













Mise en place de l’interface en ligne de commande AWS (CLI) et d’AWS S3
Avant de pouvoir commencer à synchroniser des fichiers avec S3, vous devrez configurer correctement l’AWS CLI. Cela peut sembler intimidant si vous débutez avec AWS, mais cela ne prendra que quelques minutes.
La configuration de l’interface de ligne de commande implique deux étapes principales : l’installation de l’outil et sa configuration. Je vais détailler ces deux étapes ci-dessous.
Installation de l’AWS CLI
L’installation de l’AWS CLI varie légèrement en fonction de votre système d’exploitation.
Pour les systèmes Windows :
- Accédez à la page de téléchargement du AWS CLI
- Téléchargez l’installateur Windows (64 bits)
- Exécutez l’installateur et suivez les invites
Pour les systèmes Linux :
Exécutez les trois commandes suivantes dans le Terminal :
curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip" unzip awscliv2.zip sudo ./aws/install
Pour les systèmes macOS :
En supposant que vous avez Homebrew installé, exécutez cette ligne à partir du Terminal :
brew install awscli
Si vous n’avez pas Homebrew, utilisez plutôt ces deux commandes :
curl "https://awscli.amazonaws.com/AWSCLIV2.pkg" -o "AWSCLIV2.pkg" sudo installer -pkg AWSCLIV2.pkg -target /
Vous pouvez exécuter la commande aws --version sur tous les systèmes d’exploitation pour vérifier que AWS CLI est installé. Voici ce que vous devriez voir :
Image 1 – Version AWS CLI
Configuration de AWS CLI
Maintenant que vous avez installé la CLI, vous devez la configurer avec vos identifiants AWS.
En supposant que vous avez déjà un compte AWS, connectez-vous et accédez au service IAM. Une fois là-bas, créez un nouvel utilisateur avec un accès programmatique. Vous devriez attribuer les autorisations appropriées à l’utilisateur, qui est l’accès S3 au minimum :
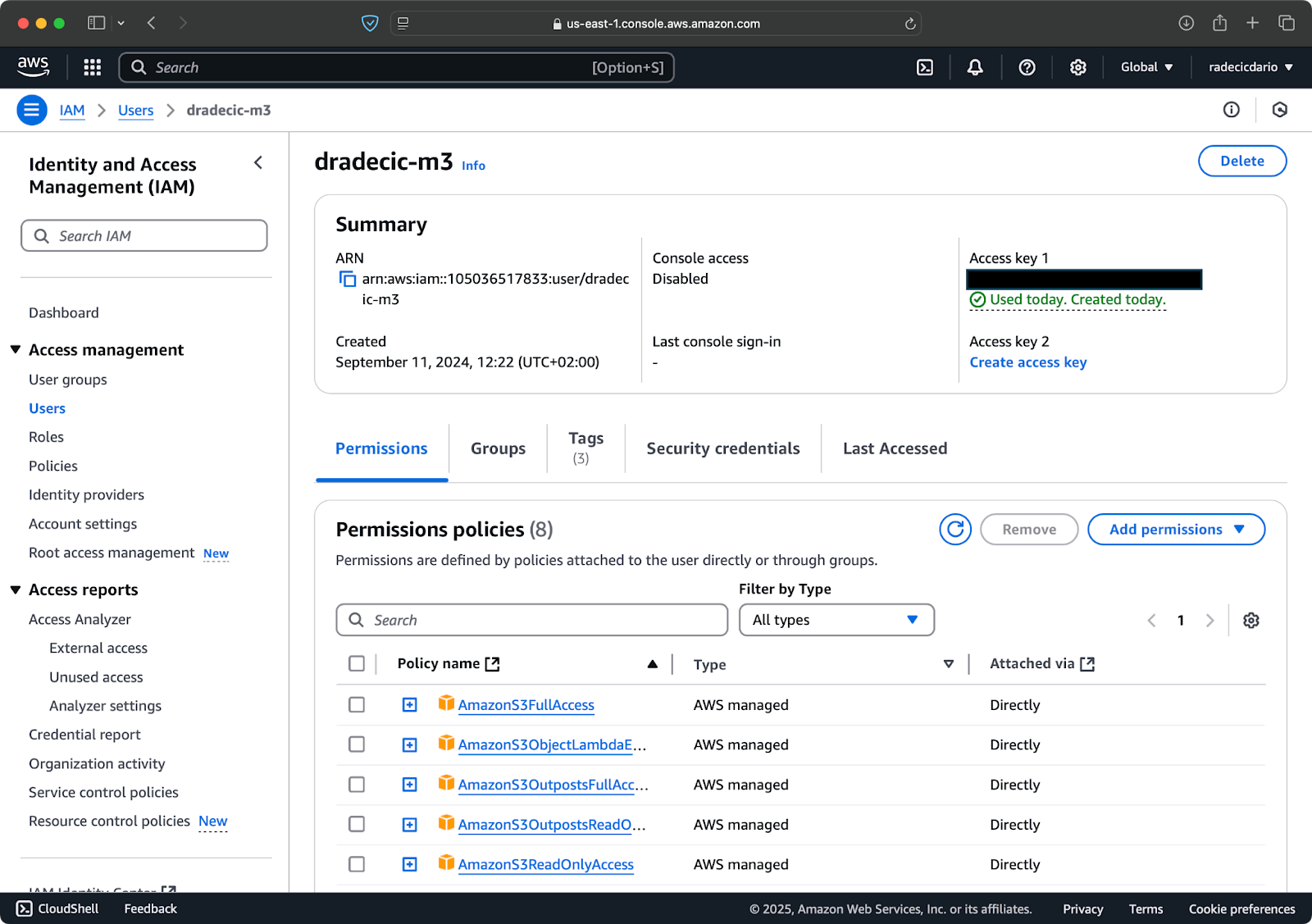
Image 2 – Utilisateur AWS IAM
Une fois terminé, allez dans « Informations d’identification de sécurité » pour créer une nouvelle clé d’accès. Après la création, vous aurez à la fois l’ ID de la clé d’accès et Clé d’accès secrète. Notez-les quelque part en sécurité car vous ne pourrez pas y accéder à l’avenir:
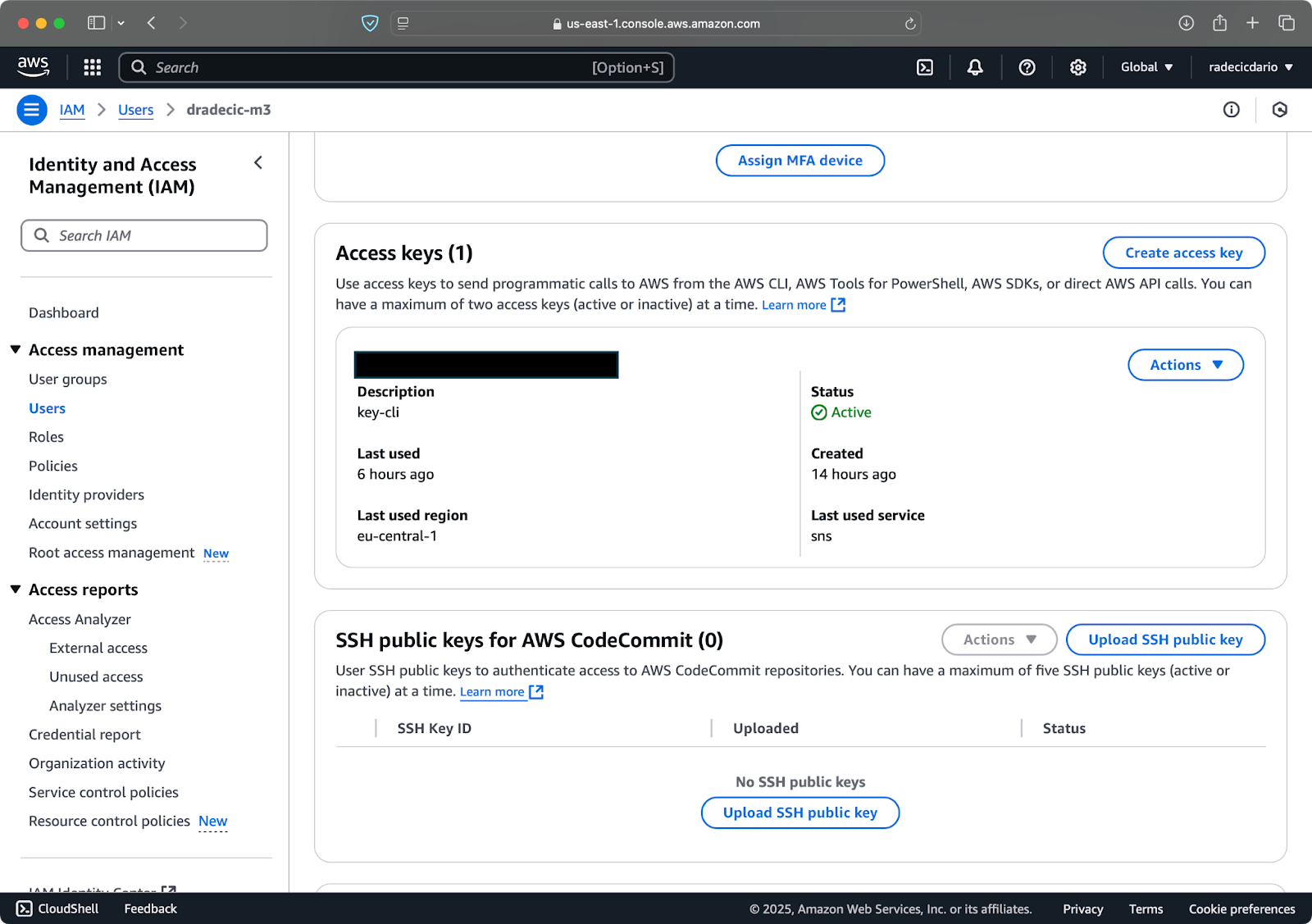
Image 3 – Informations d’identification de l’utilisateur AWS IAM
De retour dans le Terminal, exécutez la commande aws configure. Il vous demandera d’entrer votre ID de clé d’accès, votre clé d’accès secrète, la région (eu-central-1 dans mon cas) et le format de sortie préféré (json) :
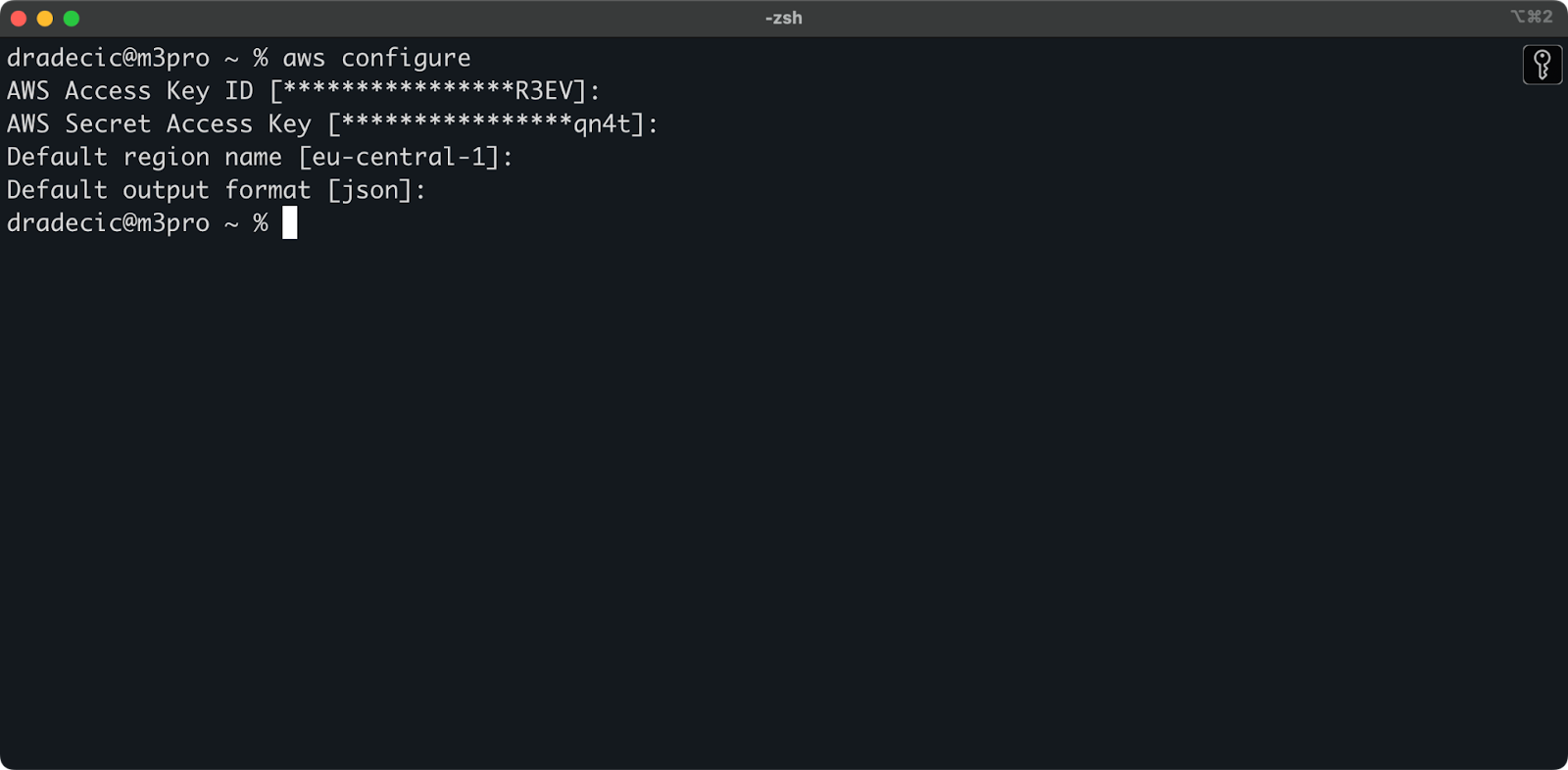
Image 4 – Configuration AWS CLI
Pour vérifier que vous êtes connecté avec succès à votre compte AWS depuis l’interface en ligne de commande, exécutez la commande suivante :
aws sts get-caller-identity
Voici la sortie que vous devriez voir :
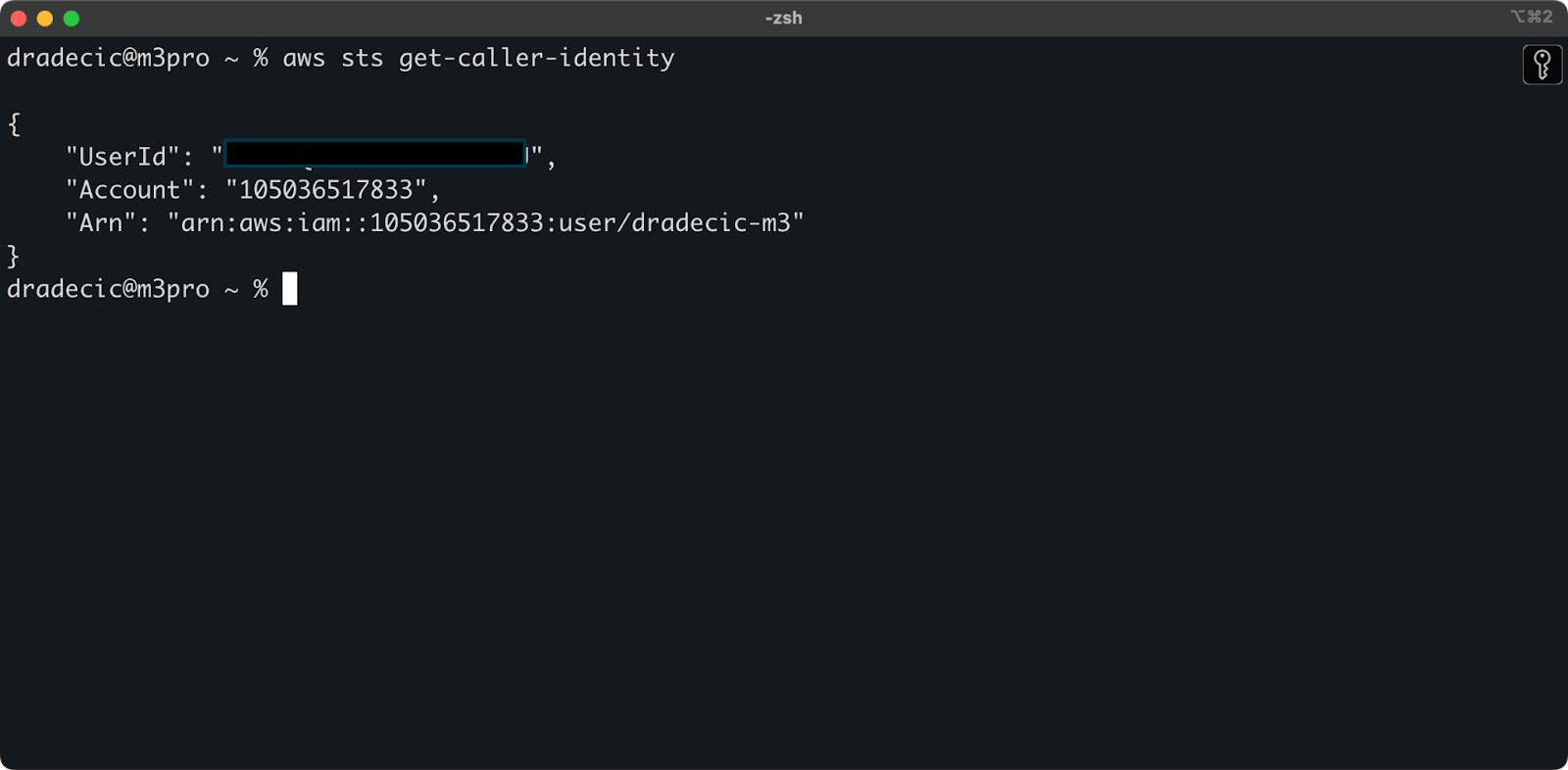
Image 5 – Commande de test de connexion AWS CLI
Et c’est tout – juste une étape de plus avant de pouvoir commencer à utiliser la commande de synchronisation S3 !
Mise en place d’un bucket AWS S3
La dernière étape consiste à créer un compartiment S3 qui stockera vos fichiers synchronisés. Vous pouvez le faire depuis l’interface en ligne de commande ou depuis la console de gestion AWS. Je vais opter pour cette dernière, juste pour changer un peu.
Pour commencer, accédez à la page du service S3 dans la console de gestion et cliquez sur le bouton « Créer un compartiment ». Ensuite, choisissez un nom de compartiment unique (unique mondialement à travers tout AWS) puis faites défiler jusqu’en bas et cliquez sur le bouton « Créer » :
Image 6 – Création du compartiment AWS
Le compartiment est maintenant créé et vous le verrez immédiatement dans la console de gestion. Vous pouvez également vérifier qu’il a été créé via l’interface en ligne de commande :
aws s3 ls
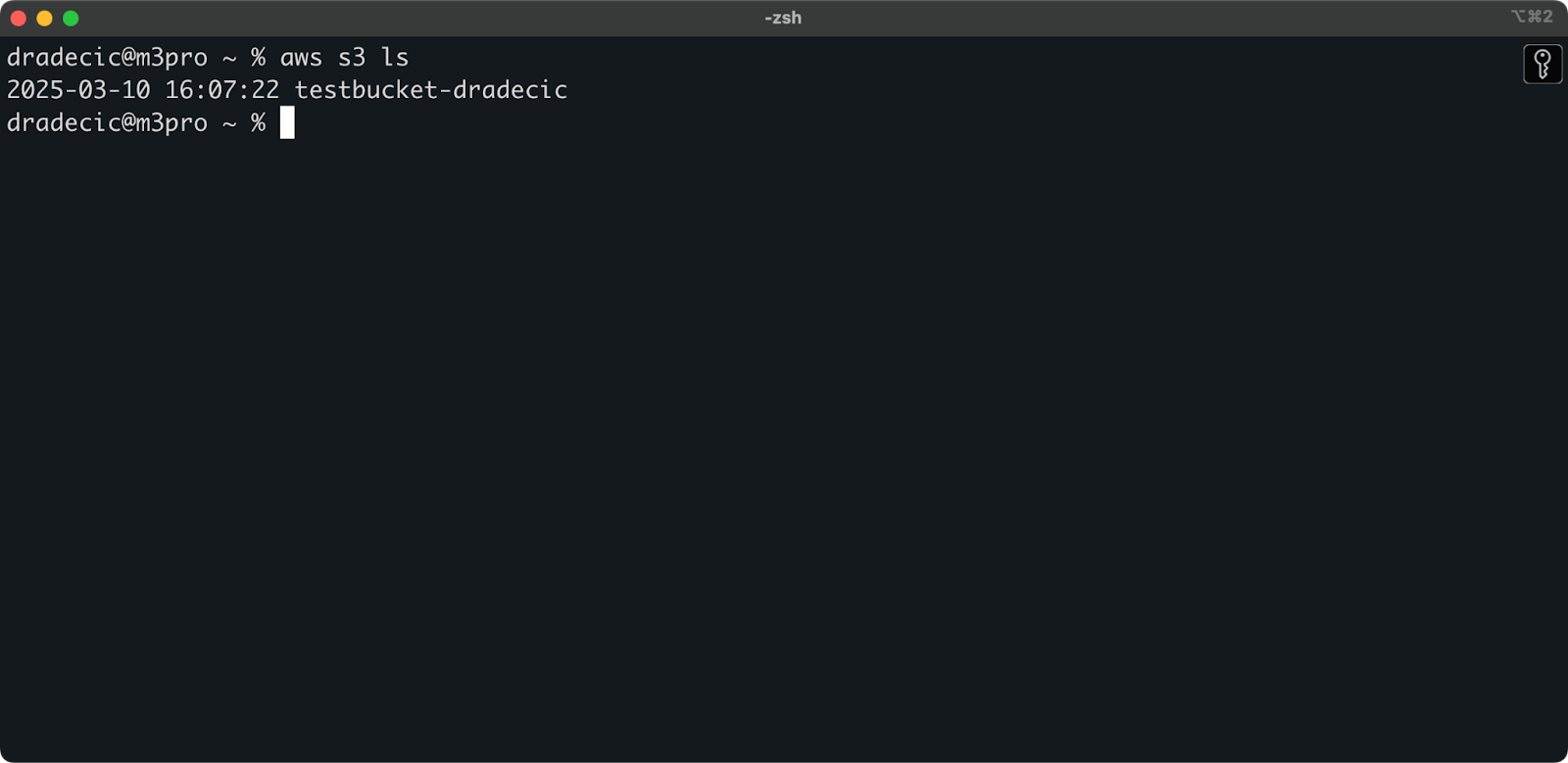
Image 7 – Tous les compartiments S3 disponibles
Gardez à l’esprit que les seaux S3 sont privés par défaut. Si vous prévoyez d’utiliser le seau pour héberger des fichiers publics (comme des ressources de site web), vous devrez ajuster les politiques et les autorisations du seau en conséquence.
Maintenant que vous êtes prêt et prêt à commencer à synchroniser des fichiers entre votre machine locale et AWS S3!
Commande de synchronisation de base AWS S3
Maintenant que vous avez installé et configuré l’interface de ligne de commande AWS et préparé un seau S3, il est temps de commencer la synchronisation! La syntaxe de base de la commande de synchronisation AWS S3 est assez simple. Laissez-moi vous montrer comment cela fonctionne.
La commande de synchronisation S3 suit ce schéma simple:
aws s3 sync <source> <destination> [options]
La source et la destination peuvent être soit un chemin de répertoire local, soit une URI S3 (commençant par s3://). Selon le sens dans lequel vous souhaitez synchroniser, vous les organiserez différemment.
Synchronisation de fichiers depuis le local vers un compartiment S3
J’ai récemment exploré la recherche approfondie d’Ollama. Disons que c’est le dossier que je veux synchroniser avec S3. Le répertoire principal se trouve sous le dossier Documents. Voici à quoi cela ressemble :
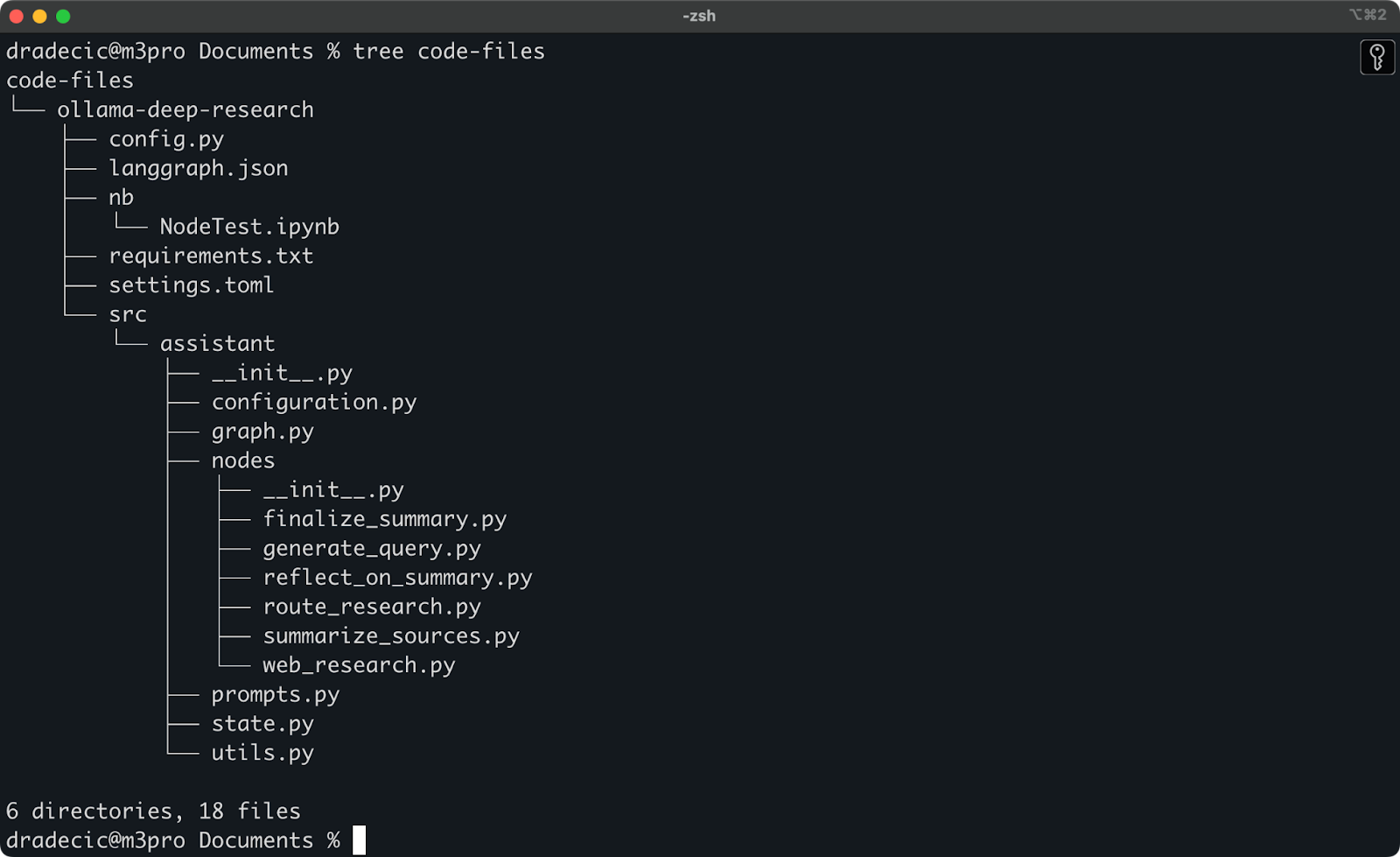
Contenu du dossier local
Voici la commande que je dois exécuter pour synchroniser le dossier local code-files avec le dossier backup sur le compartiment S3 :
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup
Le dossier backup sur le compartiment S3 sera automatiquement créé s’il n’existe pas.
Voici ce que vous verrez imprimé sur la console :
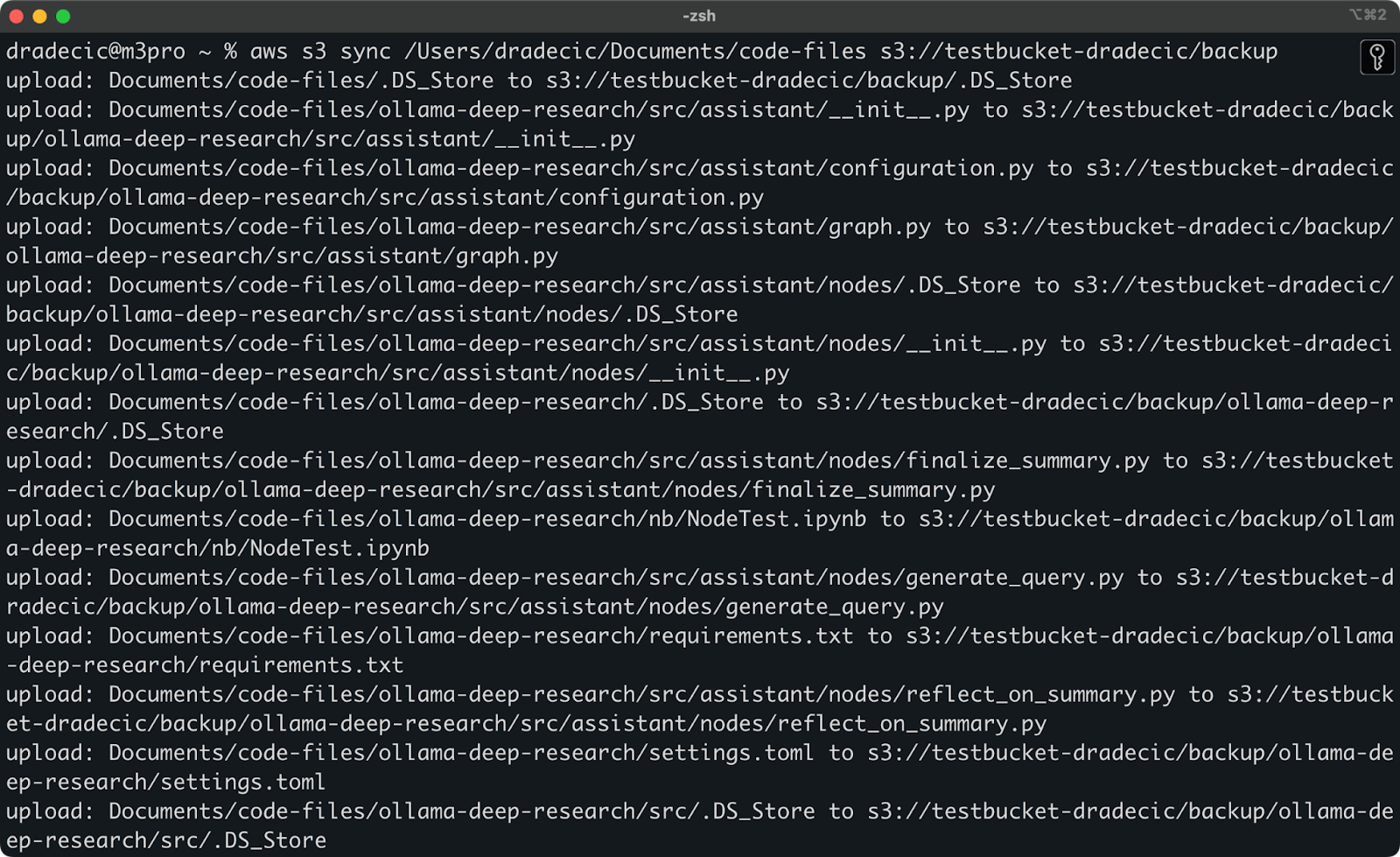
Image 9 – Processus de synchronisation S3
Après quelques secondes, le contenu du dossier local code-files est disponible sur le bucket S3 :
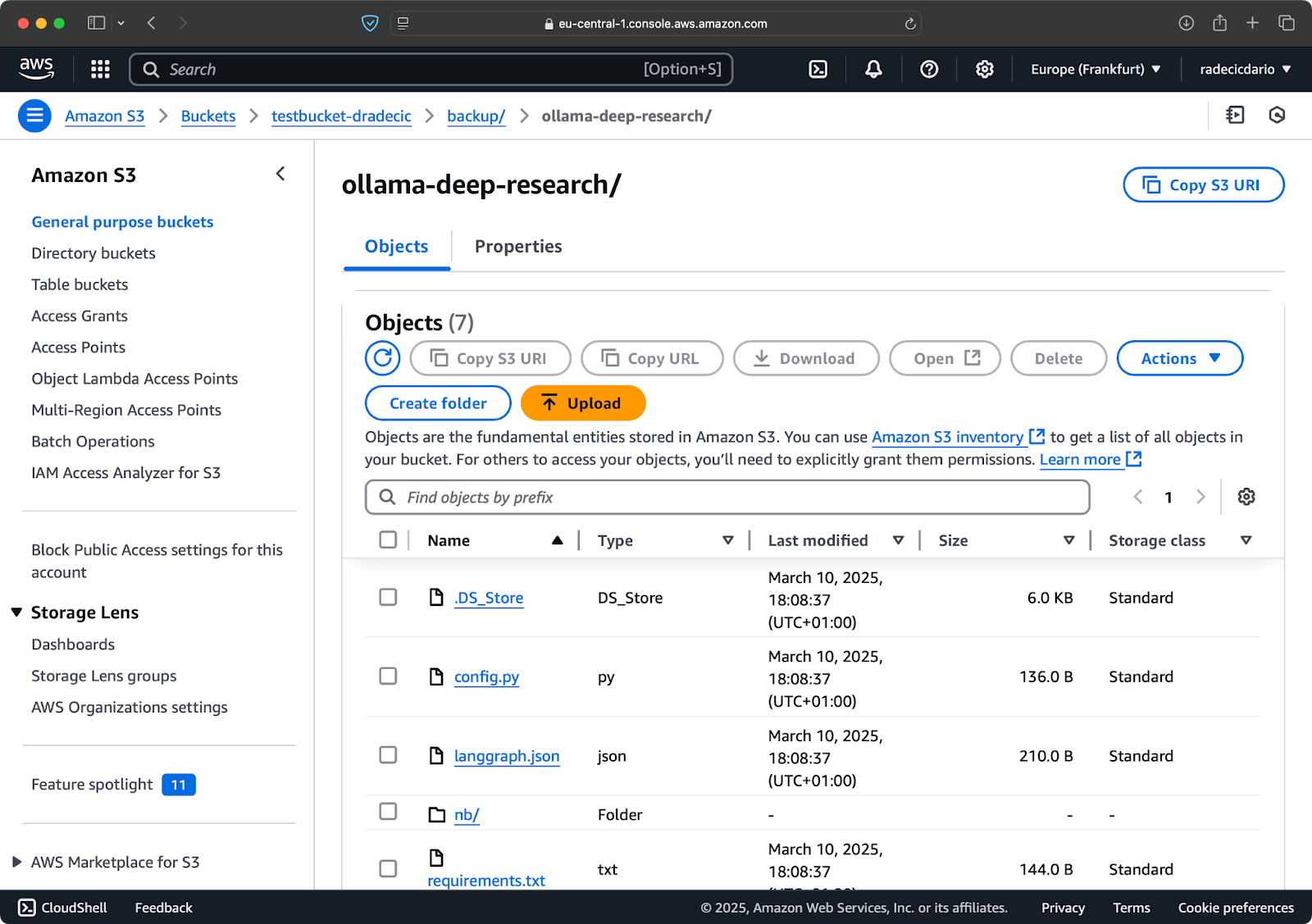
Image 10 – Contenu du bucket S3
La beauté de la synchronisation S3 est que cela ne télécharge que les fichiers qui n’existent pas dans la destination ou qui ont été modifiés localement. Si vous exécutez à nouveau la même commande sans rien changer, vous ne verrez rien ! C’est parce que l’AWS CLI a détecté que tous les fichiers sont déjà synchronisés et à jour.
Maintenant, je vais apporter deux petits changements – créer un nouveau fichier (new_file.txt) et mettre à jour un fichier existant (requirements.txt). Lorsque vous exécutez à nouveau la commande de synchronisation, seuls les fichiers nouveaux ou modifiés seront téléchargés :
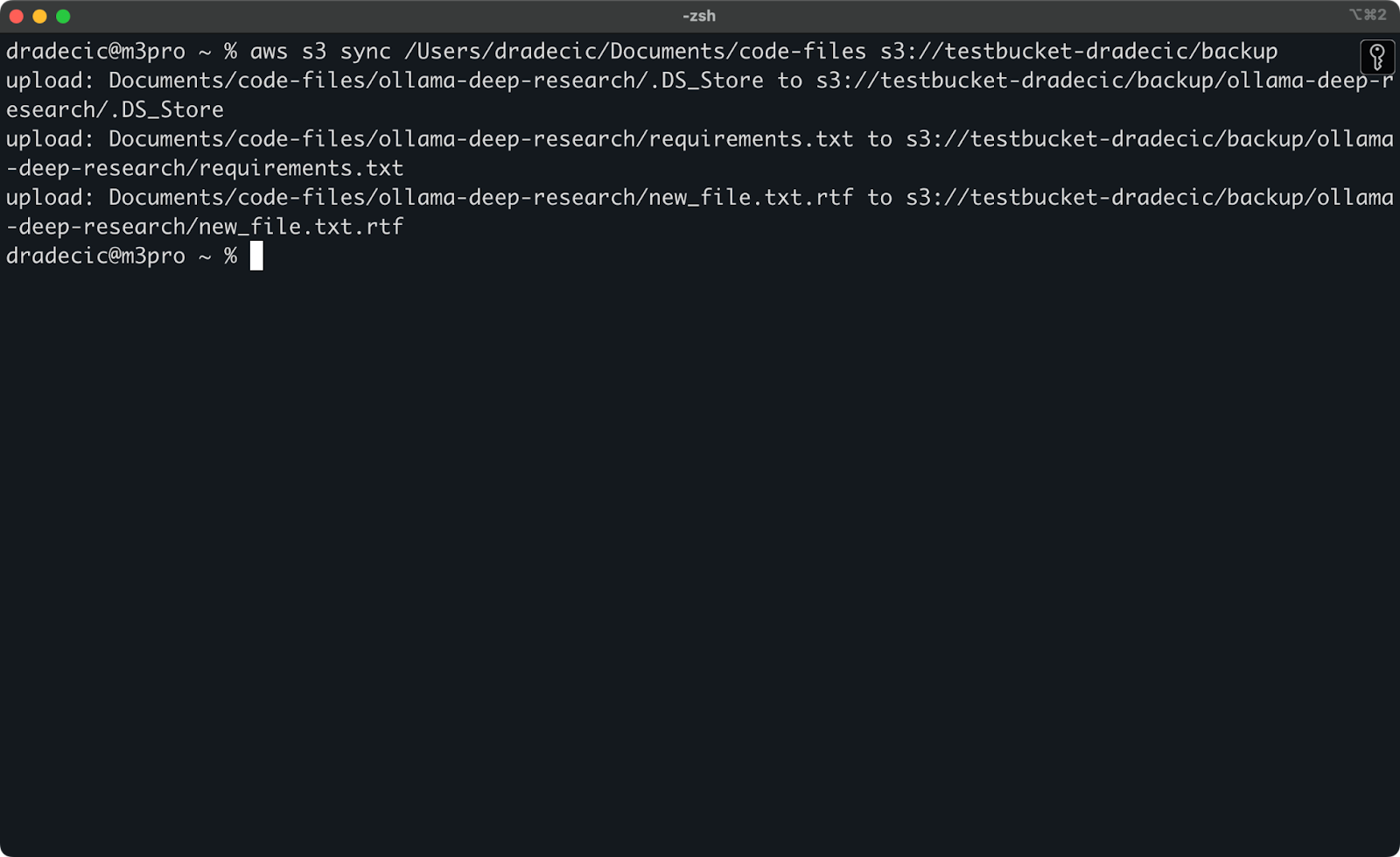
Image 11 – Processus de synchronisation S3 (2)
Et c’est tout ce que vous devez savoir lorsque vous synchronisez des dossiers locaux vers S3. Mais que faire si vous voulez faire l’inverse?
Synchronisation des fichiers du bucket S3 vers un répertoire local
Si vous voulez télécharger des fichiers depuis votre bucket S3 vers votre machine locale, il vous suffit d’inverser la source et la destination:
aws s3 sync s3://testbucket-dradecic/backup /Users/dradecic/Documents/code-files-from-s3
Cette commande téléchargera tous les fichiers du dossier backup de votre bucket S3 vers un dossier local appelé code-files-from-s3. Encore une fois, si le dossier local n’existe pas, le CLI le créera pour vous:
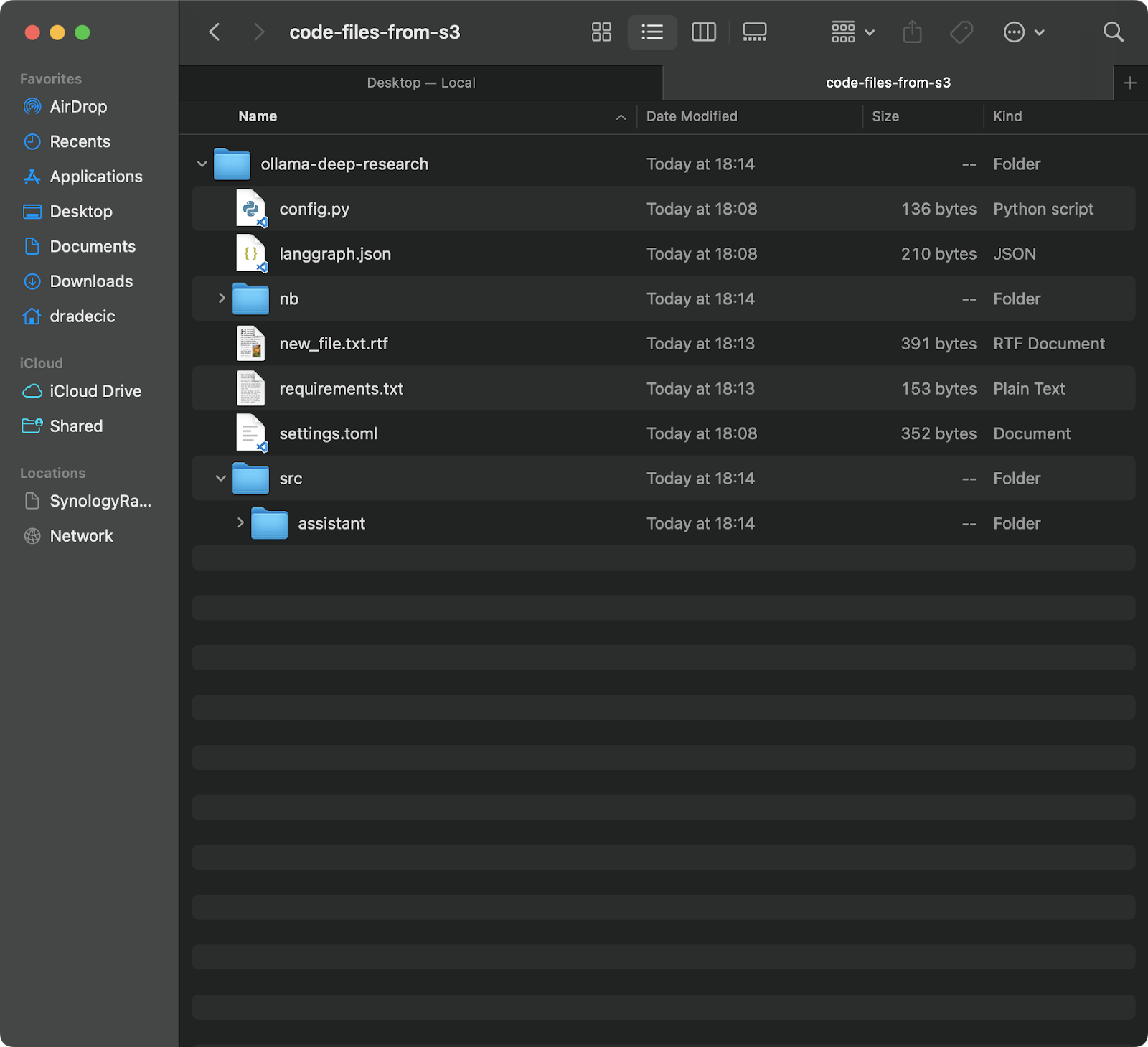
Image 12 – Synchronisation de S3 vers local
Il convient de noter que la synchronisation S3 n’est pas bidirectionnelle. Elle se fait toujours du source vers la destination, faisant correspondre la destination à la source. Si vous supprimez un fichier localement et le synchronisez ensuite avec S3, il existera toujours dans S3. De même, si vous supprimez un fichier dans S3 et le synchronisez de S3 vers le local, le fichier local restera intact.
Si vous souhaitez faire correspondre exactement la destination à la source (y compris les suppressions), vous devrez utiliser le drapeau --delete, que je couvrirai dans la section des options avancées.
Options avancées de synchronisation AWS S3
La commande de synchronisation S3 de base explorée précédemment est puissante en soi, mais AWS l’a enrichie de options supplémentaires qui vous donnent plus de contrôle sur le processus de synchronisation.
Dans cette section, je vais vous montrer quelques-uns des drapeaux les plus utiles que vous pouvez ajouter à la commande de base.
Synchronisation uniquement des fichiers nouveaux ou modifiés
Par défaut, la synchronisation S3 utilise un mécanisme de comparaison de base qui vérifie la taille du fichier et l’heure de modification pour déterminer si un fichier doit être synchronisé. Cependant, cette approche ne capture pas toujours tous les changements, notamment lorsqu’il s’agit de fichiers modifiés mais de taille identique.
Pour une synchronisation plus précise, vous pouvez utiliser le drapeau --exact-timestamps:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup --exact-timestamps
Cela force la synchronisation S3 à comparer les horodatages avec une précision jusqu’aux millisecondes. Gardez à l’esprit que l’utilisation de ce drapeau pourrait ralentir légèrement le processus de synchronisation car il nécessite des comparaisons plus détaillées.
Exclusion ou inclusion de fichiers spécifiques
Parfois, vous ne voulez pas synchroniser chaque fichier dans un répertoire. Peut-être que vous souhaitez exclure les fichiers temporaires, les journaux ou certains types de fichiers (comme .DS_Store dans mon cas). C’est là que les drapeaux --exclude et --include sont utiles.
Mais pour illustrer un point, disons que je veux synchroniser mon répertoire de code mais exclure tous les fichiers Python :
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup --exclude "*.py"
Maintenant, beaucoup moins de fichiers sont synchronisés vers S3 :
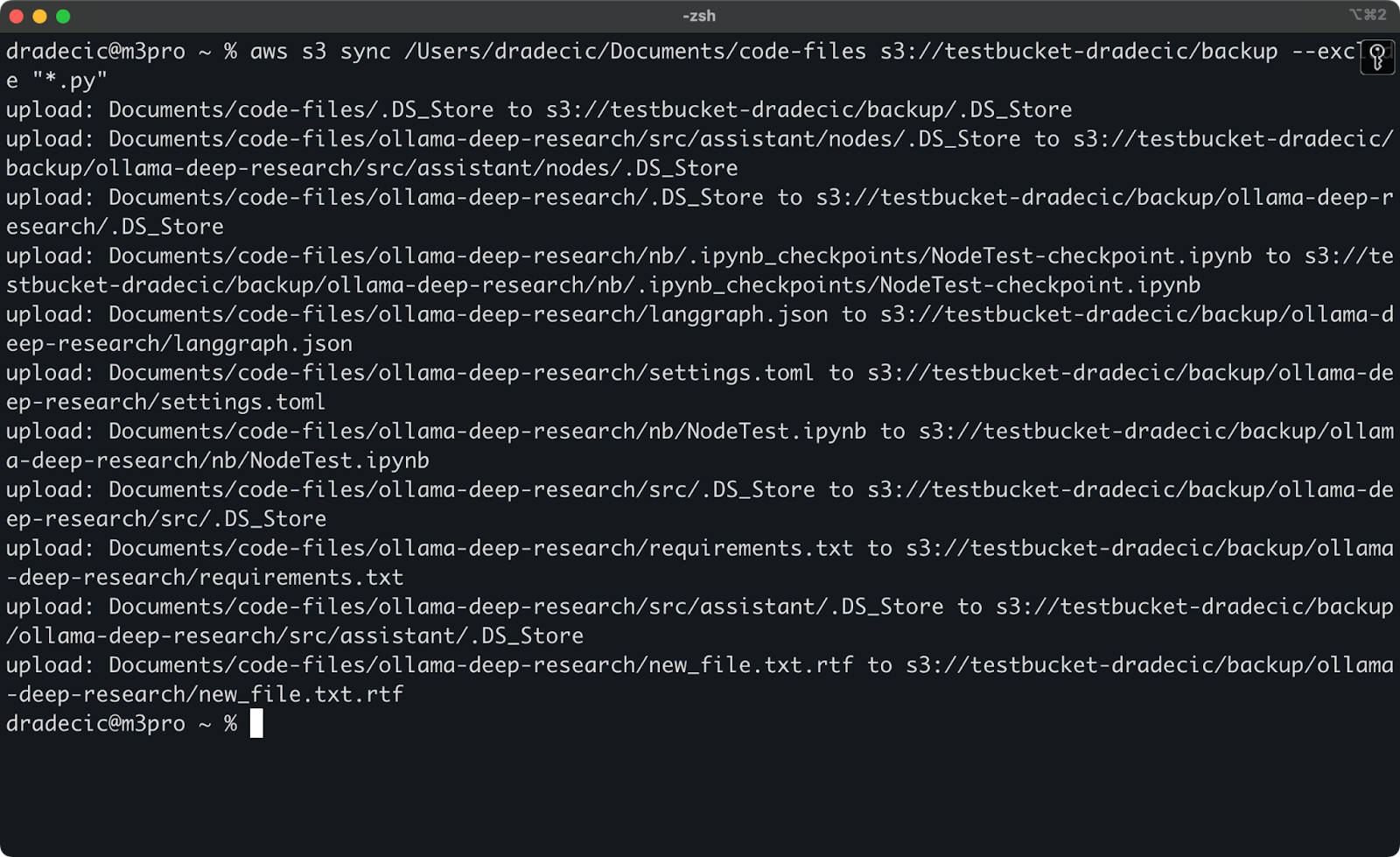
Image 13 – Synchronisation S3 avec exclusion des fichiers Python
Vous pouvez également combiner --exclude et --include pour créer des motifs plus complexes. Par exemple, exclure tout sauf les fichiers Python :
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup --exclude "*" --include "*.py"
Les motifs sont évalués dans l’ordre spécifié, l’ordre est donc important ! Voici ce que vous verrez en utilisant ces drapeaux :
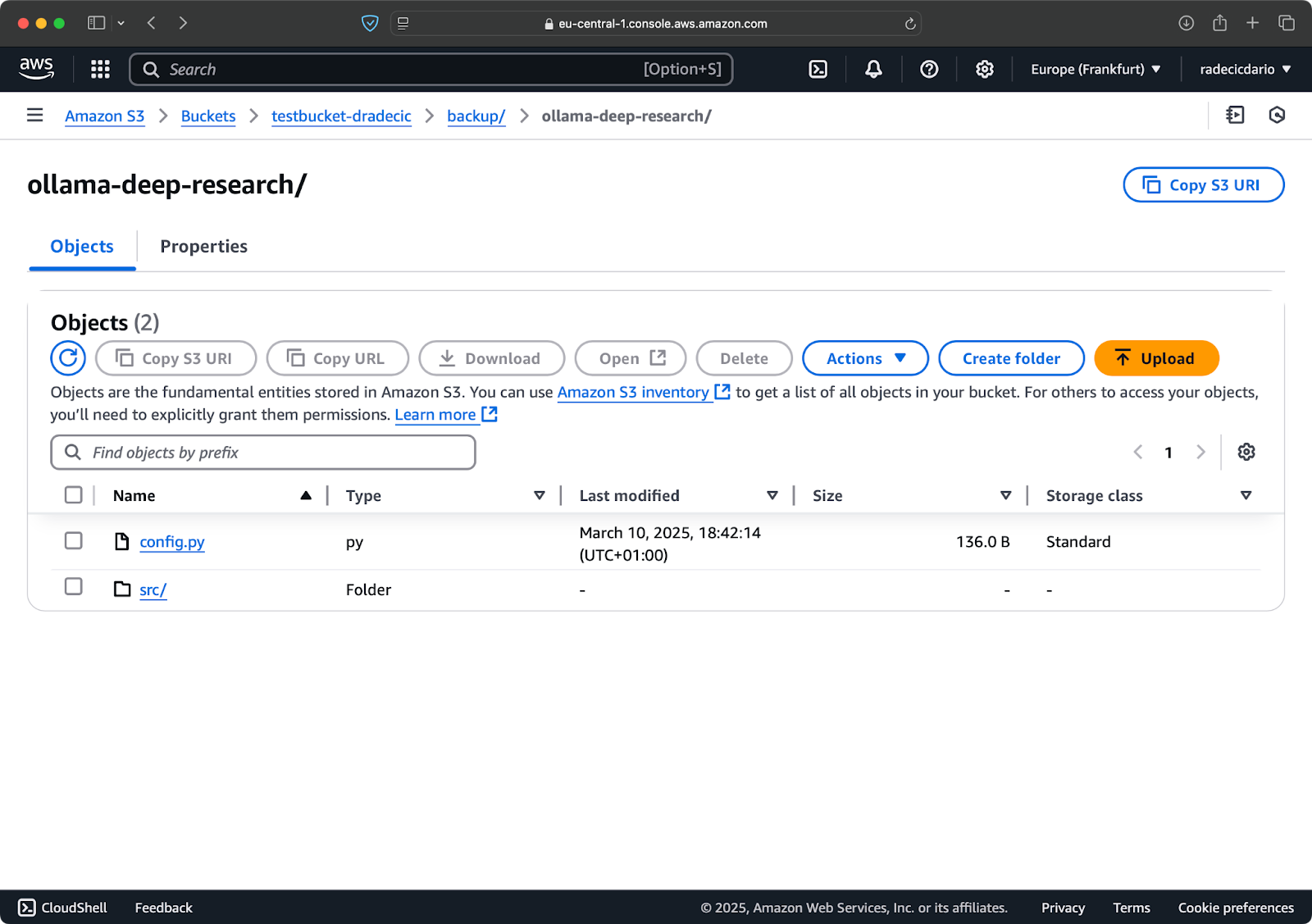
Image 14 – Drapeaux d’exclusion et d’inclusion
À présent, seuls les fichiers Python sont synchronisés, et des fichiers de configuration importants manquent.
Suppression des fichiers de la destination
Par défaut, la synchronisation S3 n’ajoute ou ne met à jour que les fichiers dans la destination, elle ne les supprime jamais. Cela signifie que si vous supprimez un fichier de la source, il restera toujours dans la destination après la synchronisation.
Pour que la destination reflète exactement la source, y compris les suppressions, utilisez le drapeau --delete :
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup --delete
Si vous exécutez ceci pour la première fois, tous les fichiers locaux seront synchronisés vers S3 :
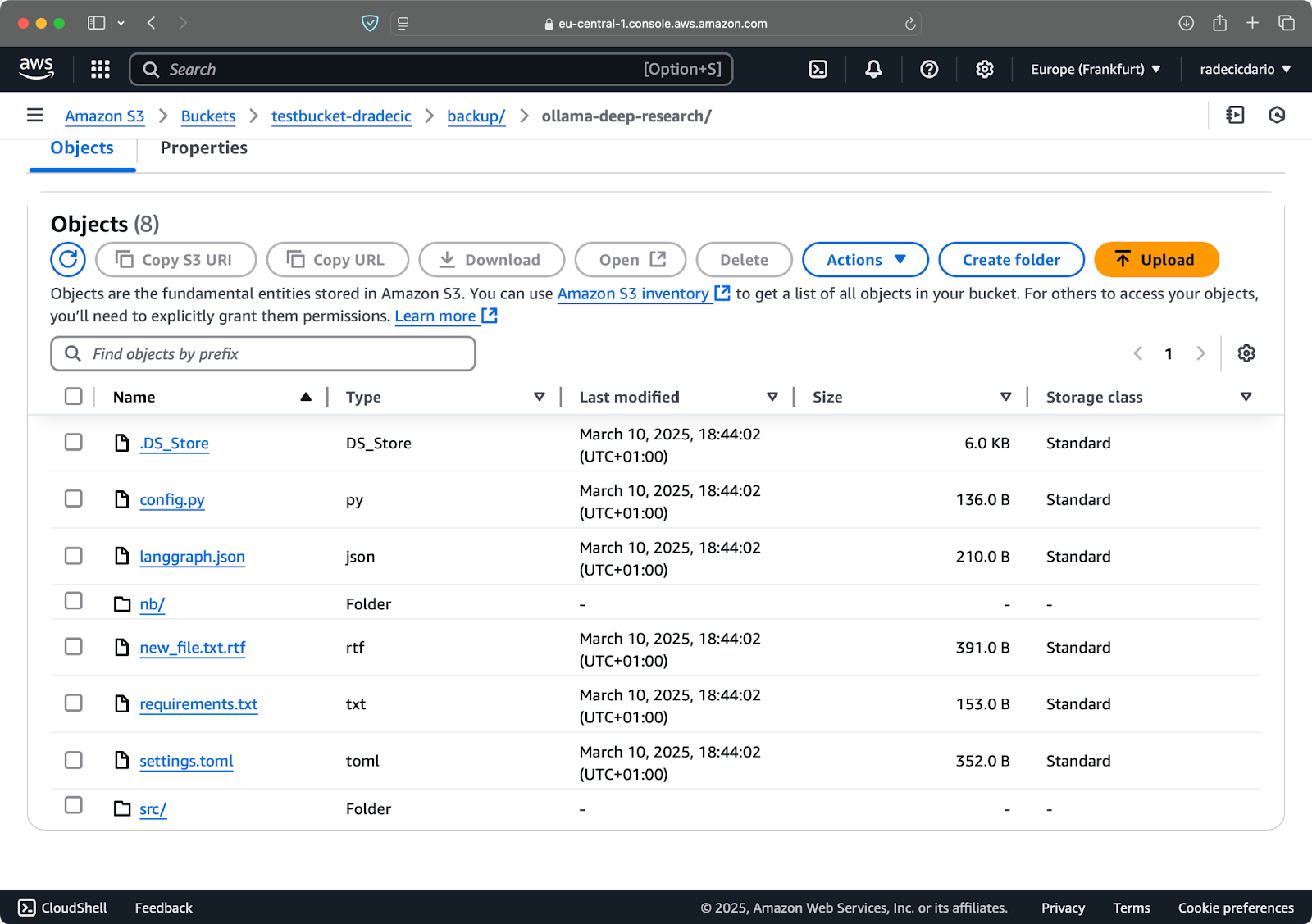
Image 15 – Drapeau de suppression
Cela est particulièrement utile pour maintenir des répliques exactes de répertoires. Mais attention – ce paramètre peut entraîner une perte de données s’il est mal utilisé.
Disons que je supprime config.py de mon dossier local et lance la commande de synchronisation avec le paramètre --delete:
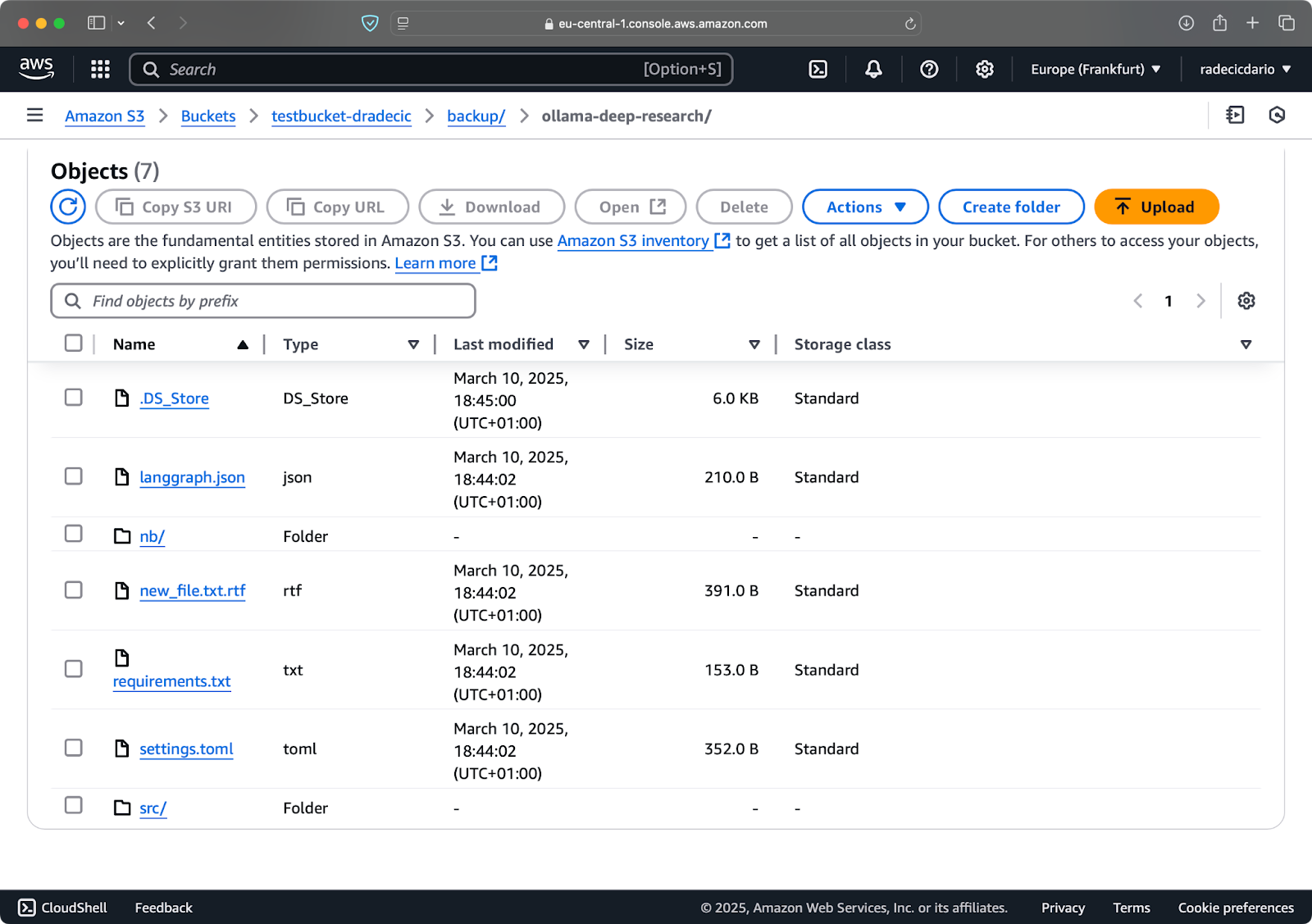
Image 16 – Paramètre de suppression (2)
Comme vous pouvez le constater, la commande synchronise non seulement les fichiers nouveaux et modifiés, mais supprime également les fichiers du compartiment S3 qui n’existent plus dans le répertoire local.
Mise en place d’une simulation pour une synchronisation sécurisée
Les opérations de synchronisation S3 les plus dangereuses sont celles impliquant le drapeau --delete. Pour éviter de supprimer accidentellement des fichiers importants, vous pouvez utiliser le drapeau --dryrun pour simuler l’opération sans apporter de réels changements :
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup --delete --dryrun
Pour illustrer, j’ai supprimé les fichiers requirements.txt et settings.toml d’un dossier local, puis j’ai exécuté la commande :
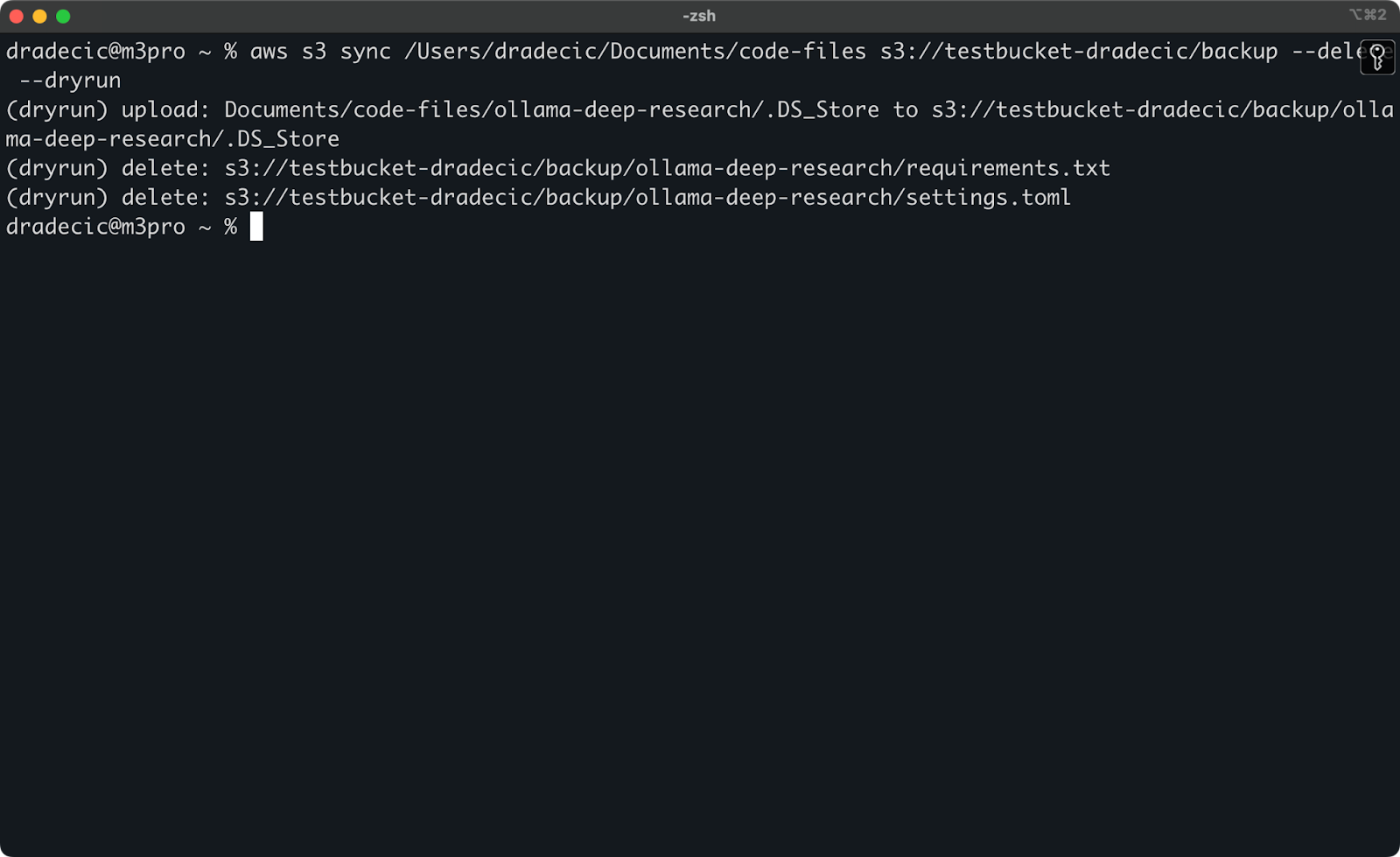
Image 17 – Simulation
Cela vous montrera exactement ce qui se passerait si vous exécutiez la commande pour de vrai, y compris quels fichiers seraient téléchargés, téléversés ou supprimés.
Je recommande toujours d’utiliser --dryrun avant d’exécuter toute commande de synchronisation S3 avec le drapeau --delete, surtout lorsque vous travaillez avec des données importantes.
Il existe de nombreuses autres options disponibles pour la commande de synchronisation S3, telles que --acl pour définir les autorisations, --storage-class pour choisir le niveau de stockage S3, et --recursive pour parcourir les sous-répertoires. Consultez la documentation officielle de l’AWS CLI pour une liste complète des options.
Maintenant que vous êtes familiarisé avec les options de synchronisation S3 de base et avancées, voyons comment utiliser ces commandes pour des scénarios pratiques tels que les sauvegardes et les restaurations.
Utilisation de la synchronisation AWS S3 pour les sauvegardes et les restaurations
Un des cas d’utilisation les plus populaires de la synchronisation S3 AWS est la sauvegarde de fichiers importants et leur restauration en cas de besoin. Découvrons comment mettre en place une stratégie de sauvegarde et de restauration simple en utilisant la commande de synchronisation.
Créer des sauvegardes sur S3
Créer des sauvegardes avec la synchronisation S3 est simple, il vous suffit d’exécuter la commande de synchronisation depuis votre répertoire local vers un bucket S3. Cependant, il existe quelques bonnes pratiques à suivre pour des sauvegardes efficaces.
Tout d’abord, il est conseillé de organiser vos sauvegardes par date ou version. Voici une approche simple utilisant un horodatage dans le chemin S3:
# Créer une variable d'horodatage TIMESTAMP=$(date +%Y-%m-%d-%H-%M-%S) # Lancer la sauvegarde aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backups/$TIMESTAMP
Cela crée un nouveau dossier pour chaque sauvegarde avec un horodatage tel que 2025-03-10-18-56-42. Voici ce que vous verrez sur S3:
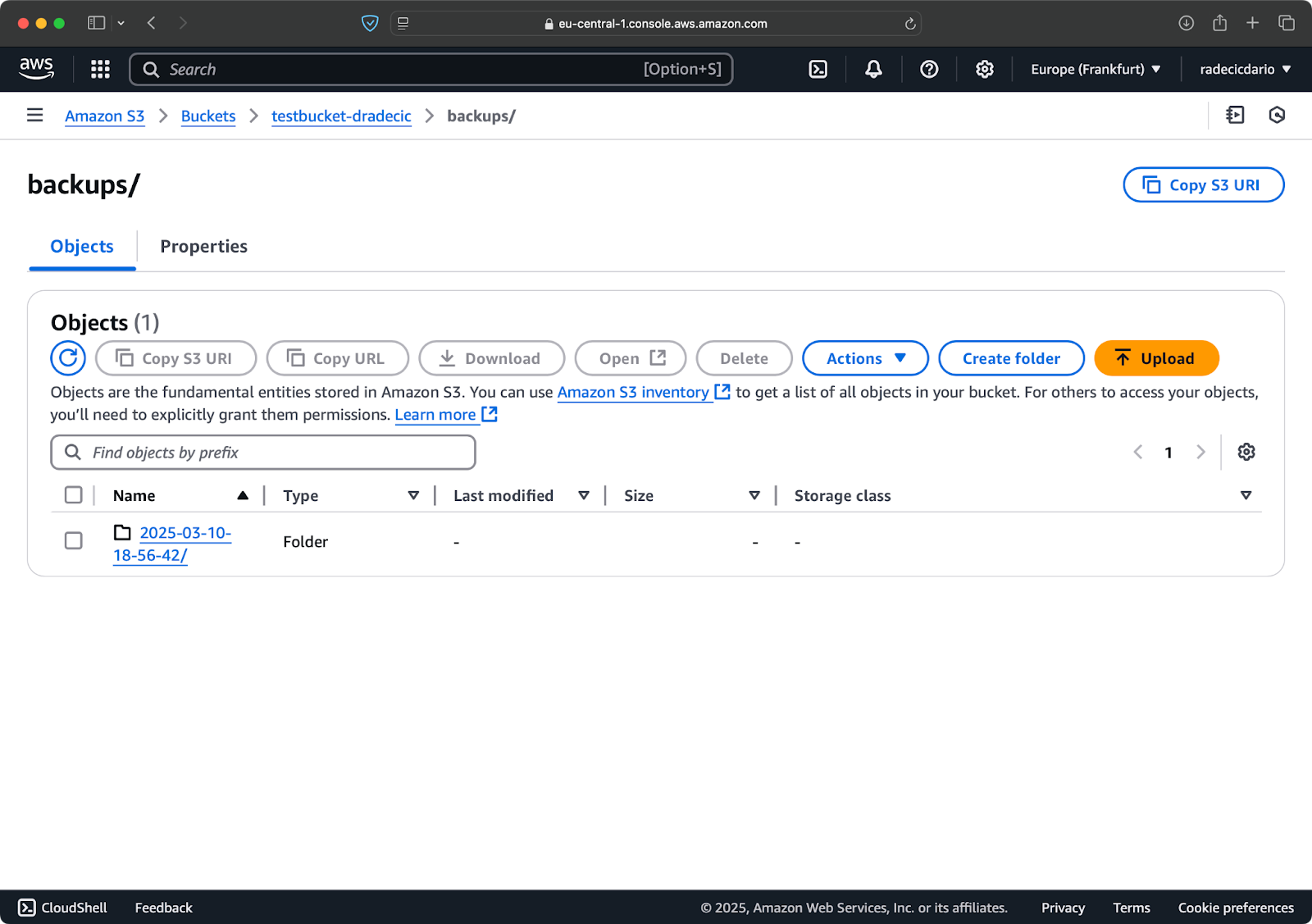
Image 18 – Sauvegardes horodatées
Pour les données critiques, vous voudrez peut-être conserver plusieurs versions de sauvegarde. C’est facile à faire en exécutant régulièrement la sauvegarde basée sur l’horodatage.
Vous pouvez également utiliser l’option --storage-class pour spécifier une classe de stockage plus économique pour vos sauvegardes :
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backups/$TIMESTAMP --storage-class STANDARD_IA
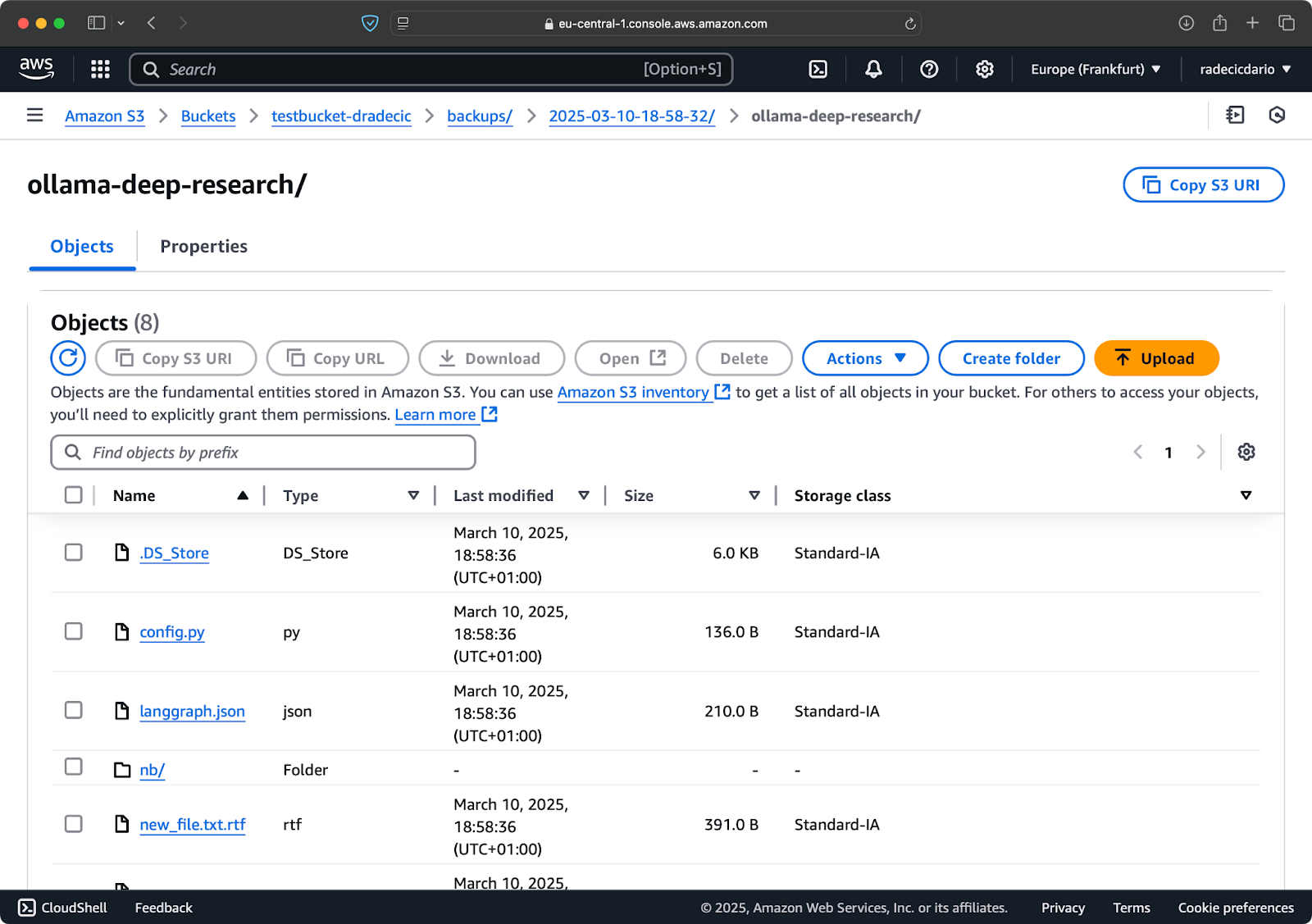
Image 19 – Contenu de la sauvegarde avec une classe de stockage personnalisée
Cela utilise la classe de stockage S3 Infrequent Access, qui coûte moins cher mais a des frais de récupération légers. Pour des archives à long terme, vous pourriez même utiliser la classe de stockage Glacier:
aws s3 sync /Users/dradecic/Documents/important-data s3://testbucket-dradecic/backups/$TIMESTAMP --storage-class GLACIER
Gardez simplement à l’esprit que les fichiers stockés dans Glacier prennent des heures à récupérer, donc ils ne conviennent pas aux données dont vous pourriez avoir besoin rapidement.
Restauration de fichiers depuis S3
La restauration à partir d’une sauvegarde est tout aussi simple – il suffit de inverser la source et la destination dans votre commande de synchronisation:
# Restaurer à partir de la sauvegarde la plus récente (en supposant que vous connaissez l'horodatage) aws s3 sync s3://testbucket-dradecic/backups/2025-03-10-18-56-42 /Users/dradecic/Documents/restored-data
Cela téléchargera tous les fichiers de cette sauvegarde spécifique dans votre répertoire local restored-data:
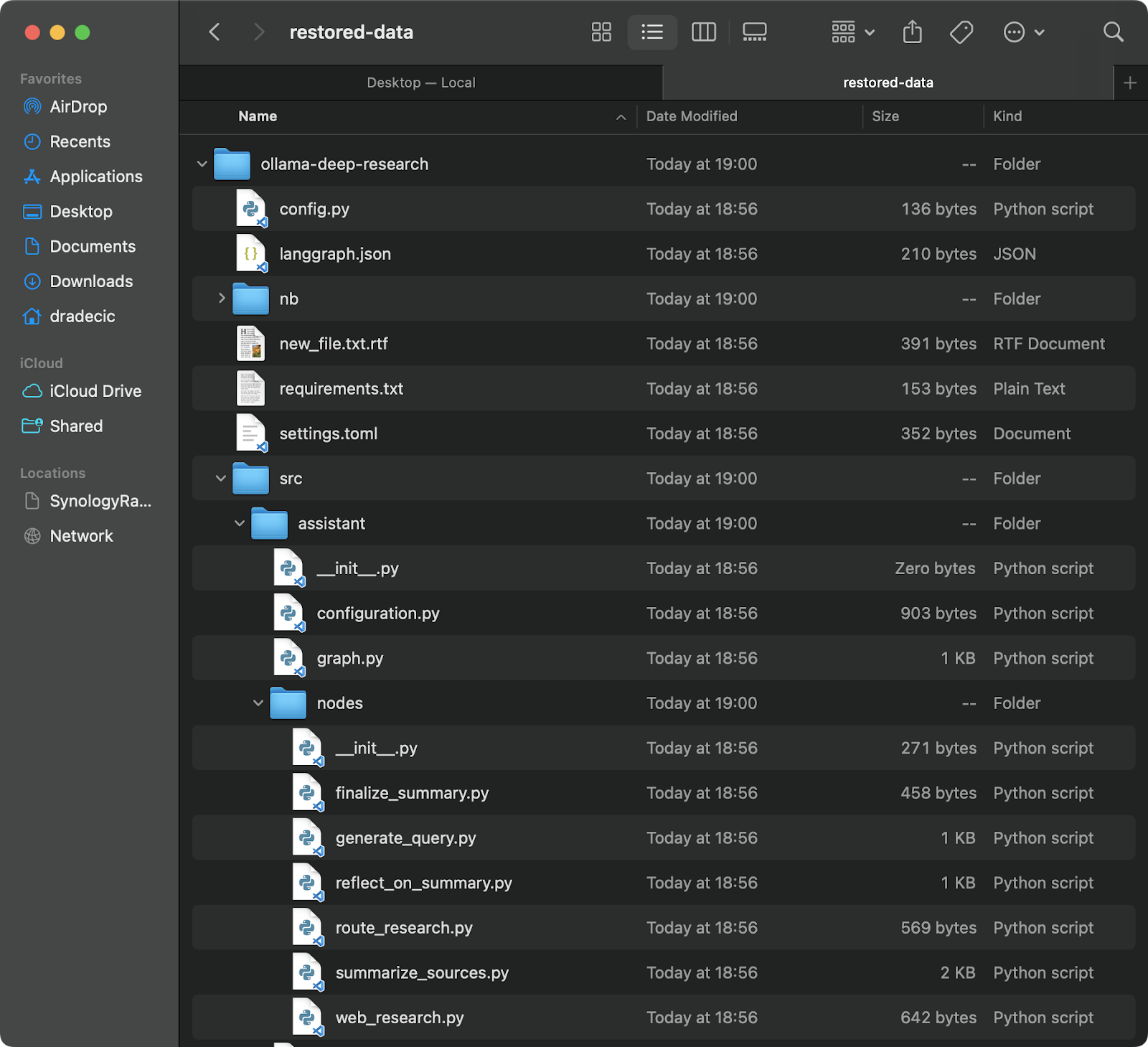
Image 20 – Restauration de fichiers depuis S3
Si vous ne vous souvenez pas de l’horodatage exact, vous pouvez d’abord lister toutes vos sauvegardes:
aws s3 ls s3://testbucket-dradecic/backups/
Ce qui vous montrera quelque chose comme:
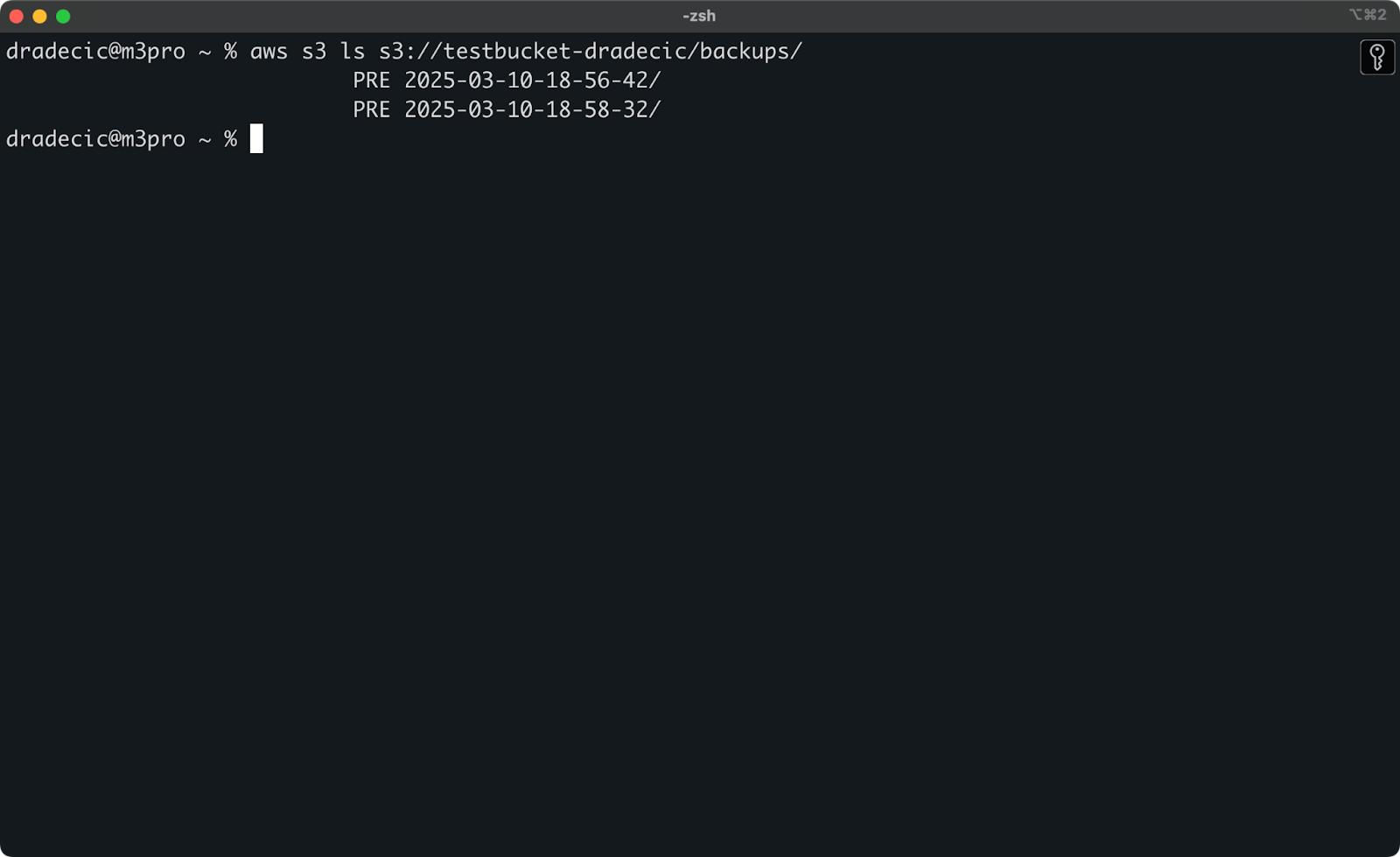
Image 21 – Liste des sauvegardes
Vous pouvez également restaurer des fichiers ou des répertoires spécifiques à partir d’une sauvegarde en utilisant les indicateurs d’exclusion/inclusion que nous avons discutés précédemment:
# Restaurer uniquement les fichiers de configuration aws s3 sync s3://testbucket-dradecic/backups/2025-03-10-18-56-42 /Users/dradecic/Documents/restored-configs --exclude "*" --include "*.config" --include "*.toml" --include "*.yaml"
Pour les systèmes critiques, je recommande d’automatiser vos sauvegardes avec des tâches planifiées (comme des tâches cron sur Linux/macOS ou le Planificateur de tâches sur Windows). Cela garantit que vous sauvegardez régulièrement vos données sans avoir à vous souvenir de le faire manuellement.
Résolution des problèmes de synchronisation AWS S3
La synchronisation AWS S3 est un outil fiable, mais vous pourriez rencontrer occasionnellement des problèmes. Cependant, la plupart des erreurs que vous rencontrerez seront liées à l’humain.
Erreurs de synchronisation courantes
Passons en revue quelques problèmes courants et leurs solutions.
- Erreur d’accès refusé signifie généralement que votre utilisateur IAM n’a pas les autorisations nécessaires pour accéder au compartiment S3 ou effectuer des opérations spécifiques. Pour résoudre ce problème, essayez l’une des solutions suivantes :
- Vérifiez que votre utilisateur IAM a les autorisations S3 appropriées (
s3:ListBucket,s3:GetObject,s3:PutObject). - Vérifiez que la stratégie du compartiment ne refuse pas explicitement l’accès à votre utilisateur.
- Assurez-vous que le compartiment lui-même ne bloque pas l’accès public si vous avez besoin d’opérations publiques.
- Fichier ou répertoire inexistant L’erreur apparaît généralement lorsque le chemin source spécifié dans la commande de synchronisation n’existe pas. La solution est simple – vérifiez à nouveau vos chemins et assurez-vous qu’ils existent. Faites particulièrement attention aux éventuelles fautes de frappe dans les noms de compartiments ou les répertoires locaux.
- Limite de taille de fichier des erreurs peuvent survenir lorsque vous souhaitez synchroniser de gros fichiers. Par défaut, la synchronisation S3 peut gérer des fichiers jusqu’à 5 Go. Pour les fichiers plus volumineux, vous verrez des délais d’attente ou des transferts incomplets.
- Pour les fichiers de plus de 5 Go, vous devriez utiliser le drapeau
--only-show-errorscombiné avec le drapeau--size-only. Cette combinaison aide pour les transferts de gros fichiers en minimisant la sortie et en comparant uniquement les tailles de fichier :
aws s3 sync /Users/dradecic/large-files s3://testbucket-dradecic/large-files --only-show-errors --size-only
Optimisation des performances de synchronisation
Si votre synchronisation S3 est plus lente que prévu, il existe quelques ajustements que vous pouvez faire pour accélérer les choses.
- Utilisez des transferts parallèles. Par défaut, la synchronisation S3 utilise un nombre limité d’opérations parallèles. Vous pouvez augmenter cela avec le paramètre
--max-concurrent-requests:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup --max-concurrent-requests 20
- Adaptez la taille des morceaux. Pour les gros fichiers, vous pouvez optimiser la vitesse de transfert en ajustant la taille des morceaux. Cela divise les gros fichiers en morceaux de 16 Mo au lieu des 8 Mo par défaut, ce qui peut être plus rapide pour les bonnes connexions réseau:
aws s3 sync /Users/dradecic/large-files s3://testbucket-dradecic/backup --cli-read-timeout 120 --multipart-threshold 64MB --multipart-chunksize 16MB
- Utilisez
--no-progresspour les scripts. Si vous exécutez la synchronisation S3 dans un script automatisé, utilisez le drapeau--no-progresspour réduire la sortie et améliorer les performances:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup --no-progress
- Utilisez des points de terminaison locaux. Si vos ressources AWS se trouvent dans la même région, spécifier le point de terminaison régional peut réduire la latence:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup --endpoint-url https://s3.eu-central-1.amazonaws.com
Ces optimisations peuvent significativement améliorer les performances de synchronisation, surtout pour les transferts de données volumineux ou lorsqu’ils sont exécutés sur des machines moins puissantes.
Si vous rencontrez toujours des problèmes après avoir essayé ces solutions, l’AWS CLI dispose d’une option de débogage intégrée. Il suffit d’ajouter --debug à votre commande pour voir des informations détaillées sur ce qui se passe pendant le processus de synchronisation:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup --debug
Attendez-vous à voir beaucoup de messages de journal détaillés, similaires à ceux-ci:
Image 22 – Exécution de la synchronisation en mode débogage
Et c’est à peu près tout en matière de dépannage de la synchronisation AWS S3. Bien sûr, d’autres erreurs peuvent survenir, mais 99 % du temps, vous trouverez la solution dans cette section.
Récapitulatif de la synchronisation AWS S3
En résumé, la synchronisation AWS S3 est l’un de ces outils rares à la fois simples à utiliser et incroyablement puissants. Vous avez appris tout, des commandes de base aux options avancées, en passant par les stratégies de sauvegarde et les conseils de dépannage.
Pour les développeurs, les administrateurs système ou toute personne travaillant avec AWS, la commande S3 sync est un outil essentiel – il fait gagner du temps, réduit l’utilisation de la bande passante et garantit que vos fichiers sont là où vous en avez besoin, quand vous en avez besoin.
Que vous sauvegardiez des données critiques, déployiez des ressources web ou simplement mainteniez la synchronisation entre différents environnements, la synchronisation AWS S3 rend le processus simple et fiable.
La meilleure façon de se familiariser avec la synchronisation S3 est de commencer à l’utiliser. Essayez de configurer une opération de synchronisation simple avec vos propres fichiers, puis explorez progressivement les options avancées pour répondre à vos besoins spécifiques.
N’oubliez pas d’utiliser toujours --dryrun d’abord lorsque vous travaillez avec des données importantes, surtout lorsque vous utilisez le drapeau --delete. Il vaut mieux prendre une minute supplémentaire pour vérifier ce qui va se passer que de supprimer accidentellement des fichiers importants.
Pour en savoir plus sur AWS, consultez ces cours par DataCamp :
- Introduction à AWS
- Technologie et Services Cloud AWS
- Sécurité et Gestion des Coûts AWS
- Introduction à AWS Boto en Python
Vous pouvez même utiliser DataCamp pour vous préparer aux examens de certification AWS – Praticien Cloud AWS (CLF-C02).