













Bij het programmeren in Python springen NumPy en Pandas eruit als twee van de krachtigste bibliotheken voor numerieke berekeningen en gegevensmanipulatie.
NumPy: De basis van numerieke berekeningen
NumPy (Numerical Python) biedt ondersteuning voor meerdimensionale arrays en een breed scala aan wiskundige functies, waardoor het essentieel is voor wetenschappelijk rekenwerk.
- NumPy is het meest fundamentele pakket voor numerieke berekeningen in Python.
- Één van de redenen waarom NumPy zo belangrijk is voor numerieke berekeningen is dat het is ontworpen voor efficiëntie met grote arrays van gegevens. De redenen hiervoor zijn onder andere:
- Het slaat data intern op in een aaneengesloten blok geheugen, onafhankelijk van andere in Python ingebouwde objecten.
- Het voert complexe berekeningen uit op hele arrays zonder de noodzaak van “for”-lussen.
- De
ndarrayis een efficiënte meerdimensionale array die snelle op array-georiënteerde rekenkundige bewerkingen en flexibele broadcasting mogelijkheden biedt. - Het NumPy
ndarrayobject is een snelle en flexibele container voor grote datasets in Python. - Arrays stellen u in staat om meerdere items van hetzelfde gegevenstype op te slaan. Het zijn de faciliteiten rond het array-object die NumPy zo handig maken voor het uitvoeren van wiskundige en gegevensmanipulaties.
Operaties in NumPy
Het maken van de array:

Het hervormen van de array:

Slicen en indexeren:

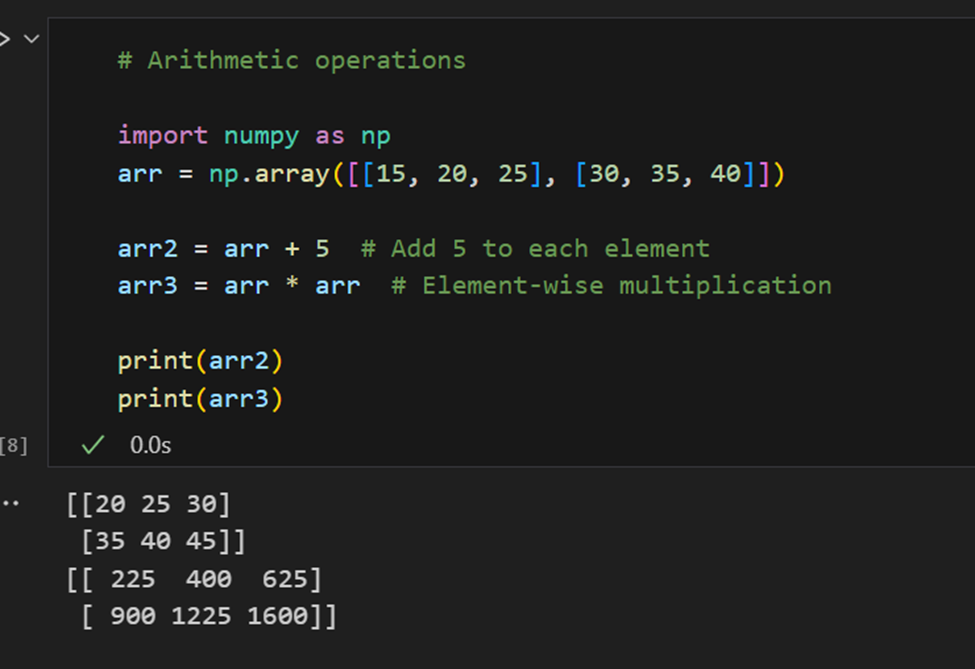
Rekenkundige bewerkingen:
Lineaire algebra:

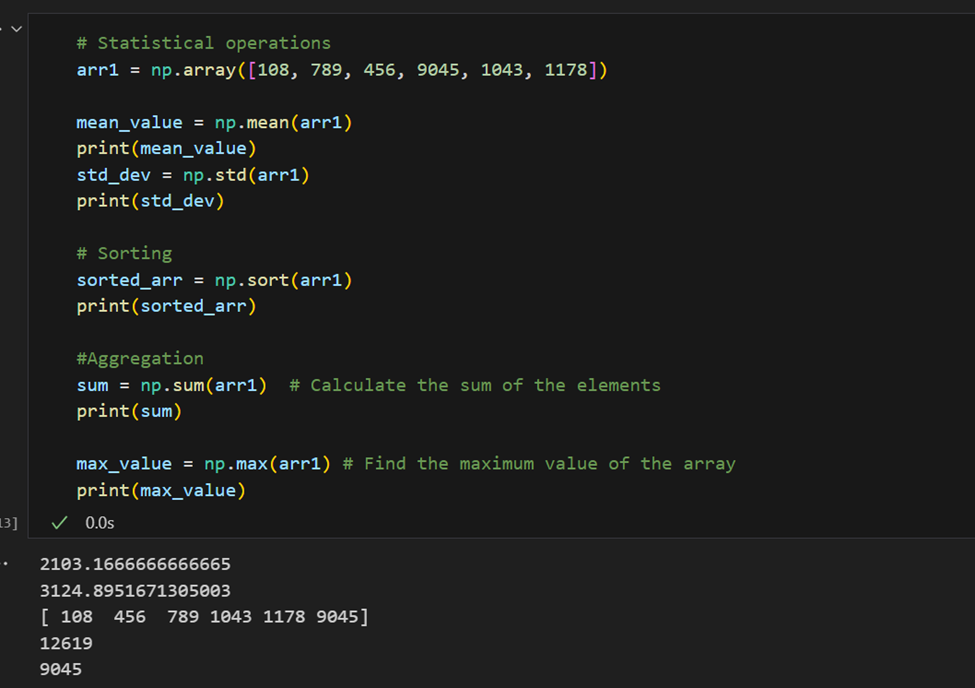
Statistische bewerkingen:
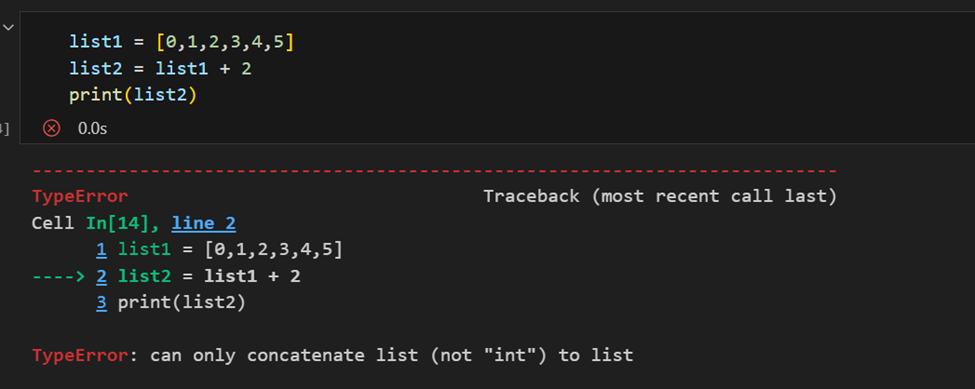
Verschil tussen NumPy-array en Python-lijst
Het belangrijkste verschil tussen een array en een lijst is dat arrays zijn ontworpen om vectorbewerkingen aan te kunnen, terwijl een Python-lijst dat niet is. Dat betekent dat als je een functie toepast, deze wordt uitgevoerd op elk item in de array, in plaats van op het hele array-object.
Pandas
Pandas springt eruit als een van de krachtigste bibliotheken voor numerieke berekeningen en gegevensmanipulatie, wat cruciaal is voor kunstmatige intelligentie en machine learning gebieden.
Pandas, net als NumPy, is een van de meest populaire Python-bibliotheken. Het is een abstractielaag boven de laag-niveau NumPy, die is geschreven in puur C. Pandas biedt high-performance, gebruiksvriendelijke datastructuren en data-analysetools. Pandas maakt gebruik van twee belangrijke structuren: dataframes en series.
Indices in Pandas Series
Een Pandas serie lijkt op een lijst, maar verschilt hierin dat een serie een label koppelt aan elk element. Dit maakt het eruit zien als een woordenboek. Als een index niet expliciet wordt opgegeven door de gebruiker, creëert Pandas een RangeIndex variërend van 0 tot N-1. Elk serie-object heeft ook een gegevenstype.
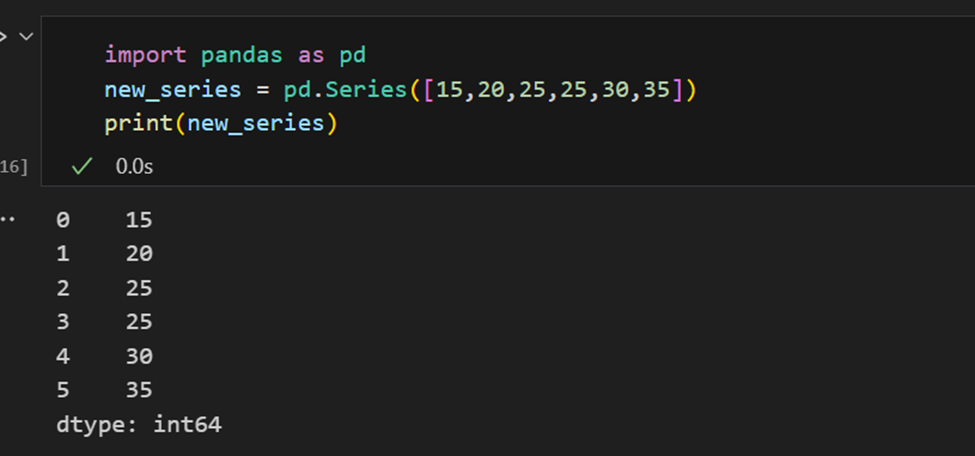
Een Pandas-serie heeft manieren om alle waarden in de serie te extraheren, evenals individuele elementen op index.
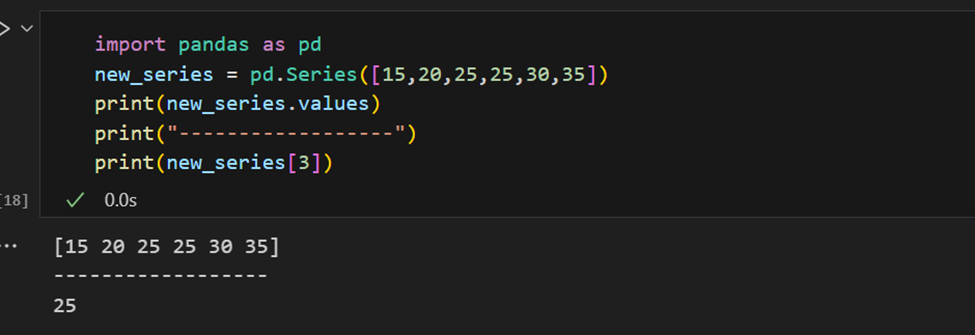
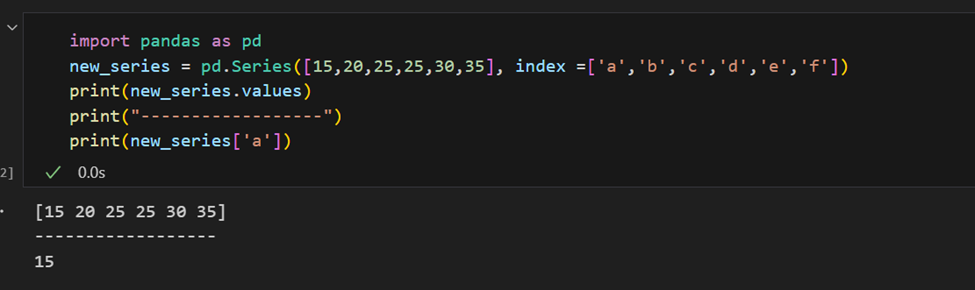
De index kan ook handmatig worden opgegeven.
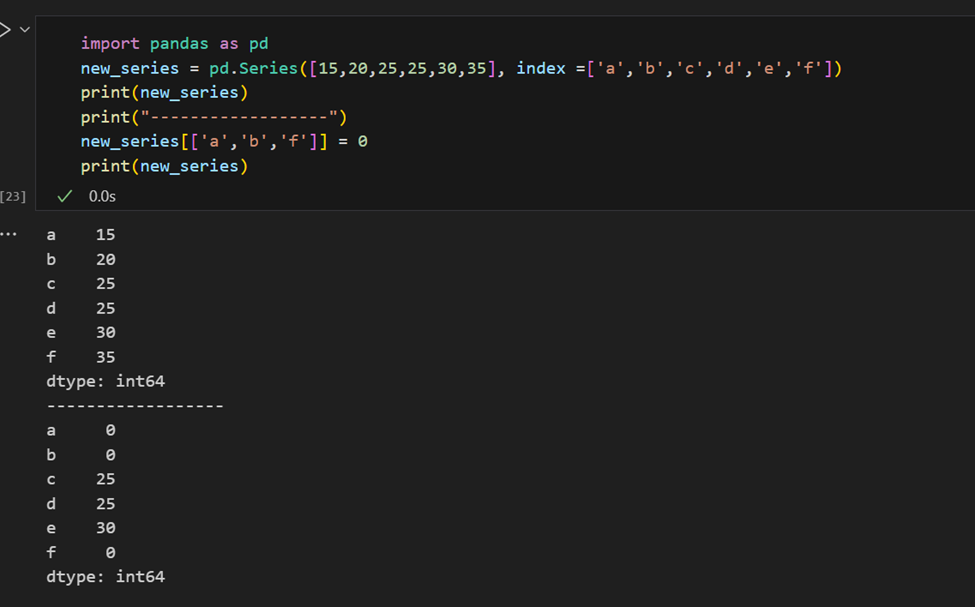
Het is eenvoudig om meerdere elementen van een serie op te halen via hun indices of groepstoewijzingen te maken.
Pandas DataFrames
Een DataFrame is een tabel met rijen en kolommen. Elke kolom in een data frame is een serie-object. Rijen bestaan uit elementen binnen series. Pandas DataFrames bieden een breed scala aan bewerkingen voor gegevensmanipulatie en -analyse. Hier is een overzicht van enkele veelvoorkomende bewerkingen:
Basisbewerkingen
DataFrames maken
- Van een woordenboek:
pd.DataFrame({'col1': [1, 2], 'col2': [3, 4]}) - Van een CSV-bestand:
pd.read_csv('data.csv') - Van een Excel-bestand:
pd.read_excel('data.xlsx')
Toegang tot Gegevens
- Kolommen selecteren:
df['col1'] - Rijen selecteren:
df.loc[0] (op indexlabel), df.iloc[0](op indexpositie) - Slicen:
df [0:2] (eerste twee rijen), df[['coll', 'col2']](meerdere kolommen)
Kolommen/Rijen Toevoegen en Verwijderen
- Een kolom toevoegen:
df['new_col'] = - Een kolom verwijderen:
df.drop('coll', axis=1) - Een rij toevoegen:
df.append({'col1': 7, 'col2': 8}, ignore_index=True) - Het verwijderen van een rij:
df.drop(0)
Filteren van Gegevens
- Gebruik van booleaanse voorwaarden:
df [df['col1'] > 2]
Wiskundige Operaties
- Rekenkundige operaties:
df['col1'] + df['col2'],df * 2, enz. - Aggregatiefuncties:
df.sum(),df.mean(),df.max(),df.min(), enz. - Het toepassen van aangepaste functies:
df.apply(lambda x: x**2)
Omgaan met Ontbrekende Gegevens
- Controleren op ontbrekende waarden:
df.isnull() - Verwijderen van ontbrekende waarden:
df.dropna() - Invullen van ontbrekende waarden:
df.fillna(0)
Samenvoegen en Koppelen van DataFrames
- Samenvoegen:
pd.merge(df1, df2, on='key_column') - Koppelen:
df1.join(df2, on='key_column')
Groeperen en Aggregeren
- Groeperen:
df.groupby('col1') - Aggregeren:
df.groupby('col1').mean()
Tijdreeksoperaties
- Hersamplen:
df.resample('D').sum()(monsters samplen naar dagelijkse frequentie) - Tijd verschuiven:
df.shift(1)(gegevens verschuiven met één periode)
Data Visualisatie
Plotten: df.plot() (lijndiagram), df.hist() (histogram), enz.
Complexe Pandas Voorbeelden
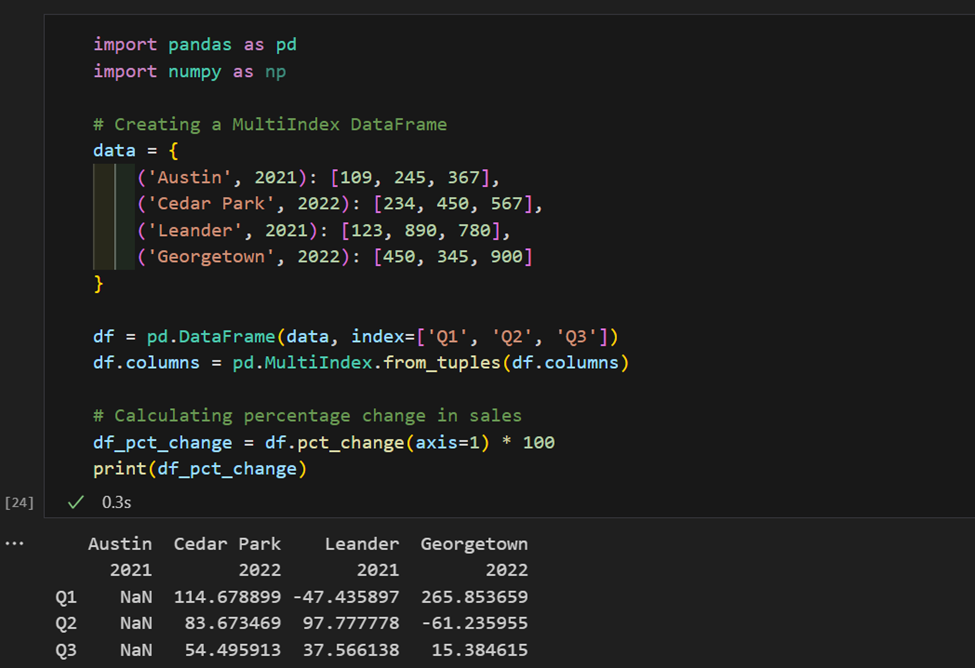
1. Hier hebben we verkoopgegevens geïndexeerd per regio en jaar. Nu berekenen we het percentage verandering in verkoop per regio.
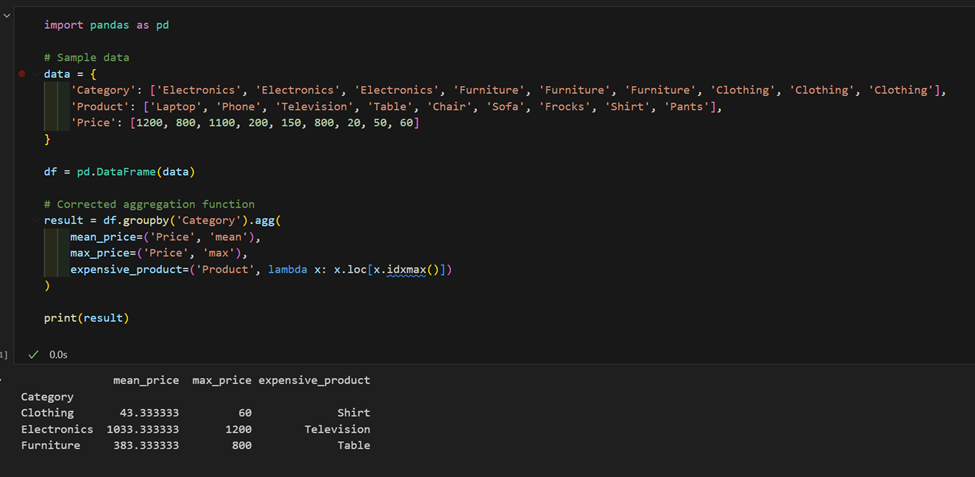
2. We hebben een dataset met producten en prijzen, bereken de gemiddelde prijs per categorie en vind het duurste product in elke categorie.
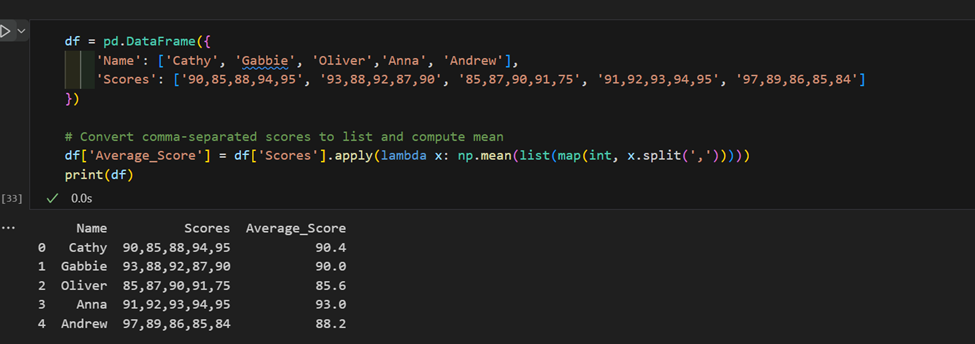
3. Complex gebruik van “apply”:
Conclusie
Deze twee bibliotheken, NumPy en Pandas, worden veel gebruikt in real-life toepassingen zoals BFSI (financiële analyse), wetenschappelijk rekenen, AI en ML, en big data verwerking. Deze twee bibliotheken spelen een cruciale rol in op data gebaseerde besluitvorming, van het analyseren van kritieke trends op de aandelenmarkt tot het beheren van grootschalige ERP-bedrijfsgegevens.
Voor beginners is de volgende stap om te oefenen met het gebruik van NumPy en Pandas door te werken aan kleine projecten, datasets te verkennen, en hun functies toe te passen in real-world scenario’s. Men kan open-source data downloaden van GitHub over financiën, onroerend goed, of algemene productiebedrijfsgegevens. Met die brondata en deze bibliotheken kan men een overtuigend verhaal of empirische analyse creëren. Ervaring opdoen zal helpen om concepten te versterken en leerlingen voor te bereiden op meer geavanceerde data science taken.
Samenvattend zijn zowel NumPy als Pandas twee essentiële Python bibliotheken voor gegevensmanipulatie en -analyse. NumPy biedt krachtige ondersteuning voor numerieke berekeningen met zijn efficiënte array-operaties, terwijl Pandas voortbouwt op NumPy om intrinsieke en intuïtieve gegevensstructuren zoals Series en DataFrame te bieden voor het hanteren van gestructureerde gegevens.
Source:
https://dzone.com/articles/python-libraries-introduction-numpy-pandas