













تقريراً في السنوات الأخيرة، أصبح أباتشي فلينك القاعدة الواضحة لمعالجة السلك الآنية. معالجة السلك هي نموذج لبناء الأنظمة يعامل سلوكيات الأحداث (تسلسل من الأحداث في الزمن) كأكبر العناصر البنائية. معالج السلك كالفلينك يستهلك سلوكيات الدخول المنتجة من مصادر الأحداث وينتج سلوكيات الخروج التي يستهلكها الوصلات (تخزن الوصلات النتائج وتجعلها متاحة للمعالجة التالية).
اسماء منازعة مثل أمازون ونيتفليكس وأوبر تعتمد على فلينك لتزود خطوط البيانات التي تعمل على مستوى عظيم في قلب أعمالهم، ولكن فلينك يلعب دوراً رئيسياً أيضاً في العديد من الشركات الصغيرة التي تملك الاحتياجات التي تسمح بالرد السريع على الأحداث الحاسمة للأعمال.
ماذا يستخدم فلينك ل؟ الحالات الشائعة تندرج تحت هذه الفئات التيلات:
|
خطوط بيانات السلك |
التحليلات الآنية |
تطبيقات تقوم بالحدوثات |
|---|---|---|
|
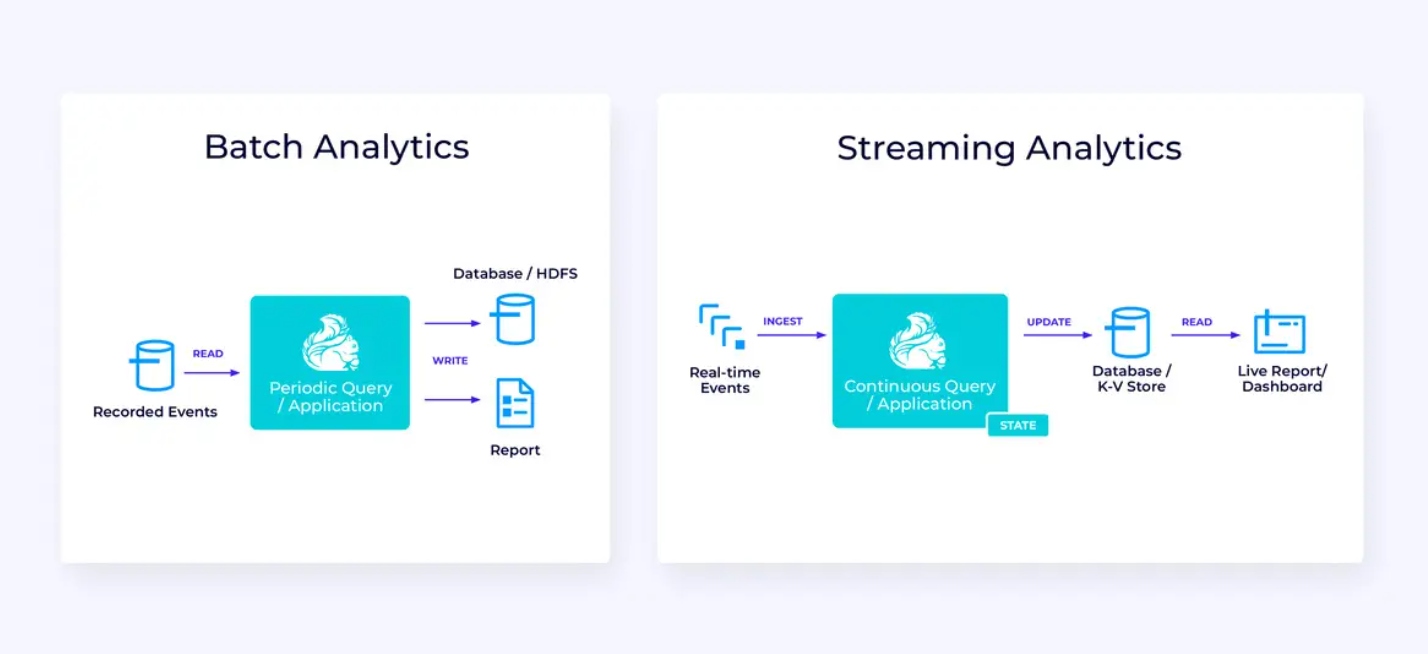
تستمر في استهلاك وتغذية وتحويل سلوكيات البيانات، وتحميلهم إلى الأنظمة الوجهة للتصرف في وقتها (مقابل معالجة الدفعات). |
تستمر في إنتاج وتحديث النتائج التي يتم عرضها وتقديمها للمستخدمين وفقاً لاستهلاك سلوكيات البيانات الآنية. |
تكتشف الأنماط وتستجيب للأحداث الواردة من خلال تشغيل الحسابات، تحديثات الحالة أو إجراءات خارجية. |
|
بعض الأمثلة تشمل:
|
بعض الأمثلة تشمل:
|
بعض الأمثلة تشمل:
|
Flink يشمل:
- دعم قوي للمستخدمين الجماعي بحجم التحكم المطلوب من عمليات التسويق العالمية
- ضمانات قوية للدقة المناسبة وإعادة التعافي
- دعم للجافا، البايثون والسيكل، مع دعم موحد للمعالجة الباتش والتستيم
- Flink مشروع مفتوح المصدر متقدم من مؤسسة Apache Software Foundation وله مجموعة من المجموعة النشطة والدعمية جدا.
يُصف Flink أحيانًا بأنه معقد وصعب التعلم. نعم، تعمل التطبيقات الجزء التنفيذي معقدة لكن ذلك لا يجب أن يكون مفاجئًا لأنه يحل بعض المشاكل الصعبة. قوائم البرمجيات Flink قد تكون تحديدًا صعبة التعلم لكن هذا يتم
قامت الفريم ورقة التعلم بتجعيل المسيرة التعلمية لفريم فليك أسهل بشكل كبير من خلال وضعها أساسياتها الرئيسية التي تحكم في تصميمها. في مرحلة ما ، وأثناء تأكدك من طريقة تكوين فريم فليك والمسائل التي يتعامل معها جهازها التشغيلية ، ينبغي عليك أن تبدأ بالإعتقاد أن تفاصيل واجهات فريم فليك هي نتائج واضحة لمجموعة قليلة من المبادئ الرئيسية بدلاً عن مجموعة من التفاصيل الغامرة التي يتوجب أن تتذكرها.
هذا المقال يهدف إلىجعل رحلة تعلم فريم فليك أسهل بشكل كبير عن طريق توصيف المبادئ الرئيسية التي تحكم في تصميمه.
فريم فليك يحمل بعض الأفكار الكبيرة القليلة
التسجيلات
فريم فليك هو إطار لبناء التطبيقات التي تعالج التسجيلات التي تكون سلسلة محددة أو غير محددة من الأحداث.
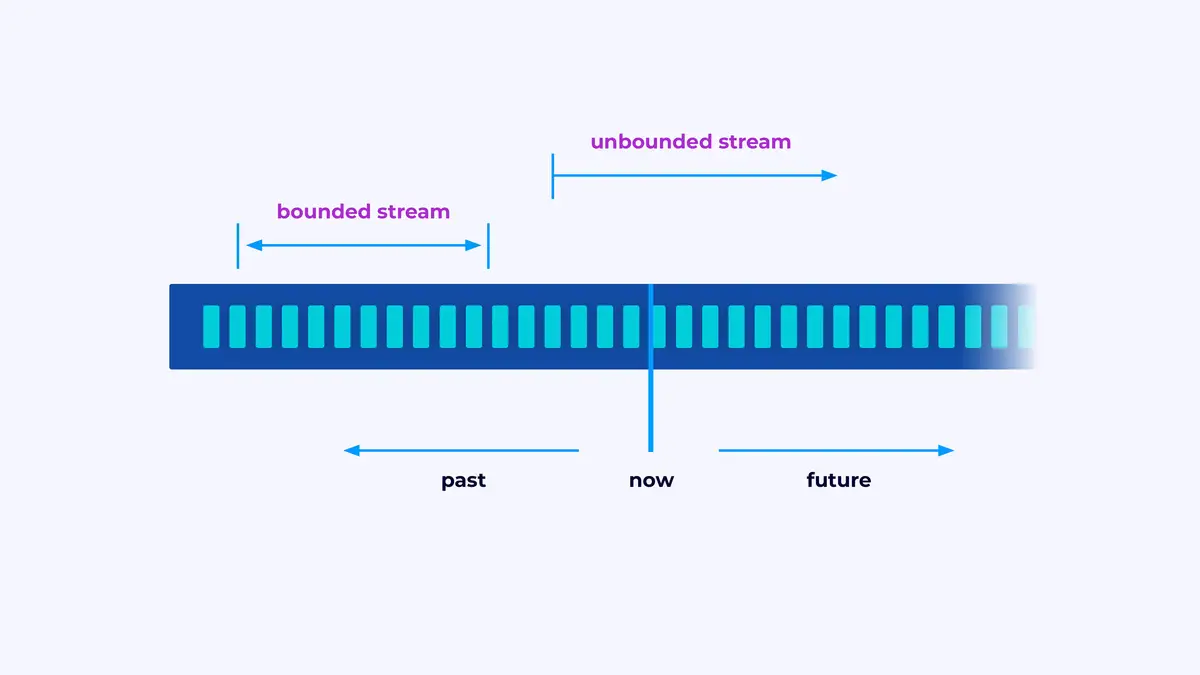
تعتبر تطبيق فريم فليك قناة تحرير البيانات. ستتدفق أحداثك من خلال هذه القناة وستتم تحكم فيها من خلال البرمجيات التي تكتب. نسمي هذه القناة الجيد الرؤية، والعناصر في هذه الرؤية (أو بعبارة أخرى، المراحل في خط التحكم) تسمى معالجون.
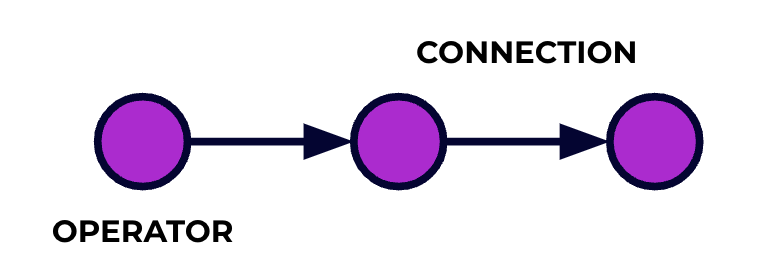
تصف البرمجيات التي تكتب بواسطة one of Flink’s APIs الرؤية الجيد، بما في ذلك تصرف المعالجون وتواصلهم.
التعامل الموازي
يمكن لكل معالج أن يكون عدة من النسخ الموازية، كله
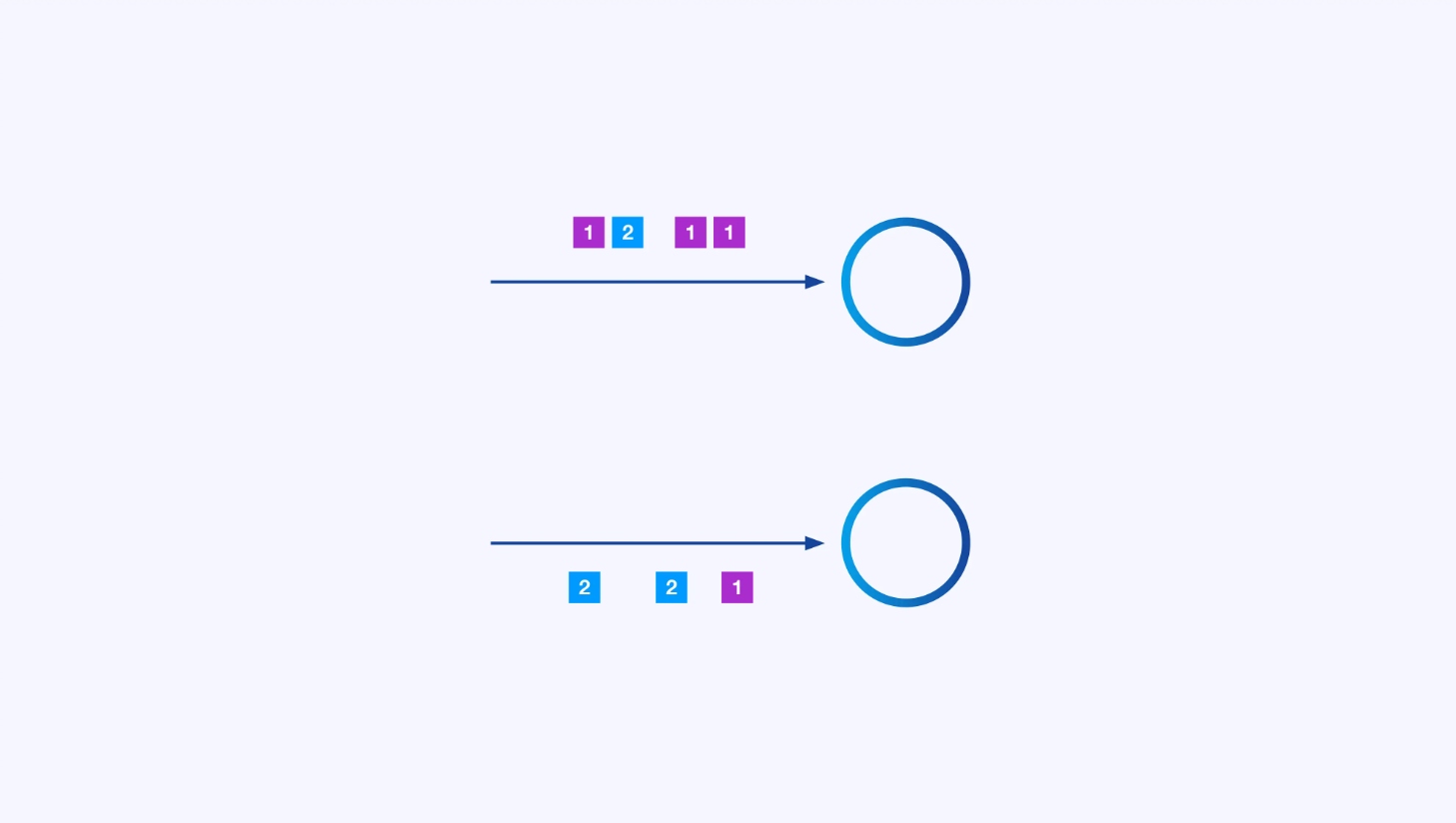
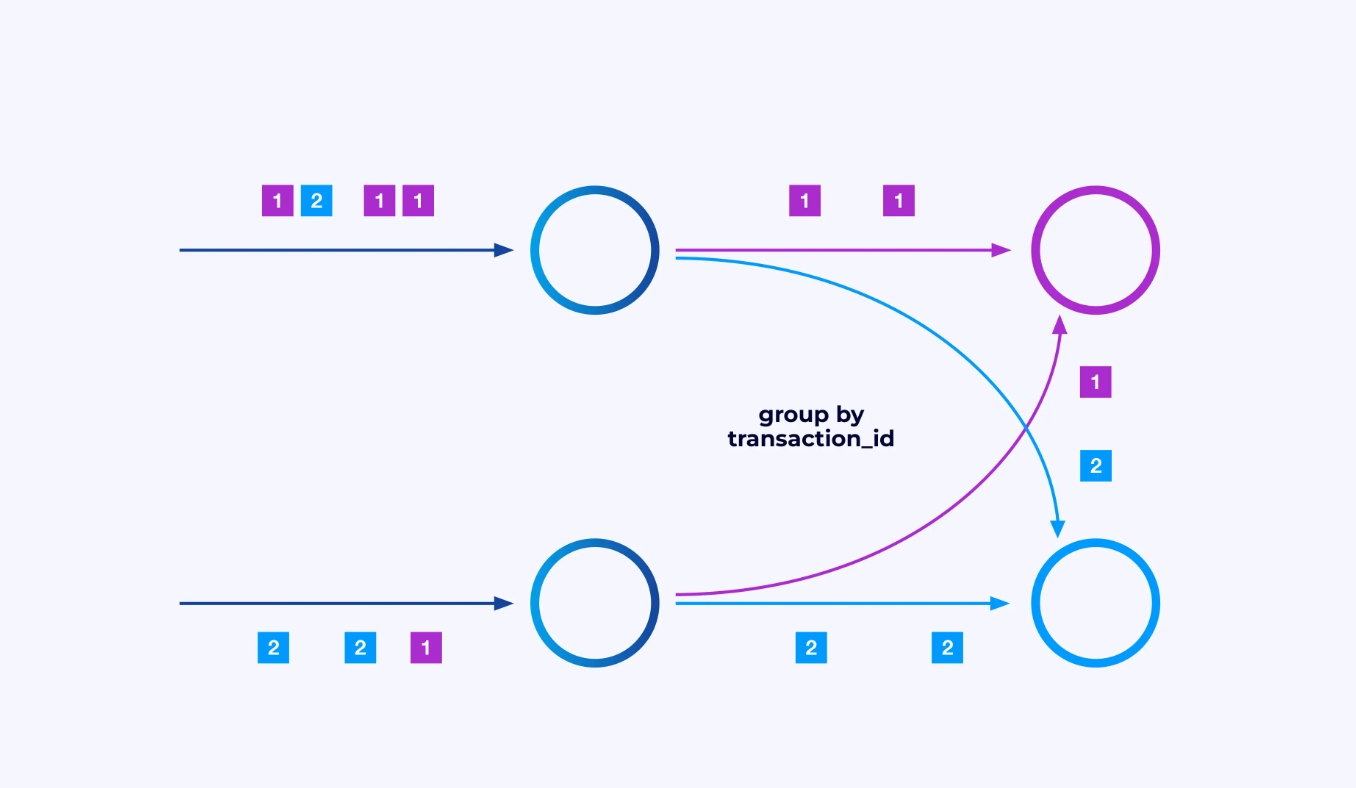
تحتاج أحياناً إلى تفريغ نظام الأجزاء المحدد على تلك القنوات الفرعية بحيث تتمجمع الأحداث وفقاً لمعالجة خاصة بتطبيق. على سبيل المثال، إذا كنت تعالج المعاملات المالية، قد تحتاج إلى ترتيب كل حدث لأي معاملة ليتم تعاليجه بنفس الخيال. هذا سيسمح لك بربط الأحداث المختلفة التي تحدث على مدى الوقت لكل معاملة
في Flink SQL، ستفعل هذا بGROUP BY transaction_id، بينما في API DataStream ستستخدم keyBy(event -> event.transaction_id) لتحديد هذه الجمعية أو تقسيم البيانات. في الحالتين، سيظهر هذا في جراف التشغيل كشبكة تبادل شاملة بين مرحلتين متتاليتين من الجراف.
الحالة
يمكن للعمليات التي تعمل على تدفقات الأجزاء المفردة إستخدام مخزن القيمة/المفتاح الموزع لفلينك للحفاظ على ما يريد بشكل دائم. الحالة لكل مفتاح محلية لمثيل محدد من عملية العمل، ولا يمكن الوصول إليها من أي مكان آخر. البوصلات الفرعية الموزعة لا تتشارك أي شئ — هذا أمرٌ حاسم للإستقرار الغير محدود.
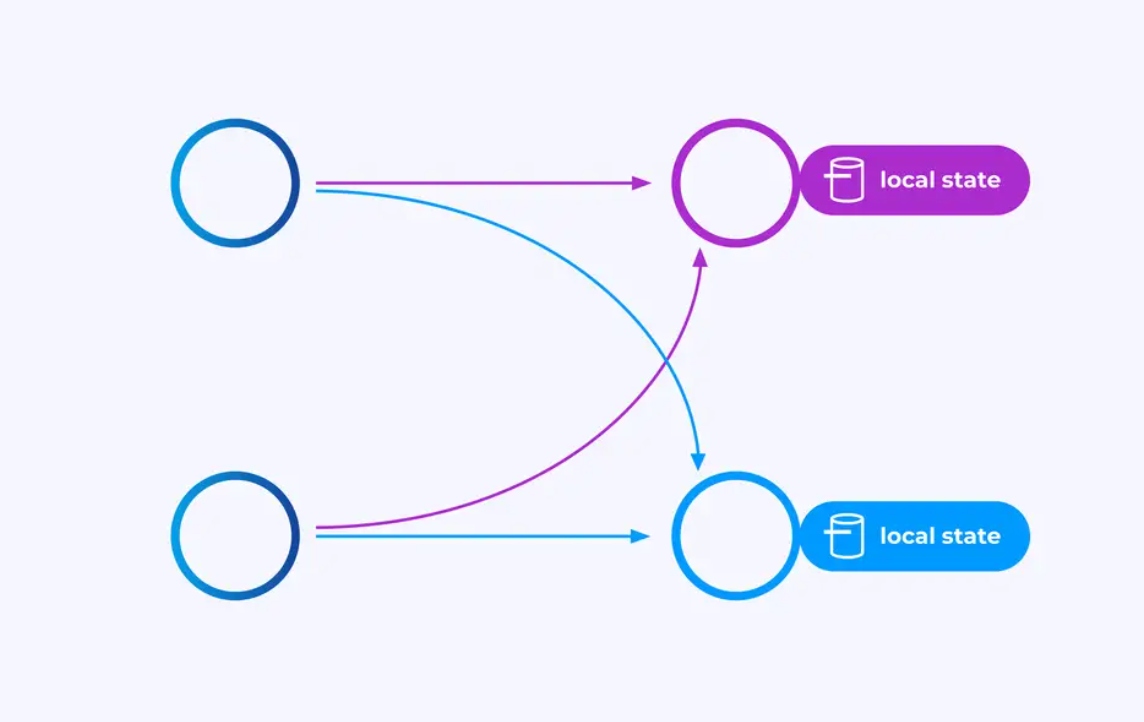
قد يتم ترك عمل فلينك ليشتغل للأبد. إذا كان عمل فلينك يصنع بشكل مستمر مفاتيح جديدة (مثل أيدي المعاملات) ويحفظ شيئاً لكل مفتاح جديد، فإن ذلك العمل يخاطر بالانفجار بسبب استخدام كمية لا نهائية من الحالة. كل من APIs فلينك هو منظم حول توفير طرق لمساعدتك في تجنب انفجار الحالة الهائل.
الوقت
إحدى الطرق التي يمكنك تجنب الاستمرار في الحفاظ على وضع لمدة طويلة هي بموجب حفظه لمدة وقت معين فقط. على سبيل المثال إذا كنت تريد حساب المعاملات في نافذة بمدة 60 دقيقة ، حينما ينتهي كل دقيقة ، يمكن إنتاج نتيجة لتلك الدقيقة ويمكن تحرير هذا الشامل.
فلينك يقوم بتفرقة مهمة بين معاني الوقت العامل:
- الوقت العامل (أو الساعة العاملة) وهو الذي يأتي من وقت اليوم الحقيقي حين يتم معالجة ال事件
- وقت الحدث وهو المبني على تواصل التوقيت مع كل حدث
لإظهار فرقهما ، فكر في ما يعنيه أن نافذة بمدة 60 دقيقة تكمل تمامًا:
- تكمل نافذة الوقت العامل عندما ينتهي الدقيقة. هذا ببساطة.
- تكمل نافذة وقت الحدث عندما يتم معالجة جميع الحدود التي حدثت خلال تلك الدقيقة. قد تكون هذا الأمر صعبًا لأن فلينك لا تعرف أي شيء عن الحدود التي لم تمعلج بعد. أفضل ما يمكننا فعله هو أن نتخمين مدى توأماً الجداول قد تكون ونطبق هذا التخمين إلهاميًا.
الاختبار لإستعادة الفشل
الفشلات من المؤكد. بالرغم من الفشلات ، يمكن لفلينك تأمين ضمانات تقريبًا مرة واحدة بالفعل ، ما يعني أن كل حدث سيؤثر على الوضع الذي يدارك فلينك بمرة واحدة فقط ، كما لو أن الفشل لم يحدث. إنها ت
التعافي يتضمن العودة إلى الوضع الذي تم تقاطه في النقطة الأخيرة للتفريغ وإجراء إعادة بدء عامة لجميع موظفي الأوامر من تلك النقطة. أثناء التعافي يتم تعامل بعض الأحداث مجدداً ، لكن Flink قادر على ضمان الدقة من خلال تأكد أن كل نقطة التفريغ هي مستند عالمي ومتكامل لحالة النظام بأكمله.
هيكل النظام
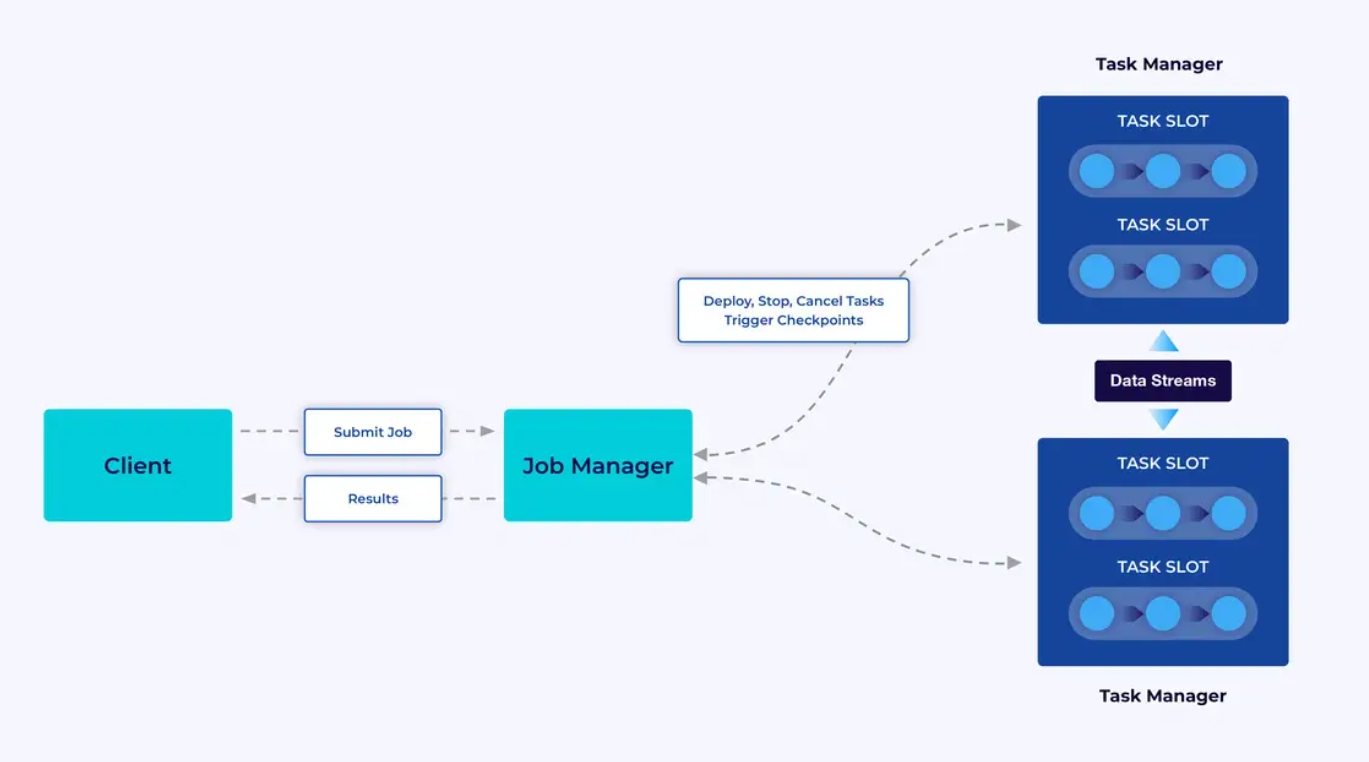
تشتغل التطبيقات Flink في مجموعات Flink، لذا قبل أن تضع تطبيق Flink في الإنتاج، سوف تحتاج لمجموعة لتوجيه فيها. بالمناسبة، يمكنك بسيط البدء أثناء التطوير والتجارب بتشغيل Flink محليًا في 环境 التطوير المتكامل (IDE) مثل IntelliJ أو Docker.
تحتوي مجموعة Flink على قطعتين من المكونات: مدير الوظائف ومجموعة من المديرين المهنيين. يقوم المديرين المهنيين بتشغيل تطبيقك (بشكل موازي) بينما يتولى المدير الوظائف دور البوابة بين المديرين المهنيين والعالم. يقدم التطبيقات للمدير الوظائف، وهو يدير الموارد التي يقدمها المديرين المهنيين، ويتنظم التفريغ، ويوفر برنامج المعلومات النظامية للمجموعة بوجه الإحصاءات.
تجارب المطورين
ستحصل على تجربة مختلفة كما مطور Flink وهذه تعتمد في حد ما على تختيارك لأي من الAPI القديم وأقلي مستوى DataStream أو الAPI الجديد والقائم على التنظيم Table والSQL.
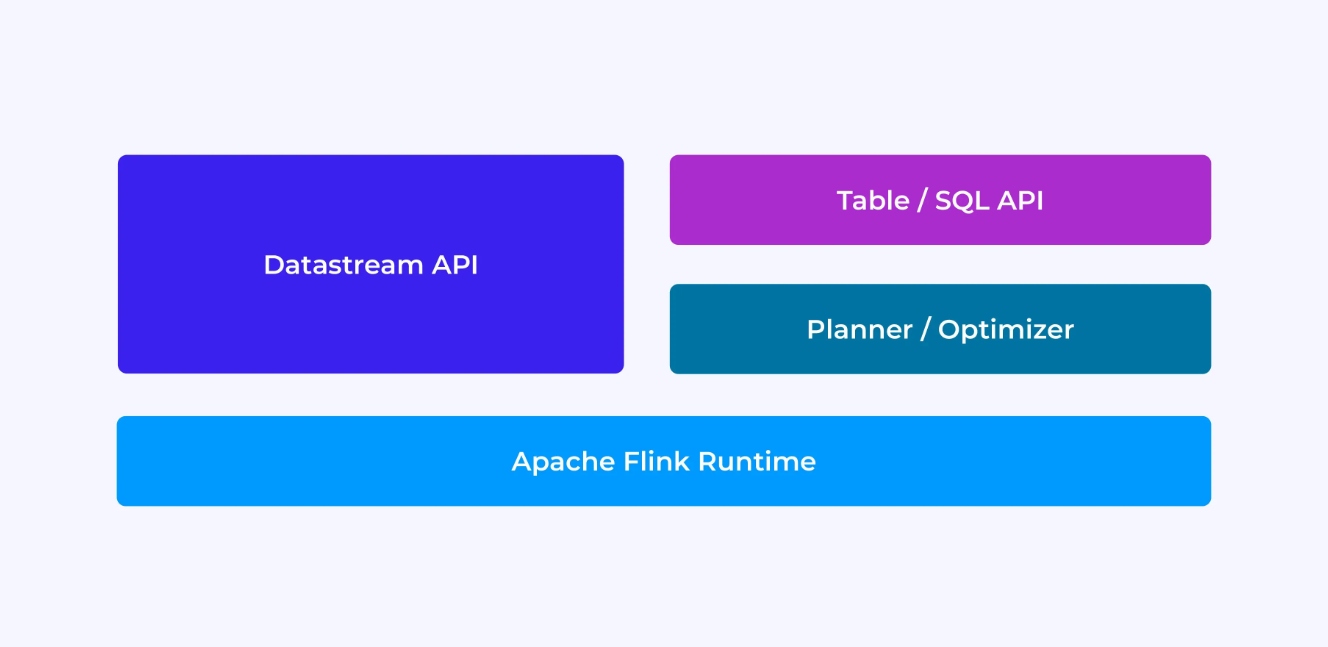
تتصور بينما تبرمج بواسطة API DataStream لـFlink، أنك تفكر بوعي فيما سيفعله إنتظام Flink أثناء تشغيل تطبيقك. هذا يعني أنك تبني جراف الوظيفة خطوة بخطوة، تصف الحالة التي تستخدمها بما فيها الأنواع المعنية وتسلسلها، وتنشئ المواقيت، وتنفذ الوظائف الرد الفنكية التي ستُنفذ عند تحفيز تلك المواقيت، إلخ. الابعاد الأساسية في API DataStream هي الحدث، والوظائف التي تكتبها ستتعامل مع حدث واحد في كل مرة، وفقاً لوصوله.
من ناحية أخرى، عندما تستخدم API Table/SQL لـFlink، تتم الإهتمام بتلك القليل من المستويات الباسية بواسطة النظام، ويمكنك التركيز بشكل مباشر على منطقك الصناعي. الابعاد الأساسية هي الجدول، وتفكر بشكل أكبر فيما يتعلق بدمج الجداول للتغذية، وجميع الصفوف معاً لحساب التحليلات المجموعة، إلخ. يتم الإهتمام بالتفاصيل بواسطة مخطط الاستعلامات SQL الداخلي ومحسن. يؤدي مخطط/محسن الأمر الى إدارة الموارد بكفاءة، وغالباً ما يعطي أداءاً أفضل من الشفرة المكتوبة باليد.
بضعة أفكار أخرى قبل الغوص في التفاصيل: أولاً، ليس عليك أن تختار DataStream أو API Table/SQL — كلا الAPI قابلين للتواصل، ويمكنك تركيبهم. قد يكون ذلك طريقة جيدة إذا كنت بحاجة إلى بعض التخصيصات التي لا تمكن منها API Table/SQL. ولكن طريقة أخرى جيدة للتخطي بما يقدمه API Table/SQL مباشرة هي إضافة بعض القدرات الإضافية بصورة функциات معرفة من قبل المستخدم (UDFs). هنا، يوفر SQL لـFlink الكثير من الخيارات للتوسيع.
بناء جراف الوظيفة
ومهما كانت الAPI التي تستخدمها، فإن هدف البرمجيات التي تكتب هو بناء جهاز العمل التي ستقوم بتنفيذها مجالد التشغيل الفلينكي بناءً لك. هذا يعني أن هذه الAPI منظمة حول خلق المفاتيح وتحديد سلوكهم وتواصلهم مع بعضهم البعض. مع API DataStream، تبني مباشرة جهاز العمل، بينما مع API Table/SQL، يتم إدارة ذلك من قِبل مخطط الSQL الفلينكي.
تسيير المادة والمعاملات
في النهاية، البرمجيات التي تقدم للفلينك ستتم تنفيذها بتوازن من قبل العمال (المديرين المهمات) في مجموعة الفلينك. لجعل هذا الحدث ، تتم تسيير الأشياء التي تنشأ من الموافقات وتمتلك بياناتها وتم إرسالها إلى المديرين المهمات حيث يتم تنفيذها. بما في ذلك ، قد تتوجب في بعض الأحيان تسيير الأحداث نفسها وإرسالها عبر الشبكة من مدير مهمات لآخر. مرة أخرى ، لن تتوجب عليك تفكير بشأن ذلك بواسطة API Table/SQL.
إدارة الحالة
يتوجب على الجهاز التشغيلي الفلينكي أن يكون واعيًا بأي حالة تتوقع إنتاجها لإستعيدتها في حالة فشل. لجعل هذا العمل يعمل ، تحتاج فلينك إلى معلومات النوع التي يمكنها استخدامها لتسيير وتكرار الأشياء هذه (ليتم كتابتها في النقاط التأكيدية وقراءتها منها). يمكنك تكوين هذه الحالة المدارة بخصائص الأمد الزمني إختيارية تستخدم من قِبل فلينك لتنقلب الحالة بشكل تلقائي بمجرد
مع API DataStream، في العادة تنتهي بإدارة مباشرة الحالة التي تحتاجها تطبيقك (عمليات النافذة الداخلية هي الاستثناء الوحيد لذلك). من ناحية أخرى، مع API Table/SQL، يتم تجريد هذا الشأن. على سبيل المثال، مع سؤال كالتالي، تعرف أنه في مكان ما في نظام Flink يجب أن تحتفظ بمؤشر لكل URL، ولكن تتم الإعتناء بتفاصيلها بدلاً عنك.
SELECT url, COUNT(*)
FROM pageviews
GROUP BY URL;إعداد وتشغيل المؤقتات
تستخدم المؤقتات لأغراض متعددة في معالجة البيانات السريعة. على سبيل المثال، من الشائع أن تحتاج تطبيقات Flink لجمع المعلومات من مصادر حدث مختلفة قبل إنتاج النتائج في النهاية. تعمل المؤقتات جيداً في الحالات التي يمكن الانتظار فيها (ولكن ليس للأبد) للبيانات التي قد لا تأتي أو تأتي بعد فترة.
تلك المؤقتات أيضاً أساسية لتنفيذ عمليات النوافذ القائمة على التوقيت. كلا من DataStream و API Table/SQL لديها دعم داخلي للنوافذ وتنشئ وتدير المؤقتات من أجلك.
حالات الاستخدام
في العودة إلى الفئات العامة الثلاثة لحالات معالجة البيانات السريعة التي تم ذكرها في بداية هذه المقالة، دعونا نرى كيف تتوافق مع ما تعلمته حديثاً عن Flink.
أنبوب البيانات السريعة
أسفله، على اليسار، هو مثال لوظيفة ETL التقليدية التي تقوم بتحميلها باستمرار من قاعدة بيانات معتمدة على الصفقات، تحويل البيانات، وتكتب النتائج إلى مخزن بيانات آخر، مثل قاعدة بيانات أو نظام الملفات أو بحيرة البيانات.
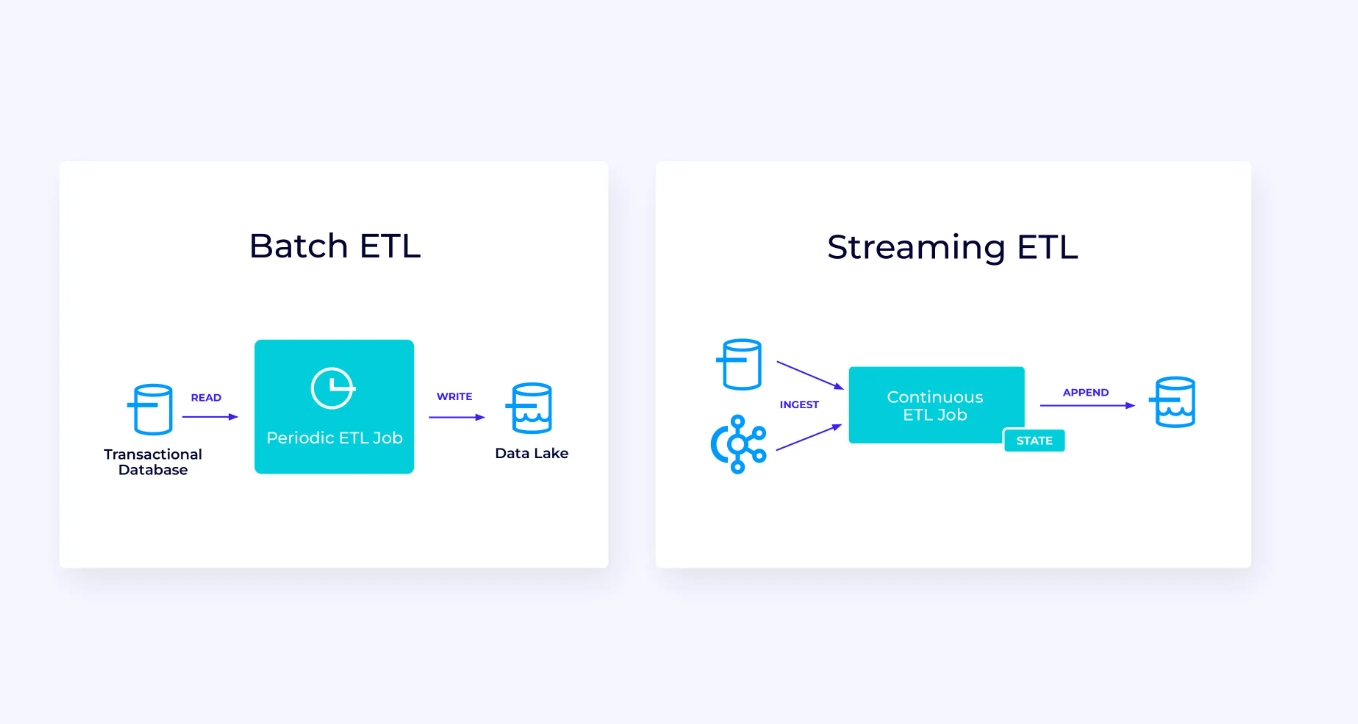
الأنبوب التي تتبادله معها البيانات السريعة تبدو مشابهة جداً، ولكن لها فروقات كبيرة:
- يكون خط أنابيب التدفق قيد التشغيل دائمًا.
- يتم تسليم بيانات المعاملات إلى خط أنابيب التدفق في جزأين: تحميل أولي مجمّع من قاعدة البيانات، بالإضافة إلى تدفق التقاط بيانات التغيير (CDC) الذي يحمل تحديثات قاعدة البيانات منذ ذلك التحميل المجمّع.
- يُنتج إصدار التدفق نتائج جديدة باستمرار بمجرد توفرها.
- تتم إدارة الحالة بشكل واضح بحيث يمكن استردادها بشكل قوي في حالة حدوث فشل. عادةً ما تستخدم خطوط أنابيب ETL المتدفقة القليل جدًا من الحالة. حيث تقوم مصادر البيانات بتتبع مقدار المدخلات التي تم استيعابها بالضبط، وعادةً ما يكون ذلك في شكل إزاحات تقوم بحساب السجلات منذ بداية التدفقات. تستخدم المصارف المعاملات لإدارة عمليات الكتابة إلى الأنظمة الخارجية، مثل قواعد البيانات أو كافكا. أثناء عملية التدقيق، تسجل المصادر إزاحاتها، وتلتزم المصارف بالمعاملات التي تحمل نتائج القراءة حتى إزاحة المصدر تلك بالضبط، ولكن ليس بعدها،
بالنسبة لحالة الاستخدام هذه، ستكون واجهة برمجة تطبيقات Table/SQL خيارًا جيدًا.
التحليلات في الوقت الحقيقي
مقارنةً بتطبيق ETL المتدفق، فإن تطبيق التحليلات المتدفقة هذا لديه بعض الاختلافات المثيرة للاهتمام:
- ومرة أخرى، يتم استخدام Flink لتشغيل تطبيق مستمر، ولكن بالنسبة لهذا التطبيق، ربما يحتاج Flink إلى إدارة حالة أكثر بكثير.
- بالنسبة لحالة الاستخدام هذه، من المنطقي أن يتم تخزين الدفق الذي يتم استيعابه في نظام تخزين أصلي للدفق، مثل Apache Kafka.
- بدلاً من إنتاج تقرير ثابت بشكل دوري، يمكن استخدام إصدار البث لتشغيل لوحة معلومات مباشرة.
مجدداً، يعتبر الAPI للجدول/SQL خيار جيد عامًا لهذه الحالة المستخدمة.
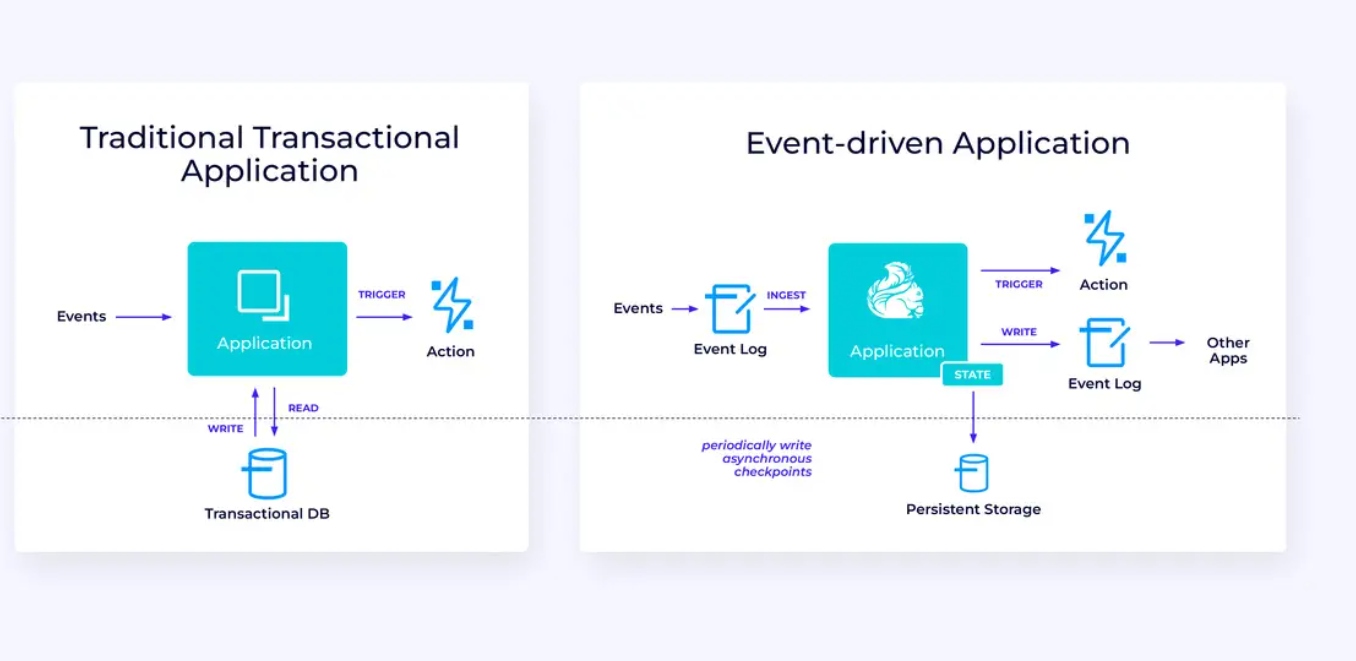
تطبيقات تتم بناءها عبر ال事件
أسرع وآخر عائلة من الحالات المستخدمة تتضمن تطبيق التطبيقات التي تنشأ عبر ال事件 أو الميكروسرفات. وقد تم كتابة الكثير من المعلومات بشأن هذا الموضوع في مواقع أخرى؛ هذا هو نموذج تصميم معماري يحمل العديد من المزايا.
فلينك قد يكون من المناسبات الأفضل لهذه التطبيقات، خاصة إذا كنت بحاجة إلى الأداء الذي يمكن أن تسمح لفلينك. في بعض الحالات سيكون الAPI الجدولي/الSQL يحمل كل ما تحتاجون ، ومع ذلك في العديد من الحالات سيتوجب عليكم استخدام تفاليل البيانات الإضافية لجزء من العمل على الأقل.
بدء التعلم بفلينك
فلينك يقدم إفراد قوية لبناء تطبيقات تتم تحميل الجدولات التي تعالج الجدولات التي تنشأ عبر الأحداث. وكما قمنا بالمرور فإن بعض المفاهيم قد تبدو جديدة في البداية، ومع ذلك إن أصبحت مهمًا أن تكون مألوفًا بطريقة تصميم وتشغيل فلينك وسيكون تطبيقاته سهلة الاستخدام وسيكون من الجيد المعرفة بفلينك بشكل كبير.
وكما هو الخطوة المقبلة، اتبعوا التعليمات في دوري الفلينك والتي ستقودكم خلال عملية تحميل وتثبيت وتشغيل أحدث إصدار مستقر من فلينك. فكر في الحالات الموارد الواسعة التي نقاشنا عنها — الأنابي
تحتوي تسجيل البيانات على أحد المجالات الأكثر إثارة للإنتباه في تكنولوجيا المجتمعات اليوم، وتحسين معالجة التسجيلات بواسطة Flink يجعلها أكثر قوة. سيكون تعلم Flink جيدًا لمنظمتك وأيضًا للمهنة الخاصة بك لأن معالجة البيانات الفورية تأخذ في المقابل أكثر قيمة للأعمال عالمًا. لذا أخبري بما يمكن أن تحقق مع هذه التكنولوجيا القوية.
Source:
https://dzone.com/articles/apache-flink-101-a-guide-for-developers