













En los últimos años, Apache Flink ha establecido itself como la norma de facto para el procesamiento en tiempo real de flujos de eventos. El procesamiento de flujos de eventos es un paradigma para la construcción de sistemas que trata los flujos de eventos (secuencias de eventos en el tiempo) como su bloque de construcción más fundamental. Un procesador de flujos, como Flink, consume flujos de entrada producidos por fuentes de eventos y produce flujos de salida que son consumidos por sumideros (los sumideros almacenan resultados y los hacen disponibles para un procesamiento posterior).
Nombres conocidos como Amazon, Netflix y Uber dependen de Flink para potenciar los pipelines de datos que funcionan a una escala tremenda en el corazón de sus negocios, sin embargo, Flink también juega un papel clave en muchas empresas pequeñas con requisitos similares para ser capaz de reaccionar rápidamente a eventos críticos de negocios.
¿Para qué se utiliza Flink? Los casos de uso comunes se dividen en estas tres categorías:
|
Pipelines de datos en flujo |
Análisis en tiempo real |
Aplicaciones dirigidas por eventos |
|---|---|---|
|
Ingiere, enrique y transforme continuamente flujos de datos, cargándolos en sistemas de destino para acciones oportunas (en comparación con el procesamiento por lotes). |
Produzca y actualice continuamente resultados que se muestran y entreguen a los usuarios a medida que se consume flujos de datos en tiempo real. |
Reconozca patrones y reaccione a eventos entrantes mediante la activación de computaciones, actualizaciones de estado o acciones externas. |
|
Algunos ejemplos incluyen:
|
Algunos ejemplos incluyen:
|
Algunos ejemplos incluyen:
|
Flink incluye:
- Soporte robusto para cargas de flujo de datos a la escala necesaria por empresas globales
- Garantías fuertes de corrección exacta una sola vez y recuperación de fallas
- Soporte para Java, Python y SQL, con un soporte unificado tanto para procesamiento por lotes como por flujo
- Flink es un proyecto de código abierto maduro de la Fundación Apache Software y tiene una comunidad muy activa y apoyada.
A veces se describe a Flink como complejo y difícil de aprender. Sí, la implementación del runtime de Flink es compleja, pero eso no debería sorprender, ya que resuelve algunos problemas difíciles. Las APIs de Flink pueden ser algo desafiantes para aprender, pero esto se relaciona más con que los conceptos y los principios organizativos son desconocidos que con cualquier complejidad inherentemente.
Flink puede ser diferente de cualquier otra cosa que haya utilizado antes, pero en muchos aspectos, realmente es bastante simple. En algún momento, a medida que se hace más familiar con la manera en que Flink se compone y los problemas que su tiempo de ejecución debe abordar, los detalles de las APIs de Flink应该empezar a parecerle consecuencias obvias de unas pocas principios clave, en lugar de una colección de detalles oscuros que debería memorizar.
Este artículo tiene el objetivo de hacer que el proceso de aprendizaje de Flink sea mucho más fácil, exponiendo los principios centrales que subyacen a su diseño.
Flink Encarna Unas Pocas ideas Grandes
Streams
Flink es un marco para construir aplicaciones que procesan flujos de eventos, donde un flujo es una secuencia limitada o no limitada de eventos.
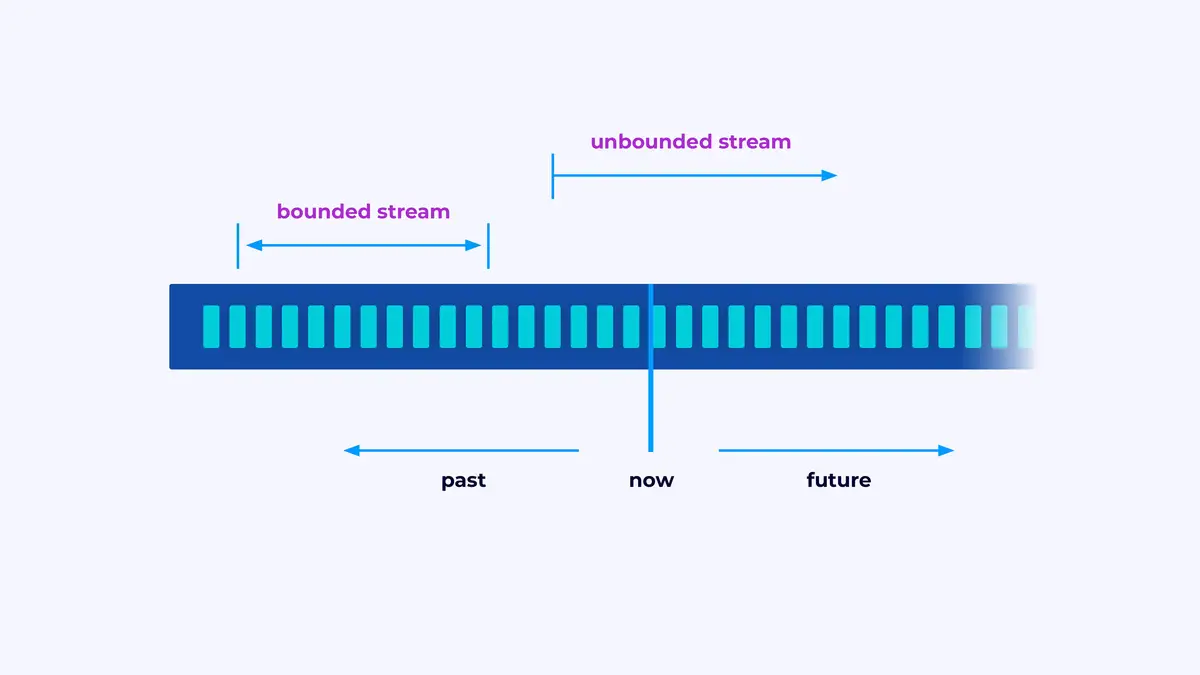
Una aplicación de Flink es un tubo de procesamiento de datos. Tus eventos fluyen a través de este tubo y son operados en cada etapa por el código que escribes. Llamamos a este tubo de procesamiento el gráfico de trabajo, y los nodos de este gráfico (o, en otras palabras, las etapas del tubo de procesamiento) se llaman operadores.
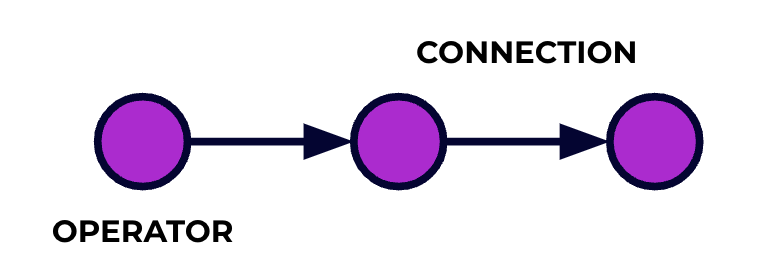
El código que escribes usando una de las APIs de Flink describe el gráfico de trabajo, incluyendo el comportamiento de los operadores y sus conexiones.
Procesamiento en Paralelo
Cada operador puede tener muchas instancias en paralelo, cada una operando de forma independiente sobre alguna subcategoría de los eventos.
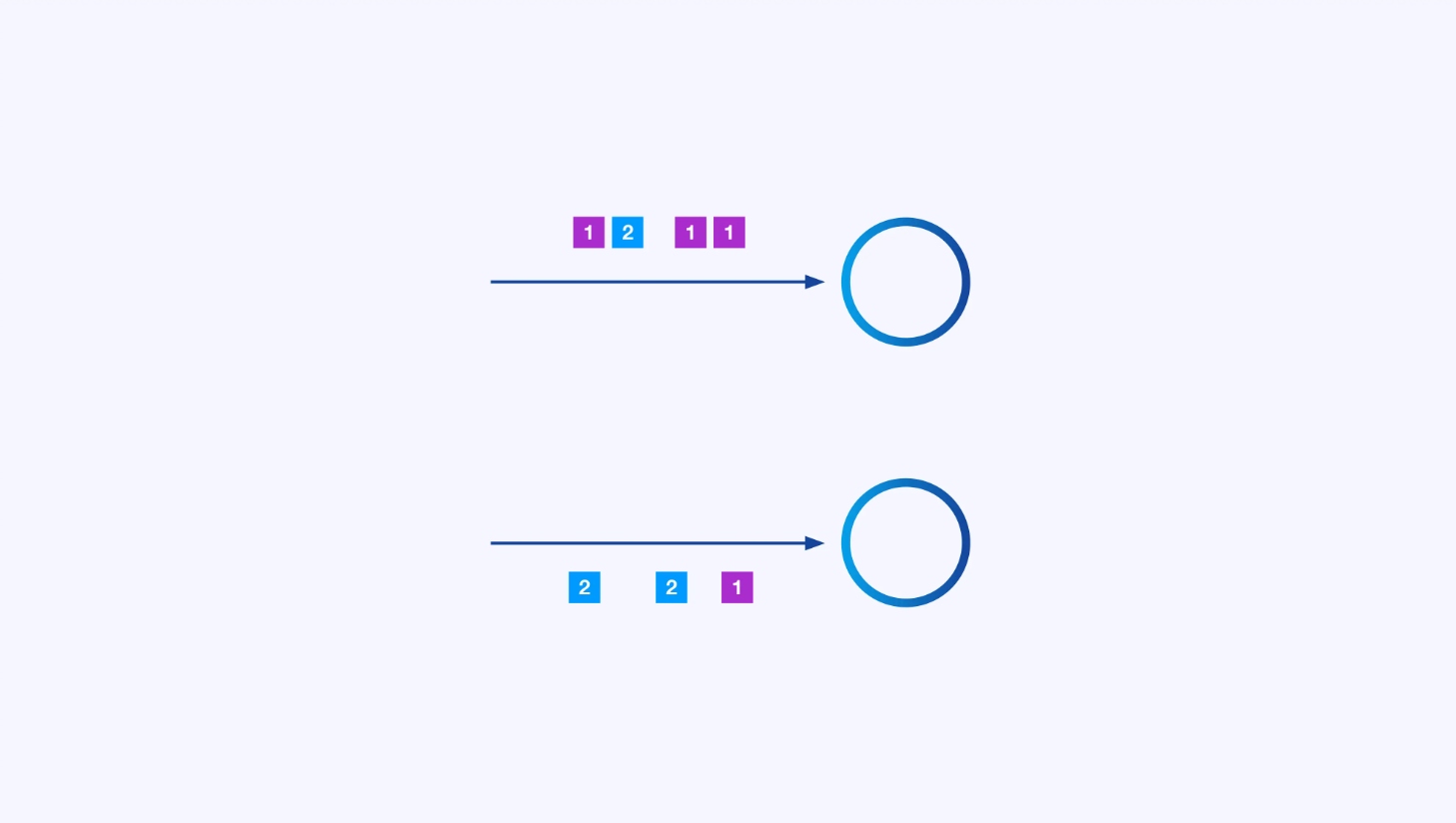
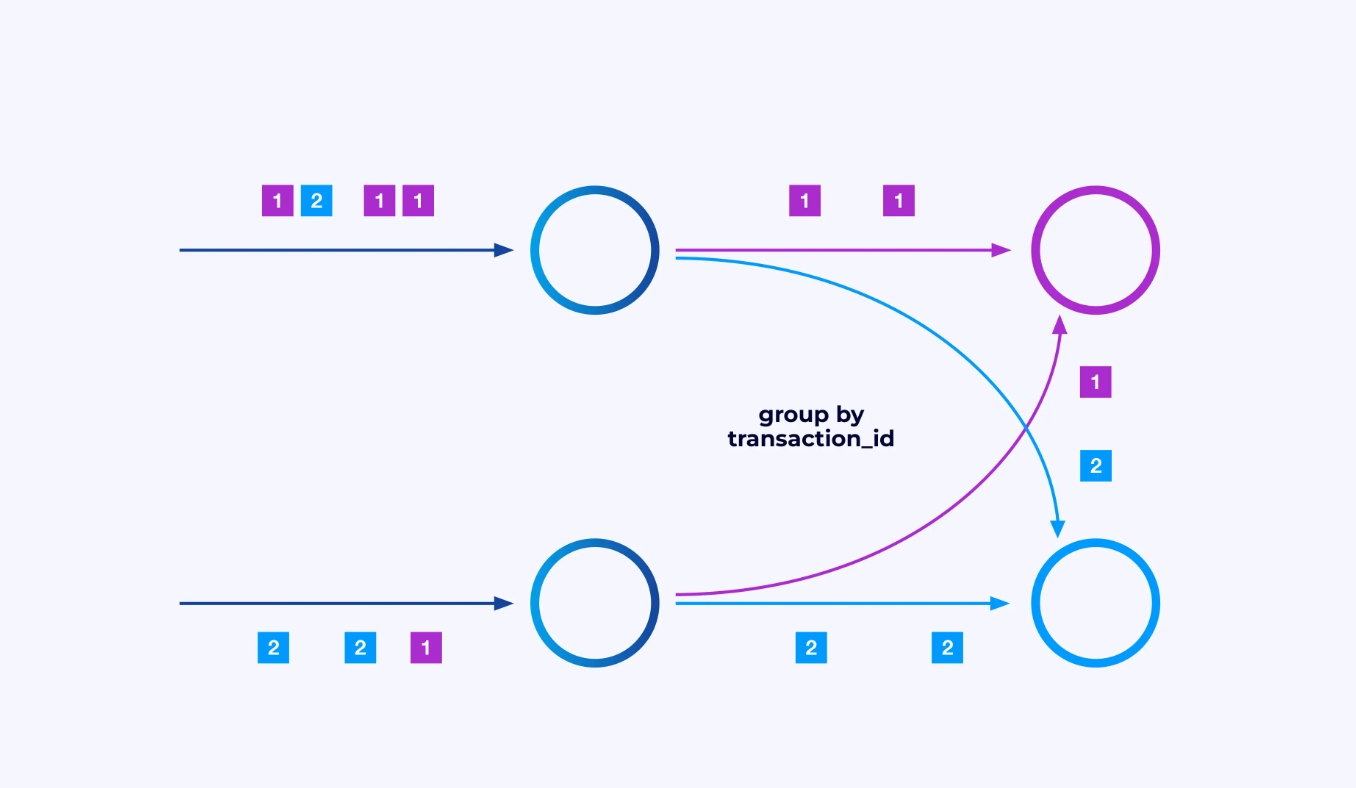
A veces deseará imponer un esquema de particionado específico en estas sub-corrientes para que los eventos se agrupen juntos según alguna lógica específica de aplicación. Por ejemplo, si estás procesando transacciones financieras, podría necesitar arreglar que cada evento para cualquier transacción dada se procese en el mismo hilo. Esto le permitirá conectar juntos los diversos eventos que ocurren en el tiempo para cada transacción
En Flink SQL, esto lo haría con GROUP BY transaction_id, mientras que en la API DataStream utilizaría keyBy(event -> event.transaction_id) para especificar este agrupamiento o particionado. En cualquier caso, esto aparecerá en el gráfico de trabajo como una red completamente conectada de mezclado entre dos etapas consecutivas del gráfico.
Estado
Los operadores que trabajan en corrientes particionadas por clave pueden utilizar el almacén de estado distribuido de clave/valor de Flink para persistir duramente lo que deseen. El estado para cada clave es local a una instancia específica del operador y no se puede acceder desde otro lugar. Las sub-topologías paralelas no comparten nada — esto es crucial para la escalabilidad ilimitada.
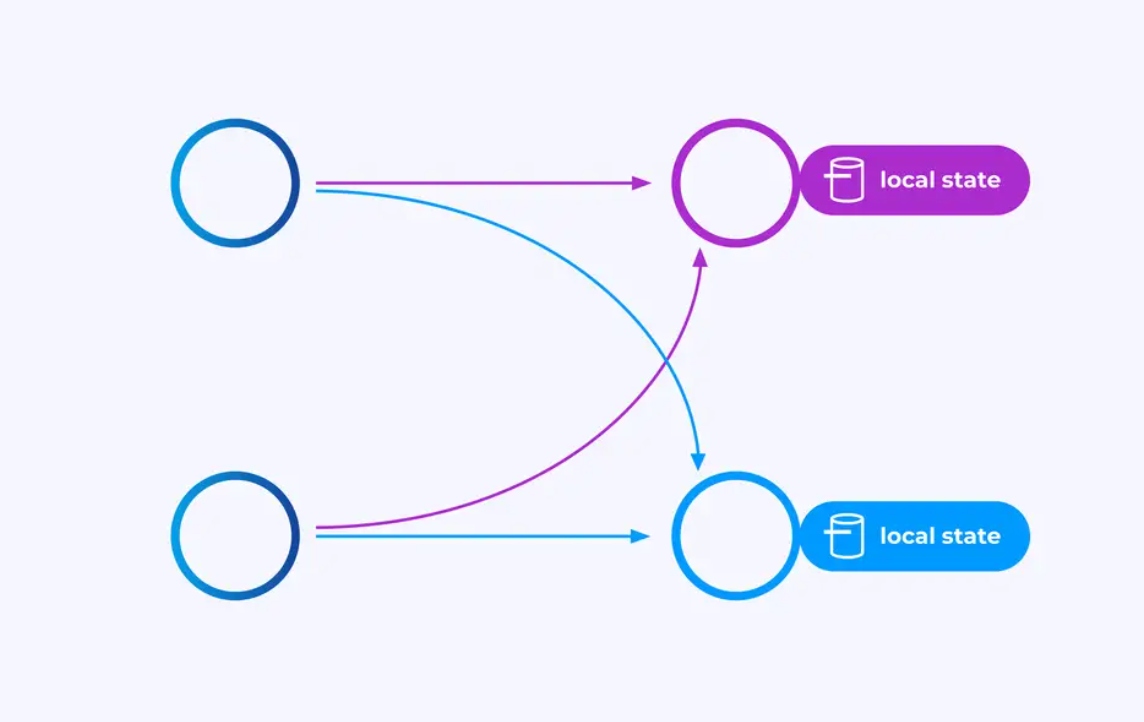
Un trabajo de Flink podría ejecutarse indefinidamente. Si un trabajo de Flink está creando continuamente nuevas claves (por ejemplo, ID de transacción) y almacenando algo para cada nueva clave, entonces ese trabajo corre el riesgo de explotar porque utiliza una cantidad de estado sin límite. Cada API de Flink está organizada alrededor de la provisión de maneras para ayudar a evitar las explosiones de estado incontroladas.
Tiempo
Una forma de evitar retener un estado por demasiado tiempo es mantenerlo solo hasta un punto específico en el tiempo. Por ejemplo, si queremos contar transacciones en ventanas de un minuto, una vez que pasa cada minuto, se puede generar el resultado para ese minuto, y ese contador se puede liberar.
Flink hace una importante distinción entre dos nociones diferentes de tiempo:
- Tiempo de procesamiento (o reloj de pared), que se deriva del tiempo real del día en que se está procesando un evento
- Tiempo de evento, que se basa en las fechas y horas registradas con cada evento
Para ilustrar la diferencia entre ellos, considerar qué significa que una ventana de un minuto haya finalizado:
- Una ventana de tiempo de procesamiento está completa cuando termina el minuto. Esto es perfectamente claro.
- Una ventana de tiempo de evento está completa cuando se ha procesado todos los eventos que ocurrieron durante ese minuto. Esto puede ser complicado ya que Flink no puede saber nada sobre los eventos que no ha procesado todavía. Lo mejor que podemos hacer es hacer una suposición sobre la desordenación que puede presentar un flujo y aplicar esa suposición heurísticamente.
Comprobación de Punto de Control para Recuperación de Fallas
Las fallas son inminentes. A pesar de las fallas, Flink es capaz de proporcionar garantías de forma efectivamente exactamente una vez, lo que significa que cada evento afectará el estado que Flink administra exactamente una vez, como si la falla nunca hubiera ocurrido. Logra esto tomando periódicas instantáneas globales y autoconsistentes de todos los estados. Estas instantáneas, creadas y administradas automáticamente por Flink, se denominan puntos de control.
El proceso de recuperación implica revertir al estado capturado en el último punto de control y llevar a cabo un reinicio global de todos los operadores a partir de ese punto de control. Durante la recuperación, algunos eventos se procesan de nuevo, pero Flink es capaz de garantizar la corrección mediante la determinación de que cada punto de control es una instantánea global y autoconsistente del estado completo del sistema.
Arquitectura del Sistema
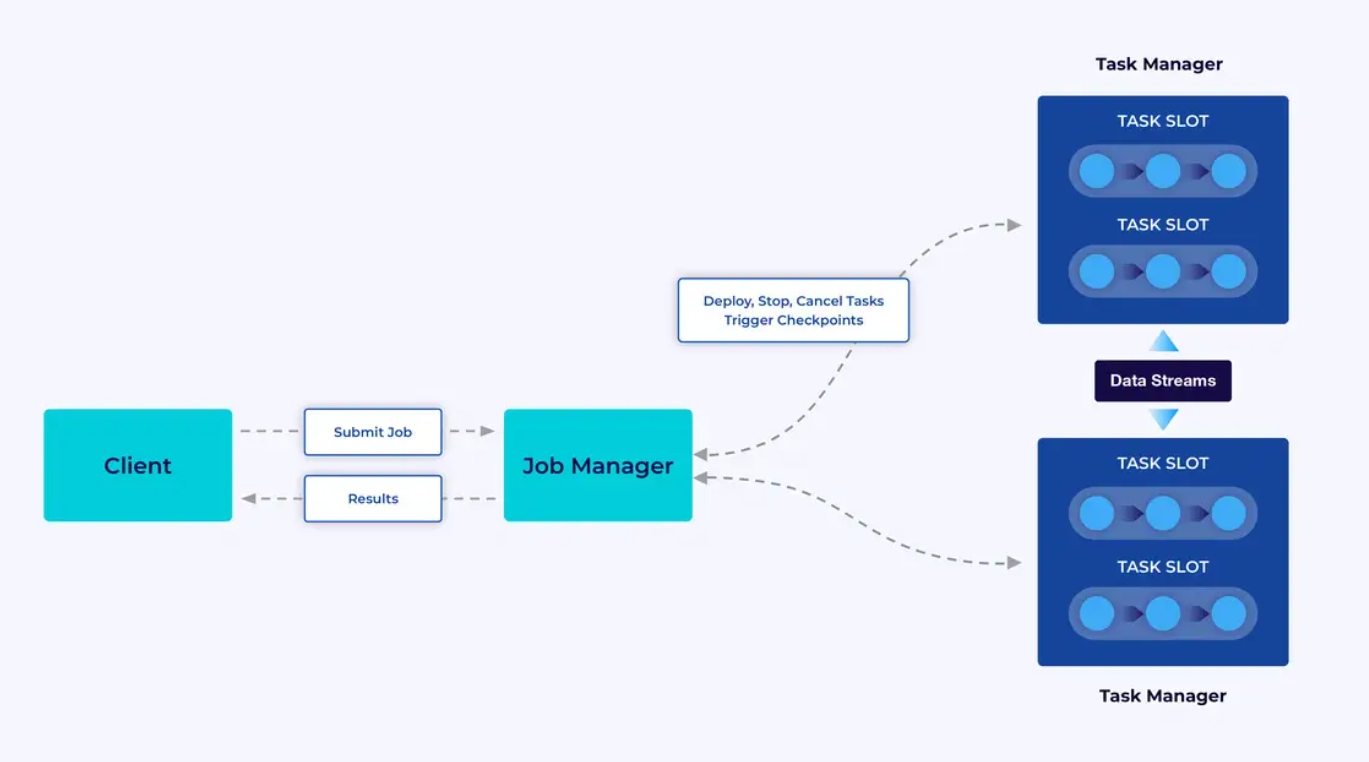
Las aplicaciones de Flink ejecutan en clusters de Flink, por lo que antes de poner una aplicación de Flink en producción, necesitarás un cluster para desplegarla. Afortunadamente, durante el desarrollo y la prueba es fácil empezar ejecutando Flink localmente en un entorno de desarrollo integrado (IDE) como IntelliJ o Docker.
Un cluster de Flink tiene dos tipos de componentes: un Job Manager y un conjunto de Task Managers. Los task managers ejecutan su aplicación (en paralelo), mientras que el job manager actúa como una puerta entre los task managers y el mundo exterior. Las aplicaciones se envían al job manager, que administra los recursos proporcionados por los task managers, coordina el control de puntos de control y proporciona visibilidad en el cluster en la forma de métricas.
La Experiencia del Desarrollador
La experiencia que tendrá como desarrollador de Flink depende, en cierta medida, de la API que elija: ya sea la antigua API de DataStream de nivel bajo o las nuevas API relacionales de Table y SQL.
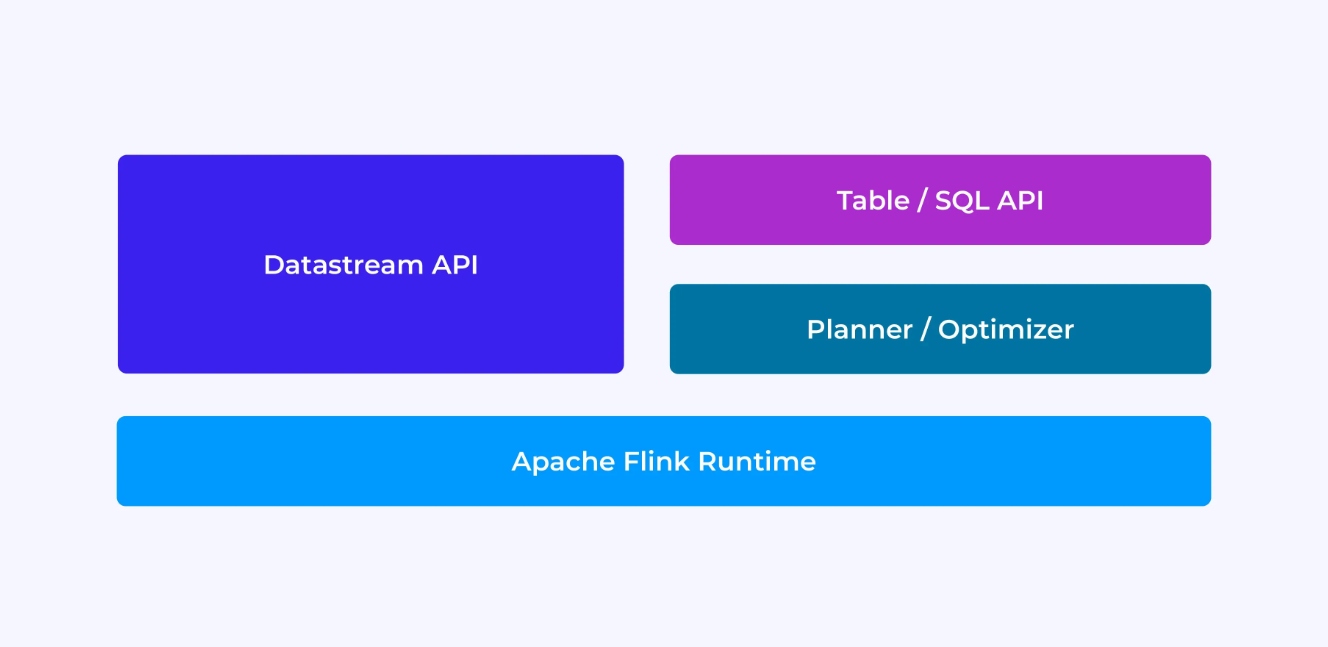
Cuando estás programando con la API DataStream de Flink, estás pensando concientemente en qué estará haciendo el tiempo de ejecución de Flink mientras tu aplicación se ejecuta. Esto significa que estás construyendo el gráfico de trabajo de la tarea una operación por vez, describiendo el estado que estás utilizando junto con los tipos involucrados y su serialización, creando temporizadores y implementando funciones de callback que se ejecutarán cuando estos temporizadores se disparan, etc. La abstracción central en la API DataStream es el evento, y las funciones que escribes manejarán un evento por vez, a medida que llegan.
Por otro lado, cuando utilizas la API de Tabla/SQL de Flink, estos problemas de nivel bajo ya están resueltos por ti, y puedes enfocarte más directamente en tu lógica de negocio. La abstracción central es la tabla, y piensas más en términos de unir tablas para enriquecer, agrupar filas juntas para calcular análisis agregados, etc. Un planificador y optimizador de consulta internos se encargan de los detalles. El planificador/optimizador hace un gran trabajo gestionando recursos eficientemente, a menudo superando al código escrito a mano.
Antes de sumergirte en los detalles, un par de consideraciones más: primero, no tienes que elegir entre DataStream o Tabla/SQL API – ambas API son interoperables y puedes combinarlas. Esto puede ser una buena opción si necesitas un poco de personalización que no es posible en la API de Tabla/SQL. Pero otra buena forma de superar lo que ofrece la API de Tabla/SQL de forma prediseñada es agregar algunas capacidades adicionales en la forma de funciones definidas por el usuario (UDFs). Aquí, Flink SQL ofrece muchas opciones para la extensión.
Construyendo el Gráfico de Trabajo
Independientemente de qué API utilices, el propósito final del código que escribes es construir el gráfico de trabajo que ejecutará el runtime de Flink en tu nombre. Esto significa que estas API están organizadas alrededor de la creación de operadores y la especificación tanto de su comportamiento como de sus conexiones entre sí. Con la API DataStream, estás construyendo directamente el gráfico de trabajo, mientras que con la API Table/SQL, el planificador SQL de Flink se encarga de esto.
Serialización de Funciones y Datos
En última instancia, el código que proporcionas a Flink será ejecutado en paralelo por los trabajadores (los gestores de tareas) en un clúster de Flink. Para que esto ocurra, los objetos de función que creas son serializados y enviados a los gestores de tareas donde se ejecutan. Similarmente, los eventos en sí mismos a veces necesitarán ser serializados y enviados a través de la red de un gestor de tareas a otro. De nuevo, con la API Table/SQL no tienes que preocuparte por esto.
Gestión del Estado
El runtime de Flink necesita ser informado de cualquier estado que esperes que recupere en caso de falla. Para que esto funcione, Flink necesita información de tipo que use para serializar y deserializar estos objetos (para que puedan ser escritos en y leídos desde los puntos de control). Puedes configurar opcionalmente este estado administrado con descriptores de tiempo de vida que Flink utilizará automáticamente para expirar el estado una vez que ha superado su utilidad.
Con la API DataStream, generalmente acabas manejando directamente el estado que necesita tu aplicación (las operaciones integradas de ventana son la excepción a esto). Por otro lado, con la API de Tabla/SQL, esta preocupación es abstracta. Por ejemplo, dada una consulta como la siguiente, sabes que en algún lugar en el tiempo de ejecución de Flink debe mantenerse una estructura de datos que contenga un contador para cada URL, pero todos los detalles están cuidados por ti.
SELECT url, COUNT(*)
FROM pageviews
GROUP BY URL;Establecimiento y Disparo de Timers
Los timers tienen muchos usos en la procesamiento de flujos. Por ejemplo, es común que las aplicaciones de Flink necesiten reunir información de muchos orígenes de eventos diferentes antes de que finalmente se produzcan resultados. Los timers funcionan bien para casos en los que es lógico esperar (pero no indefinidamente) datos que puedan (o no) llegar finalmente.
Los timers también son esenciales para la implementación de operaciones de ventana basadas en tiempo. Tanto la API DataStream como la API de Tabla/SQL tienen soporte integrado para Windows y están creando y gestionando timers por ti.
Casos de Uso
Volviendo a las tres categorías amplias de casos de uso de flujo que se presentaron al comienzo de este artículo, veamos cómo se mapean a lo que acabas de aprender sobre Flink.
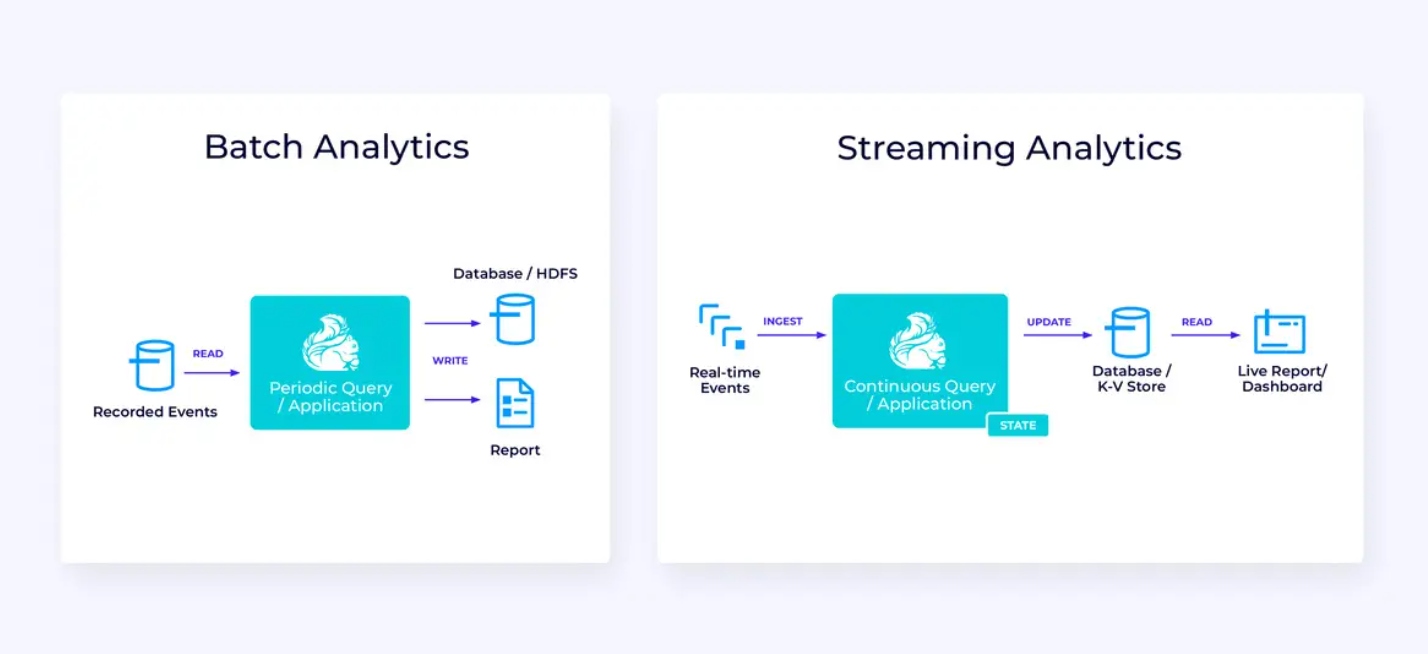
Pipeline de Datos en Flujo
Aquí a la izquierda, tenemos un ejemplo de un trabajo tradicional de ETL de extracción, transformación y carga periódico que lee de una base de datos transaccional, transforma los datos y escribe los resultados en otro almacén de datos, como una base de datos, sistema de archivos o lago de datos.
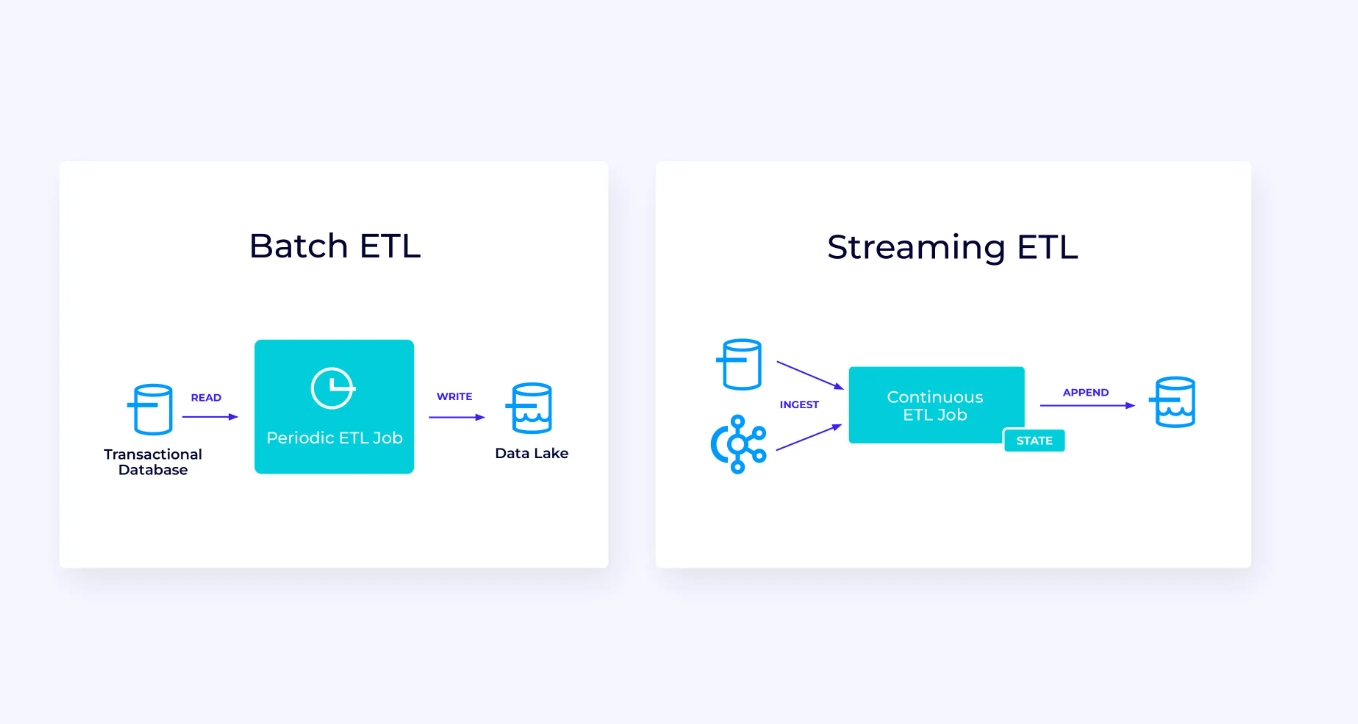
El pipeline de flujo correspondiente es superficialmente similar, pero hay diferencias significativas:
- El pipeline de streaming siempre está en ejecución.
- Los datos transaccionales se entreguen a la tubería de streaming en dos partes: una carga masiva inicial desde la base de datos, junto con una corriente de cambio de datos (CDC) que lleva las actualizaciones del origen de datos desde esa carga masiva.
- La versión en streaming produce nuevos resultados continuamente tan pronto están disponibles.
- El estado se gestiona explícitamente para que pueda recuperarse robustamente en caso de falla. Las tuberías de streaming ETL normalmente usan muy poco estado. Las fuentes de datos mantienen un seguimiento exacto de cuánto de la entrada ha sido procesado, normalmente en la forma de desplazamientos que cuentan registros desde el comienzo de las corrientes. Las tuberías utilizan transacciones para gestionar sus escrituras en sistemas externos, como bases de datos o Kafka. Durante el checkpointing, las fuentes registran sus desplazamientos, y las tuberías confirman las transacciones que llevan los resultados de haber leído exactamente hasta, pero no más allá, de esos desplazamientos de origen.
Para este caso de uso, la API de Tabla/SQL sería una buena opción.
Análisis en Tiempo Real
En comparación con la aplicación de streaming ETL, esta aplicación de análisis de streaming presenta un par de diferencias interesantes:
- De nuevo, Flink se utiliza para ejecutar una aplicación continua, pero para esta aplicación, Flink probablemente necesitará gestionar un estado sustancialmente mayor.
- Para este caso de uso, resulta lógico que la corriente que se procesa sea almacenada en un sistema de almacenamiento nativo de corrientes, como Apache Kafka.
- En lugar de producir periódicamente un informe estático, la versión en streaming puede usarse para dirigir un panel de datos en vivo.
Una vez más, la API de Tabla/SQL generalmente es una buena opción para este caso de uso.
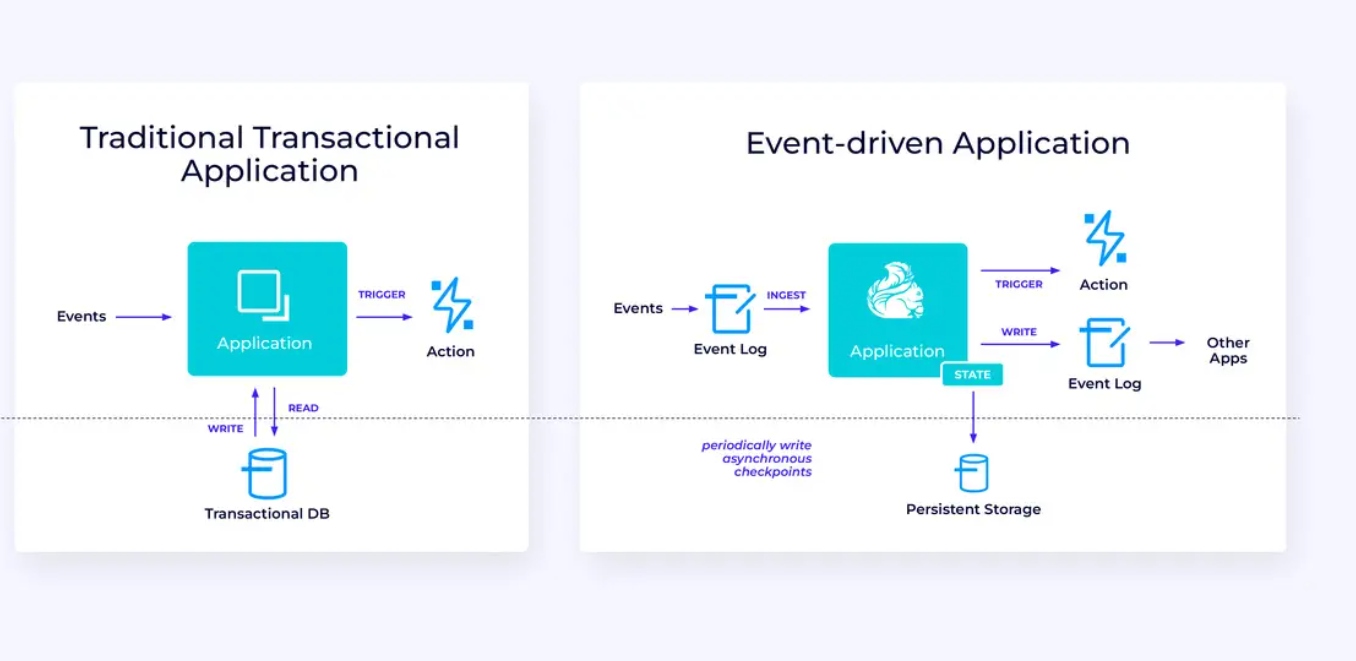
Aplicaciones Enfoque Evento
Nuestra tercera y última familia de casos de uso involucra la implementación de aplicaciones enfoque evento o microservicios. Hay mucho material escrito en otros lugares sobre este tema; este es un patrón de diseño arquitectónico que ofrece muchos beneficios.
Flink puede ser una gran opción para estas aplicaciones, especialmente si necesita el tipo de rendimiento que Flink puede proporcionar. En algunos casos, la API de Tabla/SQL tiene todo lo que necesita, pero en muchos casos, necesitará la flexibilidad adicional de la API DataStream al menos para parte del trabajo.
Primeros Pasos con Flink
Flink proporciona un potente framework para construir aplicaciones que procesan flujos de eventos. Como hemos cubierto, algunos de los conceptos pueden parecer novedosos al principio, pero una vez que esté familiarizado con la manera en que Flink está diseñado y funciona, el software es fácil de usar y las recompensas de conocer Flink son significativas.
Como siguiente paso, siga las instrucciones en la documentación de Flink, que le guiará a través del proceso de descarga, instalación y ejecución de la versión estable más reciente de Flink. Piensa en los casos de uso amplios que hemos discutido – pipelines de datos modernos, análisis en tiempo real y microservicios enfoque evento – y cómo estos pueden ayudar a abordar un reto o generar valor para su organización.
El streaming de datos es uno de los ámbitos más emocionantes de la tecnología empresarial actual, y el procesamiento en stream con Flink lo hace aún más potente. Aprender Flink será beneficioso no solo para su organización sino también para su carrera porque el procesamiento de datos en tiempo real se está haciendo más valioso para las empresas a nivel mundial. Así que echa un vistazo a Flink hoy y vea qué logros puede ayudar a alcanzar esta potente tecnología.
Source:
https://dzone.com/articles/apache-flink-101-a-guide-for-developers