













В последние годы Apache Flink закрепил за собой статус de facto стандарта для реального времени потоковой обработки. Потоковая обработка – это парадигма для строения систем, которая считает потоки событий (последовательности событий в времени) своим главным элементом. Потоковый процессор, такой как Flink, потребляет входные потоки, произведенные источниками событий, и производит выходные потоки, которые потребляются сбросами (сбросы сохраняют результаты и делают их доступными для дальнейшего процесса).
Известные компании, такие как Amazon, Netflix и Uber, полагаются на Flink для работы с данными на огромных эchelons в центре своих бизнесов, но Flink также играет ключевую роль в многих мелких компаниях с аналогичными требованиями, чтобы быть способным быстро реагировать на критические бизнес-события.
Что Flink используется для? Общепринятые примеры использования делятся на три категории:
|
Потоковые data pipelines |
Реально-временные аналитики |
Веб-приложения, работающие по принципу событий |
|---|---|---|
|
Кontinuously ingest, enrich, and transform data streams, loading them into destination systems for timely action (vs. batch processing). |
Кontinuously produce and update results which are displayed and delivered to users as real-time data streams are consumed. |
Регистрировать модели и реагировать на исходящие события, вызывая вычисления, обновления состояния или внешние действия. |
|
Которые включают в себя:
|
Некоторые примеры включают:
|
Некоторые примеры включают:
|
Flink включает:
- robust support для стримминга данных на масштабах, необходимых мировым предприятиям
- сильные гарантии точности и восстановления
- поддержка Java, Python и SQL, с объединенной поддержкой дляbatch и стримминга
- Flink – это зрелый open-source проект от Apache Software Foundation и имеет очень активную и поддерживаемую сообщество.
Flink иногда описывается как сложный и труднопонятый. Да, реализация runtime Flink сложна, но это не должно быть удивительно, так как она решает некоторые сложные проблемы. API Flink могут быть несколько сложными для изучения, но это связано больше с незнакомыми концепциями и организационными принципами, чем с каким-либо врожденным сложностью.
Flink может отличаться от всего, что вы использовали ранее, но во многих отношениях он actually rather simple. Когда вы станете более знатоками в том, каким образом Flink собраны, и вопросах, которые он должен решать во время выполнения, детали API Flink должны начать выглядеть для вас как очевидные следствия нескольких ключевых принципов, а не как набор загадочных деталей, которые вы должны запомнить.
Эта статья направлена на то, чтобы сделать полет Flink легче, указывая на ключевые принципы, лежащие в основе его дизайна.
Flink воплощает несколько больших идей
Потоки
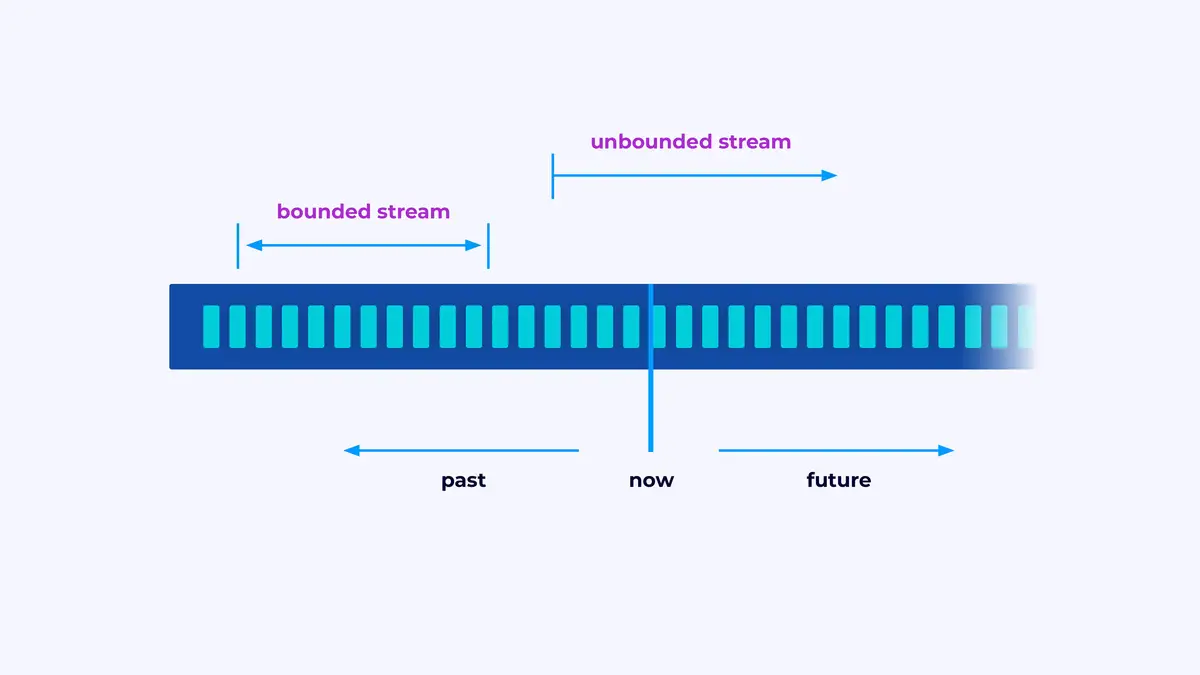
Flink – это фреймворк для создания приложений, которые обрабатывают потоки событий, где поток – это ограниченный или неограниченный последовательность событий.
Приложение Flink – это питон для обработки данных. ваши события текут через этот питон и операции на них выполняются на каждом этапе кодом, который вы напишете. Мы называем этот питон графом задачи и узлами этого графа (то есть, стадиями обработки питона) называются операторы.
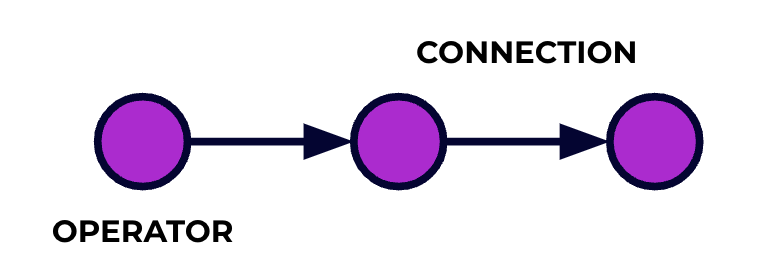
Код, который вы пишете с использованием одного из API Flink, описывает граф задачи, включая поведение операторов и их соединения.
Параллельная обработка
Каждый оператор может иметь много параллельных экземпляров, каждый из которых работает независимо над какой-то подмножеством событий.
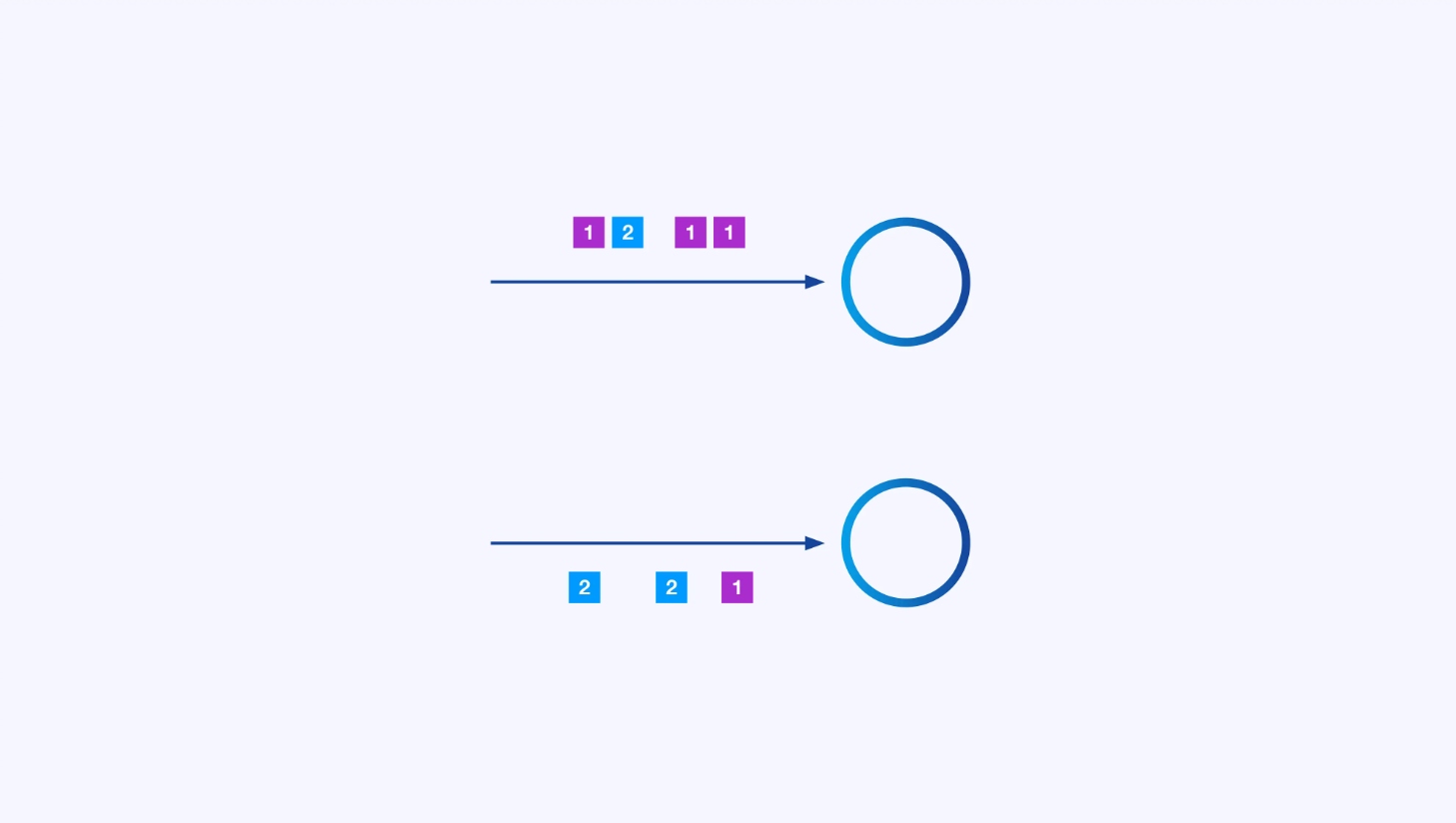
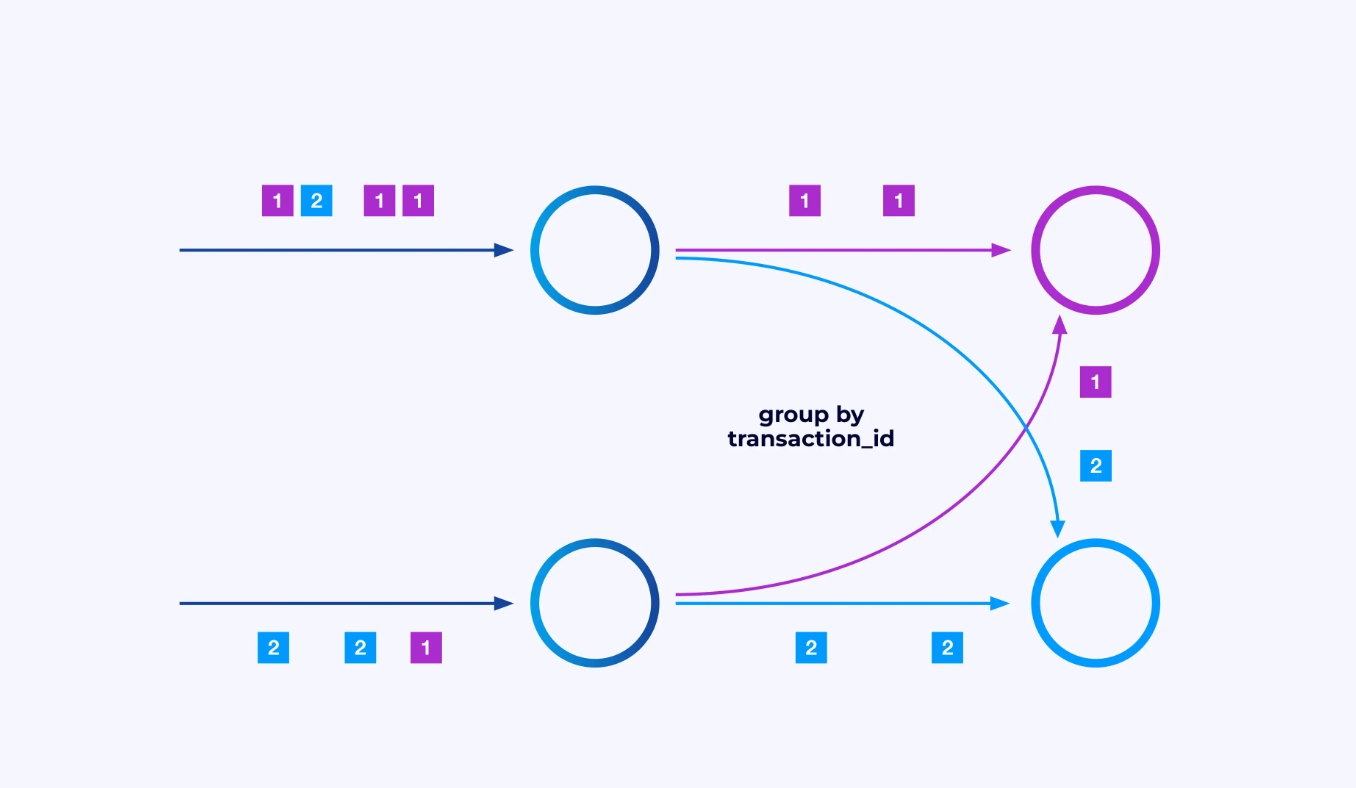
Как бы то ни было, иногда вам нужно будет наложить специфическую схему разбиения на эти субпотоки, чтобы события были группированы по какому-то специфическому для приложения логике. Например, если вы обрабатываете финансовые транзакции, вам может потребоваться организовать так, чтобы каждое событие для любой данной транзакции обрабатывалось тем же потоком. Это позволит вам соединить различные события, происходящие в течение времени для каждой транзакции
В Flink SQL вы можете сделать это с помощью GROUP BY transaction_id, а в API DataStream используете keyBy(event -> event.transaction_id), чтобы указать эту группировку или разбиение. В любом случае это появится в графе задания как полностью связанная сетевая перестановка между двумя连续ными стадиями графа.
Состояние
Операторы, работающие с ключево-разбитыми потоками, могут использовать распределенный ключ/значение для хранения состояний Flink, чтобы устойчиво сохранять все, что им нужно. Состояние для каждого ключа локально для конкретного экземпляра оператора и не может быть доступно с других мест. Параллельные суб-топологии не делят ничего — это crucial для неограниченной масштабности.
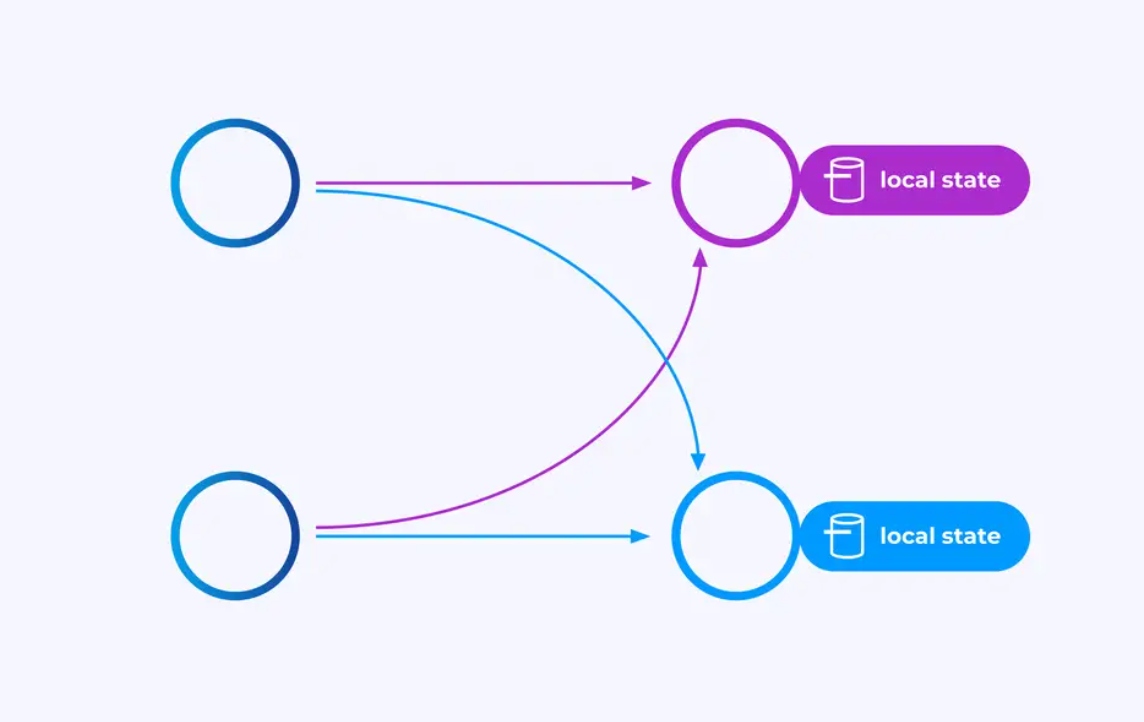
Задача Flink может работать бесконечно долго. Если задача Flink непрерывно создает новые ключи (например, идентификаторы транзакций) и хранит какое-то значение для каждого нового ключа, то эта задача рискует выросшим, поскольку использует неограниченное количество состояния. Каждая из API Flink организована вокруг того, чтобы предоставлять способы, чтобы помочь вам избежать неконтролируемого роста состояния.
Время
Одним из способов избежать длительного хранения состояния является сохранять его только до какого-то определенного момента времени. Например, если вы хотите считать транзакции в течение минутных интервалов, как только минута закончилась, результат для этой минуты может быть вычислен, и этот счетчик может быть освобожден.
Flink делает важное различие между двумя различными понятиями времени:
- Процессуальное (или стеночное) время, которое получено из реального времени дня, когда событие обрабатывается
- Время события, которое основано на метках времени, записанных с каждым событием
Чтобы иллюстрировать различие между ними, рассмотрим, что значит, чтобы минутное окно закончилось:
- Окно стеночного времени закончено, когда минута заканчивается. Это очень просто.
- Окно времени события закончено, когда все события, произошедшие в течение этой минуты, были обработаны. Это может быть нелегко, так как Flink не может знать о событиях, которые еще не были обработаны. Самое лучшее, что мы можем сделать, – это сделать предположение о том, насколько поток может быть опоздан и применить это предположение heuristically.
Реcupеration from Failures
Ошибки неизбежны. Несмотря на ошибки, Flink способен обеспечить эффективно точно-раз зарядки,意味着 each event will affect the state Flink is managing exactly once, just as though the failure never occurred. It does this by taking periodic, global, self-consistent snapshots of all the states. These snapshots, created and managed automatically by Flink, are called checkpoints.
Восстановление включает возврат к состоянию, зафиксированному в последнем контрольном точке, и производство всеми операторами глобального перезапуска с этого контрольного точки. Во время восстановления часть событий перерабатывается, но Flink может гарантировать правильность, обеспечивая тем самым, что каждая контрольная точка является глобальным самоподдерживающимся снимком всего состояния системы.
Системная архитектура
Программы Flink выполняются в кластерах Flink, поэтому перед тем, как вы можете вывести Flink-приложение в производство, вам потребуется развернуть кластер для его развертывания. К счастью, во время разработки и тестирования можно легко начать работу, выполняя Flink локально в интегрированной среде разработки (IDE), такой как IntelliJ или Docker.
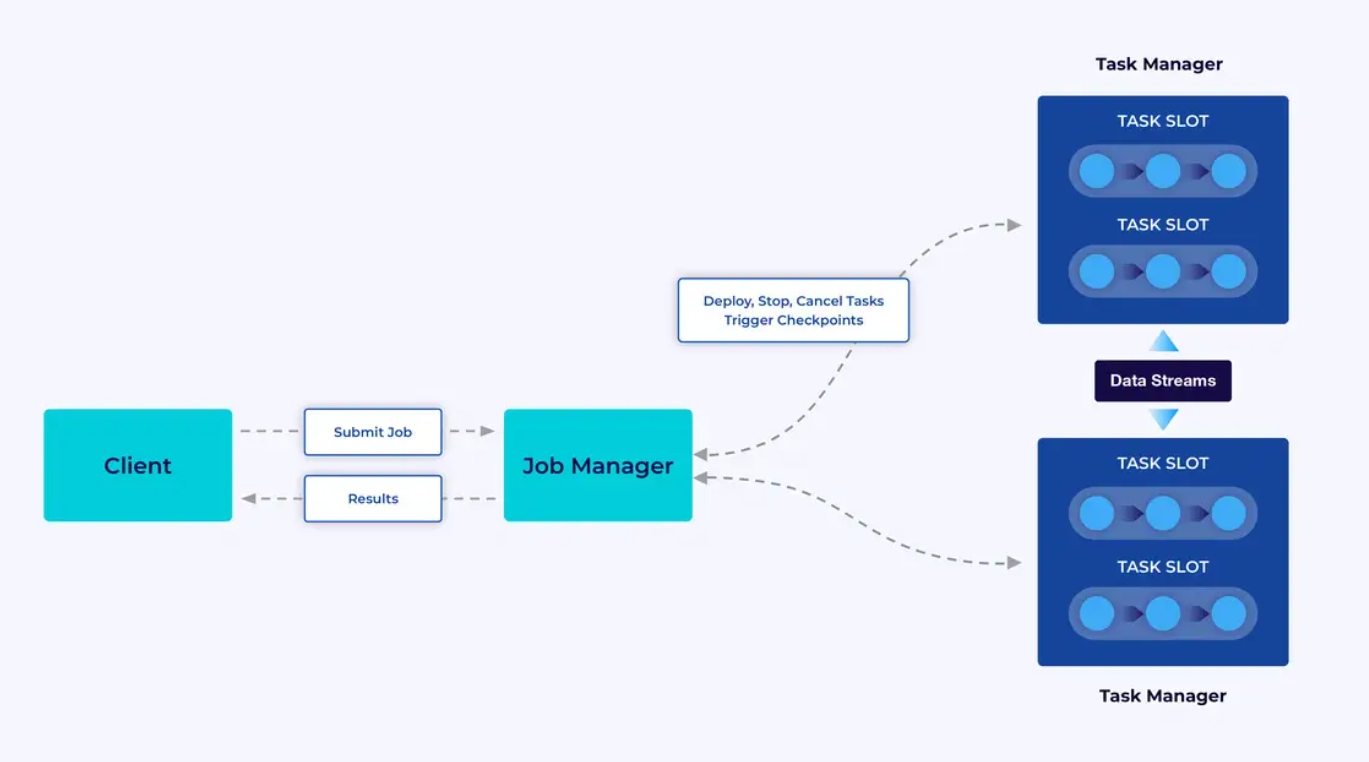
Кластер Flink состоит из двух типов компонентов: управляющего заданиями (Job Manager) и набора задачи менеджеров (Task Managers). Задачи менеджеры запускают ваше приложение (параллельно), в то время как менеджер заданий выступает в качестве шлюза между задачи менеджерами и внешним миром. Приложения подаются менеджеру заданий, который управляет ресурсами, предоставленными задачи менеджерами, координирует контрольные точки и предоставляет мониторинг кластера в виде метрик.
Опыт разработчика
Опыт разработчика Flink в некоторой степени зависит от выбора API: either the older, lower-level DataStream API or the newer, relational Table and SQL APIs.
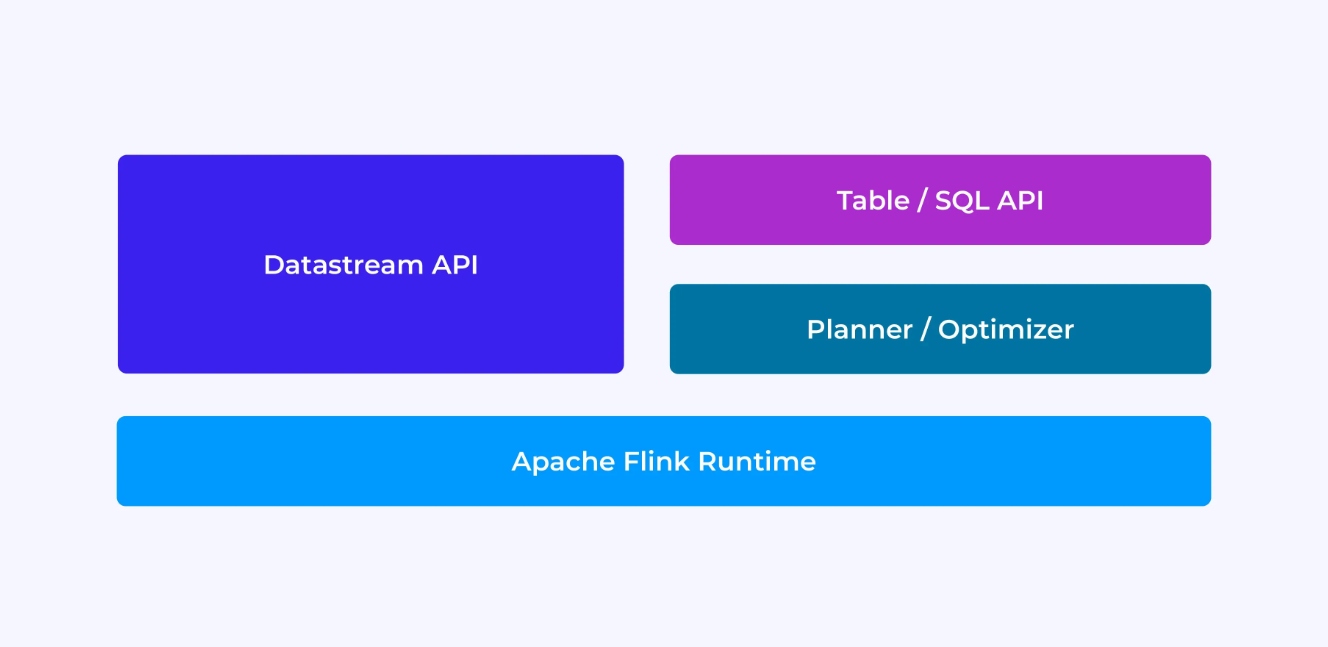
Когда вы программируете с помощью API DataStream Flink, вы сознательно думаете о том, что будет делатьRuntime Flink во время выполнения вашего приложения. Это意味着 вам приходится строить граф задания по одному оператору за раз, описывая состояние, которое вы используете, а также типы,涉及其中和 их сериализацию, создавая таймеры и реализуя callback-функции для выполнения при иницииации этих таймеров и т. д.
В то же время, когда вы используете API Table/SQL Flink, эти низкоуровневые задачи уже для вас обеспечиваются, и вы можете сфокусироваться более прямо на вашем бизнес-логике. Kernel-абстракция в API DataStream – это событие, и функции, которые вы пишете, обрабатывают одно событие за раз при их поступлении.
Еще несколько мыслей до погружения в детали: сначала, вы не обязаны выбирать DataStream или Table/SQL API – оба API взаимодействительны, и вы можете их комбинировать. Это может быть хорошим способом, если вам нужна небольшаяカスタマイズ, которая невозможна с помощью API Table/SQL. Но другим хорошим способом выйти за пределы возможностей, которые предлагает API Table/SQL out-of-the-box, является добавление дополнительных возможностей в виде пользовательских функций (UDFs). Здесь API SQL Flink предлагает множество вариантов для расширения.
Конструирование графа задания
Независимо от которой либо API, конечной целью кода, который вы пишете, является создание графа задач, который будет выполняться runtime Flink в вашем имя. Это意味着 эти API организованы вокруг создания операторов и определения поведения их и их соединений друг с другом. С API DataStream вы явно строите граф задач, а с API Table/SQL за этим делом ухаживает SQL-планировщик Flink.
Сериализация Функций и Данных
В конечном итоге, код, который вы предоставляете Flink, будет выполняться в параллеле работниками (operatornыми менеджерами) в кластере Flink. Чтобы это произошло, объекты функций, которые вы создаете, сериализуются и отправляются наoperatornые менеджеры, где они выполняются. аналогично, события сами по себе иногда также нужны быть сериализованы и отправлены по сети от одногоoperatornного менеджера к другому. Ещё раз, с API Table/SQL вам не придётся думать о этом.
Управление Состоянием
Runtime Flink должен быть проинформирован о состоянии, которое вы ожидаете, чтобы оно восстановило вас в случае сбоя. Чтобы это работало, Flink нужны типы данных, которые можно использовать для их сериализации и десериализации (так чтобы они могли быть записаны в checkpoints и прочитаны из них). Вы можете опционально настроить это управляемое состояние с помощью описателей срока действия, которые Flink будет использовать, чтобы автоматически истечь состояние, когда оно перестанет быть полезным.
С помощью API DataStream вы, в основном, работаете с состоянием, которые ваше приложение необходимо (строгие вычисления для окон являются исключением). С другой стороны, с API Table/SQL эта проблема вырабатывается. Например, учитывая запрос, показанный ниже, вы знаете, что где-то в runtime Flink должна поддерживаться структура данных, которая учитывает счетчик для каждой URL, но все детали уже для вас обслужены.
SELECT url, COUNT(*)
FROM pageviews
GROUP BY URL;Установка и запуск таймеров
Таймеры используются во многих сценариях стрим-предпроцессорирования. Например, это общее, что приложения Flink необходимо собрать информацию из множества различных источников событий, прежде чем выполнять результаты. Таймеры идеально подходят для тех случаев, когда смысл в том, чтобы ждать (но не бесконечно) данные, которые могут (или не могут) когда-то прийти.
Таймеры также необходимы для реализации операций окна с учетом времени. both DataStream и Table/SQL API имеют встроенную поддержку для окон и создают и управляют таймерами в вашем имя.
Примеры использования
Вернувшись к трем широким категориям сценариев использования стримов, представленным в начале этой статьи, посмотрим, как они соответствуют тому, что вы узнали о Flink.
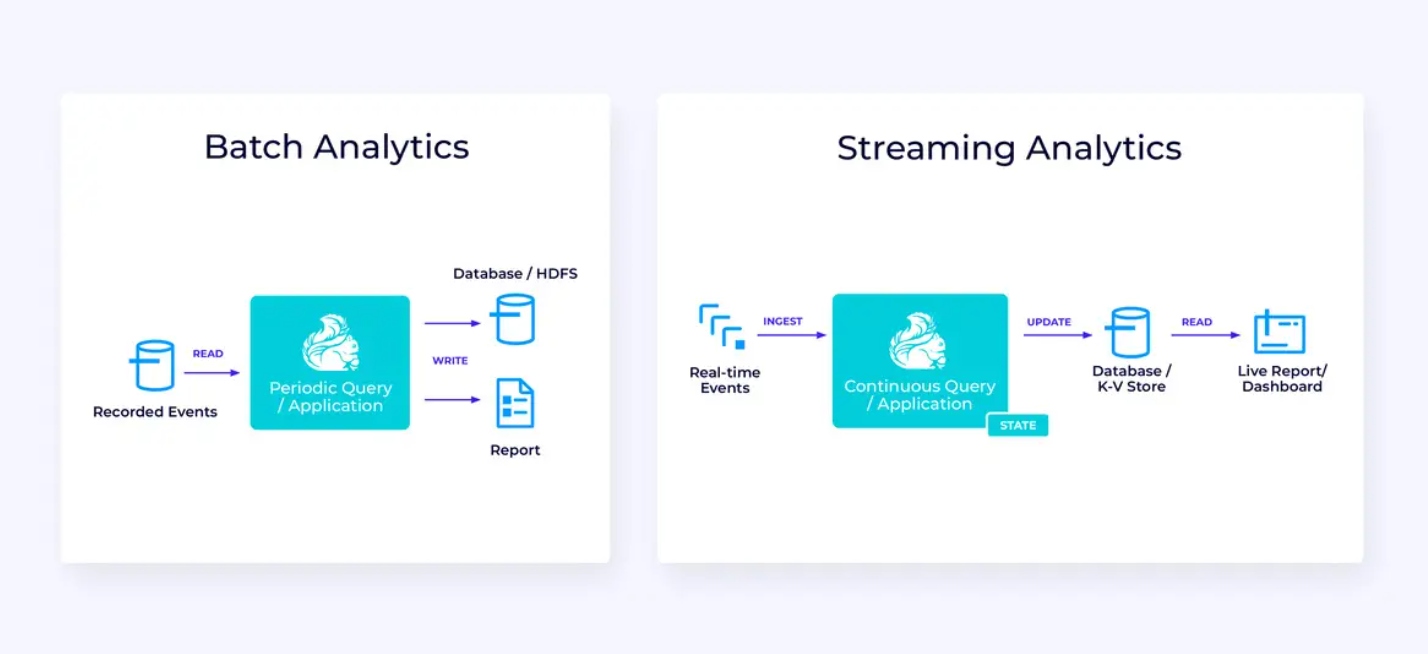
Стриминговая datagram pipeline
Ниже, слева, показано пример традиционного batch ETL-задания, которое периодически читает данные из транзакционной базы данных, преобразует их и записывает результаты в другой данных хранения, таком как база данных, файловая система или data lake.
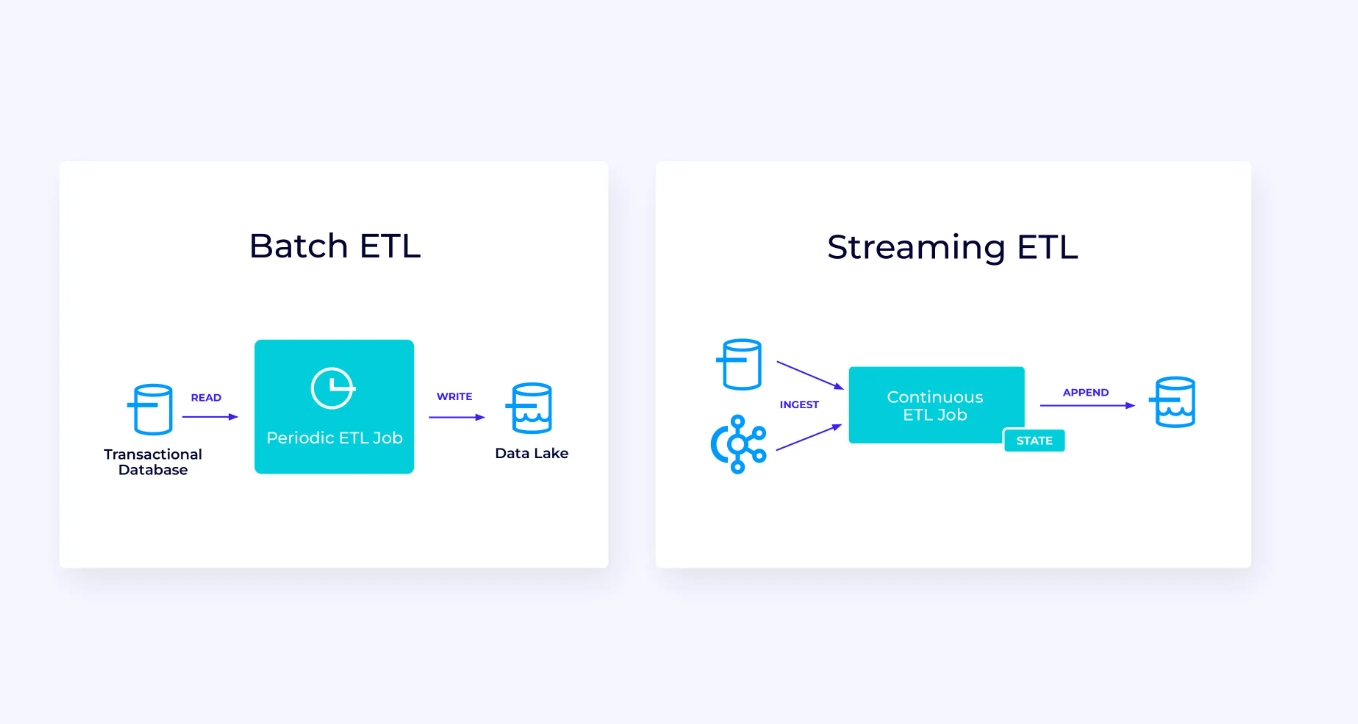
Соответствующая стриминговая pipeline внешне похожа, но есть значительные различия:
- Потоковая порция всегда работает.
- Данные транзакций доставляются в потоковую порцию в двух частях: исходный массив данных из базы данных и поток изменений (CDC), переносящий обновления базы данных, произошедшие после этого исходного загрузки.
- Версия потокового производства непрерывно генерирует новые результаты, как только они становятся доступны.
- Состояние явно управляется, что позволяет его устойчиво восстановить в случае сбоя. Типичные потоковые ETL-pipeline используют очень мало состояния. Источники данных следят за тем, какая часть входных данных была прочитана, обычно в форме смещений, которые идентифицируют записи с начала потока. Http://ru2.wikipedia.org/wiki/%D0%A1%D0%BB%D0%B0%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5 с использованием транзакций для управления своими записями в внешние системы, такие как базы данных или Kafka. Во время checkpointing источники записывают свои смещения, и Http://ru2.wikipedia.org/wiki/%D0%A1%D0%BB%D0%B0%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5 подтверждают транзакции, которые переносят результаты чтения точно до, но не после этих источниковых смещений.
Для этого用例, API Table / SQL будет хорошим выбором.
Оперативный анализ
В сравнении с потоковой ETL-applications, это приложение потокового анализа имеет несколько интересных различий:
- Once again, Flink is being used to run a continuous application, but for this application, Flink will probably need to manage substantially more state.
- Для этого用例 соответствует, что поток, который исследуется, сохраняется в потоковом хранении, таком как Apache Kafka.
- Вместо периодического создания статического отчета потоковая версия может использоваться для управления живым dashbord.
Еще раз, Tablica/SQL API, как правило, является хорошим выбором для этого用例.
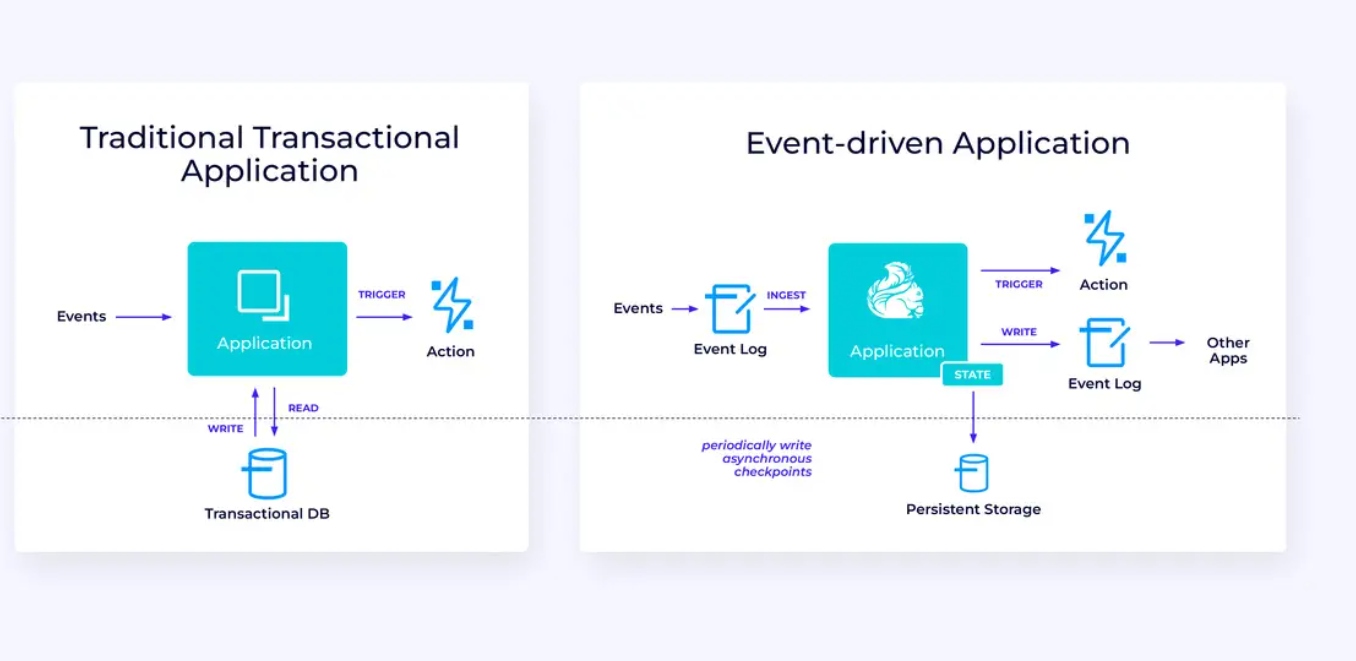
Информационно-дисциплинарные приложения
Наше третья и последняя семья использований касается реализации информационно-дисциплинарных приложений или микросервисов. Многое было написано по этому вопросу в других местах; это архитектурный дизайн-паттерн, имеющий много преимуществ.
Flink может быть отличным выбором для этих приложений, особенно если вам нужны такие характеристики, как может обеспечить Flink. В некоторых случаях Tablica/SQL API уже всё, что вам нужно, но в многих случаях вам потребуется дополнительная гибкость DataStream API хотя бы для части работы.
Приступая к работе с Flink
Flink обеспечивает мощную платформу для создания приложений, обрабатывающих поток событий. Как мы показали, некоторые понятия могут показаться новичкам немного необычными, но как только вы узнаете, как Flink designed и работает, программное обеспечение становится интуитивно использовать, и награда за изучение Flink значительна.
Как следующий шаг, следуйте инструкциям в документации Flink , которые вам покажут, как скачать, установить и запустить最新 стабильную версию Flink. Подумайте о широком спектре использований, которые мы обсуждали – современные data pipeline, реально-временные анализы и информационно-дисциплинарные микросервисы – и как они могут помочь решить задачу или создать ценность для вашей организации.
Сетевые потоки данных являются одним из самых волнующих направлений в технологиях для предприятий на сегодняшний день, и обработка потоков с помощью Flink делает ее еще более мощной. Изучение Flink будет полезно не только для вашей организации, но и для вашей карьеры, поскольку реально-временная обработка данных становится более ценной для бизнесов по всему миру. Так что взять на себя Flink сегодня и увидеть, что может помочь вам это мощная технология.
Source:
https://dzone.com/articles/apache-flink-101-a-guide-for-developers