













في برمجة Python ، تبرز NumPy و Pandas كواحدة من أقوى المكتبات للحوسبة العددية وتلاعب البيانات.
NumPy: أساس الحوسبة العددية
NumPy (Numerical Python) توفر دعمًا للمصفوفات متعددة الأبعاد ومجموعة واسعة من الوظائف الرياضية، مما يجعلها أساسية للحوسبة العلمية.
- NumPy هو الحزمة الأكثر أساسية للحوسبة العددية في Python.
- أحد الأسباب التي تجعل NumPy مهمًا جدًا للحسابات العددية هو أنه مصمم لتحقيق الكفاءة مع مصفوفات كبيرة من البيانات. تشمل الأسباب لذلك:
- إنه يخزن البيانات داخليًا في كتلة مستمرة من الذاكرة، مستقلة عن كائنات Python الأخرى المدمجة.
- إنه ينفذ عمليات حسابية معقدة على مصفوفات بأكملها دون الحاجة إلى حلقات “for”.
- كائن
ndarrayهو مصفوفة متعددة الأبعاد فعالة توفر عمليات حسابية سريعة موجهة نحو المصفوفات وإمكانيات البث المرنة. - كائن NumPy
ndarrayهو حاوية سريعة ومرنة لمجموعات بيانات كبيرة في Python. - المصفوفات تمكنك من تخزين عدة عناصر من نفس نوع البيانات. ومن المرافق حول كائن المصفوفة ما يجعل NumPy مريحًا جدًا لأداء العمليات الرياضية وتلاعب البيانات.
العمليات في نامباي
إنشاء المصفوفة:

إعادة تشكيل المصفوفة:

تقطيع وفهرسة:

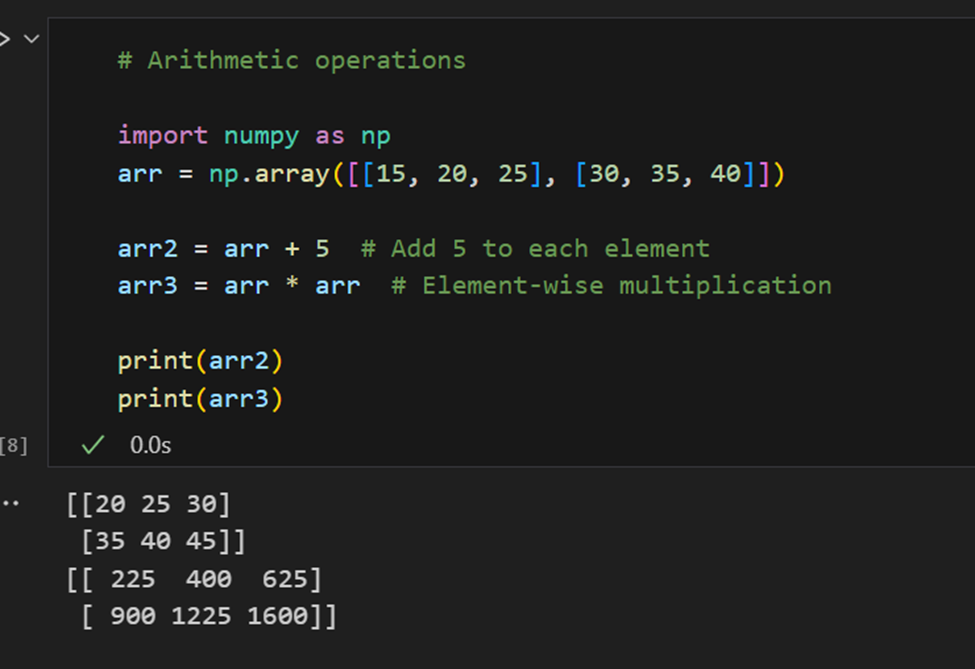
العمليات الحسابية:
الجبر الخطي:

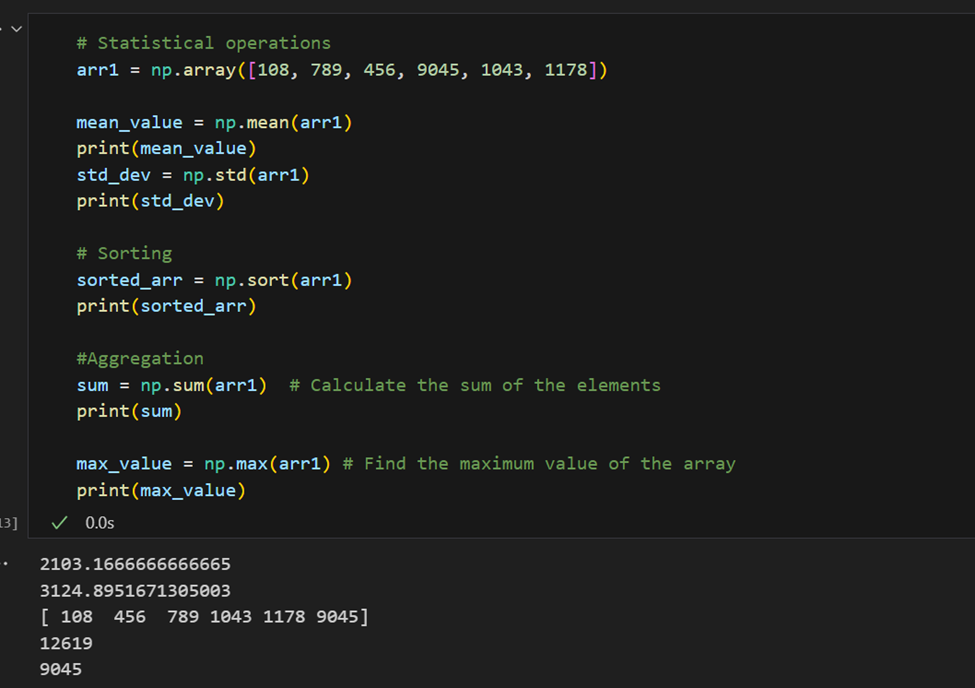
العمليات الإحصائية:
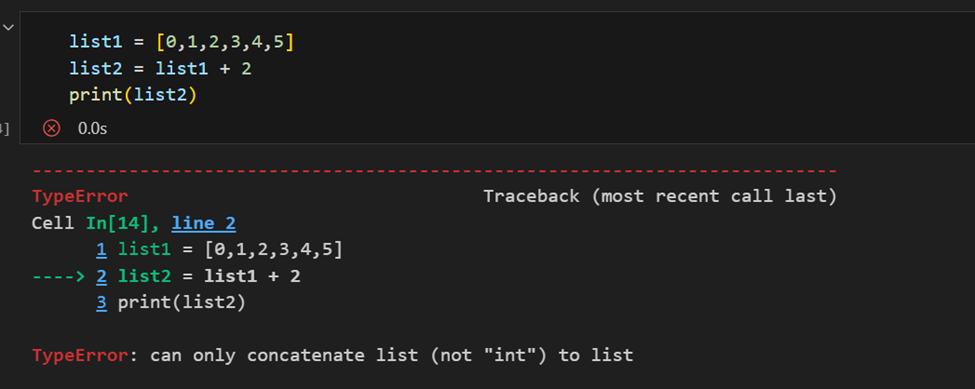
الفرق بين مصفوفة نامباي وقائمة بايثون
الفارق الرئيسي بين مصفوفة وقائمة هو أن المصفوفات مصممة للتعامل مع العمليات المتجهية، بينما القائمة في بايثون ليست كذلك. وهذا يعني أنه إذا قمت بتطبيق وظيفة، فإنها ستنفذ على كل عنصر في المصفوفة، بدلاً من الكائن كاملاً.
بانداس
تبرز بانداس كواحدة من أقوى المكتبات للحوسبة العددية وتلاعب البيانات، وهو أمر حاسم في مجالات الذكاء الاصطناعي وتعلم الآلة.
بانداس، مثل نامباي، هو واحد من أشهر مكتبات بايثون. إنه تجريب عالي المستوى فوق نامباي على مستوى منخفض، والذي كتب بلغة السي. بانداس توفر هياكل بيانات سريعة الأداء وسهلة الاستخدام وأدوات تحليل البيانات. بانداس يستخدم هيكلين رئيسيين: إطارات بيانات و سلاسل.
الفهارس في سلاسل بانداس
سلسلة بانداس مشابهة لقائمة، ولكن الاختلاف يكمن في أن السلسلة ترتبط بتسمية لكل عنصر. وهذا يجعلها تبدو مثل قاموس. إذا لم يتم توفير فهرس بوضوح من قبل المستخدم، ينشئ بانداس RangeIndex تتراوح من 0 إلى N-1. لكل كائن سلسلة نوع بيانات أيضًا.
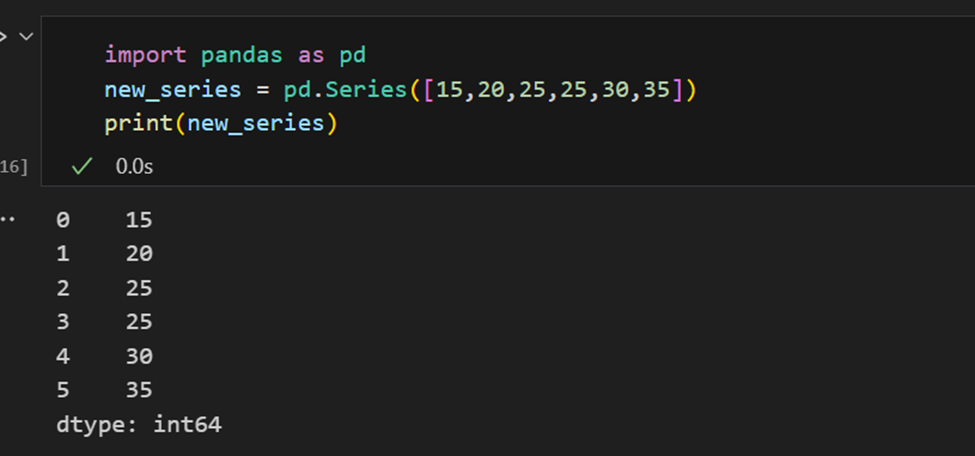
سلسلة Pandas لديها طرق لاستخراج جميع القيم في السلسلة، فضلاً عن العناصر الفردية بحسب الفهرس.
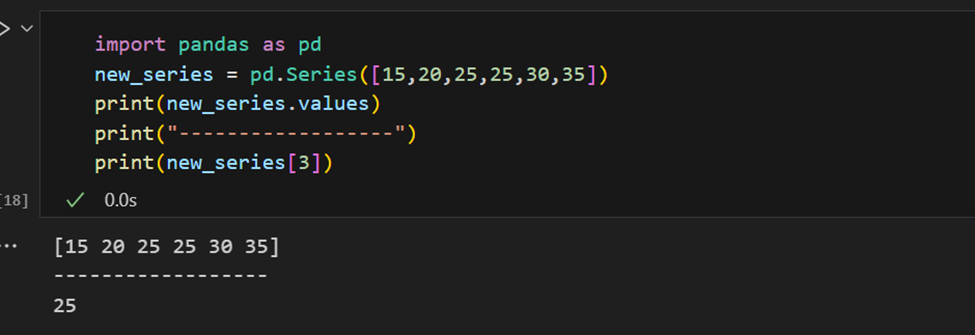
يمكن توفير الفهرس يدويًا أيضًا.
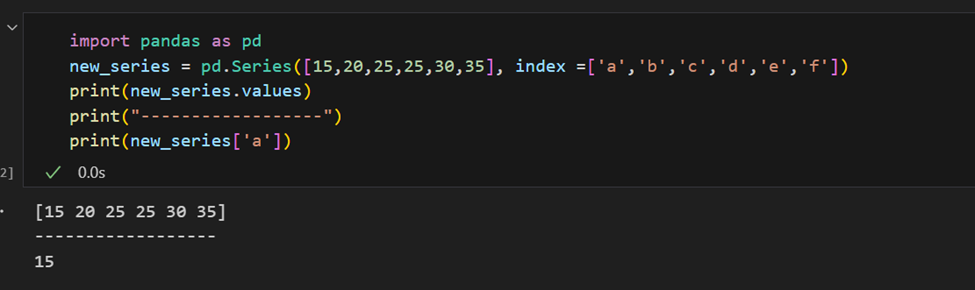
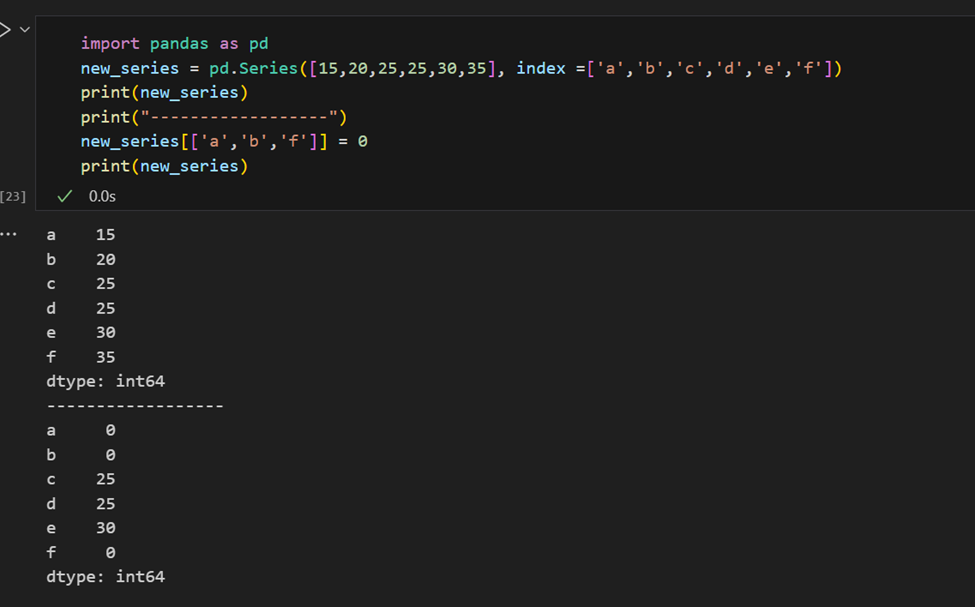
من السهل استرداد عدة عناصر من سلسلة بواسطة فهارسها أو إجراء تعيينات جماعية.
إطارات البيانات Pandas
إطار البيانات هو جدول يحتوي على صفوف وأعمدة. كل عمود في إطار البيانات هو كائن سلسلة. الصفوف تتكون من عناصر داخل السلاسل. إطارات البيانات Pandas تقدم مجموعة واسعة من العمليات لتعديل البيانات وتحليلها. إليك تفصيل بعض العمليات الشائعة:
العمليات الأساسية
إنشاء إطارات بيانات
- من القاموس:
pd.DataFrame({'col1': [1, 2], 'col2': [3, 4]}) - من ملف CSV:
pd.read_csv('data.csv') - من ملف Excel:
pd.read_excel('data.xlsx')
الوصول إلى البيانات
- اختيار الأعمدة:
df['col1'] - اختيار الصفوف:
df.loc[0] (بواسطة تسمية الفهرس)، df.iloc[0](بواسطة موضع الفهرس) - تقطيع:
df [0:2] (أول صفين)، df[['col1', 'col2']](عدة أعمدة)
إضافة وإزالة الأعمدة/الصفوف
- إضافة عمود:
df['new_col'] = - إزالة عمود:
df.drop('col1', axis=1) - إضافة صف:
df.append({'col1': 7, 'col2': 8}, ignore_index=True) - إزالة صف:
df.drop(0)
تصفية البيانات
- استخدام الشروط البوليانية:
df [df['col1'] > 2]
العمليات الرياضية
- العمليات الحسابية:
df['col1'] + df['col2']،df * 2، إلخ. - دوال التجميع:
df.sum()،df.mean()،df.max()،df.min()، إلخ. - تطبيق الدوال المخصصة:
df.apply(lambda x: x**2)
التعامل مع البيانات المفقودة
- التحقق من القيم المفقودة:
df.isnull() - حذف القيم المفقودة:
df.dropna() - ملء القيم المفقودة:
df.fillna(0)
دمج وإضافة DataFrames
- الدمج:
pd.merge(df1, df2, on='key_column') - الإضافة:
df1.join(df2, on='key_column')
التجميع والتجميع
- التجميع:
df.groupby('col1') - التجميع:
df.groupby('col1').mean()
عمليات السلاسل الزمنية
- إعادة أخذ العينات:
df.resample('D').sum()(تقليل التردد إلى يومي) - تحويل الوقت:
df.shift(1)(تحويل البيانات بفترة واحدة)
تصوير البيانات
الرسم: df.plot() (رسم خطي)، df.hist() (رسم بياني)، إلخ.
أمثلة معقدة على Pandas
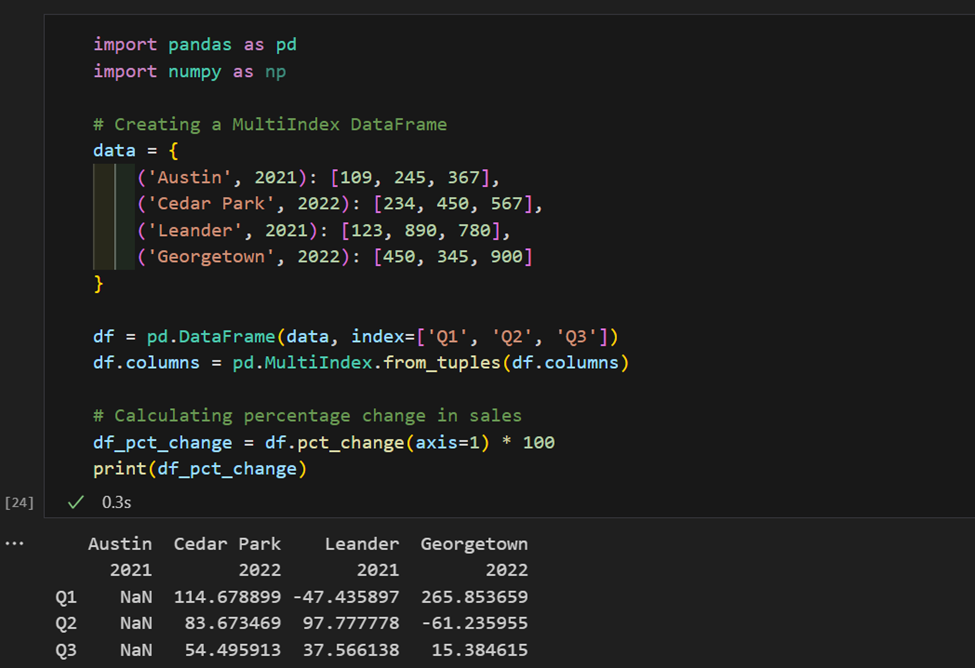
1. هنا، لدينا بيانات المبيعات مرتبة حسب المنطقة والسنة. الآن، هنا نحسب نسبة التغير في المبيعات لكل منطقة.
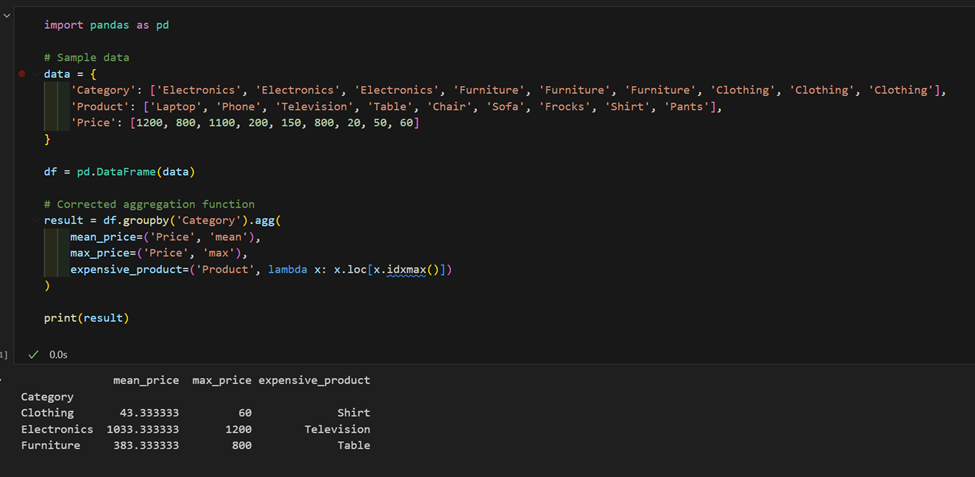
2. لدينا مجموعة بيانات تحتوي على منتجات وأسعار، احسب متوسط السعر لكل فئة وابحث عن أغلى منتج في كل منها.
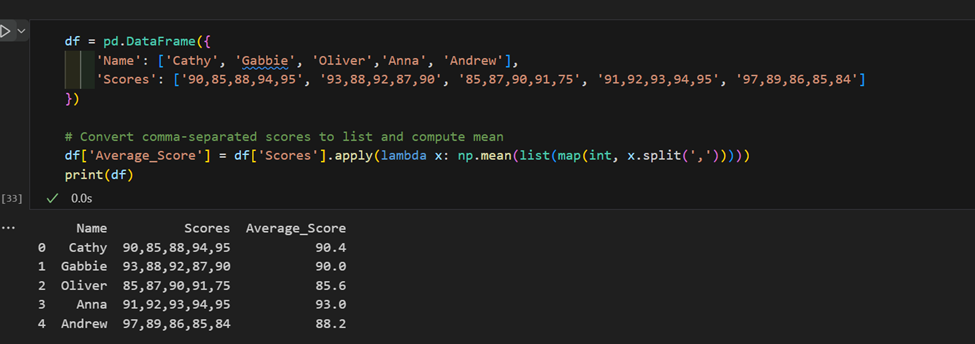
3. استخدام “apply” المعقد:
استنتاج
تُستخدم هاتان المكتبتان، NumPy وPandas، على نطاق واسع في التطبيقات الحياتية مثل BFSI (التحليل المالي)، والحوسبة العلمية، والذكاء الاصطناعي والتعلم الآلي، ومعالجة البيانات الضخمة. تلعب هاتان المكتبتان دورًا حيويًا في اتخاذ القرارات المستندة إلى البيانات، من تحليل الاتجاهات الحرجة في سوق الأسهم إلى إدارة بيانات الأعمال الكبيرة الحجم ERP.
بالنسبة للمبتدئين، فإن الخطوة التالية هي ممارسة استخدام NumPy وPandas من خلال العمل على مشاريع صغيرة، واستكشاف مجموعات البيانات، وتطبيق وظائفها في سيناريوهات العالم الحقيقي. يمكن للمرء تنزيل بيانات مفتوحة المصدر من GitHub حول البيانات المالية، أو العقارية، أو بيانات التصنيع العامة. مع تلك البيانات المصدرية وهذه المكتبات، يمكن للمرء إنشاء قصة مثيرة أو تحليل تجريبي. ستساعد الخبرة العملية على تدعيم المفاهيم وإعداد المتعلمين لمهام علم البيانات الأكثر تقدمًا.
في الختام، تعتبر كلا من NumPy وPandas مكتبتين أساسيتين في بايثون لمعالجة البيانات وتحليلها. هنا، توفر NumPy دعمًا قويًا للحسابات العددية مع عمليات المصفوفات الفعالة، بينما تبني Pandas على NumPy لتقديم هياكل بيانات جوهرية وبديهية مثل Series وDataFrame للتعامل مع البيانات المهيكلة.
Source:
https://dzone.com/articles/python-libraries-introduction-numpy-pandas