













在Python編程中,NumPy和Pandas是兩個最強大的庫,用於數值計算和數據操作。
NumPy:數值計算的基礎
NumPy(Numeric Python)支持多維數組和各種數學函數,使其成為科學計算中不可或缺的工具。
- NumPy是Python中用於數值計算的基礎庫。
- NumPy之所以在數值計算中如此重要的原因之一是,它針對大型數據數組的效率而設計。其中的原因包括:
- 它在內部以連續的內存塊存儲數據,與其他內置的Python對象獨立。
- 它對整個數組執行復雜的計算,無需“for”循環。
ndarray是一個高效的多維數組,提供快速的數組導向算術操作和靈活的廣播功能。- NumPy的
ndarray對象是Python中大數據集的快速靈活容器。 - 數組使你可以存儲相同數據類型的多個項目。正是圍繞數組對象的功能使得NumPy在執行數學和數據操作時如此方便。
NumPy操作
創建數組:

重塑數組:

切片和索引:

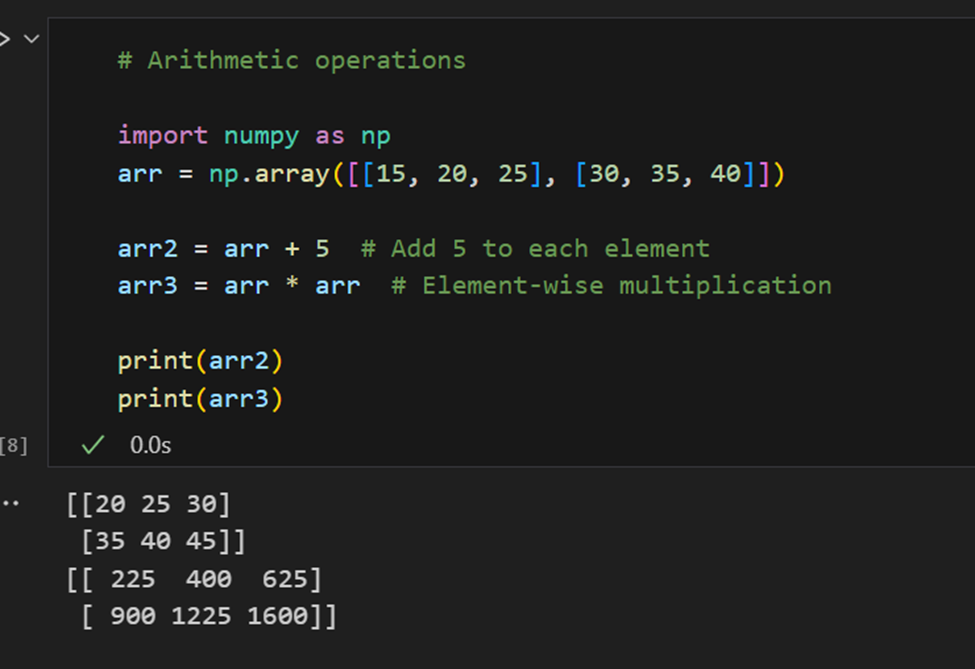
算術運算:
線性代數:

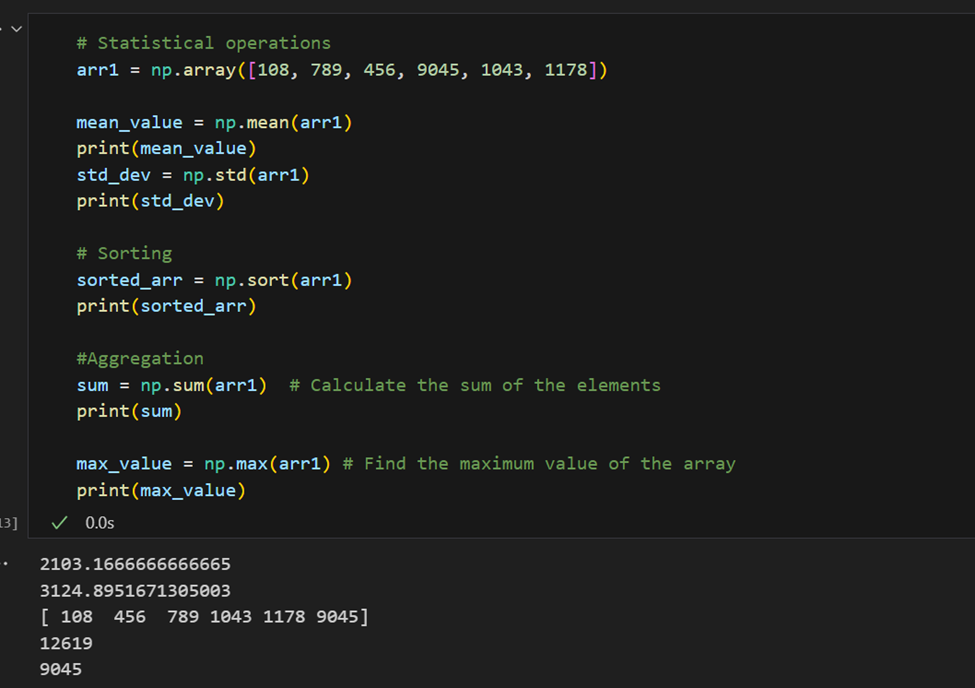
統計操作:
NumPy數組與Python列表的區別
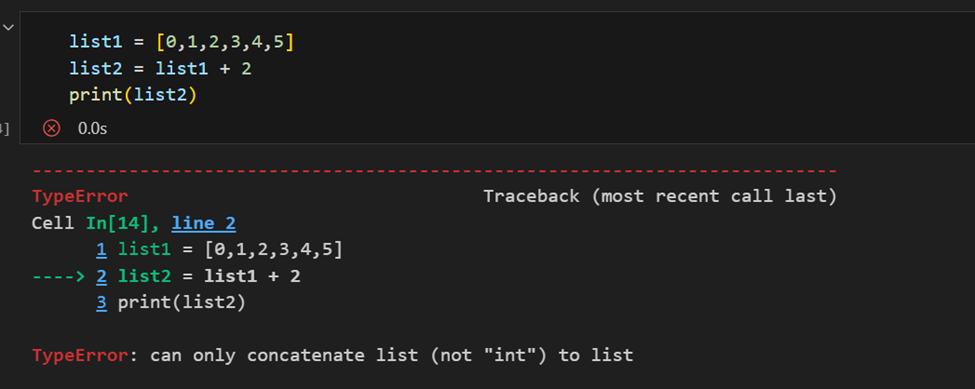
數組和列表之間的主要區別在於,數組設計用於處理向量化操作,而Python列表則不是。這意味著,如果應用函數,它會對數組中的每個項目執行,而不是對整個數組對象執行。
Pandas
Pandas脫穎而出,是最強大的數值計算和數據操作庫之一,對於人工智能和機器學習領域至關重要。
Pandas,像NumPy一樣,是最流行的Python庫之一。它是對底層NumPy的高級抽象,使用純C編寫。Pandas提供高性能、易於使用的數據結構和數據分析工具。Pandas使用兩種主要結構:數據框和系列。
Pandas系列中的索引
一個Pandas系列類似於一個列表,但不同之處在於系列將每個元素與標籤關聯起來。這使其看起來像一個字典。如果用戶沒有明確提供索引,Pandas將創建一個從0到N-1的RangeIndex。每個系列對象還具有數據類型。
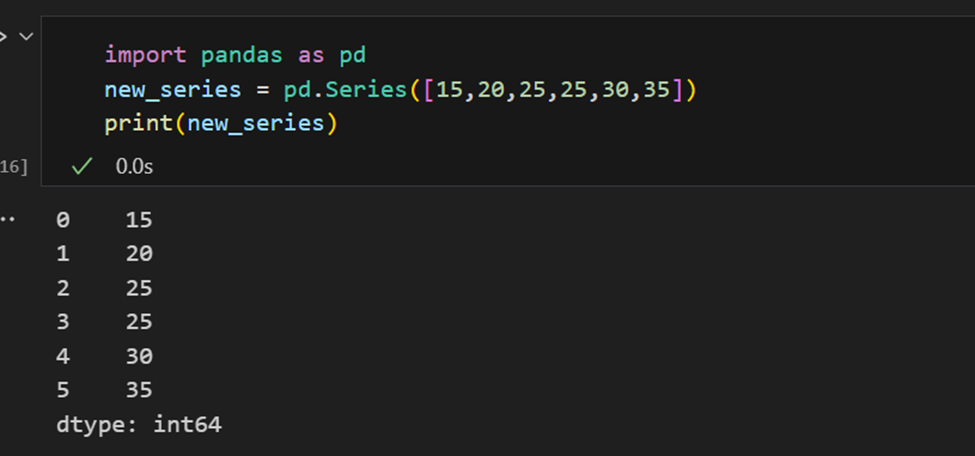
Pandas系列有多種方法可以提取系列中的所有值,以及按索引提取單個元素。
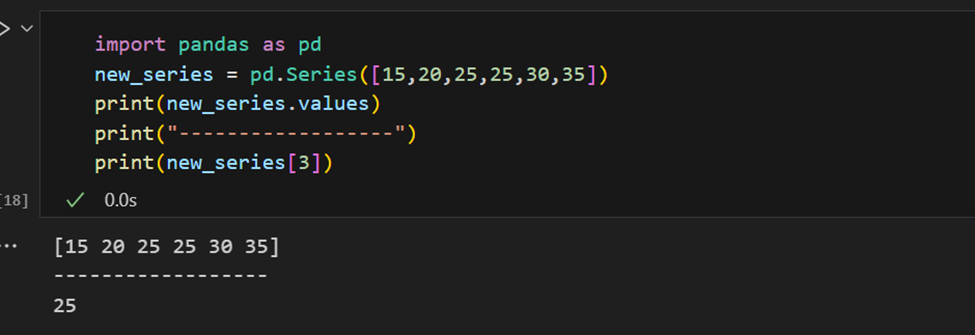
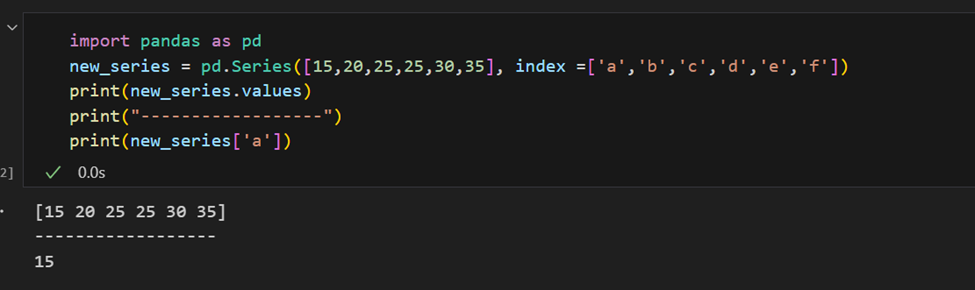
索引也可以手動提供。
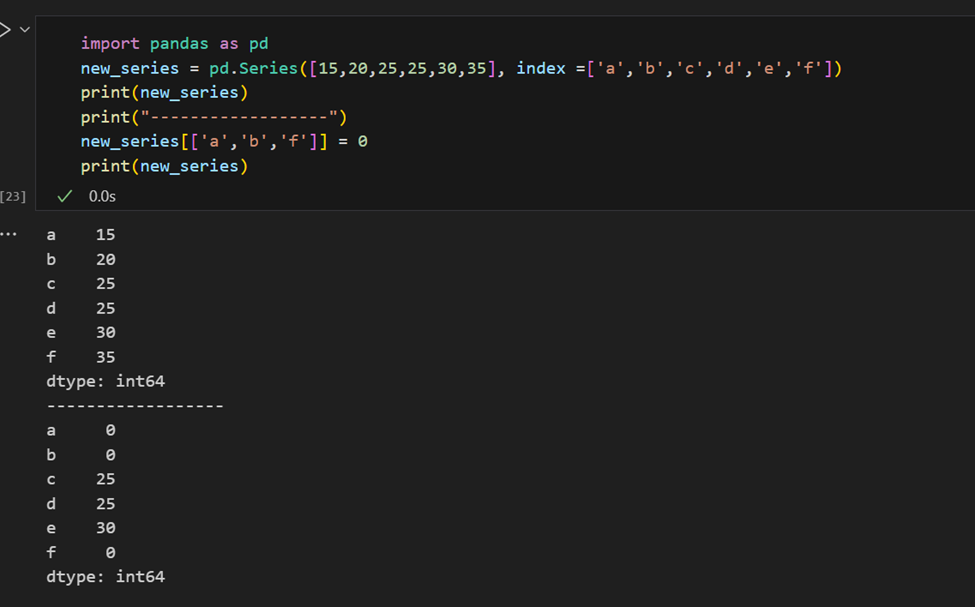
通過它容易通過它們的索引檢索系列的多個元素或進行組分配。
Pandas數據框
數據框是一個具有行和列的表格。數據框中的每一列都是一個系列對象。行由系列中的元素組成。Pandas數據框提供了各種用於數據操作和分析的操作。以下是一些常見操作的概述:
基本操作
創建數據框
- 從字典:
pd.DataFrame({'col1': [1, 2], 'col2': [3, 4]}) - 從CSV文件:
pd.read_csv('data.csv') - 從Excel文件:
pd.read_excel('data.xlsx')
訪問數據
- 選擇列:
df['col1'] - 選擇行:
df.loc[0] (按索引標籤), df.iloc[0](按索引位置) - 切片:
df [0:2] (前兩行), df[['coll', 'col2']](多列)
添加和刪除列/行
- 添加列:
df['new_col'] = - 刪除列:
df.drop('coll', axis=1) - 添加行:
df.append({'col1': 7, 'col2': 8}, ignore_index=True) - 刪除一行:
df.drop(0)
數據過濾
- 使用布爾條件:
df [df['col1'] > 2]
數學運算
- 算術運算:
df['col1'] + df['col2'],df * 2,等等。 - 聚合函數:
df.sum(),df.mean(),df.max(),df.min(),等等。 - 應用自定義函數:
df.apply(lambda x: x**2)
處理缺失數據
- 檢查缺失值:
df.isnull() - 刪除缺失值:
df.dropna() - 填充缺失值:
df.fillna(0)
合併和連接數據框
- 合併:
pd.merge(df1, df2, on='key_column') - 連接:
df1.join(df2, on='key_column')
分組和聚合
- 分組:
df.groupby('col1') - 聚合:
df.groupby('col1').mean()
時間序列操作
- 重新取樣:
df.resample('D').sum()(降低到每日頻率) - 時間移位:
df.shift(1)(將數據向前移動一個周期)
數據可視化
繪圖:df.plot()(線圖),df.hist()(直方圖),等等。
複雜的Pandas示例
1. 這裡,我們有按地區和年份索引的銷售數據。現在,我們計算每個地區銷售額的百分比變化。
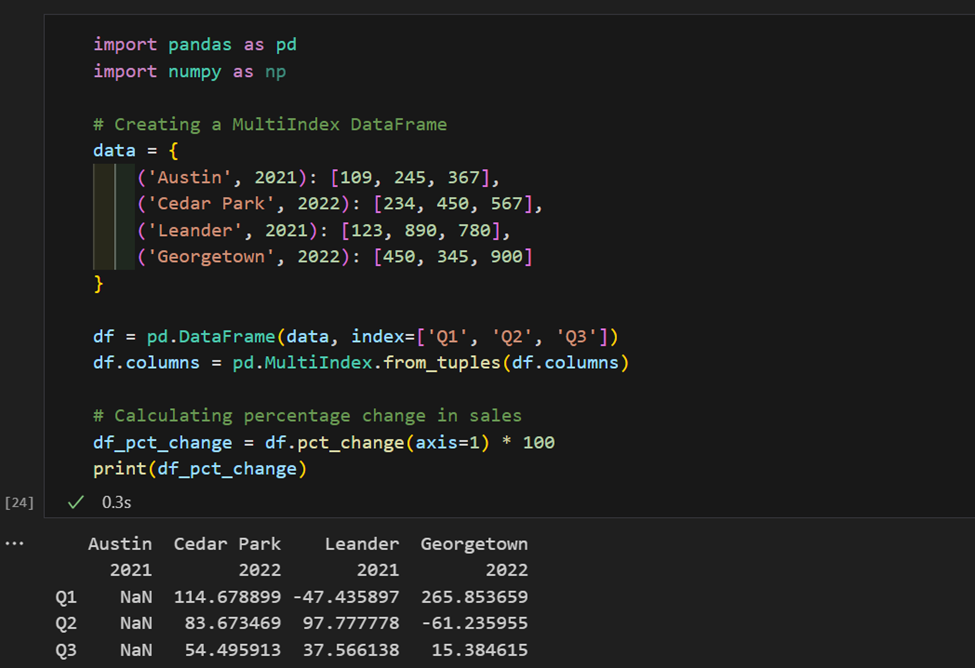
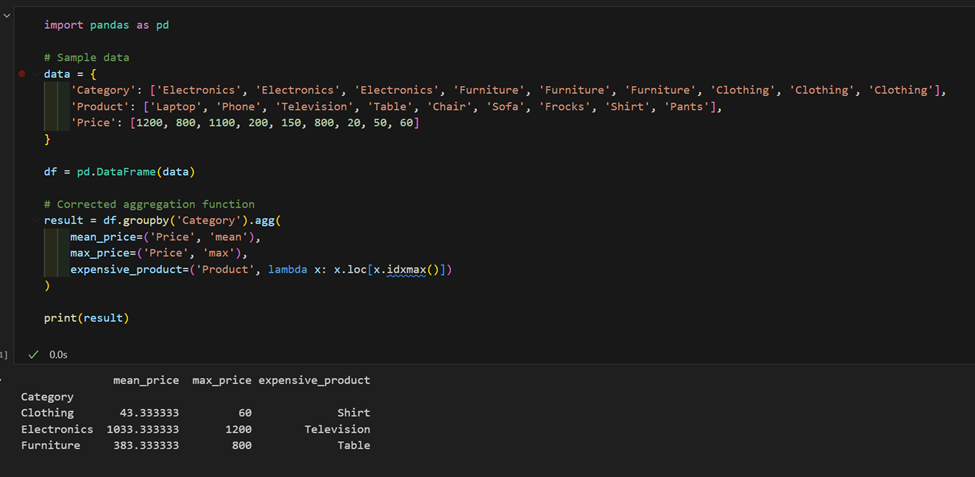
2. 我們有一個包含產品和價格的數據集,計算每個類別的平均價格,並找到每個類別中最昂貴的產品。
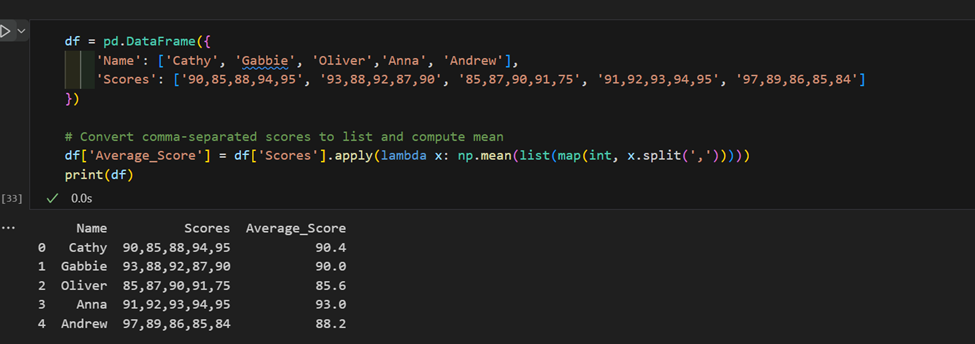
3. 複雜的“應用”用法:
結論
這兩個庫,NumPy 和 Pandas,在現實應用中被廣泛應用,例如 BFSI(金融分析)、科學計算、人工智慧和機器學習,以及大數據處理。這兩個庫在數據驅動決策中發揮著至關重要的作用,從分析關鍵的股市趨勢到管理大規模的 ERP 業務數據。
對於初學者來說,下一步是通過參與小型項目、探索數據集,並將它們應用於現實情景中來練習使用 NumPy 和 Pandas。可以從 GitHub 下載有關金融、房地產或一般製造業業務數據的開源數據。有了這些源數據和這些庫,可以創建引人入勝的故事或實證分析。實踐經驗將有助於鞏固概念,為學習者做更多先進的數據科學任務做好準備。
總之,NumPy 和 Pandas 都是數據操作和分析的 兩個必不可少的 Python 庫。在這裡,NumPy 通過其高效的數組操作提供了對數值計算的強大支持,而 Pandas 在 NumPy 的基礎上提供了內在和直觀的數據結構,如 Series 和 DataFrame,用於處理結構化數據。
Source:
https://dzone.com/articles/python-libraries-introduction-numpy-pandas