













בשנים האחרונות, Apache Flink ביססה את עצמה כסטנדרט דה פקטו לעיבוד זרמי נתונים בזמן אמת. עיבוד זרמי נתונים הוא פרדיגמה לבניית מערכות שמתייחסת לזרמי אירועים (רצפי אירועים בזמן) כמרכיב המרכזי שלה. מעבד זרמים, כמו Flink, צורך זרמי קלט המיוצרים על ידי מקורות אירועים ומייצר זרמי פלט הנצרכים על ידי sinks (ה-sinks מאחסנים תוצאות ומעמידים אותן לרשות עיבוד נוסף).
מותגים ידועים כמו Amazon, Netflix, ו-Uber מסתמכים על Flink כדי להניע את צינורות הנתונים הפועלים בקנה מידה עצום בלב העסקים שלהם, אך Flink גם משחקת תפקיד מרכזי בחברות קטנות יותר עם דרישות דומות ליכולת להגיב במהירות לאירועים עסקיים קריטיים.
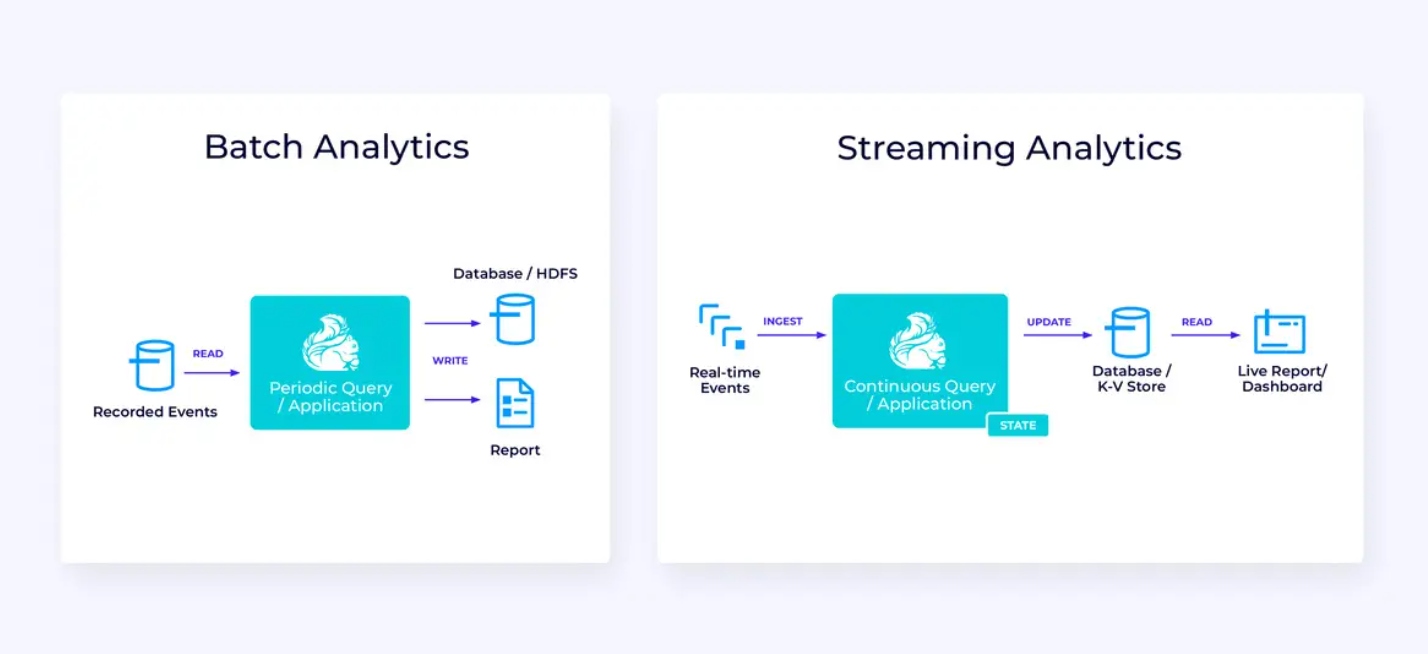
למה משמשת Flink? מקרי השימוש הנפוצים נופלים בשלוש קטגוריות אלו:
|
צינורות נתונים זורמים |
אנליטיקה בזמן אמת |
יישומים מונעי אירועים |
|---|---|---|
|
צריכת נתונים רציפה, העשרה, והמרה של זרמי נתונים, וטעינתם למערכות יעד לפעולה במועד המתאים (בניגוד לעיבוד אצווה). |
ייצור ועדכון רציף של תוצאות שמוצגות ונמסרות למשתמשים כאשר זרמי נתונים בזמן אמת נצרכים. |
זיהוי דפוסים ותגובה לאירועים נכנסים באמצעות הפעלת חישובים, עדכוני מצב, או פעולות חיצוניות. |
|
כמה דוגמאות כוללות:
|
קטעים מסוגה הם:
|
קטעים מסוגה הם:
|
Flink כולל:
- תמיכה עמידה בעבודות זרימת נתונים בקנה מידה שדרש על ידי חברות עסקיות גלובליות
- הגבהה חזקה של נכונות בדיוק-פעם ושיקום כשלון
- תמיכה עבור Java, Python וSQL, עם תמיכה מאחדת גם לעיבוד מקבץ וגם לעיבוד זרימה
- Flink הוא פרוייקט פתוח-מקורי בוגר מהקרן Apache Software Foundation ויש לו קהילה מאד פעילה ומסייעת.
לפעמים הם מתארים Flink כמובן וקשה ללמוד. כן, המימוש של הרצאת Flink הוא מורכב, אך זה לא מפתיע, בגלל שהוא פותר בעיות קשות. הAPI של Flink יכול להיות קצת מאתגר
Flink עשוי להיות שונה מכל דבר שהשתמשתם בו קודם, אך בהרבה מובנים, הוא למעשה די פשוט. בנקודה מסויימת, כשנעבור להתמחות יותר בדרך בה מורכב פלינק, ובבעיות שהתהליך הרנטימי שלו צריך להתמודד איתן, פרטי פלינק עלולים להיות לך ההשלכות הברורות של כמה עקרונות עיקריים, במקום אוסף של פרטים מסוימים שצריך לזכור.
המאמר הזה מטרה להקל במסע הלמידה של פלינק על ידי הצגת העקרונות המרכזיים שמורכבים בעיקרון העיצוב שלו.
פלינק מייצג כמה רעיונות גדולים
זרמים
פלינק הוא רשת לבניית יישומים שמעבדים זרמי אירועים, בהם זרם הוא רצף מוגבל או לא מוגבל של אירועים.
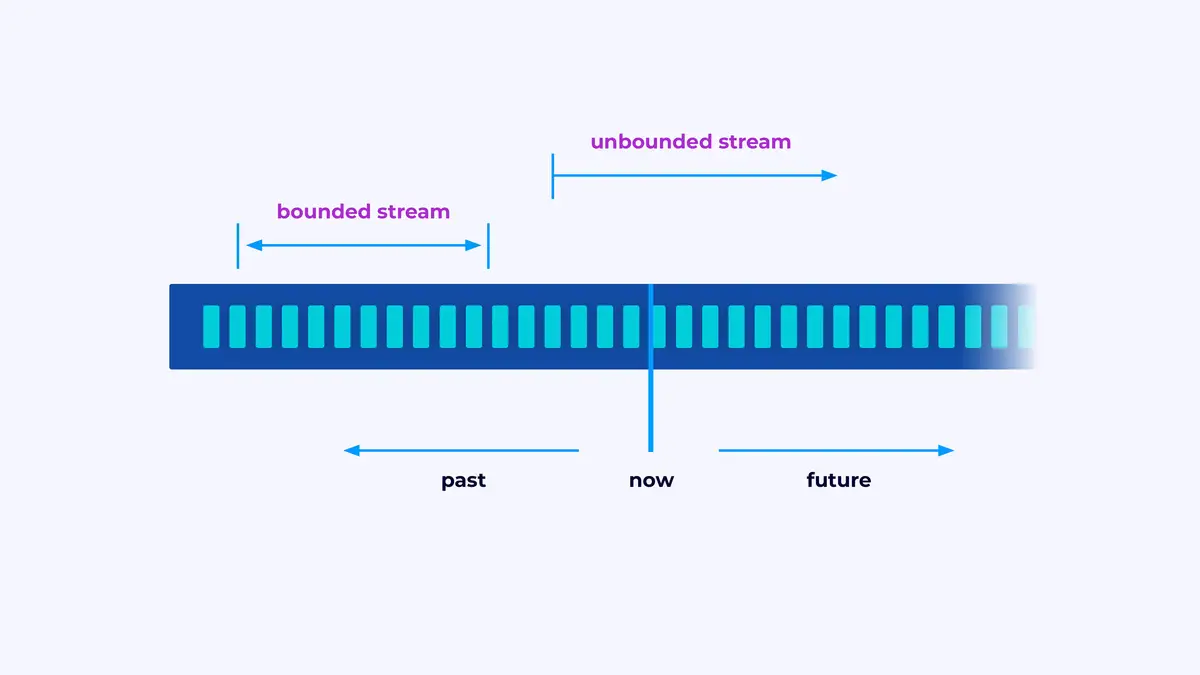
יישום פלינק הוא ציוד עיבוד מידע. האירועים שלך נוזרים דרך הציוד הזה ומעבדים בכל שלב על-ידי הקוד שכתבתם. אנו קוראים לציוד הזה גרף העבודה, ולנקודות בגרף הזה (או במילים אחרות, לשלבים במעבדת העיבוד) אנו קוראים להם מפעלים.
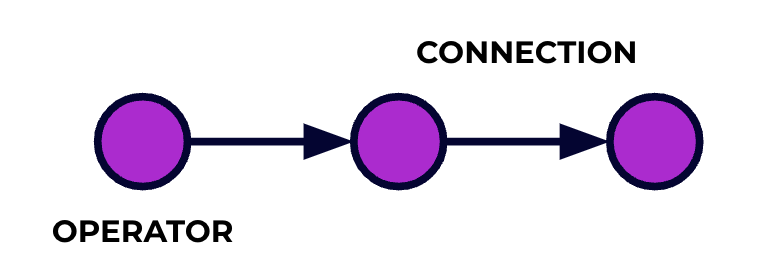
הקוד שכתבתם בעזרת אחד מה API של פלינק תואר את הגרף העבודה, כולל את ההתנהגות של המפעלים והחיבורים ביניהם.
עיבוד מקבילים
כל מפעל יכול להיות בעל מספר מיקומים מקבילים, כל אחד מהם פועל בעצמו על חלק מסויי
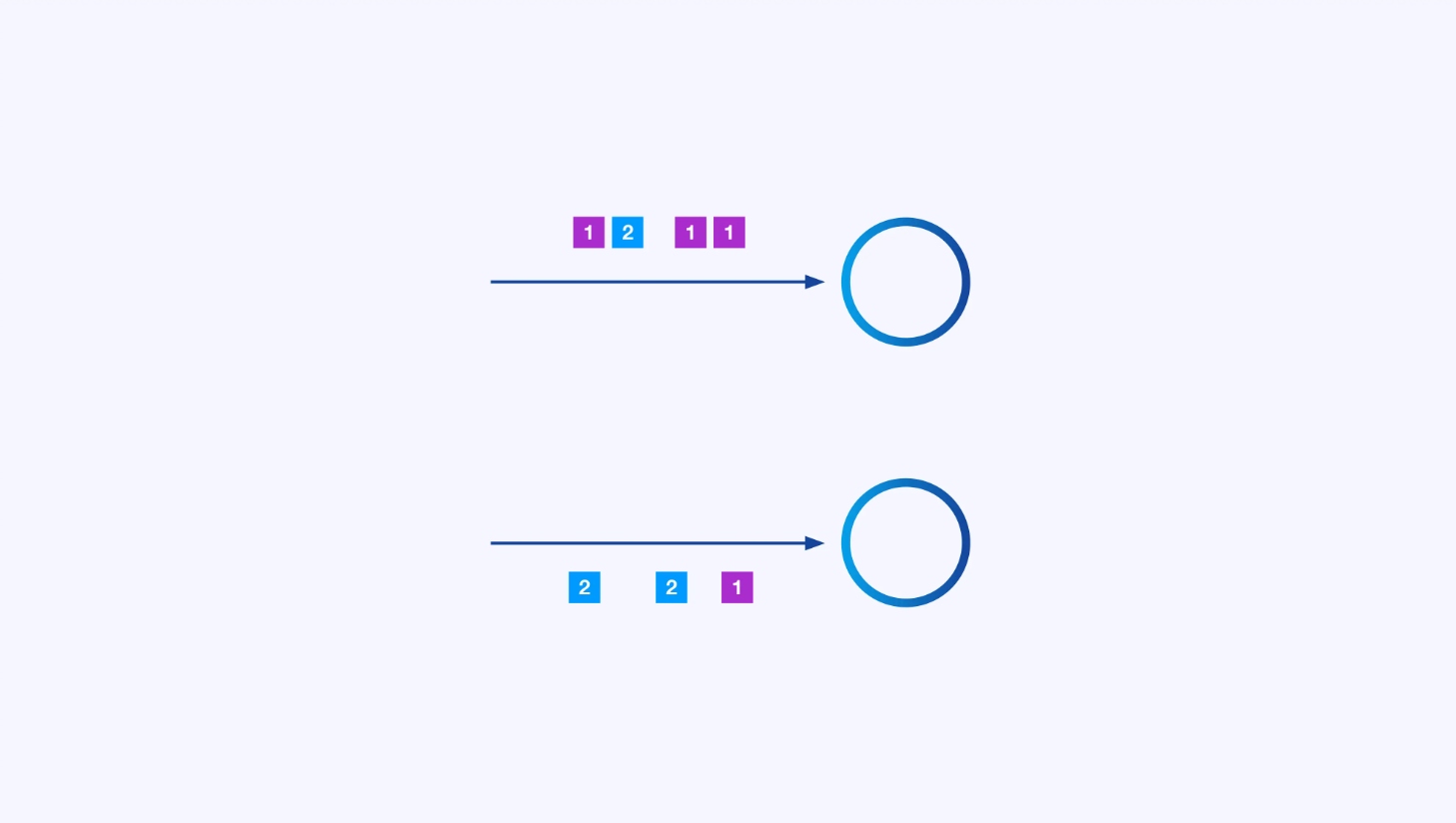
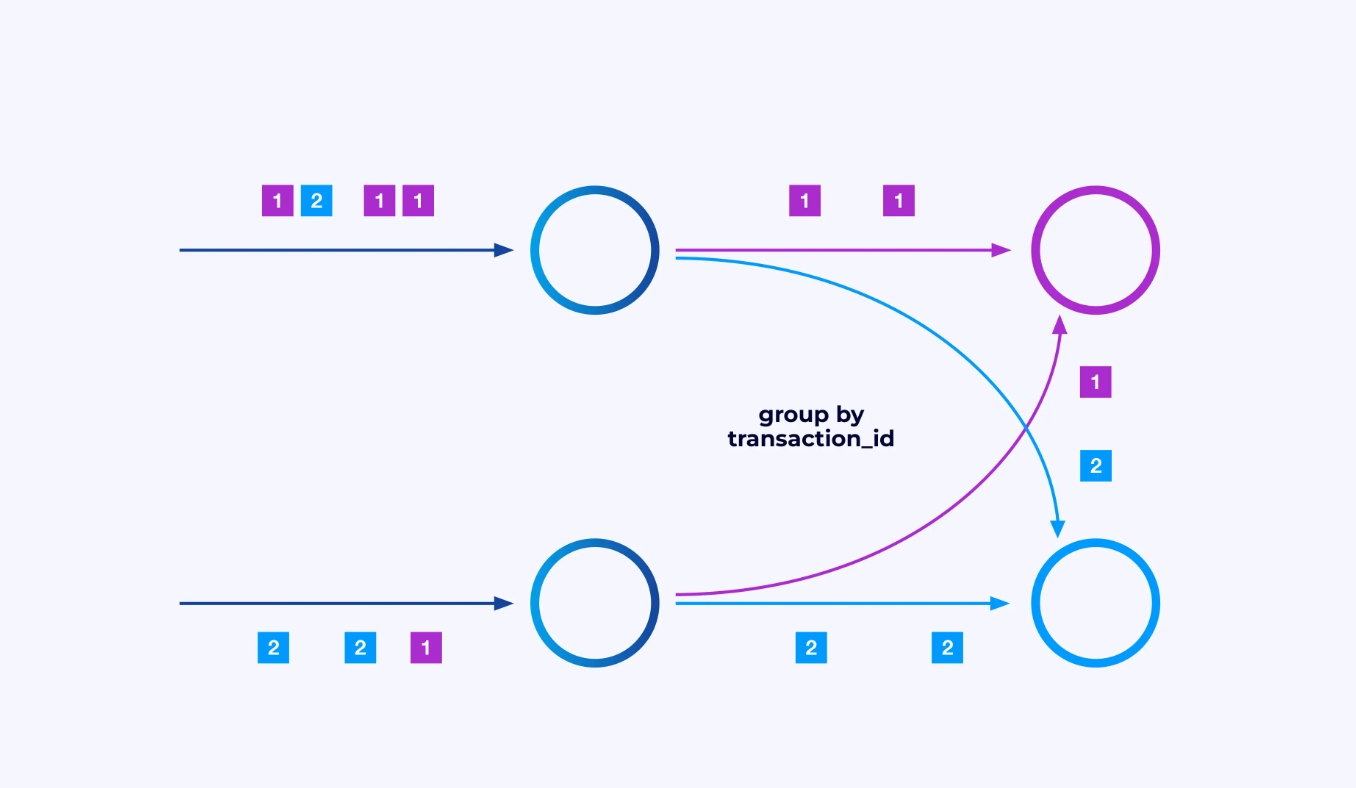
לפעמים תרצה להכפיח תכנית מחלוקת ספציפית על הזרמים המשניים הללו כדי שהאירועים יקבצו יחד לפי לוגיקה ייחודית ליישום. לדוגמה, אם אתה מעבד עיסקאות פיננסיות, עליך ייתכן שתארגן שכל אירוע לכל עיסקה נעבד על ידי אותו נפרד. זה יאפשר לך לחבר ביחד את האירועים השונים שמתרחשים לאורך זמן עבור כל עיסקה
ב-Flink SQL, תעשה זאת עם GROUP BY transaction_id, בעוד ב-DataStream API תשתמש ב-keyBy(event -> event.transaction_id) כדי לציין את הקבוצה או המחלוקה הזו. בשני המקרים, זה יופיע בגרף העבודה כרשת סידור מוחלטת בין שני שלבים רצופים בגרף.
State
מפעילים העובדים על זרמים מחולקים למפתח יכולים להשתמש באחסן המפתח/ערך המבוזר של Flink כדי לשמור ברציפות מה שתרצה. המצב עבור כל מפתח הוא מקומי למושלם של מפעיל, ולא ניתן לגשת אליו ממקום אחר. הסבך המפרוללים משתפים כלום — זה חיוני לקיימות מלאה.
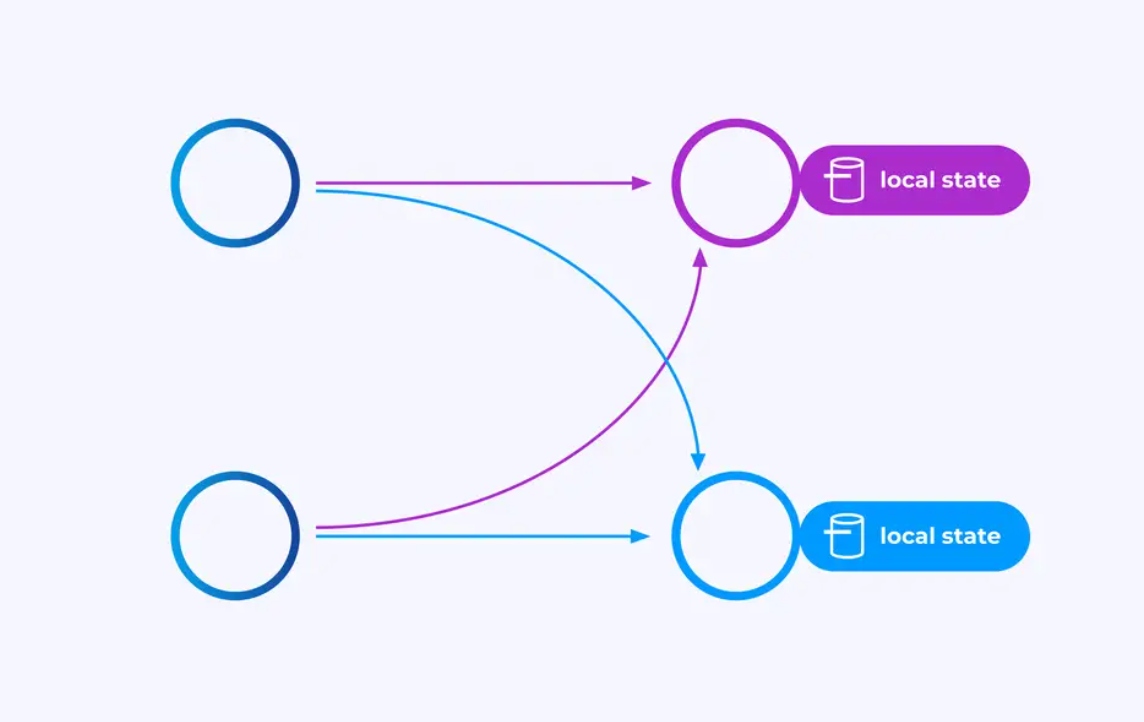
עבודת Flink עשויה להישאר בריצה לתמיד. אם עבודת Flink ממשיכה ליצור מפתחות חדשים (לדוגמה, מספרי עיסקאות) ולשמור משהו עבור כל מפתח חדש, העבודה עלולה להתפוצצת בגלל שהיא משתמשת בכמות גדולה של מצב. כל אחד מה-APIים של Flink מאורגן סביב הספקת דרכים לעזור לך להימנע מהתפוצצות נסיביות של מצב.
Time
דרך אחת להימנע מלהחזיק ממשק במשך זמן רב יותר מדי היא לשמר אותו רק עד לנקודה ספציפית בזמן. לדוגמה, אם תרצו לספור עיסקאות בחלונות של דקה אחת, אחרי שהדקה מסתיימת, ניתן לייצר את התוצאה עבור הדקה הזו, ואז נשחרר את הספור.
Flink מבדיך בין שתי מושגים שונים של זמן:
- זמן עיבוד (או שעון קיר), שמקורו בזמן האמתי בו אירוע מתעבד
- זמן אירוע, שמבוסס על תגיות זמן שנערכו ביחד עם כל אירוע
כדי להדגים את ההבדל בינהם, תחשבו מה זה אומר לגבי חלון דקה אחת שהוא מושלם:
- חלון זמן עיבוד הוא מושלם כשהדקה מסתיימת. זה די ברור.
- חלון זמן אירוע הוא מושלם כשכל האירועים שהתרחשו בתוך הדקה הזו נעבדו. זה יכול להיות מסובך מפני שFlink לא יכול לדעת על אירועים שעדיין לא נעבדו. הטובה היחידה שאנחנו יכולים לעשות היא להעריך את העוולת של הזרם וליישם את ההערכה ההיא היותרית.
איוון לשיקום אחר כשלון
כשלון הם בלתי-נמנעים. למרות הכשלון, Flink מספק הבטחה של 'בדיוק פעמיים' באופן מועיל, אז כל אירוע ישפיע על הממשק של Flink בדיוק פעמיים, כאילו הכשלון מעולם לא התרחש. הוא עושה זאת על-ידי לוקח סנא
השיקום מכיל שיבת המצב למצב האחרון שנאחד בנקודת הבדיקה האחרונה וביצוע מתחדשות גלובלית של כל אופרטורים מהנקודה הזאת. בזמן השיקום, חלק מהאירועים מושנים מחדש, אך Flink מסוגל לאשר את הנכונות על ידי בטחת שכל נקודת הבדיקה היא תמונה גלובלית וסלביסטית של המצב המלא של המערכת.
ארכיטקטורת המערכת
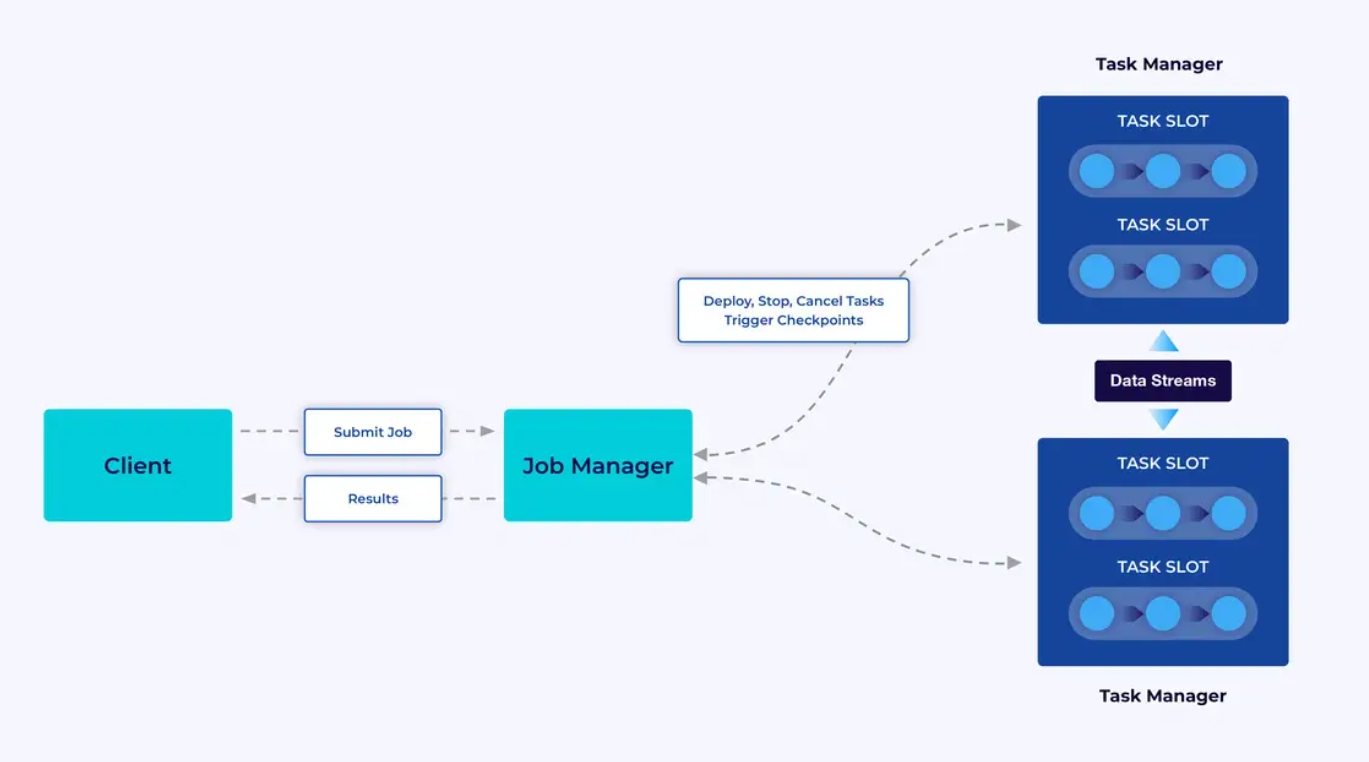
אייפוייסטים Flink מתפקדים במערך Flink, אז לפני שאפשר לשים אייפוייסט Flink בתפקוד, תצטרכו לקיים מערך להשתמש בו. למרבה המזל, בזמן הפיתוח והבדיקות קל להתחיל על ידי הפעלת Flink מקומית בסביבת הפיתוח המקומית (IDE) כמו IntelliJ או Docker.
למערך Flink ישני סוגי רכיבים: מנהל העבודה וקבוצת מנהלי המשימות. המנהלים מנהלים את היישומך (בפעולה מורחבת), בעוד שמנהל העבודה פועל כמוף בין המנהלים לחוץ. יישומים מועברים למנהל העבודה, שמנהל את המשאבים שמסוגלים על ידי המנהלים, מתאהב את הניהול של הנקודות הבדיקה, ומספק את הראיות בצורה מוגבלת במערך באופן של מדדים.
החוויה של הפיתוחן
החוויה של פיתוחן Flink תלויה במידה מסויימת באיזה אפי הם מבחרים: באפי השונה הישן והבסיסי DataStream או באפי החדש והקשור בטאבלים וSQL APIs.
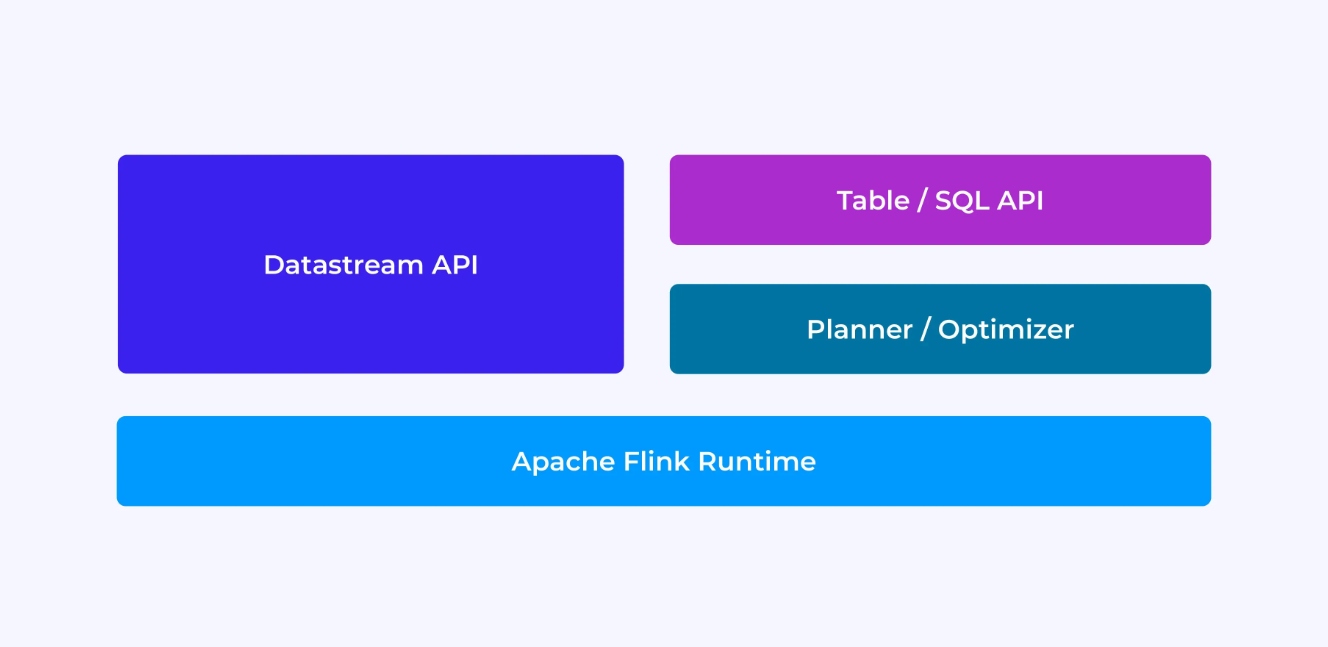
כשאתה מתכנת עם ה-DataStream API של Flink, אתה מודע למה שמנוע הריצה של Flink יעשה כשהוא מריץ את האפליקציה שלך. זה אומר שאתה בונה את גרף העבודה מפעיל אחד בכל פעם, מתאר את המצב שאתה משתמש בו יחד עם סוגי הנתונים המעורבים והסיריאליזציה שלהם, יוצר טיימרים, ומממש פונקציות callback שיבוצעו כשהטיימרים מופעלים, ועוד. ההפשטה המרכזית ב-DataStream API היא האירוע, והפונקציות שאתה כותב יטפלו באירוע אחד בכל פעם, כשהם מגיעים.
מצד שני, כשאתה משתמש ב-Table/SQL API של Flink, הדאגות ברמה הנמוכה האלה מטופלות עבורך, ואתה יכול להתמקד בצורה ישירה יותר בלוגיקה העסקית שלך. ההפשטה המרכזית היא הטבלה, ואתה חושב יותר במונחים של חיבור טבלאות להעשרה, קיבוץ שורות יחד לחישוב אנליטיקות מצטברות וכו'. מתכנן ומבצע אופטימיזציה מובנה של שאילתות SQL דואג לפרטים. המתכנן/מבצע אופטימיזציה עושה עבודה מצוינת בניהול משאבים בצורה יעילה, ולעיתים קרובות עולה בביצועיו על קוד שנכתב ידנית.
עוד כמה מחשבות לפני שנצלול לפרטים: ראשית, אינך חייב לבחור בין ה-DataStream או ה-Table/SQL API – שני ה-API ניתנים לשילוב, ואתה יכול לשלב ביניהם. זו יכולה להיות דרך טובה ללכת אם אתה זקוק לקצת התאמה אישית שלא מתאפשרת ב-Table/SQL API. אבל דרך טובה נוספת לעבור מעבר למה ש-Table/SQL API מציע כברירת מחדל היא להוסיף יכולות נוספות בצורה של פונקציות שהוגדרו על ידי המשתמש (UDFs). כאן, Flink SQL מציע הרבה אפשרויות להרחבה.
בניית גרף העבודה
ובכל מקרה, המטרה הסופית של הקוד שאתה כותב היא לבנות את הגרף העבודה שהריצוף של Flink יבצע בשם שלך. זה אומר שהAPI האלה מארגנים סביב בניית מפעילים והגדרת התנהגותם והקישורים ביניהם. בעזרת API DataStream, אתה בונה ישורת העבודה המייצגת באופן ישיר, בעוד שבעזרת API Table/SQL, מעצב הSQL של Flink מתחבר לעבודה.
מימוץ פונקציות ומידע
בסוף היום, הקוד שאתה מספק לFlink ייבצע בפרלקל על ידי העובדים (המנהלים המשימות) במערכת קלט Flink. כדי לגרום לזה לקרות, האובייקטים של הפונקציות שאתה יוצר מסרילים ושולחים למנהלים המשימות בהם הם מבצעים. באופן דומה, האירועים עצמם לפעמים צריכים להימוץ ולהישדר דרך הרשת מאחד מנהלים המשימות לשני. שוב, בעזרת API Table/SQL אתה לא צריך לחשוב על זה.
ניהול מצב
הריצוף Flink צריך להיות מודע למצב שאתה מצפה שישקם אותו במקרה של כשל. כדי לגרום לזה לעבוד, Flink צריך מידע סוגי שימושי בכדי לסרילות ולהדביקה של האובייקטים האלה (כך שהם יכולים להיכנס לתשומות ולהיקבע) אתה יכול באפשרותך להגדיר את המצב הניהולי הזה עם תווים חיים של זמן שFlink ישתמש בהם להסתגל באופן אוטומטי להסתדר בעולם.
עם ה-DataStream API, אתה בדרך כלל נדרש לנהל ישירות את המצב שהאפליקציה שלך צריכה (הפעולות המובנות על חלונות הן החריגה היחידה לכך). מצד שני, עם ה-Table/SQL API, הדאגה הזו מופשטת ממך. לדוגמה, אם יש לך שאילתה כמו זו שלמטה, אתה יודע שבמקום כלשהו במנוע הריצה של Flink חייבת להתקיים מבנה נתונים ששומר על מונה עבור כל URL, אבל הפרטים מטופלים כולם עבורך.
SELECT url, COUNT(*)
FROM pageviews
GROUP BY URL;הגדרת והפעלת טיימרים
לטיימרים יש שימושים רבים בעיבוד זרמים. לדוגמה, נפוץ שאפליקציות Flink צריכות לאסוף מידע ממקורות אירועים רבים ושונים לפני שהן מייצרות תוצאות בסופו של דבר. טיימרים עובדים היטב במקרים שבהם הגיוני לחכות (אבל לא לנצח) לנתונים שעשויים (או לא עשויים) להגיע בסופו של דבר.
טיימרים גם חיוניים לביצוע פעולות חלונות מבוססות זמן. גם ל-DataStream וגם ל-Table/SQL API יש תמיכה מובנית בחלונות והם יוצרים ומנהלים טיימרים מטעמך.
מקרי שימוש
נחזור לשלוש הקטגוריות הרחבות של מקרי שימוש בזרמים שהוצגו בתחילת המאמר, ונראה איך הן מתאימות למה שלמדת עד עכשיו על Flink.
צינור נתונים זורם
למטה, משמאל, יש דוגמה לעבודה מסורתית של חילוץ, שינוי וטעינה (ETL) שמדי פעם קוראת ממסד נתונים טרנזקציוני, משנה את הנתונים וכותבת את התוצאות למסד נתונים אחר, מערכת קבצים או אגם נתונים.
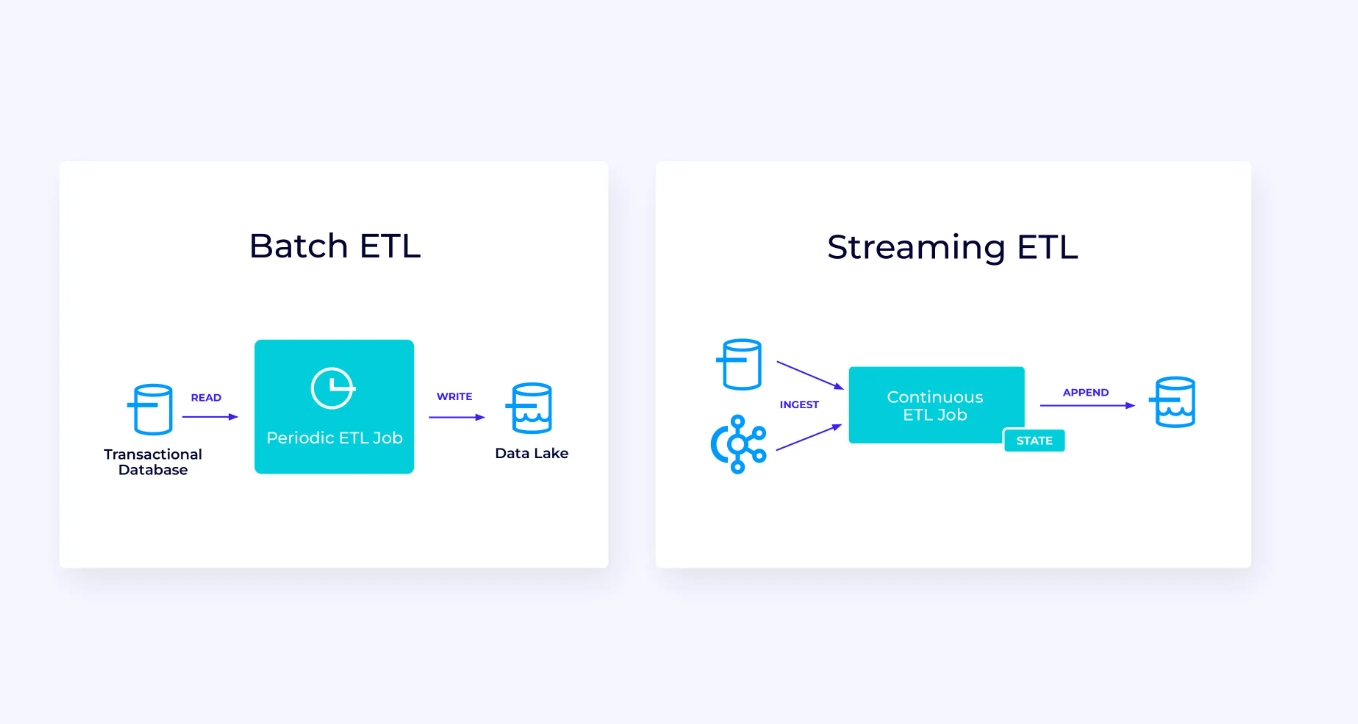
צינור הזרימה המקביל דומה למראית עין, אך יש לו כמה הבדלים משמעותיים:
- צינור הזרימה פועל תמיד.
- הנתונים הטרנזקציוניים מועברים לצינור הזרימה בשני חלקים: טעינה ראשונית בכמות גדולה ממסד הנתונים, בשילוב עם זרם של לכידת נתוני שינויים (CDC) שנושא את העדכונים למסד הנתונים מאז הטעינה הראשונית הזו.
- הגרסה הזורמת מייצרת באופן רציף תוצאות חדשות ברגע שהן זמינות.
- המצב מנוהל בצורה מפורשת כך שניתן לשחזר אותו בצורה חזקה במקרה של כשל. צינורות ETL זורמים משתמשים בדרך כלל במעט מאוד מצב. מקורות הנתונים עוקבים במדויק אחר כמה מהקלט נבלע, בדרך כלל בצורה של אופסטים שסופרים רשומות מתחילת הזרמים. ה-sinks משתמשים בטרנזקציות כדי לנהל את הכתיבות שלהם למערכות חיצוניות, כמו מסדי נתונים או Kafka. במהלך ביצוע נקודות ביקורת, המקורות מקליטים את האופסטים שלהם, וה-sinks מתחייבים לטרנזקציות שנושאות את התוצאות של קריאה בדיוק עד לאותם אופסטים של המקורות, אך לא מעבר לכך.
למקרה שימוש זה, API של Table/SQL יהיה בחירה טובה.
ניתוח בזמן אמת
בהשוואה לאפליקציית ה-ETL הזורמת, לאפליקציית הניתוח הזורמת הזו יש כמה הבדלים מעניינים:
- פעם נוספת, Flink משמש להפעלת אפליקציה רציפה, אך עבור אפליקציה זו, Flink כנראה יצטרך לנהל מצב רב יותר באופן משמעותי.
- למקרה שימוש זה, הגיוני שהזרם הנקלט יאוחסן במערכת אחסון ייעודית לזרמים, כגון Apache Kafka.
- במקום לייצר דוח סטטי באופן תקופתי, הגרסה הזורמת יכולה לשמש להפעלת לוח מחוונים חי.
שוב, ה API לשולחן או SQL הוא בד "" כ בחירה טובה לשימוש במקרה זה.
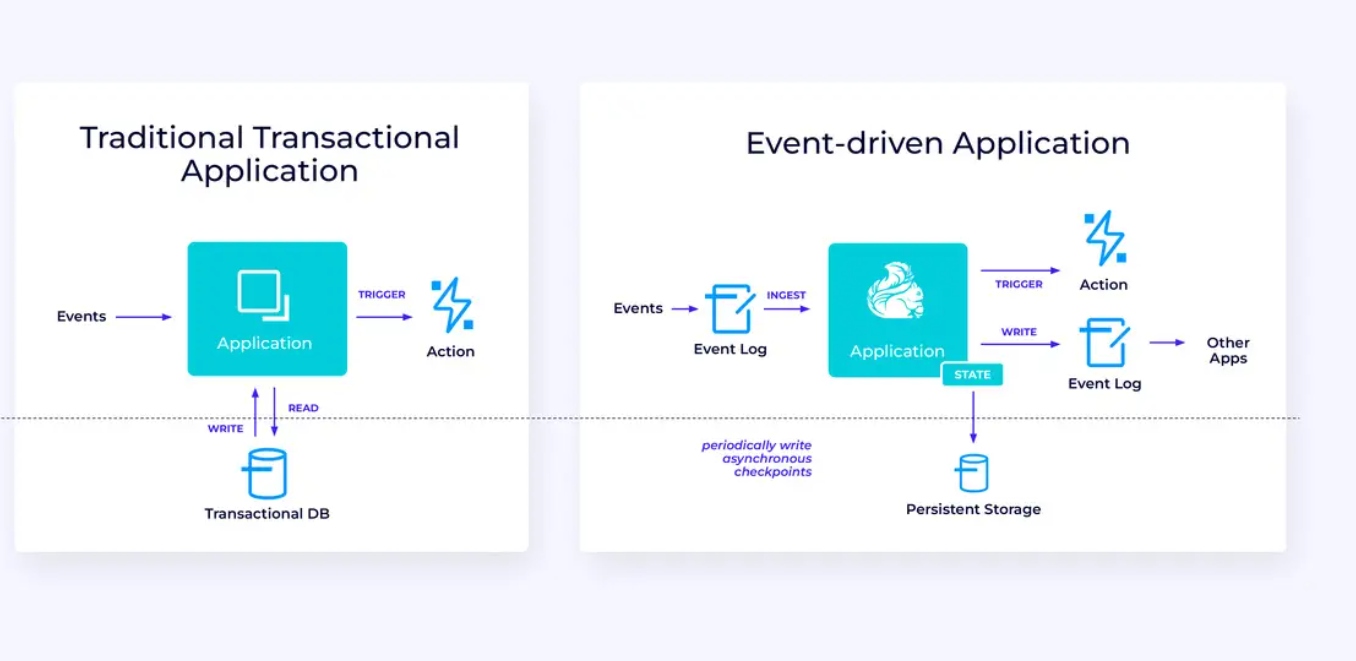
יישומים מוטבעים בעקבות אירועים
משפחת היישומים השלישי והאחרונה שלנו מועדכנת את היישומים המוטבעים בעקבות אירועים או של מיקרו-שירותים. נכתב הרבה על הנושא במקומות אחרים; זהו דפוס עיצוב ארכיטקטורי שיש לו הרבה יתרונות.
Flink יכול להיות תואם מעולה ליישומים אלה, בעיקר אם אתה צריך את הביצועים המומצאים של Flink. במקרים מסויימים, ל API של שולחן/SQL יש הכל מה שצריך, אך בהרבה מהמקרים, תצטרך לעזרת הפלטיות הנוספת של API ה DataStream לפחות חלק מהעבודה.
התחלה עם Flink
Flink מעניק מערכת חזקה לבניית יישומים שמעבדים זרמי אירועים. כפי שעברנו עליו, חלק מהמושגים עלולים להישמע חדשניים בהתחלה, אך ברגע שתהייה מורגל לדרך בה מעוצב Flink ופועל, התוכנה קלה לשימוש, והשכר של הידע על Flink הוא משמעותי.
כעת השלב הבא הוא לעקוב אחר ההוראות במסמך ההדרכה של Flink, שידורך את דרכך להוריד, להתקין ולרצף את הגרסה היעילה האחרונה של Flink. חישבו על היישומים הרחבים שאנחנו דיברנו עליהם — צירופי נתונים מודרניים, אנליזת אמת בזמן אמת, ומיקרו-שירותים מוטבעים בעקבות אירועים — ואיך אלה יכו
הזרמת נתונים היא אחד התחומים המרתקים ביותר בטכנולוגיית הארגונים כיום, ועיבוד זרמים עם Flink הופך אותו לעוד יותר עוצמתי. לימוד Flink יהיה מועיל לא רק לארגון שלך אלא גם לקריירה שלך, מכיוון שעיבוד נתונים בזמן אמת הופך ליותר ויותר יקר ערך לעסקים ברחבי העולם. אז בדוק את Flink היום וראה מה הטכנולוגיה העוצמתית הזו יכולה לעזור לך להשיג.
Source:
https://dzone.com/articles/apache-flink-101-a-guide-for-developers