













近年來,Apache Flink 已經确立了自己作為實時流處理的事實標準。流處理是一個系統建的 paradigm,將事件流(時間序列的事件)視為其最基本的建造塊。流處理器(如 Flink)消耗由事件源生成的輸入流,並產生由源(源存儲結果並供進一步處理使用)消耗的輸出流。
像 Amazon、Netflix 和 Uber 這樣的知名企業依賴 Flink 來驅動在其業務中心運行的大量數據管道,但 Flink 在許多有類似需求的較小公司中也扮演著关键角色。
Flink 用途何在?常見用例可分為這三個類別:
|
流的數據管道 |
實時分析 |
事件驱动應用 |
|---|---|---|
|
持續摄取、豐富和變換數據流,將它們載入目標系統以進行及時操作(與批次處理相比)。 |
持續產生和更新結果,這些結果在用戶消費實時數據流的同時顯示並傳送給用戶。 |
通過觸發計算、狀態更新或外部動作來認識模樣和對入站事件做出反應。 |
|
一些例子包括:
|
一些例子包括:
|
一些例子包括:
|
Flink 包括:
- 为全球企业所需的规模提供数据流工作负载的强健支持
- 强有力地保证了一次性正确性和故障恢复
- 支持 Java、Python 和 SQL,并统一支持批处理和流处理
- Flink 是 Apache Software Foundation 的一个成熟的开源项目,并且有一个非常活跃和支持性的社区。
Flink 有时被描述为复杂且难以学习。是的,Flink 的运行时实现是复杂的,但这并不令人惊讶,因为它解决了一些难题。Flink API 可能有些难以学习,但这更多是因为概念和组织原则不熟悉,而不是任何内在的复杂性。
Flink 或许與你以前所用過的任何東西都不同,但在很多方面,它實際上相当簡單。在一個時刻,隨著你對 Flink 的結構方式越來越熟悉,以及它Runtime 必須解決的問題,Flink 的 API 細節應該開始讓你覺得是幾個關鍵原則的明顯結果,而不是你应该記憶的一堆神秘的詳細信息。
這篇文章的目的是通過揭示其設計背后的核心原則,使 Flink 的學習旅程變得更加容易。
Flink 體現了幾個大的想法
流
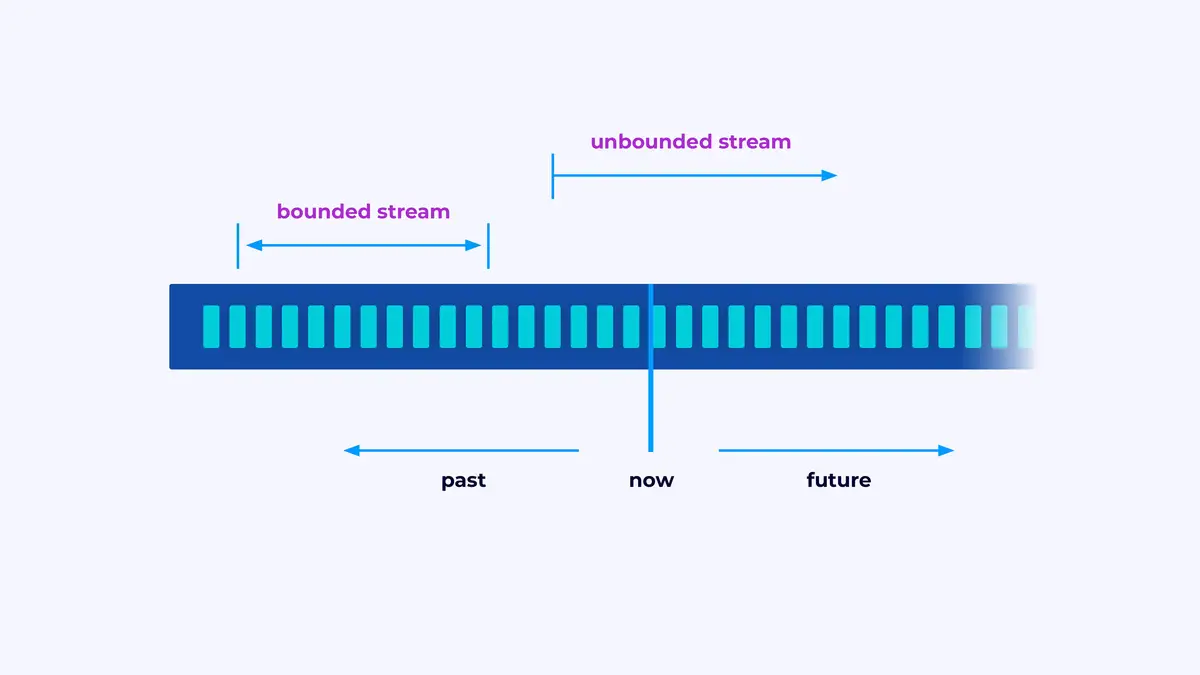
Flink 是一個用於建造處理事件流的應用程序的框架,其中一個流是一個有界或無界的的事件序列。
一個 Flink 應用程序是一個數據處理管線。你的事件流转過這個管線,並且在每個階段都是由你寫的代码進行操作。我們稱這個管線為作业圖(job graph),這個圖的節點(也就是說,處理管線的階段)稱為運算符。
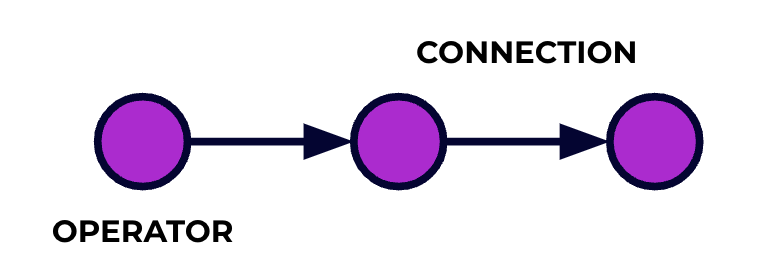
你使用 Flink 的 API 寫的代碼描述了作业圖,包括運算符的行為和它們的連接。
並行處理
每個運算符都可以有許多並行的實例,每個實例都在獨立地對事件的一部分進行操作。
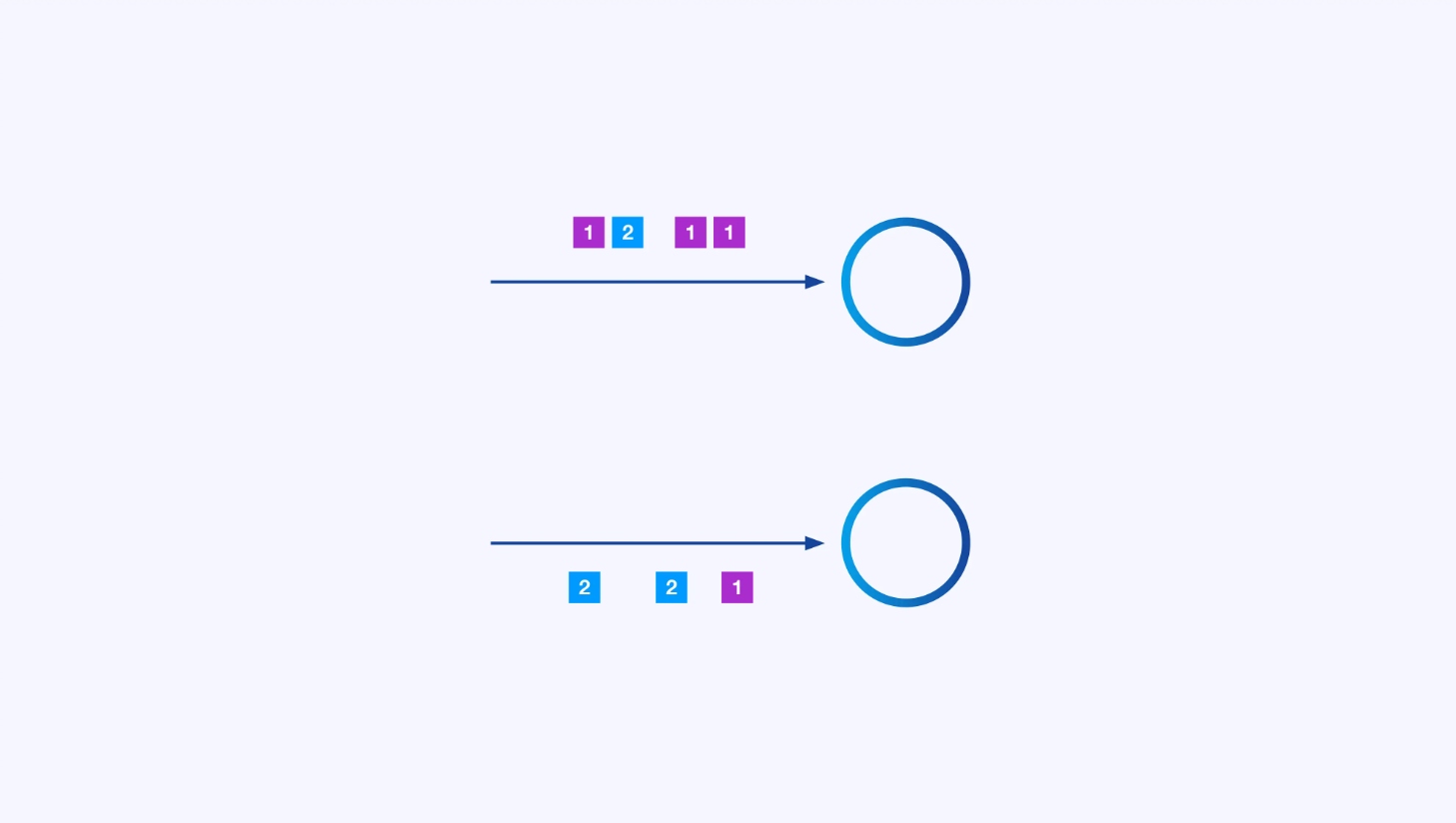
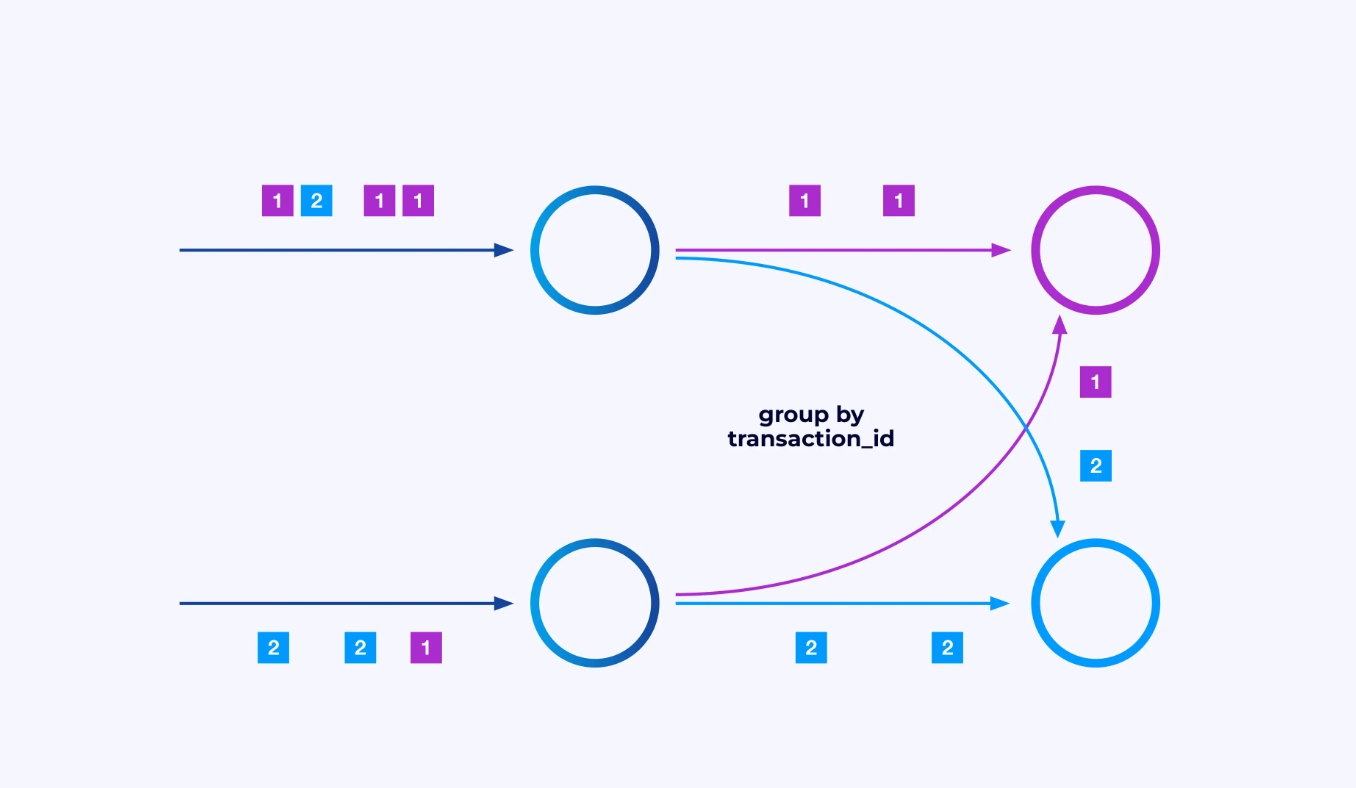
有时您會希望对这些子流施加特定的分区方案,以便根据某些特定于应用程序的逻辑将事件分组在一起。例如,如果您正在处理金融交易,您可能需要安排每个给定交易的所有事件由同一个线程处理。这允许您连接每个交易随时间发生的相关事件
在Flink SQL中,您会使用GROUP BY transaction_id进行此操作,而在DataStream API中,您会使用keyBy(event -> event.transaction_id)来指定此分组或分区。无论哪种情况,这都会在作业图中显示为一个完全连接的网络交换,连接图的两个连续阶段。
状态
在键分区流上工作的操作员可以使用Flink的分布式键/值状态存储来持久化他们想要保存的任何内容。对于每个键的状态仅限于特定操作员的实例,无法从其他地方访问。并行子结构之间毫无共享——这对于无限制的可伸缩性至关重要。
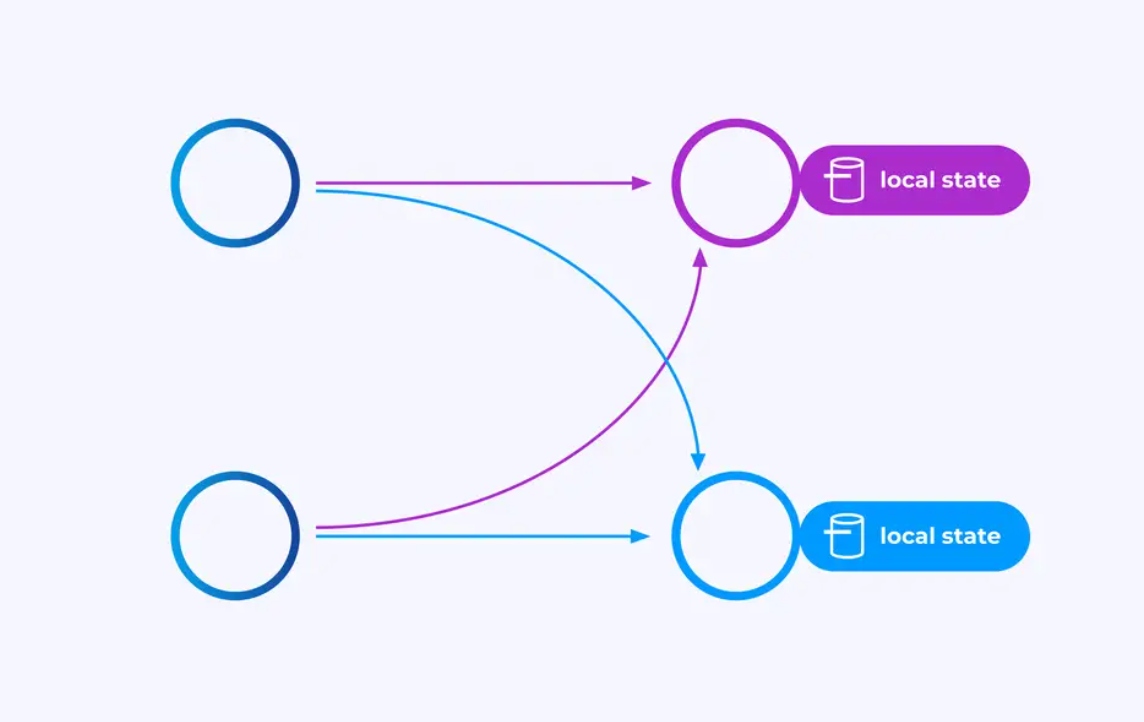
Flink作业可能会无限期地运行。如果Flink作业持续创建新的键(例如,交易ID)并为每个新键存储某些内容,那么该作业有爆炸的风险,因为它使用了无界的状态量。Flink的每个API都是围绕提供帮助您避免状态无限膨胀的方法进行组织的。
时间
避免過長保持狀態的一種方法是只在特定時間點保留它。例如,如果你想要對每1分鐘的交易進行計數,一旦每1分鐘過去了,該分鐘的結果就可以產生,那个計數器就可以釋放。
Flink 對兩個不同的時間概念做出了重要区分:
- 處理(或墙上時鐘)時間,它是從事件被處理的实际時間來 derivate 的
- 事件時間,它是基於每個事件記錄的 timestamps 來Based 的
為了说明它們之間的差異,考慮一下1分鐘長窗口何時算完成:
- 一個處理時間窗口在分鐘結束時完成。這是非常直觀的。
- 一個事件時間窗口在該分鐘所有事件都被處理後完成。這可能會有 trick 因為 Flink 還不能知道還沒有處理過的 events。我們能做最好的就是對一個 stream 可能有多少延遲做出假設,並將該假設 heuristically 應用。
故障恢復的 Checkpointing
失敗是不可避免的。儘管有失敗,Flink 仍然能夠提供近乎 exactly-once 的保證,意思是每個事件將恰好影響 Flink 正在管理的狀態一次,就像發生失敗一樣。它通過定期、全局、自一致地截取所有狀態的快照來實現這一目標。這些由 Flink automatically created and managed 的快照稱為 checkpoints。
復原過程涉及回退到最新檢查點捕捉的狀態,並從該檢查點global重启所有 operator。在復原過程中,一些事件會被重新處理,但 Flink 能夠通過確保每個檢查點是系統完整狀態的全球自洽快照來保證正確性。
系統結構
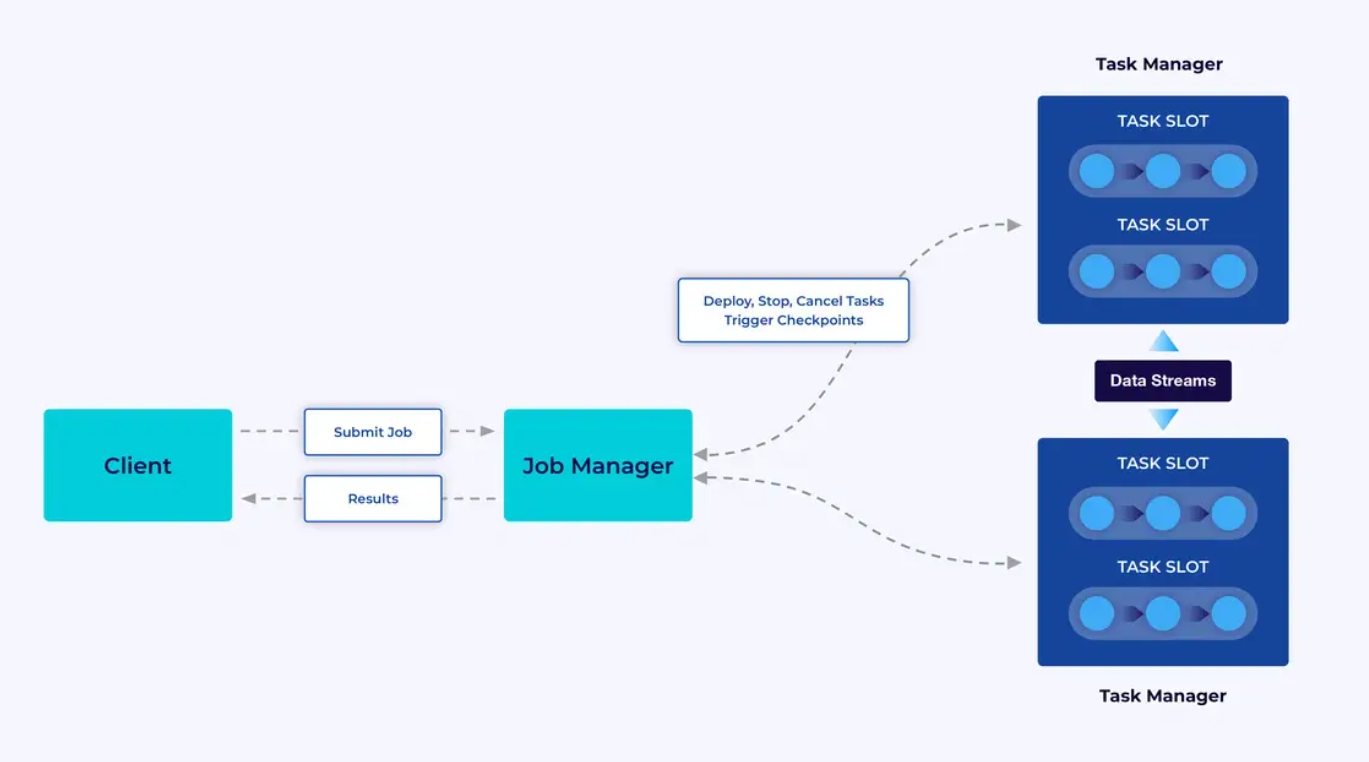
Flink 應用程序在 Flink 集群中運行,因此在將 Flink 應用程序投入生產之前,您需要一個集群來部署它。幸運的是,在開發和測試過程中,通過在 IntelliJ 或 Docker 這樣的集成開發環境(IDE)中本地下运行 Flink 是很容易開始的。
Flink 集群有两種類型的組件:Job Manager 和一組 Task Managers。 task managers 運行您的應用程序(並行),而 job manager 作為 task managers 和外部世界之間的网关。應用程序提交給 job manager,它管理 task managers 提供的資源,協調檢查點,並以指標的形式為集群提供可见性。
開發者體驗
作為 Flink 開發者,您的體驗在很大程度上取決於您選擇了哪種 API:較舊的低級 DataStream API 或較新的關係型 Table 和 SQL API。
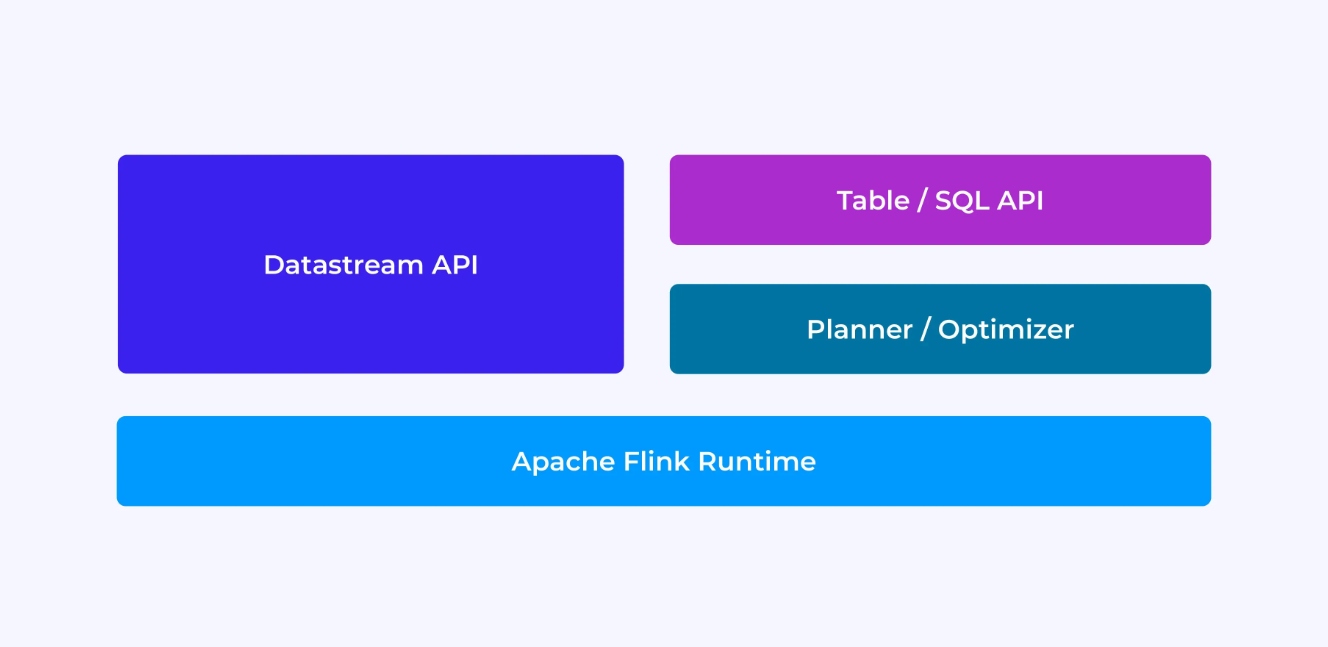
當你使用Flink的DataStream API進行編程時,你意識地思考Flink運行時序環境將如何运行你的應用程序。這意味著你逐個操作員地建立作业圖,描述所使用的狀態以及涉及的類型和它們的序列化,創建時鐘,並實現當這些時鐘被觸發时要執行的回調函數等。DataStream API的核心抽象化是事件,你寫的函數將一次處理一個事件,它們按到達順序進行。
另一方面,當你使用Flink的Table/SQL API時,這些低級關注點已為你处理好,你可以更直觀地關注你的業務邏輯。核心抽象化是表,你更多的是考慮將表結合以豐富數據,將行組合起來計算汇总分析等。內置的SQL查詢规划器和優化器處理細節。規劃器/優化器在管理資源方面表現出色,往往優於手寫代碼。
在進入詳細信息之前,还有一些其他想法:首先,你不必選擇DataStream或Table/SQL API – 這兩個API是互操作的,你可以將它們結合使用。這是一種可以在Table/SQL API中無法實現的自定义的好方法。但是,另一种在Table/SQL API提供的預置功能之外添加一些額外功能的好方法是通過使用用戶定義的函數(UDFs)。在這裡,Flink SQL為擴展提供了很多選項。
建立作业圖
無論使用哪個 API,您寫的代碼的最終目的都是構建 Flink 運行時將為您执行的作业圖。這意味著這些 API 是围绕創建操作員以及指定它們彼此的行為和連接组织的。使用 DataStream API 時,您正在直接構建作业圖,而使用 Table/SQL API 時,則由 Flink 的 SQL 計劃器來處理。
序列化函數和數據
最終,您供给 Flink 的代碼将由 Flink 集群中的工作者(任務管理器)並行执行。為了實現這一目標,您創建的函數物件被序列化並傳送至任務管理器,在哪裡它們被執行。同樣,事件本身有时需要被序列化並通過網絡從一個任務管理器傳送到另一個。再次地,使用 Table/SQL API 時您不需要考慮這件事。
管理狀態
Flink 運行時需要了解您期望它在 Failure 事件中恢复的任何状态。為此工作,Flink 需要可以使用來序列化和反序列化這些物件的類型信息(這樣它們可以被寫入並從檢查點中讀取)。您可以選擇性地配置這種受管制的狀態,使用 Flink 將使用來自動過期狀態的生命週期描述符。
資料流 API 支持下,您通常會直接管理應用程序所需的狀態(此例中,內建窗口操作是例外)。另一方面,對於 Table/SQL API,這種關注點已被抽象化。例如,對於下面的查詢,您知道在 Flink Runtime 中的某處,必須為每個 URL 保持一個計數器,但所有詳細信息都已為您处理好。
SELECT url, COUNT(*)
FROM pageviews
GROUP BY URL;設定和觸發計時器
計時器在資料流處理中有許多用途。例如,Flink 應用程序通常需要從許多不同的事件來源收集信息,然後最終產生結果。計時器對於那些有意义等待(但不是無窮無盡)可能(或可能不會)最終到來的數據的情況非常管用。
計時器對於實現基於時間的窗口操作也是必不可少。DataStream 和 Table/SQL API 都有內建支持 Windows,並為您創建和管理計時器。
應用案例
回到本文開頭介紹的三種广泛的資料流使用案例,讓我們看看它們如何映射到您剛剛學到的 Flink 知識。
資料流數據管線
在左圖中,有一個傳統的批次提取、轉换和載入(ETL)作业的例子,它定期從交易型数据库讀取數據,轉換數據,並將結果寫入另一個數據存儲,如数据库、文件系統或數據湖。
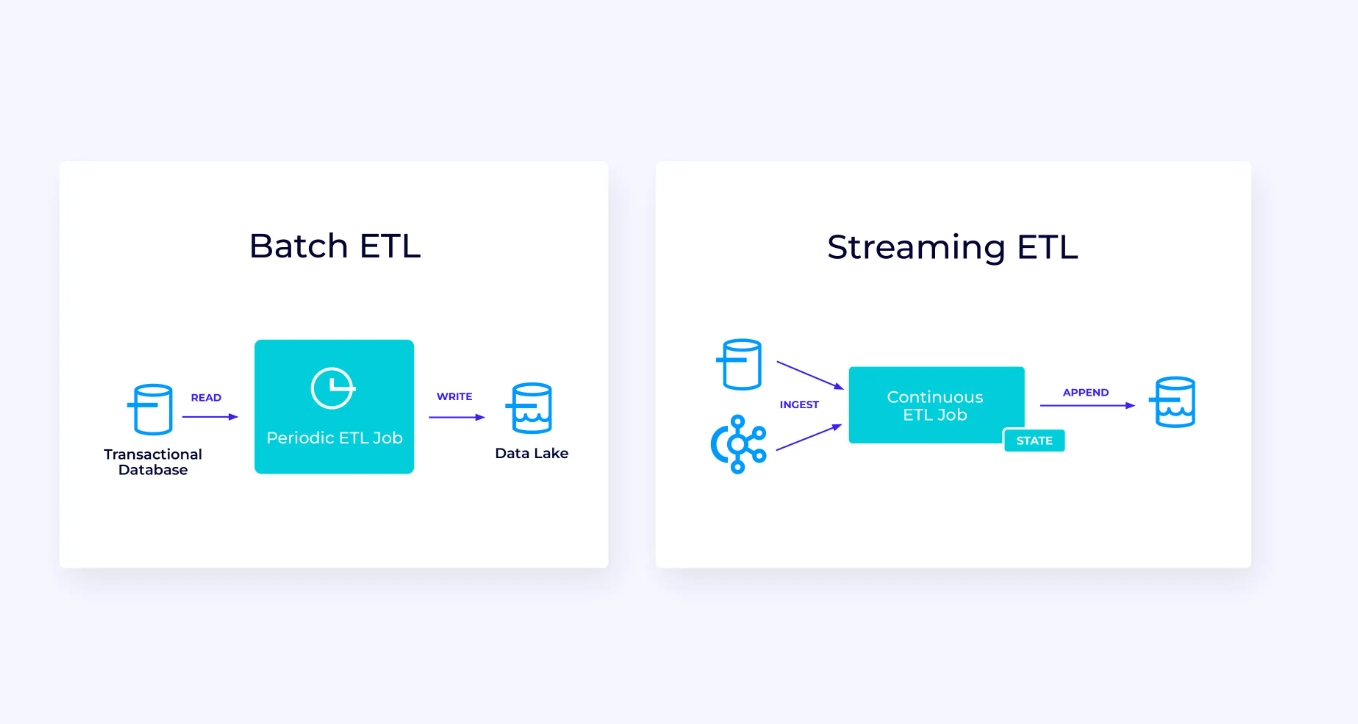
相應的 Streaming Pipeline 表面上類似,但有一些顯著差異:
- 串流處理管線持續運行中。
- 交易數據分兩部分送達串流處理管線:從數據庫 initially 進行一次大量載入,并结合 change data capture (CDC) 串流傳送自該大量載入以來數據庫的更新。
- 串流版本一旦數據可供即持續產生新結果。
- 狀態是明確管理的,以便在發生故障時能夠強健地恢復。串流 ETL 管線通常使用非常少的狀態。數據源會記錄正確已經處理的輸入量,通常以記錄偏移量的形式,自串流開始計算記錄。串流目的地使用事務來管理對如數據庫或 Kafka 之外部系統的寫入。在checkpointing時,源端記錄其偏移量,而目的地提交承载了剛好讀取至但不超过那些源端偏移量結果的事務。
對於此使用案例,Table/SQL API 會是一個好選擇。
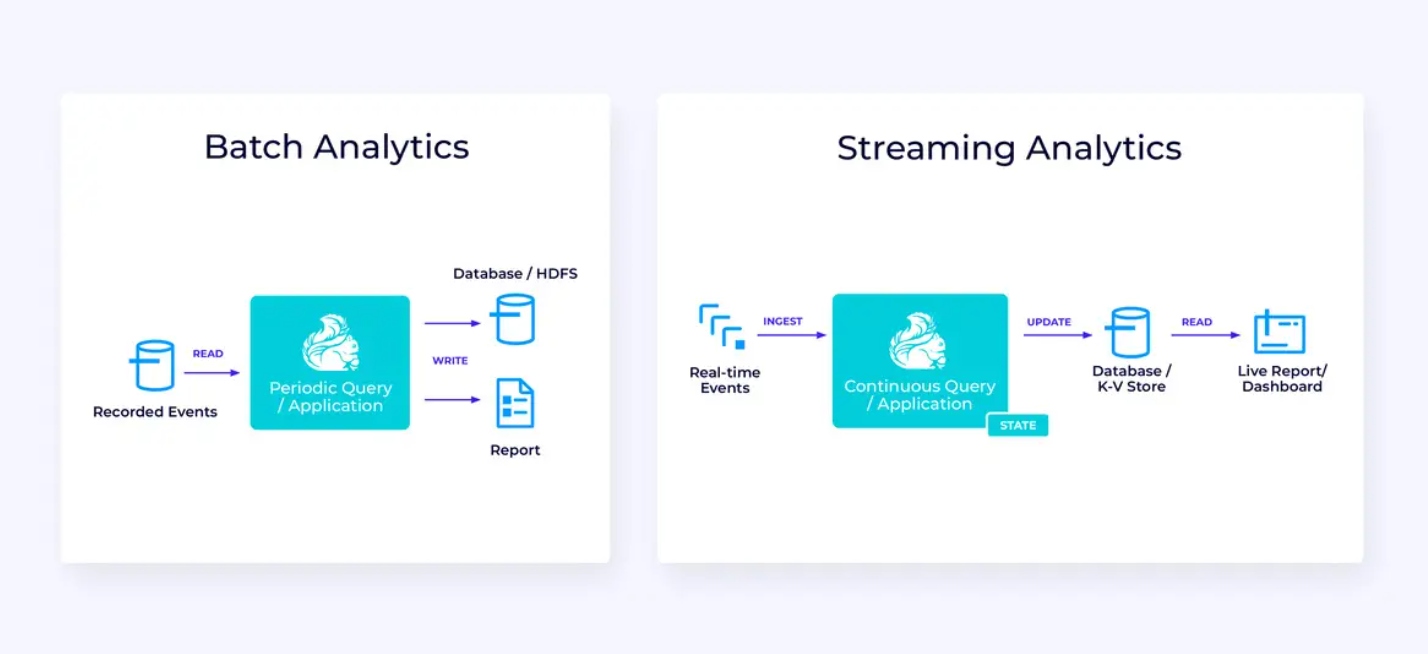
实时分析
與串流 ETL 應用相比,此串流分析應用有几个有趣的差異:
- 再次,Flink 用於運行持續應用,但對於此應用,Flink 可能需要管理更多的狀態。
- 對於此用途,讓串流中被吸入的數據存儲在如 Apache Kafka 的串流原生存儲系統中是有意义的。
- 代替定期的產生静态報告,串流版本可用來驅動现场仪表板。
再次,表/SQL API通常是为這種使用案例提供一个好的选择。
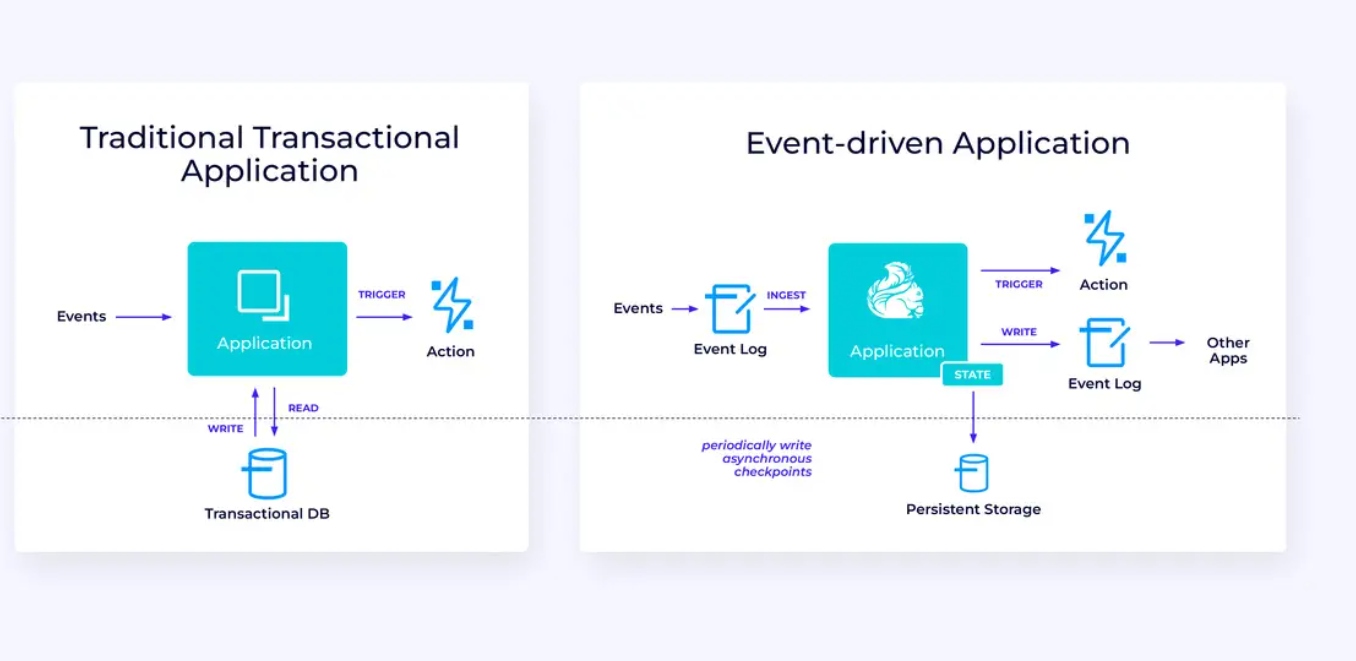
事件驱动應用程序
我們第三個也是最後一個使用案例族涉及事件驱动應用程序或微服務的實現。這方面的內容在其他地方已有許多论述;這是一種建築設計模式,具有很多好处。
Flink 對於這些應用程序來說可能是一個非常好的選擇,特別是如果您需要 Flink 能夠提供的這種性能。在某些情況下,表/SQL API 已有您所需的一切,但在許多情況下,您可能需要 DataStream API 的額外靈活性來完成至少一部分工作。
開始使用 Flink
Flink 提供了建造處理事件流的應用程序的强大框架。正如我們所覆盖的,一些概念最初可能會讓人感到陌生,但一旦您熟悉了 Flink 的設計和使用方式,這個軟件就容易使用得多,而且精通 Flink 的獎勵是顯著的。
作為下一個步驟,請遵循 Flink 文档中的指示,這將引导您通過下載、安裝和運行 Flink 最新穩定版本的過程。考慮我們討論的廣泛使用案例 — 現代數據管道、實時分析以及事件驅動的微服務 — 以及這些如何幫助解決您組織面臨的挑戰或創造價值。
數據流的處理是目前企業技術中最令人激動的領域之一,透過Flink進行流的處理更增加了其威力。學習Flink不僅對你的組織有益,对你的職業生涯也很有幫助,因為實時數據處理對全球企業來說變得更加有價值。所以今天就檢查一下Flink,看看這個強大的技術能幫助你達到什麼目標。
Source:
https://dzone.com/articles/apache-flink-101-a-guide-for-developers