













Configuración de la AWS CLI y AWS S3
Antes de poder empezar a sincronizar archivos con S3, necesitarás configurar y ajustar el AWS CLI adecuadamente. Esto puede sonar intimidante si eres nuevo en AWS, pero solo tomará un par de minutos.
Configurar el CLI implica dos pasos principales: instalar la herramienta y configurarla. A continuación, explicaré ambos pasos.
Instalación del AWS CLI
La instalación del AWS CLI varía ligeramente dependiendo de tu sistema operativo.
Para sistemas Windows:
- Ve a la página de descarga de AWS CLI
- Descarga el instalador de Windows (64 bits)
- Ejecuta el instalador y sigue las indicaciones
Para sistemas Linux:
Ejecuta los siguientes tres comandos a través de la Terminal:
curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip" unzip awscliv2.zip sudo ./aws/install
Para sistemas macOS:
Suponiendo que tienes Homebrew instalado, ejecuta esta línea desde la Terminal:
brew install awscli
Si no tienes Homebrew, utiliza estos dos comandos en su lugar:
curl "https://awscli.amazonaws.com/AWSCLIV2.pkg" -o "AWSCLIV2.pkg" sudo installer -pkg AWSCLIV2.pkg -target /
Puedes ejecutar el comando aws --version en todos los sistemas operativos para verificar que AWS CLI fue instalado. Esto es lo que deberías ver:
Imagen 1 – Versión de AWS CLI
Configurando el AWS CLI
Ahora que tienes el CLI instalado, necesitas configurarlo con tus credenciales de AWS.
Suponiendo que ya tienes una cuenta de AWS, inicia sesión y ve al servicio IAM. Una vez allí, crea un nuevo usuario con acceso programático. Debes asignar el permiso apropiado al usuario, que es acceso a S3 como mínimo:
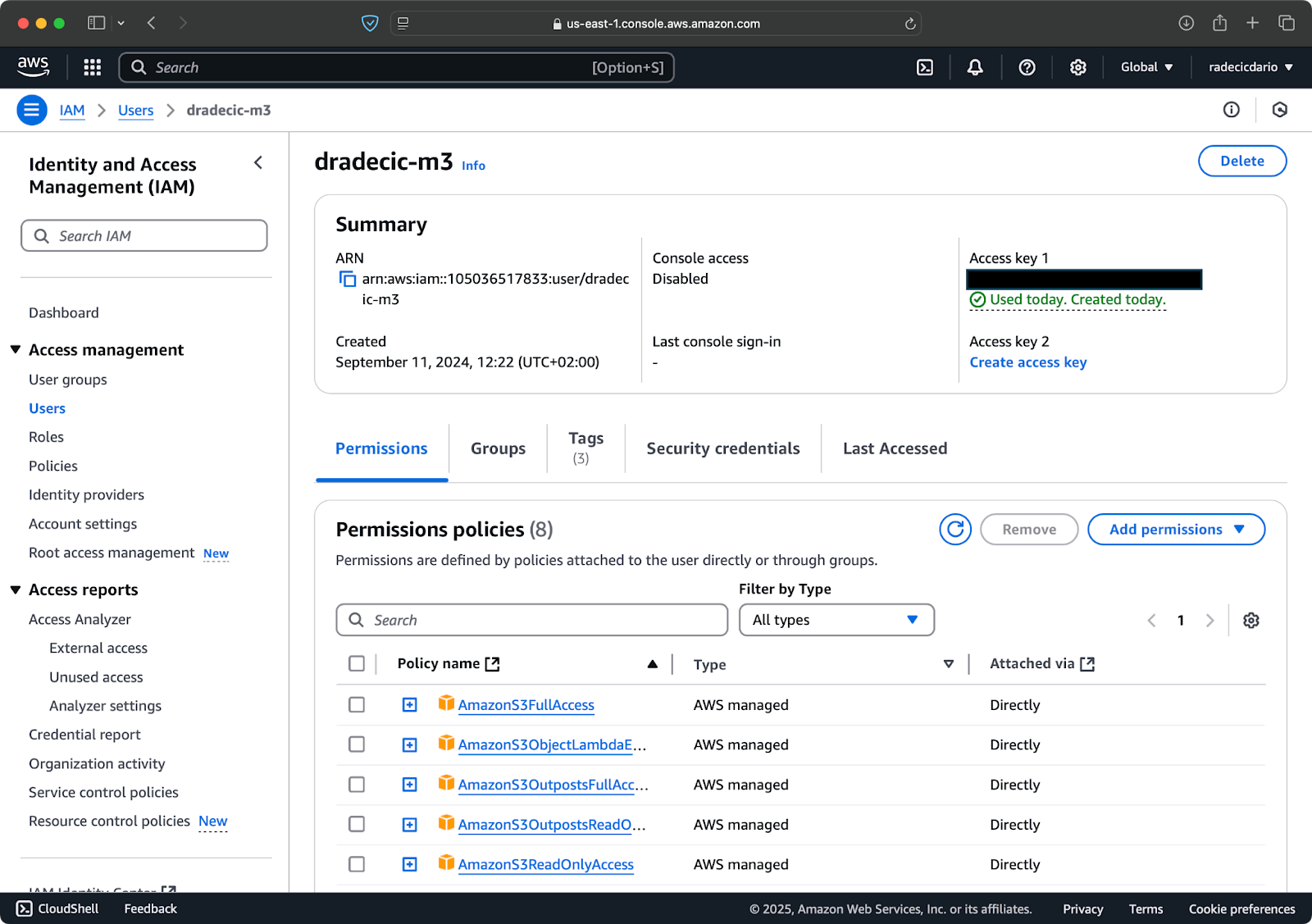
Imagen 2: Usuario IAM de AWS
Una vez hecho esto, ve a “Credenciales de seguridad” para crear una nueva clave de acceso. Después de crearla, tendrás tanto la ID de la clave de acceso como la clave de acceso secreta. Apúntalas en un lugar seguro porque no podrás acceder a ellas en el futuro:
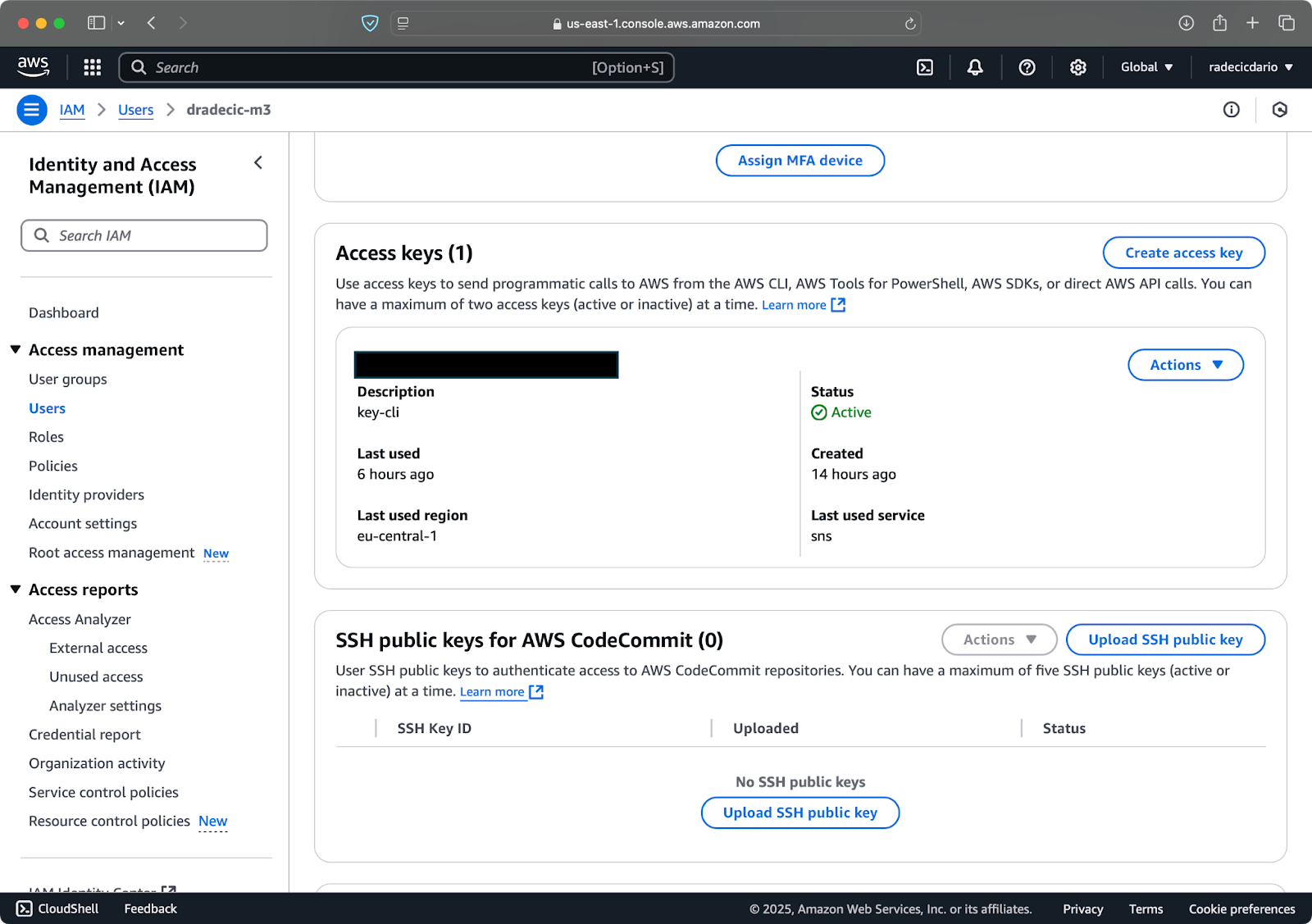
Imagen 3: Credenciales de usuario IAM de AWS
De vuelta en la Terminal, ejecuta el comando aws configure. Te pedirá que ingreses tu ID de clave de acceso, clave de acceso secreta, región (eu-central-1 en mi caso) y formato de salida preferido (json):
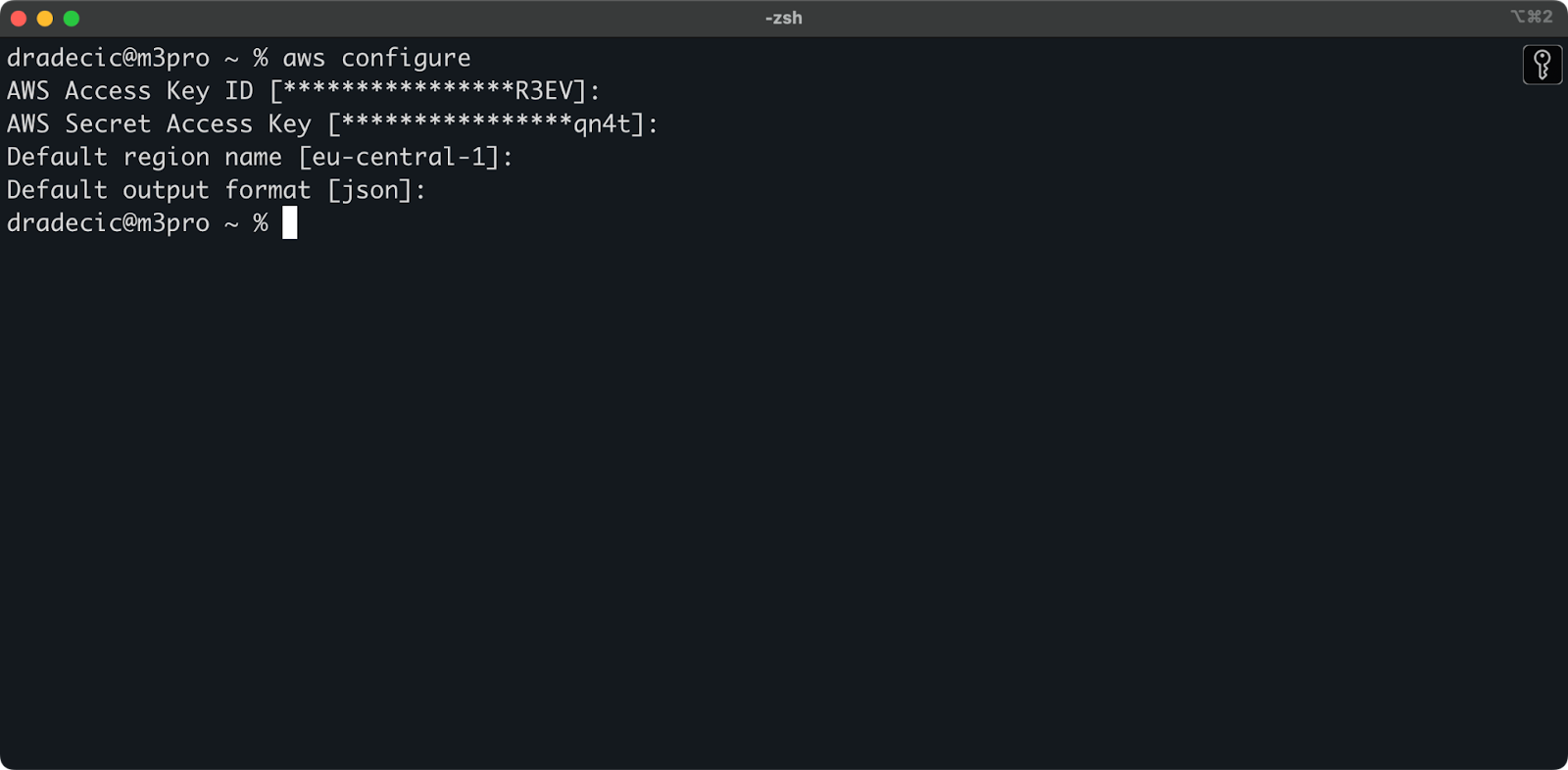
Imagen 4 – Configuración de AWS CLI
Para verificar que estás conectado correctamente a tu cuenta de AWS desde la CLI, ejecuta el siguiente comando:
aws sts get-caller-identity
Este es el resultado que deberías ver:
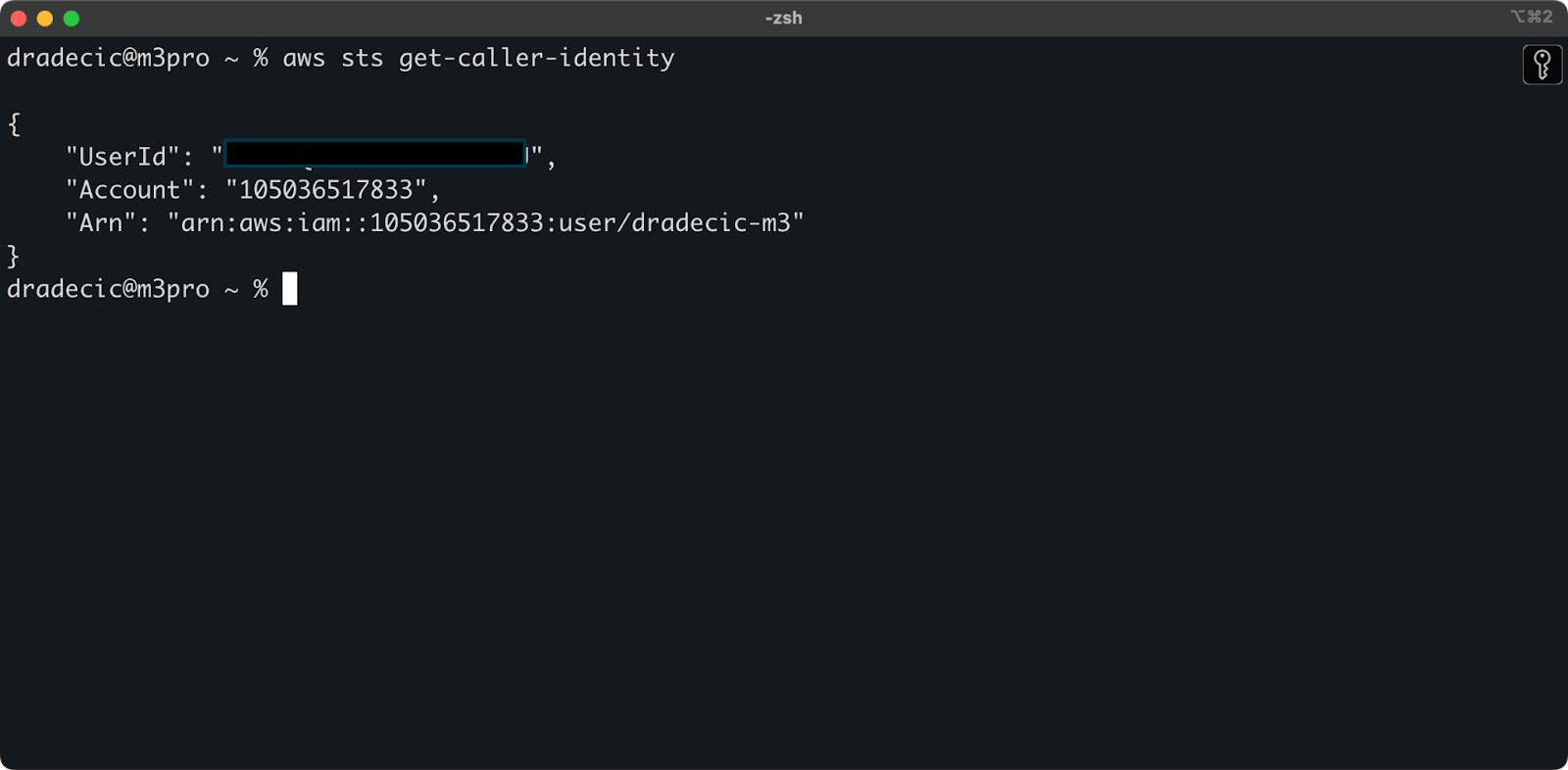
Imagen 5 – Comando de prueba de conexión AWS CLI
¡Y eso es todo, solo un paso más antes de que puedas empezar a usar el comando de sincronización de S3!
Configuración de un bucket de AWS S3
El paso final es crear un bucket S3 que almacenará tus archivos sincronizados. Puedes hacerlo desde la CLI o desde la Consola de Administración de AWS. Optaré por esta última, solo para variar un poco.
Para empezar, ve a la página del servicio S3 en la Consola de Administración y haz clic en el botón “Crear bucket”. Una vez allí, elige un nombre de bucket único (único a nivel global en todo AWS) y luego desplázate hacia abajo y haz clic en el botón “Crear”:
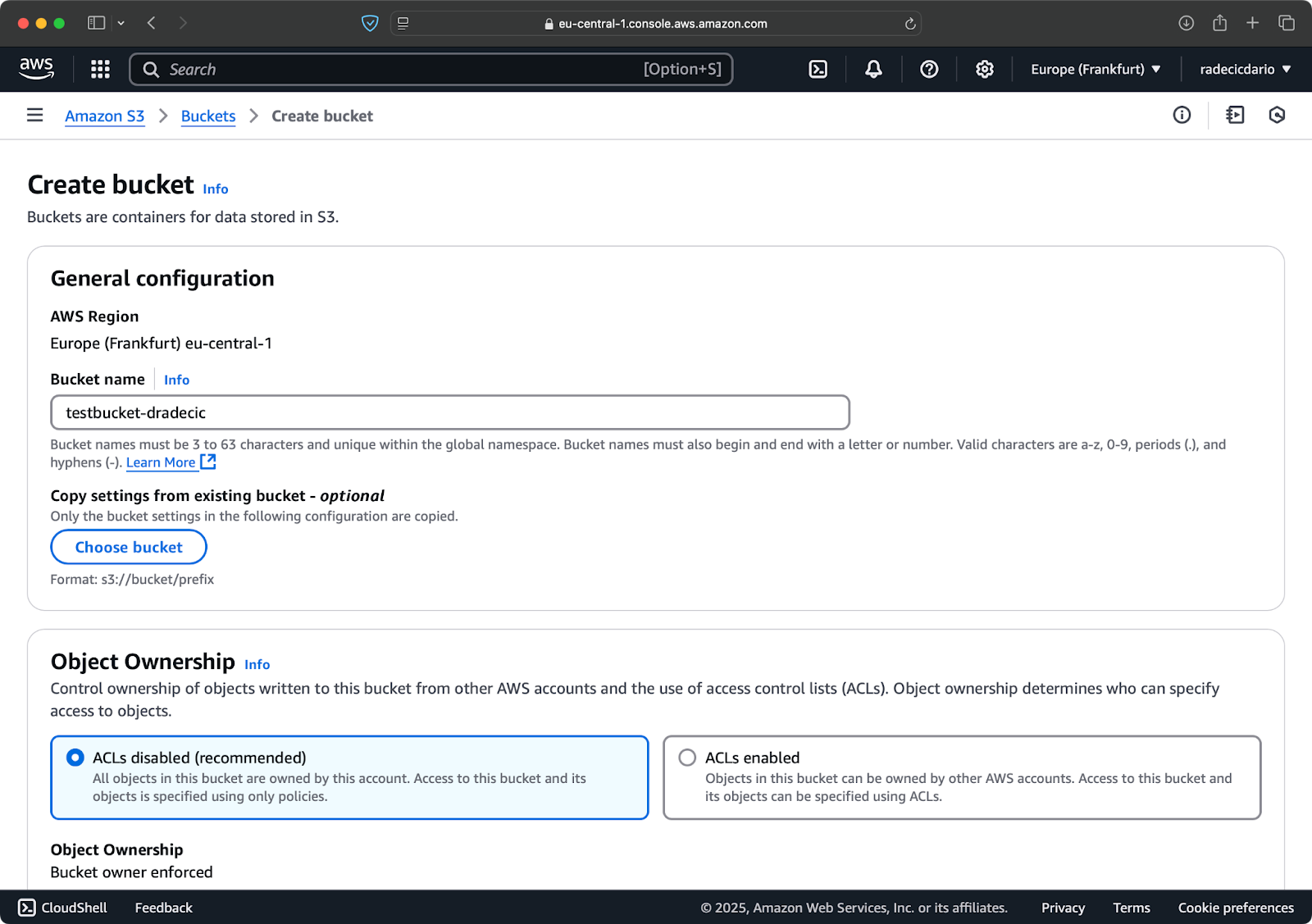
Imagen 6 – Creación de bucket AWS
El bucket ha sido creado y lo verás inmediatamente en la consola de administración. También puedes verificar que se haya creado a través de la CLI:
aws s3 ls
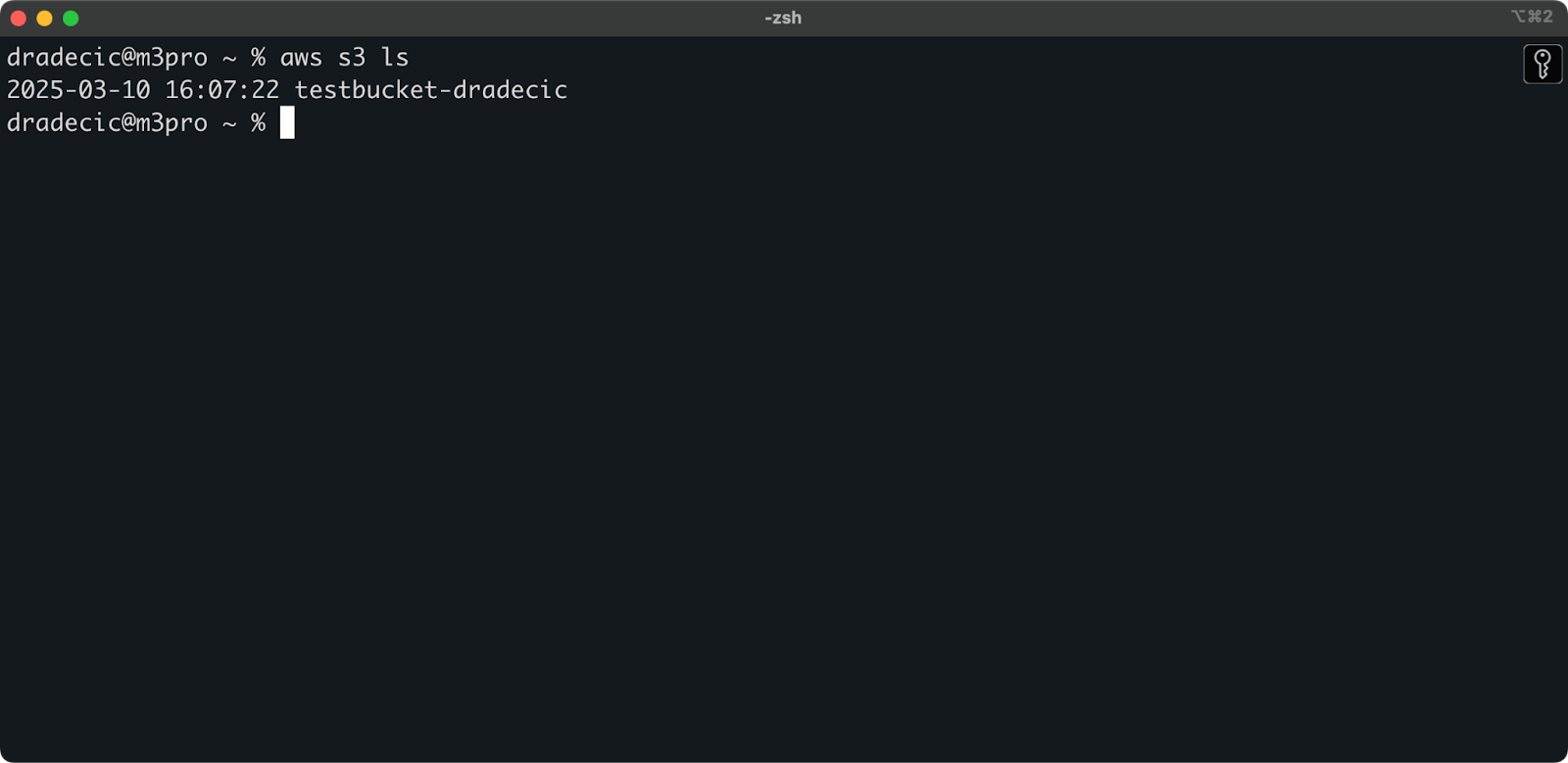
Imagen 7 – Todos los buckets S3 disponibles
Ten en cuenta que los buckets de S3 son privados por defecto. Si planeas usar el bucket para alojar archivos públicos (como activos de un sitio web), deberás ajustar las políticas y permisos del bucket en consecuencia.
¡Ahora estás listo y preparado para empezar a sincronizar archivos entre tu máquina local y AWS S3!
Comando básico de sincronización de AWS S3
Ahora que tienes instalada la AWS CLI, configurada y un bucket de S3 listo para usar, ¡es hora de empezar a sincronizar! La sintaxis básica del comando de sincronización de AWS S3 es bastante sencilla. Permíteme mostrarte cómo funciona.
El comando de sincronización de S3 sigue este patrón simple:
aws s3 sync <source> <destination> [options]
Tanto la fuente como el destino pueden ser una ruta de directorio local o una URI de S3 (que comienza con s3://). Dependiendo de la dirección en la que desee sincronizar, los organizará de manera diferente.
Sincronización de archivos desde local a un bucket de S3
Recientemente estuve experimentando con la investigación profunda de Ollama. Digamos que esa es la carpeta que quiero sincronizar con S3. El directorio principal está ubicado bajo la carpeta Documents. Así es como se ve:
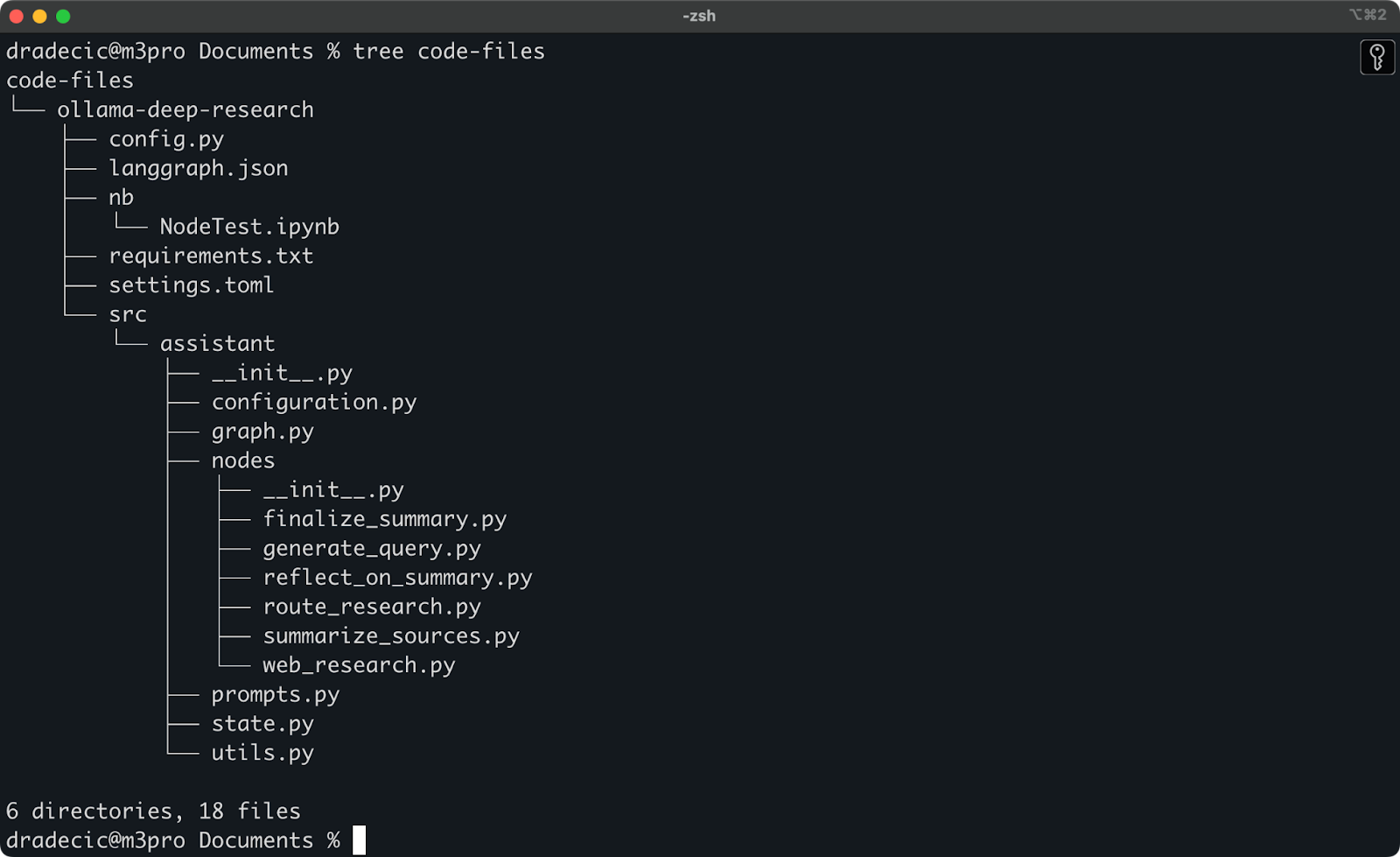
Contenidos de la carpeta local
Este es el comando que debo ejecutar para sincronizar la carpeta local code-files con la carpeta backup en el bucket de S3:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup
La carpeta backup en el bucket de S3 se creará automáticamente si no existe.
Esto es lo que verás impreso en la consola:
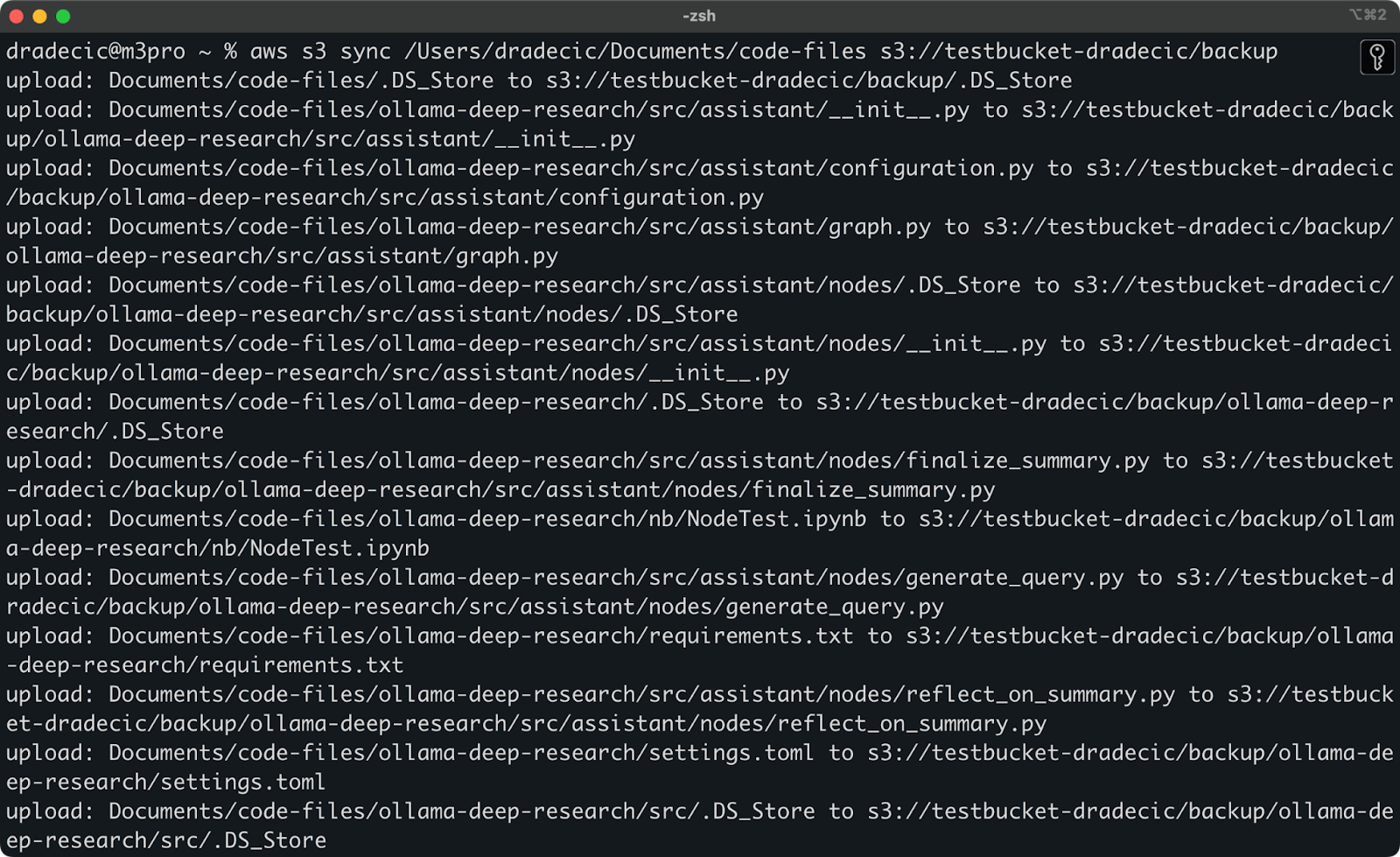
Imagen 9 – Proceso de sincronización S3
Después de un par de segundos, el contenido de la carpeta local code-files estará disponible en el bucket de S3:
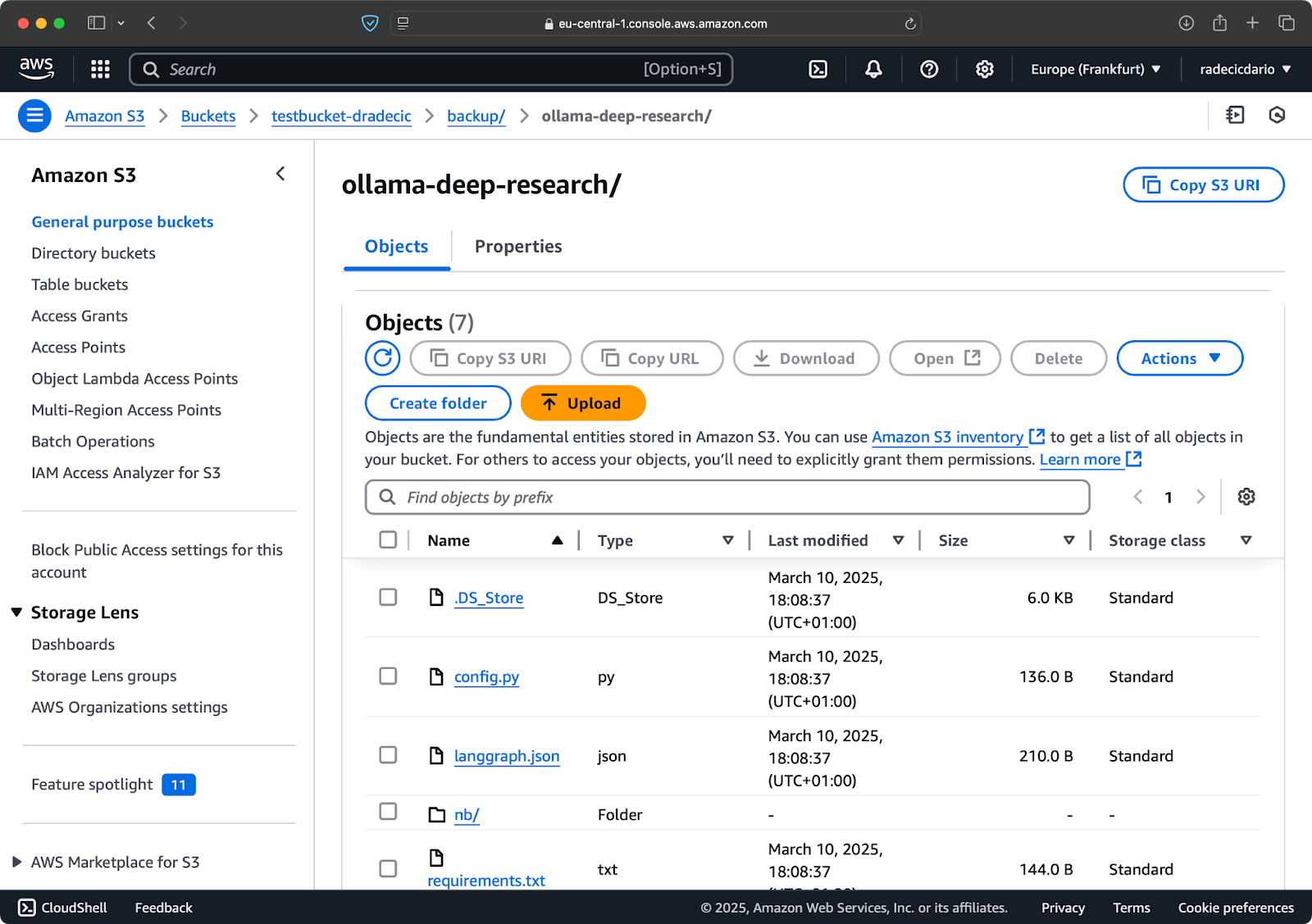
Imagen 10 – Contenido del bucket de S3
La belleza de la sincronización S3 es que solo sube archivos que no existen en el destino o que han sido modificados localmente. Si ejecutas el mismo comando nuevamente sin cambiar nada, verás… ¡nada! Eso es porque AWS CLI detectó que todos los archivos ya están sincronizados y actualizados.
Ahora, haré dos pequeños cambios: crearé un nuevo archivo (new_file.txt) y actualizaré uno existente (requirements.txt). Cuando ejecutes el comando de sincronización nuevamente, solo se subirán los archivos nuevos o modificados:
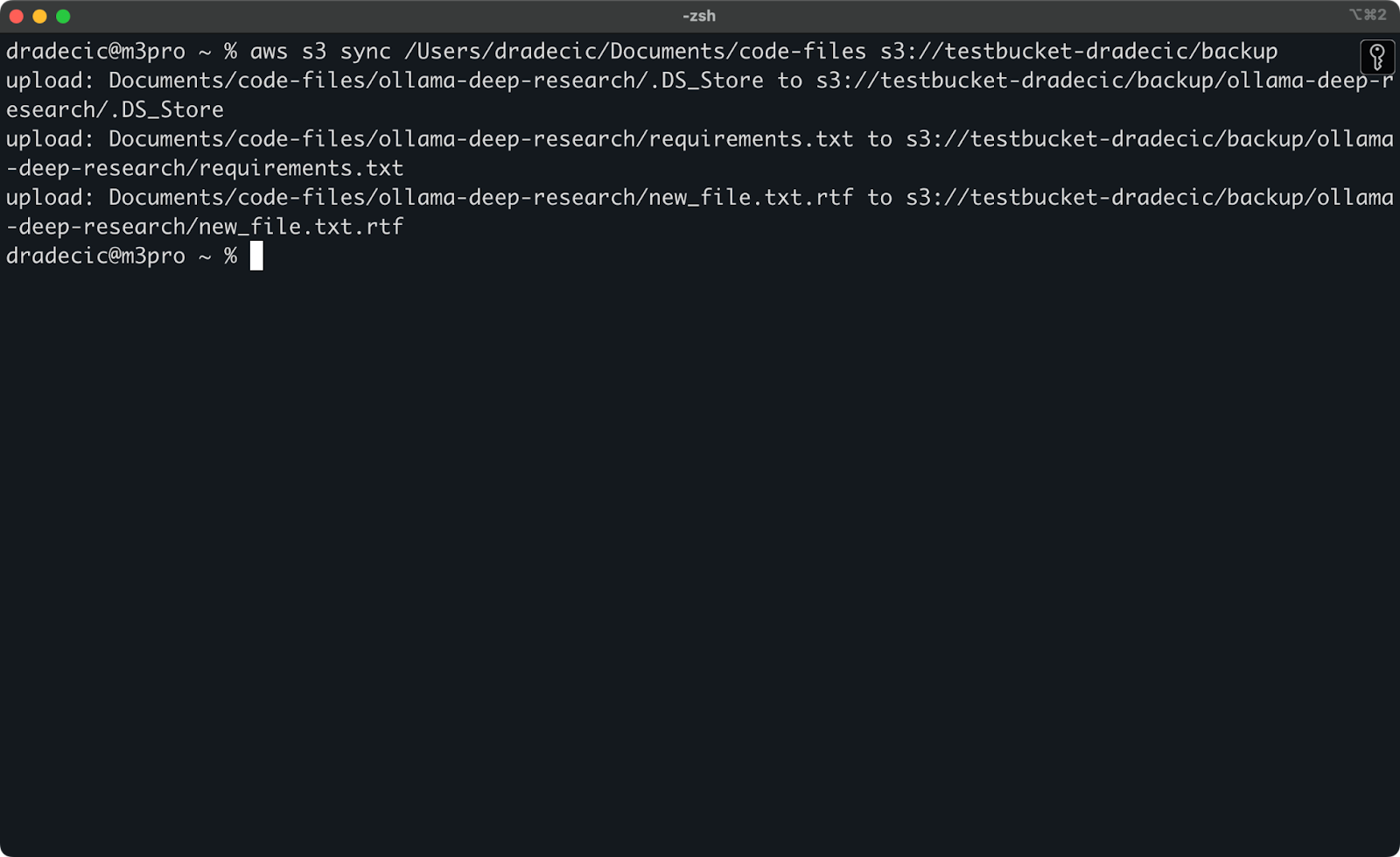
Imagen 11 – Proceso de sincronización S3 (2)
Y eso es todo lo que necesitas saber al sincronizar carpetas locales con S3. ¿Pero qué pasa si quieres hacerlo en la dirección opuesta?
Sincronización de archivos desde el bucket de S3 a un directorio local
Si deseas descargar archivos de tu bucket de S3 a tu máquina local, simplemente invierte el origen y el destino:
aws s3 sync s3://testbucket-dradecic/backup /Users/dradecic/Documents/code-files-from-s3
Este comando descargará todos los archivos de la carpeta backup en tu bucket de S3 a una carpeta local llamada code-files-from-s3. Nuevamente, si la carpeta local no existe, la CLI la creará por ti:
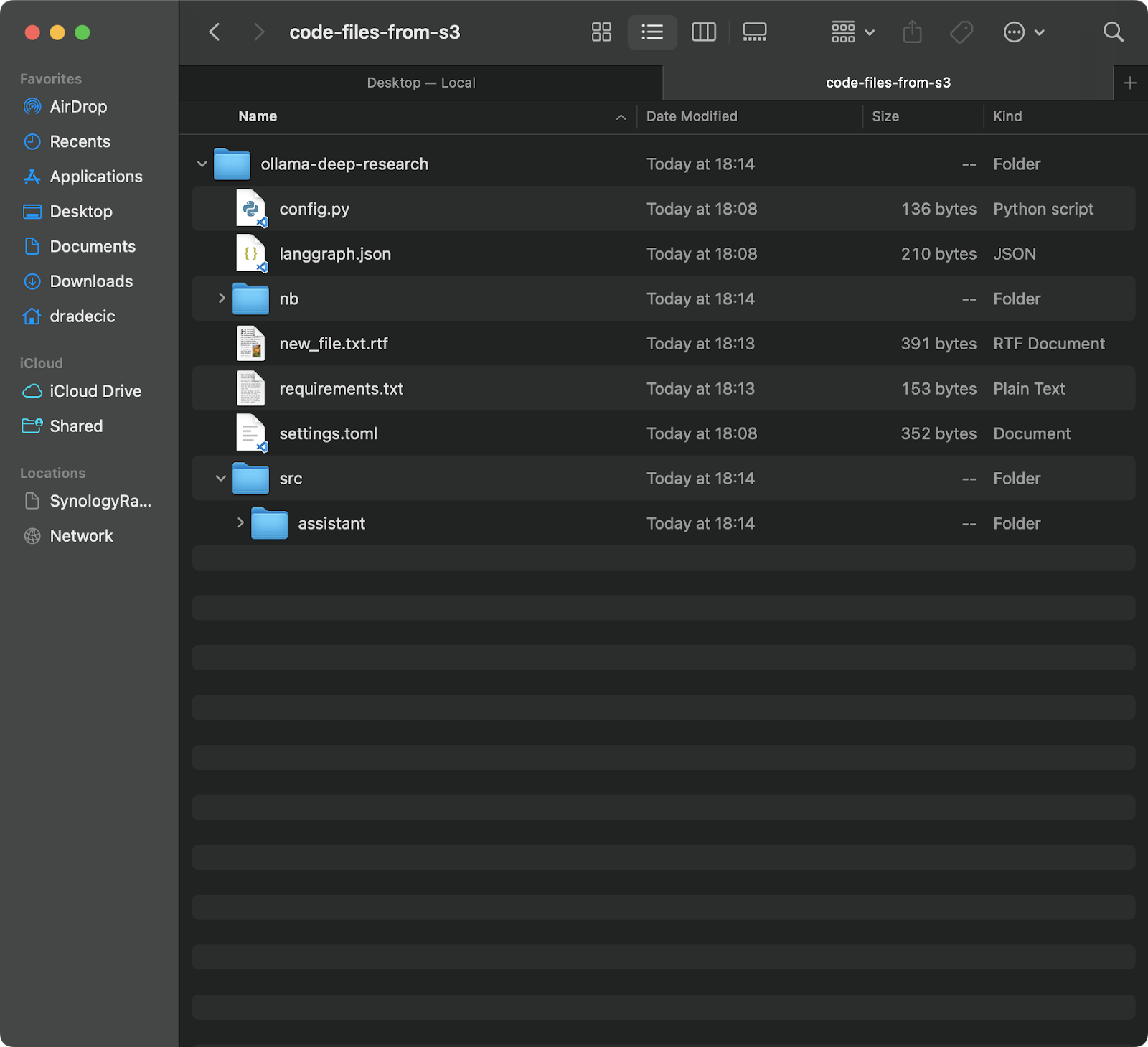
Imagen 12 – Sincronización de S3 a local
Vale la pena señalar que la sincronización de S3 no es bidireccional. Siempre va de la fuente al destino, haciendo que el destino coincida con la fuente. Si eliminas un archivo localmente y luego lo sincronizas con S3, seguirá existiendo en S3. De manera similar, si eliminas un archivo en S3 y sincronizas de S3 a local, el archivo local permanecerá intacto.
Si deseas que el destino coincida exactamente con la fuente (incluidas las eliminaciones), deberás usar la bandera --delete, la cual cubriré en la sección de opciones avanzadas.
Opciones Avanzadas de Sincronización de AWS S3
El comando básico de sincronización de S3 explorado anteriormente es poderoso por sí solo, pero AWS lo ha dotado de opciones adicionales que te brindan más control sobre el proceso de sincronización.
En esta sección, te mostraré algunas de las banderas más útiles que puedes agregar al comando básico.
Sincronizando solo archivos nuevos o modificados
Por defecto, S3 sync utiliza un mecanismo de comparación básico que verifica el tamaño del archivo y el tiempo de modificación para determinar si un archivo necesita ser sincronizado. Sin embargo, este enfoque puede no capturar siempre todos los cambios, especialmente cuando se trata de archivos que han sido modificados pero que mantienen el mismo tamaño.
Para una sincronización más precisa, puedes usar la bandera --exact-timestamps:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup --exact-timestamps
Esto fuerza la sincronización de S3 a comparar las marcas de tiempo con una precisión hasta los milisegundos. Ten en cuenta que el uso de esta bandera podría ralentizar ligeramente el proceso de sincronización, ya que requiere comparaciones más detalladas.
Exclusión o inclusión de archivos específicos
A veces, no deseas sincronizar cada archivo en un directorio. Tal vez quieras excluir archivos temporales, logs o ciertos tipos de archivo (como .DS_Store en mi caso). Ahí es donde resultan útiles las banderas --exclude y --include.
Pero para ilustrar un punto, digamos que quiero sincronizar mi directorio de código pero excluir todos los archivos Python:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup --exclude "*.py"
Ahora, muchos menos archivos se sincronizan con S3:
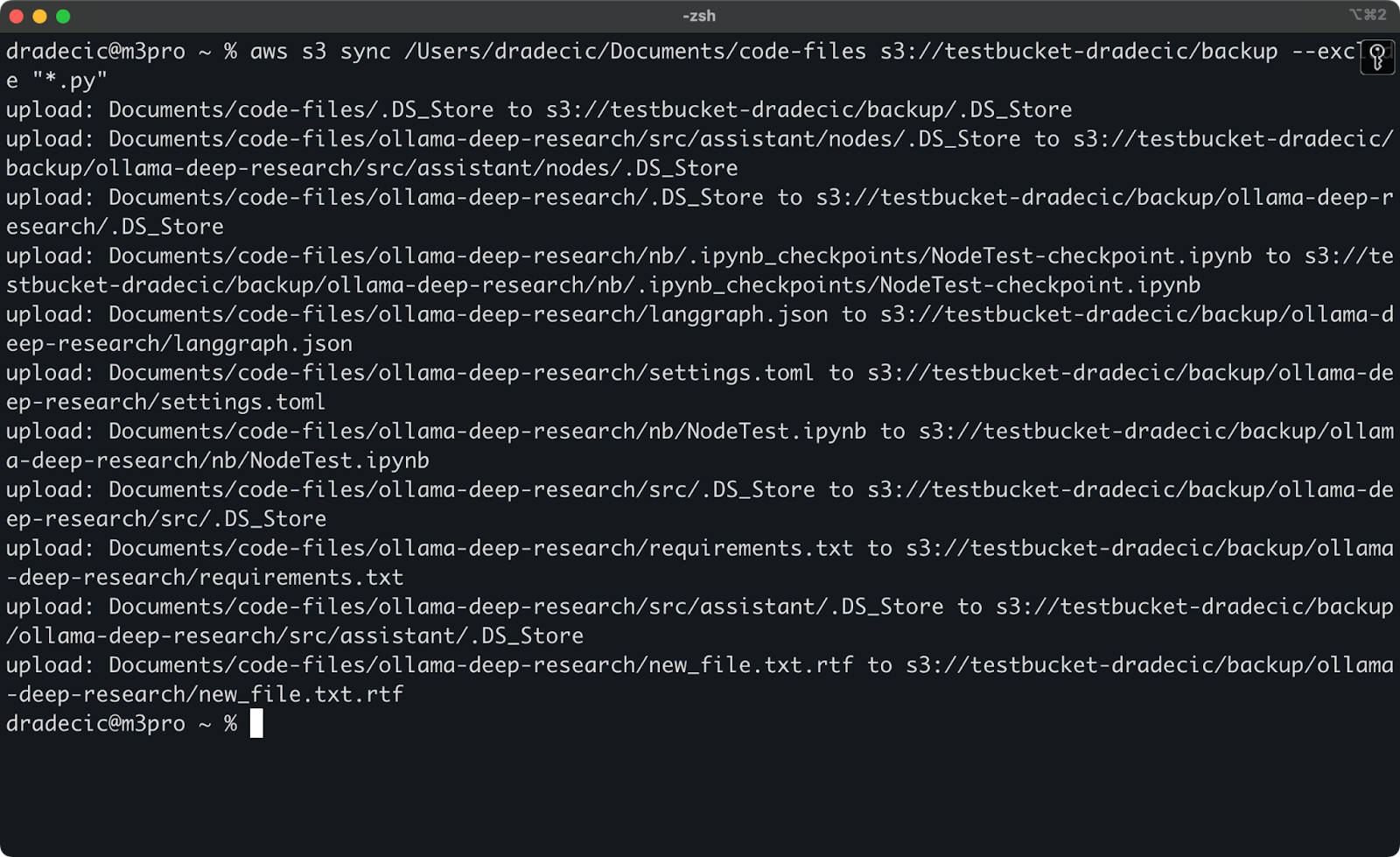
Imagen 13 – Sincronización con S3 excluyendo archivos de Python
También puedes combinar --exclude y --include para crear patrones más complejos. Por ejemplo, excluir todo excepto los archivos de Python:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup --exclude "*" --include "*.py"
¡Los patrones se evalúan en el orden especificado, por lo que el orden importa! Esto es lo que verás al usar estas banderas:
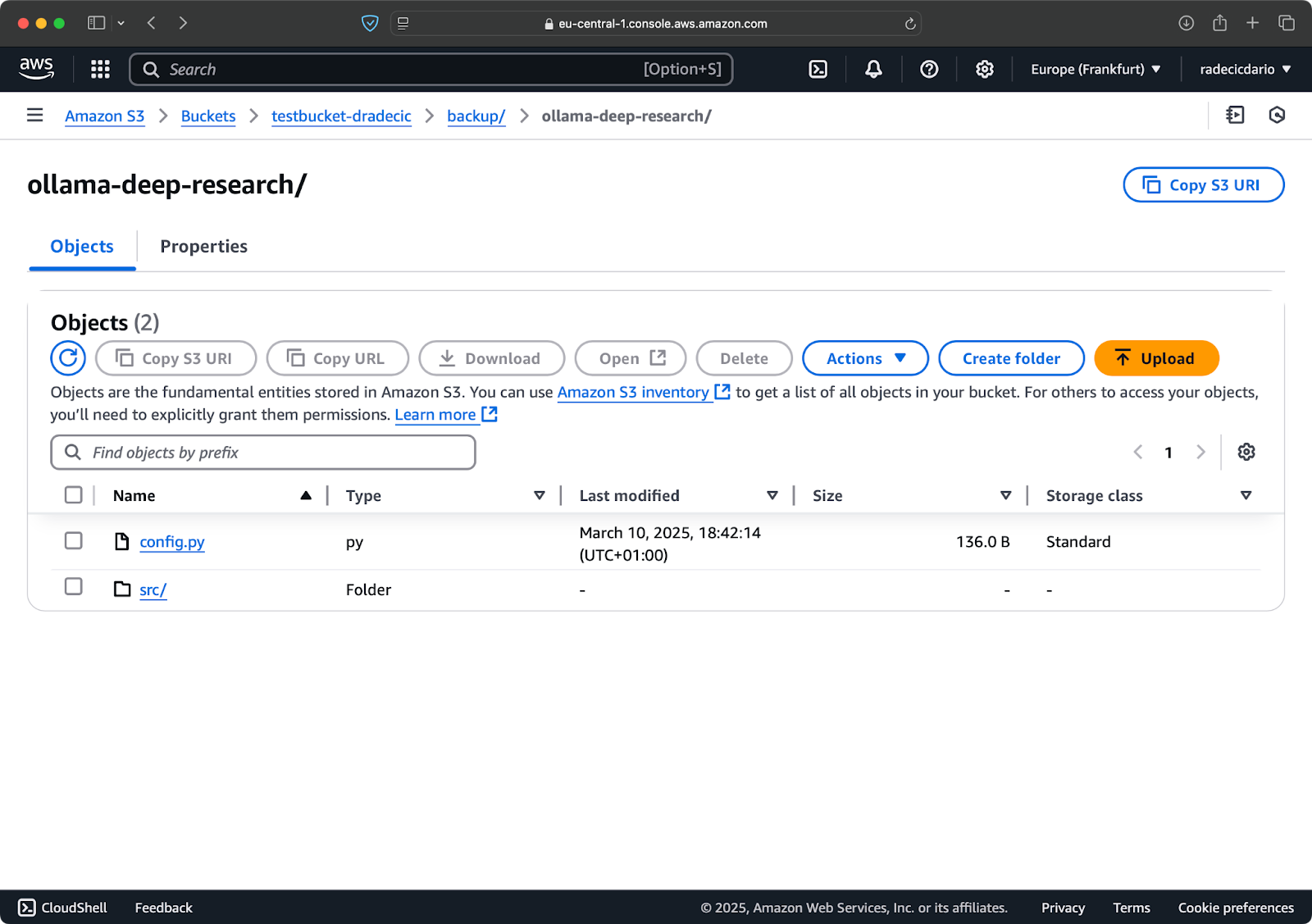
Imagen 14 – Banderas de exclusión e inclusión
Ahora solo se sincronizan los archivos de Python, y faltan archivos de configuración importantes.
Eliminando archivos del destino
Por defecto, la sincronización de S3 solo agrega o actualiza archivos en el destino, nunca los elimina. Esto significa que si eliminas un archivo de la fuente, seguirá existiendo en el destino después de la sincronización.
Para hacer que el destino refleje exactamente la fuente, incluidas las eliminaciones, utiliza la bandera --delete:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup --delete
Si ejecutas esto la primera vez, todos los archivos locales se sincronizarán en S3:
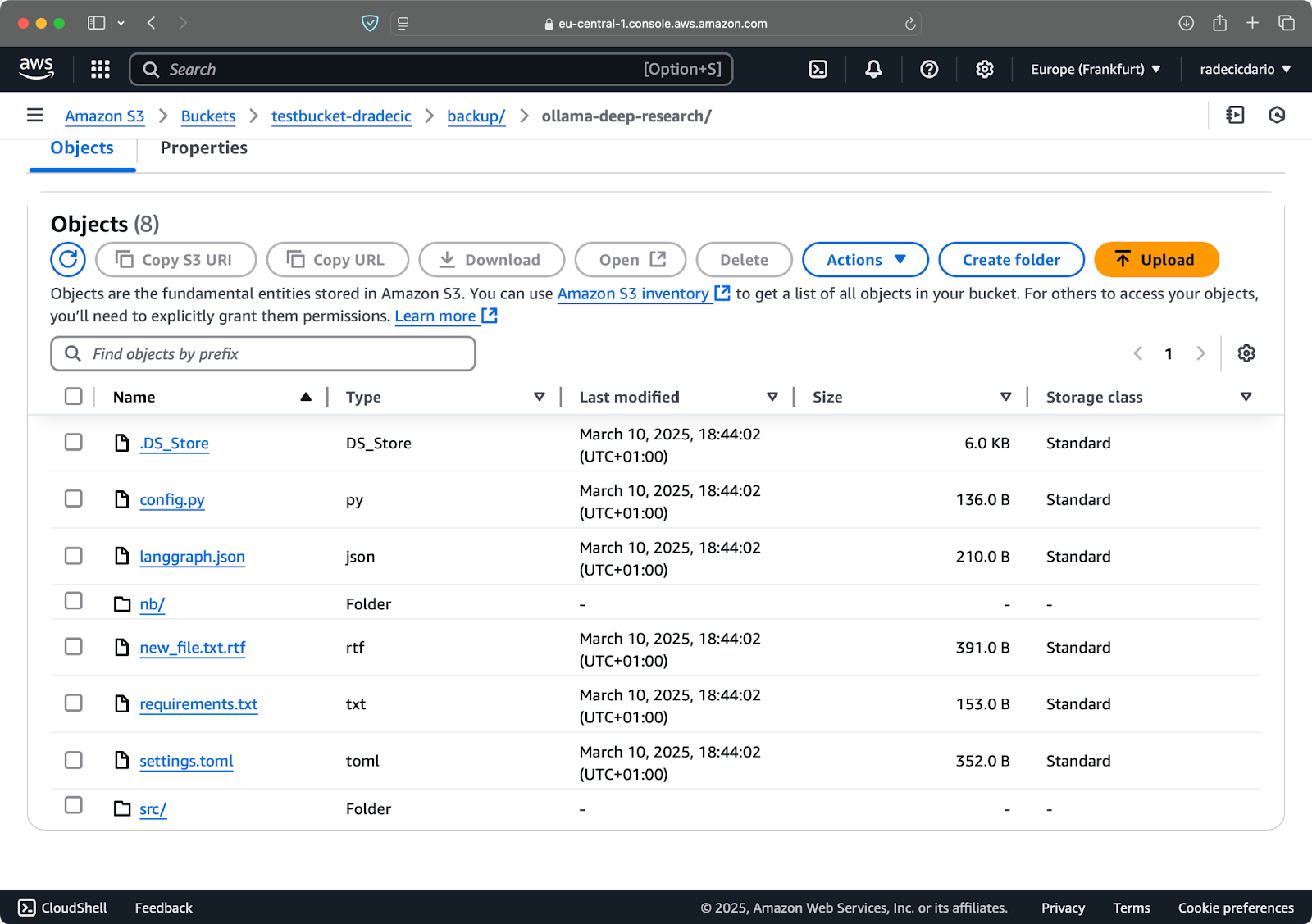
Imagen 15 – Bandera de eliminación
Esto es particularmente útil para mantener réplicas exactas de directorios. Pero ten cuidado: esta bandera puede provocar pérdida de datos si se utiliza incorrectamente.
Supongamos que borro config.py de mi carpeta local y ejecuto el comando de sincronización con la bandera --delete:
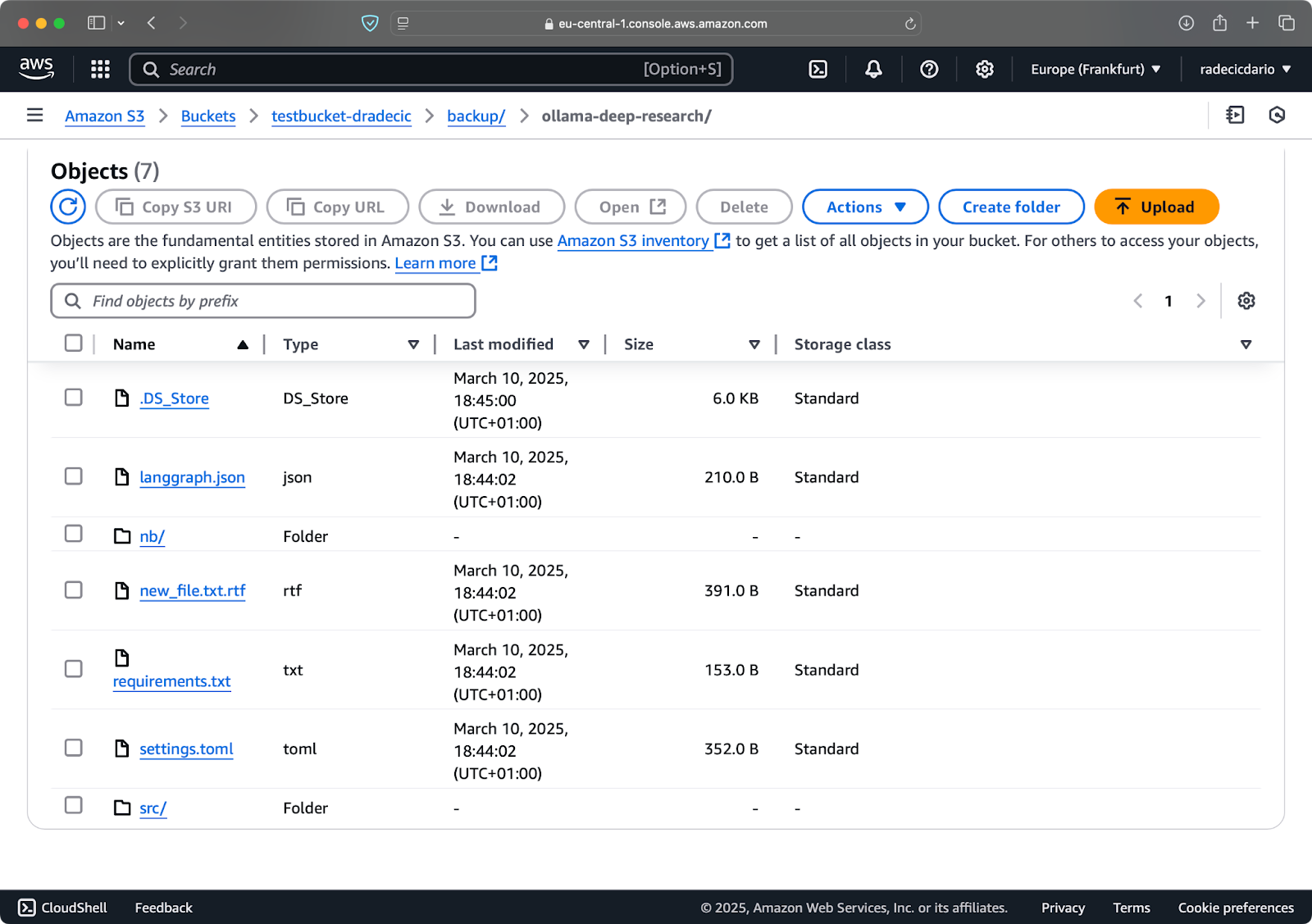
Imagen 16 – Bandera de eliminación (2)
Como puedes ver, el comando no solo sincroniza archivos nuevos y modificados, sino que también elimina archivos del bucket de S3 que ya no existen en el directorio local.
Configurando ejecución en seco para una sincronización segura
Las operaciones de sincronización S3 más peligrosas son aquellas que implican la bandera --delete. Para evitar eliminar accidentalmente archivos importantes, puedes usar la bandera --dryrun para simular la operación sin realizar cambios:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup --delete --dryrun
Para demostrar, he eliminado los archivos requirements.txt y settings.toml de una carpeta local y luego ejecuté el comando:
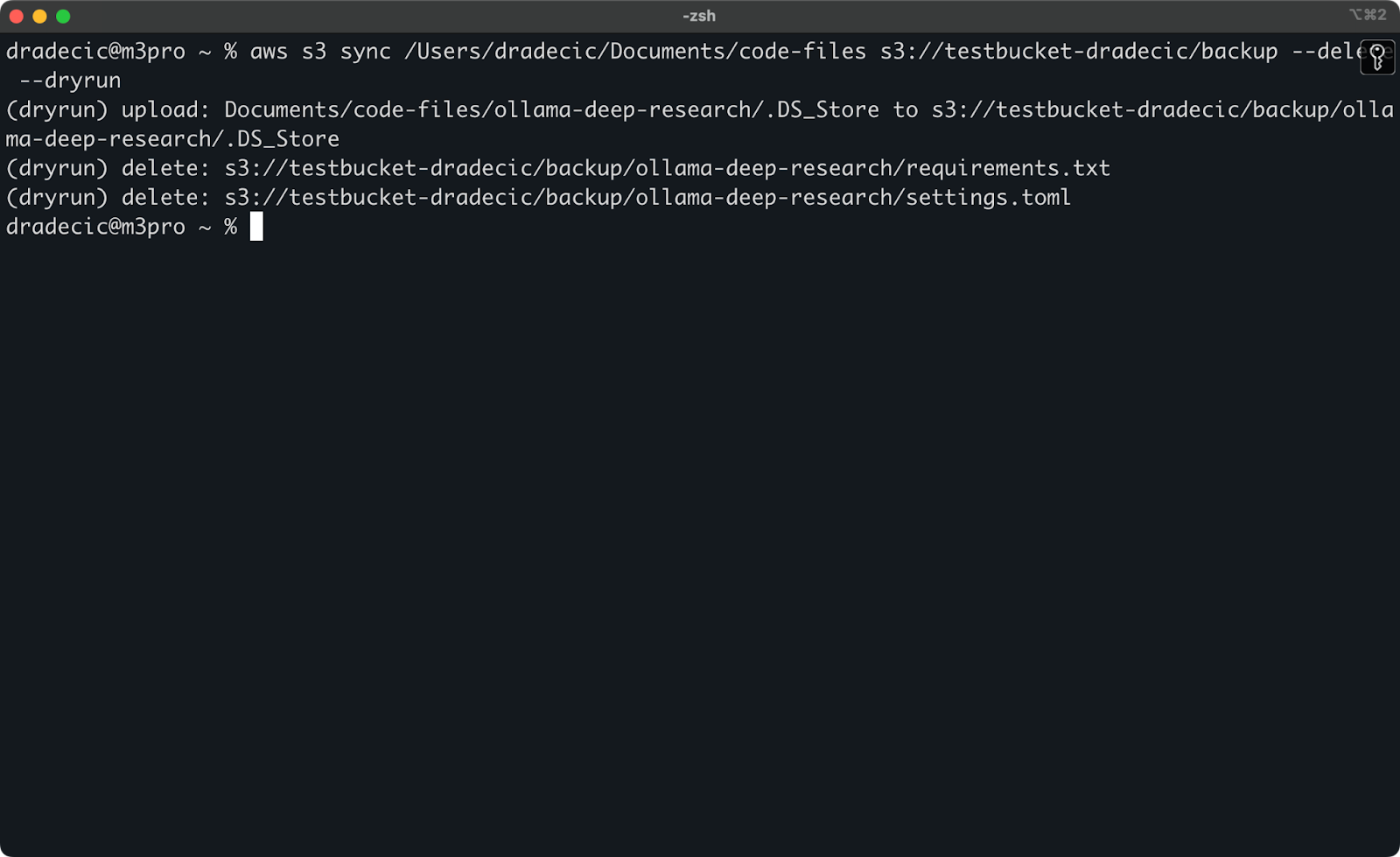
Imagen 17 – Simulación
Esto te mostrará exactamente lo que sucedería si ejecutaras el comando de verdad, incluyendo qué archivos serían subidos, descargados o eliminados.
Siempre recomiendo usar --dryrun antes de ejecutar cualquier comando de sincronización S3 con la bandera --delete, especialmente al trabajar con datos importantes.
Hay muchas otras opciones disponibles para el comando de sincronización S3, como --acl para establecer permisos, --storage-class para elegir la capa de almacenamiento S3, y --recursive para atravesar subdirectorios. Consulta la documentación oficial de AWS CLI para obtener una lista completa de opciones.
Ahora que estás familiarizado con las opciones básicas y avanzadas de sincronización de S3, veamos cómo utilizar estos comandos para escenarios prácticos como copias de seguridad y restauraciones.
Uso de AWS S3 Sync para Copias de Seguridad y Restauración
Uno de los casos de uso más populares para la sincronización de S3 de AWS es hacer copias de seguridad de archivos importantes y restaurarlos cuando sea necesario. Vamos a explorar cómo puedes implementar una estrategia simple de copia de seguridad y restauración utilizando el comando de sincronización.
Creación de copias de seguridad en S3
Crear copias de seguridad con S3 sync es sencillo, solo necesitas ejecutar el comando sync desde tu directorio local a un bucket de S3. Sin embargo, hay algunas buenas prácticas a seguir para copias de seguridad efectivas.
Primero, es una buena idea organizar tus copias de seguridad por fecha o versión. Aquí tienes un enfoque simple utilizando una marca de tiempo en la ruta de S3:
# Crear una variable de marca de tiempo TIMESTAMP=$(date +%Y-%m-%d-%H-%M-%S) # Ejecutar la copia de seguridad aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backups/$TIMESTAMP
Esto crea una nueva carpeta para cada copia de seguridad con una marca de tiempo como 2025-03-10-18-56-42. Así es como se verá en S3:
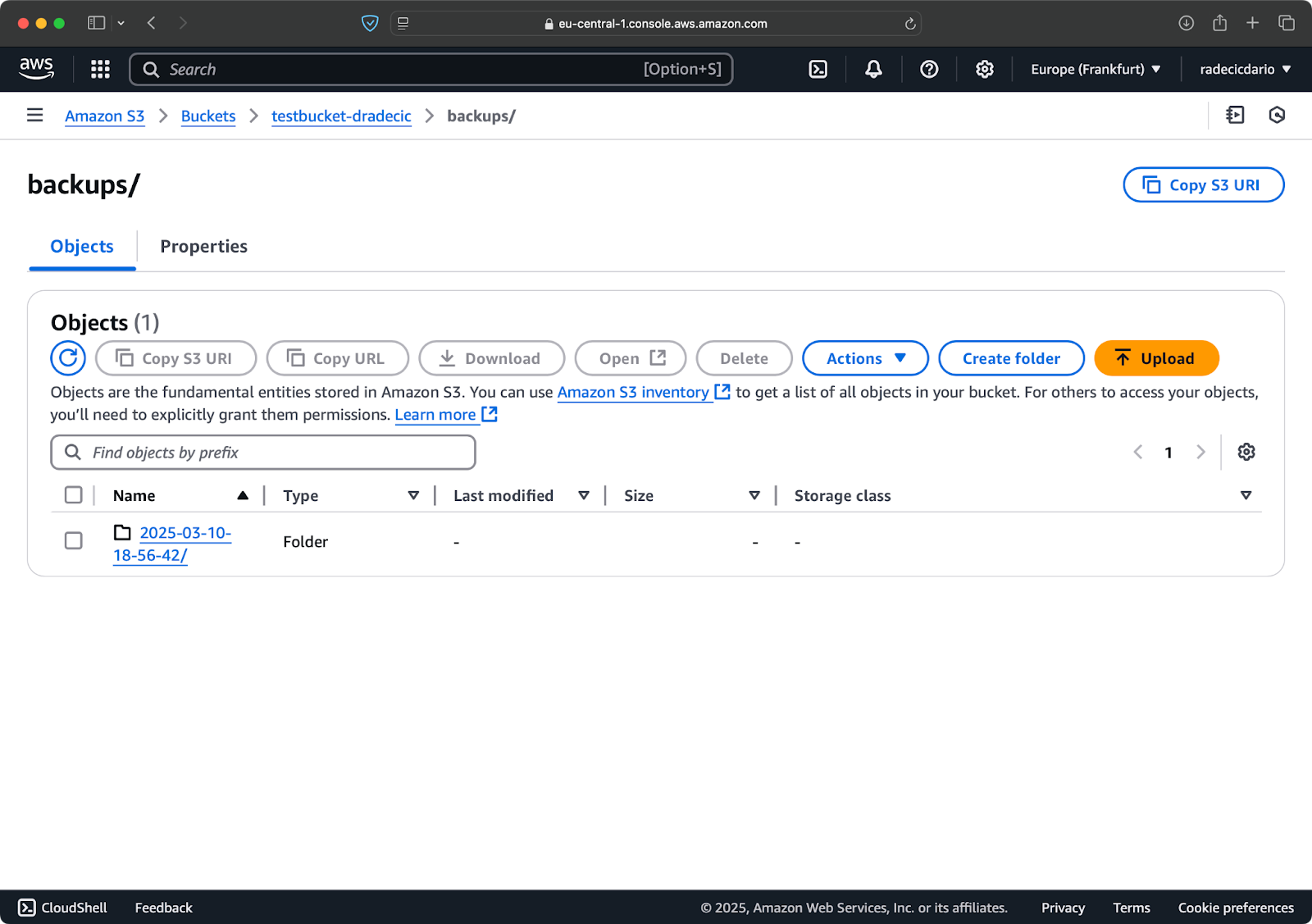
Imagen 18 – Copias de seguridad con marca de tiempo
Para datos críticos, es posible que desees mantener múltiples versiones de copias de seguridad. Esto se puede hacer fácilmente ejecutando regularmente copias de seguridad basadas en marcas de tiempo.
También puedes utilizar la opción --storage-class para especificar una clase de almacenamiento más coste-efectiva para tus copias de seguridad:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backups/$TIMESTAMP --storage-class STANDARD_IA
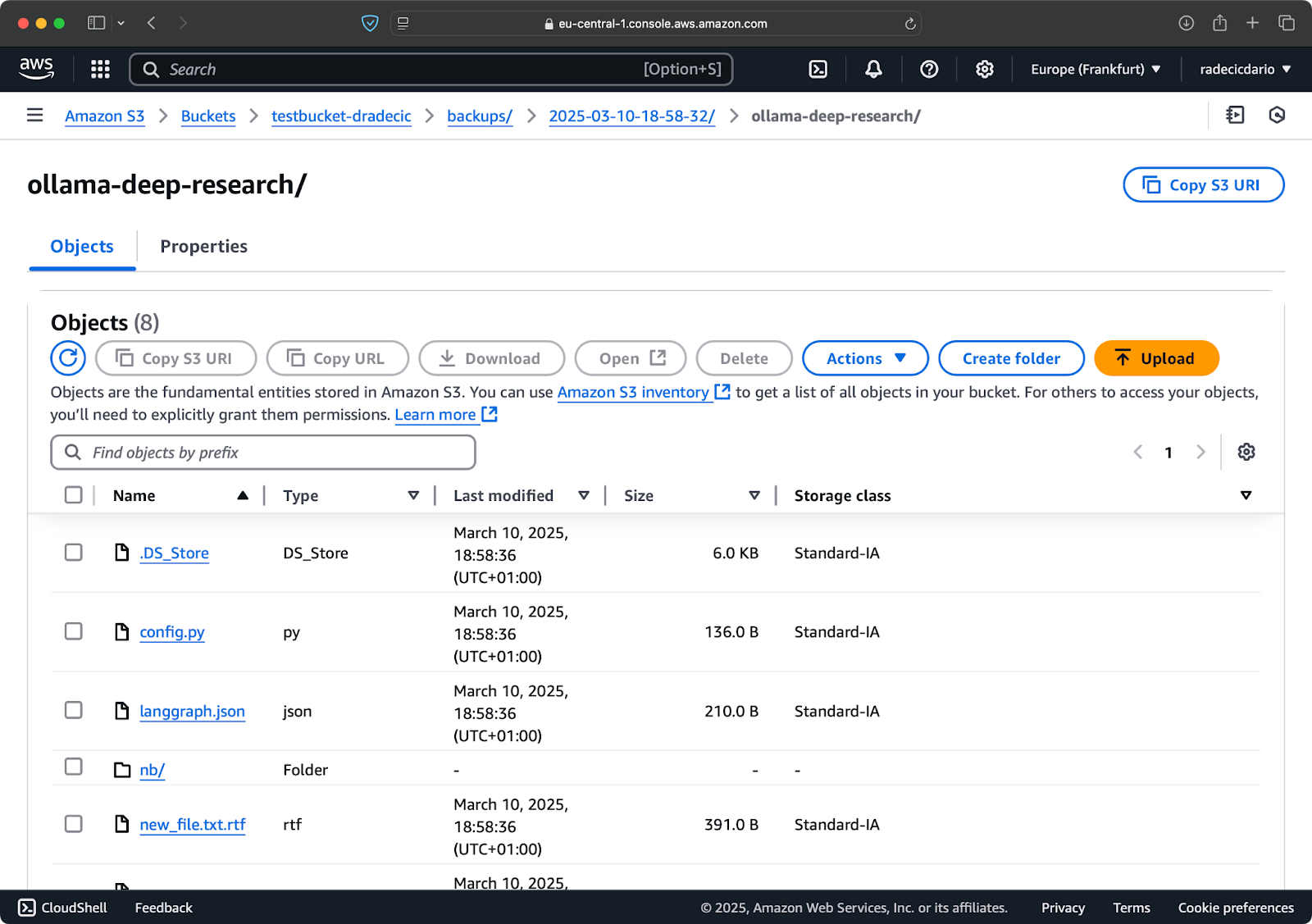
Imagen 19 – Contenidos de copia de seguridad con una clase de almacenamiento personalizada
Esto utiliza la clase de almacenamiento S3 Infrequent Access, que cuesta menos pero tiene una pequeña tarifa de recuperación. Para archivos de archivo a largo plazo, incluso podrías usar la clase de almacenamiento Glacier:
aws s3 sync /Users/dradecic/Documents/important-data s3://testbucket-dradecic/backups/$TIMESTAMP --storage-class GLACIER
Solo ten en cuenta que los archivos almacenados en Glacier tardan horas en recuperarse, por lo que no son adecuados para datos que puedas necesitar rápidamente.
Restauración de archivos desde S3
Restaurar desde una copia de seguridad es igual de fácil, simplemente invierte la fuente y el destino en tu comando de sincronización:
# Restaurar desde la copia de seguridad más reciente (asumiendo que conoces la marca de tiempo) aws s3 sync s3://testbucket-dradecic/backups/2025-03-10-18-56-42 /Users/dradecic/Documents/restored-data
Esto descargará todos los archivos de esa copia de seguridad específica a tu directorio local restored-data:
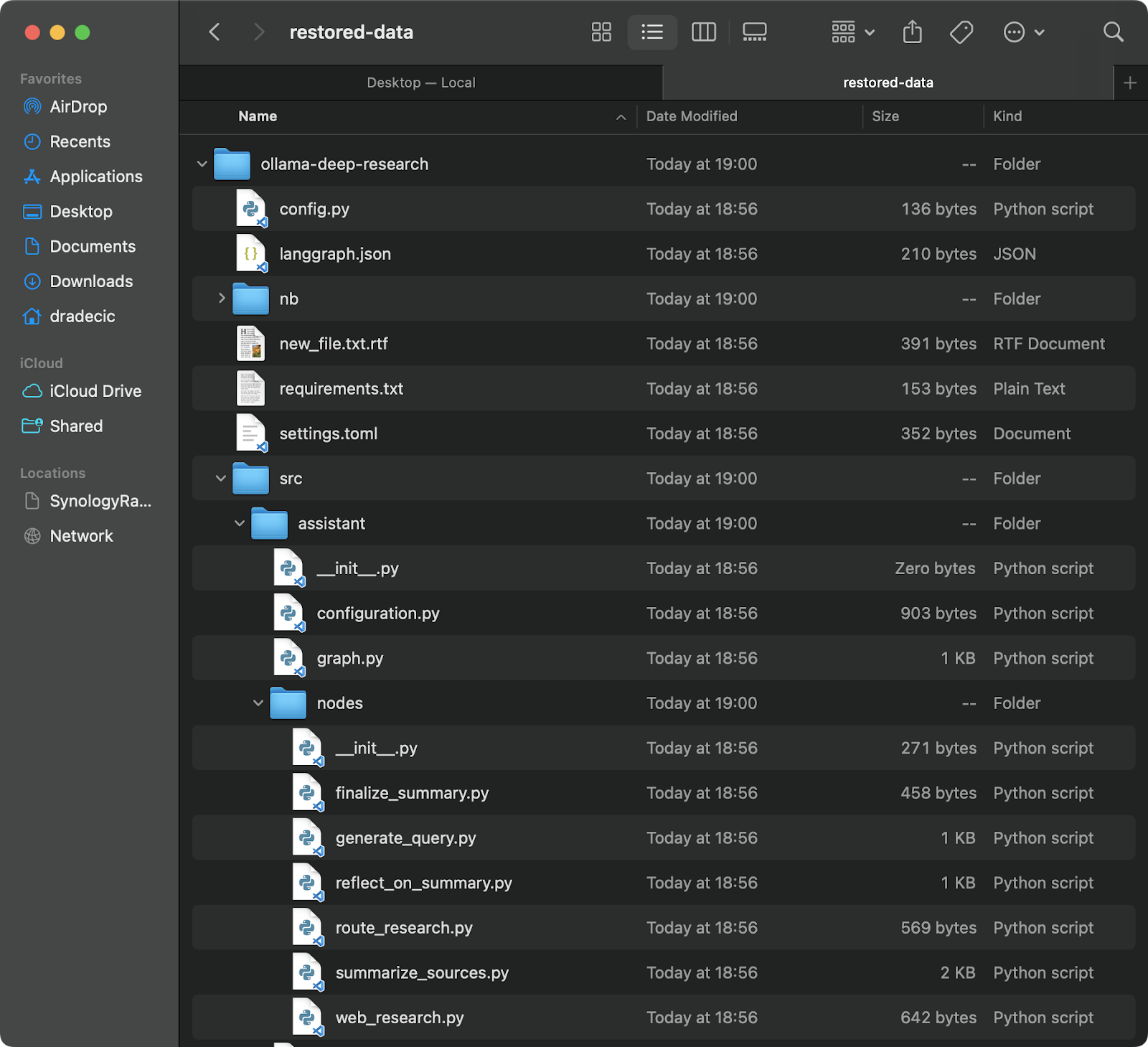
Imagen 20 – Restaurando archivos desde S3
Si no recuerdas la marca de tiempo exacta, primero puedes listar todas tus copias de seguridad:
aws s3 ls s3://testbucket-dradecic/backups/
Lo cual te mostrará algo como:
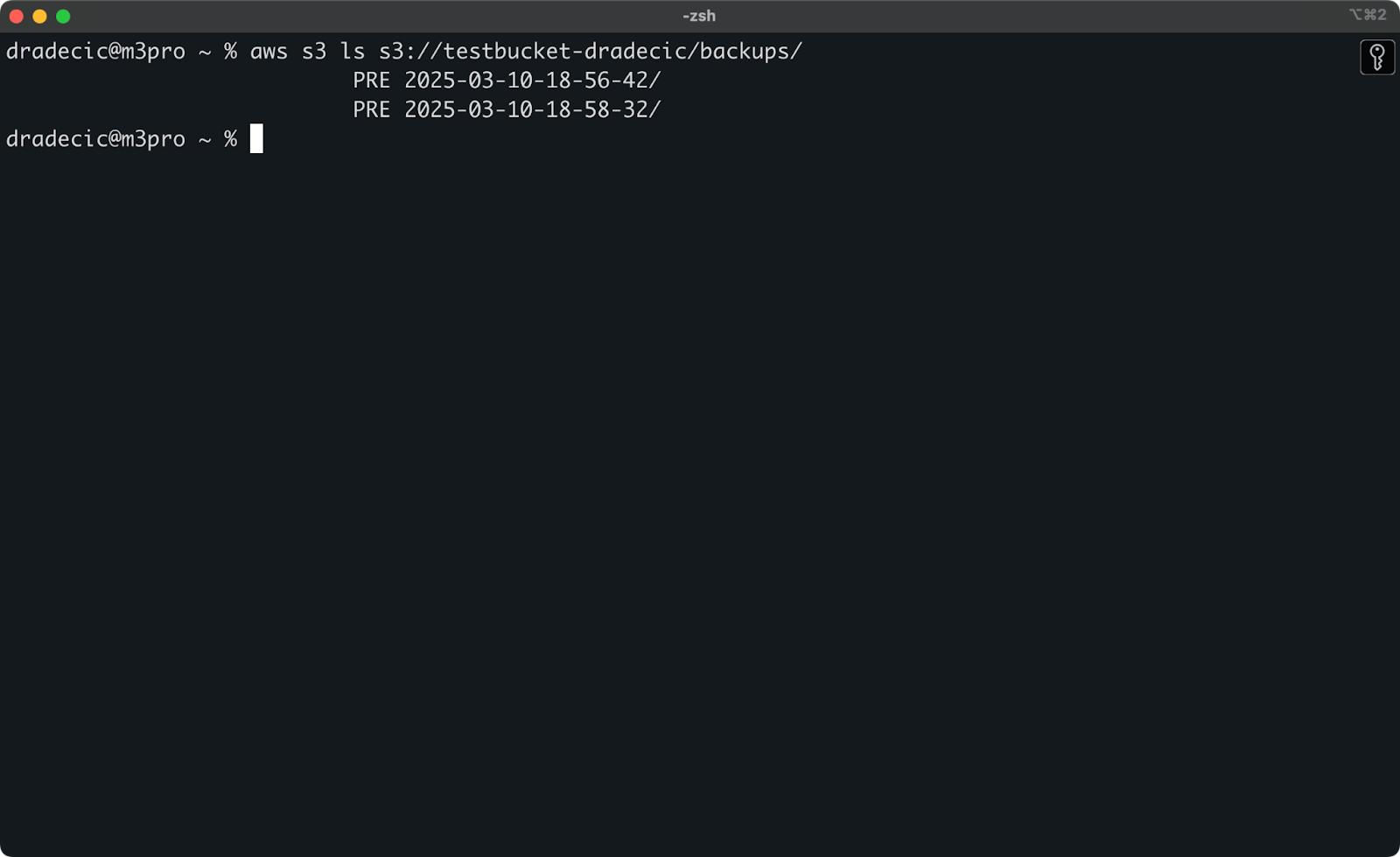
Imagen 21 – Lista de copias de seguridad
También puedes restaurar archivos o directorios específicos de una copia de seguridad usando las banderas de exclusión/inclusión que discutimos anteriormente:
# Restaurar solo los archivos de configuración aws s3 sync s3://testbucket-dradecic/backups/2025-03-10-18-56-42 /Users/dradecic/Documents/restored-configs --exclude "*" --include "*.config" --include "*.toml" --include "*.yaml"
Para sistemas críticos de misión, recomiendo automatizar sus copias de seguridad con tareas programadas (como cron jobs en Linux/macOS o Programador de tareas en Windows). Esto asegura que esté respaldando consistentemente sus datos sin tener que recordar hacerlo manualmente.
Resolución de problemas de AWS S3 Sync
AWS S3 sync es una herramienta confiable, pero ocasionalmente puede encontrar problemas. Sin embargo, la mayoría de errores que verá son de origen humano.
Errores comunes de sincronización
Vamos a repasar algunos problemas comunes y sus soluciones.
- Error de acceso denegado generalmente significa que su usuario IAM no tiene los permisos necesarios para acceder al bucket de S3 o realizar operaciones específicas. Para solucionar esto, intente una de las siguientes opciones:
- Verifique que su usuario IAM tenga los permisos S3 apropiados (
s3:ListBucket,s3:GetObject,s3:PutObject). - Verifique que la política del bucket no deniegue explícitamente el acceso a su usuario.
- Asegúrese de que el propio bucket no esté bloqueando el acceso público si necesita operaciones públicas.
- No existe tal archivo o directorio error suele aparecer cuando la ruta de origen que especificó en el comando de sincronización no existe. La solución es sencilla: verifique nuevamente sus rutas y asegúrese de que existan. Preste especial atención a posibles errores tipográficos en los nombres de los buckets o directorios locales.
- Límite de tamaño de archivo pueden ocurrir errores cuando se desea sincronizar archivos grandes. De forma predeterminada, la sincronización S3 puede manejar archivos de hasta 5 GB de tamaño. Para archivos más grandes, verás tiempos de espera o transferencias incompletas.
- Para archivos mayores de 5 GB, debes usar la bandera
--only-show-errorscombinada con la bandera--size-only. Esta combinación ayuda con las transferencias de archivos grandes al minimizar la salida y comparar solo los tamaños de archivo:
aws s3 sync /Users/dradecic/large-files s3://testbucket-dradecic/large-files --only-show-errors --size-only
Optimización del rendimiento de la sincronización
Si tu sincronización S3 se está ejecutando más lenta de lo esperado, hay algunos ajustes que puedes hacer para acelerar las cosas.
- Utilice transferencias paralelas. De forma predeterminada, la sincronización de S3 utiliza un número limitado de operaciones paralelas. Puede aumentar esto con el parámetro
--max-concurrent-requests:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup --max-concurrent-requests 20
- Ajuste el tamaño del fragmento. Para archivos grandes, puede optimizar la velocidad de transferencia ajustando el tamaño del fragmento. Esto divide los archivos grandes en fragmentos de 16MB en lugar de los 8MB predeterminados, lo que puede ser más rápido para conexiones de red buenas:
aws s3 sync /Users/dradecic/large-files s3://testbucket-dradecic/backup --cli-read-timeout 120 --multipart-threshold 64MB --multipart-chunksize 16MB
- Utilice
--no-progresspara scripts. Si está ejecutando la sincronización de S3 en un script automatizado, use la bandera--no-progresspara reducir la salida y mejorar el rendimiento:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup --no-progress
- Usa puntos finales locales. Si tus recursos de AWS están en la misma región, especificar el punto final regional puede reducir la latencia:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup --endpoint-url https://s3.eu-central-1.amazonaws.com
Estas optimizaciones pueden mejorar significativamente el rendimiento de sincronización, especialmente para transferencias de datos grandes o al ejecutarse en máquinas menos potentes.
Si sigues experimentando problemas después de probar estas soluciones, la AWS CLI tiene una opción de depuración incorporada. Simplemente agrega --debug a tu comando para ver información detallada sobre lo que está sucediendo durante el proceso de sincronización:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup --debug
Espera ver una gran cantidad de mensajes de registro detallados, similares a estos:
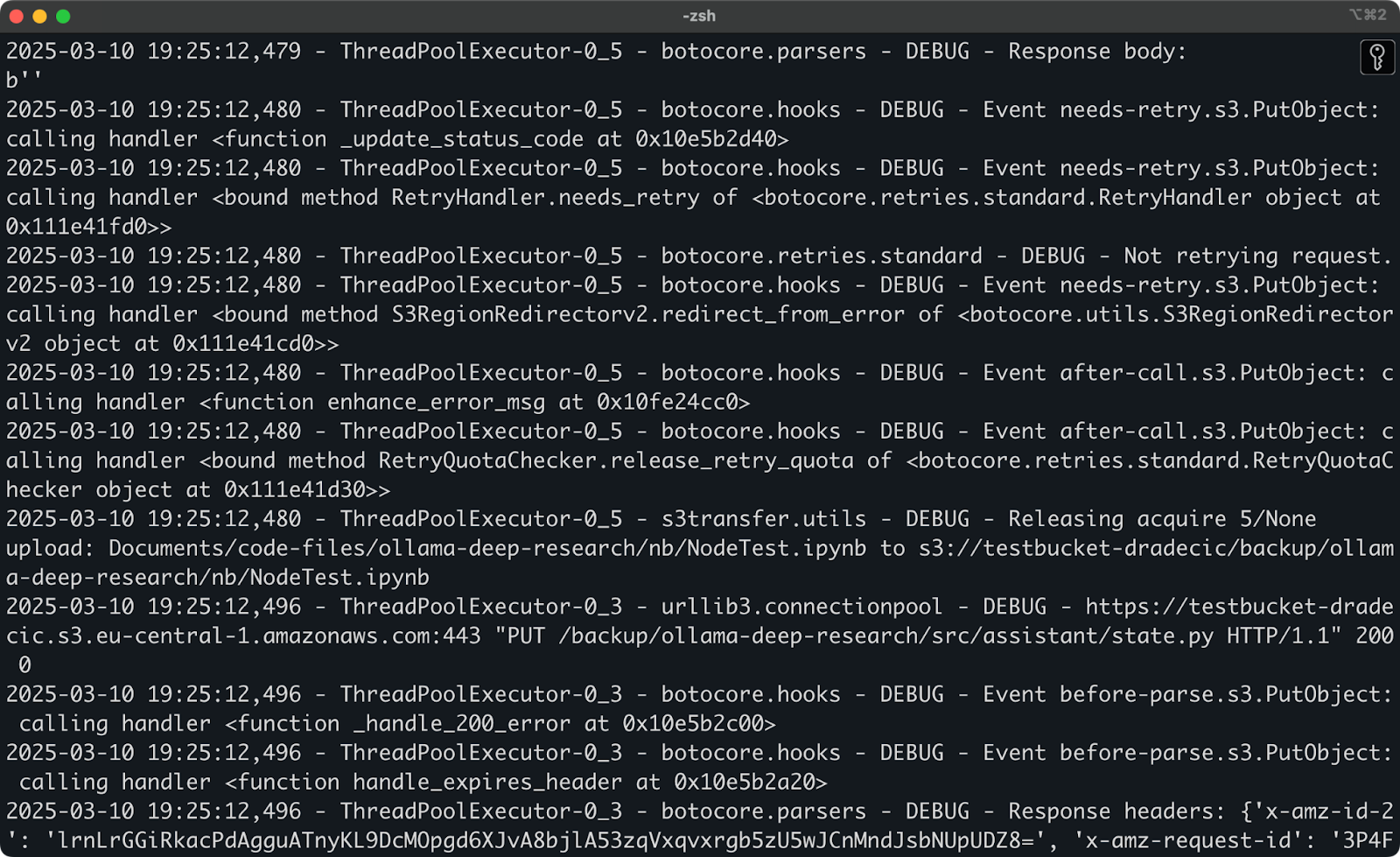
Imagen 22 – Ejecutando la sincronización en modo de depuración
Y eso es prácticamente todo cuando se trata de solucionar problemas de sincronización de AWS S3. Claro, pueden ocurrir otros errores, pero el 99% del tiempo, encontrarás la solución en esta sección.
Resumiendo la sincronización de AWS S3
En resumen, la sincronización de AWS S3 es una de esas herramientas raras que son tanto simples de usar como increíblemente poderosas. Has aprendido todo, desde comandos básicos hasta opciones avanzadas, estrategias de respaldo y consejos de solución de problemas.
Para desarrolladores, administradores de sistemas o cualquier persona que trabaje con AWS, el comando de sincronización S3 es una herramienta esencial: ahorra tiempo, reduce el uso de ancho de banda y garantiza que tus archivos estén donde los necesitas, cuando los necesitas.
Ya sea que estés respaldando datos críticos, implementando activos web o simplemente manteniendo diferentes entornos sincronizados, la sincronización de AWS S3 hace que el proceso sea sencillo y confiable.
La mejor manera de familiarizarse con S3 sync es comenzar a usarlo. Intenta configurar una operación de sincronización simple con tus propios archivos, y luego explora gradualmente las opciones avanzadas para adaptarlas a tus necesidades específicas.
Recuerda siempre usar --dryrun primero cuando trabajes con datos importantes, especialmente al usar la opción --delete. Es mejor tomarse un minuto extra para verificar qué sucederá que borrar accidentalmente archivos importantes.
Para aprender más sobre AWS, consulta estos cursos de DataCamp:
- Introducción a AWS
- Tecnología y Servicios de AWS Cloud
- Seguridad y Gestión de Costos de AWS
- Introducción a AWS Boto en Python
Puedes incluso usar DataCamp para prepararte para los exámenes de certificación de AWS – Practicante de la Nube de AWS (CLF-C02).