













近年、Apache Flinkは実時間のストリーム処理のデフォルトの標準として自己立ち上がりしています。ストリーム処理は、事件ストリーム(時間の系列における事件の列)を最も基本的な構築ブロックとして扱うことを特征づけるシステム構築のパラダイムです。Flinkなどのストリームプロセッサは、事件源から生成される入力ストリームを消費し、消费者(消费者は結果を格納し、さらなる処理に使用できるように提供する)によって消費される出力ストリームを生成します。
アマゾン、ネットflix、ユーバーなどの有名企業は、Flinkを実行してビジネスの中心部分で大規模にデータパイプラインを運営していますが、Flinkは迅速に重要なビジネス事件に対応することが必要な多くの小企業でも重要な役割を果たしています。
Flinkは何のために使用されているのでしょうか?一般的な使用例はこれらの3つのカテゴリーに分けられます。
|
ストリーミングデータパイプライン |
実時間分析 |
イベント駆動型应用 |
|---|---|---|
|
データストリームを持続的に吸入し、充てて、変換し、適切な時間に行動するための宛先システムに読み込む(バッチ処理とは対照的) |
結果を持続的に生成し、更新し、実時間データストリームが消費されたときに表示し、ユーザーに提供する |
入力事件に基づいてパターン認識し、計算をトリガー、状態更新を行い、外部行動を実行する |
|
以下はいくつかの例です。
|
いくつかの例があります:
|
いくつかの例があります:
|
Flinkには以下が含まれています:
- 世界の企業が必要とする规模のデータストreamワークロードに強力なサポート
- 正確な一度の処理と失敗の復旧の強い保証
- Java、Python、SQLのサポートを提供し、バッチとストリーム処理の両方を统一的にサポート
- FlinkはApache Software Foundationの成熟したオープンソースプロジェクトであり、非常に活動的でサポート的なコミュニティがあります。
Flinkは時に複雑で学習するのが難しいと言われます。はい、Flinkの実装のRuntimeは複雑であり、驚くべきではありませんが、いくつかの難しい問題を解決するためのものです。FlinkのAPIは学習するのに一定の困難があるかもしれませんが、これは概念や組織原理が未知であるためにより多いですが、固有の Complexityによるものではありません。
Flinkは、以前に使われていたものとは異なるかもしれませんが、多くの点で実際にはかなりシンプルです。あなたがFlinkが構築されている方法や、 runtimeに直面する問題についてより熟悉になるにつれ、FlinkのAPIの詳細が、いくつかの键となる原則の显然な結果であると感じられるようになるでしょう。
この記事は、Flinkの設計に基づく核心原則を説明して、Flinkの学習の道をもっと簡単にすることを目指しています。
Flinkは、いくつかの大きなアイデアを体現しています。
ストリーム
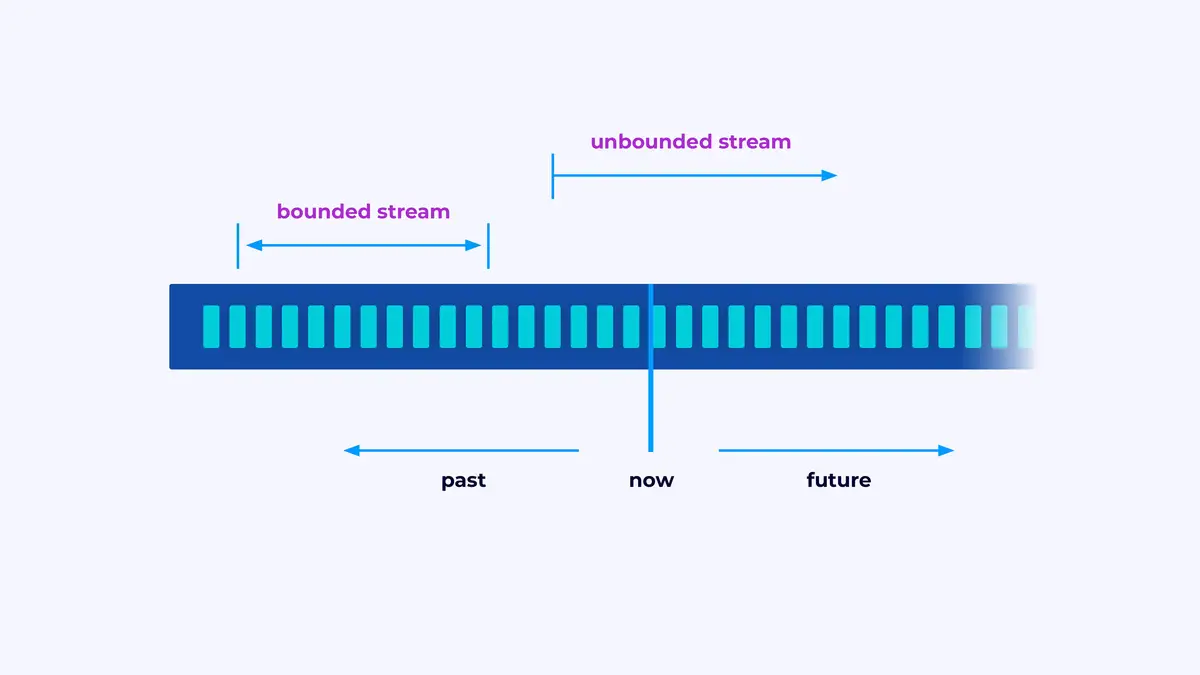
Flinkは、イベントストリームを処理するアプリケーションを構築するフレームワークです。ストリームは、限定されたまたは限定されないイベントの序列です。
Flinkアプリケーションは、データ処理パイプラインです。あなたのイベントはこのパイプラインを流れ、それぞれの段階であなたのコードによって操作されます。このパイプラインをジョブグラフと呼んでいます。このグラフのノード(つまり、処理パイプラインの段階)はオペレータと呼ばれます。
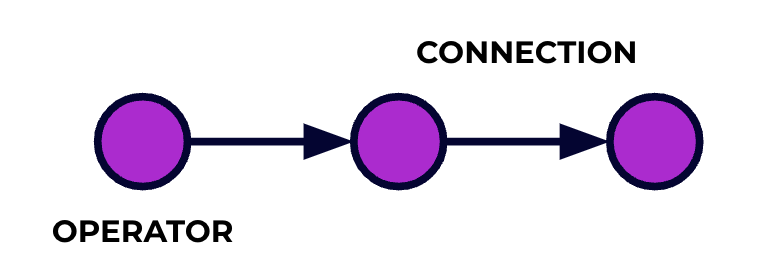
あなたがFlinkのAPIのいずれか一つを使用して書くコードは、ジョブグラフを説明します。これには、オペレータの行動とそれらの接続が含まれます。
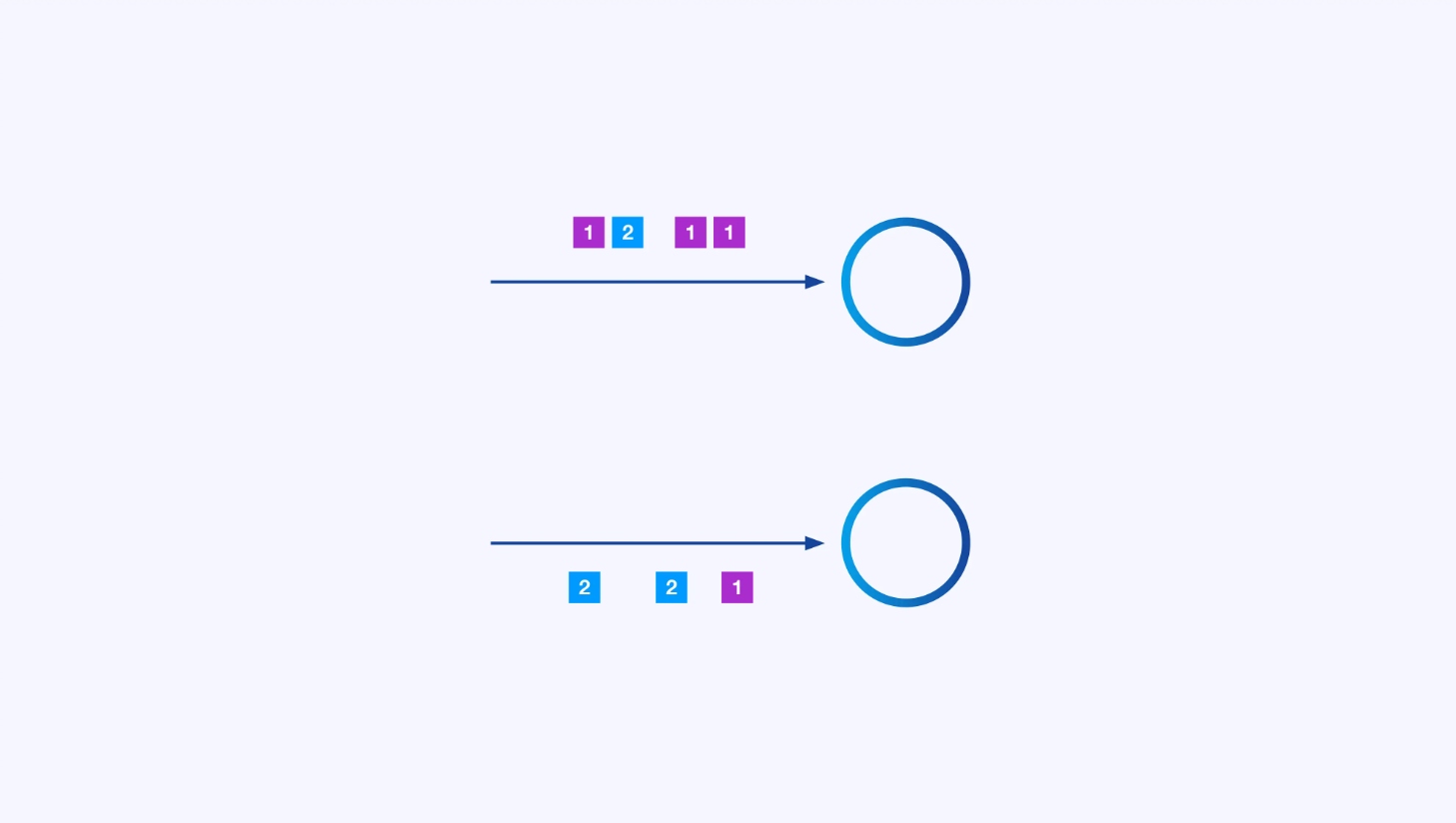
並列処理
各オペレータは、独立していくつかのイベントのサブセットに対して操作を行うことができる多くの並列なインスタンスを持つことができます。
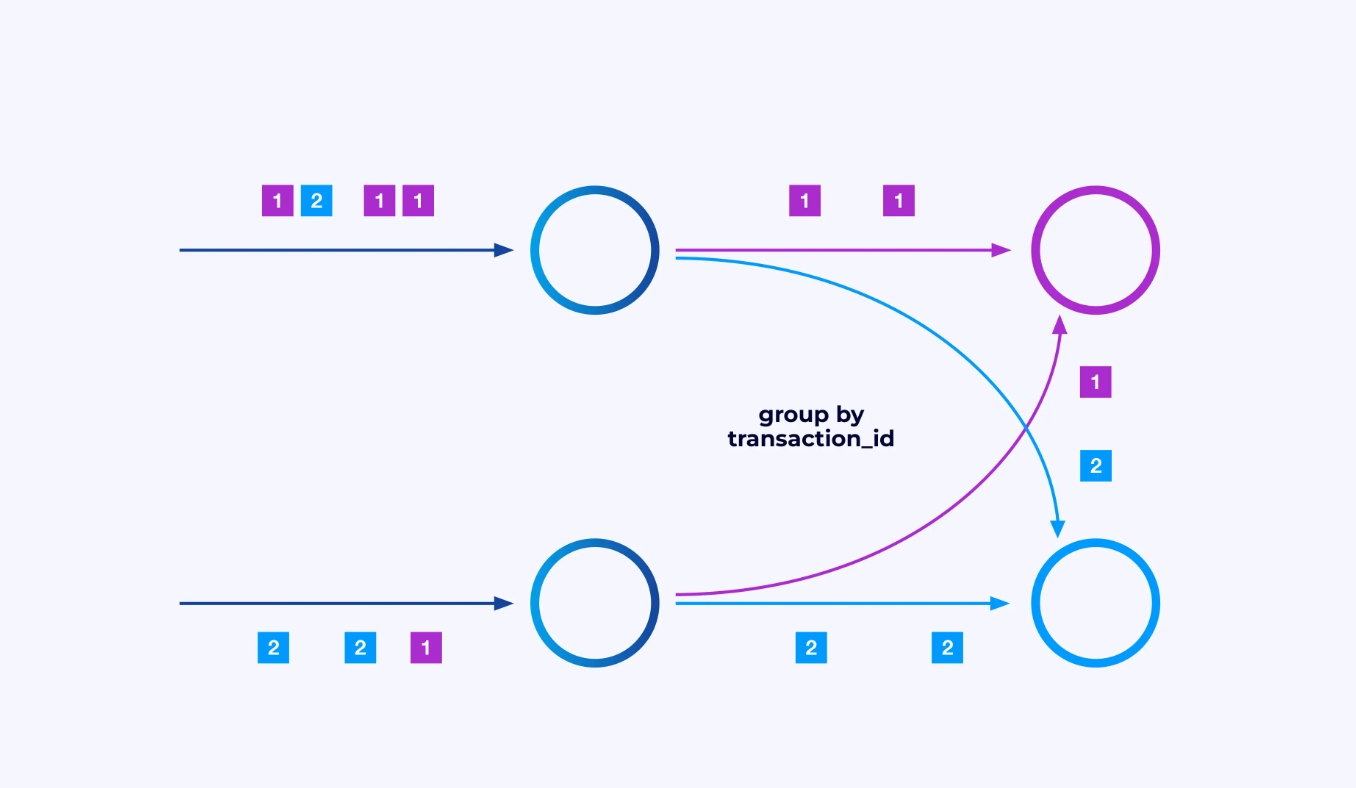
時に、あなたは、これらのサブストreamsに特定の分割schemeを適用し、イベントを、与应用 specific logicに基づいて一緒にグループ化する必要があることがある。たとえば、 Financial transactionsを処理している場合、あなたは、各 transactionに対するすべてのイベントを同じ threadで処理するように構成する必要があるかもしれません。これにより、各 transactionによる時間を経て発生するさまざまなイベントを接続することができます。
Flink SQLでは、GROUP BY transaction_idを使用してこれを行い、DataStream APIでは、この分割または分割を指定するkeyBy(event -> event.transaction_id)を使用します。どちらの場合も、これはジョブグラフの2つの連続した段階の間に完全に接続されたネットワークシャッフルとして表示されます。
状態
key-partitioned streamsで操作を行うオペレーターは、Flinkの分布的なkey/value状態ストアを使用して、彼らが望む内容を持久的に保持することができます。各keyの状態は、オペレーターの特定のインスタンスに限定されており、他のどこからもアクセスできません。並列サブトポロジーは何も共有しませんが、これは無制限のスケールアップに非常に重要です。
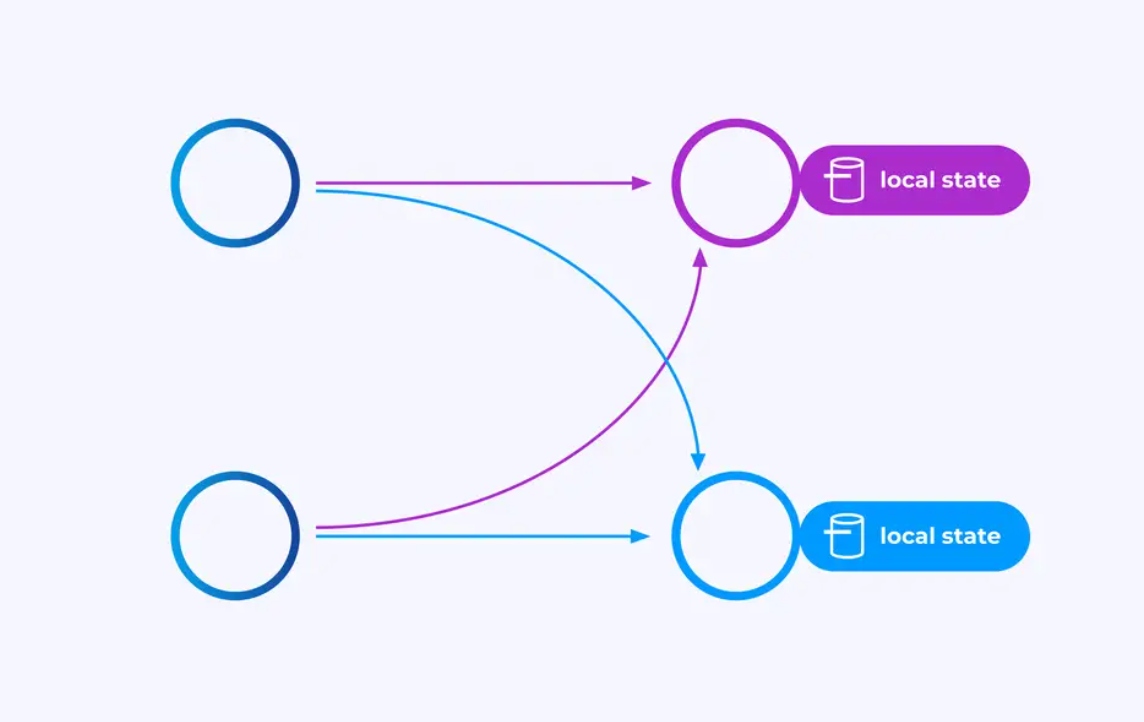
Flinkジョブは、無限に実行される可能性があります。Flinkジョブが新しいkey(例えば、transaction ID)を連続的に作成し、新しいkeyに対して何かを保存している場合、このジョブは unbounded amount of stateを使用しているため、爆発する危険があります。FlinkのAPIすべては、runaway explosions of stateを防ぐための方法を提供するように構成されています。
時間
状態を長い時間を持って保持してはならないという一つの方法は、特定の時間点までのみ状態を保持することです。たとえば、1分間のトランザクション数をカウントしたい場合、それぞれの1分間が終わると、その1分間の結果を生成することができ、そのカウンターを解放することができます。
Flinkでは、2つの異なる時間概念に対する重要な区別を作ります。
- 処理(または壁時計)時間は、イベントが処理される実際の日時から導出されます。
- イベント時間は、各イベントに記録されたタイムスタンプに基づいています。
これらの違いを説明するために、1分間のウィンドウが完了する意味を考えてみましょう。
- 処理時間のウィンドウは、1分が終わると完了します。これは完璧に明快です。
- イベント時間のウィンドウは、その分に発生したすべてのイベントが処理されると完了します。これはtrickyになる可能性があります。なぜなら、Flinkはまだ処理されていないイベントについて何も知らないからです。私たちがすることの最善は、ストリームがいかに乱雑であるかの仮説を作り、その仮説を啟発的に適用することです。
失敗の復帰にたいするチェックポイント
失敗は避けられないものです。しかしながら、Flinkは効果的に正確に一度だけの保証を提供することができます。つまり、各イベントはFlinkが管理している状態に一度だけ影響を与えることになり、失敗が起きていないかのようになります。Flinkは定期的に、全ての状態について自己コンシステントなスナップショットを取ることで、これを実現します。これらのスナップショットはFlinkによって作成および管理され、チェックポイントと呼ばれます。
回復は、最新のチェックポイントに記録された状態にロールバックし、そのチェックポイントから全てのオペレーターを再起動することで行われます。回復中に、一部のイベントが再処理されますが、Flinkは、各チェックポイントがシステムの完全な状態のための全局的で一貫性を保つスナップショットであることを保証することで、正しさを保証します。
システムアーキテクチャ
FlinkアプリケーションはFlinkクラスター内で実行されますので、Flinkアプリケーションをプロダクションに導入する前に、デプロイ先となるクラスターが必要です。幸いにも、開発やテスト中には、IntelliJやDockerなどの統合開発環境(IDE)内でFlinkをローカルに実行することで簡単に始めることができます。
Flinkクラスターには2種類のコンポーネントがあります: Job ManagerとTask Managerの集合。Task Managerはあなたのアプリケーション(並行に)を実行しますが、Job ManagerはTask Managerと外部世界との間のゲートウェイとして機能します。アプリケーションはJob Managerに送信され、Task Managerから提供されるリソースを管理し、チェックポイントのコーディングを調整し、メトリックとしてクラスターに対する視覚的な情報を提供します。
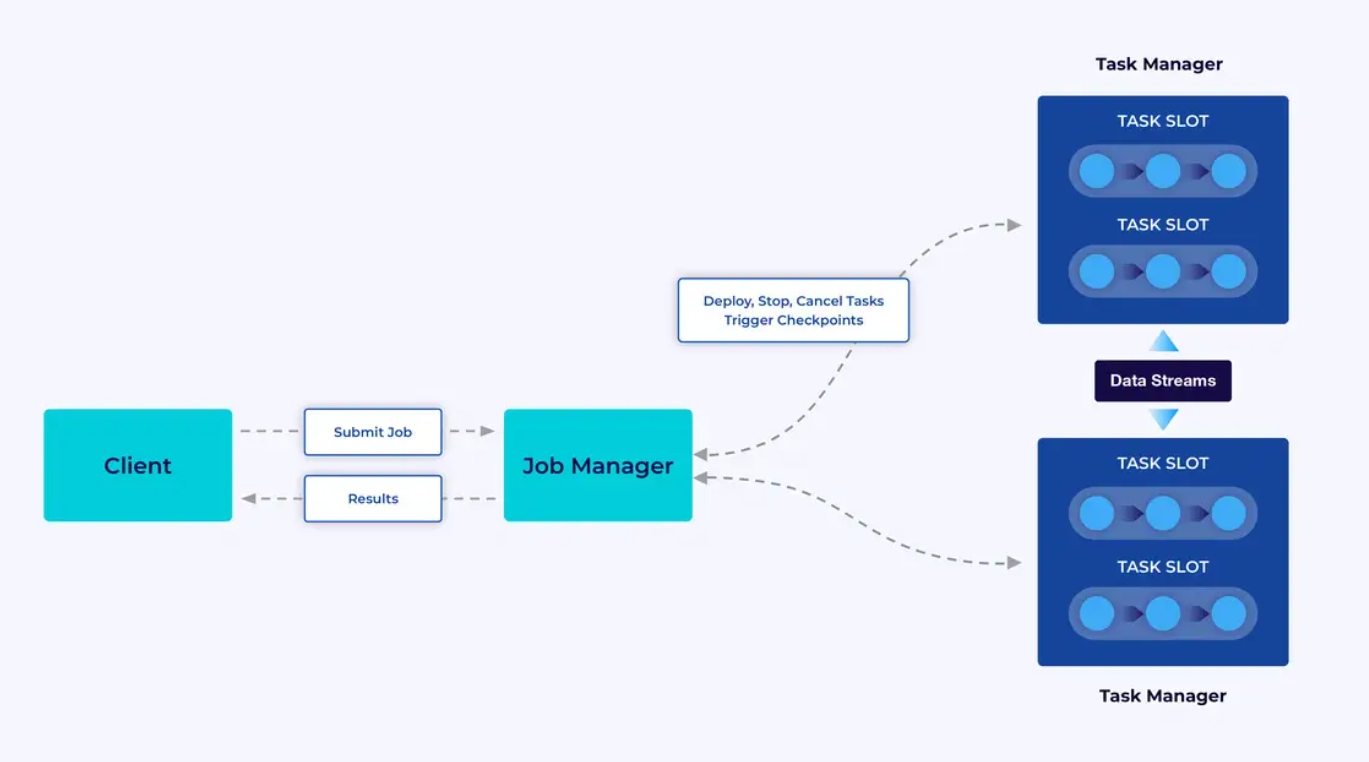
開発者の経験
Flink開発者としての経験は、どのAPIを選択するかによって一定の程度に影響されます。APIには古い、低レベルのDataStream APIや新しい、関連性のあるテーブルとSQL APIがあります。
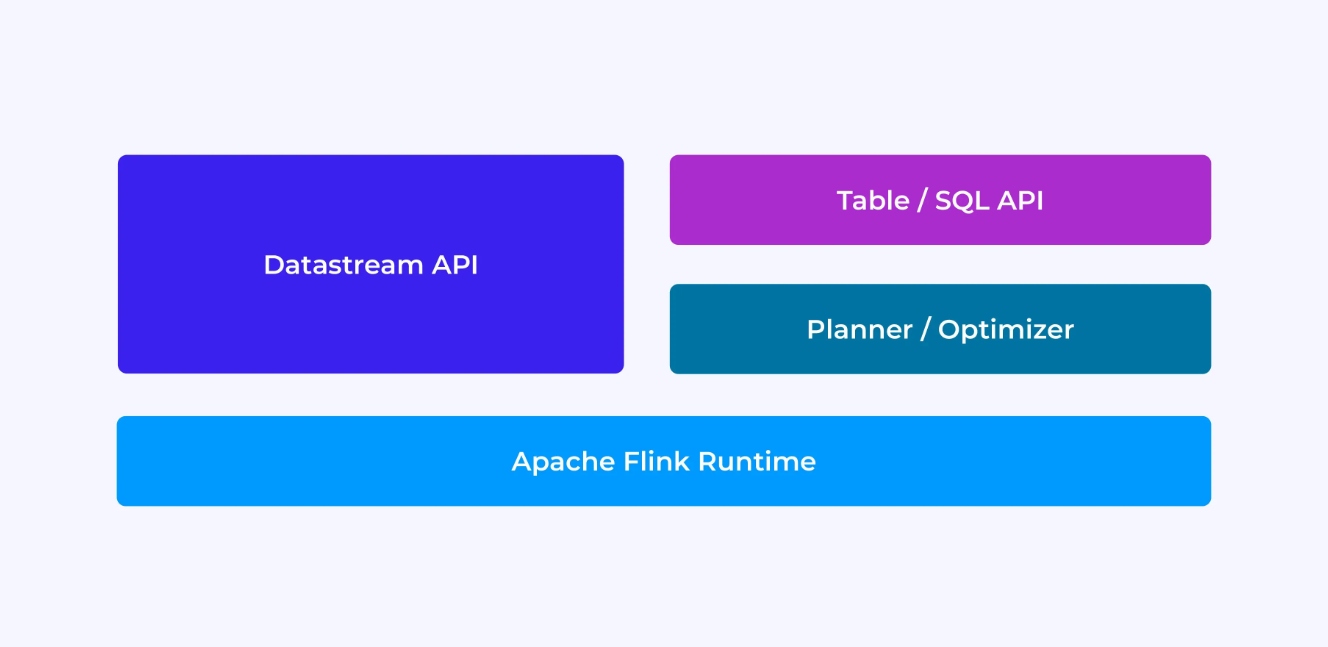
FlinkのDataStream APIを使用してプログラムを書いている時、Flink运行時がアプリケーションを実行する際の動作を意識的に考えています。これは、1つのオペレーターに1つのオペレーターを追加して、使用している状態を説明し、関与している型とその序列化、タイマーを作成し、タイマーが発生した際に実行されるコールバック関数を実装しています。DataStream APIの核心抽象化は、イベントであり、書く関数は一度に1つのイベントを受信した後で、それに対応しています。
他方に、FlinkのTable/SQL APIを使用する際には、これらの低レベルの懸念は自動的に処理され、ビジネスロジックに直接焦点を当てることができます。核心抽象化は、テーブルであり、より多くのテーブルを結合して強化、行を集めて集計分析を計算するなど、テーブルをより多く考えることができます。組み込まれたSQLクエリプランナーと最適化器は詳細を処理します。プランナー/最適化器はリソースを効率よく管理するには優れた成果をあげますが、手書きコードをはるかに上回る場合が多いです。
詳細に深入了解する前に、いくつかの考えを述べます。まず、DataStream APIまたはTable/SQL APIを選ぶ必要はないです。この2つのAPIは互換性があり、 Combine them as you like. それは、Table/SQL APIで不可能なカスタマイズが必要な場合に便利な方法です。しかし、Table/SQL APIが提供しているものを超えるために、ユーザー定義の関数(UDF)という形で追加の機能を追加することも良い方法です。ここでは、Flink SQLには扩展性に関する多くの選択肢があります。
ジョブグラフの構築
どのAPIを使用しても、書いたコードの最終的な目的は、Flinkの実行時によって代わって実行されるジョブグラフを構築することです。これは、これらのAPIはOperatorの作成と、その振る舞いや互いの接続を指定することに缭っていることを意味します。DataStream APIを使用すると、直接ジョブグラフを構築しますが、Table/SQL APIを使用すると、FlinkのSQLプランナがこれを行います。
関数とデータのシリアライズ
最終的に、Flinkに提供するコードは、Flinkクラスタのワーカー(タスクマネージャ)によって並行に実行されます。これを実現するために、作成した関数オブジェクトはシリアライズされ、タスクマネージャに送信され、そこで実行されます。同様に、イベント自体も、時々タスクマネージャの間でネットワーク上に送信される必要があります。再度、Table/SQL APIではこれについて考える必要はありません。
状態管理
Flink実行時には、失敗時に復元する予定の状態を認識する必要があります。これを機能させるために、Flinkはこれらのオブジェクトをシリアライズおよびデシリアライズするために使用できる型情報が必要です(これらがチェックポイントに書き込まれ、読み取られることができるように)。この管理された状態に時間制限のディスクリプターを任意に設定することができ、これによりFlinkは自動的に状態を有効期限切れにします。
DataStream APIを使用すると、通常、アプリケーションに必要な状態を直接管理することになります(これには内置的なウィンドウ操作が例外です)。その一方、Table/SQL APIでは、この关心点が抽象化されます。たとえば以下のようなクエリを与えたとして、Flink runtimeの何か中で、各URLに対するカウンターを保持するデータ構造が存在しなくてはならないことがわかりますが、すべての詳細はあなたのために処理されています。
SELECT url, COUNT(*)
FROM pageviews
GROUP BY URL;タイマの設定と発火
ストリーム処理において、タイマーは多くの用途があります。たとえば、Flinkアプリケーションは、最終的な結果を生成する前に、さまざまな異なるイベント源から情報を集める必要があることがよくあります。タイマーは、最後まで待機する必要がないが、最終的に到着するか否かを待つことが合理なケースに適用されます。
タイマーは、時間ベースのウィンドウ操作を実装するためにも不可欠です。DataStreamとTable/SQLの両方のAPIには、ウィンドウの内置サポートがあり、あなたのためにタイマーを作成および管理しています。
使用案例
この記事の初めに紹介したストリーム処理の3つの大きなカテゴリーについて、どのようにFlinkに対応するか見てみましょう。
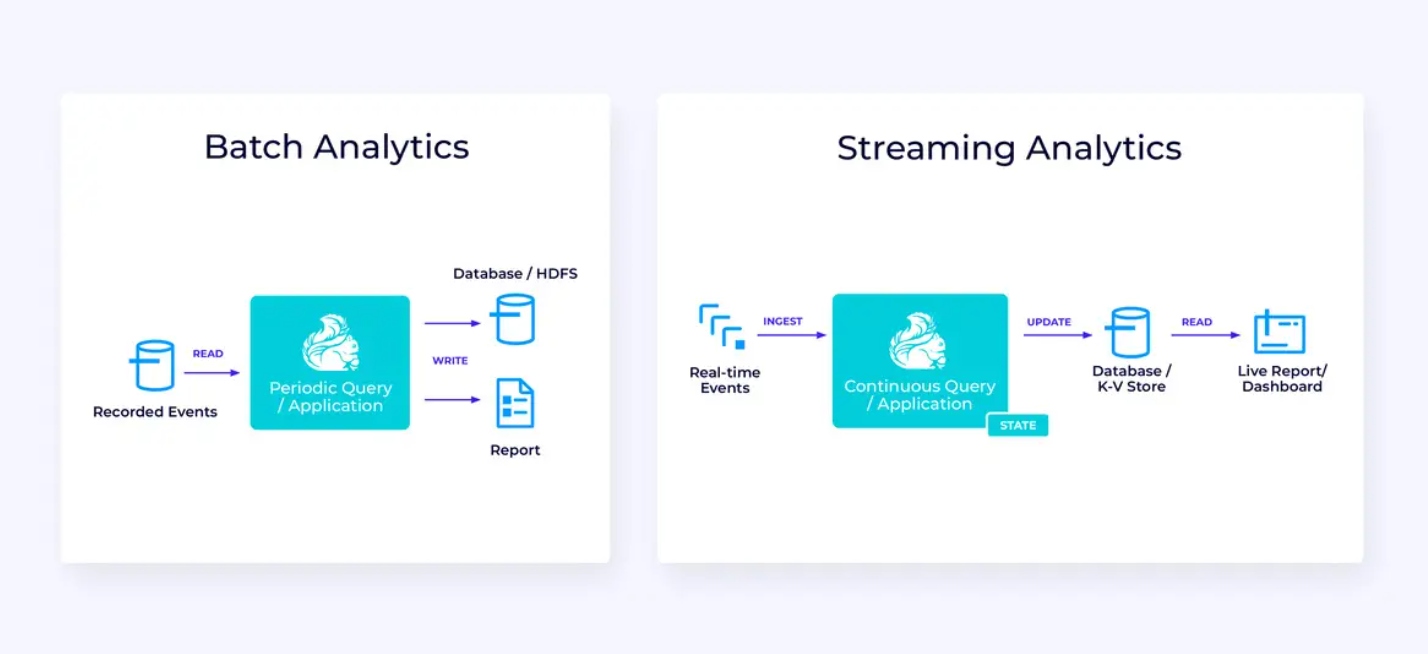
ストリームデータパイプライン
以下は、左側にある、 traditions batch extract, transform, and load (ETL) jobの例です。これは周期的にトランザクショナルデータベースから読み取り、データを変換し、データストア(データベース、ファイルシステム、データ湖など)に書き出すことができます。
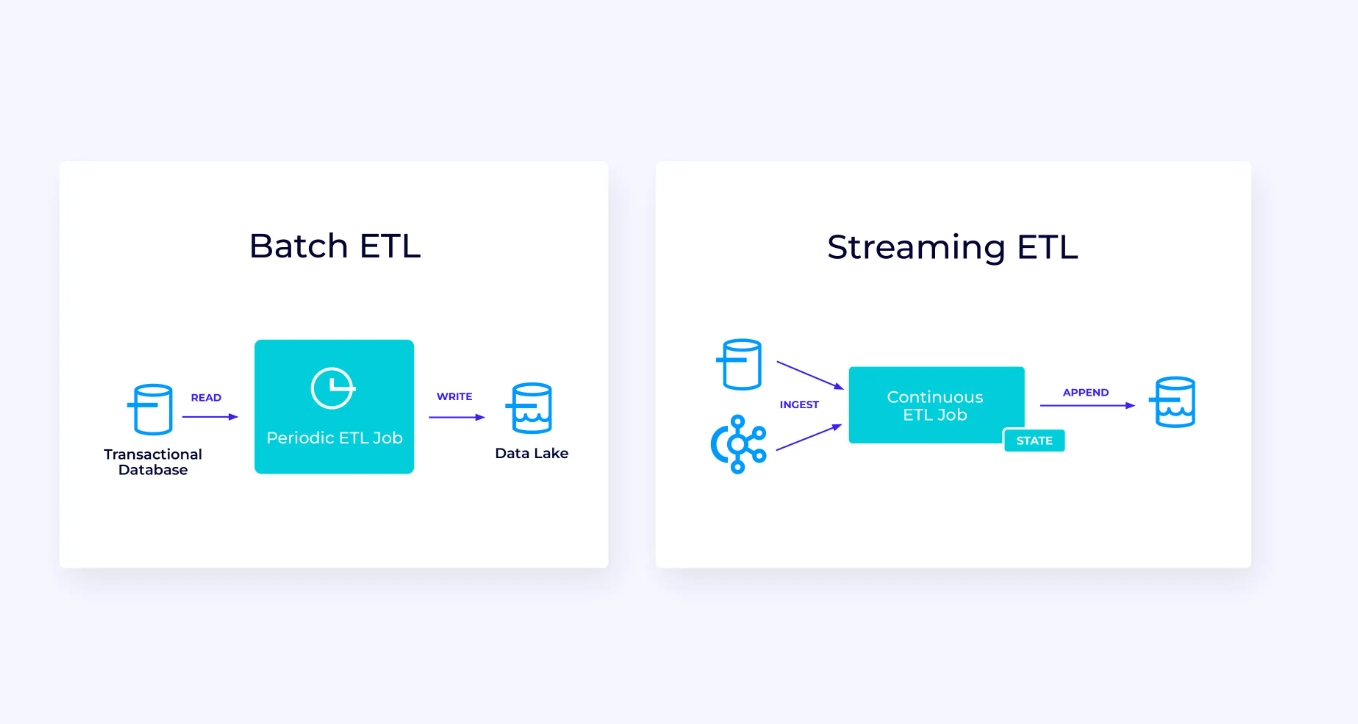
対応するストリームパイプラインは、表面上には似ていますが、重要な違いがあります。
- ストreamingパイプラインは常に運行しています。
- トランザクションデータはストreamingパイプラインに2つの部分で送信されます。データベースからの最初の大規模ロードと、その後の大規模ロード以降のデータベース更新を運搬する変更データ捕獲(CDC)ストリームです。
- ストリーミングバージョンは新しい結果が利用可能になるたびに新たに生成し続けます。
- 状態は明示的に管理されており、失敗事件で強力に復旧できるようになっています。ストリーミングETLパイプラインでは通常、状態を多く使用しません。データ源は、ストリームの開始からの記録数と同じ形で入力の有多少を管理しています。スインクは、データベースやKafkaなどの外部システムへの書き込みをトランザクションを使用して管理します。チェックポイントングの間、源は彼らのオフセットを記録し、スインクは、それら源のオフセットに正確に到达したが、それを超えないように読んだ結果を持ったトランザクションをコミットします。
この用途にとって、Table/SQL APIは適切な選択肢です。
リアルタイムアナリティクス
ストリーミングETLアプリケーションと比較して、このストリーミングアナリティクスアプリケーションにはいくつかの興味深い違いがあります。
- また一度、Flinkが連続的なアプリケーションを実行するために使用されていますが、このアプリケーションでは、Flinkがもっとも多くの状態を管理する必要があるでしょう。
- この用途によって、取り込まれるストリームを、Apache KafkaなどのストリームネイティブストORAGEシステムに格納することが合理です。
- 静的なレポートを周期的に生成する代わりに、ストリーミングバージョンはライブデータスイートを驶けるように使用できます。
再び、テーブル/SQL APIはこの用途において通常良い選択肢です。
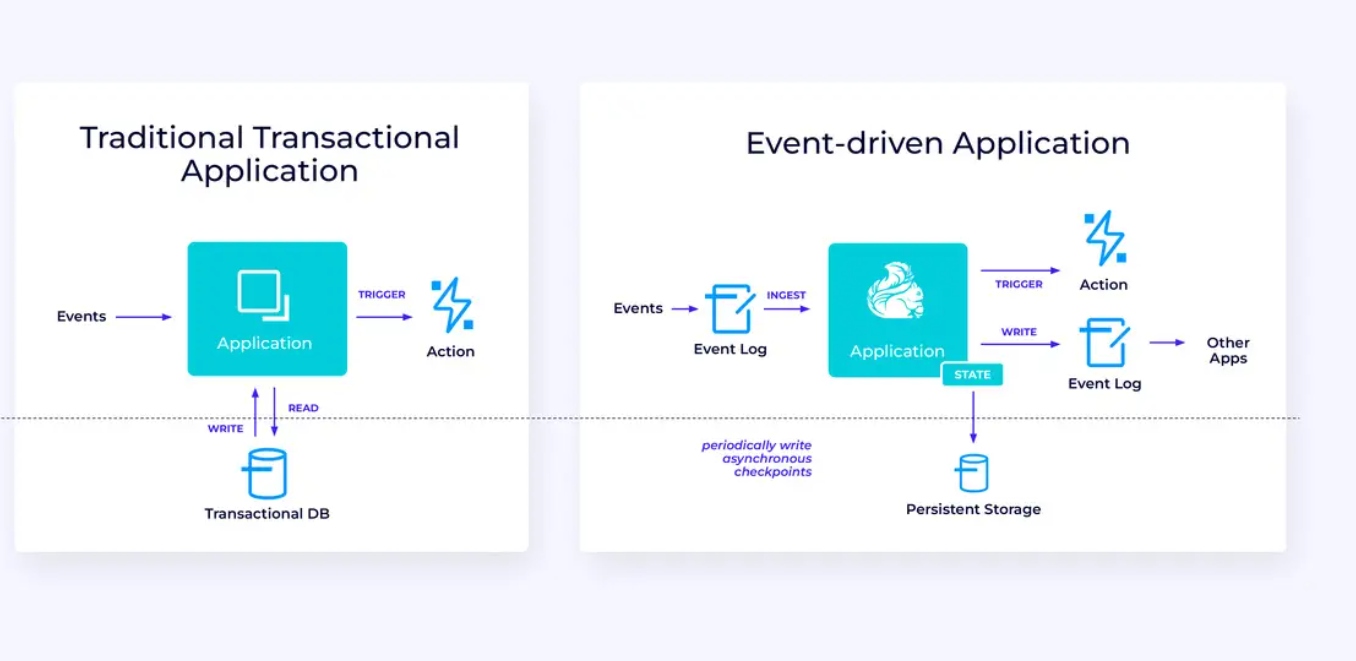
イベント駆動アプリケーション
私たちの第三のおよび最後の用途族群は、イベント駆動アプリケーションまたはマイクロサービスの実装に関するものです。このトピックについては他の場所でも多くの記述があります;これはARCHITECTURAL DESIGN PATTERNで、多くの利点があります。
Flinkはこれらのアプリケーションに非常に適していますが、特にFlinkが供給できるパフォーマンスが必要であれば。いくつかの場合、テーブル/SQL APIは必要なものすべてを提供していますが、多くの場合、少なくとも一部の作业にはDataStream APIの追加の柔軟性が必要です。
Flinkの始め方
Flinkはイベントストreamを処理するアプリケーションを構築する強力なフレームワークを提供します。私たちがカバーしたように、いくつかの概念は最初に新しいと感じるかもしれませんが、Flinkが設計されて機能している方法に慣れると、ソフトウェアは使用しやすくなり、Flinkを知ることの報酬は大きいです。
次の手順はFlinkのドキュメントに記載されています。これに従って、Flinkの最新の安定版をダウンロードし、インストールし、実行する手順を导かれます。私たちが議論した幅広い用途病例を思い出してください;現代的なデータパイプライン、リアルタイムアナリティクス、そしてイベント駆動のマイクロサービスについて。これらがあなたの組織の課題を解決するためのものか、価値を生み出すためのものであるかを考えてください。
データストreamingは、今日の企業技術の最も魅力的な分野の1つであり、Flinkを使用したストリーム処理はそのパワーをさらに增幅する。实时データ処理が世界中の企業にとってより有価なものになるため、Flinkを学ぶことは、あなたの組織だけでなく、キャリアにも大きな利益をもたらす。なので、今日からFlinkをご覧ください。このパワーフルな技術があなたに何を達成することができるか確認してみてください。
Source:
https://dzone.com/articles/apache-flink-101-a-guide-for-developers