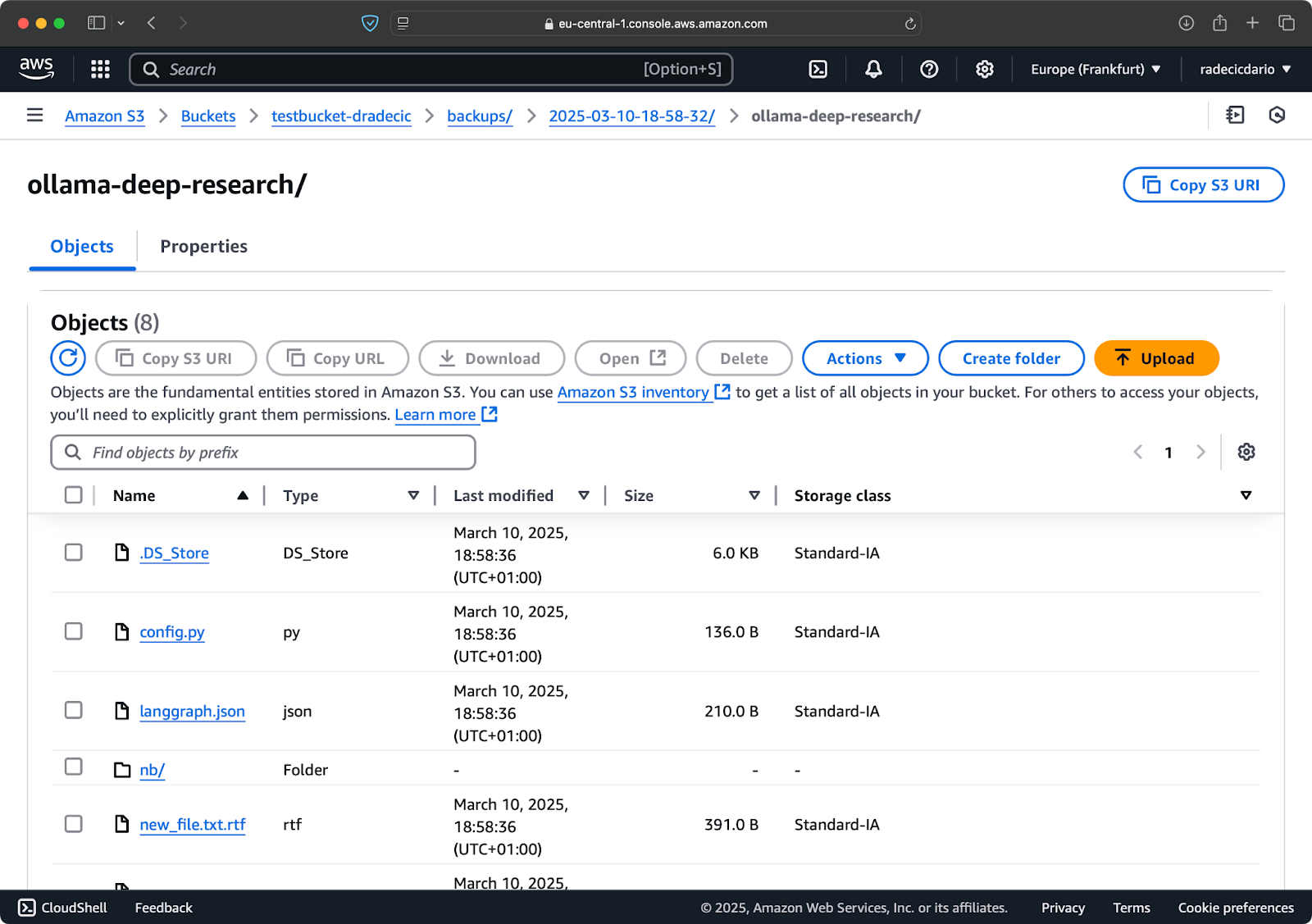
תמונה 19 – תוכן גיבוי עם כיתה של אחסון מותאמת
זה משתמש במחלקת אחסון S3 Infrequent Access, שעלותה נמוכה יותר אך כוללת תשלום קליטה קטן. לארכיון לטווח ארוך, אפשר גם להשתמש במחלקת אחסון Glacier:
aws s3 sync /Users/dradecic/Documents/important-data s3://testbucket-dradecic/backups/$TIMESTAMP --storage-class GLACIER
רק תשים לב שקבצים המאוחסנים ב-Glacier לוקחים שעות לשחזור, לכן הם לא מתאימים לנתונים שעשויים להיות נחוצים מהר.
שחזור קבצים מ-S3
שחזור מגיבוי פשוט בדיוק כמו – פשוט הפוך את המקור והיעד בפקודת הסנכרון שלך:
# שחזור מהגיבוי האחרון ביותר (בהנחה שאתה יודע את הזמן) aws s3 sync s3://testbucket-dradecic/backups/2025-03-10-18-56-42 /Users/dradecic/Documents/restored-data
זה יוריד את כל הקבצים מגיבוי זה לתיקיית restored-data במחשבך:
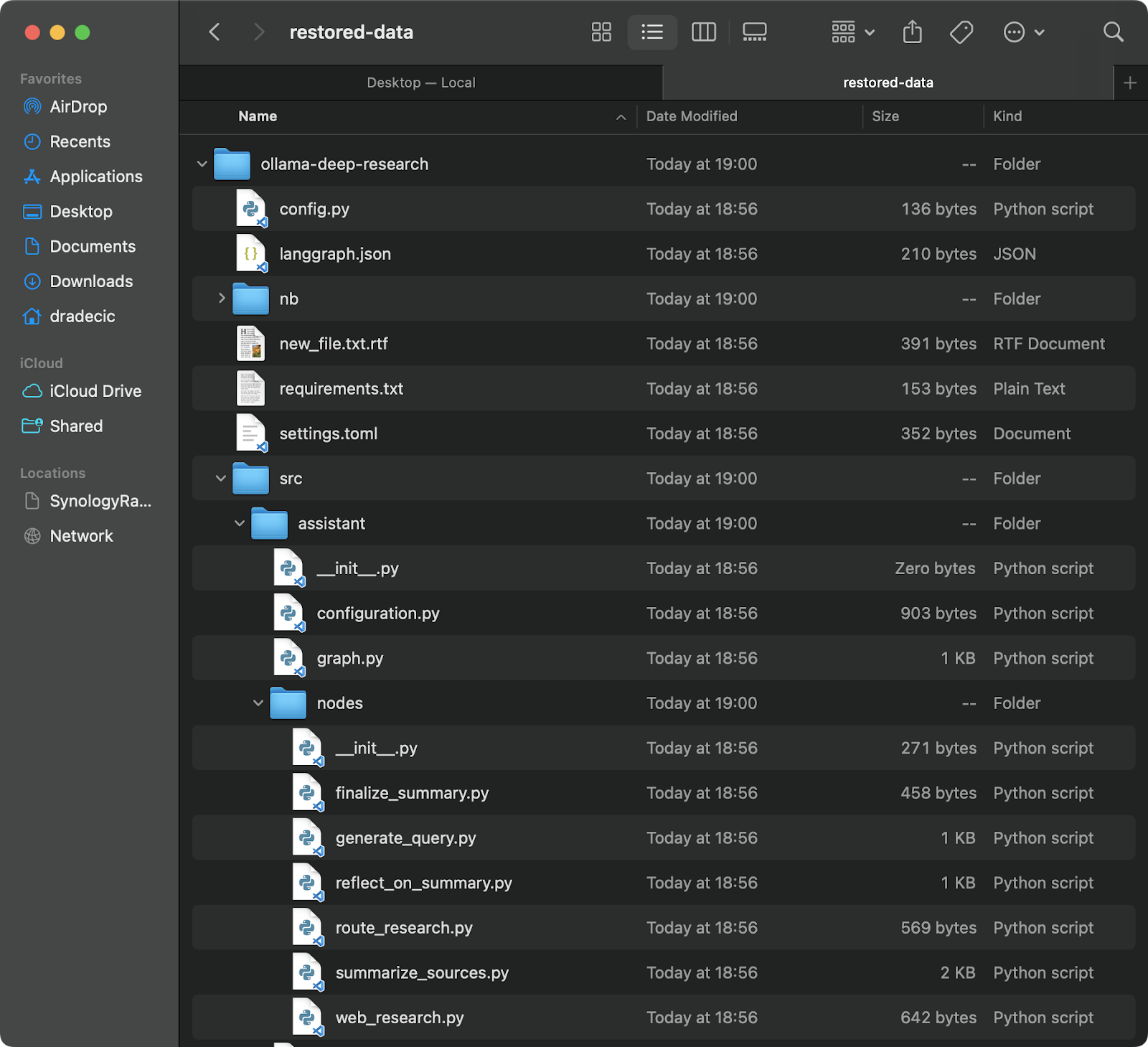
תמונה 20 – שחזור קבצים מ־S3
אם אין לך את הזמן המדויק, תוכל לרשום ראשית את כל הגיבויים שלך:
aws s3 ls s3://testbucket-dradecic/backups/
שיזהו לך משהו דומה לזה:
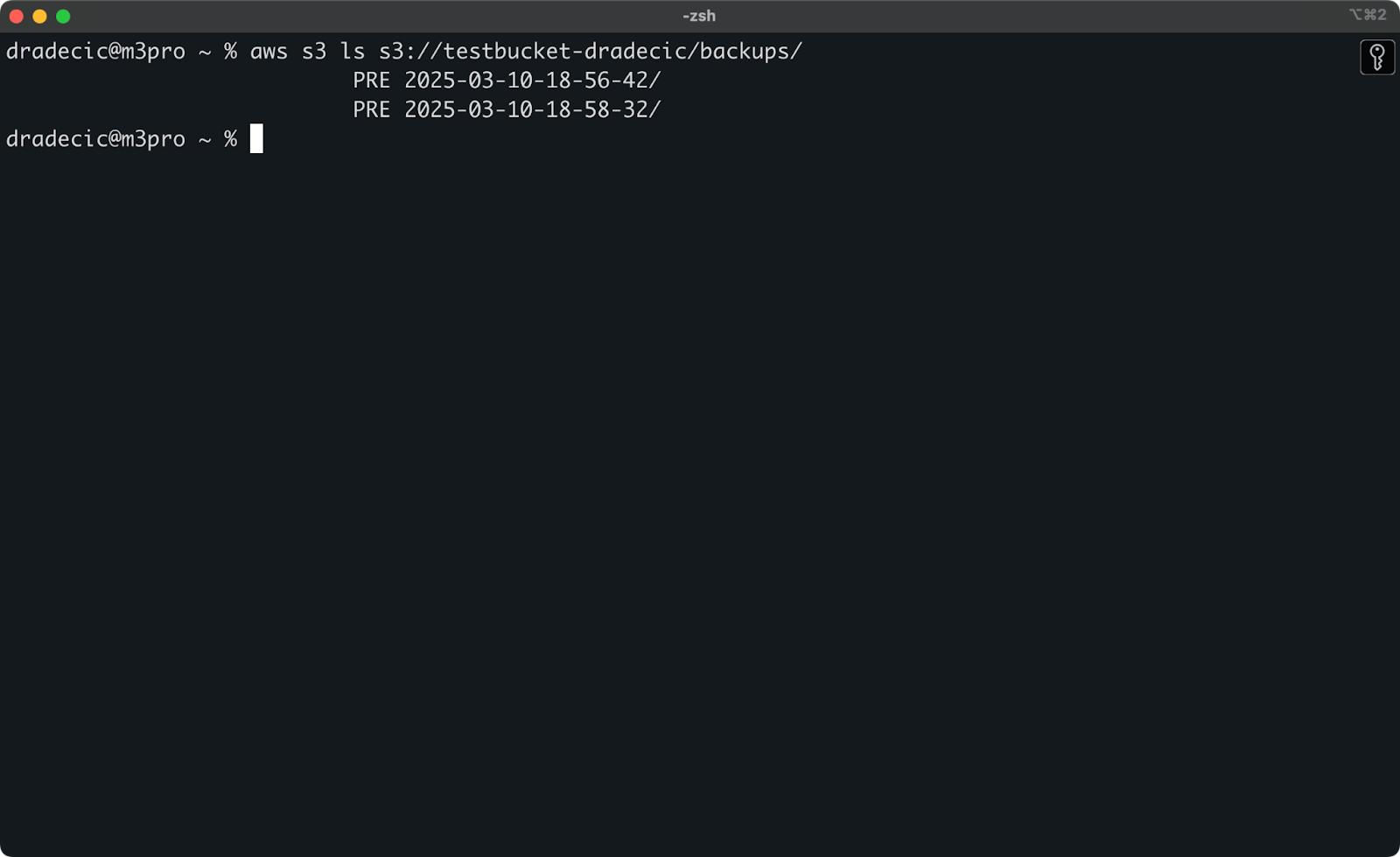
תמונה 21 – רשימת גיבויים
תוכל גם לשחזר קבצים או תיקיות ספציפיים מגיבוי באמצעות הדגלים של השולחן הלחמים והכללים שדנינו בהם קודם:
# לשחזר רק את קבצי התצורה aws s3 sync s3://testbucket-dradecic/backups/2025-03-10-18-56-42 /Users/dradecic/Documents/restored-configs --exclude "*" --include "*.config" --include "*.toml" --include "*.yaml"
עבור מערכות קריטיות למשימה, אני ממליץ להפעיל אוטומציה על הגיבויים שלך עם משימות מתוזמנות (כמו עבודות cron ב-Linux/macOS או מתזמן המשימות ב-Windows). זה מבטיח שתעשה גיבויים לנתונים שלך באופן עקבי בלי לצטרך לזכור לעשות זאת באופן ידני.
פתרון בעיות בסנכרון של AWS S3
כלי הסנכרון של AWS S3 הוא כלי אמין, אך לפעמים תיתקל בבעיות. עדיין, רוב השגיאות שתראה הן מבוססות על טעויות אנושיות.
שגיאות סנכרון נפוצות
בואו נעבור על כמה בעיות נפוצות ואת הפתרונות שלהן.
- שגיאת גישה נדחית כללית רומזת שהמשתמש שלך ב- IAM אינו מספיקה לו ההרשאות הנדרשות לגישה לדלת S3 או לביצוע פעולות ספציפיות. כדי לתקן זאת, נסה אחת מהאפשרויות הבאות:
- בדוק שיש למשתמש IAM הרשאות S3 המתאימות (
s3:ListBucket,s3:GetObject,s3:PutObject). - וודא שמדיניות האמצעי איננה מורידה במפורש גישה למשתמש שלך.
- ודא שהדלי עצמו לא חוסם גישה ציבורית אם נדרשות פעולות ציבוריות.
- אין קובץ או ספרייה השגיאה מופיעה בדרך כלל כאשר הנתיב המקורי שציינת בפקודת הסנכרון אינו קיים. הפתרון פשוט – בדוק בצורה כפולה את הנתיבים שלך וודא שהם קיימים. התכוונן במיוחד לשגיאות כתיב בשמות הדליים או בספריות המקומיות.
- מגבלת גודל קובץ שגיאות יכולות להתרחש כאשר אתה רוצה לסנכרן קבצים גדולים. ברירת המחדל של S3 sync יכולה להתמודד עם קבצים בגודל של עד 5GB. עבור קבצים גדולים יותר, תיתקל בזמני חכות או העברות חסרות.
- עבור קבצים הגדולים מ-5GB, עליך להשתמש בדגל
--only-show-errorsבשילוב עם הדגל--size-only. השילוב הזה עוזר בהעברת קבצים גדולים על ידי צמצום הפלט והשוואה רק של גדלי הקבצים:
aws s3 sync /Users/dradecic/large-files s3://testbucket-dradecic/large-files --only-show-errors --size-only
אופטימיזציה של ביצועי סנכרון
אם ה-S3 sync שלך פועל לאט יותר מהצפוי, ישנם כמה שיפורים שאתה יכול לעשות כדי להאיץ את הדברים.
- השתמש בהעברות מקבילות. כברירת מחדל, S3 sync משתמש במספר מוגבל של פעולות מקבילות. אתה יכול להגדיל זאת באמצעות הפרמטר
--max-concurrent-requests:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup --max-concurrent-requests 20
- התאם את גודל החתיכות. עבור קבצים גדולים, אתה יכול לייעל את מהירות ההעברה על ידי התאמת גודל החתיכות. זה מפרק קבצים גדולים לחתיכות של 16MB במקום 8MB בברירת המחדל, מה שיכול להיות מהיר יותר עבור חיבורים איכותיים:
aws s3 sync /Users/dradecic/large-files s3://testbucket-dradecic/backup --cli-read-timeout 120 --multipart-threshold 64MB --multipart-chunksize 16MB
- השתמש ב
--no-progressעבור סקריפטים. אם אתה מריץ S3 sync בסקריפט אוטומטי, השתמש בדגל--no-progressכדי לצמצם את הפלט ולשפר את הביצועים:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup --no-progress
- השתמש בנקודות קצה מקומיות. אם משאבי ה־AWS שלך נמצאים באותה אזור, ציון הנקודה האזורית עשוי להפחית את זמן התגובה:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup --endpoint-url https://s3.eu-central-1.amazonaws.com
האופטימיזציות הללו עשויות לשפר באופן משמעותי את ביצועי הסנכרון, במיוחד בהעברות נתונים גדולות או כאשר מריצים על מכונות פחות עוצמתיות.
אם עדיין נתקלים בבעיות לאחר ניסיון פתרון אלו, יש ל־AWS CLI אפשרות ניפוי שגיאות מובנית. יש להוסיף פשוט את --debug לפקודתך כדי לראות מידע מפורט על מה שקורה במהלך תהליך הסנכרון:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup --debug
צפו בהודעות לוג מפורטות רבות, דומות לאלו:
תמונה 22 – מפעיל את הסנכרון במצב ניפוי שגיאות
וכך זה בערך כשמדובר בפתרון בעיות בסנכרון של AWS S3. כמובן, ישנם שגיאות אחרות שעשויות להתרחש, אך 99% מהזמן, תמצאו את הפתרון בסעיף זה.
סיכום של סנכרון של AWS S3
כדי לסכם, סנכרון של AWS S3 הוא אחד מהכלים המיוחדים שהם גם פשוטים לשימוש וגם עוצמתיים ביותר. למדתם הכל מפקודות בסיסיות עד אפשרויות מתקדמות, אסטרטגיות גיבוי וטיפים לפתרון בעיות.
עבור מפתחי תוכנה, מנהלי מערכות או כל אדם העובד עם AWS, פקודת ה-S3 sync היא כלי חיוני – היא חוסכת זמן, מפחיתה את שימוש הרוחב פס ומבטיחה שהקבצים שלך נמצאים במקום שאתה צריך אותם, כאשר אתה זקוק אליהם.
בין אם אתה עושה גיבוי לנתונים חיוניים, פותח נכסים אינטרנטיים או פשוט שומר על סינכרון של סביבות שונות, סנכרון של AWS S3 הופך את התהליך לפשוט ואמין.
הדרך הטובה ביותר להתחיל להרגיש בנוח עם הסנכרון של S3 היא להתחיל להשתמש בו. נסה להגדיר פעולת סנכרון פשוטה עם הקבצים שלך, ואז לחקות על האפשרויות המתקדמות בהדרגה כדי להתאים אותן לצרכים הספציפיים שלך.
זכור להשתמש תמיד ב---dryrun תחילה כאשר אתה עובד עם נתונים חשובים, במיוחד כאשר משתמשים בדגל --delete. זה טוב יותר לקחת דקה נוספת כדי לוודא מה יקרה מאשר למחוק בטעות קבצים חשובים.
כדי ללמוד עוד על AWS, בדוק את הקורסים האלה של DataCamp:
ניתן גם להשתמש ב-DataCamp כדי להתכונן למבחני התעוזה של AWS – מאמץ הענן של AWS (CLF-C02).