













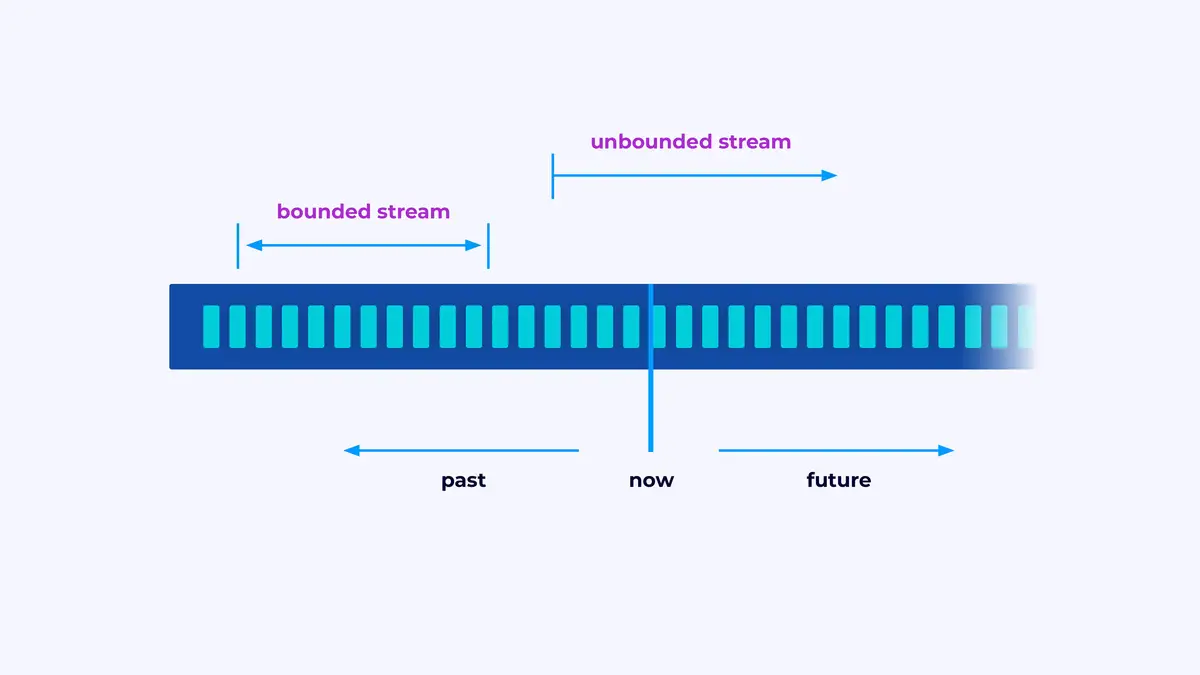
최근 몇 해 동안 Apache Flink은 실시간 스트림 처리의 사실상 표준이 되었습니다. 스트림 처리는 이벤트 스트림(시간에 따라 이벤트의 시퀀스)를 가장 essental building block로 여기는 시스템 구축의 paradigm입니다. Flink과 같은 스트림 처리기는 이벤트 소스로부터 생성되는 입력 스트림을 소비하고 삽입 스트림을 생성하고 있으며, 삽입 스트림은 삽입 장치(삽입 장치는 결과를 저장하고 추가 처리에 사용할 수 있는 것을 제공합니다.)로 이동합니다.
Amazon, Netflix, Uber과 같은 가정 이름들은 자신의 사업 근심의 가장 중요한 부분에서 hugescale로 실시간 Datapipeline를 동작시키기 위해 Flink을 依存하고 있으며, Flink은 빠르게 중요한 사업 이벤트에 대한 반응을 위한 유사한 요구를 가진 많은 smaller company에서도 중요한 rolls을 하고 있습니다.
Flink은 어떻게 사용되고 있을까요? 일반적인 사용 사례는 이러한 세 개의 ategorie에 해당합니다:
|
스트림 데이터 파이프라인 |
실시간 분석 |
이벤트 기반 응용 |
|---|---|---|
|
데이터 스트림을 지속적으로 소비하고, 개선하고, 변경하고, 지속적으로 azione할 수있는 이를 수신 시스템으로 이동시키는 것(batch processing와 대조적으로) |
결과를 계속해서 생성하고 갱신하며, 사용자에게 real-time data stream을 소비하면서 표시하고 제공합니다. |
이벤트를 수신하면서 모양을 인지하고, 계산을 실시하고, 상태 갱신 또는 외부 행위를 트리거하는 것입니다. |
|
이러한 예들이 있습니다:
|
예시:
|
예시:
|
플링크 포함:
- 글로벌 기업이 필요로 하는 규모의 데이터 스트리밍 워크로드에 대한 강력한 지원
- 정확한 정확성 및 장애 복구에 대한 강력한 보장
- 배치 및 스트림 처리를 모두 통합 지원하는 Java, Python 및 SQL 지원
- Flink는 Apache Software Foundation의 성숙한 오픈 소스 프로젝트이며 매우 활발하고 지지적인 커뮤니티를 보유하고 있습니다.
Flink는 복잡하고 배우기 어렵다고 알려져 있습니다. 네, Flink의 런타임 구현이 복잡한 것은 사실이지만 어려운 문제를 해결하기 때문에 놀랄 일은 아닙니다. Flink API는 배우기 다소 어려울 수 있지만, 이는 본질적인 복잡성보다는 개념과 구성 원리가 익숙하지 않은 것과 더 관련이 있습니다.
Flink은 이전에 사용过度的 것과 다르게 기능하지만, 많은 면에서 실제로 상당히 간단해요. 뭔가 해당되는 지점에, Flink이 어떻게 구성되어 있는지 famililar하게 되고, runtime으로 해결해야하는 문제들을 배워봐요. Flink의 API의 세부 사항은 Flink의 FEW 주요 원칙의 显然한 결과라는 것이라고 느낀다고 해야돼요, 읽어야 할 arcane detail의 모음이 아닌 것이죠.
이 글은 Flink을 배우는 여행을 어느程度上 더 이해하기 쉽게 만들기 위해서, 그 기획의 的核心원칙을 기술하고 있어요.
Flink은 몇 가지 큰 아이디어를 具体化시켰어요.
Streams
Flink은 이벤트 스트림을 처리하는 응용 프레임웍을 제공하는 것이에요. 스트림은 이벤트의 한 序列이나 이를 구하고자 하는 것을 제한하지 않는다는 의미의 한 序列이에요.
Flink 응용은 데이터 처리 펑션 ipeline로 표현되어 있어요. 이벤트는 이러한 펑션 pipeline를 통과하고, 코드를 썼을 때 어느 단계에서 어느 것을 수행할지 정해지는 것이에요. 이러한 펑션을 일의 그래프라고 부르며, 이러한 그래프의 노드(或者说, 처리 펑션 pipeline의 단계)를 操作者라고 합니다.
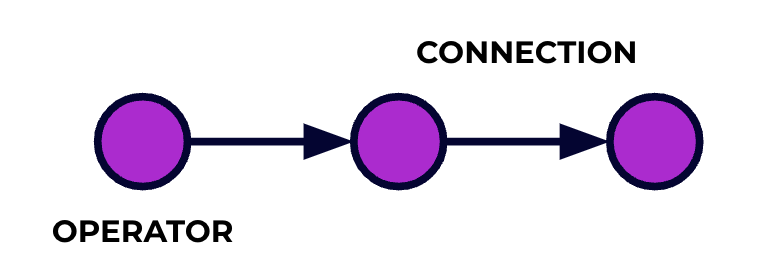
API를 사용하여 썼던 코드는 일의 그래프를 기술하며, 操作者의 행위와 그들의 연결을 包括하고 있어요.
Parallel Processing
각 操作者는 여러 paralle instance를 가질 수 있어요, 이러한 모든 instance는 이벤트의 일부로 독립적으로 동작합니다.
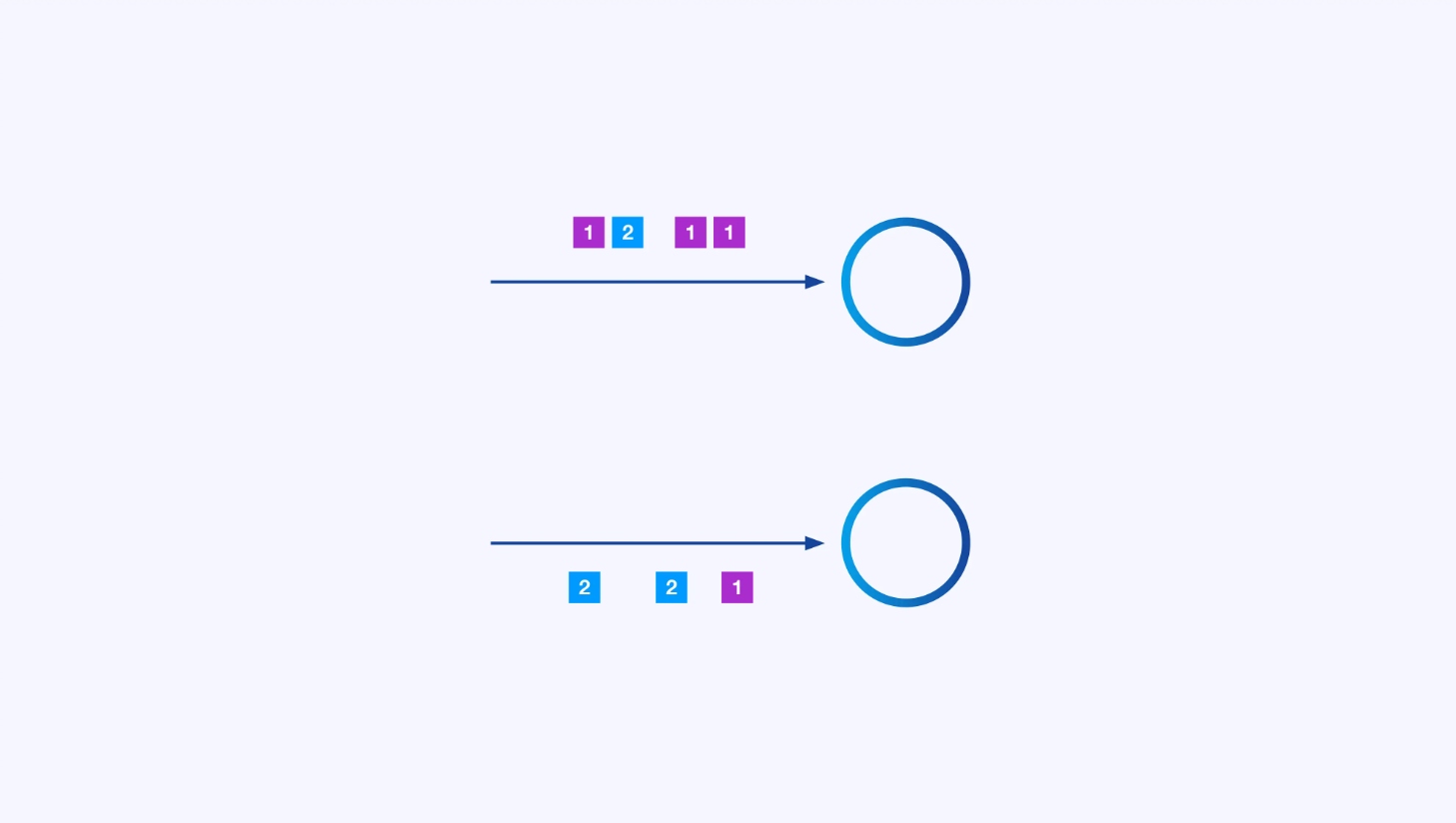
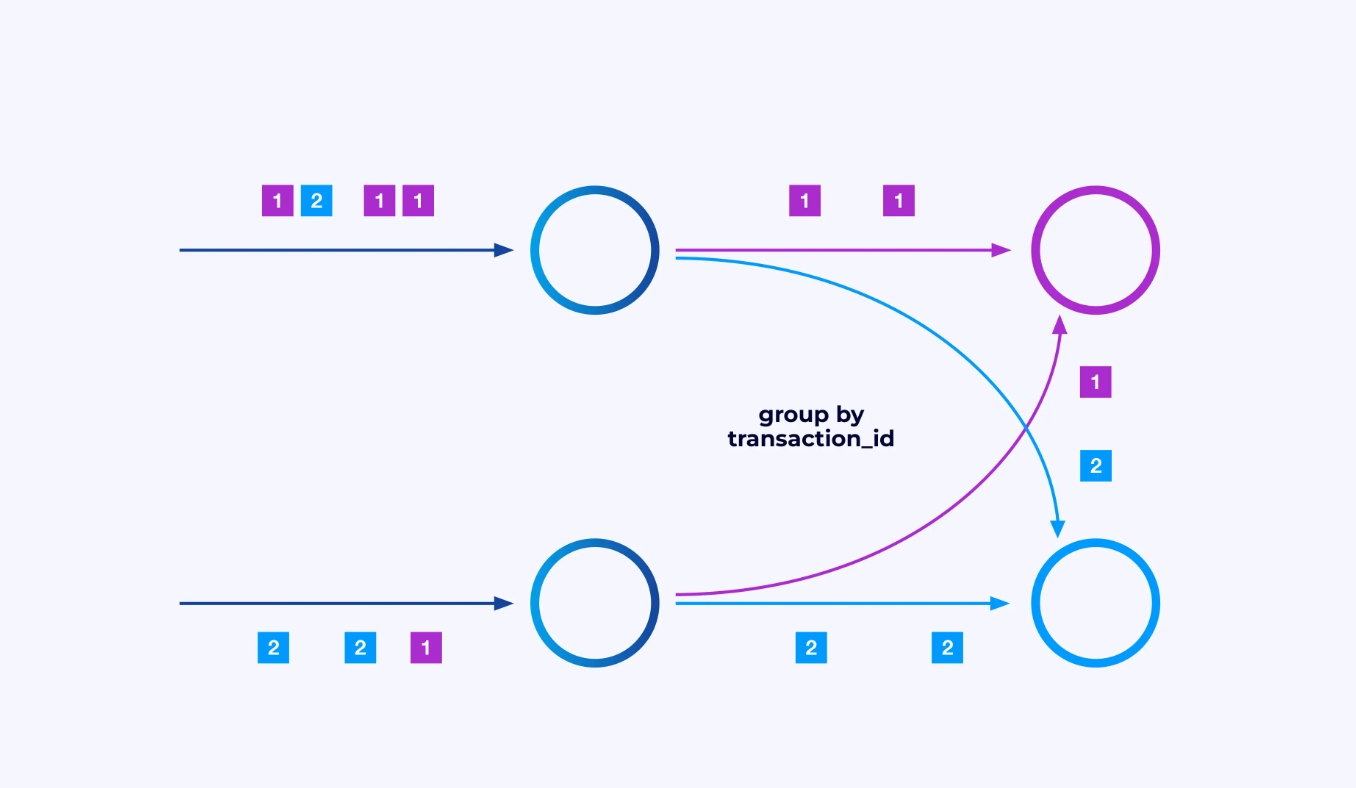
때로는 이러한 서브스트림에 특정 분할 스키마를 적용하여 어떤 응용 specifiec 로직에 따라 이벤트가 그룹화되는 것을 원할 수 있습니다. 예를 들어, finanical transaction을 처리하는 경우, 각 transaction의 이벤트가 같은 thread에서 처리되도록 조정해야 할 수 있습니다. 이这将 각 transaction의 이벤트가 시간이 지나 발생하는 various event를 연결하게 됩니다.
Flink SQL로서는 GROUP BY transaction_id로 이를 실시하며, DataStream API로서는 keyBy(event -> event.transaction_id)을 사용하여 이 그룹화 또는 분할을 지정합니다. 이러한 경우, 일의 그래프에서는 그래프의 두 连续 단계 사이에 전체 연결 network shuffle가 보입니다.
State
key-partitioned stream에 작업하는 오퍼레이터는 Flink의 분산 key/value state store를 사용하여 他们想要的 무결하게 지속되는 상태를 지정할 수 있습니다. 각 key의 상태는 특정 오퍼레이터 인스턴스에 로컬적으로 유지되며, 다른 곳에서 접근할 수 없습니다. paralle sub-topologies은 공유하는 것이 없습니다. 이것은 제한없는 확장성을 위한 중요한 요소입니다.
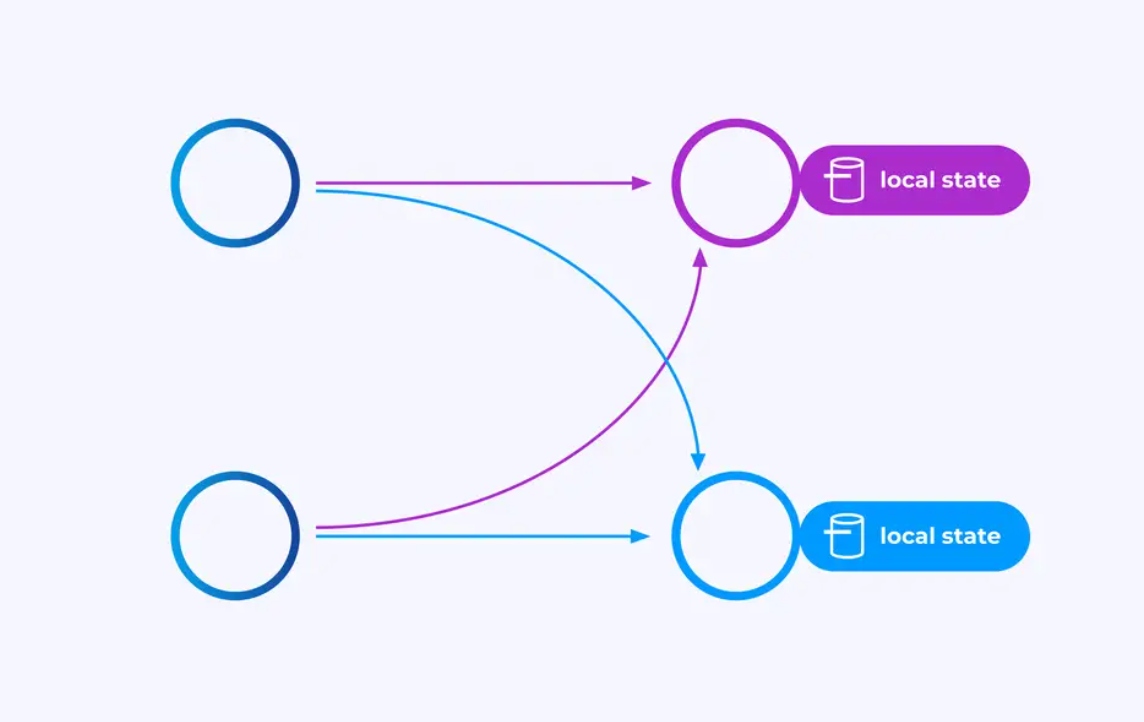
Flink 일을 无线 시간동안 실행 시키는 것이 가능합니다. Flink 일이 지속적으로 새로운 key를 생성하는 것(예 : transaction ID)이고 각 새로운 key에 대해 어떤 것을 저장하는 것이면 그 일이 연 degrading state를 사용하는 것을 위험izeble 해질 수 있습니다. Flink의 모든 API는 상태가 제한없이 Bomit하는 것을 방지하기 위한 방법을 제공하는 것을 기반으로 구성되어 있습니다.
Time
하나의 상태를 지속적으로 유지하지 않는 방법 중의 하나는 특정 시간 지점까지 유지하는 것입니다. 예를 들어, 분 単位로 거래 수를 카운트하고자 하면, 각 분이 끝나면 그 분의 결과를 생성할 수 있고, 그 카운TER를 해제할 수 있습니다.
Flink은 두 가지 다른 시간 관념을 중요하게 구분합니다.:
- 처리 (또는 壁时计) 시간, 이벤트가 처리되는 실제 시간에서 派生되는 시간
- 이벤트 시간, 이벤트에 함께 기록된 시기를 기반으로 구해지는 시간
이들의 차이를 이해하기 위해, 분 単位의 widow가 완료되는 것의 의미를 고려해보십시오.:
- 처리 시간 widow가 완료되는 것은 분이 끝나는 时刻이며, 이 것은 완전히 간단합니다.
- 이벤트 시간 window가 완료되는 것은 그 분 안에 발생한 모든 이벤트가 처리되었다는 것입니다. 이러한 과정은 Flink이 아직 처리하지 않은 이벤트에 대한 정보를 가지고 있지 않기 때문에 어려울 수 있습니다. 우리는 스ream이 얼마나 늦게 到达할 수 있는지 의사 결정을 하고 이를 heuristically 적용할 수 밖에 없습니다.
실패 복구를 위한 Checkpointing
실패는 inevitable합니다. 尽管 실패, Flink은 실제로 정확히 一次 보장을 제공할 수 있습니다. 이 의미는 각 이벤트가 Flink이 관리하는 상태에 정확히 once에 영향을 미칠 것입니다. 실패가 발생하지 않았을 것 같습니다. 이를 achieve하기 위해, Flink은 모든 상태를 regular interval로 구성하는 전체적으로 자신에 대한 일관성이 있는 스냅샷을 인정적으로 TAKE하고 있습니다. 이러한 스냅샷은 Flink이 자동적으로 생성하고 관리하며, checkpoint라고 불립니다.
회복 과정에서는 가장 최근의 检查点에 저장된 상태로 되돌리고, 그 检查点から 모든 opera tor를 重启하는 과정이 있다. 회복 과정 동안, 某些 event가 다시 처리되지만, Flink은 각 checkpoint이 시스템의 전체 상태를 表시하는 전역적인 자체 일치 사진(self-consistent snapshot)이라는 것을 보장하여 정확성을 보장할 수 있다.
시스템 Architecture
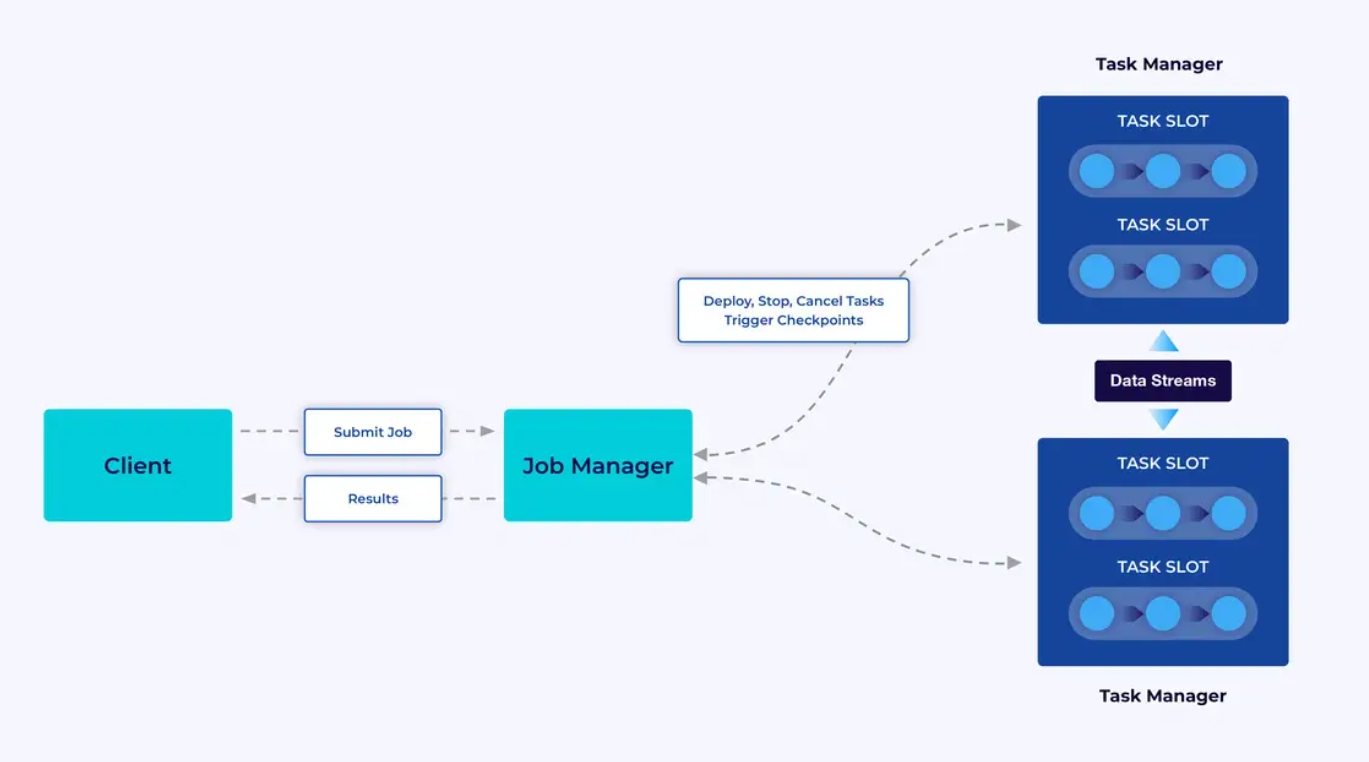
Flink 应用程序은 Flink 集群에서 실행되므로, Flink 应用程序을 생산環境에 投入하려면, 그것을 배포할 集群이 필요하다. ortunately, 開発과 테스트 동안, IntelliJ 또는 Docker 같은 Integrated Development Environment (IDE)에서 Flink을 로컬에서 시작하는 것이 쉽다.
Flink 集群은 두 종류의 component이 있다: Job Manager와 Task Manager의 집합이다. Task Manager는 应用程序(들)을 paralle로 실행하고, Job Manager는 Task Manager와 外界의 문을 여는 역할을 한다. 应用程序은 Job Manager에 제출되며, Task Manager에서 제공되는 자원을 관리하고, checkpointing을 조정하고, 集群의 성능 지표로 cluster의 안정성을 제공한다.
개발자 경험
Flink 개발자로서 당신이 against, 老旧的, 낮은 수준의 DataStream API를 선택하는 것이 与否決적이다. 이는 새로운, 관계형 Table and SQL APIs로 해결할 수 있다.
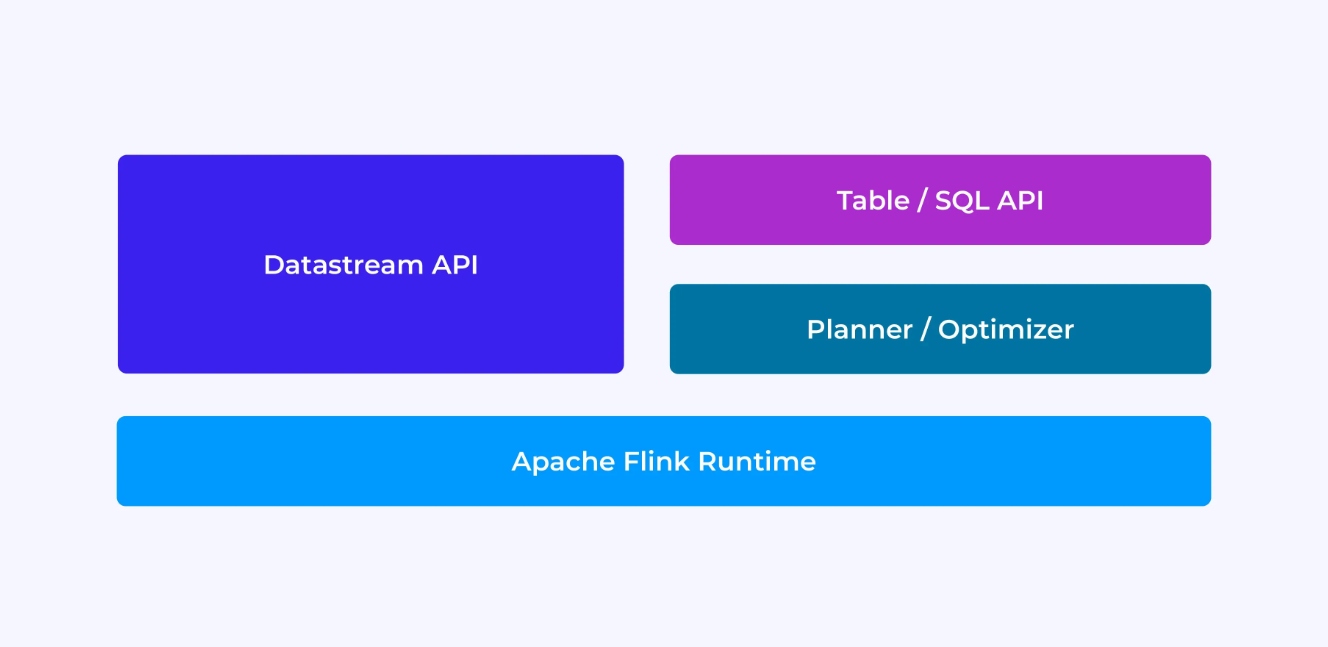
Flink의 DataStream API로 프로그래밍을 할 때는 애플리케이션을 실행할 때 Flink 런타임이 무엇을 할 것인지 의식적으로 생각하게 됩니다. 즉, 한 번에 하나의 연산자씩 작업 그래프를 작성하고, 사용 중인 상태와 관련된 유형 및 직렬화를 설명하고, 타이머를 만들고, 타이머가 트리거될 때 실행될 콜백 함수를 구현하는 등의 작업을 수행하게 됩니다. 데이터스트림 API의 핵심 추상화는 이벤트이며, 여러분이 작성하는 함수는 이벤트가 도착할 때마다 한 번에 하나씩 처리하게 됩니다.
반면, Flink의 Table/SQL API를 사용하면 이러한 저수준의 문제는 자동으로 처리되므로 비즈니스 로직에 더 직접적으로 집중할 수 있습니다. 핵심 추상화는 테이블이며, 보강을 위한 테이블 조인, 집계된 분석을 계산하기 위해 행을 그룹화하는 등의 측면에서 더 많은 것을 생각하게 됩니다. 내장된 SQL 쿼리 플래너와 최적화 도구가 세부 사항을 처리합니다. 플래너/최적화 도구는 리소스를 효율적으로 관리하는 데 탁월한 성능을 발휘하며, 종종 직접 작성한 코드를 능가합니다.
자세한 내용을 살펴보기 전에 몇 가지 더 고려할 사항은 첫째, DataStream 또는 Table/SQL API를 선택할 필요 없이 두 API를 상호 운용할 수 있으며 결합할 수 있다는 점입니다. Table/SQL API에서는 불가능한 약간의 사용자 정의가 필요한 경우 좋은 방법이 될 수 있습니다. 하지만 Table/SQL API가 기본적으로 제공하는 기능을 넘어서는 또 다른 좋은 방법은 사용자 정의 함수(UDF)의 형태로 몇 가지 추가 기능을 추가하는 것입니다. 여기서 Flink SQL은 다양한 확장 옵션을 제공합니다.
작업 그래프 구성하기
어떤 API를 사용하든, 작성하는 코드의 궁극적인 목적은 Flink의 런타임이 사용자를 대신해 실행할 작업 그래프를 구성하는 것입니다. 즉, 이러한 API는 연산자를 생성하고 연산자의 동작과 서로의 연결을 지정하는 것을 중심으로 구성되어 있습니다. 데이터스트림 API를 사용하면 작업 그래프를 직접 구성하는 반면, 테이블/SQL API를 사용하면 Flink의 SQL 플래너가 이를 처리합니다.
함수와 데이터 직렬화
최종적으로 Flink에 제공하는 코드는 Flink 클러스터의 워커(작업 관리자)에 의해 병렬로 실행됩니다. 이를 위해 사용자가 생성한 함수 객체는 직렬화되어 작업 관리자에게 전송되어 실행됩니다. 마찬가지로 이벤트 자체도 때때로 직렬화되어 네트워크를 통해 한 작업 관리자에서 다른 작업 관리자로 전송되어야 할 때가 있습니다. 다시 말하지만, Table/SQL API를 사용하면 이에 대해 생각할 필요가 없습니다.
상태 관리
장애 발생 시 Flink 런타임은 사용자가 복구할 것으로 예상되는 모든 상태를 인식해야 합니다. 이를 위해 Flink는 이러한 객체를 직렬화하고 역직렬화하는 데 사용할 수 있는 유형 정보가 필요합니다(이를 통해 체크포인트에 쓰거나 체크포인트에서 읽을 수 있음). 이 관리 상태를 선택적으로 수명 기간 디스크립터를 사용하여 구성할 수 있으며, 이 디스크립터는 Flink가 유용성이 다한 상태를 자동으로 만료하는 데 사용됩니다.
DataStream API를 사용하면 일반적으로 애플리케이션에 필요한 상태를 직접 관리하게 됩니다(내장된 창 작업은 예외입니다). 반면에 Table/SQL API를 사용하면 이러한 문제가 추상화됩니다. 예를 들어, 아래와 같은 쿼리가 있다고 가정하면, Flink 런타임 어딘가에 각 URL에 대한 카운터를 유지해야 하는 데이터 구조가 있지만 세부 사항은 모두 사용자가 알아서 처리합니다.
SELECT url, COUNT(*)
FROM pageviews
GROUP BY URL;타이머 설정 및 트리거
타이머는 스트리밍 처리에서 많은 용도로 사용됩니다. 예를 들어, Flink 애플리케이션은 최종적으로 결과를 생성하기 전에 다양한 이벤트 소스에서 정보를 수집해야 하는 경우가 많습니다. 타이머는 최종적으로 도착할 수도 있고 도착하지 않을 수도 있는 데이터를 무한정 기다리는 것이 합당한 경우에 적합합니다.
타이머는 시간 기반 윈도우 작업을 구현하는 데도 필수적입니다. DataStream과 Table/SQL API는 모두 Windows를 기본적으로 지원하며 사용자를 대신해 타이머를 생성하고 관리합니다.
사용 사례
이 글의 서두에서 소개한 세 가지 스트리밍 사용 사례로 돌아가서, 이 사례들이 지금까지 Flink에 대해 배운 내용과 어떻게 매핑되는지 살펴봅시다.
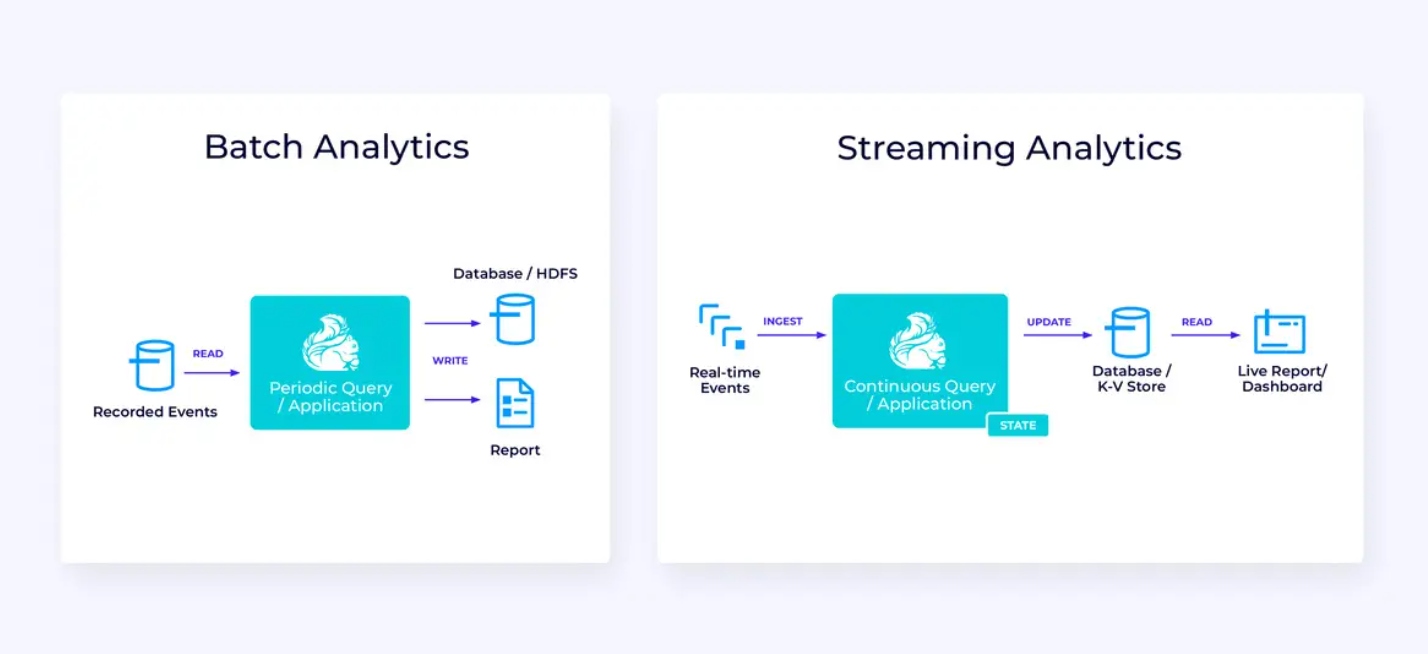
스트리밍 데이터 파이프라인
아래 왼쪽은 트랜잭션 데이터베이스에서 주기적으로 데이터를 읽고, 데이터를 변환한 후 결과를 데이터베이스, 파일 시스템 또는 데이터 레이크와 같은 다른 데이터 저장소에 쓰는 전통적인 배치 추출, 변환 및 로드(ETL) 작업의 예입니다.
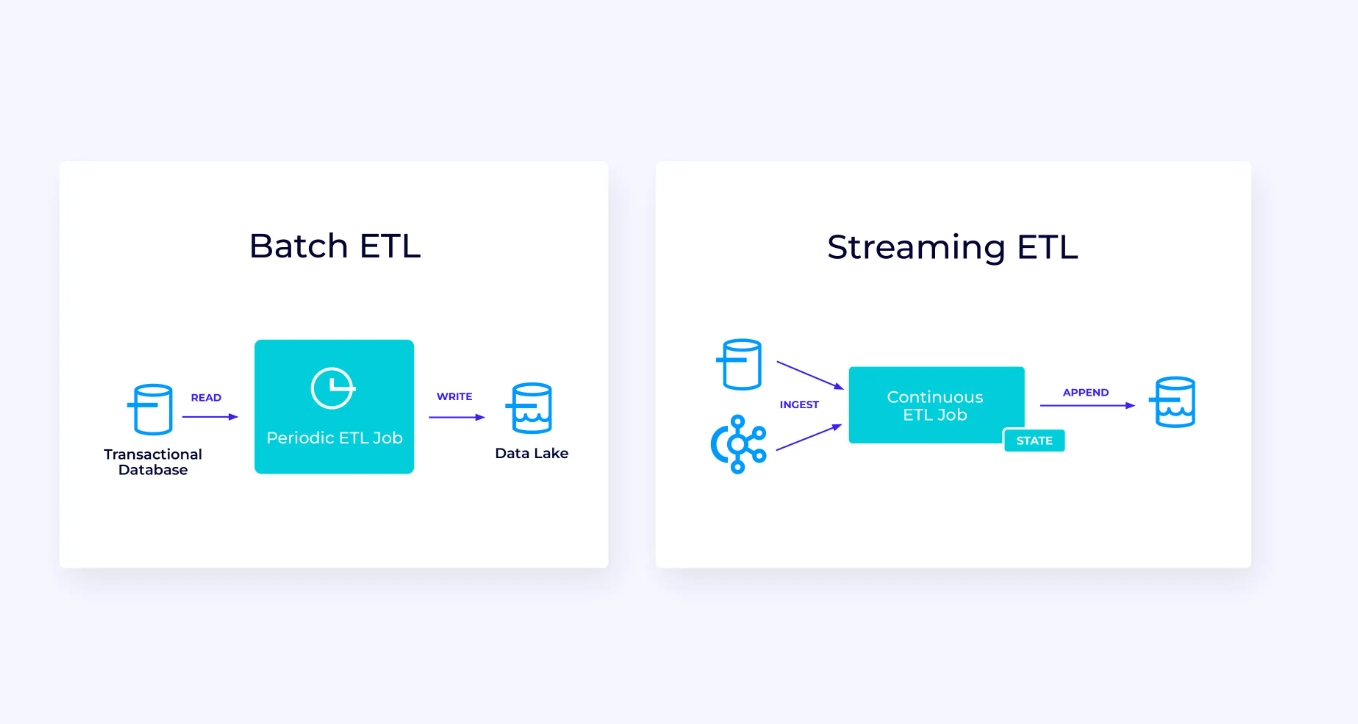
상응하는 스트리밍 파이프라인은 표면적으로 유사하지만 몇 가지 중요한 차이점이 있습니다:
- 스트reaming 파이프라인은 always running.
- Transaction data는 스트reaming 파이프라인에 두 部分로 제공되ます: 데이터 베이스から 초기 大众 로딩, 이를 통한 Change Data Capture (CDC) 스트ream이 데이터 베이스 업데이트를 전달합니다.
- Streaming version은 새로운 result를 계속해서 생성합니다.
- State는 명시적으로 관리되어 에러 발생 시 강한 재구성 가능하도록 되어 있습니다. Streaming ETL pipelines는 일반적으로 state를 사용하는 것이 적습니다. 데이터 소스는 입력 data가 인gested되었는지 정확하게 추적하는 방식으로, 스트ream의 시작 시점 이후 레코드의 오프셋을 사용합니다. Sink는 데이터베이스나 Kafka 같은 外的 시스템에 쓰기를 관리하기 위해 트랜잭션을 사용합니다. 체크 포인트 하는 동안, 소스는 오프셋을 기록하고, Sink는 소스 오프셋까지, 그러나 그 オフ셋을 벗어나지 않은 것까지 읽은 것을 결과로 갖춘 트랜잭션을 확정합니다.
이 사용 사례에서는 Table/SQL API가 좋은 선택입니다.
실시간 분석
스트reaming ETL 应用程序과 대비해서, 이 스트reaming 분석 应用程序은 몇 가지 흥미로운 차이가 있습니다:
- 다시 한 번, Flink은 지속적인 응용程序을 실행하는 데 사용되고 있지만, 이 응용 program에서는 Flink이 상당히 더 많은 state를 관리해야 합니다.
- 이 사용 사례에서는 스트ream이 인gested되는 것을 저장하는 것이 중요합니다.
- periodically static report를 생성하는 것 대신, streaming version은 실시간 dashboard를 사용하는 것이 가능합니다.
다시 한 번, Table/SQL API는 이 사용 사례에 대해 일반적으로 좋은 선택이 될 수 있습니다.
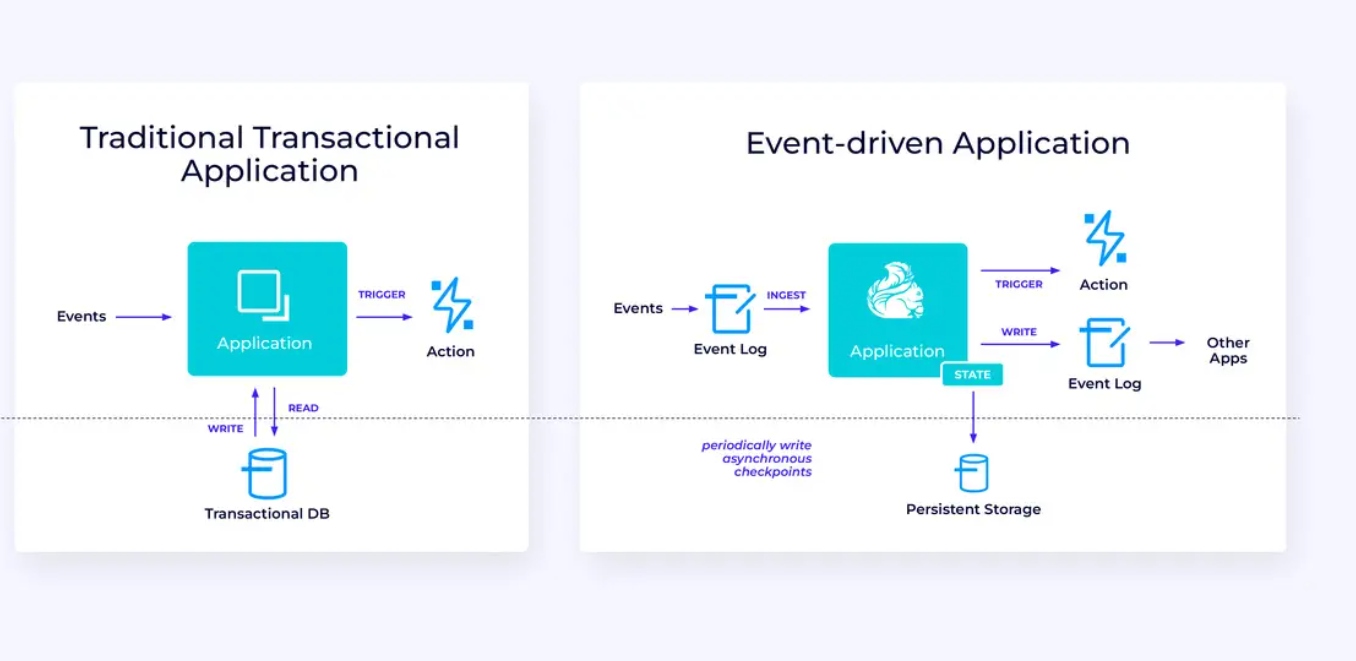
이벤트-기반 应用程序
우리의 第三의 그 final 가 이용 사례는 이벤트-기반 应用程序 또는 마이크로 서비스의 구현을 涉め고 있습니다. 이 주제에 대해 다른 곳에서 많은 것이 쓰여 있습니다; 이것은 시스템 기반 디자인 패턴으로 많은 이점이 있습니다.
Flink은 이러한 应用程序에 대해 좋은 해결 scheme가 될 수 있습니다. 특히, Flink이 제공하는 성능을 필요로 하는 경우에는 더욱 좋습니다. 일부 일정의 경우, Table/SQL API는 모든 것을 제공합니다만, 많은 경우에는 적절한 일부를 위해 DataStream API의 추가적인 유연성이 필요합니다.
Flink 시작하기
Flink는 이벤트 스트림을 처리하는 应用程序을 構築하는 強力한 프레임워크를 제공합니다. 우리가 다루었던 一些의 개념은 처음에는 낯설게 보일 수 있지만, Flink의 설계와 operaes를 熟悉하면 软件은 이해하기 쉽고, Flink을 熟悉하는 이점은 크게 Substantial합니다.
다음 단계로, Flink 문서에 있는 지침을 따라야합니다. 이것은 Flink의 最新 안정 버전을 다운로드, 설치하고 실행하는 과정을 指导할 것입니다. 우리가 다루었던 대형 사용 사례를 생각해보세요 – 현대 데이터 유입, 실시간 분석, 이벤트-기반 마이크로 서비스 – 이러한 것들이 어떤 도전을 해결하거나 조직에 가치를 창출하는 것에 어떻게 도울 수 있는지 생각해보세요.
오늘 기업 기술의 가장 exciting한 분야 중 하나로 데이터 스트리밍이 있으며, Flink을 사용하여 스트리밍 처리하면 더욱 강력해집니다. 실시간 데이터 처리가 글로벌 기업들에게 더욱 가치가 있어지고 있으므로, Flink을 배우는 것은 ваше 조직뿐만 아니라 ваше 직업적인 발전에서도 이점이 있습니다. 그렇기 때문에 Flink을 오늘 한번 확인하여 이 강력한 기술이 你们에게 어떻게 도울 수 있는지 확인하십시오.
Source:
https://dzone.com/articles/apache-flink-101-a-guide-for-developers