













Em recentes anos, o Apache Flink se tornou a referência padrão para processamento de stream de modo real-time. O processamento de stream é um paradigma para a construção de sistemas que trata de fluxos de eventos (sequências de eventos em tempo) como seu bloco de construção fundamental. Um processador de stream, como o Flink, consome fluxos de entrada produzidos por fontes de eventos e produz fluxos de saída que são consumidos por coletores (os coletores armazenam resultados e os tornam disponíveis para processamento adicional).
Nomes conhecidos como Amazon, Netflix e Uber dependem do Flink para alimentar pipelines de dados em escala tremenda no coração de suas negócios, mas o Flink também desempenha um papel chave em muitas empresas pequenas com requisitos semelhantes para serem capazes de reagir rapidamente a eventos críticos de negócios.
O que é que o Flink está sendo usado? Casos de uso comuns se enquadram nestas três categorias:
|
Pipelines de dados em streaming |
Análise em tempo real |
Aplicações com eventos |
|---|---|---|
|
Ingere, enriqueça e transforme fluxos de dados, carregando-os em sistemas de destino para ação oportuna (em oposição ao processamento por lote). |
Produza e atualize resultados que são exibidos e entregues aos usuários conforme os fluxos de dados em tempo real são consumidos. |
Reconheça padrões e reaja a eventos de entrada ativando cálculos, atualizações de estado ou ações externas. |
|
Alguns exemplos incluem:
|
Alguns exemplos incluem:
|
Alguns exemplos incluem:
|
Flink inclui:
- Forte suporte para cargas de streaming de dados à escala necessária por empresas globais
- Fortes garantias de corretude exatamente uma vez e recuperação de falha
- Suporte para Java, Python e SQL, com suporte unificado tanto para processamento em lote quanto em stream
- Flink é um projeto de código aberto maduro da Fundação Apache Software e tem uma comunidade muito ativa e apoiadora.
Flink às vezes é descrito como sendo complexo e difícil de aprender. Sim, a implementação do runtime de Flink é complexa, mas esse não deve surpreender, já que resolve alguns problemas difíceis. As APIs de Flink podem ser algo desafiantes para aprender, mas isso tem mais a ver com os conceitos e princípios de organização estarem desconhecidos do que com qualquer complexidade inata.
Flink pode ser diferente de tudo que você já usou antes, mas em muitos aspectos, é mesmo bem simples. Em certo ponto, conforme você se familiariza com a maneira como o Flink está montado e com os problemas que o runtime deve resolver, os detalhes das APIs do Flink deveriam começar a parecer-se a você como sendo o resultado óbvio de alguns princípios chave, em vez de uma coleção de detalhes esotéricos que você deveria memorizar.
Este artigo visa tornar a jornada de aprendizagem do Flink muito mais fácil, expondo os princípios centrais que subjazem à sua concepção.
O Flink Encarna Algumas Ideias Grandes
Streams
O Flink é um framework para a construção de aplicações que processam fluxos de eventos, onde um fluxo é uma sequência limitada ou não limitada de eventos.
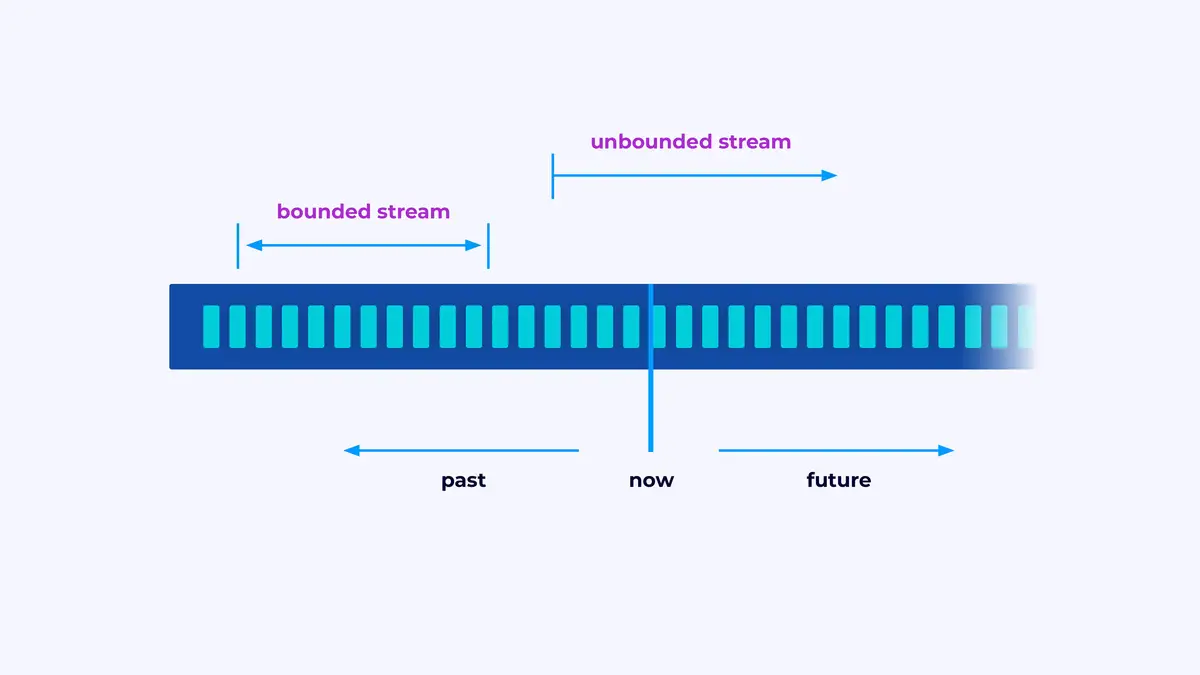
Uma aplicação Flink é um pipeline de processamento de dados. Seus eventos fluem por este pipeline e são operados em cada estação pelo código que você escreve. Nós chamamos este pipeline de grafo de job e os nós deste grafo (ou seja, as etapas do pipeline de processamento) são chamados de operadores.
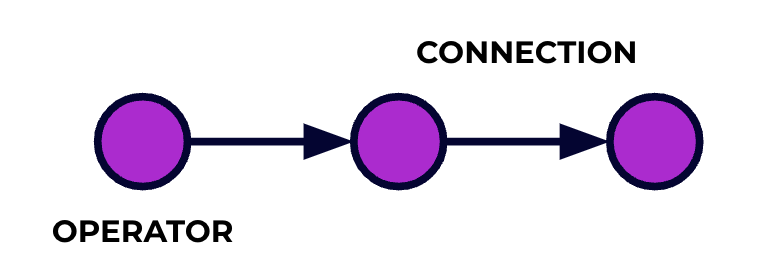
O código que você escreve usando uma das APIs do Flink descreve o grafo de job, incluindo o comportamento dos operadores e suas conexões.
Processamento Paralelo
Cada operador pode ter muitas instâncias paralelas, cada uma operando independentemente sobre algum subconjunto dos eventos.
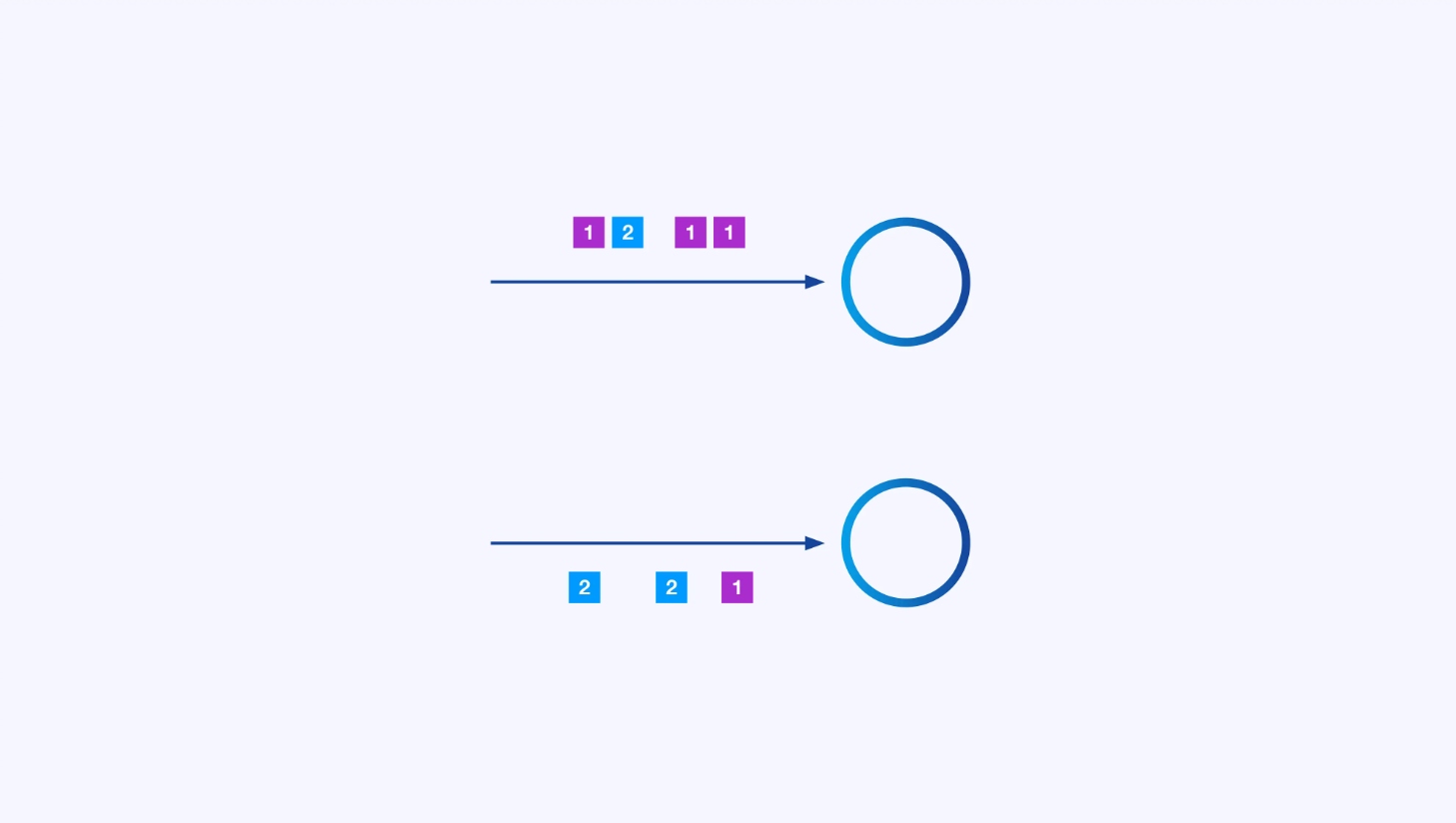
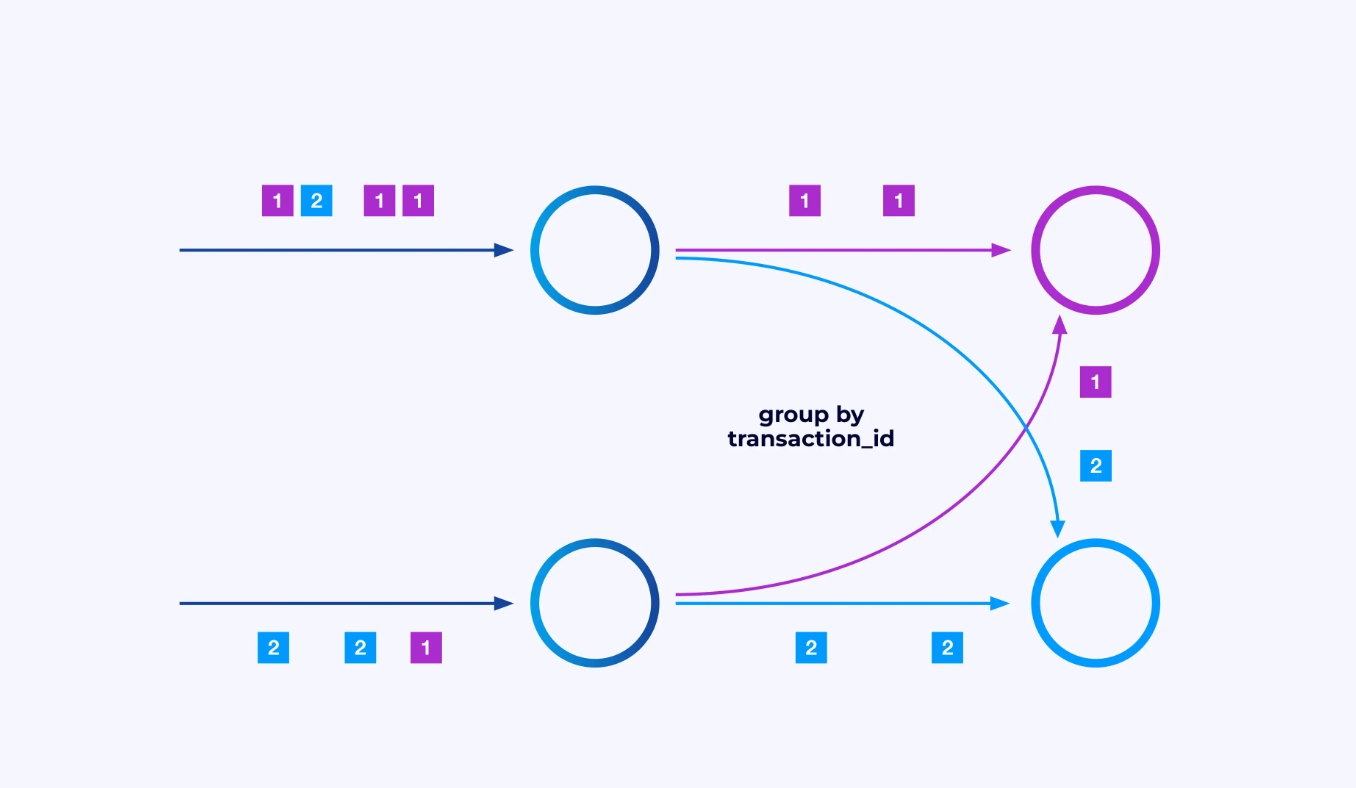
Às vezes, você desejará impor um esquema de particionamento específico nestas sub-streams para que os eventos sejam agrupados juntos de acordo com alguma lógica específica da aplicação. Por exemplo, se você estiver processando transações financeiras, você pode precisar arranjar para que todos os eventos de uma dada transação sejam processados pela mesma thread. Isto permitirá que você conecte juntos os vários eventos que ocorrem ao longo do tempo para cada transação
No Flink SQL, você faria isso com GROUP BY transaction_id, enquanto no DataStream API, você usaria keyBy(event -> event.transaction_id) para especificar este agrupamento ou particionamento. Em ambos os casos, isso aparecerá no gráfico de trabalho como uma rede de troca totalmente conectada entre dois estágios consecutivos do gráfico.
Estado
Operadores trabalhando em streams particionadas por chave podem usar o armazenamento de estado distribuído de chave/valor do Flink para persistir duravelmente o que quiserem. O estado para cada chave é local a uma instância específica de um operador e não pode ser acessado de outro lugar. As sub-topologias paralelas não compartilham nada — essa é uma característica crucial para a escalabilidade sem restrições.
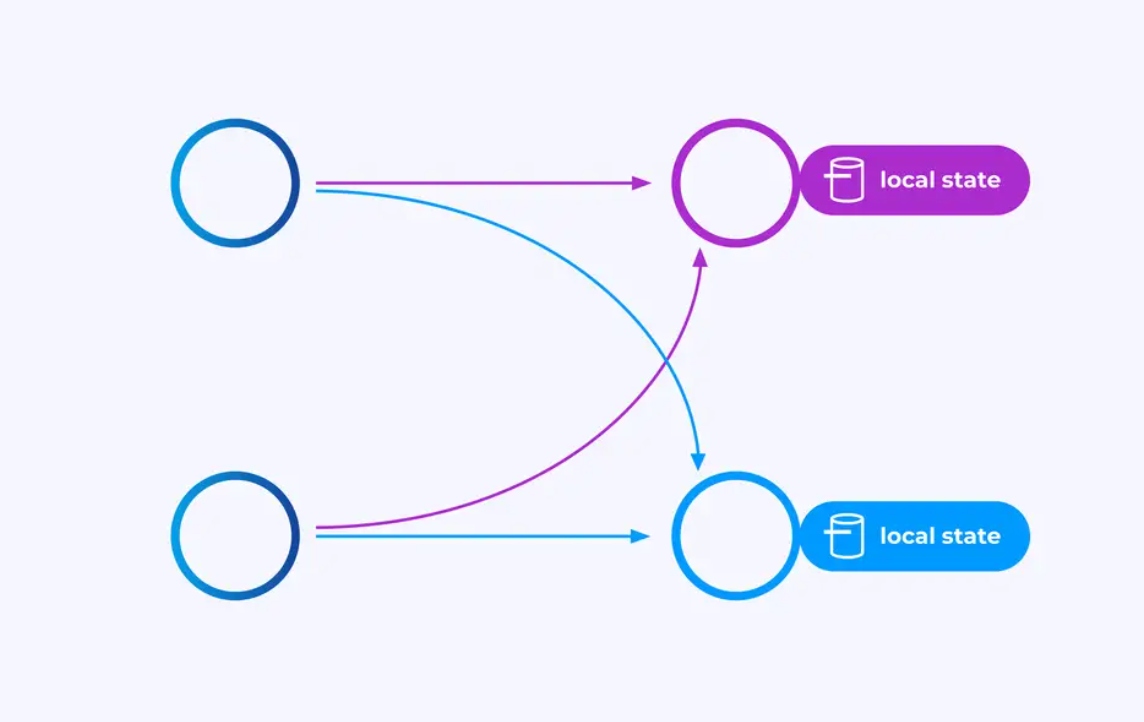
Um trabalho Flink pode ser deixado rodando indefinidamente. Se um trabalho Flink estiver continuamente criando novas chaves (por exemplo, IDs de transação) e armazenando alguma coisa para cada nova chave, então esse trabalho corre o risco de explodir porque está usando uma quantidade ilimitada de estado. Cada API do Flink está organizada em torno de meios para ajudar você a evitar explosões de estado desenfreadas.
Tempo
Uma maneira de evitar manter um estado por muito tempo é retê-lo apenas até um ponto específico em tempo. Por exemplo, se você quiser contar transações em janelas de 1 minuto, assim que cada minuto acabar, o resultado para esse minuto pode ser produzido, e esse contador pode ser liberado.
Flink faz uma distinção importante entre duas noções diferentes de tempo:
- Tempo de processamento (ou relógio de parede), que é derivado do tempo real do dia em que um evento está sendo processado
- Tempo de evento, que é baseado em timestamp gravados com cada evento
Para ilustrar a diferença entre eles, considere o que significa que uma janela de 1 minuto está completa:
- Uma janela de tempo de processamento está completa quando o minuto acaba. Isto é perfeitamente claro.
- Uma janela de tempo de evento está completa quando todos os eventos que ocorreram durante esse minuto foram processados. Isto pode ser complicado, pois Flink não consegue saber nada sobre eventos que ainda não foram processados. O melhor que podemos fazer é fazer uma suposição sobre quanto um fluxo de dados pode estar fora de ordem e aplicar essa suposição heurísticamente.
Captura de pontos de controle para recuperação de falhas
Falhas são inevitáveis. Apesar das falhas, Flink é capaz de fornecer garantias próximas a exatamente uma vez, o que significa que cada evento afetará o estado que Flink está gerenciando exatamente uma vez, como se a falha nunca tivesse ocorrido. Isso é feito tomando pontos de snapshot periódicos, globais e auto-consistentes de todos os estados. Esses snapshot, criados e gerenciados automaticamente por Flink, são chamados de checkpoints.
Recuperação envolve voltar para o estado capturado no ponto de verificação mais recente e realizar um reinício global de todos os operadores a partir desse ponto de verificação. Durante a recuperação, alguns eventos são reprocessados, mas o Flink consegue garantir a corretude garantindo que cada ponto de verificação é um snapshop global e self-consistent do estado completo do sistema.
Arquitetura do Sistema
As aplicações do Flink executam em clusters Flink, portanto, antes de colocar uma aplicação do Flink em produção, você precisará de um cluster para deploy-la. Felizmente, durante o desenvolvimento e teste, é fácil começar executando o Flink localmente em um ambiente de desenvolvimento integrado (IDE) como o IntelliJ ou Docker.
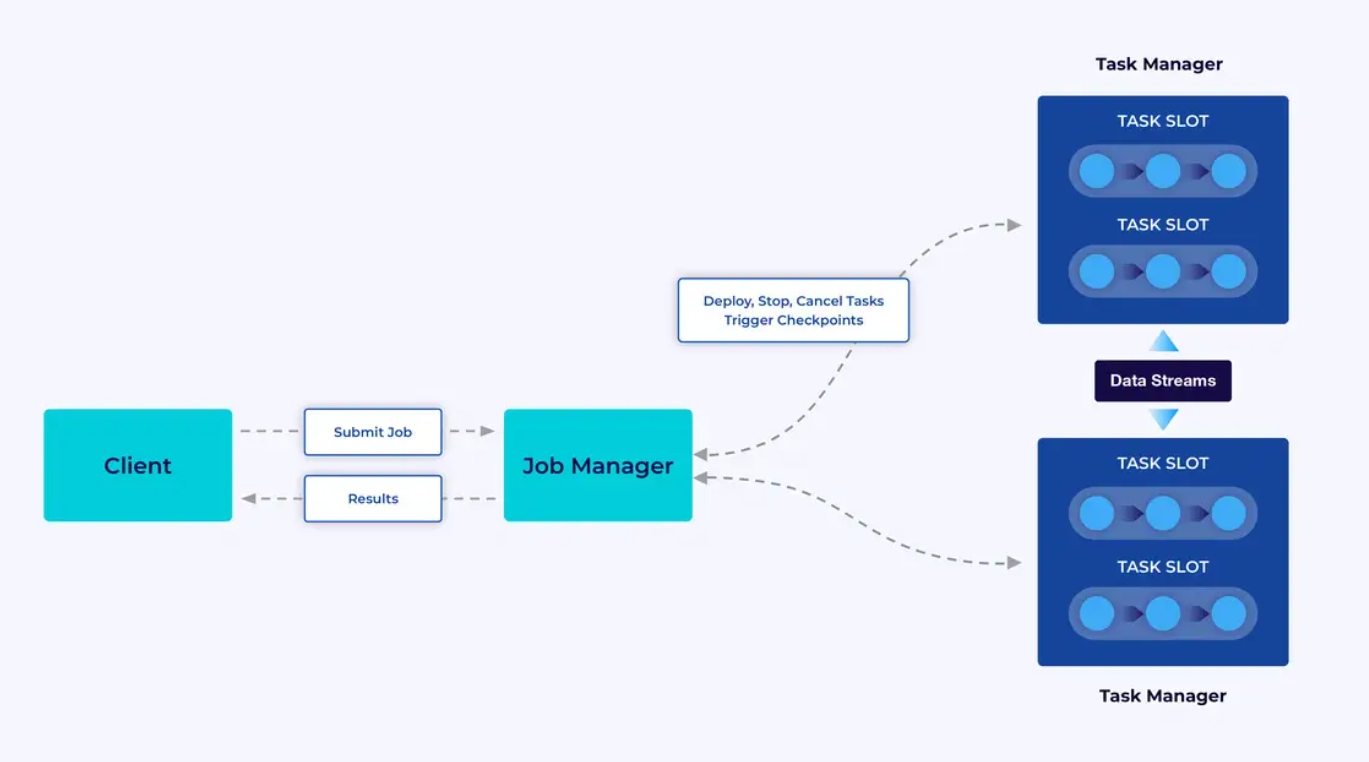
Um cluster Flink tem dois tipos de componentes: um Gerenciador de Trabalhos e um conjunto de Gerentes de Tarefas. Os gerentes de tarefas executam suas aplicações (em paralelo), enquanto o gerenciador de trabalhos age como um gateway entre os gerentes de tarefas e o mundo exterior. As aplicações são submetidas ao gerenciador de trabalhos, que gerencia os recursos fornecidos pelos gerentes de tarefas, coordena o checkpointing e fornece visibilidade no cluster em formato de métricas.
A Experiência do Desenvolvedor
A experiência como desenvolvedor do Flink depende, em certa medida, da escolha do API: ou o antigo, de nível inferior DataStream API ou o novo, relacional Table e SQL APIs.
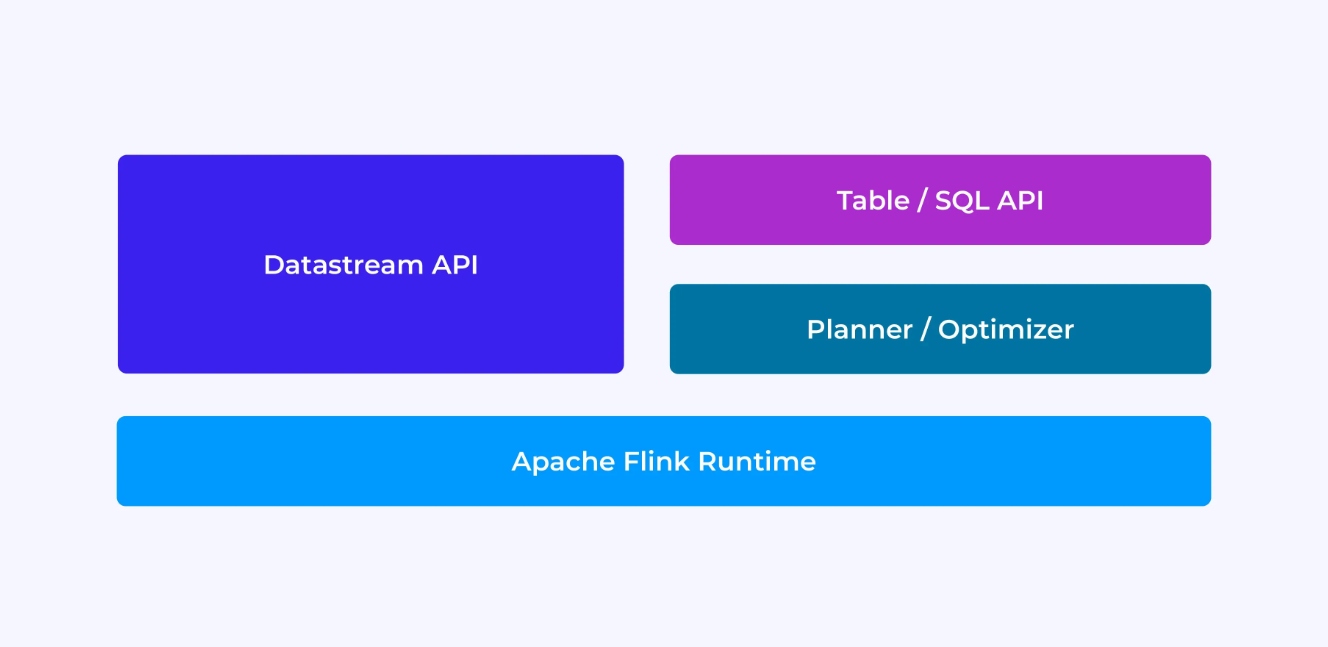
Quando você está programando com a API DataStream do Flink, você está pensando conscienciosamente sobre o que o runtime do Flink fará enquanto sua aplicação está sendo executada. Isso significa que você está montando o grafo de trabalho de um operador de cada vez, descrevendo o estado que você está usando juntamente com os tipos envolvidos e sua serialização, criando timers e implementando funções de callback para serem executadas quando esses timers são disparados, etc. A abstração central na API DataStream é o evento, e as funções que você escreve vão lidar com um evento de cada vez, conforme eles chegam.
Por outro lado, quando você usa a API Table/SQL do Flink, essas preocupações de nível baixo já foram cuidadas por você, e você pode se concentrar mais diretamente na lógica de negócios. A abstração central é a tabela, e você pensa mais em juntar tabelas para enriquecimento, agrupar linhas juntas para computar análise agregada, etc. Um planejador e otimizador de consulta internos cuidam dos detalhes. O planejador/otimizador faz um excelente trabalho de gerenciamento de recursos eficientemente, frequentemente superando o código escrito à mão.
Pense em algumas coisas antes de mergulhar nas detalhes: primeiro, você não precisa escolher entre a DataStream ou a Table/SQL API – ambas as APIs são interoperáveis e você pode combiná-las. Isso pode ser uma boa opção se você precisar de personalizações que não são possíveis na Table/SQL API. Mas outra boa opção para ultrapassar o que a Table/SQL API oferece de fábrica é adicionar algumas capacidades adicionais na forma de funções definidas pelo usuário (UDFs). Aqui, a SQL do Flink oferece muitas opções para extensão.
Construindo o Grafo de Trabalho
Independentemente da API que você use, o objetivo final do código que você escreve é construir o gráfico de trabalho que o runtime do Flink executará em seu nome. Isso significa que essas APIs estão organizadas em torno da criação de operadores e da especificação tanto do comportamento deles quanto das suas conexões entre si. Com a API DataStream, você está construindo diretamente o gráfico de trabalho, enquanto com a API Table/SQL, o planejador SQL do Flink faz isso por você.
Serializando Funções e Dados
No final, o código que você fornece ao Flink será executado de forma paralela pelos trabalhadores (gerentes de tarefas) em um cluster Flink. Para fazer isso acontecer, os objetos de função que você cria são serializados e enviados para os gerentes de tarefas onde são executados. Similarmente, os eventos próprios às vezes precisarão ser serializados e enviados pela rede de um gerente de tarefa para outro. Novamente, com a API Table/SQL você não precisa se preocupar com isso.
Gerenciando Estado
O runtime do Flink precisa ser avisado de qualquer estado que você espera que ele recupere em caso de falha. Para fazer isso funcionar, o Flink precisa de informações de tipo que possa usar para serializar e deserializar esses objetos (para serem escritos em e lidos de pontos de verificação). Você pode configurar opcionalmente este estado gerenciado com descritores de tempo de vida que o Flink usará para expirar automaticamente o estado assim que ele deixar de ser útil.
Com a API DataStream, você normalmente acaba gerenciando diretamente o estado necessário para sua aplicação (as operações internas da janela são a exceção a isso). Por outro lado, com a API de Tabela/SQL, essa preocupação é abstraída. Por exemplo, dada a consulta abaixo, sabe que algures no tempo de execução do Flink, alguma estrutura de dados deve manter um contador para cada URL, mas todos os detalhes são cuidados por você.
SELECT url, COUNT(*)
FROM pageviews
GROUP BY URL;Configuração e Disparo de Timers
Timers têm muitos usos em processamento de stream. Por exemplo, é comum que as aplicações do Flink precisejam reunir informações de muitas fontes de eventos diferentes antes de eventualmente produzir resultados. Os timers funcionam bem para casos onde é sensato esperar ( mas não indefinidamente) por dados que podem (ou não) chegar eventualmente.
Timers também são essenciais para a implementação de operações de janela baseadas em tempo. Ambos as APIs DataStream e Table/SQL têm suporte interno para Janelas e estão criando e gerenciando timers em seu nome.
Casos de Uso
Voltando às três categorias amplas de casos de uso de streamings introduzidas no início deste artigo, vejamos como elas se mapem ao que você acaba de aprender sobre o Flink.
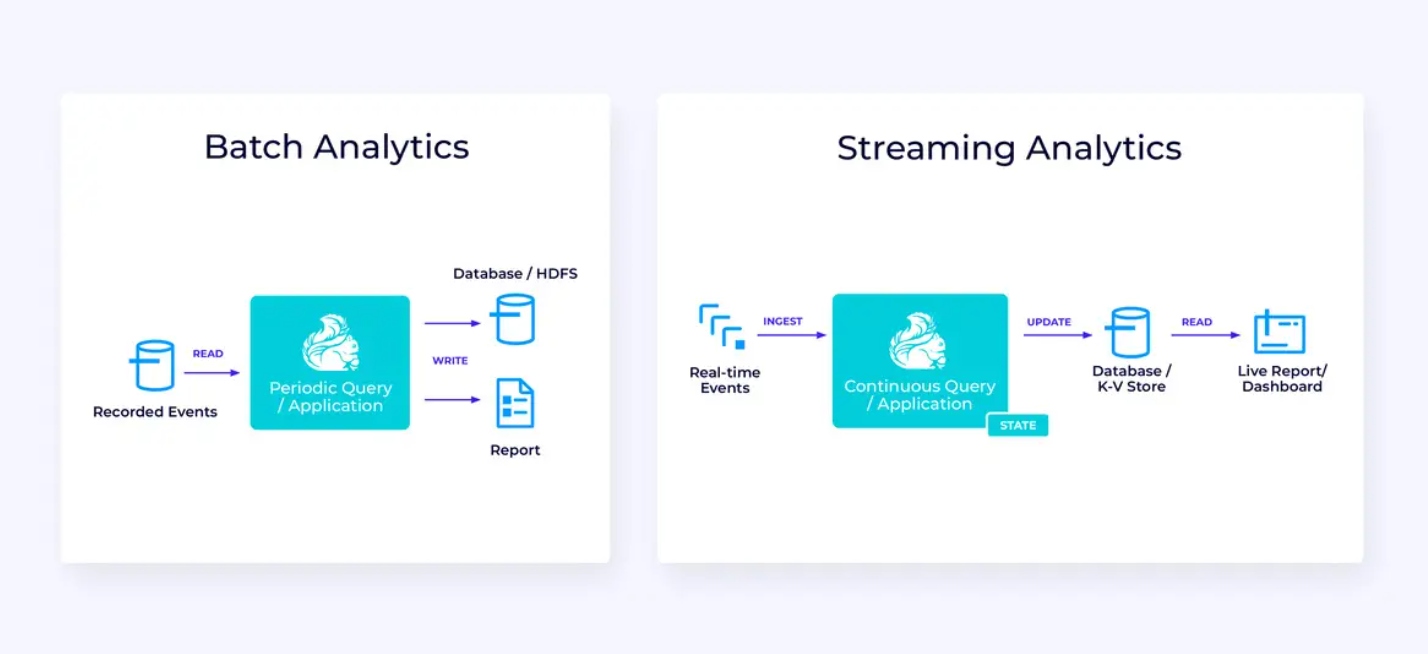
Pipeline de Dados em Streaming
Abaixo, à esquerda, está um exemplo de um trabalho tradicional de extração, transformação e carregamento em lote (ETL) que periodicamente lê de um banco de dados transacionais, transforma os dados e escreve os resultados para outro armazenamento, como um banco de dados, sistema de arquivos ou lago de dados.
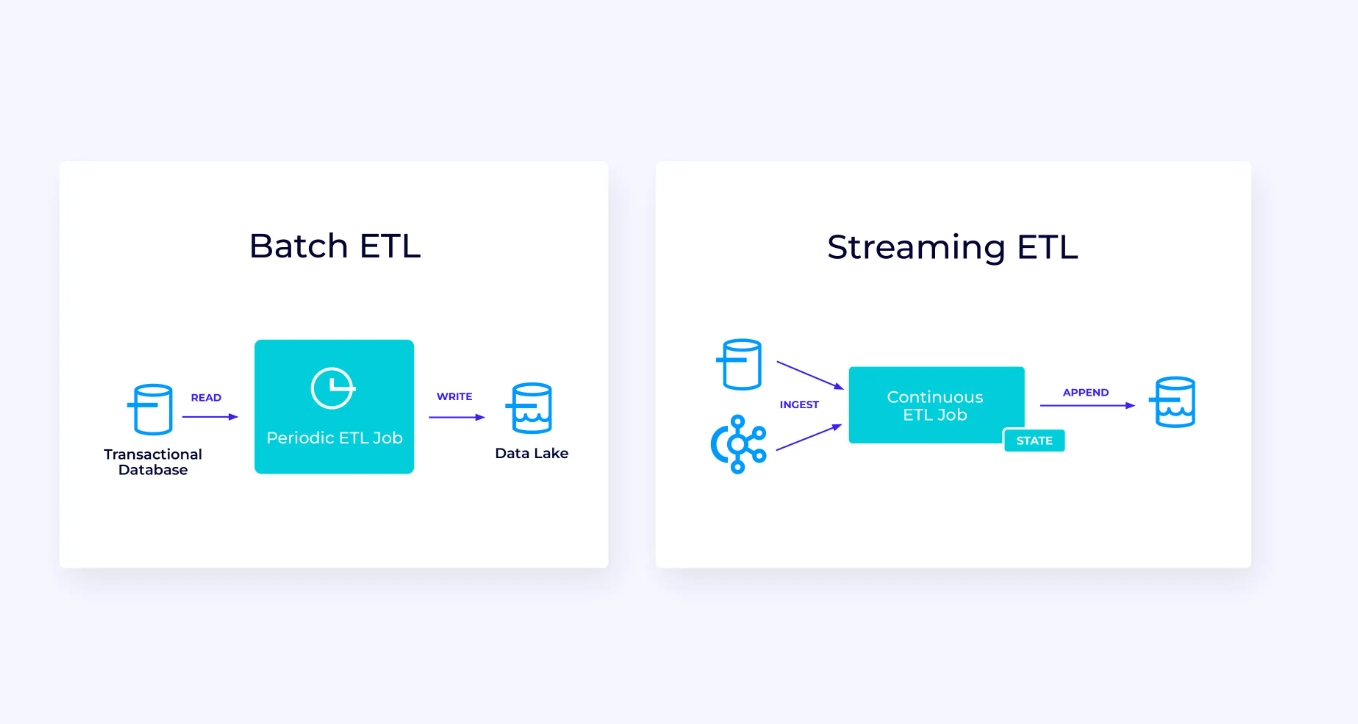
O pipeline streaming correspondente é superficialmente semelhante, mas há algumas diferenças significativas:
- O pipeline de streaming está sempre em execução.
- Os dados transacionais são entregues ao pipeline de streaming em duas partes: um carregamento em massa inicial do banco de dados, combinado com uma stream de captura de mudanças (CDC) que transporta as atualizações do banco de dados desde esse carregamento em massa.
- A versão streaming continuamente produz novos resultados assim que eles tornam-se disponíveis.
- O estado é gerenciado explicitamente para que possa ser recuperado robustamente em caso de falha. Os pipelines de ETL de streaming normalmente usam muito pouco estado. As fontes de dados mantêm controle exato de quanto do input já foi processado, normalmente na forma de deslocamentos que contam registros desde o início dos streams. As fontes usam transações para gerenciar suas escritas em sistemas externos, como bancos de dados ou Kafka. Durante o checkpointing, as fontes registram seus deslocamentos, e as fontes concluem as transações que carregam os resultados de terem lido exatamente até, mas não além, desses deslocamentos de origem.
Para este caso de uso, a API Table/SQL seria uma boa escolha.
Análise em Tempo Real
Em comparação com a aplicação de ETL de streaming, esta aplicação de análise de streaming tem algumas diferenças interessantes:
- Novamente, Flink está sendo usado para executar uma aplicação contínua, mas para esta aplicação, Flink provavelmente precisará gerenciar substancialmente mais estado.
- Para este caso de uso, é sensato para que o stream sendo processado seja armazenado em um sistema de armazenamento nativo de stream, como o Apache Kafka.
- Em vez de produzir periodicamente um relatório estático, a versão streaming pode ser usada para operar um painel dinâmico.
Novamente, a API de Tabela/SQL é usualmente uma boa escolha para este caso de uso.
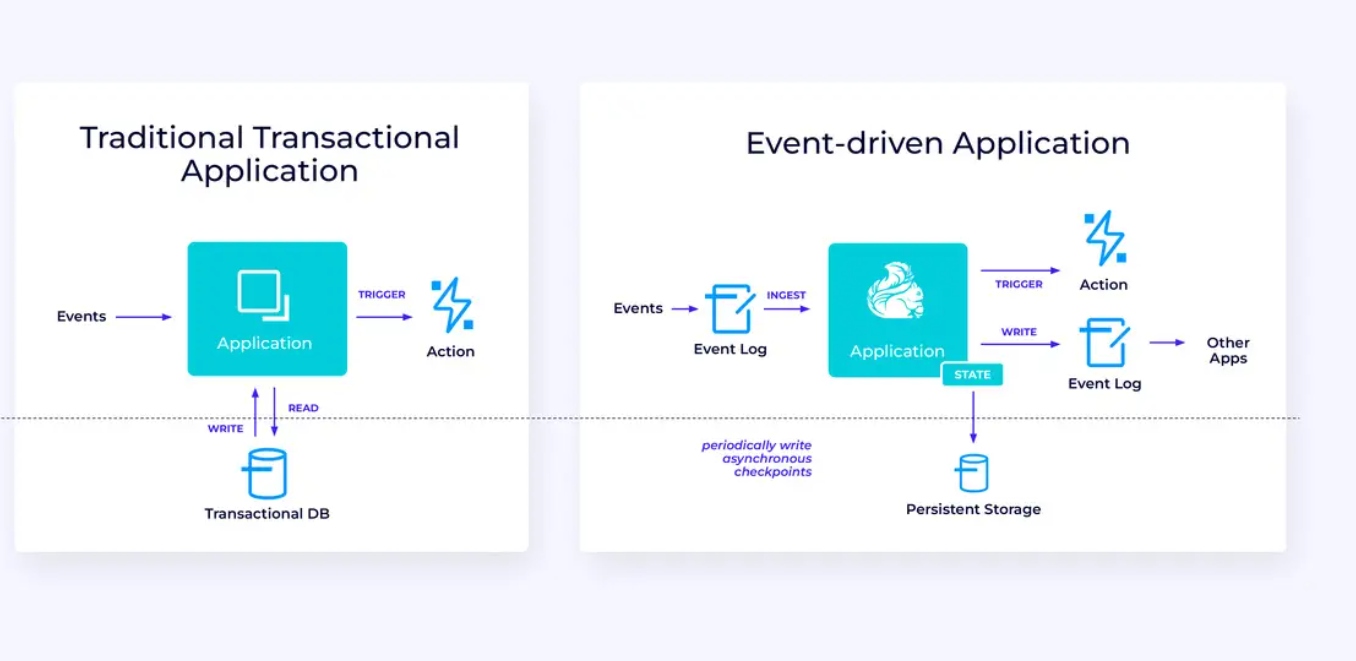
Aplicações Baseadas em Eventos
Nossa terceira e última família de casos de uso envolve a implementação de aplicações baseadas em eventos ou microsserviços. Muito já foi escrito sobre este tópico; este é um padrão de projeto arquitetural que oferece muitos benefícios.
Flink pode ser um ótimo candidato para essas aplicações, especialmente se você precisar do tipo de performance que Flink pode fornecer. Em alguns casos, a API de Tabela/SQL tem tudo o que você precisa, mas, muitas vezes, você precisará da flexibilidade adicional da API DataStream para, pelo menos, parte do trabalho.
Começando com Flink
Flink fornece um framework poderoso para construir aplicações que processam fluxos de eventos. Como covermos, algumas das ideias podem parecer iniciais ao princípio, mas, assim que você estiver familiarizado com a maneira como Flink está projetado e funciona, o software é fácil de usar e os benefícios de conhecer Flink são significativos.
Como próximo passo, siga as instruções na documentação do Flink, que o guiará pelo processo de download, instalação e execução da versão estável mais recente do Flink. Pense nos casos de uso amplos que discutimos – pipeline de dados moderno, análise em tempo real e microserviços baseados em eventos – e como esses podem ajudar a resolver um desafio ou aumentar o valor para sua organização.
Transmissão de dados é um dos setores mais empolgantes da tecnologia empresarial hoje em dia, e o processamento de stream com Flink torna-o ainda mais poderoso. Aprender com Flink será benéfico não só para sua organização quanto para sua carreira, pois o processamento de dados em tempo real está se tornando cada vez mais valioso para as empresas em todo o mundo. Então, explore Flink hoje e veja o que esta tecnologia poderá ajudá-lo a alcançar.
Source:
https://dzone.com/articles/apache-flink-101-a-guide-for-developers