













Pythonプログラミングにおいて、NumPyとPandasは数値計算とデータ操作のための2つの最も強力なライブラリとして際立っています。
NumPy: 数値計算の基盤
NumPy(Numerical Python)は、多次元配列と幅広い数学関数のサポートを提供し、科学計算に不可欠です。
- NumPyはPythonにおける数値計算の基本的なパッケージです。
- NumPyが数値計算において非常に重要な理由の1つは、大きなデータ配列に対する効率性を考慮して設計されていることです。その理由には次のようなものがあります:
- それは他の組み込みPythonオブジェクトとは独立した連続したメモリブロックにデータを内部的に格納します。
- 「for」ループを必要とせずに配列全体で複雑な計算を実行します。
ndarrayは、高速な配列指向の算術演算と柔軟なブロードキャスト機能を提供する効率的な多次元配列です。- NumPyの
ndarrayオブジェクトは、Pythonにおける大規模なデータセットのための高速かつ柔軟なコンテナです。 - 配列を使用することで、同じデータ型の複数のアイテムを格納できます。NumPyを数学的な操作やデータ操作を行うのに非常に便利にするのは、配列オブジェクト周りの機能です。
NumPyでの操作
配列の作成:

配列の形状変更:

スライスとインデックス:

四則演算:
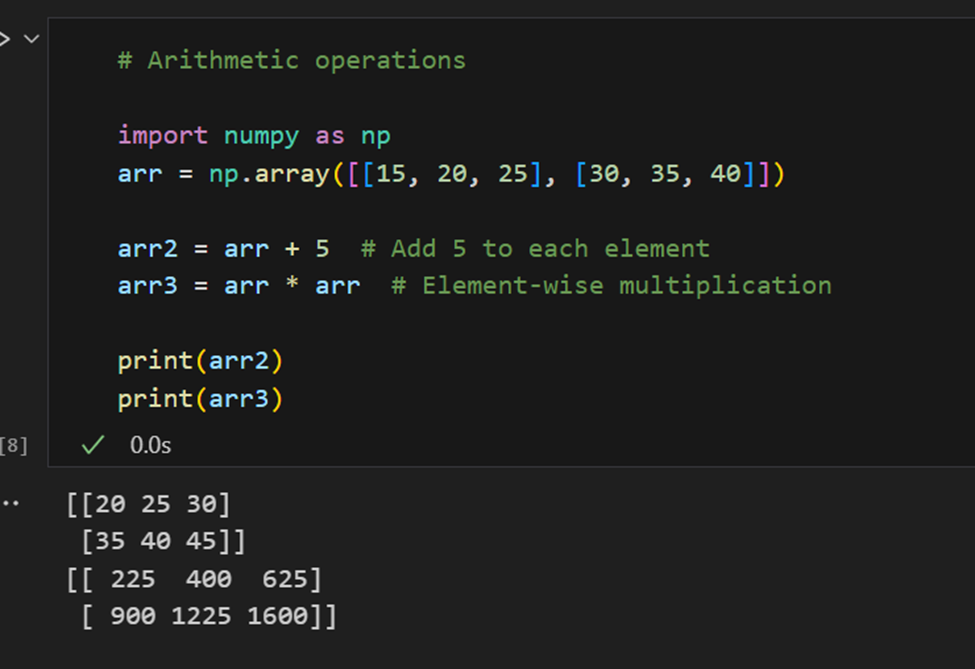
線形代数:

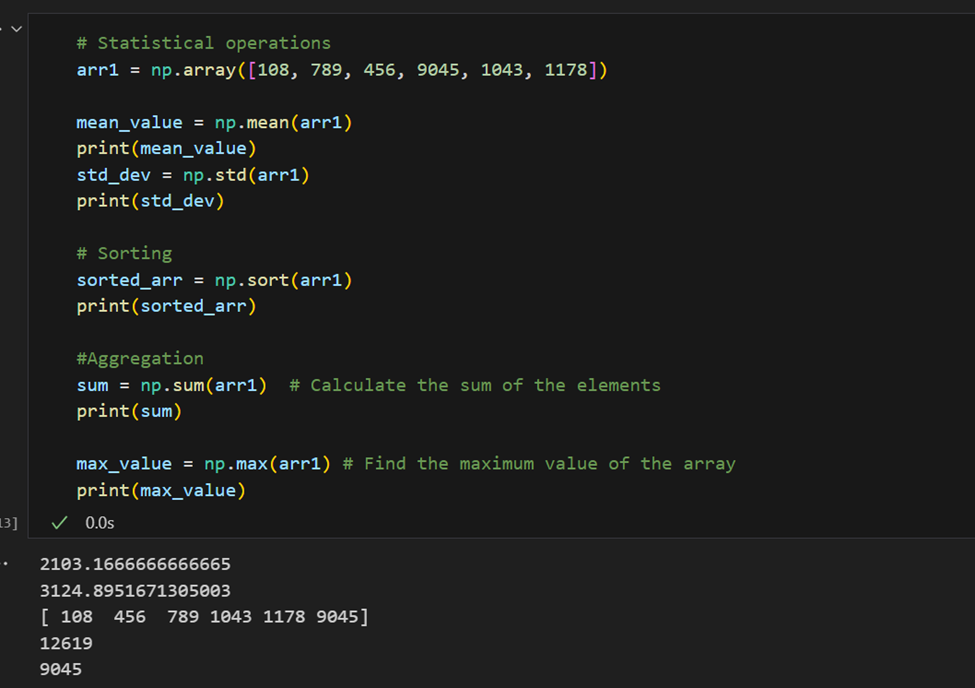
統計操作:
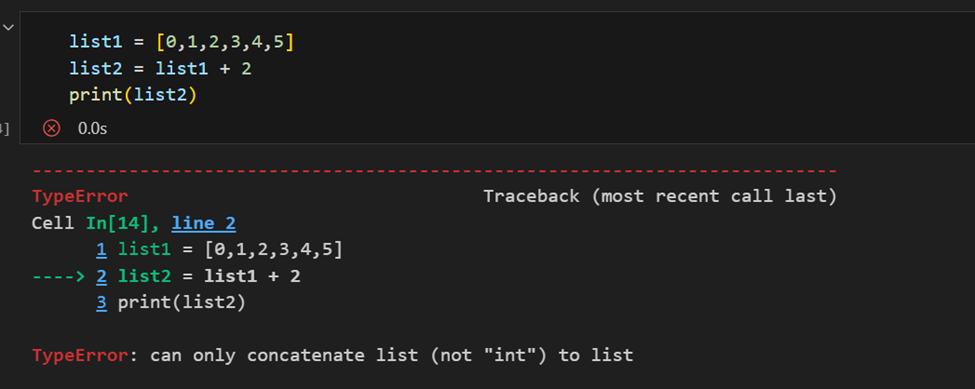
NumPy配列とPythonリストの違い
配列とリストの主な違いは、配列はベクトル化された操作を扱うように設計されている一方、Pythonリストはそうではないことです。つまり、関数を適用すると、配列内のすべてのアイテムに対して実行されます。全体の配列オブジェクト全体には適用されません。
Pandas
Pandasは、人工知能や機械学習領域にとって重要な数値計算およびデータ操作のための最も強力なライブラリの1つとして際立っています。
PandasはNumPyと同様に、最も人気のあるPythonライブラリの1つです。これは、純粋なC言語で書かれた低レベルのNumPyの上に構築された高レベルの抽象化ライブラリです。Pandasは高性能で使いやすいデータ構造とデータ分析ツールを提供します。Pandasは主に2つの構造、データフレームとシリーズを使用します。
Pandasシリーズのインデックス
Pandasシリーズはリストに似ていますが、各要素にラベルが関連付けられる点が異なります。これにより、辞書のように見えます。ユーザーが明示的にインデックスを指定しない場合、Pandasは0からN-1までの範囲のRangeIndexを作成します。各シリーズオブジェクトにはデータ型もあります。
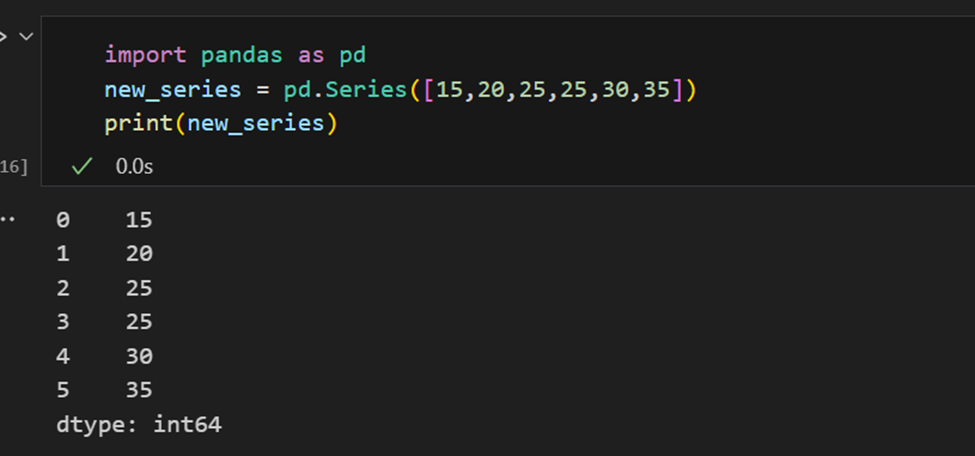
Pandasシリーズには、シリーズ内のすべての値を抽出する方法と、インデックスによる個々の要素を取得する方法があります。
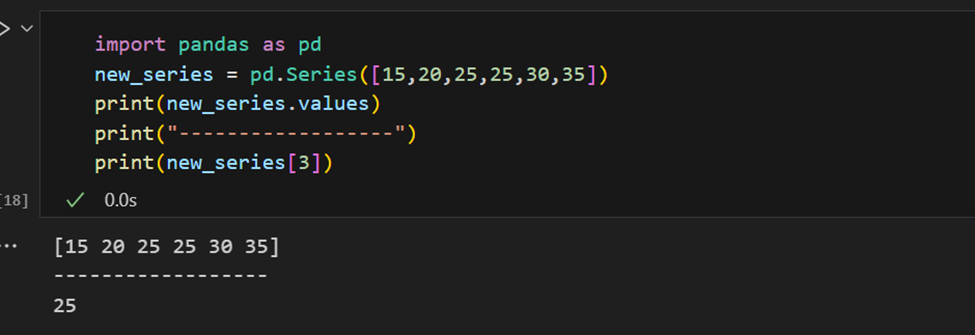
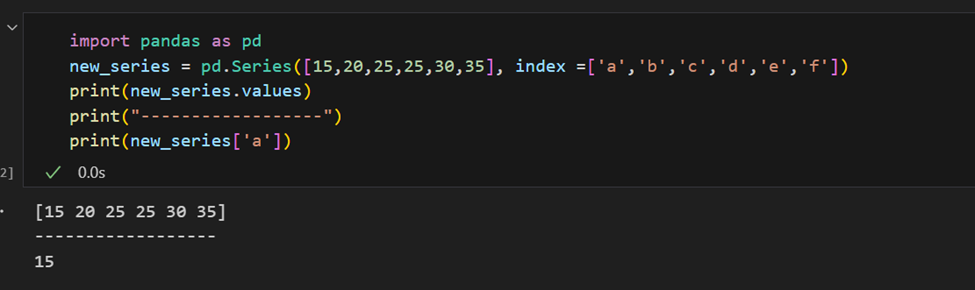
インデックスは手動で指定することもできます。
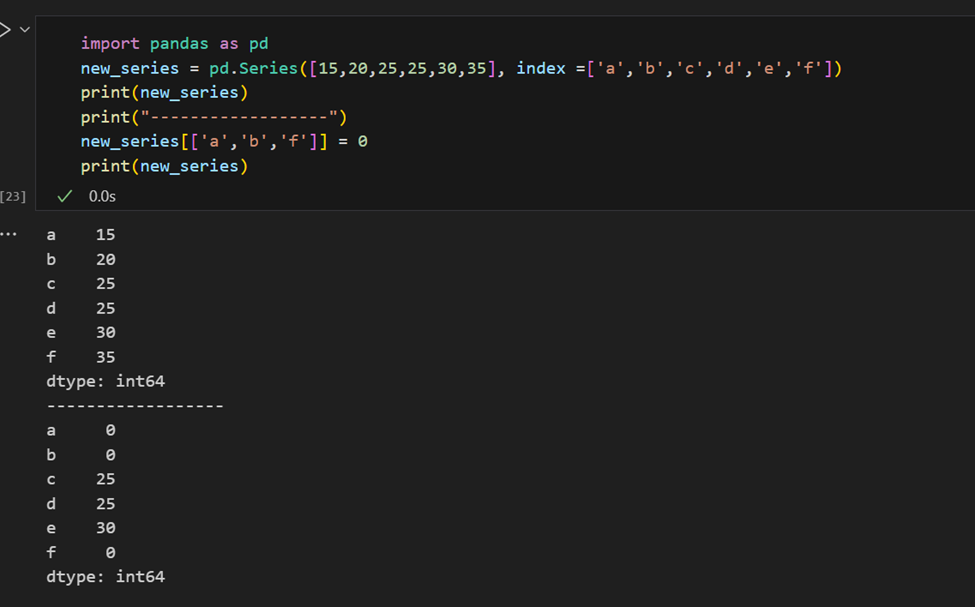
シリーズの複数の要素をインデックスで取得したり、グループへの割り当てを行うのは簡単です。
Pandasデータフレーム
データフレームは行と列を持つ表です。データフレームの各列はシリーズオブジェクトです。行はシリーズ内の要素で構成されています。Pandasデータフレームには、データの操作と分析のための幅広い操作が提供されています。以下は一部の一般的な操作の概要です:
基本操作
データフレームの作成
- 辞書から:
pd.DataFrame({'col1': [1, 2], 'col2': [3, 4]}) - CSVファイルから:
pd.read_csv('data.csv') - Excelファイルから:
pd.read_excel('data.xlsx')
データのアクセス
- 列の選択:
df['col1'] - 行の選択:
df.loc[0] (インデックスラベルによる), df.iloc[0](インデックス位置による) - スライス:
df [0:2] (最初の2行), df[['coll', 'col2']](複数の列)
列/行の追加と削除
- 列の追加:
df['new_col'] = - 列の削除:
df.drop('coll', axis=1) - 行の追加:
df.append({'col1': 7, 'col2': 8}, ignore_index=True) - 行の削除:
df.drop(0)
データのフィルタリング
- ブール条件を使用:
df [df['col1'] > 2]
数学的な操作
- 算術演算:
df['col1'] + df['col2'],df * 2, など - 集計関数:
df.sum(),df.mean(),df.max(),df.min(), など - カスタム関数の適用:
df.apply(lambda x: x**2)
欠損データの処理
- 欠損値のチェック:
df.isnull() - 欠損値の削除:
df.dropna() - 欠損値の穴埋め:
df.fillna(0)
データフレームのマージと結合
- マージ:
pd.merge(df1, df2, on='key_column') - 結合:
df1.join(df2, on='key_column')
グループ化と集計
- グループ化:
df.groupby('col1') - 集計:
df.groupby('col1').mean()
時系列操作
- リサンプリング:
df.resample('D').sum()(日次の頻度にダウンサンプリング) - 時間のシフト:
df.shift(1)(データを1期間シフト)
データの可視化
プロット: df.plot() (折れ線グラフ), df.hist() (ヒストグラム), など
複雑なPandasの例
1. ここでは、地域と年次でインデックス付けされた売上データがあります。今、ここで地域ごとの売上の変化率を計算します。
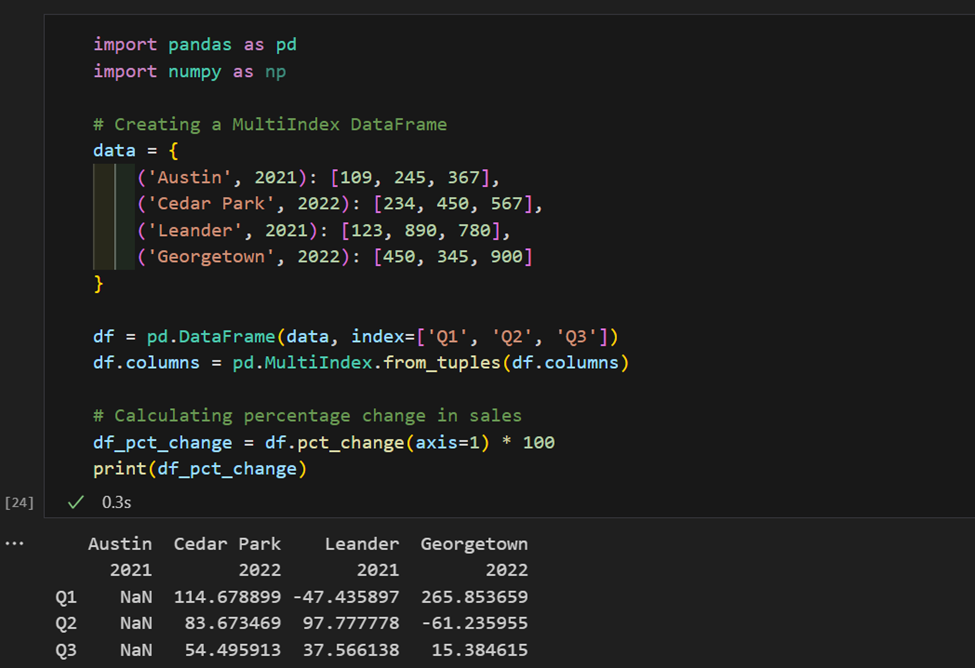
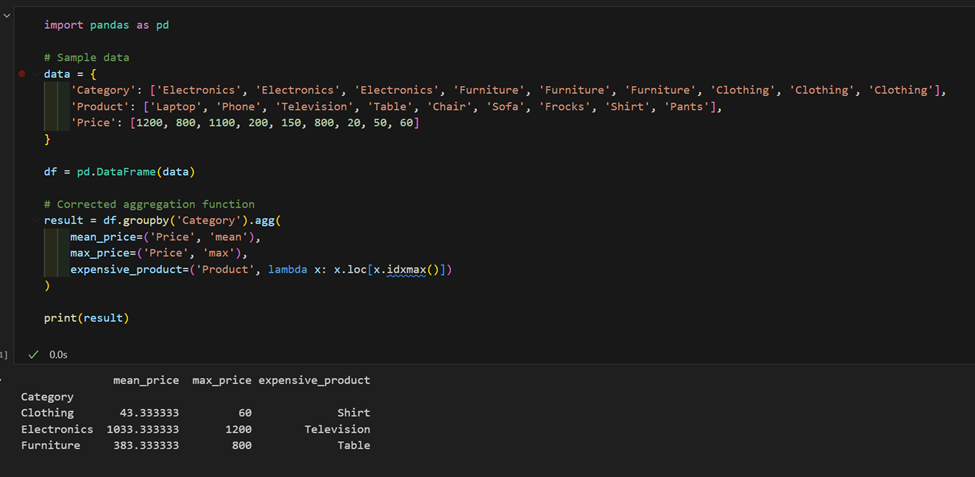
2. 製品と価格のデータセットがあります。カテゴリごとの平均価格を計算し、各カテゴリで最も高価な製品を見つけます。
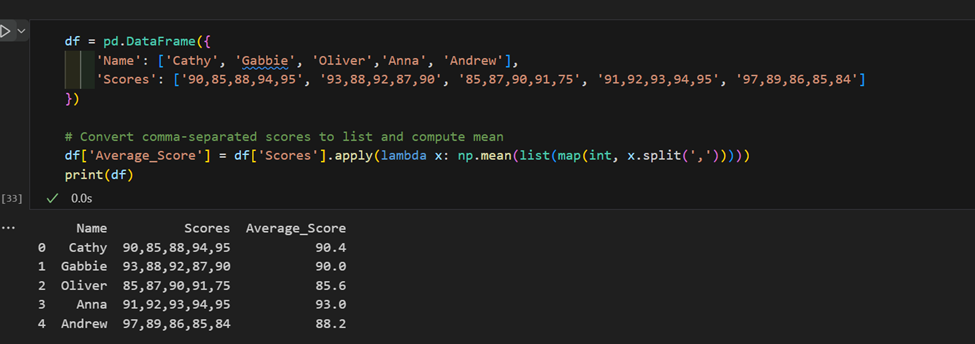
3. 複雑な「apply」の使用:
結論
これらの2つのライブラリ、NumPyとPandasは、BFSI(金融分析)、科学計算、AIおよびML、およびビッグデータ処理などの実際のアプリケーションで広く使用されています。これらの2つのライブラリは、株式市場の重要なトレンドを分析することから大規模ERPビジネスデータを管理するまで、データ駆動型意思決定において重要な役割を果たしています。
初心者にとって、次のステップは、NumPyとPandasを使って小規模プロジェクトに取り組み、データセットを探索し、それらの機能を実世界のシナリオで適用することです。GitHubから金融、不動産、または一般的な製造業のビジネスデータをオープンソースでダウンロードすることができます。そのソースデータとこれらのライブラリを使用すると、説得力のあるストーリーや実証分析を作成することができます。実践的な経験は、概念を確立し、より高度なデータサイエンスのタスクに備えるための学習者を準備するのに役立ちます。
まとめると、NumPyとPandasは、データ操作と分析のための2つの必須のPythonライブラリです。ここで、NumPyは効率的な配列操作を提供することで数値計算の強力なサポートを提供し、一方、PandasはNumPyを基盤として構造化データを処理するためのSeriesやDataFrameなどの固有で直感的なデータ構造を提供しています。
Source:
https://dzone.com/articles/python-libraries-introduction-numpy-pandas