













Configurando a AWS CLI e o AWS S3
Antes de começar a sincronizar arquivos com o S3, você precisará configurar corretamente a AWS CLI. Isso pode parecer intimidante se você é novo na AWS, mas só vai levar alguns minutos.
Configurar a CLI envolve dois passos principais: instalar a ferramenta e configurá-la. Vou explicar ambos os passos a seguir.
Instalando a AWS CLI
A instalação da AWS CLI varia ligeiramente dependendo do seu sistema operacional.
Para sistemas Windows:
- Acesse a página de download do AWS CLI
- Windows installer (64 bits)
- Execute o instalador e siga as instruções
Para sistemas Linux:
Execute os três comandos a seguir pelo Terminal:
curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip" unzip awscliv2.zip sudo ./aws/install
Para sistemas macOS:
Supondo que você tenha o Homebrew instalado, execute esta linha no Terminal:
brew install awscli
Se você não tem o Homebrew, use esses dois comandos em vez disso:
curl "https://awscli.amazonaws.com/AWSCLIV2.pkg" -o "AWSCLIV2.pkg" sudo installer -pkg AWSCLIV2.pkg -target /
Você pode executar o comando aws --version em todos os sistemas operacionais para verificar se o AWS CLI foi instalado. Veja o que você deve ver:
Imagem 1 – Versão do AWS CLI
Configurando o AWS CLI
Agora que você tem o CLI instalado, precisa configurá-lo com suas credenciais da AWS.
Supondo que você já tenha uma conta na AWS, faça login e acesse o serviço IAM. Uma vez lá, crie um novo usuário com acesso programático. Você deve atribuir as permissões apropriadas ao usuário, sendo o acesso ao S3 no mínimo:
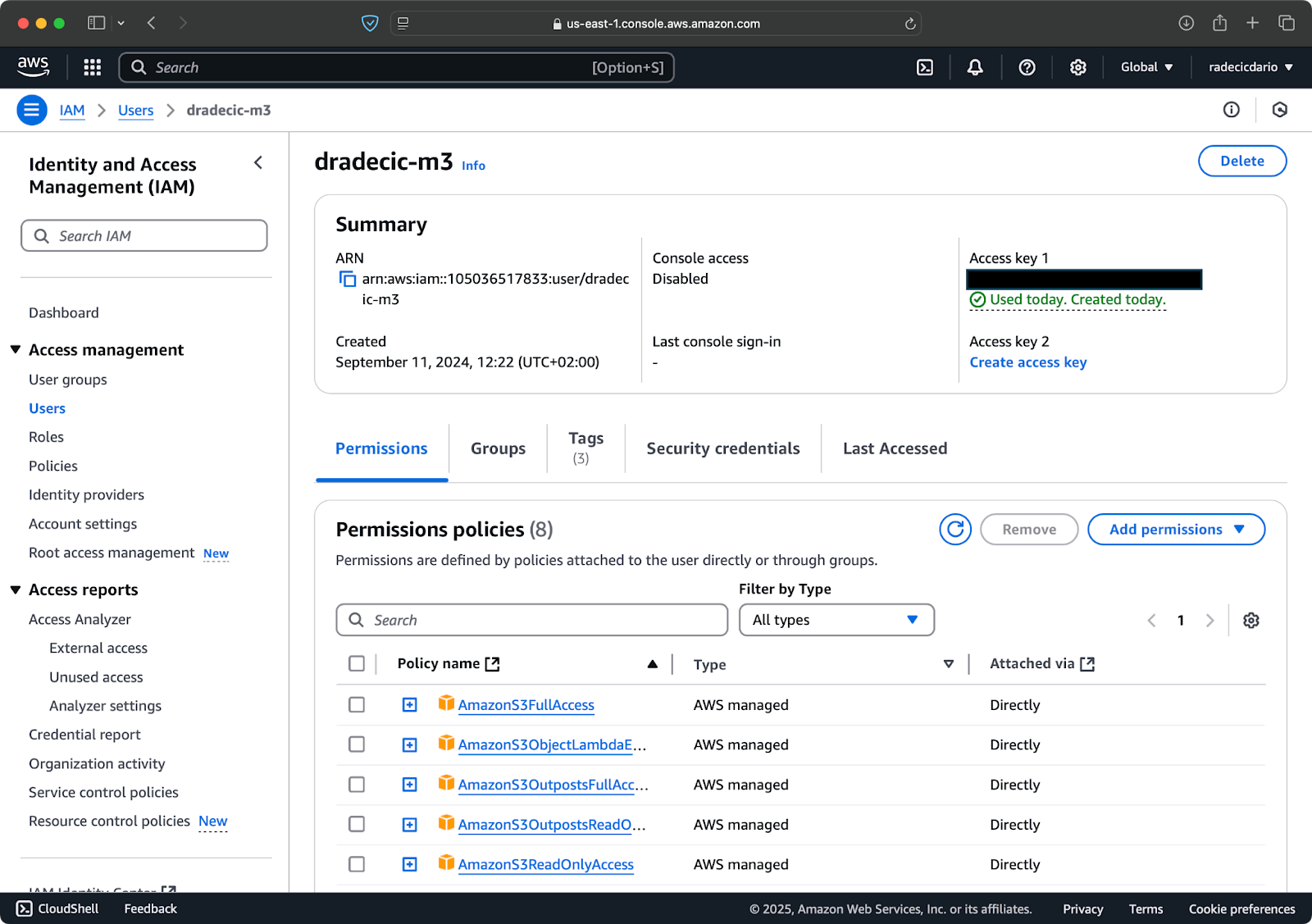
Imagem 2 – Usuário AWS IAM
Depois de concluído, vá para “Credenciais de segurança” para criar uma nova chave de acesso. Após a criação, você terá tanto a ID da chave de acesso quanto a Chave de acesso secreta. Anote-os em um local seguro porque você não poderá acessá-los no futuro:
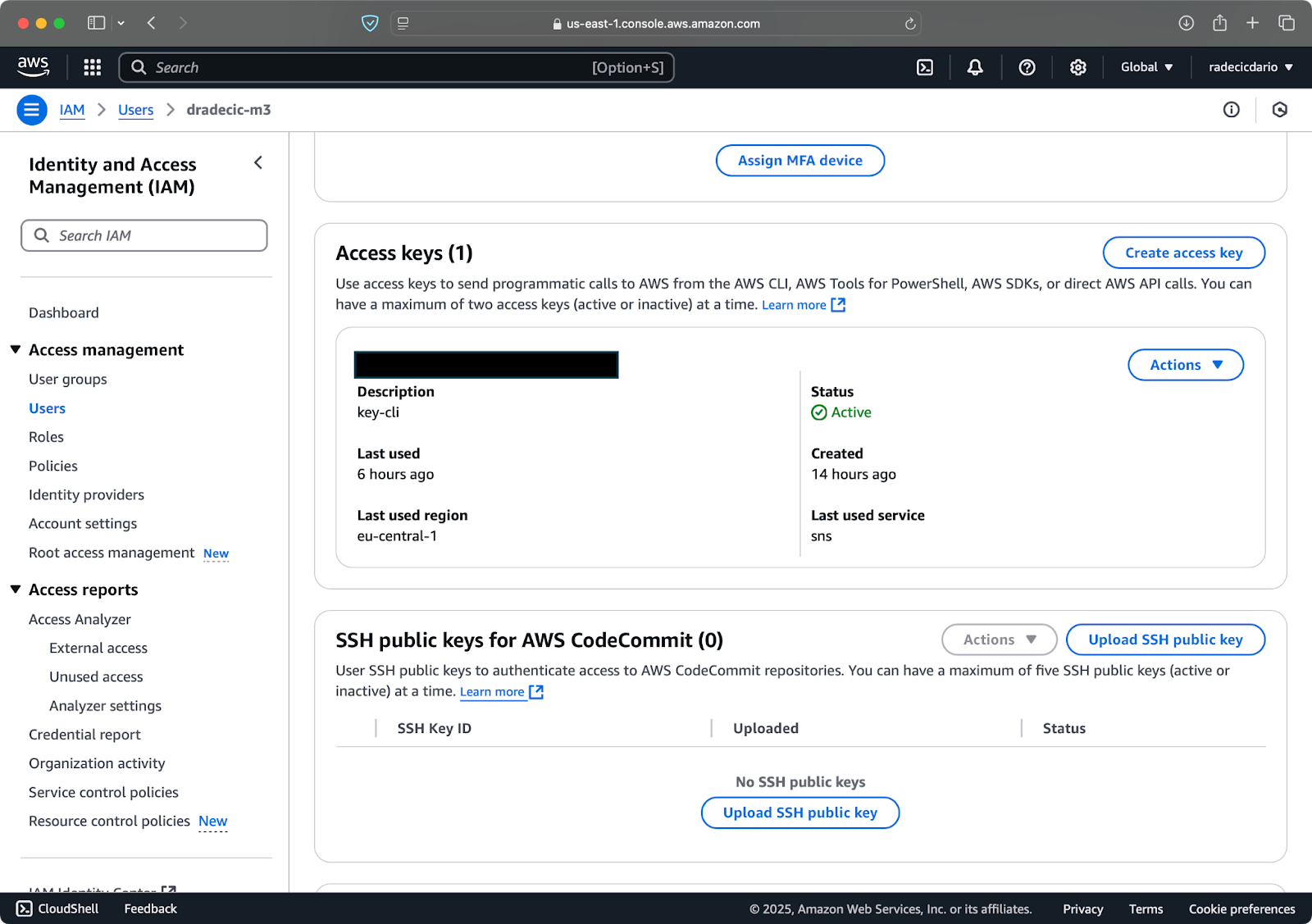
Imagem 3 – Credenciais de usuário AWS IAM
De volta ao Terminal, execute o comando aws configure. Ele solicitará que você insira sua ID da chave de acesso, chave de acesso secreta, região (eu-central-1 no meu caso) e formato de saída preferido (json):
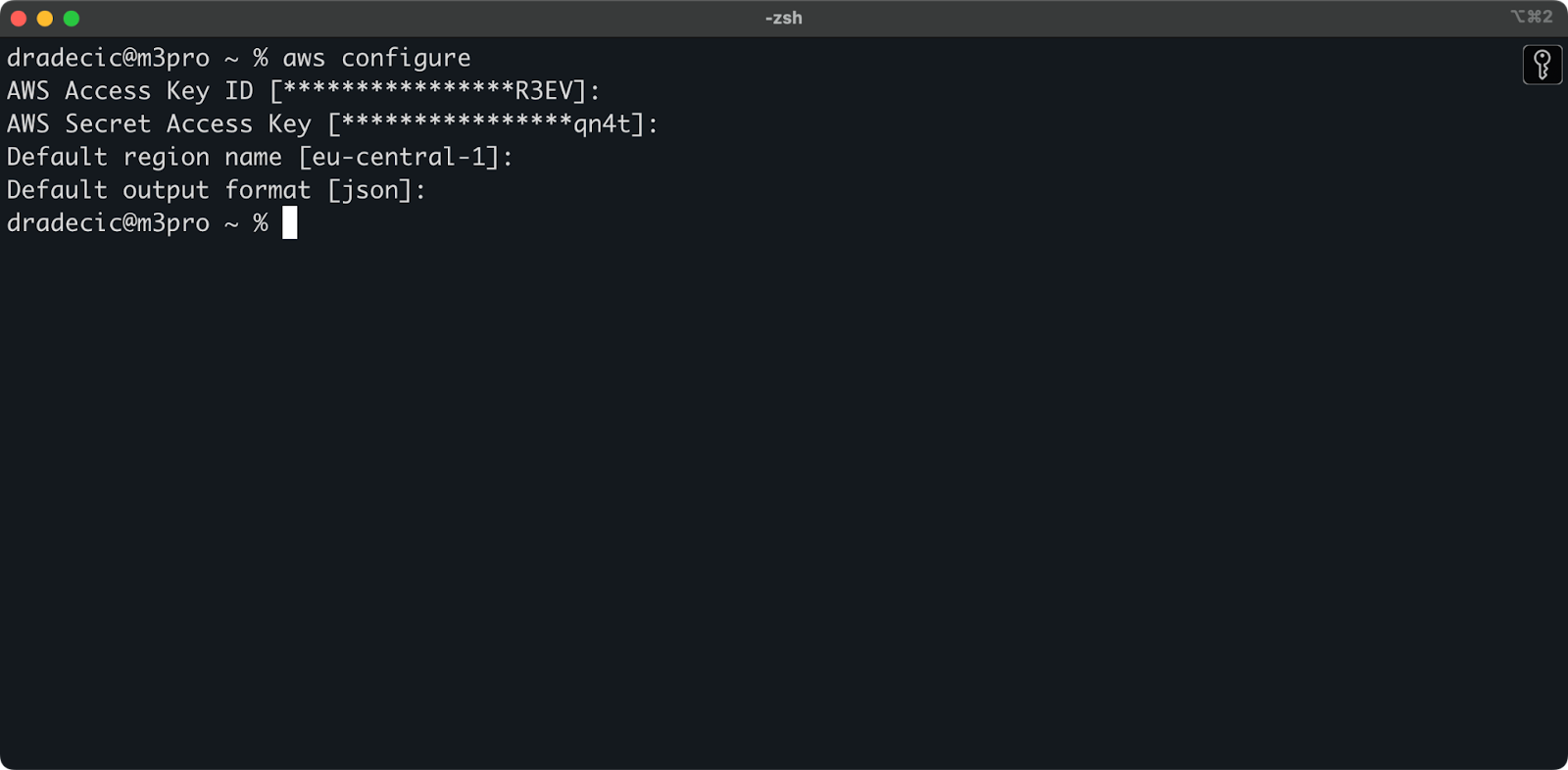
Imagem 4 – Configuração do AWS CLI
Para verificar se você está conectado com sucesso à sua conta da AWS a partir do CLI, execute o seguinte comando:
aws sts get-caller-identity
Este é o resultado que você deve ver:
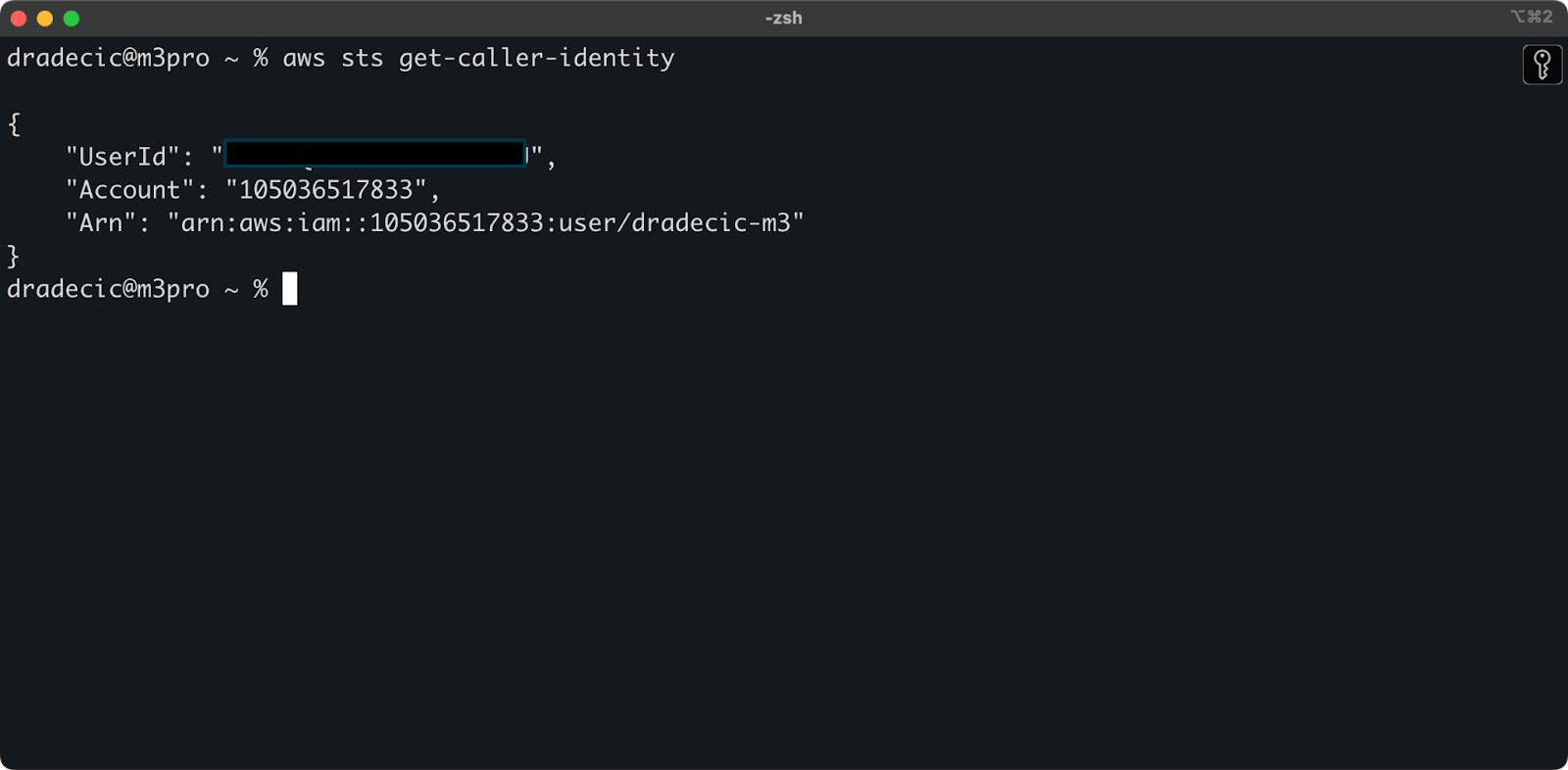
Imagem 5 – Comando de teste de conexão do AWS CLI
E é isso – apenas mais um passo antes de começar a usar o comando de sincronização do S3!
Configuração de um bucket do AWS S3
A etapa final é criar um bucket S3 que armazenará seus arquivos sincronizados. Você pode fazer isso pelo CLI ou pelo AWS Management Console. Vou optar por este último, apenas para variar.
Para começar, vá até a página do serviço S3 no Management Console e clique no botão “Criar bucket”. Uma vez lá, escolha um nome de bucket exclusivo (único globalmente em toda a AWS) e então role até o final e clique no botão “Criar”:
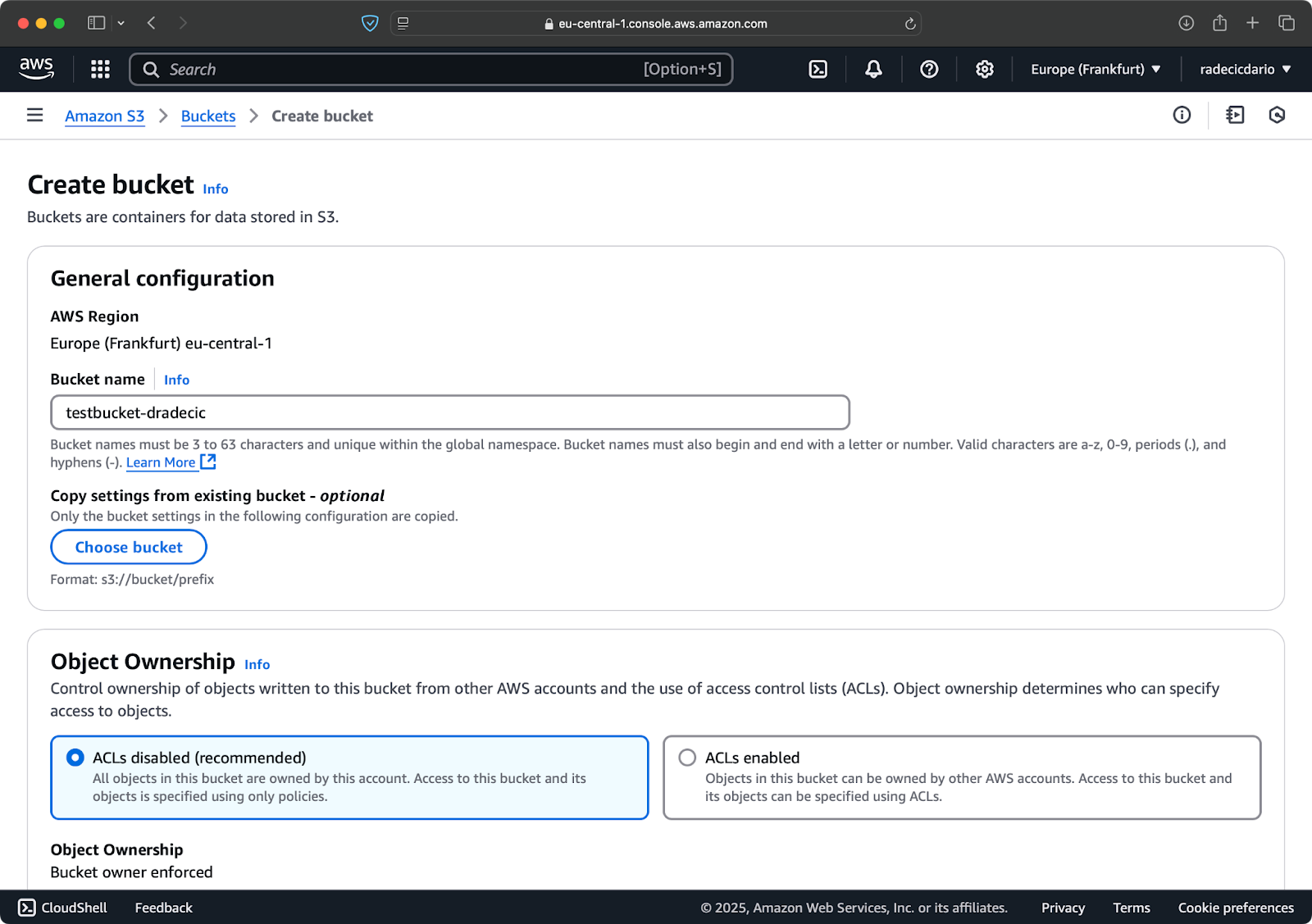
Imagem 6 – Criação de bucket na AWS
O bucket agora está criado, e você o verá imediatamente no console de gerenciamento. Você também pode verificar se ele foi criado através do CLI:
aws s3 ls
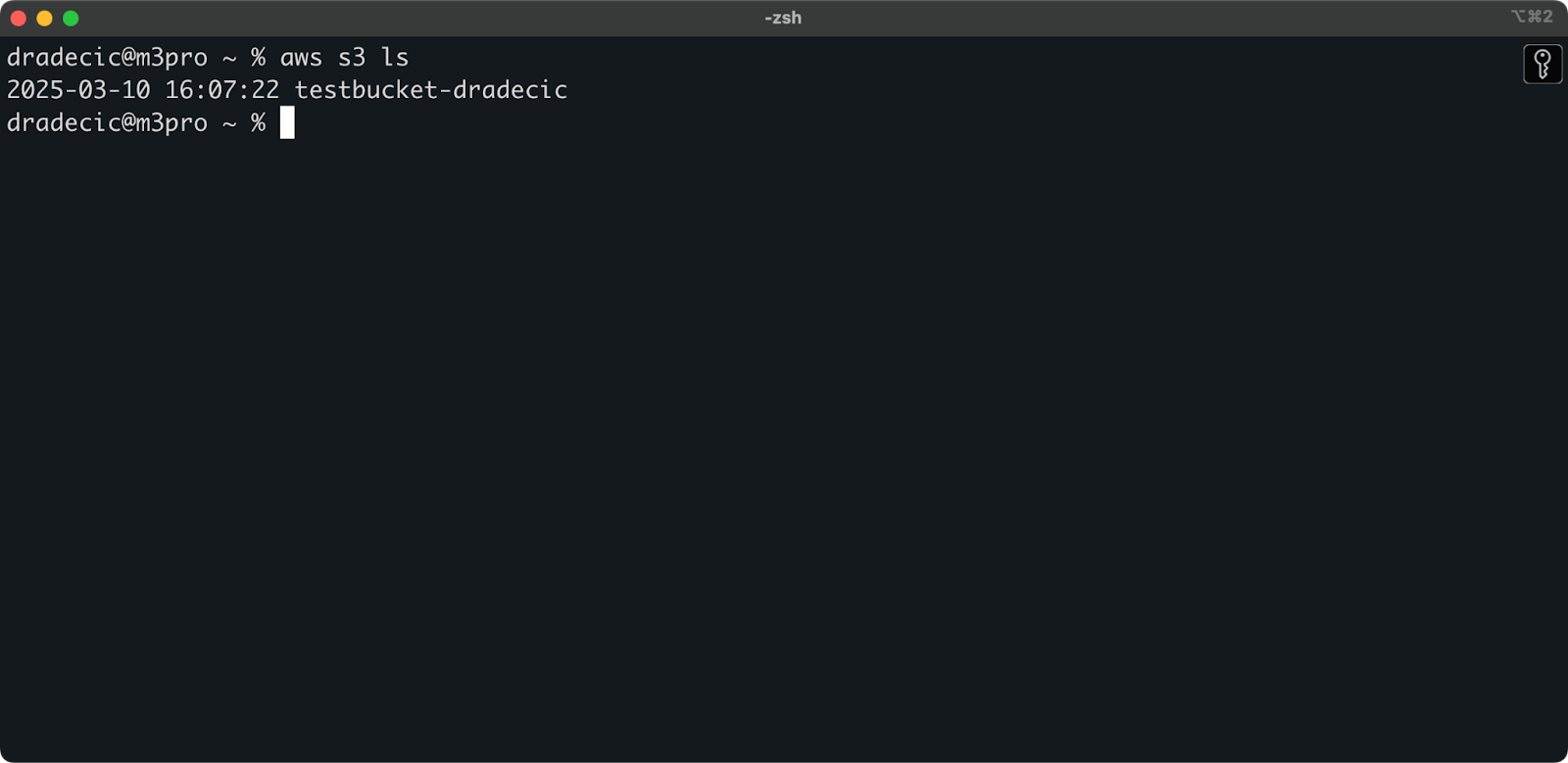
Imagem 7 – Todos os buckets S3 disponíveis
Lembre-se de que os buckets S3 são privados por padrão. Se você pretende usar o bucket para hospedar arquivos públicos (como ativos de um site), precisará ajustar as políticas e permissões do bucket conforme necessário.
Agora você está pronto para começar a sincronizar arquivos entre sua máquina local e o AWS S3!
Comando básico de sincronização do AWS S3
Agora que você tem o AWS CLI instalado, configurado e um bucket S3 pronto para uso, é hora de começar a sincronizar! A sintaxe básica para o comando de sincronização do AWS S3 é bastante simples. Deixe-me mostrar como funciona.
O comando de sincronização do S3 segue este padrão simples:
aws s3 sync <source> <destination> [options]
Tanto a origem quanto o destino podem ser um caminho de diretório local ou um URI S3 (começando com s3://). Dependendo de qual forma você deseja sincronizar, você os organizará de maneira diferente.
Sincronizando arquivos do local para um bucket S3
Eu estava brincando recentemente com a pesquisa profunda do Ollama. Digamos que essa seja a pasta que eu quero sincronizar com o S3. O diretório principal está localizado na pasta Documents. Veja como está:
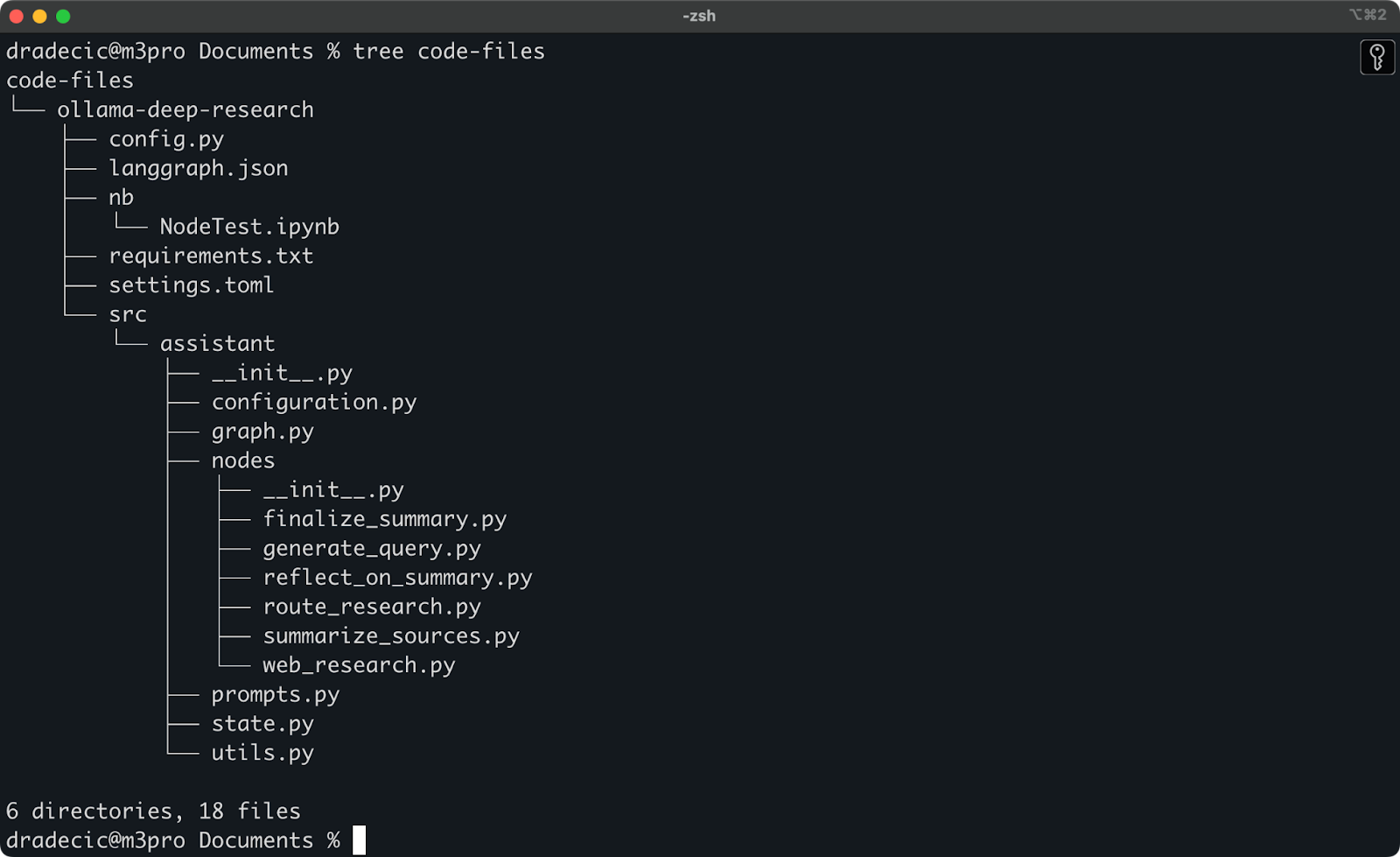
Conteúdo da pasta local
Este é o comando que preciso executar para sincronizar a pasta local code-files com a pasta backup no bucket S3:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup
A pasta backup no bucket S3 será criada automaticamente se não existir.
Aqui está o que você verá impresso no console:
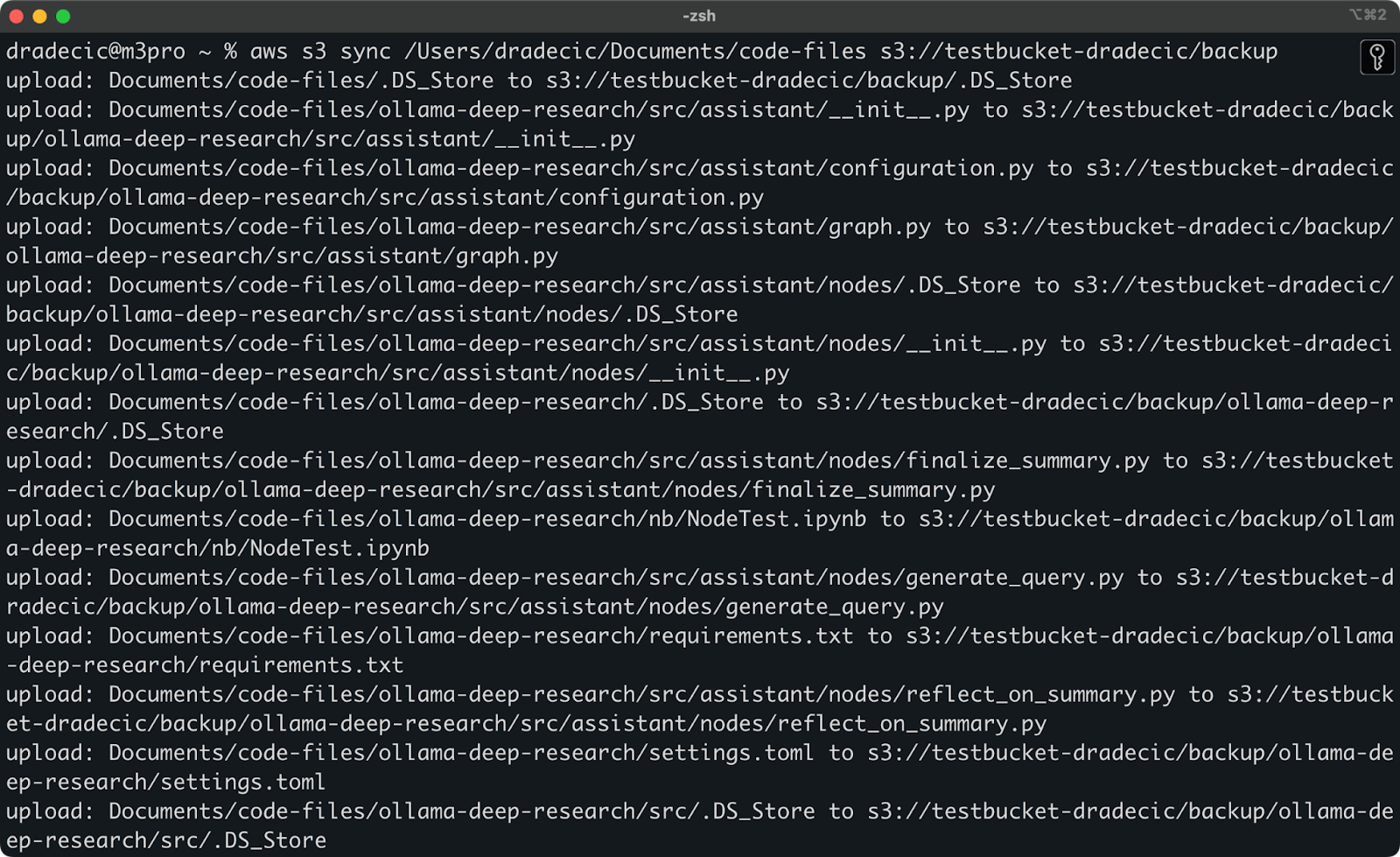
Imagem 9 – Processo de sincronização S3
Após alguns segundos, o conteúdo da pasta local code-files está disponível no bucket S3:
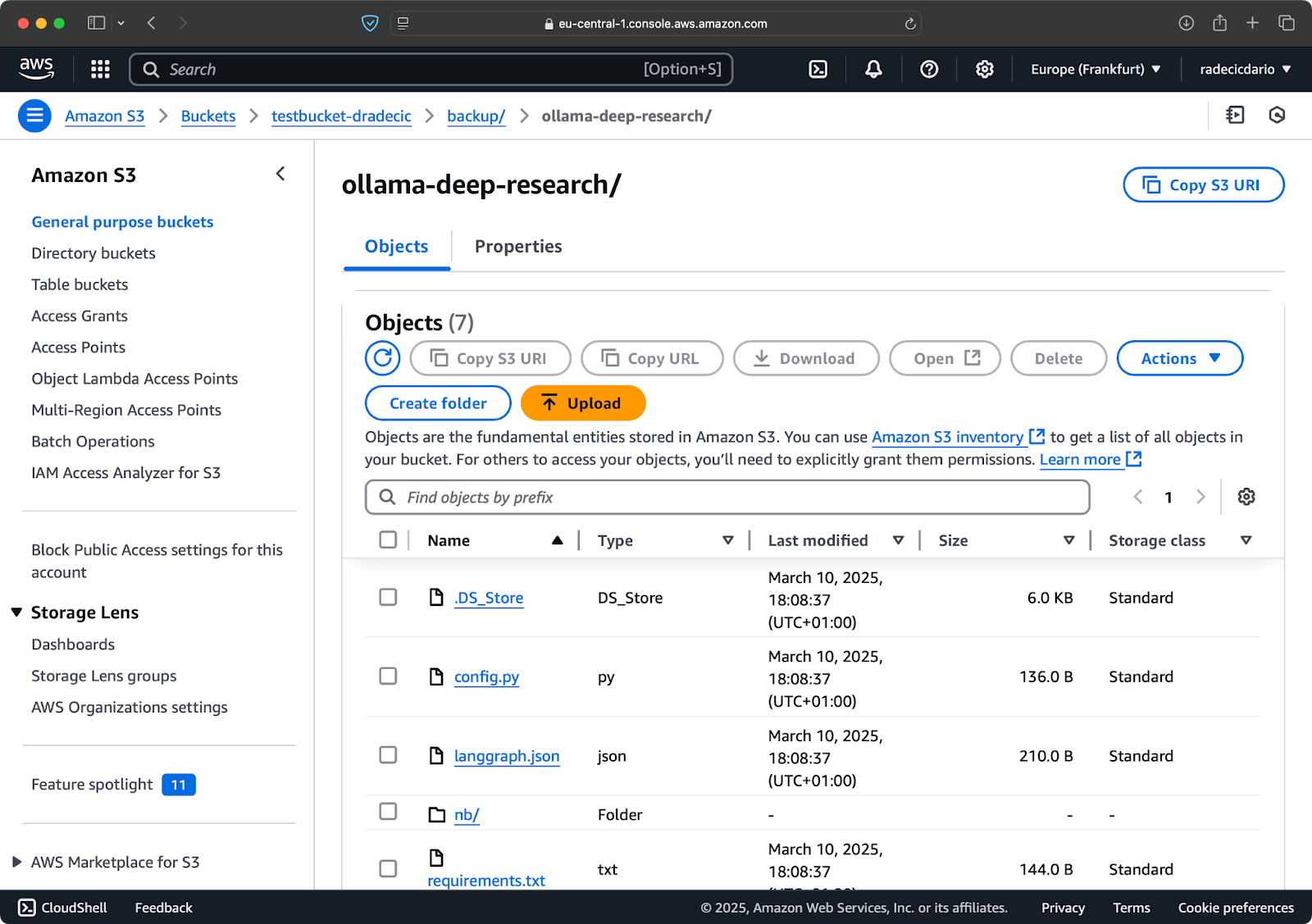
Imagem 10 – Conteúdo do bucket S3
A beleza da sincronização S3 é que ela apenas faz upload de arquivos que não existem no destino ou foram modificados localmente. Se você executar o mesmo comando novamente sem alterar nada, você verá… nada! Isso porque a AWS CLI detectou que todos os arquivos já estão sincronizados e atualizados.
Agora, farei duas pequenas mudanças – criar um novo arquivo (new_file.txt) e atualizar um existente (requirements.txt). Quando você executar o comando de sincronização novamente, apenas os arquivos novos ou modificados serão enviados:
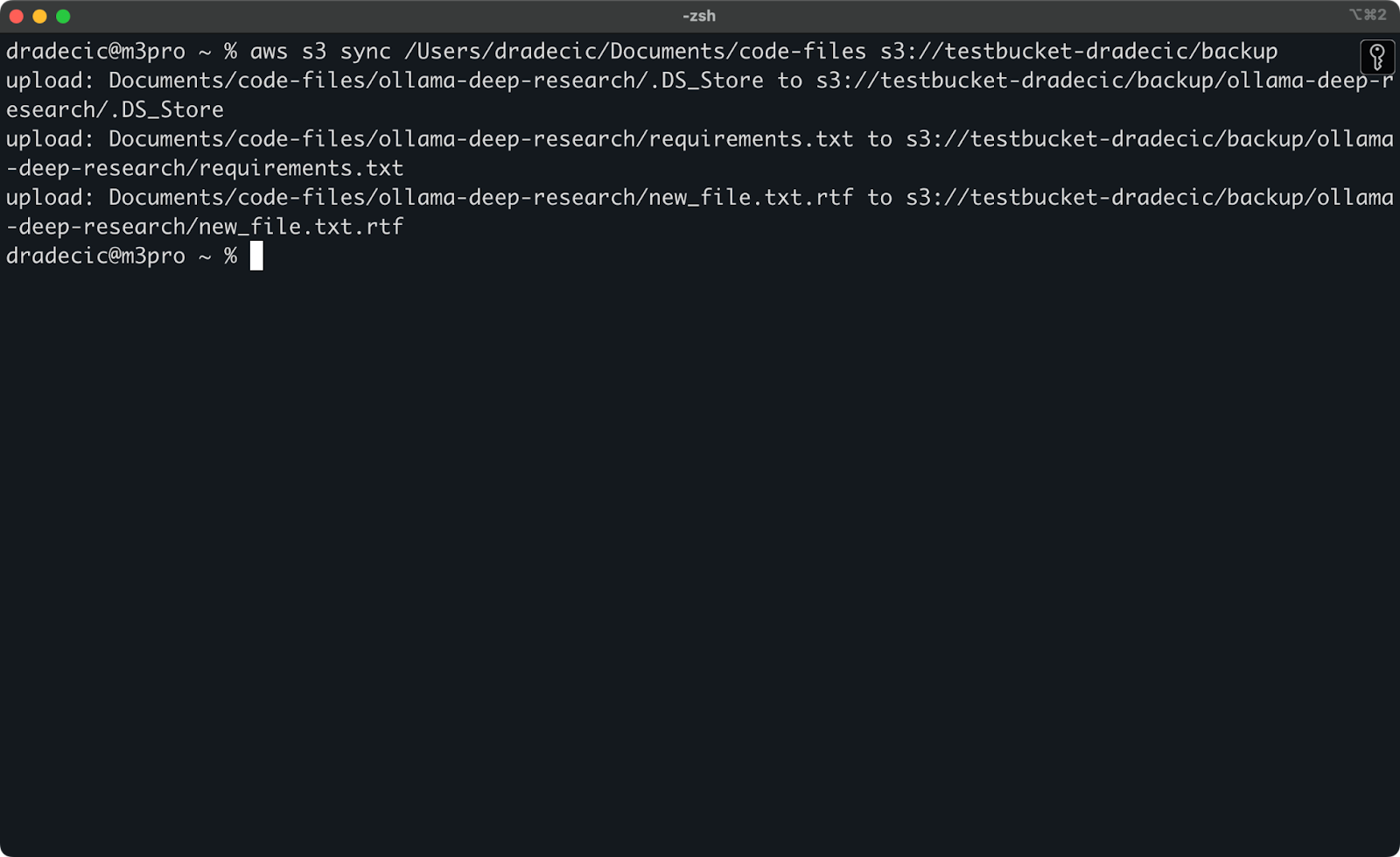
Imagem 11 – Processo de sincronização S3 (2)
E isso é tudo que você precisa saber ao sincronizar pastas locais com o S3. Mas e se você quiser fazer o contrário?
Sincronizando arquivos do bucket S3 para um diretório local
Se você deseja baixar arquivos do seu bucket S3 para sua máquina local, basta inverter a origem e o destino:
aws s3 sync s3://testbucket-dradecic/backup /Users/dradecic/Documents/code-files-from-s3
Este comando irá baixar todos os arquivos da pasta backup em seu bucket S3 para uma pasta local chamada code-files-from-s3. Novamente, se a pasta local não existir, o CLI a criará para você:
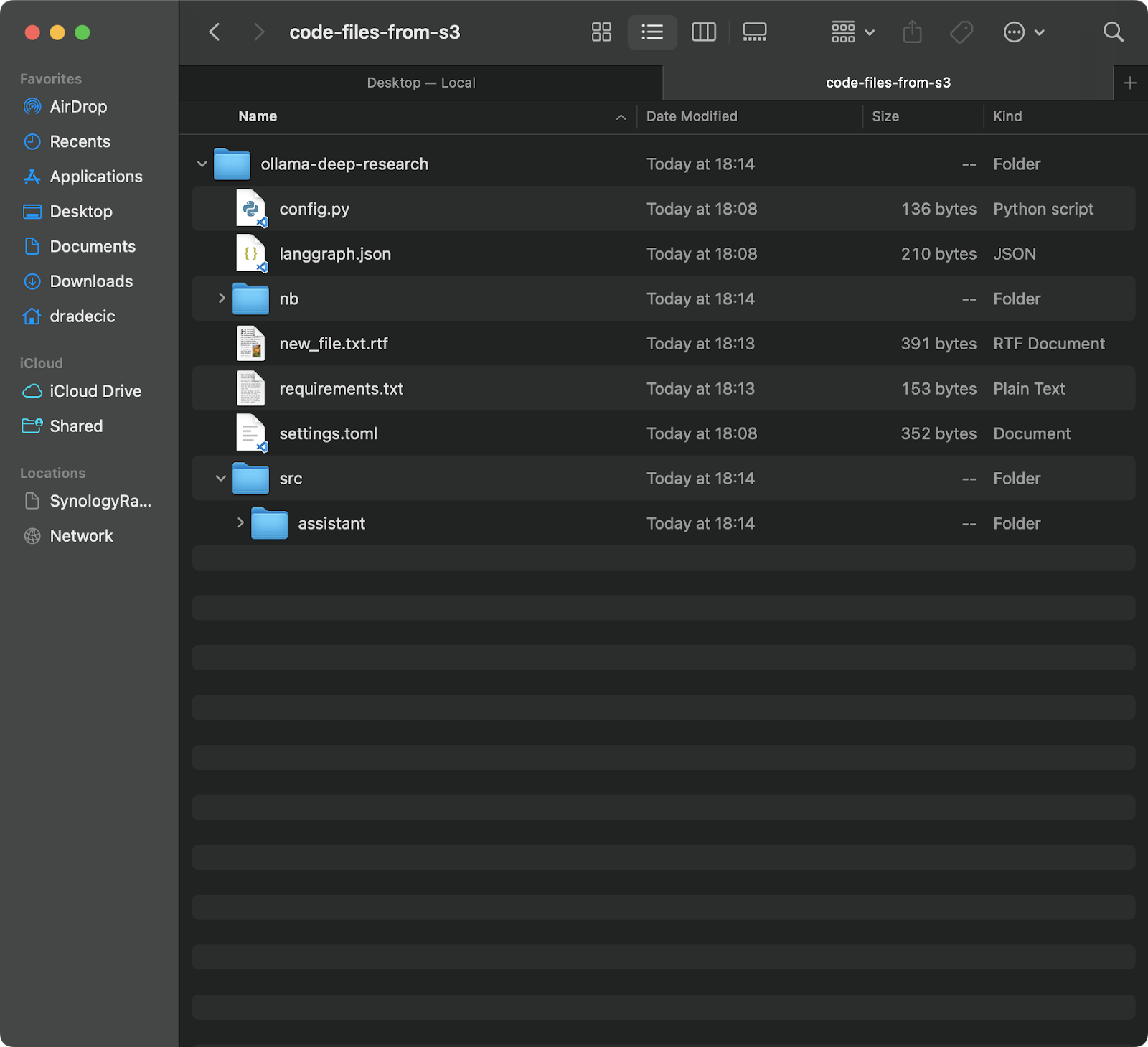
Imagem 12 – S3 para sincronização local
Vale ressaltar que a sincronização do S3 não é bidirecional. Sempre ocorre do origem para o destino, fazendo com que o destino corresponda à origem. Se você excluir um arquivo localmente e depois sincronizá-lo com o S3, ele ainda existirá no S3. Da mesma forma, se você excluir um arquivo no S3 e sincronizar do S3 para o local, o arquivo local permanecerá intocado.
Se você deseja fazer com que o destino corresponda exatamente à origem (incluindo exclusões), será necessário usar a flag --delete, que abordarei na seção de opções avançadas.
Opções Avançadas de Sincronização do AWS S3
O comando básico de sincronização do S3 explorado anteriormente é poderoso por si só, mas a AWS o equipou com opções adicionais que oferecem mais controle sobre o processo de sincronização.
Nesta seção, vou mostrar algumas das bandeiras mais úteis que você pode adicionar ao comando básico.
Sincronizando apenas arquivos novos ou modificados
Por padrão, o S3 sync usa um mecanismo de comparação básico que verifica o tamanho do arquivo e a hora da modificação para determinar se um arquivo precisa ser sincronizado. No entanto, essa abordagem pode não capturar todas as mudanças, especialmente ao lidar com arquivos que foram modificados, mas permanecem do mesmo tamanho.
Para uma sincronização mais precisa, você pode usar a bandeira --exact-timestamps:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup --exact-timestamps
Isso força a sincronização do S3 a comparar timestamps com precisão até milissegundos. Tenha em mente que o uso dessa flag pode diminuir a velocidade do processo de sincronização ligeiramente, já que requer comparações mais detalhadas.
Excluindo ou incluindo arquivos específicos
Às vezes, você não deseja sincronizar todos os arquivos em um diretório. Talvez queira excluir arquivos temporários, logs ou certos tipos de arquivos (como .DS_Store no meu caso). É aí que entram em cena as flags --exclude e --include.
Mas para ilustrar um ponto, digamos que eu queira sincronizar meu diretório de código, mas excluir todos os arquivos Python:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup --exclude "*.py"
Agora, muito menos arquivos estão sincronizados com o S3:
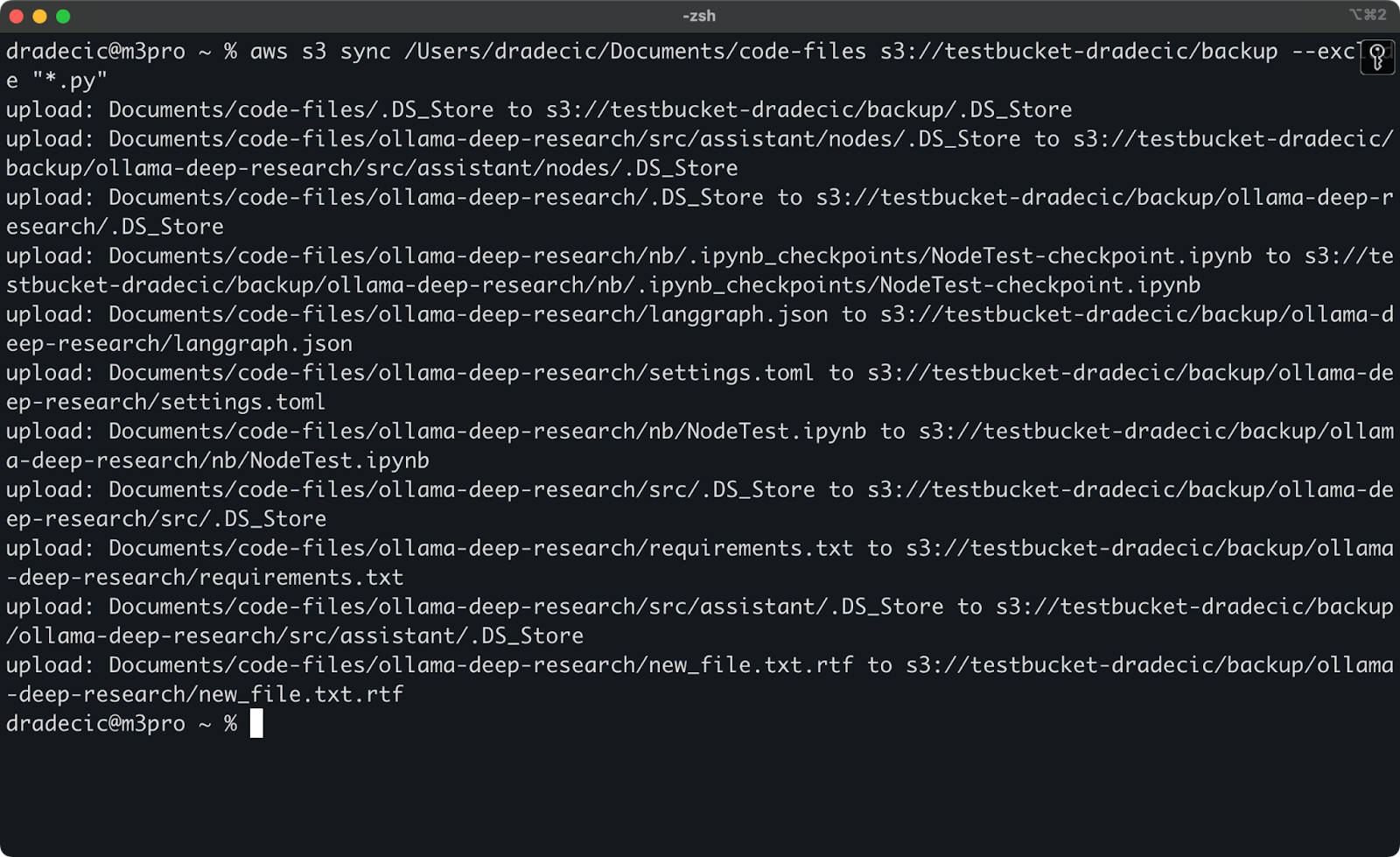
Imagem 13 – Sincronização do S3 com arquivos Python excluídos
Você também pode combinar --exclude e --include para criar padrões mais complexos. Por exemplo, excluir tudo exceto arquivos Python:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup --exclude "*" --include "*.py"
Os padrões são avaliados na ordem especificada, então a ordem importa! Aqui está o que você verá ao usar essas flags:
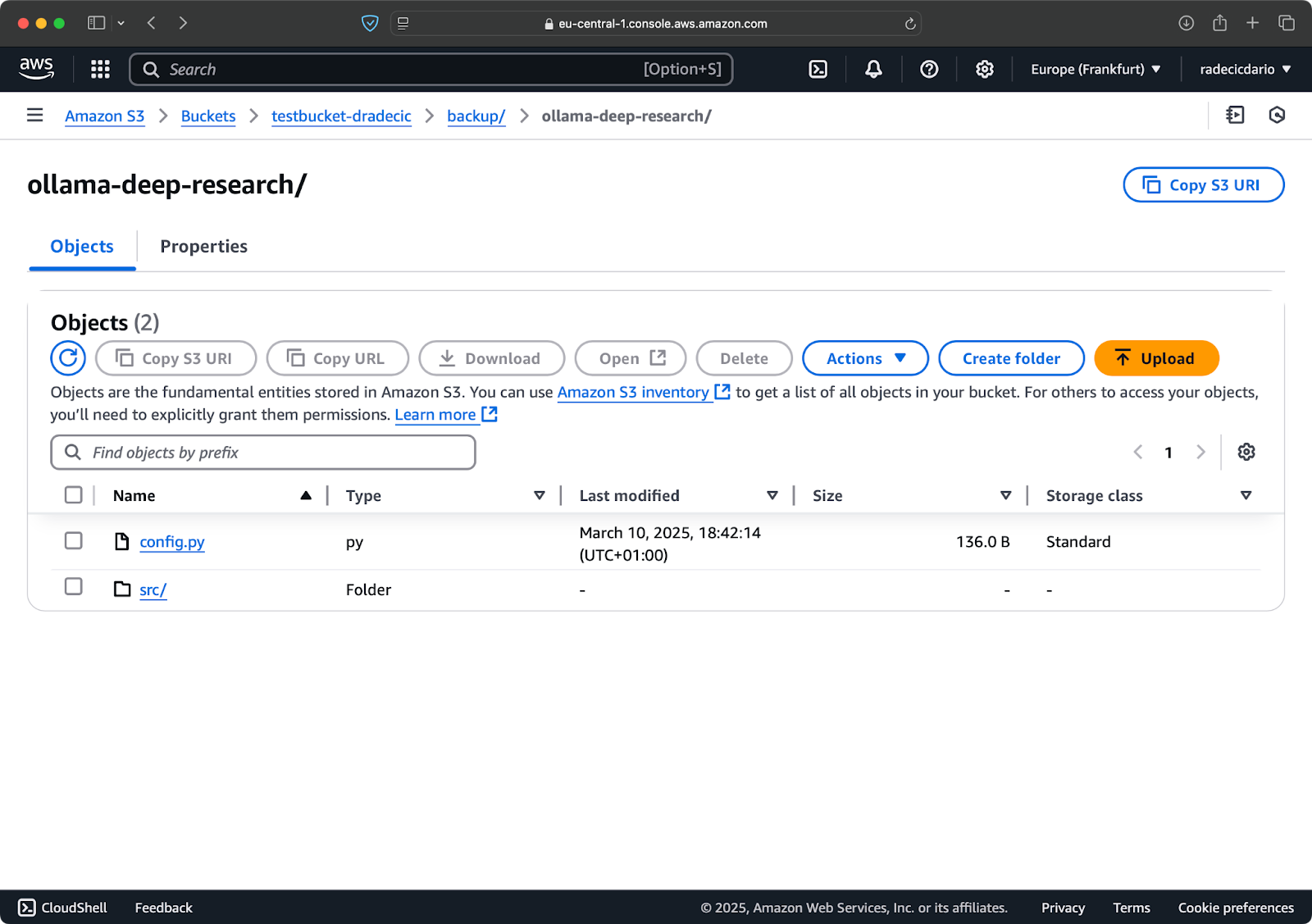
Imagem 14 – Flags de exclusão e inclusão
Agora apenas os arquivos Python estão sincronizados, e arquivos de configuração importantes estão faltando.
Excluindo arquivos do destino
Por padrão, o S3 sync apenas adiciona ou atualiza arquivos no destino, nunca os exclui. Isso significa que se você excluir um arquivo da origem, ele ainda permanecerá no destino após a sincronização.
Para fazer com que o destino seja exatamente espelhado pela origem, incluindo exclusões, use a flag --delete:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup --delete
Se você executar isso pela primeira vez, todos os arquivos locais serão sincronizados com o S3:
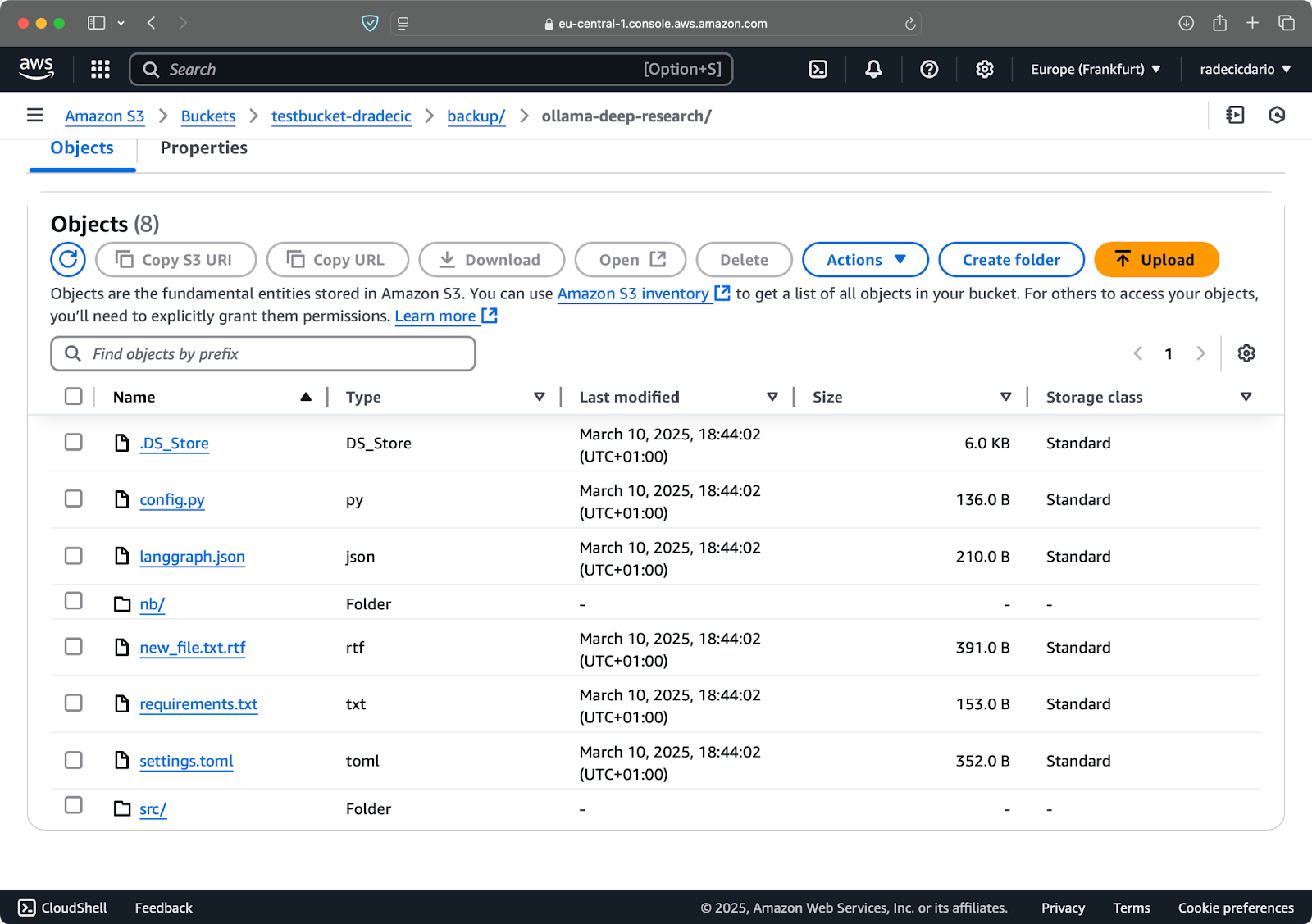
Imagem 15 – Flag de exclusão
Isso é particularmente útil para manter replicas exatas de diretórios. Mas tenha cuidado – essa flag pode levar à perda de dados se usada incorretamente.
Vamos supor que eu delete config.py da minha pasta local e execute o comando de sincronização com a flag --delete:
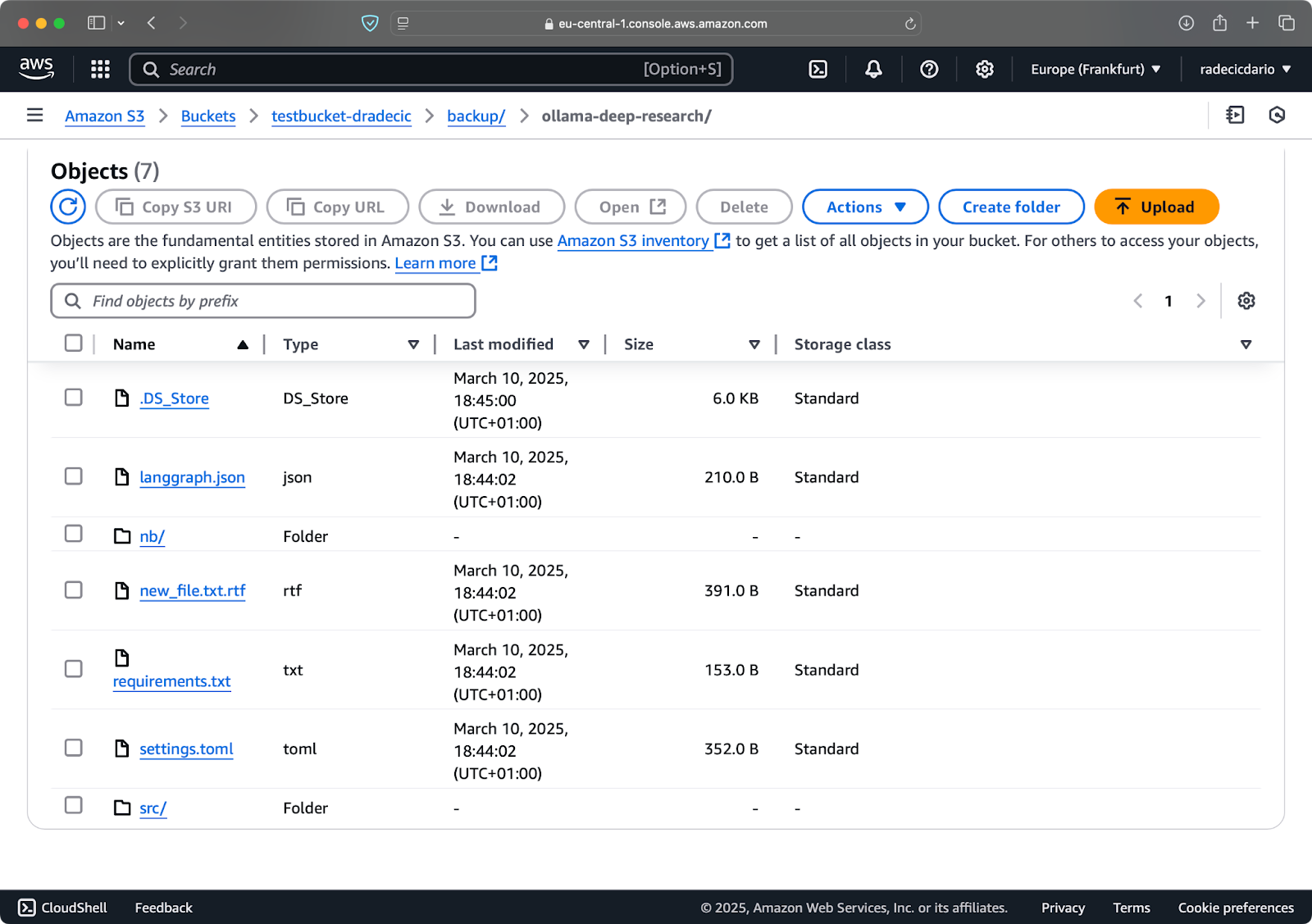
Imagem 16 – Flag de exclusão (2)
Como você pode ver, o comando não apenas sincroniza arquivos novos e modificados, mas também exclui arquivos do bucket S3 que não existem mais no diretório local.
Configurando execução simulada para sincronização segura
As operações de sincronização S3 mais perigosas são aquelas que envolvem a flag --delete. Para evitar excluir acidentalmente arquivos importantes, você pode usar a flag --dryrun para simular a operação sem efetuar realmente nenhuma alteração:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup --delete --dryrun
Para demonstrar, eu deletei os arquivos requirements.txt e settings.toml de uma pasta local e então executei o comando:
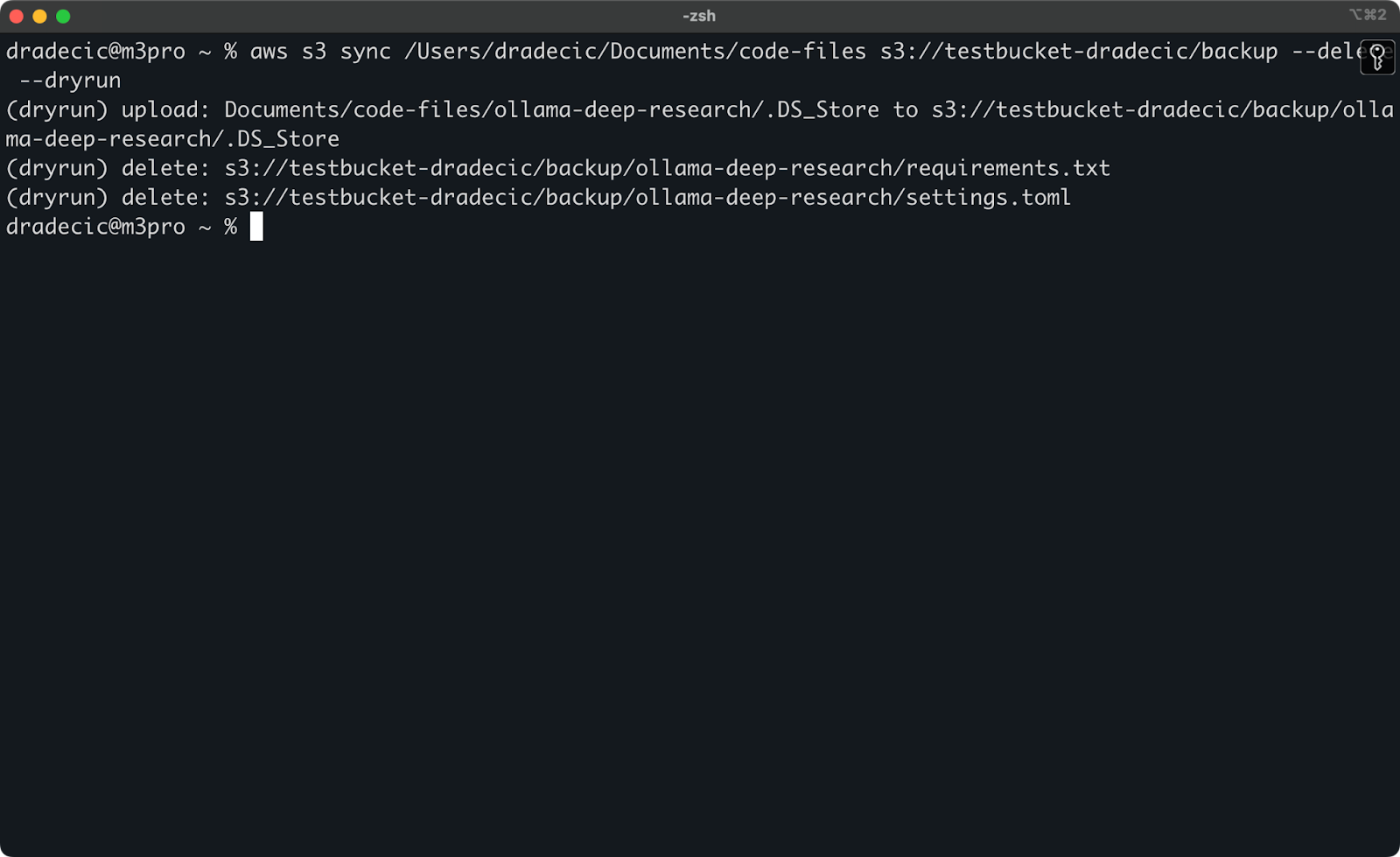
Imagem 17 – Simulação
Isso mostrará exatamente o que aconteceria se você executasse o comando de verdade, incluindo quais arquivos seriam enviados, baixados ou excluídos.
Sempre recomendo usar a flag --dryrun antes de executar qualquer comando de sincronização S3 com a flag --delete, especialmente ao trabalhar com dados importantes.
Existem muitas outras opções disponíveis para o comando de sincronização S3, como --acl para configurar permissões, --storage-class para escolher a camada de armazenamento S3 e --recursive para percorrer subdiretórios. Confira a documentação oficial da AWS CLI para obter uma lista completa de opções.
Agora que você está familiarizado com as opções básicas e avançadas de sincronização do S3, vamos ver como usar esses comandos para cenários práticos como backups e restaurações.
Usando AWS S3 Sync para Backup e Restauração
Um dos casos de uso mais populares para o sincronização do AWS S3 é fazer backup de arquivos importantes e restaurá-los quando necessário. Vamos explorar como você pode implementar uma estratégia simples de backup e restauração usando o comando de sincronização.
Criando backups no S3
Criar backups com o S3 sync é simples – você só precisa executar o comando sync do seu diretório local para um bucket S3. No entanto, existem algumas melhores práticas a seguir para backups eficazes.
Em primeiro lugar, é uma boa ideia organizar seus backups por data ou versão. Aqui está uma abordagem simples usando um carimbo de data/hora no caminho do S3:
# Criar uma variável de carimbo de data/hora TIMESTAMP=$(date +%Y-%m-%d-%H-%M-%S) # Executar o backup aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backups/$TIMESTAMP
Isso cria uma nova pasta para cada backup com um carimbo de data/hora como 2025-03-10-18-56-42. Aqui está o que você verá no S3:
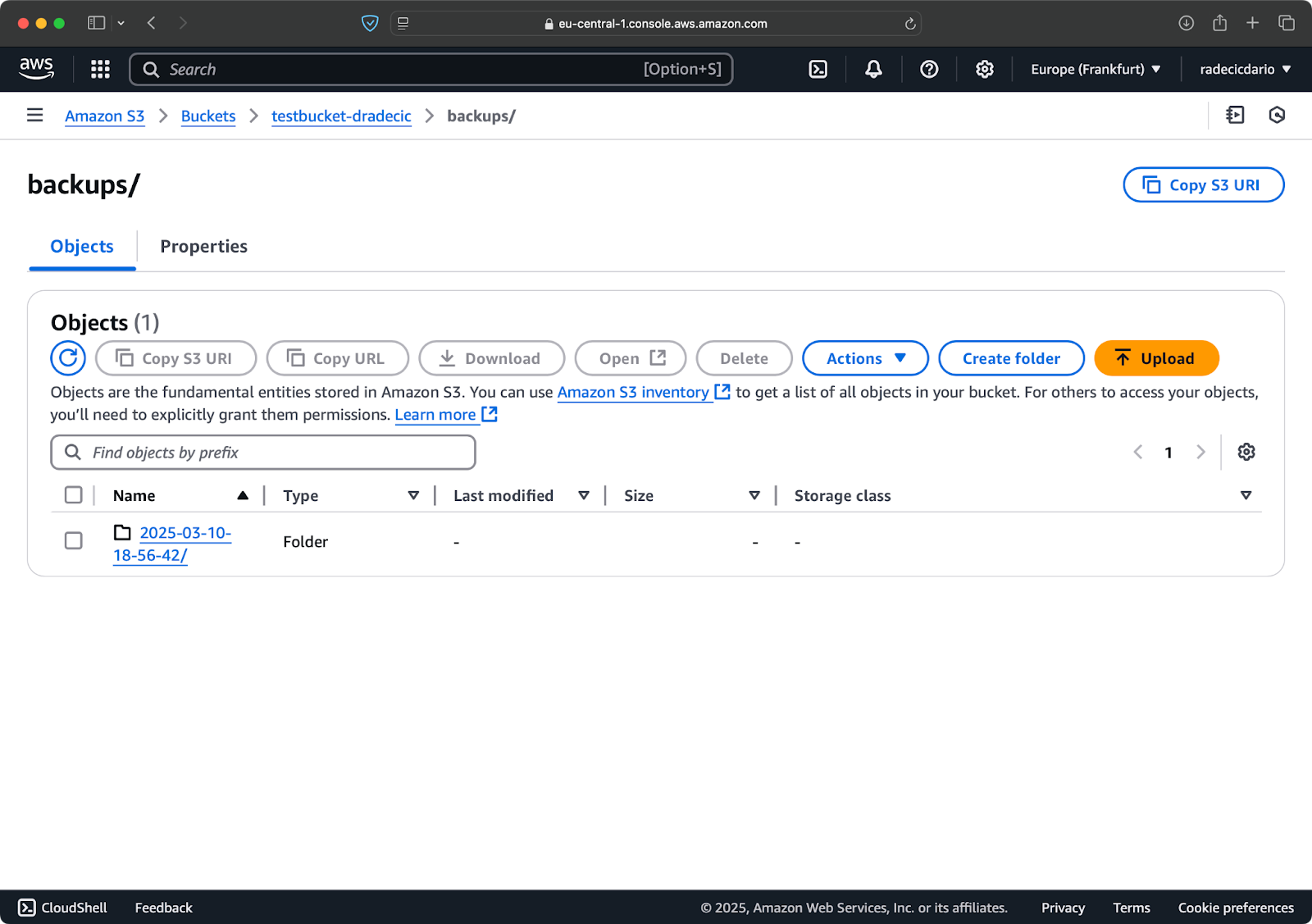
Imagem 18 – Backups com marcação de data e hora
Para dados críticos, você pode querer manter várias versões de backup. Isso é fácil de fazer apenas executando o backup baseado em marcação de tempo regularmente.
Você também pode usar a opção --storage-class para especificar uma classe de armazenamento mais eficiente em termos de custo para seus backups:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backups/$TIMESTAMP --storage-class STANDARD_IA
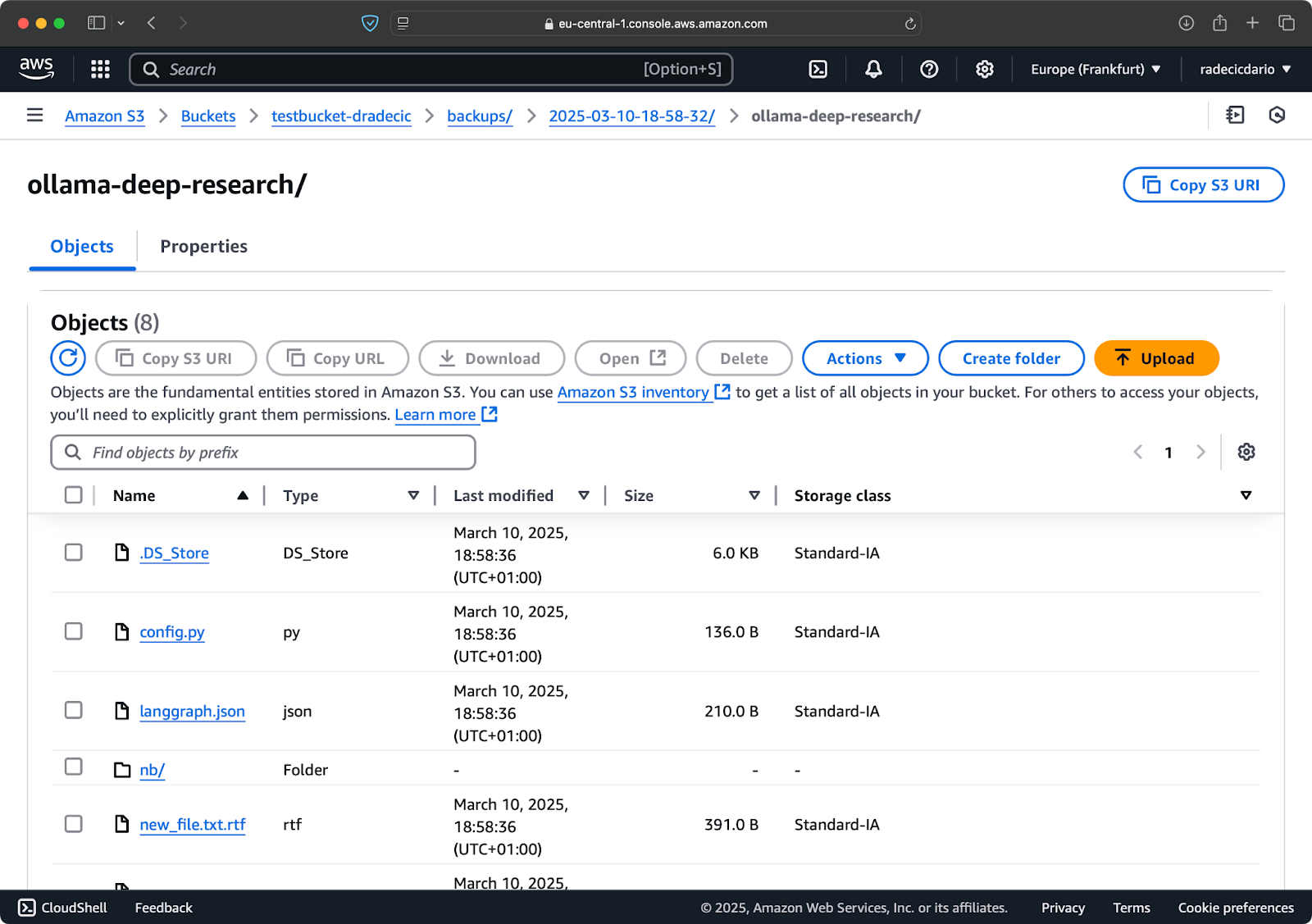
Imagem 19 – Conteúdos de backup com uma classe de armazenamento personalizada
Isso usa a classe de armazenamento S3 de Acesso Infrequente, que custa menos, mas tem uma pequena taxa de recuperação. Para arquivamento a longo prazo, você pode até usar a classe de armazenamento Glacier:
aws s3 sync /Users/dradecic/Documents/important-data s3://testbucket-dradecic/backups/$TIMESTAMP --storage-class GLACIER
Apenas lembre-se de que os arquivos armazenados no Glacier levam horas para serem recuperados, então não são adequados para dados que você pode precisar rapidamente.
Restaurando arquivos do S3
Restaurar de um backup é tão fácil – simplesmente inverter a origem e o destino no seu comando de sincronização:
# Restaurar do backup mais recente (supondo que você saiba o timestamp) aws s3 sync s3://testbucket-dradecic/backups/2025-03-10-18-56-42 /Users/dradecic/Documents/restored-data
Isso fará o download de todos os arquivos do backup específico para o diretório local restored-data:
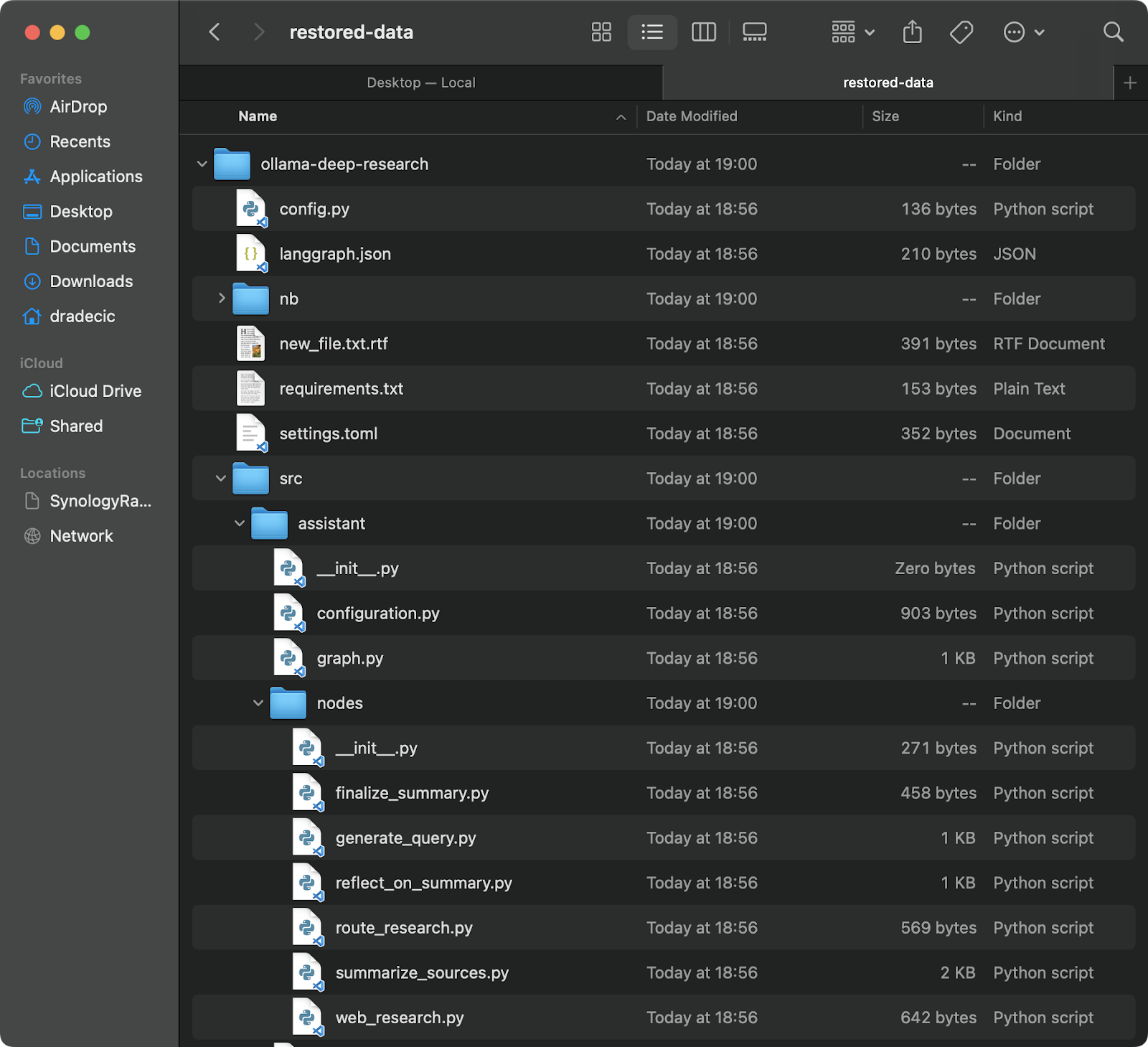
Imagem 20 – Restaurando arquivos do S3
Se você não se lembra do timestamp exato, você pode listar todos os seus backups primeiro:
aws s3 ls s3://testbucket-dradecic/backups/
O que mostrará algo como:
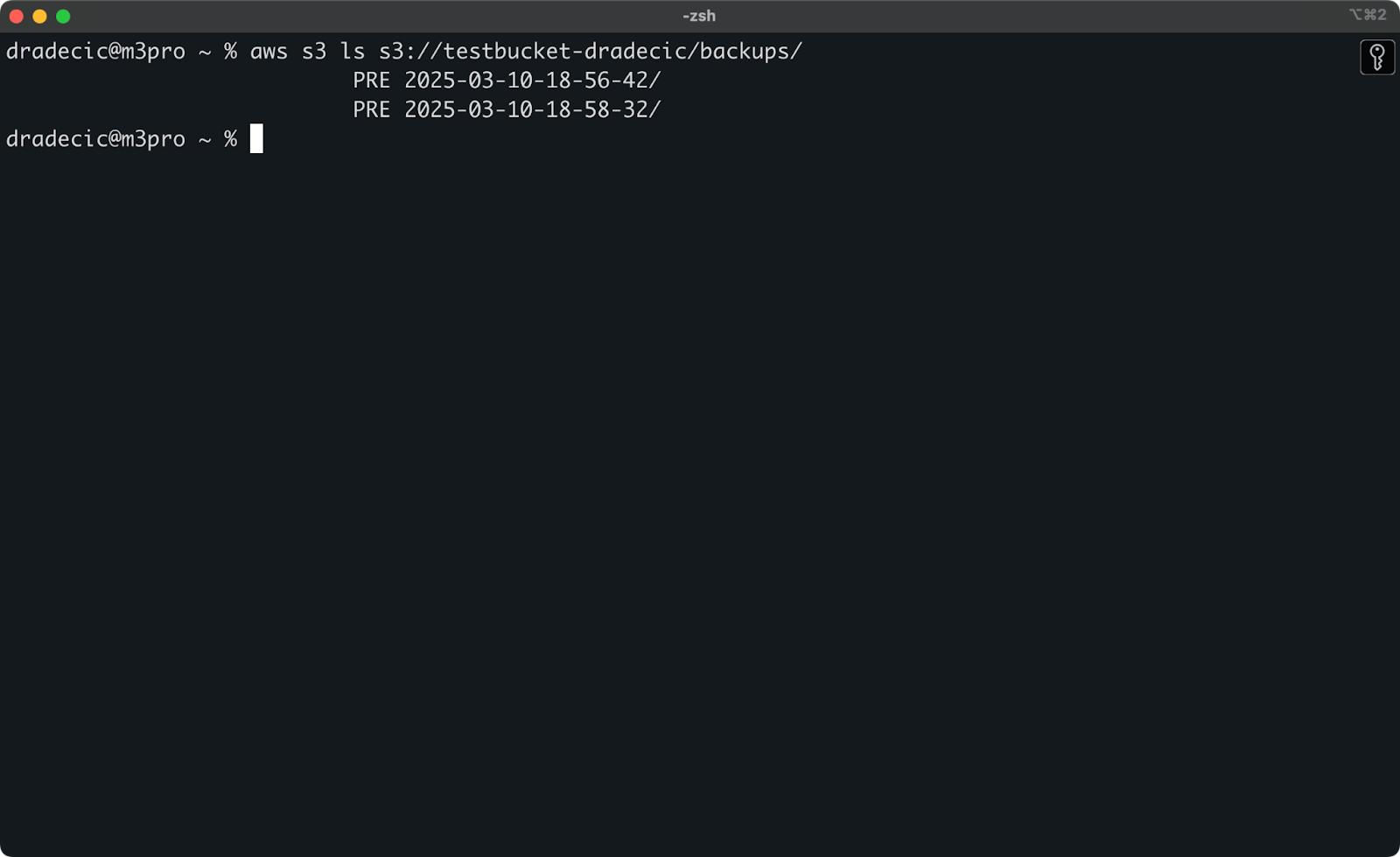
Imagem 21 – Lista de backups
Você também pode restaurar arquivos ou diretórios específicos de um backup usando as flags de exclusão/inclusão que discutimos anteriormente:
# Restaurar apenas os arquivos de configuração aws s3 sync s3://testbucket-dradecic/backups/2025-03-10-18-56-42 /Users/dradecic/Documents/restored-configs --exclude "*" --include "*.config" --include "*.toml" --include "*.yaml"
Para sistemas críticos, recomendo automatizar seus backups com tarefas agendadas (como cron jobs no Linux/macOS ou Task Scheduler no Windows). Isso garante que você esteja fazendo backup dos seus dados de forma consistente sem precisar se lembrar de fazer manualmente.
Resolução de problemas do AWS S3 Sync
O AWS S3 sync é uma ferramenta confiável, mas você pode ocasionalmente encontrar problemas. Ainda assim, a maioria dos erros que você verá são baseados em falhas humanas.
Erros de sincronização comuns
Vamos analisar alguns problemas comuns e suas soluções.
- Erro de acesso negado geralmente significa que seu usuário IAM não possui as permissões necessárias para acessar o bucket S3 ou realizar operações específicas. Para corrigir isso, tente uma das seguintes soluções:
- Verifique se seu usuário IAM possui as permissões S3 apropriadas (
s3:ListBucket,s3:GetObject,s3:PutObject). - Verifique se a política do bucket não nega explicitamente o acesso do seu usuário.
- Garanta que o próprio bucket não esteja bloqueando o acesso público se você precisar de operações públicas.
- Arquivo ou diretório não encontrado erro geralmente aparece quando o caminho de origem especificado no comando de sincronização não existe. A solução é simples – verifique novamente seus caminhos e certifique-se de que eles existam. Preste atenção especial a erros de digitação nos nomes dos buckets ou diretórios locais.
- Limite de tamanho de arquivo erros podem ocorrer quando você deseja sincronizar arquivos grandes. Por padrão, a sincronização S3 pode lidar com arquivos de até 5GB de tamanho. Para arquivos maiores, você verá timeouts ou transferências incompletas.
- Para arquivos maiores que 5GB, você deve usar a flag
--only-show-errorscombinada com a flag--size-only. Essa combinação ajuda nas transferências de arquivos grandes, minimizando a saída e comparando apenas os tamanhos dos arquivos:
aws s3 sync /Users/dradecic/large-files s3://testbucket-dradecic/large-files --only-show-errors --size-only
Otimização de desempenho de sincronização
Se a sua sincronização S3 estiver rodando mais devagar do que o esperado, existem alguns ajustes que você pode fazer para acelerar as coisas.
- Use transferências paralelas. Por padrão, a sincronização do S3 utiliza um número limitado de operações paralelas. Você pode aumentar isso com o parâmetro
--max-concurrent-requests:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup --max-concurrent-requests 20
- Ajuste o tamanho do chunk. Para arquivos grandes, você pode otimizar a velocidade de transferência ajustando o tamanho do chunk. Isso divide arquivos grandes em pedaços de 16MB em vez dos 8MB padrão, o que pode ser mais rápido para boas conexões de rede:
aws s3 sync /Users/dradecic/large-files s3://testbucket-dradecic/backup --cli-read-timeout 120 --multipart-threshold 64MB --multipart-chunksize 16MB
- Use
--no-progresspara scripts. Se você estiver executando a sincronização do S3 em um script automatizado, use a flag--no-progresspara reduzir a saída e melhorar o desempenho:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup --no-progress
- Use endpoints locais. Se os seus recursos da AWS estiverem na mesma região, especificar o endpoint regional pode reduzir a latência:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup --endpoint-url https://s3.eu-central-1.amazonaws.com
Essas otimizações podem melhorar significativamente o desempenho da sincronização, especialmente para transferências de dados grandes ou ao executar em máquinas menos potentes.
Se ainda estiver enfrentando problemas após tentar essas soluções, o AWS CLI possui uma opção de depuração integrada. Basta adicionar --debug ao seu comando para ver informações detalhadas sobre o que está acontecendo durante o processo de sincronização:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup --debug
Espere ver muitas mensagens de log detalhadas, semelhantes a estas:
Imagem 22 – Executando sincronização em modo de depuração
E isso é praticamente tudo quando se trata de solucionar problemas de sincronização do AWS S3. Claro, outros erros podem ocorrer, mas 99% das vezes, você encontrará a solução nesta seção.
Resumindo a Sincronização do AWS S3
Para resumir, a sincronização do AWS S3 é uma daquelas ferramentas raras que são tanto simples de usar quanto incrivelmente poderosas. Você aprendeu desde comandos básicos até opções avançadas, estratégias de backup e dicas de solução de problemas.
Para desenvolvedores, administradores de sistemas ou qualquer pessoa que trabalhe com a AWS, o comando de sincronização do S3 é uma ferramenta essencial – ela economiza tempo, reduz o uso de largura de banda e garante que seus arquivos estejam onde você precisa, quando precisa.
Seja para fazer backup de dados críticos, implantar ativos da web ou simplesmente manter diferentes ambientes em sincronia, o AWS S3 sync torna o processo simples e confiável.
A melhor maneira de se acostumar com a sincronização do S3 é começar a usá-la. Experimente configurar uma operação de sincronização simples com seus próprios arquivos e, aos poucos, explore as opções avançadas para atender às suas necessidades específicas.
Lembre-se de sempre usar --dryrun primeiro ao trabalhar com dados importantes, especialmente ao usar a opção --delete. É melhor gastar um minuto extra verificando o que vai acontecer do que excluir acidentalmente arquivos importantes.
Para aprender mais sobre a AWS, confira estes cursos da DataCamp:
- Introdução à AWS
- Tecnologia e Serviços de Nuvem da AWS
- Segurança e Gerenciamento de Custos da AWS
- Introdução ao AWS Boto em Python
Você também pode usar o DataCamp para se preparar para os exames de certificação da AWS – Praticante de Nuvem da AWS (CLF-C02).