













Ces dernières années, Apache Flink est devenu le standard de facto pour le traitement en direct des flux de données. Le traitement des flux est un paradigme pour la construction de systèmes qui considère les flux d’événements (sequences d’événements dans le temps) comme son bloc de construction le plus essentiel. Un traitement de flux, tel que Flink, consomme des flux d’entrée produits par des sources d’événements et produit des flux de sortie qui sont consommés par des collecteurs (les collecteurs stockent les résultats et les rendent disponibles pour un traitement ultérieur).
Des noms de marque connus comme Amazon, Netflix et Uber font appel à Flink pour alimenter les pipelines de données fonctionnant à une échelle colossale au cœur de leurs entreprises, mais Flink joue également un rôle clé dans de nombreuses petites entreprises avec des exigences similaires pour pouvoir réagir rapidement à des événements commerciaux critiques.
À quoi est-il utilisé Flink ? Les cas d’utilisation courants se divisent en trois catégories :
|
Pipelines de données en flux |
Analytics en temps réel |
Applications basées sur les événements |
|---|---|---|
|
Ingérer, enrichir et transformer en continu les flux de données, les chargeant dans les systèmes de destination pour une action temporelle (par opposition au traitement en batch). |
Produire et mettre à jour en continu les résultats, qui sont affichés et fournis aux utilisateurs à mesure que les flux de données en direct sont consommés. |
Reconnaître des patrons et réagir aux événements entrants en déclenchant des calculs, des mises à jour d’état ou des actions externes. |
|
Quelques exemples incluent :
|
Quelques exemples incluent :
|
Quelques exemples incluent :
|
Flink inclut :
- Un soutien robuste pour les charges de travail de flux de données à l’échelle requise par les entreprises mondiales
- Des garanties solides de correction exacte à la fois et de récupération des pannes
- Un support pour Java, Python et SQL, avec un support unifié pour le traitement en lot et en flux
- Flink est un projet open source mature de la fondation Apache et compte une communauté très active et appuyante.
Flink est parfois décrit comme complexe et difficile à apprendre. Oui, l’implémentation du runtime de Flink est complexe, mais cela ne devrait pas surprendre, car il résout certains problèmes difficiles. Les API de Flink peuvent être assez défisantes à apprendre, mais cela a davantage à voir avec les concepts et les principes d’organisation qui sont inconnus que avec une complexité inhérente.
Flink peut être différent de tout ce que vous avez utilisé auparavant, mais en de nombreuses occasions, il est en fait plutôt simple. À un certain moment, au fur et à mesure que vous devenez plus familier avec la manière dont Flink est structuré et les problèmes que son exécutif doit résoudre, les détails des API de Flink devraient commencer à vous sembler être les conséquences logiques de quelques principes clés, plutôt que comme une collection de détails reculés à mémoriser.
Cet article vise à rendre le processus d’apprentissage de Flink beaucoup plus facile, en exposant les principes centraux à la base de son design.
Flink Incarne quelques Grands Idées
Flux
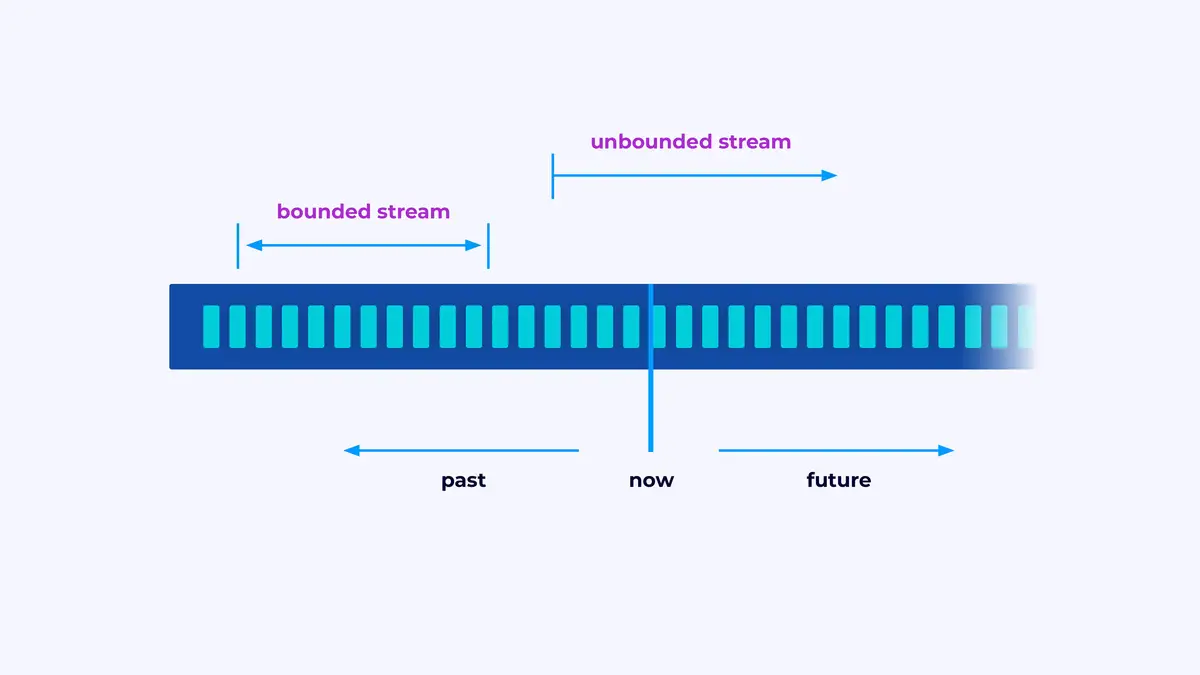
Flink est un cadre pour construire des applications qui travaillent avec des flux d’événements, où un flux est une suite d’événements bornée ou non bornée.
Une application Flink est un pipeline de traitement de données. Vos événements courent le long de ce pipeline et sont traités à chaque étape par le code que vous écrivez. Nous appelons ce pipeline le graphe de job, et les nœuds de ce graphe (ou en d’autres termes, les étapes du pipeline de traitement) sont appelés opérateurs.
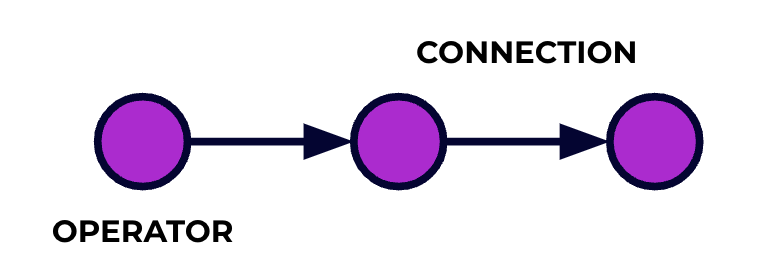
Le code que vous écrivez en utilisant l’une des API de Flink décrit le graphe de job, y compris le comportement des opérateurs et leurs connexions.
Traitement Parallèle
Chaque opérateur peut avoir de nombreuses instances parallèles, chacune opérant indépendamment sur une sous-partie des événements.
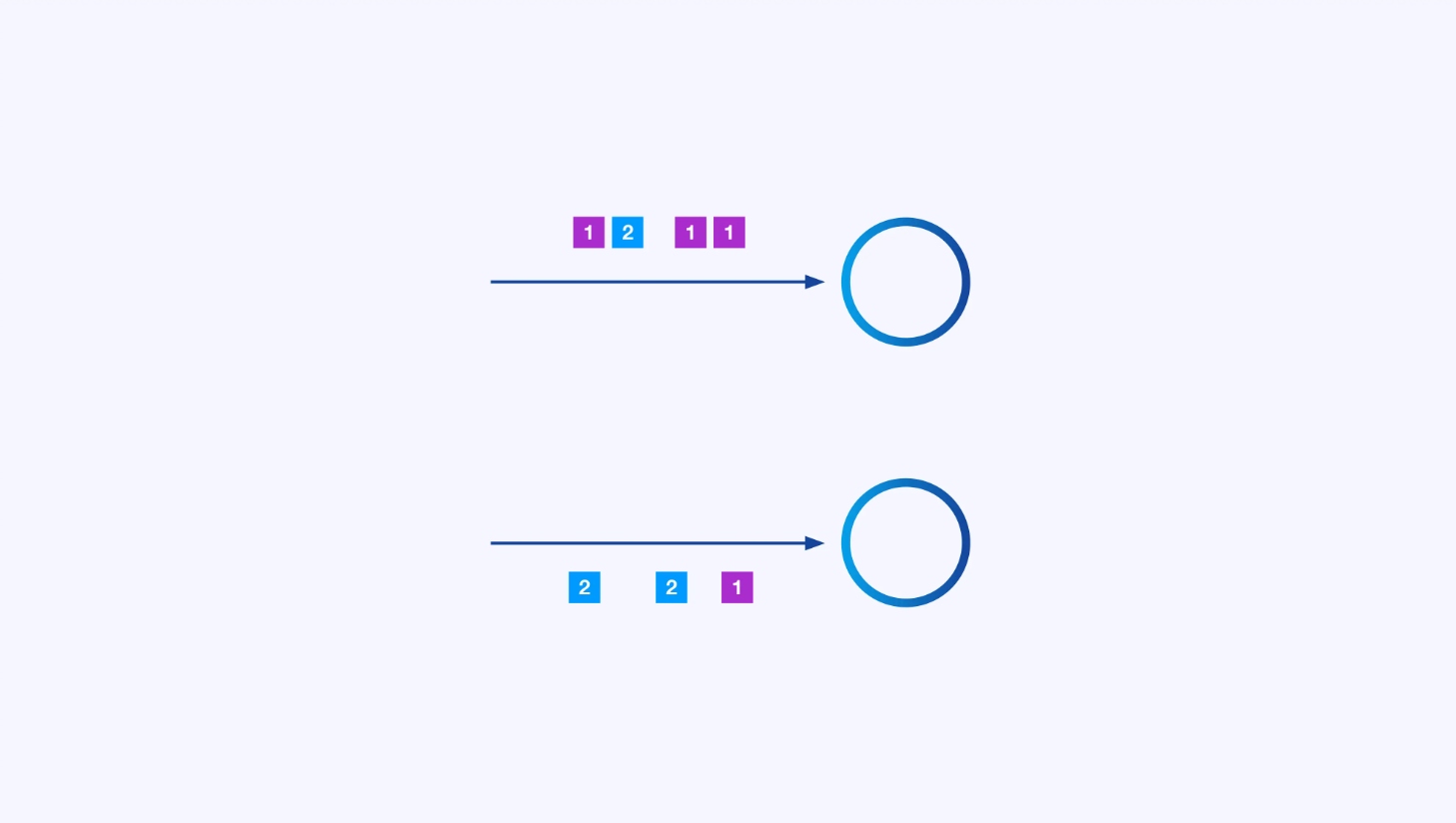
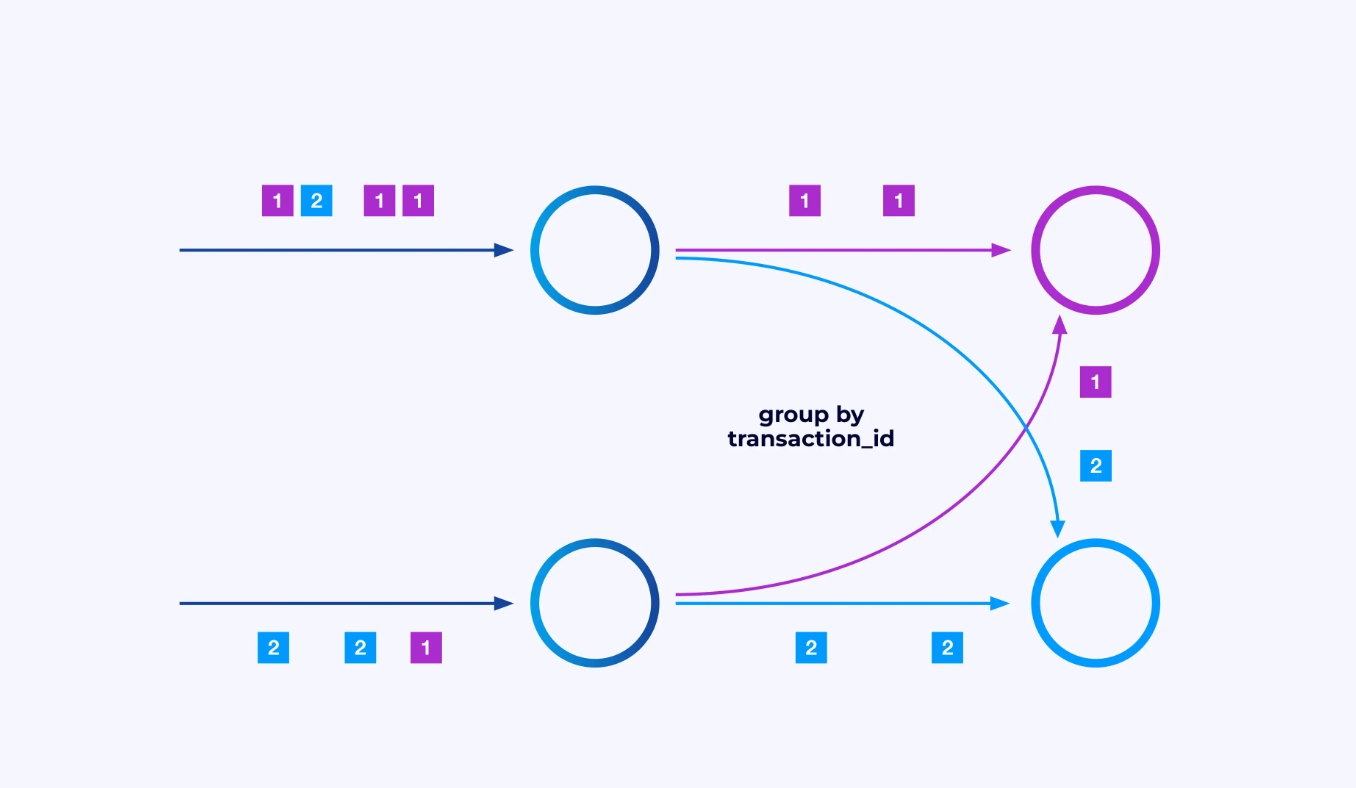
Parfois, vous voudrez imposer un schéma de partitionnement spécifique sur ces sous-flux de données afin que les événements soient regroupés selon une logique spécifique à l’application. Par exemple, si vous traitez des transactions financières, vous pourriez avoir besoin d’arranger pour que chaque événement d’une transaction donnée soit traité par le même fil. Cela vous permettra de connecter les différents événements qui se produisent au fil du temps pour chaque transaction
En Flink SQL, vous feriez cela avec GROUP BY transaction_id, tandis qu’en utilisant l’API DataStream, vous utiliseriez keyBy(event -> event.transaction_id) pour spécifier ce regroupement ou partitionnement. Dans tous les cas, cela apparaîtra dans le graphe de job comme un jeu de données entièrement connecté entre deux étapes consécutives du graphe.
État
Les opérateurs travaillant sur des flux partitionnés par clé peuvent utiliser le stockage de clés/valeurs distribué de Flink pour persister durablement ce qu’ils souhaitent. L’état pour chaque clé est local à une instance spécifique d’un opérateur et ne peut être accessible nulle part ailleurs. Les sous-topologies parallèles ne partagent rien — c’est crucial pour l’échelle illimitée.
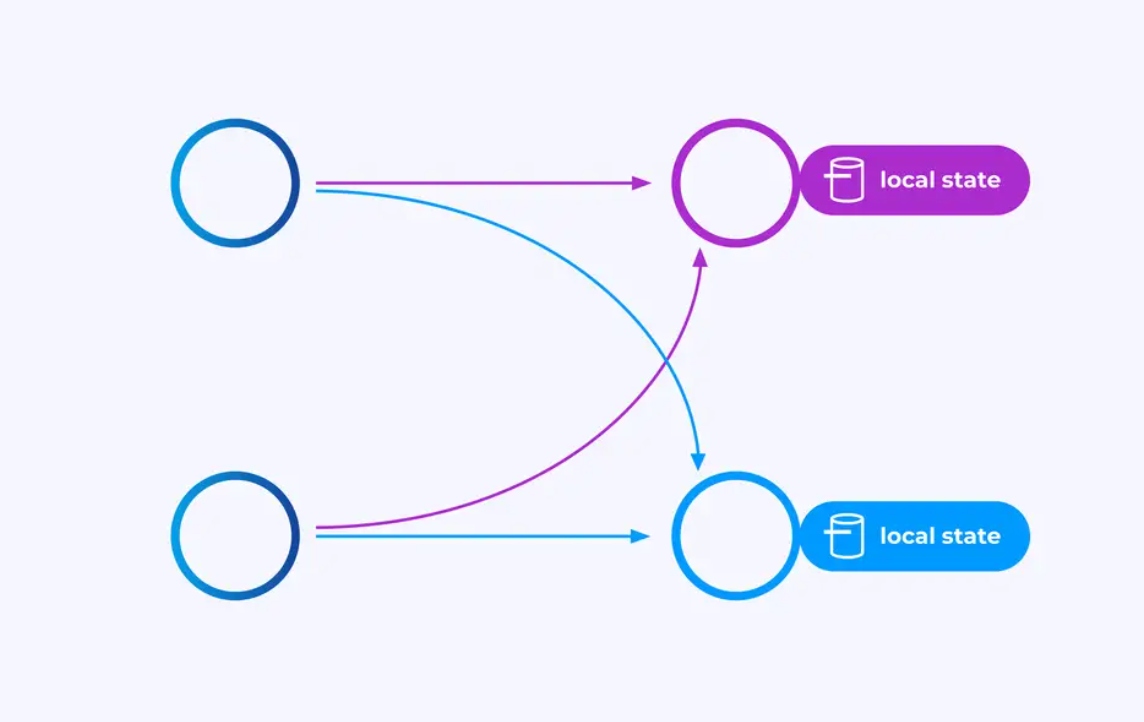
Un job Flink pourrait être laissé en cours d’exécution indéfiniment. Si un job Flink continue de créer de nouvelles clés (par exemple, des ID de transactions) et de stocker quelque chose pour chaque nouvelle clé, alors ce job court risque d’exploser parce qu’il utilise une quantité d’état non bornée. Chaque API de Flink est organisée autour de mécanismes pour vous aider à éviter des explosions d’état incontrôlables.
Temps
Une façon de ne pas tenir trop longtemps une état est de le conserver uniquement jusqu’à un point de temps spécifique. Par exemple, si vous voulez compter les transactions dans des fenêtres de une minute, une fois que chaque minute est terminée, le résultat pour cette minute peut être produit, et ce compteur peut être libéré.
Flink fait une distinction importante entre deux notions différentes de temps :
- Le temps de traitement (ou l’horloge du mur), qui est dérivé de l’heure réelle de la journée où un événement est traité
- Le temps des événements, qui est basé sur les horodatages enregistrés avec chaque événement
Pour illustrer la différence entre eux, réfléchissez à ce que signifie que une fenêtre de une minute est complète :
- Une fenêtre de temps de traitement est complète quand la minute est terminée. C’est parfaitement simple.
- Une fenêtre de temps des événements est complète quand tous les événements qui se sont produits pendant cette minute ont été traités. Cela peut être compliqué car Flink ne peut pas savoir à propos des événements qu’il n’a pas encore traités. La meilleure chose que nous pouvons faire est de faire une hypothèse sur la latence possible d’un flux et d’appliquer cette hypothèse heuristiquement.
Pointage pour la récupération des échecs
Les échecs sont inévitables. Malgré les échecs, Flink est capable de fournir des garanties effectivement à la fois précise, ce qui signifie que chaque événement affectera l’état géré par Flink exactement une fois, comme si l’échec n’avait jamais eu lieu. Il le fait en prenant des instantanés périodiques, mondiaux et auto-consistents de tous les états. Ces instantanés, créés et gérés automatiquement par Flink, sont appelés points de contrôle.
Le processus de récupération consiste à retourner à l’état capturé dans le plus récent point de contrôle et à effectuer un redémarrage global de tous les opérateurs à partir de ce point de contrôle. Pendant la récupération, certains événements sont rétraité à nouveau, mais Flink est capable de garantir la corrélité en vérifiant que chaque point de contrôle est un instantané global et cohérent de l’état complet du système.
Architecture système
Les applications Flink s’exécutent dans des clusters Flink, donc avant de pouvoir mettre une application Flink en production, vous serez donc nécessité de disposer d’un cluster pour le déployer. Heureusement, pendant la phase de développement et de test, il est aisé de démarrer en exécutant Flink localement dans un environnement de développement intégré (IDE) tel que IntelliJ ou Docker.
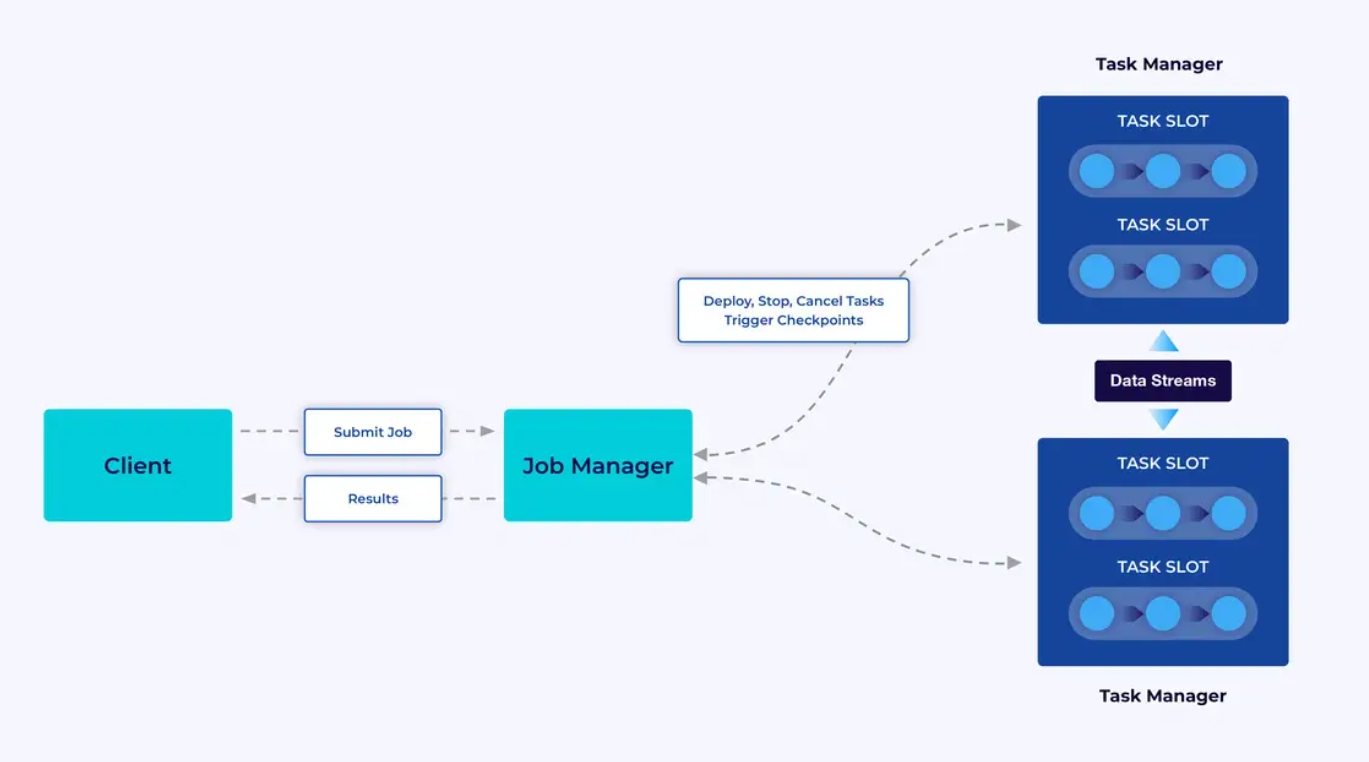
Un cluster Flink est composé de deux types de composants : un gestionnaire de jobs et un ensemble de gestionnaires de tâches. Les gestionnaires de tâches exécutent votre application (en parallèle), tandis que le gestionnaire de jobs agit en tant que passerelle entre les gestionnaires de tâches et le monde extérieur. Les applications sont soumises au gestionnaire de jobs, qui gère les ressources fournies par les gestionnaires de tâches, coordonne le processus de pointage de contrôle et fournit une visibilité sur le cluster sous forme de métriques.
L’expérience du développeur
L’expérience que vous aurez en tant que développeur Flink dépend, dans une certaine mesure, du choix de l’API que vous faites : soit l’ancienne API DataStream de bas niveau, soit les nouvelles API relationnelles Table et SQL.
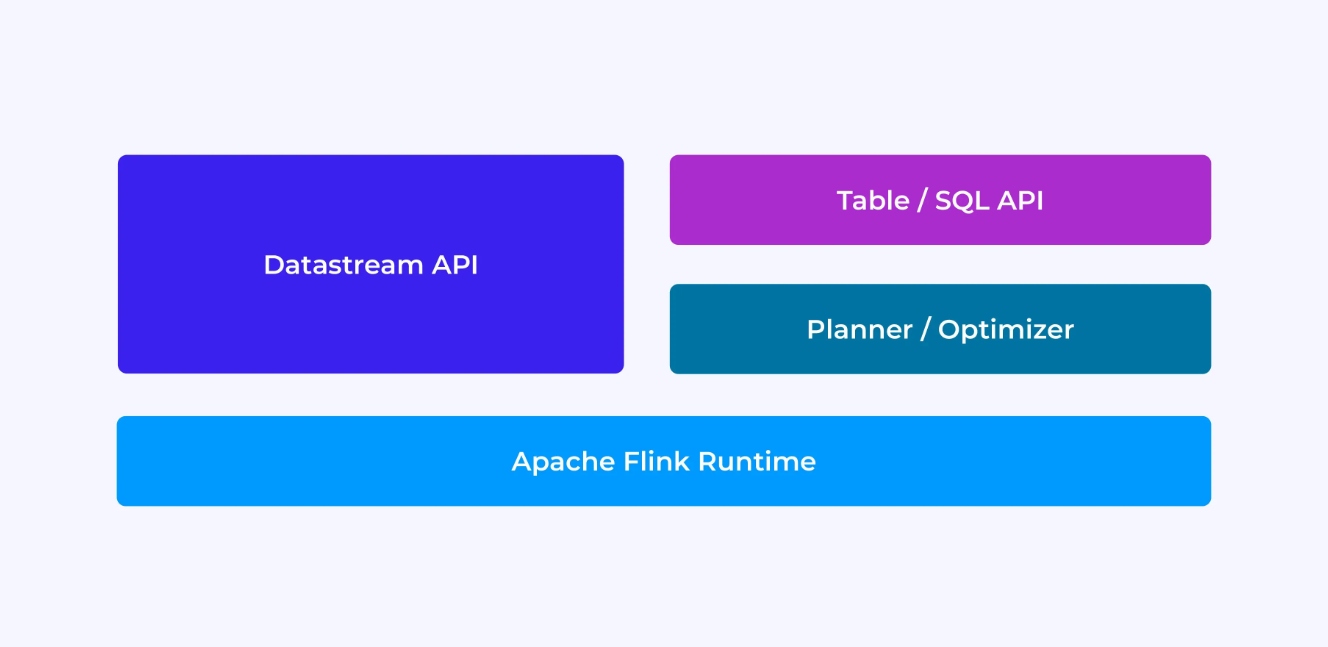
Lorsque vous programmez avec l’API DataStream de Flink, vous pensez consciemment à ce que le runtime de Flink fera lors de l’exécution de votre application. Cela signifie que vous construitz le graphe de job une opération à la fois, décrivant le statut que vous utilisez ainsi que les types impliqués et leur serialization, créant des minuteries et implémentant des fonctions de rappel pour être exécutées lorsque ces minuteries sont déclenchées, etc. L’abstraction centrale dans l’API DataStream est l’événement, et les fonctions que vous écrivez traiteront un événement à la fois, à leur arrivée.
D’autre part, lorsque vous utilisez l’API Table/SQL de Flink, ces préoccupations de bas niveau sont prises en charge pour vous, et vous pouvez vous concentrer davantage sur votre logique métier. L’abstraction centrale est la table, et vous pensez davantage en termes de jointures de tables pour l’enrichissement, de regroupements de lignes pour calculer les analytics agrégées, etc. Un planificateur et optimiseur de requêtes SQL intégrés s’occupent des détails. Le planificateur/optimiseur fait un excellent travail de gestion des ressources, souvent surpassant le code écrit à la main.
Avant de plonger dans les détails, deux ou trois idées supplémentaires : premièrement, vous n’avez pas à choisir entre DataStream et Table/SQL API – les deux APIs sont interopérables et vous pouvez les combiner. C’est souvent une bonne manière de procéder si vous avez besoin de personnalisations qui ne sont pas possibles dans l’API Table/SQL. Mais une autre bonne manière de dépasser ce que l’API Table/SQL offre de base est d’ajouter certaines capacités supplémentaires sous forme de fonctions définies par l’utilisateur (UDFs). Là, l’API SQL de Flink offre de nombreuses options pour l’extension.
Construction du graphe de job
Indépendamment de quelle API vous utilisez, l’objectif ultime du code que vous écrivez est de construire le graphe de travail qui sera exécuté en votre nom par l’exécutif de Flink. Cela signifie que ces APIs sont organisées autour de la création d’opérateurs et de la spécification de leur comportement ainsi que de leurs connexions les uns aux autres. Avec l’API DataStream, vous construisez directement le graphe de travail, tandis que avec l’API Table/SQL, l’planificateur SQL de Flink s’en charge.
Serialization des fonctions et des données
En fin de compte, le code que vous fournissez à Flink sera exécuté en parallèle par les workers (les gestionnaires de tâches) dans un cluster Flink. Pour que cela se produise, les objets de fonctions que vous créez sont sérialisés et envoyés aux gestionnaires de tâches où ils sont exécutés. De même, les événements eux-mêmes devront parfois être sérialisés et envoyés sur le réseau d’un gestionnaire de tâche à un autre. Encore une fois, avec l’API Table/SQL, vous n’avez pas à vous préoccuper de cela.
Gestion des États
Le runtime de Flink doit être informé de tout état que vous espérez qu’il récupère pour vous en cas de panne. Pour que cela fonctionne, Flink a besoin de renseignements de type qu’il peut utiliser pour sérialiser et déserialiser ces objets (afin qu’ils puissent être écrits dans et lus à partir de points de contrôle). Vous pouvez configurer ce état géré facultativement avec des descripteurs de temps de vie que Flink utilisera ensuite automatiquement pour expirer l’état une fois qu’il aura perdu sa pertinence.
Avec l’API DataStream, vous gérez généralement directement l’état requis par votre application (les opérations de fenêtre internes sont l’exception à cette règle). D’autre part, avec l’API Table/SQL, cette préoccupation est abstraite. Par exemple, en donnant une requête comme celle ci-dessous, vous savez que quelque part dans l’exécution du Flink, une structure de données doit maintenir un compteur pour chaque URL, mais tout est géré pour vous.
SELECT url, COUNT(*)
FROM pageviews
GROUP BY URL;Configuration et Déclenchement des Timers
Les timers ont de nombreuses utilisations dans le traitement des flux. Par exemple, il est courant que les applications Flink aient besoin de rassembler des informations provenant de nombreux sources d’événements différentes avant de produire finalement des résultats. Les timers sont bons pour les cas où il est sensé attendre (mais pas indéfiniment) pour des données qui peuvent (ou ne peuvent pas) arriver finalement.
Les timers sont également essentiels pour la mise en œuvre d’opérations de fenêtre temporelle. Les deux API DataStream et Table/SQL ont une prise en charge intégrée des fenêtres et gèrent les timers pour vous.
Cas d’utilisation
Revenons aux trois grandes catégories de cas d’utilisation de flux présentés au début de cet article, et voyons comment elles se mappent sur ce que vous veniez d’apprendre sur Flink.
Canal de données en flux
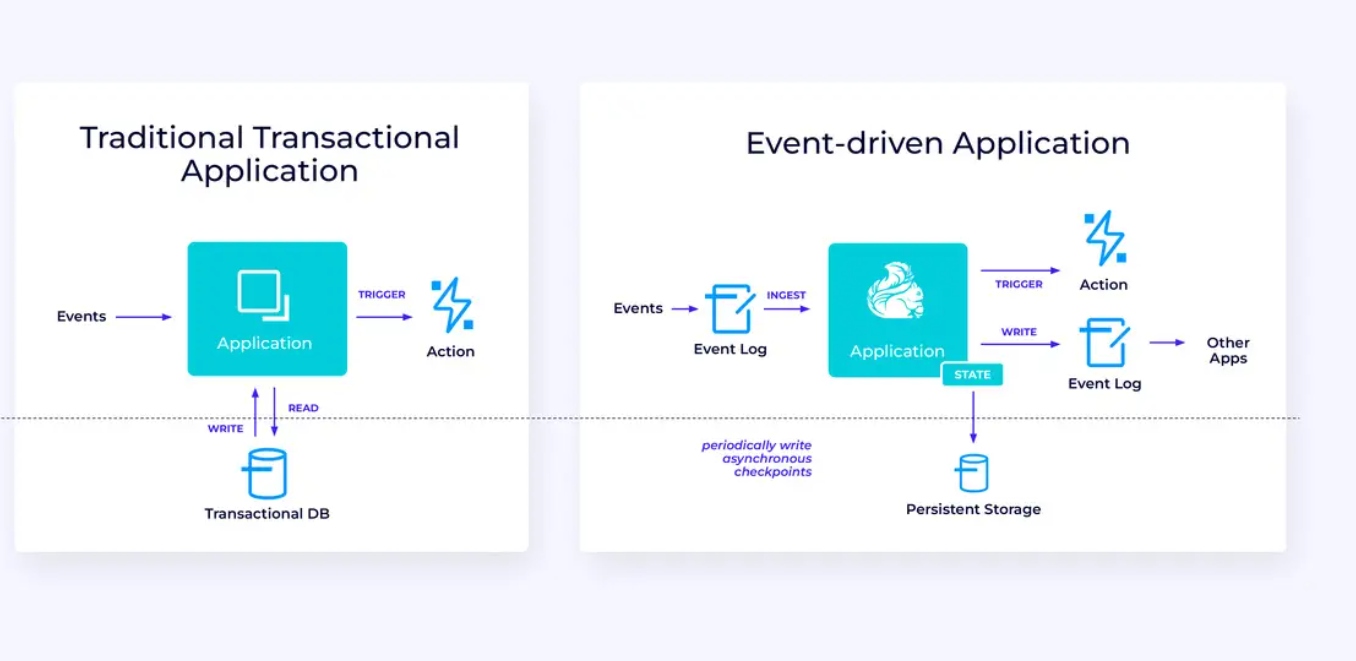
En dessous, à gauche, il y a un exemple d’une job traditionnel d’extraction, de transformation et de chargement (ETL) qui lit périodiquement une base de données transactionnelle, transforme les données et écrit les résultats vers un autre stockage, comme une base de données, un système de fichiers ou un lac de données.
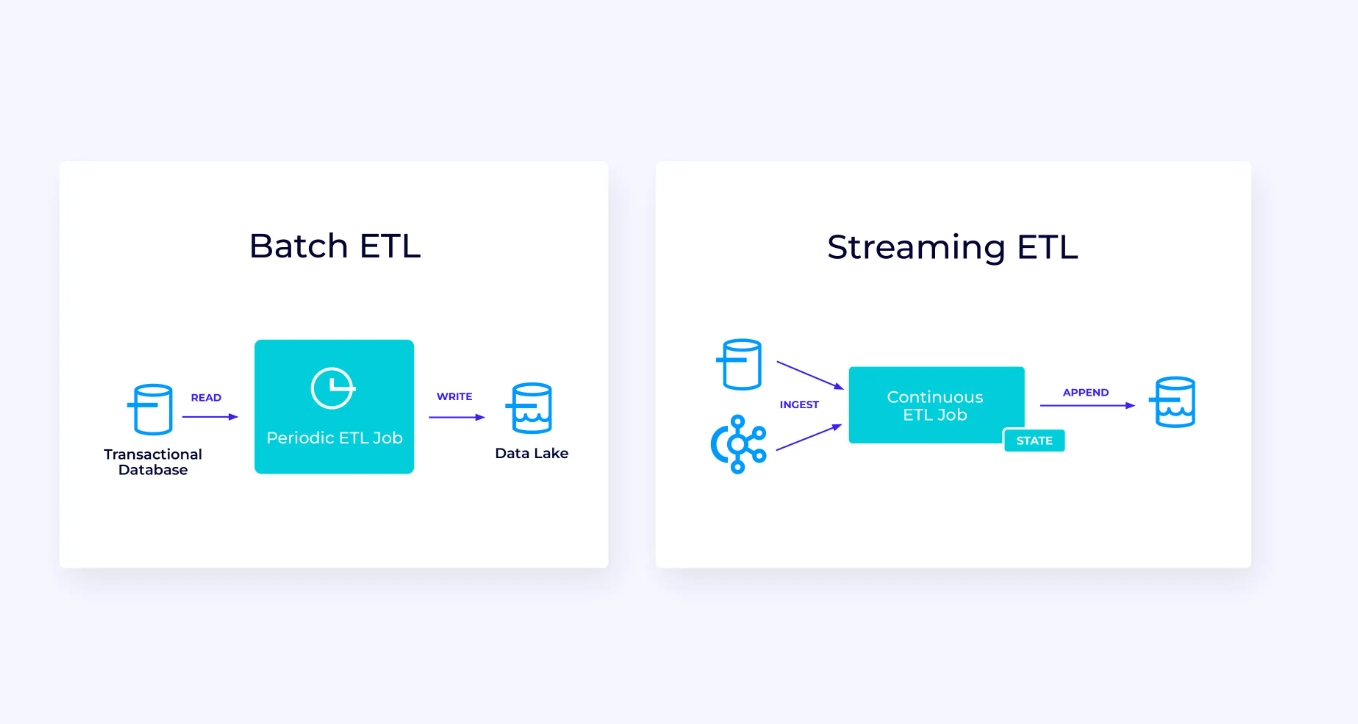
Le pipeline de streaming correspondant est superficiellement similaire, mais comporte quelques différences importantes :
- Le pipeline de streaming est toujours en cours d’exécution.
- Les données transactionnelles sont livrées au pipeline de streaming en deux parties : un chargement initial en masse depuis la base de données, en combinaison avec une stream de capture de changement (CDC) portant les mises à jour de la base de données depuis ce chargement initial.
- La version en streaming produit constamment de nouveaux résultats dès qu’ils sont disponibles.
- Le state est géré explicitement de manière à ce qu’il puisse être récupéré robustement en cas d’échec. Les pipelines ETL en streaming utilisent généralement très peu de state. Les sources de données gardent la trace exacte du nombre d’éléments ingérés, généralement sous forme d’offsets comptant les enregistrements depuis le début des streams. Les destinations utilisent des transactions pour gérer leurs écritures vers des systèmes externes, tels que les bases de données ou Kafka. Lors du checkpoint, les sources enregistrent leurs offsets, et les destinations valident les transactions portant les résultats de la lecture exacte jusqu’à, mais pas au-delà, de ces offsets sources.
Pour ce cas d’utilisation, l’API Table/SQL serait une bonne choix.
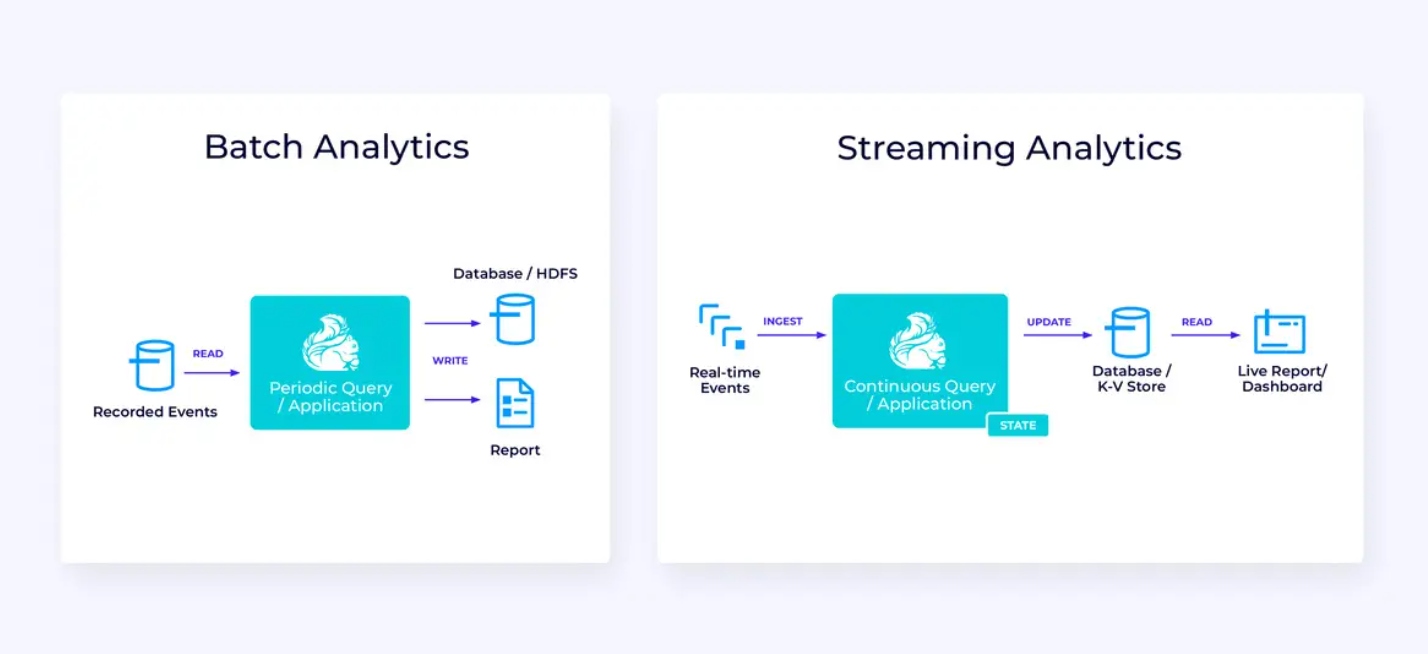
Analyse en Temps Reel
Par rapport à l’application de streaming ETL, cette application d’analyse en temps réel présente quelques différences intéressantes :
- Encore une fois, Flink est utilisé pour exécuter une application continue, mais pour cette application, Flink sera probablement nécessaire à gérer beaucoup plus de state.
- Pour ce cas d’utilisation, il est logique que le flux d’ingestion soit stocké dans un système de stockage natif de flux, tel que Apache Kafka.
- Plutôt que de produire périodiquement un rapport statique, la version en streaming peut être utilisée pour piloter un tableau de bord en direct.
Une fois de plus, l’API Table/SQL est généralement une bonne option pour ce cas d’utilisation.
Applications basées sur les événements
Notre troisième et dernière famille d’utilisations implique l’implémentation d’applications basées sur les événements ou de microservices. Beaucoup a été écrit ailleurs sur ce sujet ; il s’agit d’un patron architectural qui offre de nombreux avantages.
Flink peut être un excellent choix pour ces applications, en particulier si vous avez besoin de la performance que Flink peut fournir. Dans certains cas, l’API Table/SQL contient tout ce dont vous avez besoin, mais dans de nombreux cas, vous aurez besoin de la flexibilité additionnelle de l’API DataStream pour au moins une partie du travail.
Pour démarrer avec Flink
Flink fournit un puissant framework pour construire des applications qui travaillent avec des flux d’événements. Comme nous l’avons vu, certains des concepts peuvent sembler novateurs au départ, mais une fois que vous soyez familiarisé avec la manière dont Flink est conçu et fonctionne, le logiciel est facile à utiliser, et les récompenses de connaissance de Flink sont importantes.
Comme prochain pas, suivez les instructions dans la documentation de Flink, qui vous guideront dans le processus de téléchargement, d’installation et d’exécution de la dernière version stable de Flink. Réfléchissez aux cas d’utilisation larges que nous avons discutés – les pipelines de données modernes, l’analyse en temps réel et les microservices basés sur les événements – et comment ces options peuvent aider à relever un défi ou à créer de la valeur pour votre organisation.
Le streaming de données est l’un des domaines les plus passionnants de la technologie enterprise aujourd’hui, et le traitement en continu avec Flink le rend encore plus puissant. Apprendre Flink sera bénéfique non seulement pour votre organisation mais également pour votre carrière car le traitement de données en temps réel est devenu plus précieux pour les entreprises mondiales. Alors, découvrez Flink aujourd’hui et voyez ce que cette technologie puissante peut vous aider à accomplir.
Source:
https://dzone.com/articles/apache-flink-101-a-guide-for-developers