













In de afgelopen jaren heeft Apache Flink zich ontwikkeld tot de feitelijke standaard voor real-time stream processing. Stream processing is een Paradigma voor het bouwen van systemen dat gebeurtenissenstromen (sequenties van gebeurtenissen in tijd) beschouwt als zijn meest fundamentele bouwblokken. Een stream processor, zoals Flink, consumeert invoerstromen die zijn gegenereerd door gebeurtenisbronnen en produceert uitvoerstromen die worden geconsumeerd door storageplaatsen (de storageplaatsen bewaren de resultaten en maken ze beschikbaar voor verdere verwerking).
Bekende bedrijven zoals Amazon, Netflix en Uber zijn afhankelijk van Flink om data pijplijnen op een grote schaal te laten werken in het hart van hun bedrijven, maar Flink speelt ook een cruciale rol in veel kleinere bedrijven met soortgelijke eisen voor het snel reageren op belangrijke bedrijfsgebeurtenissen.
Wat wordt Flink voor gebruikt? Common use cases fall into these three categories:
|
Streaming data pipelines |
Real-time analytics |
Event-driven applications |
|---|---|---|
|
Continuously ingest, enrich, and transform data streams, loading them into destination systems for timely action (vs. batch processing). |
Continuously produce and update results which are displayed and delivered to users as real-time data streams are consumed. |
Recognize patterns and react to incoming events by triggering computations, state updates, or external actions. |
|
Some examples include:
|
Enkele voorbeelden zijn:
|
Enkele voorbeelden zijn:
|
Flink omvat:
- Robuste ondersteuning voor data stream workloads op de schaal die nodig is bij wereldwijde bedrijven
- Sterke garanties van exact-eenmaal correctheid en foutherstel
- Ondersteuning voor Java, Python en SQL, met gecontroleerde ondersteuning voor zowel batch als stream processing
- Flink is een volwassen opensource project van de Apache Software Foundation en heeft een zeer actieve en steunende community.
Flink wordt soms beschreven als complex en moeilijk te leren. Ja, de implementatie van de Flink runtime is complex, maar dat zou niet verwacht worden, omdat het enkele moeilijke problemen oplost. Flink APIs kunnen enigszins uitdagend zijn om te leren, maar dat heeft meer te maken met de onbekendheid van de concepten en organiserende principes dan met enige inherente complexiteit.
Flink kan verschillend zijn van alles wat u eerder heeft gebruikt, maar in veel opzichten is het eigenlijk vrij eenvoudig. Op een bepaald moment, als u zich meer vertrouwt met de manier waarop Flink is samengesteld en de problemen die zijn runtime moet aanpakken, zouden de details van Flink’s APIs voor u moeten beginnen aan te steken als de logische consequenties van enkele sleutelprincipes in plaats van een verzameling van arcane details die u moet onthouden.
Dit artikel doet een poging om de leerprocessen van Flink aanzienlijk gemakkelijker te maken, door de kernprincipes uit te leggen die zijn ontwerp ondersteunen.
Flink wordt uitgebeeld door enkele grote ideeën
Stromen
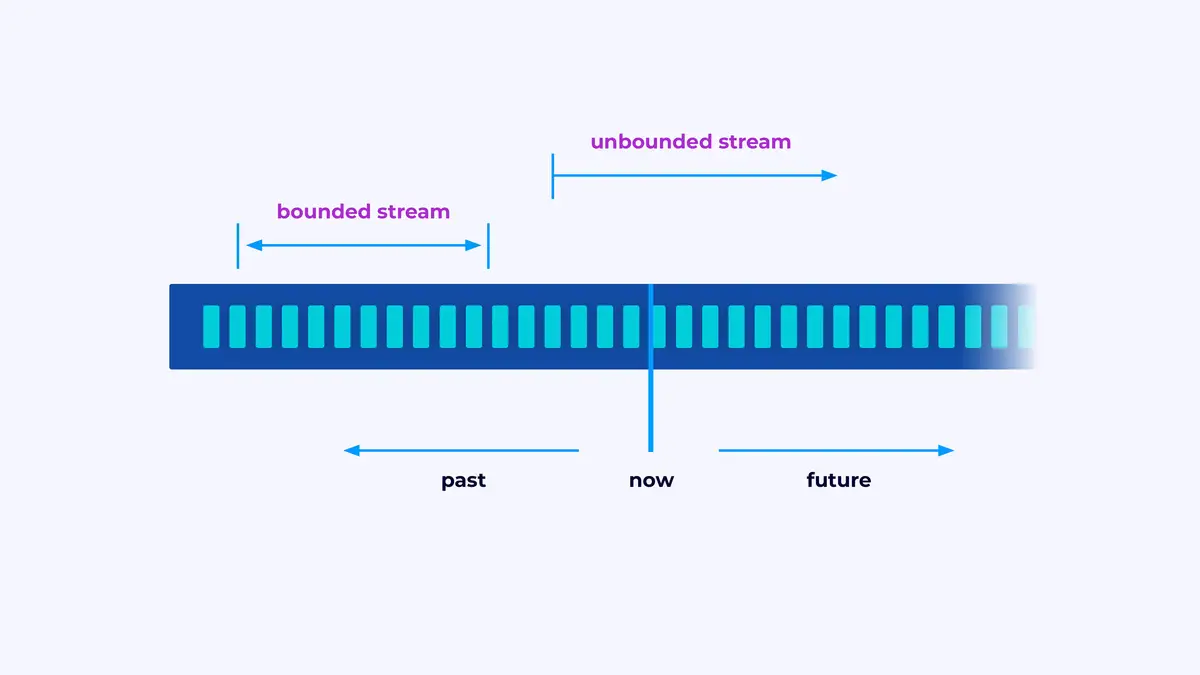
Flink is een framework voor het bouwen van toepassingen die eventuele stromen verwerken, waar een stroom een gelimiteerde of ongelimiteerde reeks gebeurtenissen is.
Een Flink-toepassing is een gegevensverwerkingspijplijn. Uw gebeurtenissen stromen door deze pijplijn en worden op elke fase bewerkt door de code die u schrijft. We noemen deze pijplijn de taakgraph en de nodes van dit graaf (of anders gezegd, de fases van de verwerkingspijplijn) worden operators genoemd.
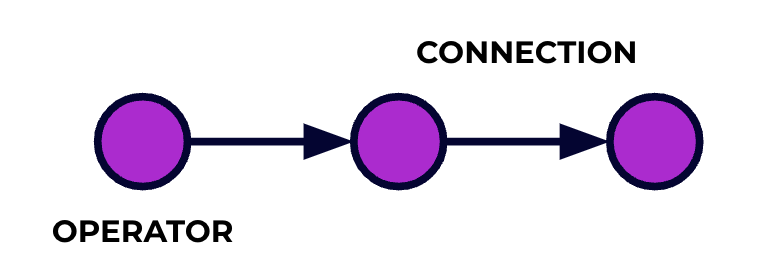
De code die u schrijft met behulp van een van Flink’s APIs beschrijft de taakgraph, inclusief het gedrag van de operators en hun verbindingen.
Parallelle verwerking
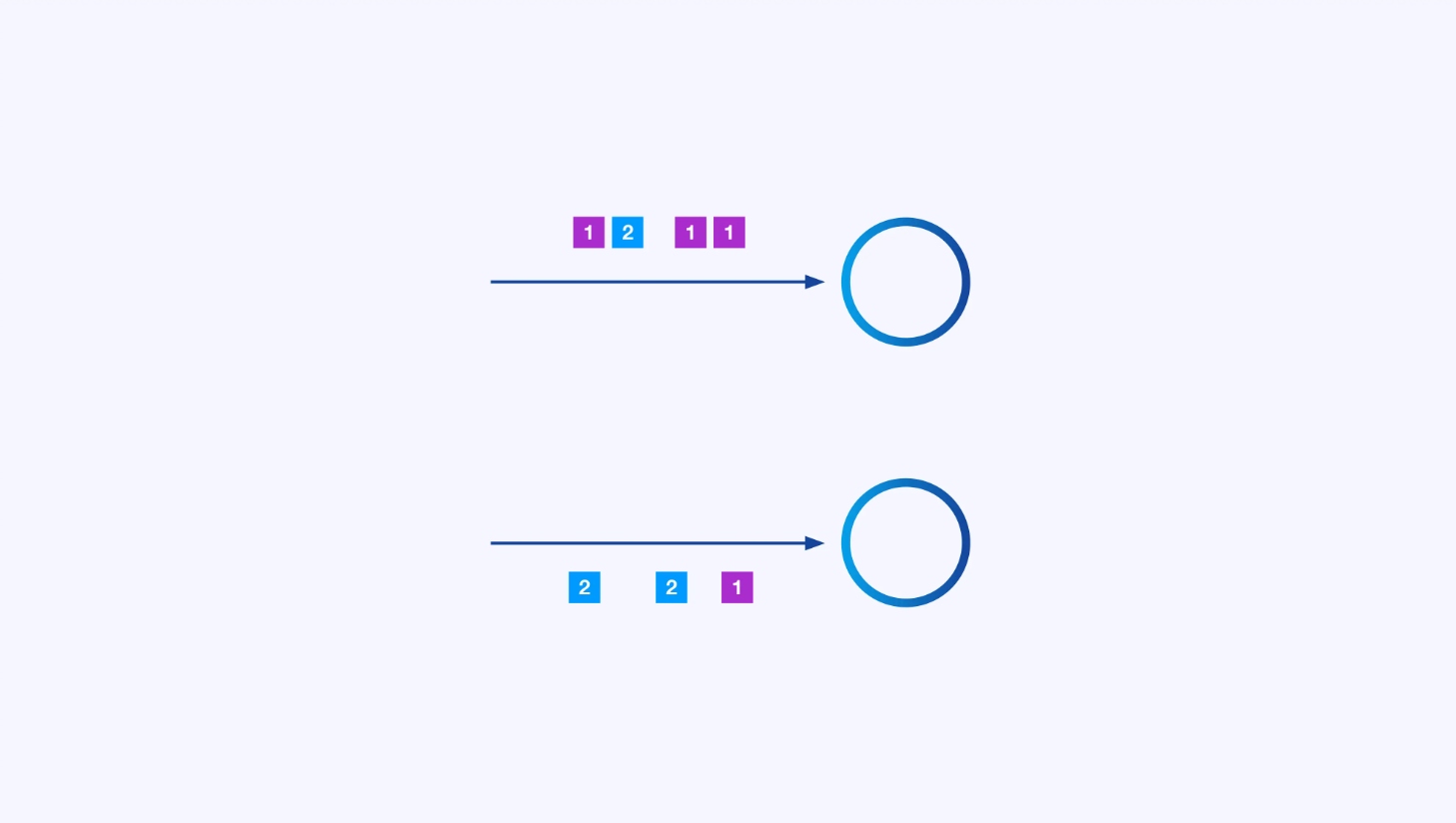
Elke operator kan veel parallelle instanties hebben, elke een onafhankelijke bewerking uitvoerd op een deel van de gebeurtenissen.
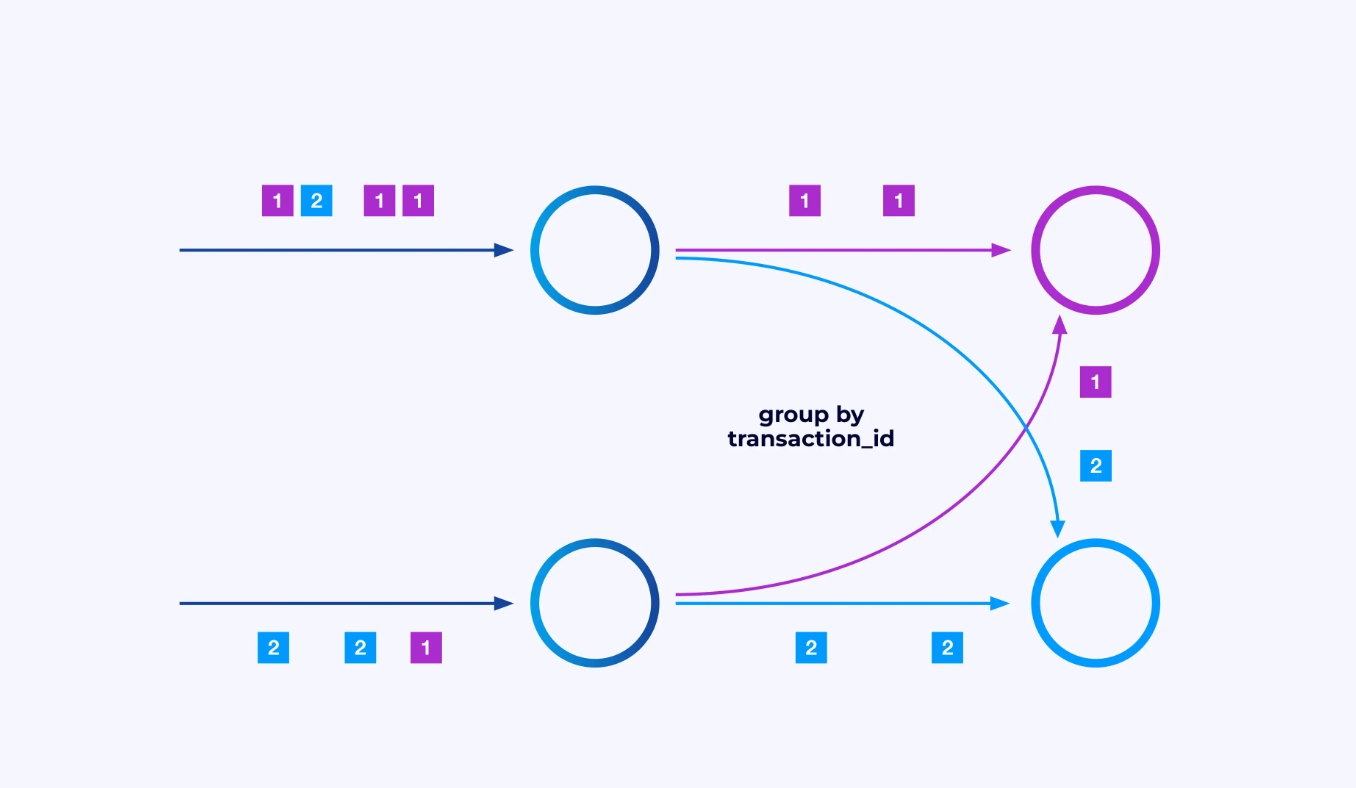
Sommige keren zult u een specifieke partitieschema op deze sub-stromen willen afdwingen zodat de gebeurtenissen bij elkaar gegroepeerd worden volgens enige toepassingsspecifieke logica. Bijvoorbeeld, als u financiële transacties verwerkt, zou u misschien moeten afspreken dat elke gebeurtenis voor elke gegeven transactie door dezelfde thread verwerkt wordt. Dit zal u in staat stellen de verschillende gebeurtenissen die over tijd voor elke transactie plaatsvinden, met elkaar te verbinden
In Flink SQL zou u dit doen met GROUP BY transaction_id, terwijl u in de DataStream API keyBy(event -> event.transaction_id) zou gebruiken om deze groepering of partitieschema aan te geven. In elk geval zal dit in het taakdiagram verschijnen als een volledig verbonden netwerkverschuiving tussen twee achter elkaar gelegen fasen van het diagram.
State
Operators die werken op key-gepartitioneerde stromen kunnen gebruik maken van Flink’s verspreidde key/value state store om wat dan ook duurzaam opslaan. Het stateless voor elke toets is lokaal aan een specifieke instantie van een operator en kan nergens anders wordt aangevraagd. De parallelle sub-topologieën delen niets — dit is crucial voor onbeperkte schaalbaarheid.
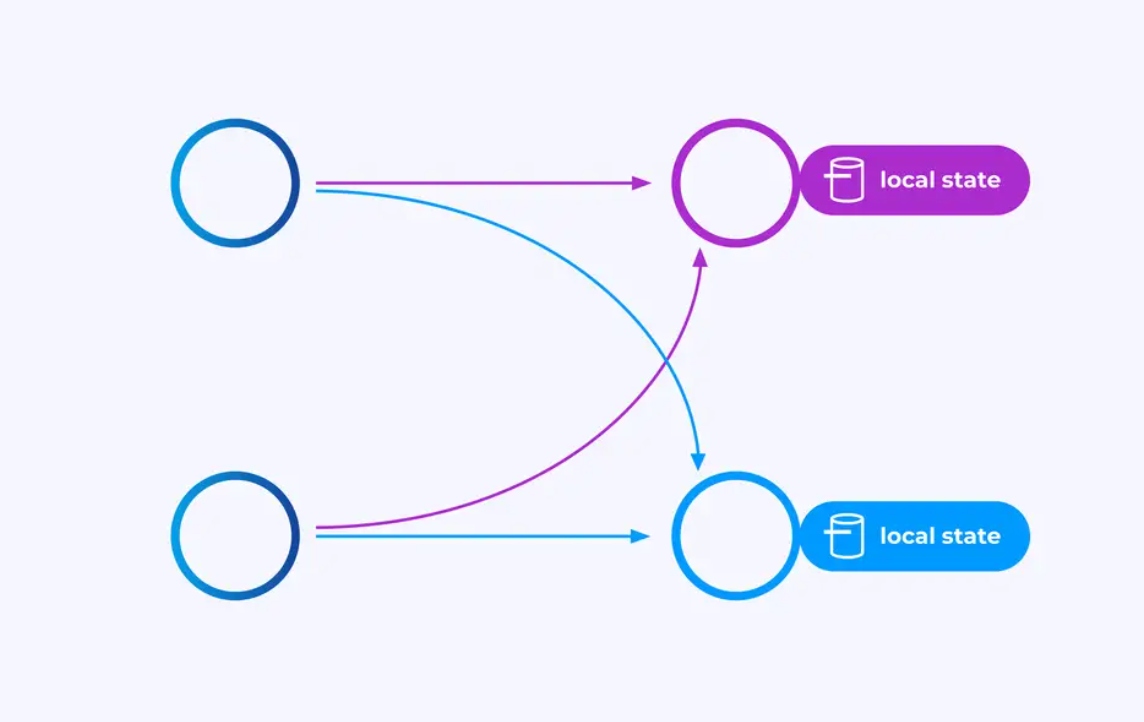
Een Flink-taak zou onbegrensd lang kunnen blijven draaien. Als een Flink-taak continu nieuwe toetsen (bijv. transactie-ID’s) aanmaakt en iets opslaat voor elke nieuwe toets, dan riskeert dat taak te exploderen omdat het een onbegrensd aantal staat gebruikt. Elke van Flink’s API’s is ingericht rond het verschaffen van manieren om u te helpen vermijden dat de staat uit de hand geloopt.
Time
Een manier om niet te langs te hangen aan een status is om die alleen behouden te houden tot een specifiek punt in de tijd. Bijvoorbeeld, als u wilt tellen transacties in minuutennetten, zodra iedere minuut voorbij is, kan het resultaat voor die minuut worden ge produceerd, en dat teller kan vrijgegeven worden.
Flink maakt een belangrijke onderscheid tussen twee verschillende noties van tijd:
- Verwerkingstijd (of muurkloktijd), die afgeleid is van de feitelijke tijd van de dag als een gebeurtenis wordt verwerkt
- Gebeurtenistijd, die gebaseerd is op de tijdsbestekeningen die bij elke gebeurtenis zijn opgenomen
Om de verschillen tussen hen weer te geven, denk over wat het betekent voor een minuutennet volledig te zijn:
- Een verwerkingstijdnet is voltooid als de minuut voorbij is. Dit is perfect duidelijk.
- Een gebeurtenistijdnet is voltooid als alle gebeurtenissen die tijdens die minuut hebben plaatsgevonden zijn verwerkt. Dit kan lastig zijn omdat Flink niets weet over gebeurtenissen die nog niet zijn verwerkt. Het beste dat we kunnen doen is een veronderstelling te trekken over hoe vertragingen er mogelijk zijn in een stream en dat veronderstelling heuristisch toe te passen.
Checkpointing voor Foutherstel
Fouten zijn onvermijdelijk. Desondanks kan Flink effectively exact-een keer garanderen, wat betekent dat elke gebeurtenis exact eenmaal de status die Flink beheert zal beïnvloeden, net alsof de fout nooit is opgetreden. Het doet dit door periodieke, wereldwijde, zelfconsistente snapshotten van alle statussen te maken. Deze snapshotten, gemaakt en beheerd automatisch door Flink, worden checkpoints genoemd.
Herstel bestaat uit het teruggaan naar de status die is vastgelegd in de meest recente checkpoint, en het uitvoeren van een wereldwijde herstart van alle operators vanaf dat checkpoint. Tijdens de herstelproces worden enkele gebeurtenissen opnieuw verwerkt, maar Flink kan de correctheid garanderen door er voor te zorgen dat elke checkpoint een wereldwijde, zelfconsistente snapshot is van het complete systeemtoestand.
Systeemarchitectuur
Flink-toepassingen worden uitgevoerd in Flink-clusters, dus voordat u een Flink-toepassing in productie kunt plaatsen, moet u een cluster hebben waarop u de toepassing kunt uitvoeren. Gelukkig is het tijdens ontwikkeling en testen gemakkelijk om aan de slag te komen door Flink lokaal te draaien in een geïntegreerde ontwikkelingsomgeving (IDE) zoals IntelliJ of Docker.
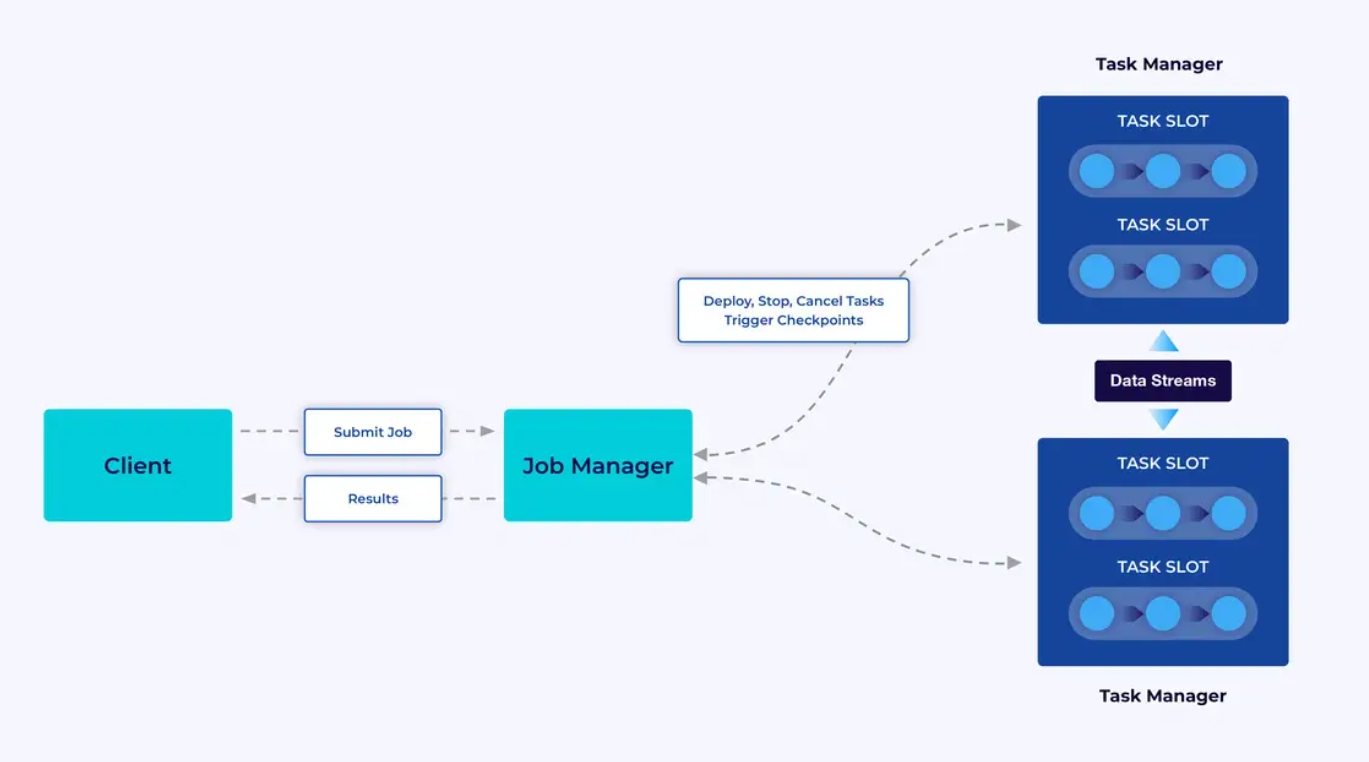
Een Flink-cluster heeft twee soorten componenten: een Job Manager en een set Task Managers. De task managers laten uw toepassingen (parallel) uitvoeren, terwijl de job manager een gateway is tussen de task managers en de buitenwereld. Toepassingen worden bij de job manager ingediend, die de door de task managers beschikbare resources beheert, coördineert welke checkpoints worden uitgevoerd en biedt zichtbaarheid op het cluster in de vorm van metrieken.
De ontwikkelaarshulpmiddelen
Het ervaren van een Flink-ontwikkelaar hangt, in sommige mate, af op welke API u kiest: of de oudere, lagere niveau DataStream API of de nieuwere, relatieve Tabel en SQL-API’s.
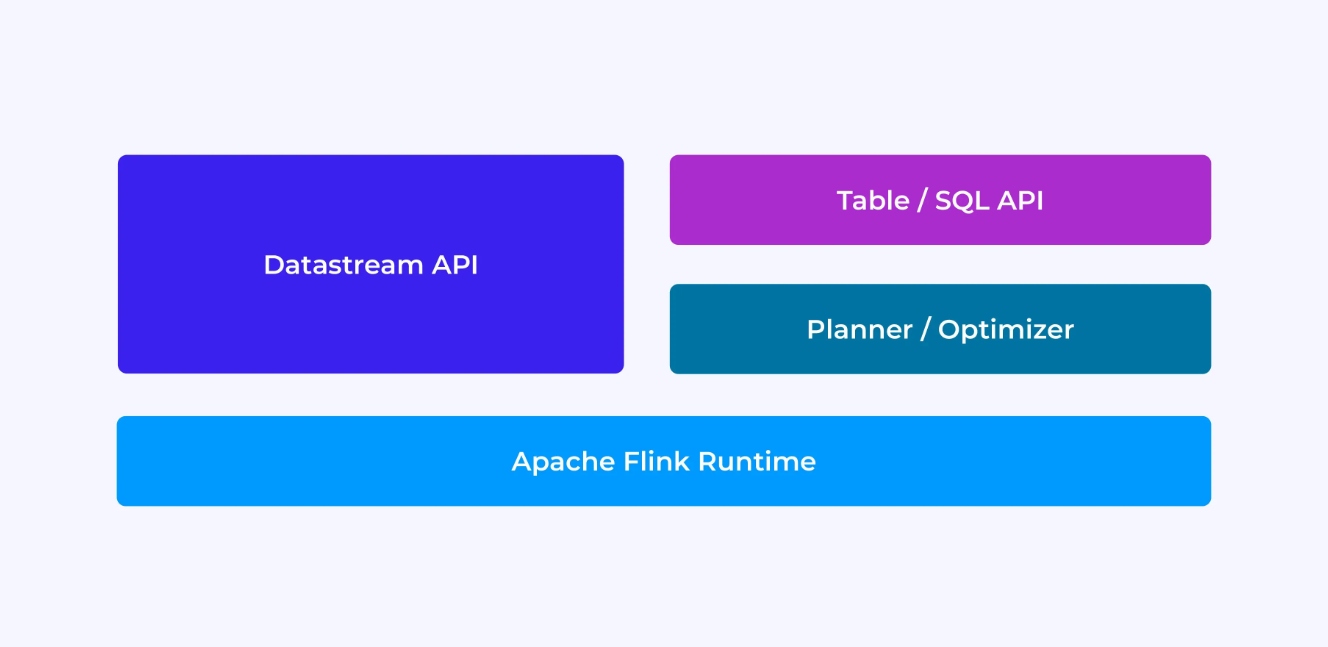
Als u programmeert met Flink’s DataStream API, denkt u bewust na over wat de Flink runtime zal doen bij het uitvoeren van uw toepassing. Dit betekent dat u de job graph stap voor stap opbouwt, deel uitmakende van de staat die u gebruikt, en de betreffende typen en hun serialisatie, timers aanmaakt en callbackfuncties implementeert die worden uitgevoerd wanneer die timers worden afgeroepen, enzovoort. De kernabstractie in de DataStream API is het evenement, en de functies die u schrijft zullen een evenement per keer afhandelen, zoals ze arriveren.
Anderzijds, als u de Table/SQL API van Flink gebruikt, worden deze lagere niveau zorgen voor u gekregen, en u kunt zich meer direct op uw bedrijfslogica richten. De kernabstractie is de tabel, en u denkt meer in termen van tabelen samenvoegen voor verrijking, rijen bij elkaar groeperen om geaggregeerde analytics uit te voeren, enzovoort. Een ingebouwde SQL-queryplanner en optimizer neemt de details voor u waar. De planner/optimizer doet een uitstekende job van resourcebeheer efficiënt te behandelen, vaak beter dan handgeschreven code.
Een paar gedachten vooraleer we de details in gaat: eerstens, u hoeft niet te kiezen tussen de DataStream of de Table/SQL API – beide APIs zijn interoperabel, en u kunt ze combineren. Dat kan een goede manier zijn als u wat aangepaste functionaliteit nodig heeft die niet mogelijk is in de Table/SQL API. Maar een andere goede manier om buiten de scope van de Table/SQL API uit te komen is om enkele aanvullende functionaliteiten toe te voegen in de vorm van gebruikergedefinieerde functies (UDFs). Hier biedt Flink SQL veel opties voor uitbreiding.
Bouwen van de Job Graph
Hoewel u kiest welke API u gebruikt, is het uiteindelijke doel van het schrijven van de code om de takengraph te bouwen die de Flink-runtime voor u zal uitvoeren. Dit betekend dat deze API’s gericht zijn op het maken van operators en het specificeren van zowel hun gedrag als hun connecties tot elkaar. Met de DataStream API bouwt u direct de takengraph, terwijl dit met de Table/SQL API wordt gedaan door de SQL-planner van Flink.
Functies en Data Serializeren
Uiteindelijk zal de code die u aan Flink geeft in parallel worden uitgevoerd door de werkers (de taakmanagers) in een Flink-cluster. Om dit te laten gebeuren, worden de functieobjecten die u maakt gedeserialiseerd en naar de taakmanagers verzonden, waar ze worden uitgevoerd. eveneens moeten de gebeurtenissen soms worden gedeserialiseerd en over het netwerk van een taakmanager naar een andere verzonden. Opnieuw hoeft u hiervoor geen rekening te houden met de Table/SQL API.
State Beheren
De Flink-runtime moet worden op de hoogte gesteld van elke staat die u verwacht dat het voor u hersteld wordt bij een fout. Om dit te laten werken, heeft Flink nodig aan type-informatie die kan worden gebruikt om deze objecten te serialiseren en te deserialiseren (zodat ze in checkpoints kunnen worden geschreven en gelezen). U kunt optioneel deze geëngineerde staat configureren met tijd-tot-leven-beschrijvers die Flink gebruikt om de staat automatisch te verwijderen zodra deze zijn nuttigheid verloren heeft.
Met de DataStream API komt u meestal direct beheer terecht over de toestand die uw toepassing nodig heeft (de ingebouwde vensterbewerkingen zijn de enige uitzondering op dit gebied). Aan de andere kant is de zorg voor deze zaken met de Table/SQL API abstractie. Bijvoorbeeld, given een query zoals onderstaand, weet u dat er ergens in de Flink runtime een datastructuur moet worden bijgehouden een teller voor elke URL, maar de details worden allemaal voor u afgehandeld.
SELECT url, COUNT(*)
FROM pageviews
GROUP BY URL;Instellen en activeren van timers
Timers hebben veel toepassingen in stream processing. Bijvoorbeeld, het is niet ongebruikelijk voor Flink-toepassingen om informatie te verzamelen uit veel verschillende gebeurtenisbronnen voordat uiteindelijk resultaten worden gegenereerd. Timers werken goed voor gevallen waar het maar zin heeft te wachten (maar niet ondefinitief) op gegevens die misschien (of misschien niet) uiteindelijk zullen arriveren.
Timers zijn ook essentieel voor het implementeren van tijd gebaseerde vensterbewerkingen. Zowel de DataStream als de Table/SQL-API’s hebben ingebouwde ondersteuning voor vensters en maken en beheren timers voor u.
Toepassingsgebieden
Teruggaande naar de drie brede categorieën van streamen gebruiksgevallen die aan het begin van dit artikel werden geïntroduceerd, zie hoe ze overgaan naar wat u zojuist heeft geleerd over Flink.
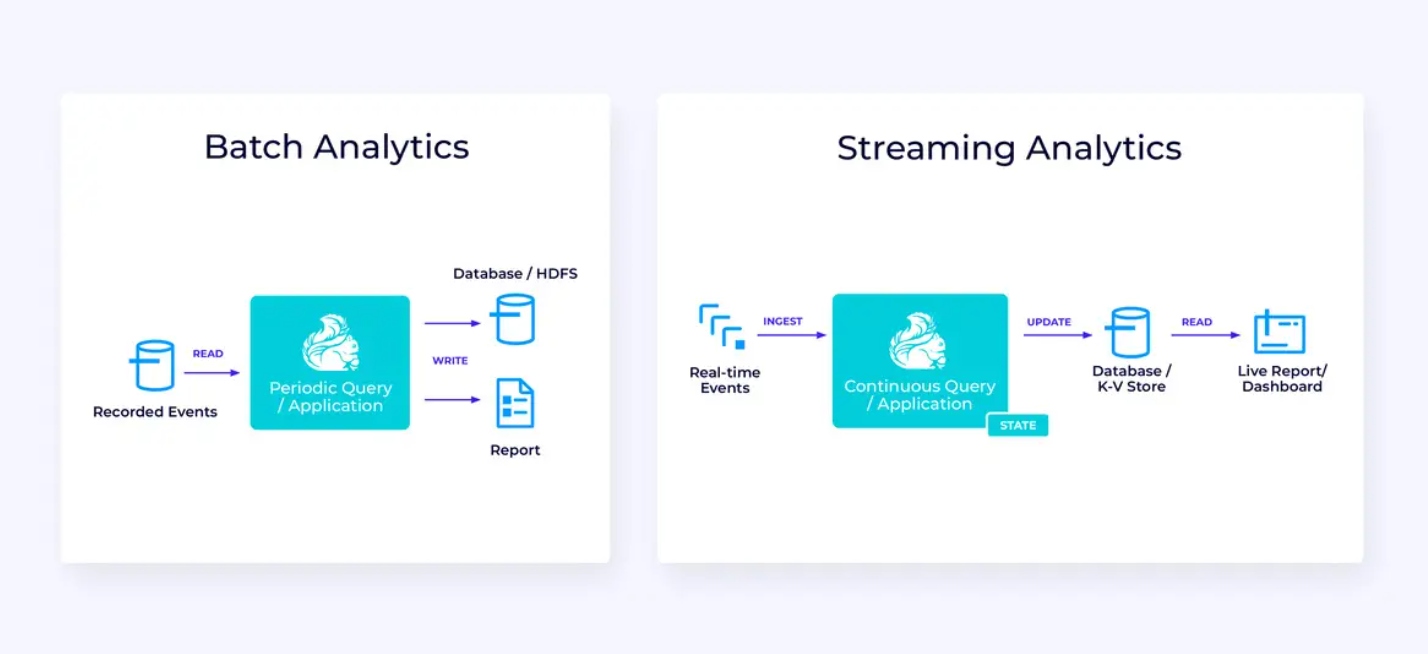
Streamen datapijp
Hieronder, aan links, is een voorbeeld van een traditionele batch extract, transformeer en laden (ETL) taak die periodiek uit een transactiegegevensbank leest, de gegevens transformeert en de resultaten schrijft naar een andere gegevensopslag, zoals een database, bestandsysteem of data lake.
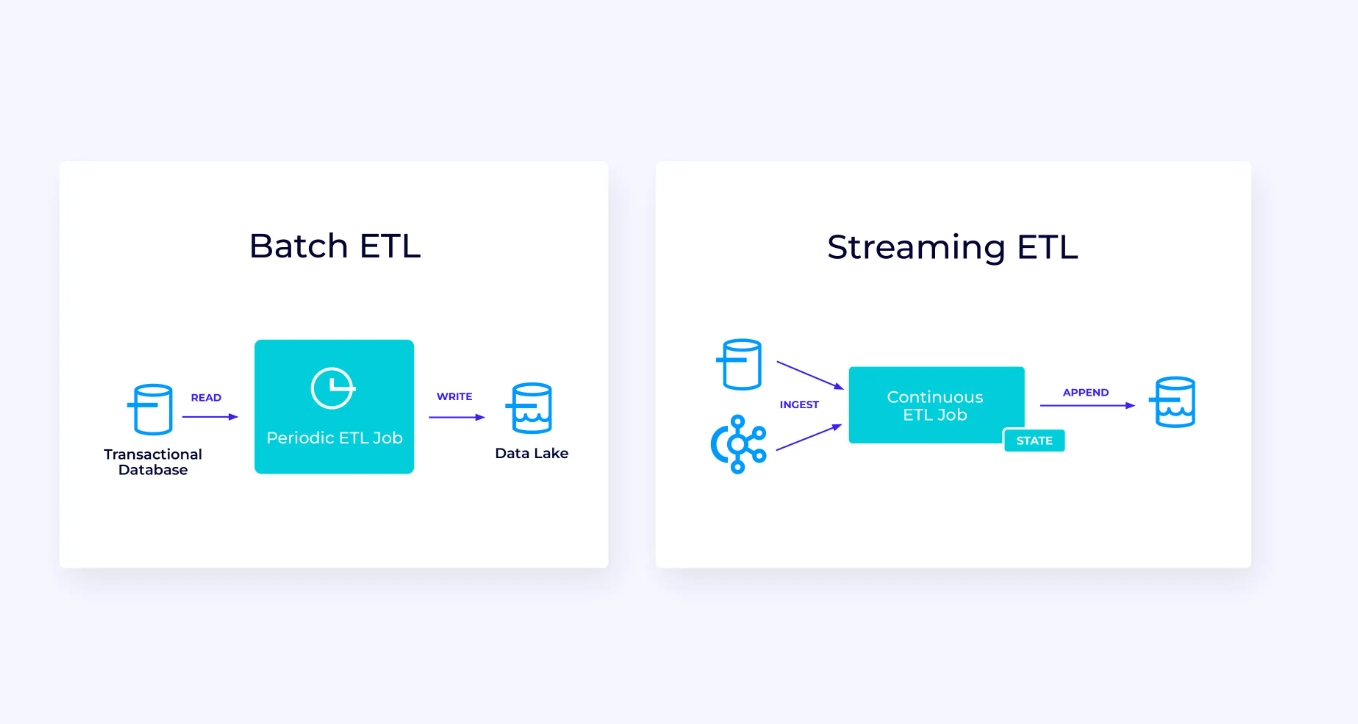
De corresponderende streamen pijp lijkt op het eerste gezicht op zijn gelijken, maar heeft enkele significante verschillen:
- De streaming pipeline draait altijd.
- Het transactiegegevens wordt verzonden naar de streaming pipeline in twee delen: een initiële bulk load uit de database, in combinatie met een change data capture (CDC) stream die de database updates bevat sinds die bulk load.
- De streaming versie produceert nieuwe resultaten altijd zodra ze beschikbaar zijn.
- Het geheugen wordt expliciet beheerd zodat het in geval van een fout robuust hersteld kan worden. Streaming ETL-pipelines gebruiken meestal weinig geheugen. De gegevensbronnen houden exact bij hoe veel van de invoer is ingelezen, meestal in de vorm van offsets die aantallen records tellen vanaf het begin van de streams. De storage systemen gebruiken transacties om hun schrijfoperaties naar externe systemen te beheren, zoals databases of Kafka. Tijdens checkpointing worden de bronnen hun offsets vastgelegd, en de storage systemen bevestigen de transacties die de resultaten bevatten van het precies tot, maar niet verder dan, die bron offsets hebben gelezen.
Voor dit gebruiksscenario zou de Table/SQL API een goede keuze zijn.
Real-Time Analytics
Vergeleken met de streaming ETL-toepassing heeft deze streaming analytics-toepassing enkele interessante verschillen:
- Opnieuw wordt Flink gebruikt om een continue toepassing uit te voeren, maar voor deze toepassing zal Flink waarschijnlijk een substantieel groter geheugen moeten beheren.
- Voor dit gebruiksscenario maakt het makkelijker voor de stream die wordt ingelezen om opgeslagen te worden in een stream-native opslag systeem, zoals Apache Kafka.
- In plaats van periodiek een statische rapport te produceren, kan de streaming versie gebruikt worden om een live dashboard aan te drijven.
Opnieuw is de Tabel/SQL API meestal een goede keuze voor ditgebruik.
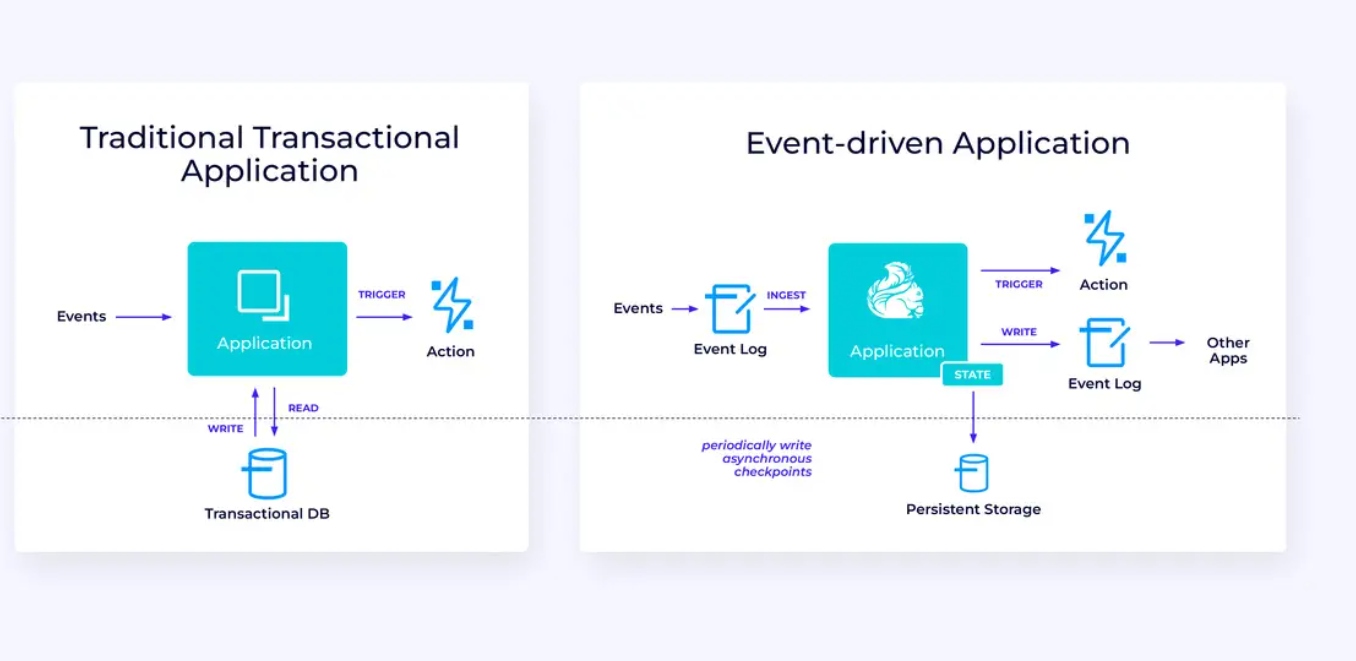
Eventge drijven Applicaties
Ons derde en laatste gezins van gebruiksgevallen betreft de implementatie van eventge drijvende applicaties of microservices. Er is veel andere waarover geschreven op dit onderwerp; dit is een architectonisch ontwerppatroon dat veel voordelen heeft.
Flink kan een uitstekende keuze zijn voor deze applicaties, vooral als u de soort van prestaties nodig heeft die Flink kan leveren. In sommige gevallen heeft de Tabel/SQL API alles wat u nodig heeft, maar in veel gevallen zal u de aanvullende flexibiliteit nodig van de DataStream API voor ten minste een deel van het werk.
Beginnen met Flink
Flink biedt een krachtige framework voor het bouwen van applicaties die gebeurtenisstromen verwerken. Zoals we hebben overzien, kunnen sommige concepten aanvankelijk vreemd aanvoelen, maar zodra u bekend bent met de manier waarop Flink is ontworpen en werkt, is het software gemakkelijk te gebruiken en de beloning van Flink kennen is significant.
Als een volgende stap, volg de instructies in de Flink documentatie, die u door het proces van downloaden, installeren en uitvoeren van de nieuwste stabiele versie van Flink zal leiden. Overweeg de brede gevallen van gebruik die we besproken hebben – moderne data pijplijnen, real-time analytics en eventge drijvende microservices – en hoe deze kunnen helpen om een uitdaging aan te spreken of waardevolle drive voor uw organisatie.
Data streamen is een van de meest spannende gebieden in hedendaagse bedrijfstechnologie en streamverwerking met Flink maakt het nog krachtiger. Het leren van Flink zal niet alleen nuttig zijn voor uw organisatie, maar ook voor uw carrière, want real-time dataverwerking wordt wereldwijd steeds meer waardevoller voor bedrijven. Controleer dus vandaag nog op Flink en zie wat deze krachtige technologie u kunt helpen bereiken.
Source:
https://dzone.com/articles/apache-flink-101-a-guide-for-developers