













In den letzten Jahren hat Apache Flink sich als defacto Standard für Echtzeitspektorverarbeitung etabliert. Die Streamverarbeitung ist ein Paradigma für Systembau, das Ereignisströme (Sequenzen von Ereignissen im Zeitverlauf) als grundlegendsten Baustein ansieht. Ein Streamverarbeiter, wie z.B. Flink, verarbeitet Eingabeströme, die von Ereignissourcen erzeugt werden und erzeugt Ausgabeströme, die von Senken (die Senken Ergebnisse speichern und für weitere Verarbeitung bereitstellen) verwendet werden.
Berühmte Namen wie Amazon, Netflix und Uber verlassen sich auf Flink, um Datenpipelines mit einer großen Skalierung im Herzen ihrer Geschäfte zu versorgen, aber Flink spielt auch eine Schlüsselrolle in vielen kleineren Unternehmen mit ähnlichen Anforderungen, die die Möglichkeit haben, schnell auf kritische Geschäftsereignisse zu reagieren.
Wofür wird Flink verwendet? Allgemeine Anwendungsfälle fallen in diese drei Kategorien:
|
Streaming-Datenpipelines |
Echtzeitanalyse |
Ereignisgetriebene Anwendungen |
|---|---|---|
|
Datenströme kontinuierlich einlesen, vervollständigen und verändern und sie in Zieldatenbanken laden, um zeitgerechte Aktionen durchzuführen (im Gegensatz zur Batchverarbeitung). |
Ergebnisse kontinuierlich erzeugen und aktualisieren und diese Ergebnisse den Benutzern als Echtzeitdatenströme zugeführt werden. |
Erkennen von Mustern und reagieren auf eingehende Ereignisse, indem Verarbeitungen, Zustandsaktualisierungen oder externe Aktionen ausgelöst werden. |
|
Einige Beispiele hierfür sind:
|
Einige Beispiele:
|
Einige Beispiele:
|
Flink beinhaltet:
- Robuste Unterstützung für Datenstrom-Arbeitslasten auf der Größe, die globalen Unternehmen notwendig ist
- Starke Garantien für exakt-einmalige Korrektheit und Fehler-Wiederherstellung
- Unterstützung für Java, Python und SQL mit einer vereinheitlichten Unterstützung sowohl für batch- als auch streambasierte Verarbeitung
- Flink ist ein reifes Open-Source-Projekt der Apache Software Foundation und hat eine sehr aktive und Unterstützende Gemeinschaft.
Flink wird manchmal als komplex und schwer zu lernen beschrieben. Ja, die Implementierung von Flink’s Laufzeit ist komplex, aber das sollte nicht verwundern, da es einige schwierige Probleme löst. Flink-APIs können etwas schwierig zu lernen sein, aber das hat mehr mit den fremden Konzepten und Organisierungsprinzipien zu tun als mit irgendeiner angeblichen Komplexität.
Flink mag sich von etwas, das du zuvor verwendet hast, unterscheiden, aber in vielerlei Hinsicht ist er eigentlich recht einfach. Irgendwann, als du dich besser mit der Art und Weise vertraut, wie Flink zusammengesetzt ist, und den Problemen, die seine Laufzeit erfüllt werden müssen, wird die Detailfülle von Flinks APIs dich möglicherweise als die offensichtlichen Folgen von wenigen Schlüsselprinzipien erinnern, anstatt als eine Sammlung von abgelegenen Details, die du merken solltest.
Dieser Artikel zielt darauf ab, den Lernprozess von Flink erheblich zu vereinfachen, indem er die grundlegenden Prinzipien aufzeigt, die seine Designentscheidung beeinflussen.
Flink konzentriert sich auf wenige große Ideen
Ströme
Flink ist ein Framework für die Erstellung von Anwendungen, die Ereignisströme verarbeiten, wobei ein Strom eine eingeschränkte oder unbegrenzte Folge von Ereignissen ist.
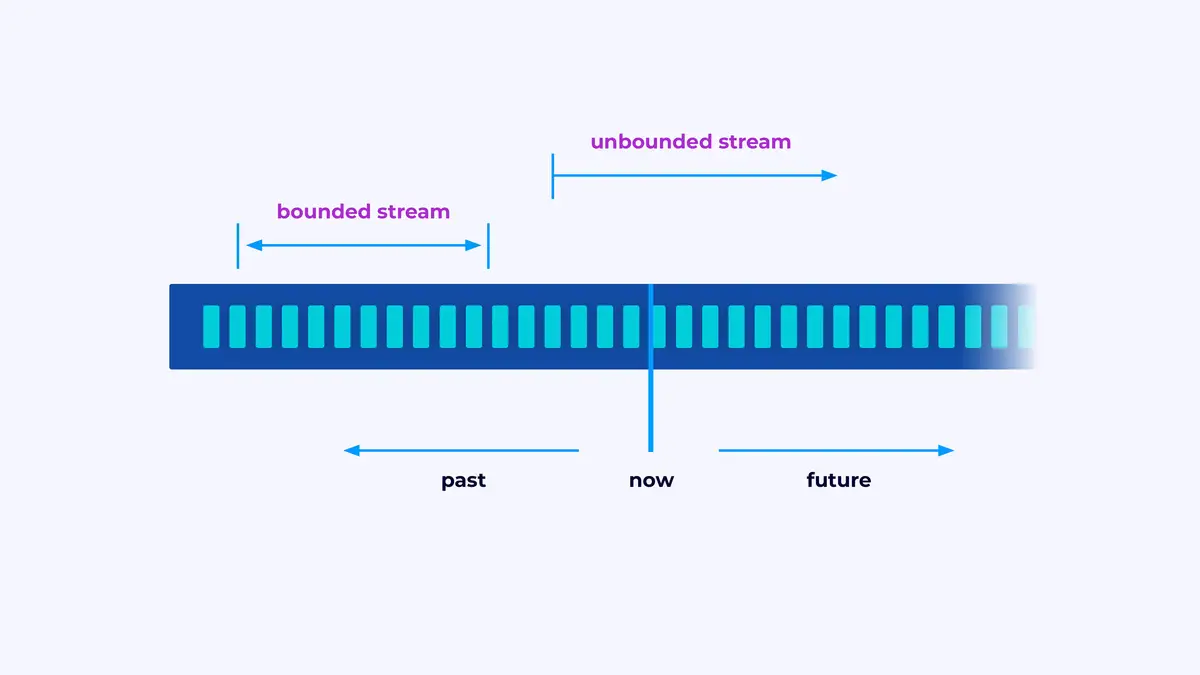
Eine Flink-Anwendung ist ein Datenverarbeitungspipeline. Deine Ereignisse fließen durch diesen Pipeline und werden auf jeder Stufe durch den Code, den du schreibst, verarbeitet. Wir bezeichnen diesen Pipeline als Job-Graph und die Knoten dieses Graphen (oder mit anderen Worten, die Stufen der Verarbeitungspipeline) werden als Operatoren bezeichnet.
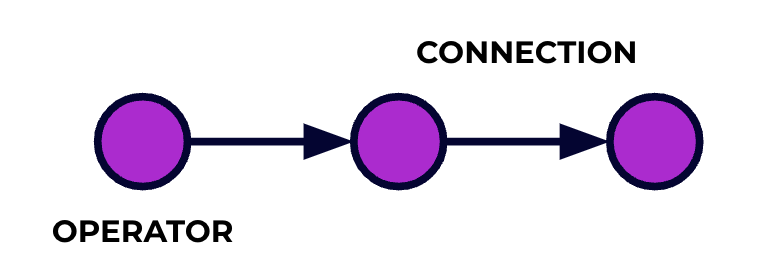
Der Code, den du mit einer von Flinks APIs schreibst, beschreibt den Job-Graph, einschließlich des Verhaltens der Operatoren und ihrer Verbindungen.
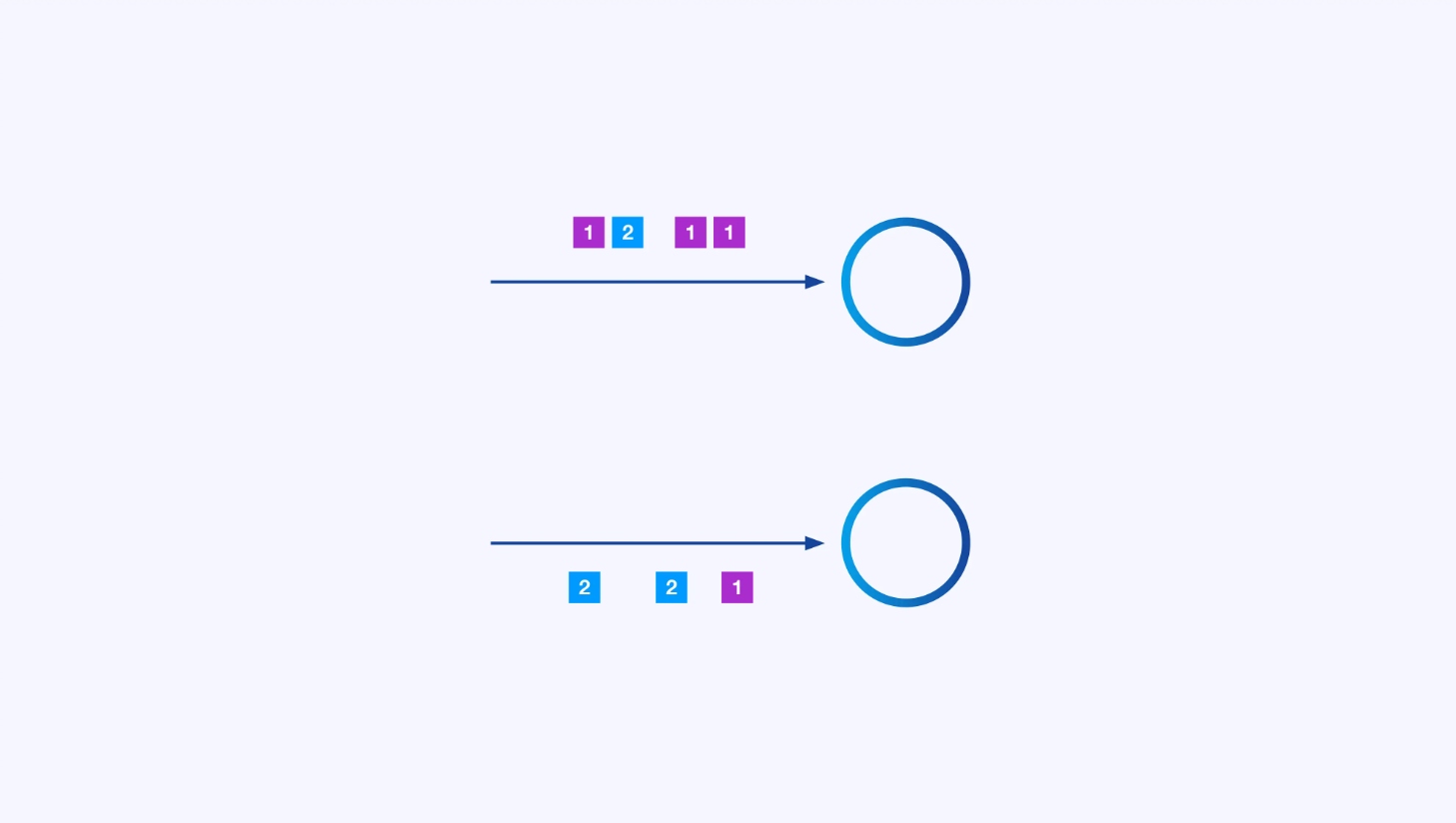
Parallelle Verarbeitung
Jeder Operator kann viele parallele Instanzen haben, die jeweils unabhängig von einander auf einer Teilmenge der Ereignisse arbeiten.
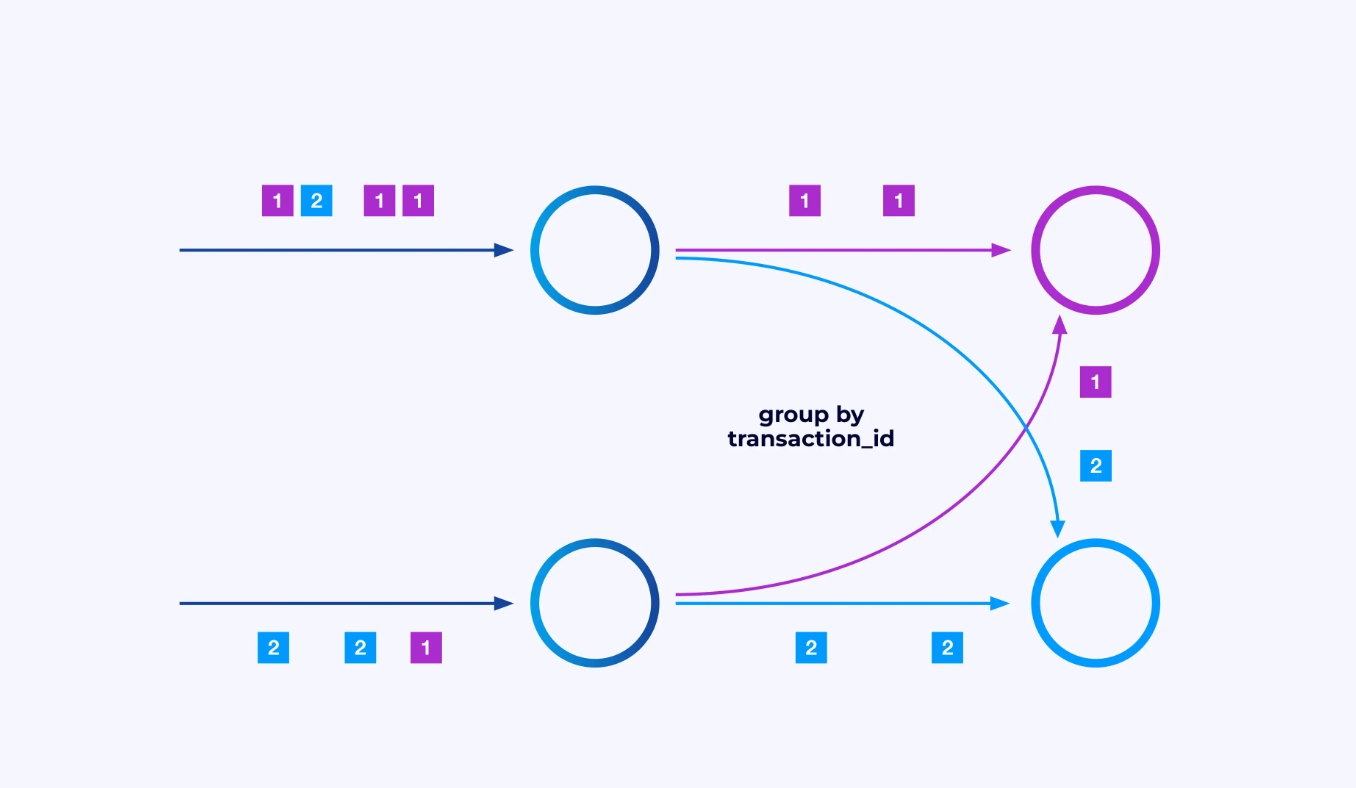
Manchmal möchtest du eine bestimmte Partitionierungsvorrichtung auf diese Unterströme anwenden, sodass die Ereignisse gemäß einer bestimmten Anwendungsspezifikation zusammengefasst werden. Zum Beispiel, wenn du Finanztransaktionen verarbeite, müsstest du veranlassen, dass jedes Ereignis für eine gegebene Transaktion von derselben Thread bearbeitet wird. Dies ermöglicht es dir, die verschiedenen Ereignisse, die im Verlauf einer Transaktion auftreten, zusammenzubringen
In Flink SQL würdest du dies mit GROUP BY transaction_id tun, während du im DataStream API keyBy(event -> event.transaction_id) verwenden kannst, um diese Gruppierung oder Partitionierung anzugeben. In jedem Fall erscheint das im Job-Diagramm als eine vollständig verknüpfte Netz-Shuffle-Verbindung zwischen zwei aufeinanderfolgenden Stufen des Diagramms.
State
Operatoren, die auf key-partitionierten Strömen arbeiten, können Flink’s verteiltes Key/Value-Staatspeicher verwenden, um alles, was sie wollen, dauerhaft zu speichern. Der Staat für jedes Schlüssel ist lokal für eine bestimmte Instanz eines Operators und kann nicht von anderen Orten aus zugegriffen werden. Die parallelen Untertopologien teilen nichts — das ist entscheidend für uneingeschränkte Skalierbarkeit.
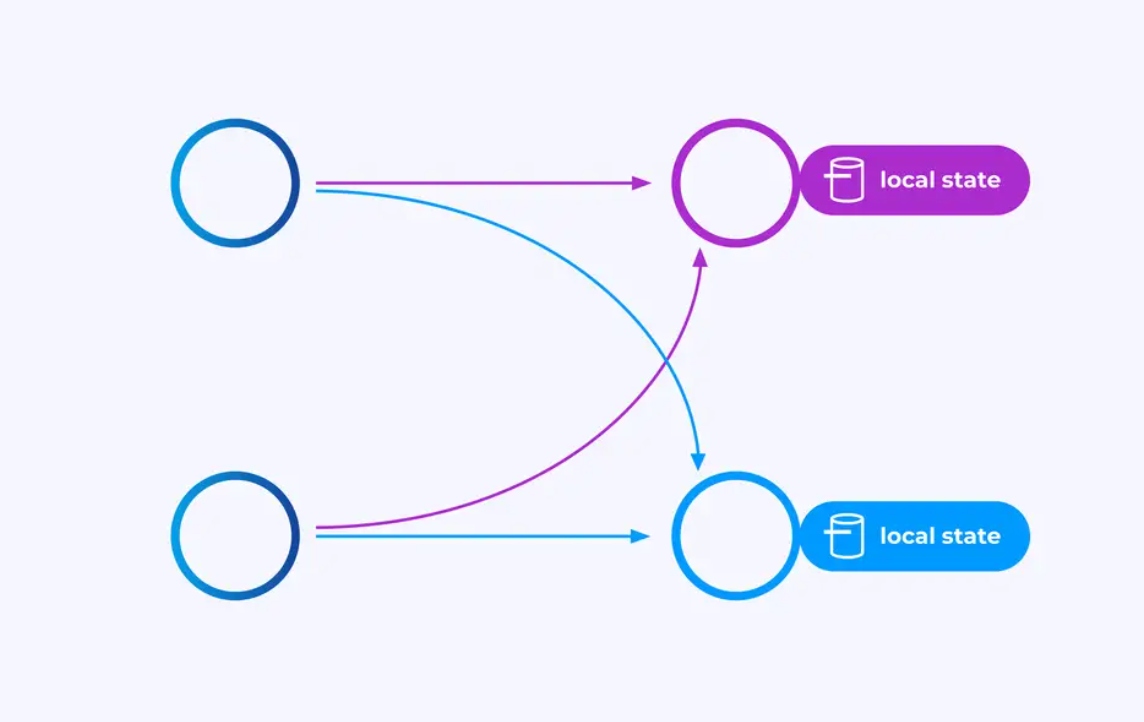
Ein Flink-Job kann unendlich lange laufen bleiben. Wenn ein Flink-Job kontinuierlich neue Schlüssel erzeugt (z.B. Transaktions-IDs) und für jeden neuen Schlüssel etwas speichert, dann besteht dieser Job durch den Gebrauch eines unbegrenzten Staatsvolumens die Gefahr, sich zu explosionsartig zu vergrößern. Jeder der Flink-APIs ist auf die Organisation von Möglichkeiten ausgerichtet, um dir zu helfen, solche staatsexplosiven Situationen zu vermeiden.
Time
Eine Methode, um zu vermeiden, dass ein Zustand zu lange behalten wird, besteht darin, ihn nur bis zu einem bestimmten Zeitpunkt zu behalten. Zum Beispiel, wenn du Transaktionen in Minuten窗haltigen Fenstern zählen willst, kann das Ergebnis für diese Minute nach Ablauf der Minute erzeugt werden, und dieser Zähler kann freigegeben werden.
Flink unterscheidet zwischen zwei verschiedenen Zeitnotionen:
- Verarbeitungszeit (oder Uhrzeit), die von der tatsächlichen Uhrzeit abgeleitet wird, wenn ein Ereignis verarbeitet wird
- Ereigniszeit, die auf Basis der mit jedem Ereignis erfassten Zeitstempel basiert
Um die Differenz zwischen diesen beiden zu verdeutlichen, erinnern Sie sich an das, was es bedeutet, dass ein Minuten窗hafte Fenster abgeschlossen ist:
- Ein Verarbeitungszeitfenster ist fertig, wenn die Minute zu Ende geht. Dies ist ganz einfach.
- Ein Ereigniszeitfenster ist fertig, wenn alle Ereignisse, die während dieser Minute aufgetreten sind, verarbeitet wurden. Dies kann problematisch sein, da Flink nichts über Ereignisse erfahren kann, die noch nicht verarbeitet wurden. Die beste Lösung besteht darin, eine Annahme darüber zu treffen, wie ungeordnet ein Stream sein kann und diese Annahme heuristisch anzuwenden.
Checkpointing für Fehlerwiederherstellung
Fehler sind unvermeidbar. Trotz Fehlern ist Flink in der Lage, prinzipiell exakt-einmalige Garantien anzubieten, was bedeutet, dass jedes Ereignis genau einmal den Zustand beeinflussen wird, den Flink verwaltet, als ob die Fehlern gar nicht passiert wären. Dies erreicht Flink, indem es periodisch globale, selbstkonsistente Snapshots aller Zustände aufnimmt. Diese Snapshots, erstellt und verwaltet automatisch von Flink, heißen Checkpoints.
Die Wiederherstellung umfasst den Rücksetzten auf den Zustand, der in dem letzten Checkpoint aufgezeichnet wurde, und den globalen Neustart aller Operatoren von diesem Checkpoint aus. Während der Wiederherstellung werden einige Ereignisse neu verarbeitet, aber Flink kann durch die Gewährleistung, dass jeder Checkpoint ein globaler, selbstkonsistenter Snapshot des kompletten Systems ist, Korrektheit gewährleisten.
Systemarchitektur
Flink-Anwendungen laufen in Flink-Clustern, sodass du einen Cluster benötigst, um eine Flink-Anwendung in die Produktion zu bringen. Glücklicherweise kannst du während der Entwicklung und der Testphase leicht beginnen, indem du Flink lokal in einer integrierten Entwicklungsumgebung (IDE) wie IntelliJ oder Docker ausführen lässt.
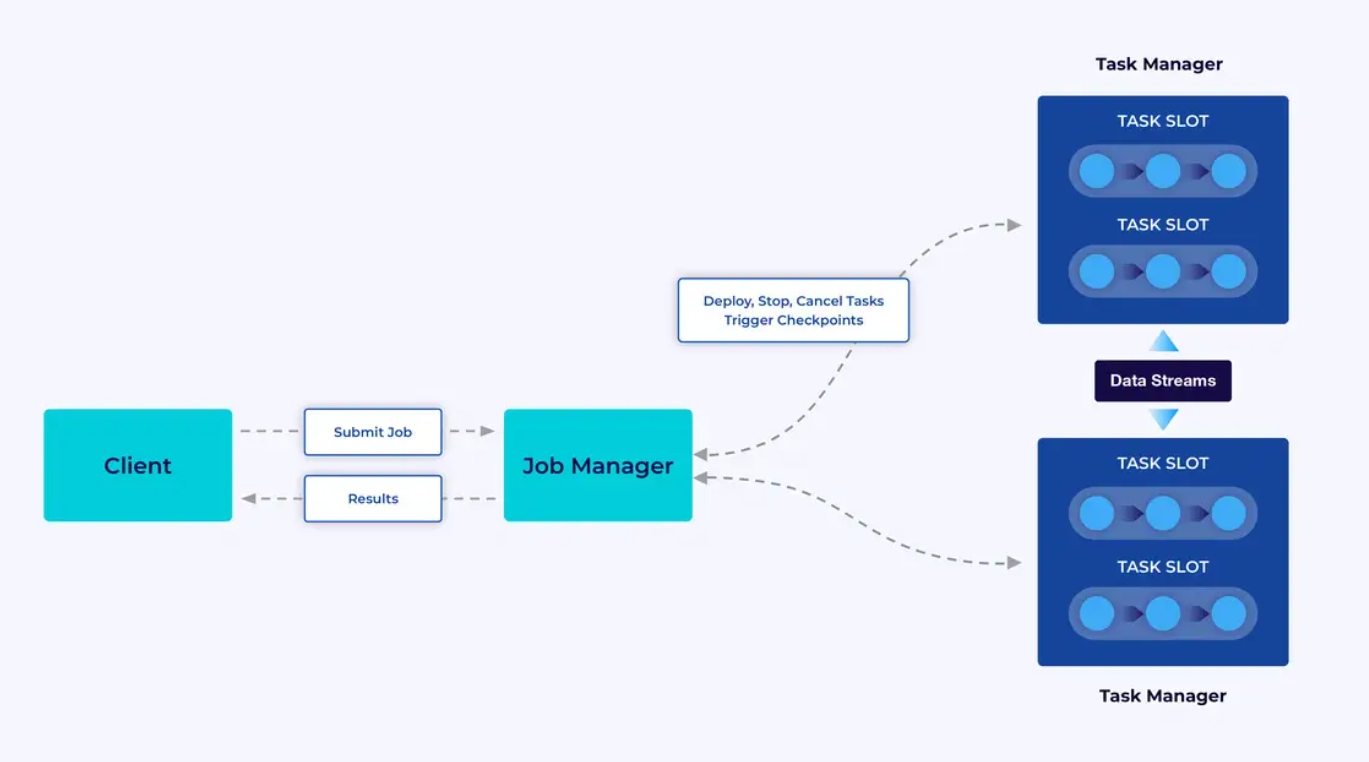
Ein Flink-Cluster verfügt über zwei Arten von Komponenten: einen Job Manager und eine Sammlung von Task Managers. Die Task Manager führen deine Anwendungen (parallelt) aus, während der Job Manager als Gateway zwischen den Task Managers und der Außenwelt agiert. Anwendungen werden dem Job Manager übergeben, der die von den Task Managers bereitgestellten Ressourcen verwaltet, Koordinaten für das Checkpointing und im Rahmen von Metriken die Sichtbarkeit des Clusters bereitstellt.
Die Entwickler Erfahrung
Die Erfahrung, die du als Flink-Entwickler hast, hängt zu einem gewissen Grad davon ab, welche der APIs du wählen kannst: entweder die ältere, niedrigere Ebene DataStream API oder die neuere, relationale Tabellen- und SQL-APIs.
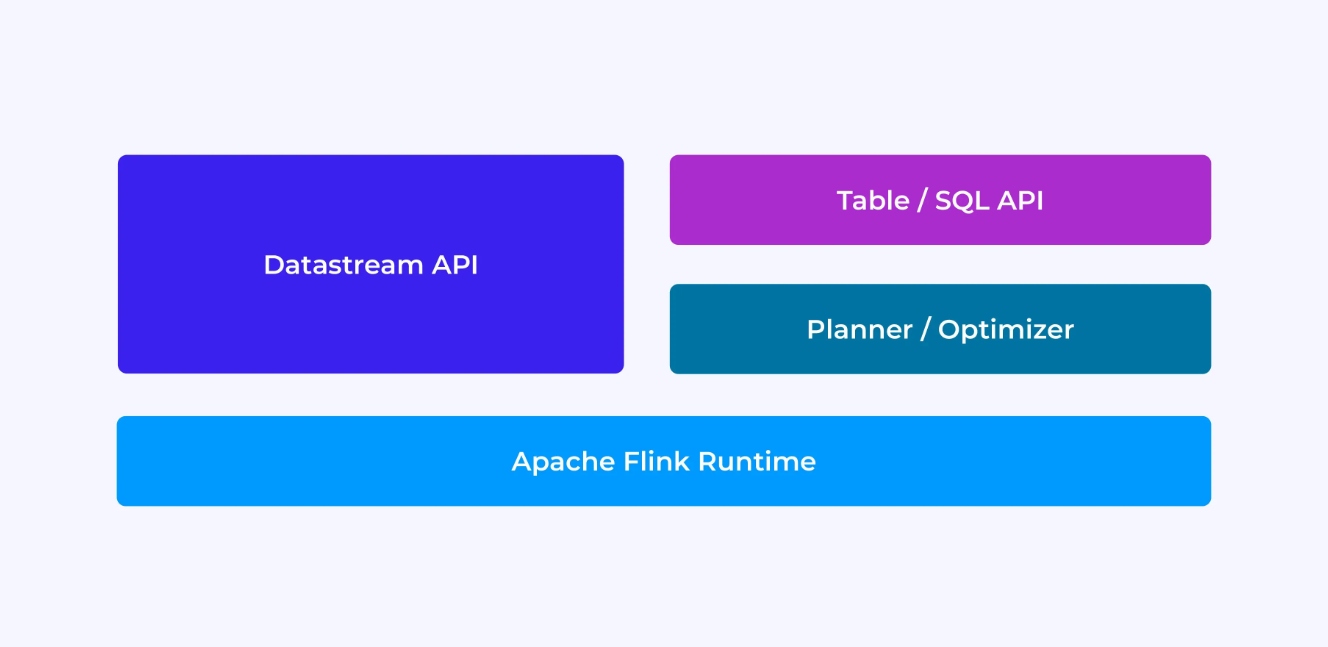
Wenn Sie mit Flink‘s DataStream API programmieren, denken Sie konzentriert an, was der Flink-Laufzeitbetrieb als Ihre Anwendung läuft. Dies bedeutet, dass Sie den Job-Graphen ein Operator nach dem anderen aufbauen, die verwendeten Zustände beschreiben sowie die beteiligten Typen und ihre Serialisierung, Timer erstellen und Callback-Funktionen implementieren, die ausgeführt werden, wenn diese Timer aktiviert werden etc. Die Kernabstraktion in der DataStream API ist das Ereignis und die von Ihnen geschriebenen Funktionen behandeln ein Ereignis pro Zeit, wie sie eintreffen.
Andersseits bietet Flink‘s Table/SQL API Ihnen diese untergeordneten Angelegenheiten auf und Sie können sich direkter auf Ihre Geschäftslogik konzentrieren. Die Kernabstraktion ist die Tabelle und Sie denken eher in Bezug auf die Tabelle verbinden, um zu vervollständigen, Gruppieren von Zeilen zusammen, um aggregierte Analytik zu berechnen etc. Ein integriertes SQL-Abfrageplaner und Optimierer nimmt sich der Detailarbeit an. Der Planer/Optimierer leistet hervorragende Arbeit bei der effizienten Ressourcenverwaltung und erzielt oft bessere Leistungen als manuell geschriebener Code.
Ein paar weitere Gedanken, bevor wir in die Details tauchen: Erstens müssen Sie nicht zwischen DataStream und Table/SQL API wählen – beide API‘s sind interoperabel und Sie können sie kombinieren. Dies kann eine gute Lösung sein, wenn Sie etwas benötigen, das mit der Table/SQL API nicht möglich ist. Aber eine weitere Möglichkeit, über die Table/SQL API aus der Box bietet hinauszukommen, besteht in der Form von benutzerdefinierten Funktionen (UDFs) hinzuzufügen. Hier bietet Flink SQL viele Optionen für die Erweiterung an.
Der Aufbau des Job-Graphen
Unabhängig von der API, die Sie verwenden, besteht das ultimate Ziel des von Ihnen geschriebenen Codes darin, den Job-Graph zu erstellen, der vom Flink-Laufzeitbetrieb auf Ihrer Behalf ausgeführt wird. Dies bedeutet, dass diese APIs sich um das Erstellen von Operatoren und das Spezifizieren ihres Verhaltens sowie ihrer Verbindungen zueinander organisieren. Mit der DataStream-API erstellen Sie direkt den Job-Graph, während mit der Table/SQL-API der Flink-SQL-Planer dies erledigt.
Funktionen und Daten serialisieren
Schließlich wird der von Ihnen an Flink gelieferte Code in Parallel von den Workern (den Task-Managern) innerhalb eines Flink-Clusters ausgeführt. Um dies zu erreichen, müssen die Funktionsobjekte, die Sie erstellt haben, serialisiert und an die Task-Manager gesendet werden, wo sie ausgeführt werden. Analog dazu werden die Ereignisse manchmal auch serialisiert und über das Netz von einem Task-Manager zum anderen gesendet. Auch mit der Table/SQL-API müssen Sie sich nicht diesen Aspekt anschließen.
Zustandsverwaltung
Der Flink-Laufzeitbetrieb muss aufgeklärt werden, welche Zustände er bei einem Fehler für Sie wiederherstellen soll. Um dies zu funktionieren, benötigt Flink Typinformation, die es verwenden kann, um diese Objekte zu serialisieren und zu deserialisieren (damit sie in Checkpoints geschrieben und gelesen werden können). Optional können Sie diesen verwalteten Zustand mit Time-to-Live-Beschreibungen konfigurieren, die Flink verwendet, um den Zustand automatisch abzufließen, sobald er seine Nutzung verloren hat.
Mit der DataStream API enden Sie in der Regel direkt mit der Verwaltung des Status, der Ihrer Anwendung notwendig ist (die integrierten Fensteroperationen sind der einzige Ausnahme zu dieser Regel). Andererseits ist dieses Problem mit der Table/SQL API abstrahiert. Zum Beispiel, wenn Sie eine Abfrage wie unten vorfinden, ist bekannt, dass irgendwo in der Flink- Laufzeit eine Datenstruktur einen Zähler für jeden URL aufrecht erhalten muss, aber alle Details werden für Sie behandelt.
SELECT url, COUNT(*)
FROM pageviews
GROUP BY URL;Setzen und Triggern von Timern
Timers haben viele Anwendungen in der Streamverarbeitung. Zum Beispiel ist es häufig der Fall, dass Flink-Anwendungen Informationen aus vielen verschiedenen Ereignisquellen sammeln müssen, bevor sie letztendlich Ergebnisse erzeugen. Timer funktionieren gut für Fälle, wo es sinnvoll ist, auf Daten zu warten (aber nicht unendlich), die eventuell (oder vielleicht nicht) irgendwann eintreffen.
Timers sind auch essentiell für die Implementierung zeitbasierter Fensteroperationen. Sowohl die DataStream als auch die Table/SQL-APIs haben integrierten Support für Fenster und verursachen und verwalten Timer für Sie.
Anwendungsfälle
Gehen wir zurück zu den drei breiten Kategorien von Streaming-Anwendungsfällen, die am Anfang dieses Artikels vorgestellt wurden, und sehen, wie sie auf das, was Sie bisher über Flink gelernt haben, abgebildet werden.
Streaming-Datenpipeline
Unten links ist ein Beispiel einer traditionellen batch extract, transform, and load (ETL)-Job, der periodisch aus einem transaktionellen Datenbanken liest, die Daten transformiert und die Ergebnisse in eine andere Datenquelle schreibt, wie z.B. eine Datenbank, ein Dateisystem oder ein Datensee.
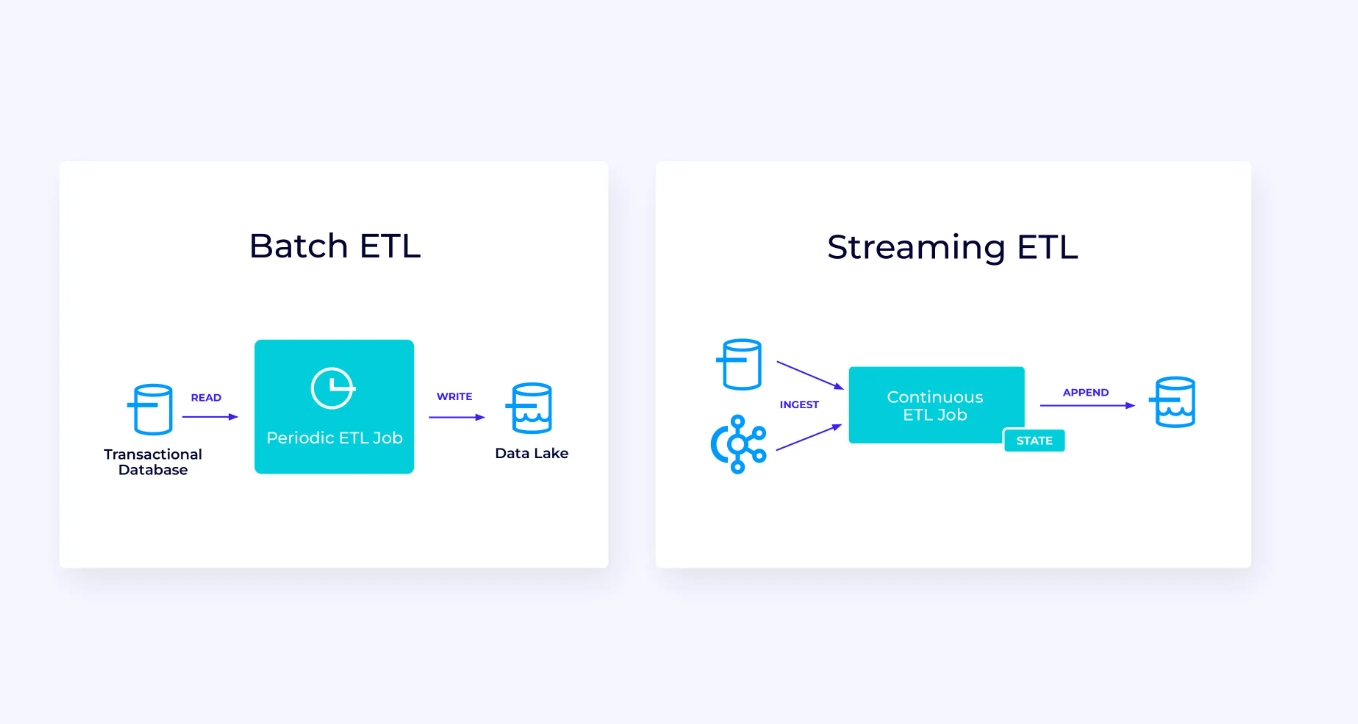
Der entsprechende Streaming-Pipeline ist oberflächlich ähnlich, aber es gibt bedeutende Unterschiede:
- Der Streaming-Pipeline läuft immer.
- Die transaktionellen Daten werden in zwei Teilen an den Streaming-Pipeline geliefert: eine initiale Massenlade aus der Datenbank und eine Änderungsdatenabfang-Stream (Change Data Capture, CDC), der die Datenbankupdates enthält, die seit dem Massenlade erfolgt sind.
- Die Streaming-Version erzeugt kontinuierlich neue Ergebnisse, sobald sie verfügbar sind.
- Der Zustand wird explizit verwaltet, sodass er bei einem Fehler robust恢复 werden kann. Streaming-ETL-Pipelines verwenden typischerweise sehr wenig Zustand. Die Datenquellen halten genau verträglich, wie viel der Eingaben verarbeitet wurde, typischerweise in Form von Offsets, die die Datensätze seit dem Anfang der Streams zählen. Die Senken verwenden Transaktionen, um ihre Schreibungen in externe Systeme wie Datenbanken oder Kafka zu verwalten. Während des Checkpoints werden die Quellen ihre Offsets aufzeichnen und die Senken die Transaktionen, die die Ergebnisse darstellen, die genau bis zu, aber nicht über diesen Quellensprung hinaus gelesen wurden, bestätigen.
Für diesen Anwendungsfall wäre die Tabellen/SQL-API eine gute Wahl.
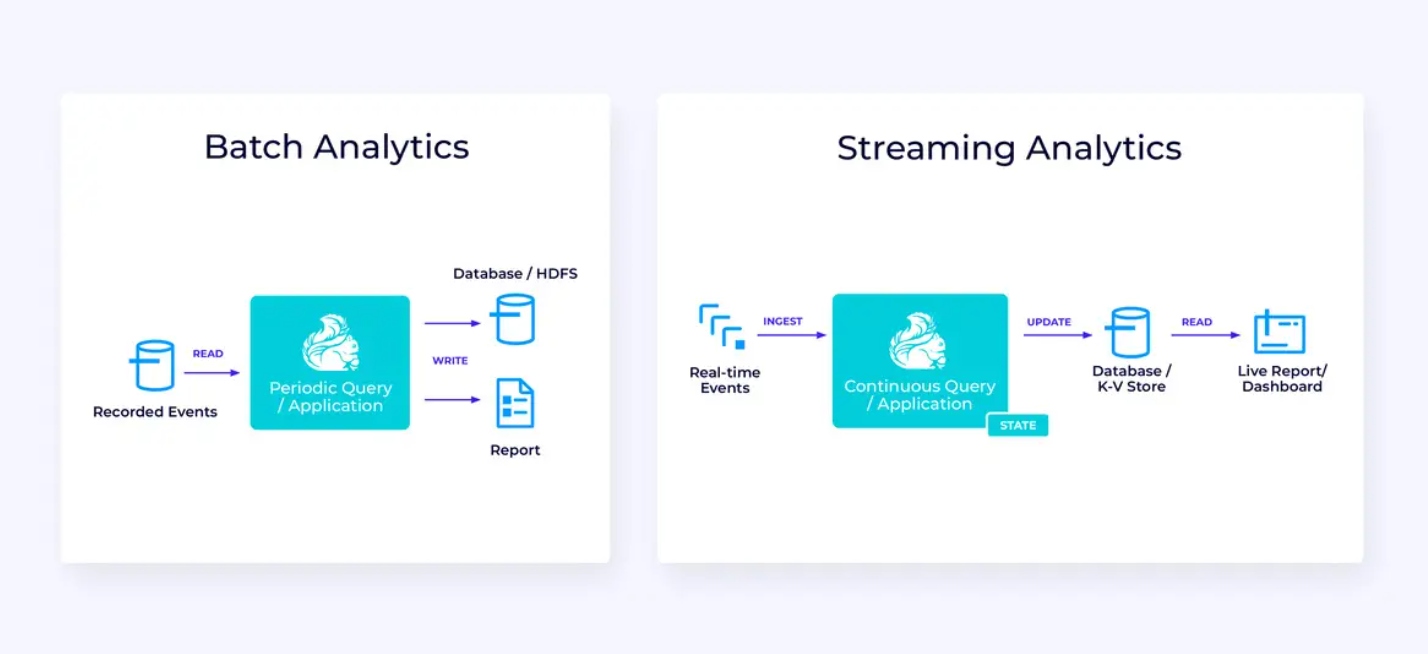
Echtzeit-Analytics
Im Vergleich zur Streaming-ETL-Anwendung weist diese Streaming-Analytikanwendung einige interessante Unterschiede auf:
- Erneut wird Flink verwendet, um eine kontinuierliche Anwendung zu betreiben, aber für diese Anwendung wird Flink wahrscheinlich erheblich mehr Zustand verwalten müssen.
- Für diesen Anwendungsfall ergibt es Sinn, dass der eingespeiste Stream in ein stream-native Speichersystem gespeichert wird, wie z.B. Apache Kafka.
- Statt der periodischen Erstellung eines statischen Berichts kann die Streaming-Version zur Steuerung eines Live-Dashboards verwendet werden.
Noch einmal ist die Tabellen/SQL-API in der Regel eine gute Wahl für diesen Anwendungsfall.
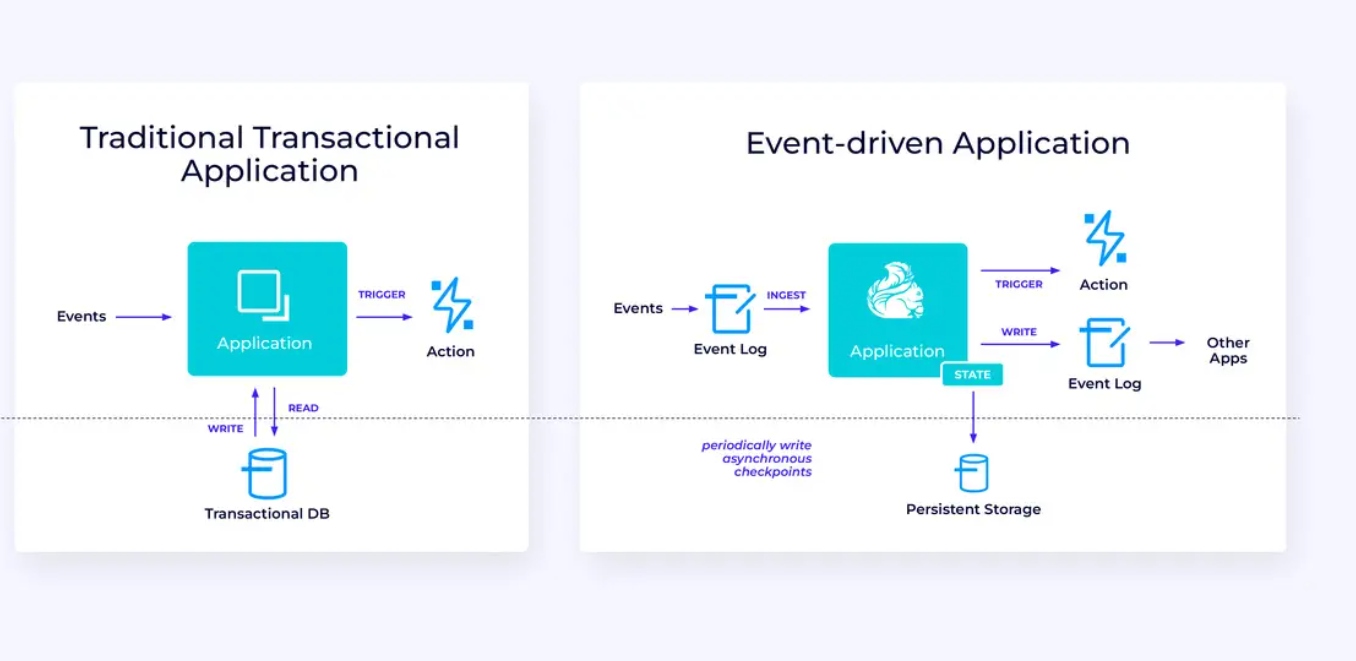
Ereignisgetriebene Anwendungen
Unser drittes und letztes Familie von Anwendungsfällen beinhaltet die Implementierung von ereignisgetriebenen Anwendungen oder Mikroservices. Vieles wurde an anderer Stelle zu diesem Thema geschrieben; dies ist ein Architekturmuster, das zahlreiche Vorteile bietet.
Flink kann ideal für diese Anwendungen passen, insbesondere, wenn Sie die von Flink bereitgestellte Leistung benötigen. In manchen Fällen bietet die Tabellen/SQL-API bereits alles, was Sie brauchen, aber in vielen Fällen müssen Sie die zusätzliche Flexibilität der DataStream-API mindestens für einen Teil der Arbeit benötigen.
Erste Schritte mit Flink
Flink stellt ein leistungsstarkes Framework für Anwendungen bereit, die Ereignisströme verarbeiten. Wie wir gesehen haben, könnten einige der Konzepte zunächst einmal neuartig erscheinen, aber sobald Sie sich mit der Art und Weise vertraut haben, wie Flink entwickelt und funktioniert, ist das Software zu verwenden intuitiv und die Belohnungen, die das Wissen um Flink bringt, sind erheblich.
Als nächster Schritt folgen den Anweisungen in der Flink-Dokumentation, die Ihnen durch den Prozess der Herunterladen, Installieren und Ausführen der aktuell stabilen Version von Flink führen. Den weitreichenden Anwendungsfällen, die wir diskutiert haben — moderne Datenpipelines, Echtzeitanalyse und ereignisgetriebene Mikroservices — und wie diese Ihrer Organisation helfen können, um eine Herausforderung zu lösen oder Wert zu schaffen, Gedanken.
Datenstreaming ist eines der spannendsten Bereiche der heutigen Unternehmenstechnologie und die Streamverarbeitung mit Flink macht es noch effizienter. Denken Sie daran, Flink zu erlernen, da die Echtzeitverarbeitung von Daten zunehmend für Unternehmen weltweit von großem Wert ist. Probieren Sie also Flink heute aus und sehen Sie, was Sie mit dieser leistungsstarken Technologie erreichen können.
Source:
https://dzone.com/articles/apache-flink-101-a-guide-for-developers