













בתכנות ב-Python, NumPy ו־Pandas תופסים מקום מובהק כשתי מהספריות החזקות ביותר לחישובים נומריים ולעיבוד נתונים.
NumPy: היסוד של חישובים נומריים
NumPy (Numeric Python) מספק תמיכה במערכות מרובות מימדים ומגוון רחב של פונקציות מתמטיות, מה שהופך אותו לכלי חיוני לחישובים מדעיים.
- NumPy היא החבילה היסודית ביותר לחישובים נומריים ב-Python.
- אחד הסיבות לכך ש־NumPy כל כך חשוב לחישובים נומריים היא שהוא מיועד ליעילות עם מערכות נתונים גדולות. הסיבות לכך כוללות:
- הוא שומר נתונים פנימית בבלוק מתמיד של זיכרון, תלויים באובייקטים אחרים מובנים ב-Python.
- הוא מבצע חישובים מורכבים על מערכות שלמות ללא צורך בלולאות "for".
- ה־
ndarrayהוא מערך מרוב־ממדי יעיל המספק פעולות אריתמטיות מהירות ויכולויות שידור גמישות. - אובייקט ה־
ndarrayשל NumPy הוא תופסן מהיר וגמיש למערכות נתונים גדולות ב-Python. - מערכות מאפשרות לך לאחסן פריטים מרובים של אותו סוג נתונים. זהו המתן הנתונים מסביב לאובייקט המערך שהופך את NumPy לנוח כל כך לביצוע חישובים מתמטיים ולעיבוד נתונים.
פעולות ב-NumPy
יצירת המערך:

שינוי צורת המערך:

חיתוך ואינדוקס:

פעולות אריתמטיות:
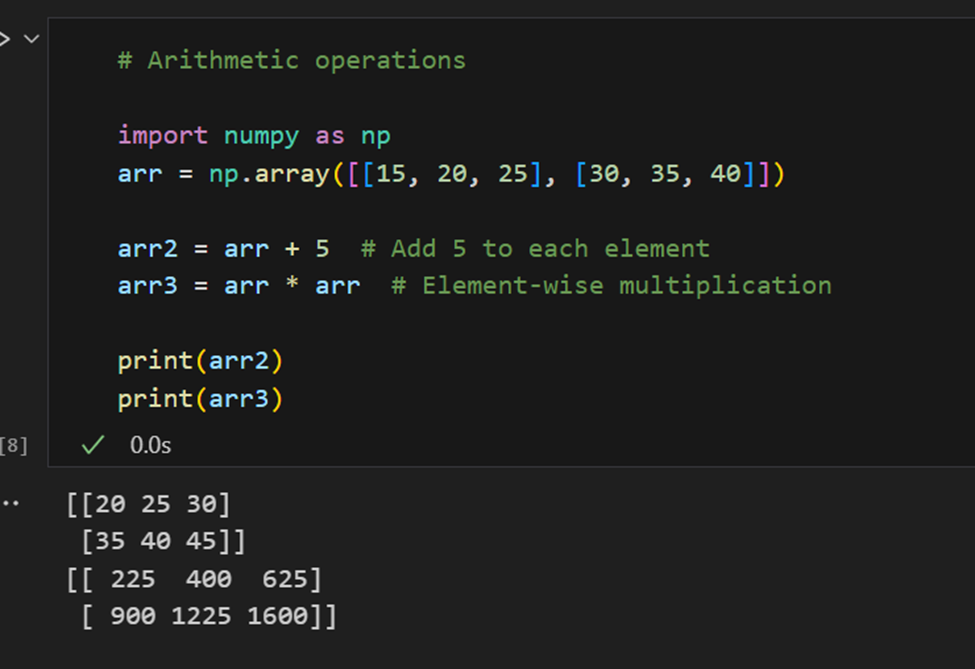
אלגברה ליניארית:

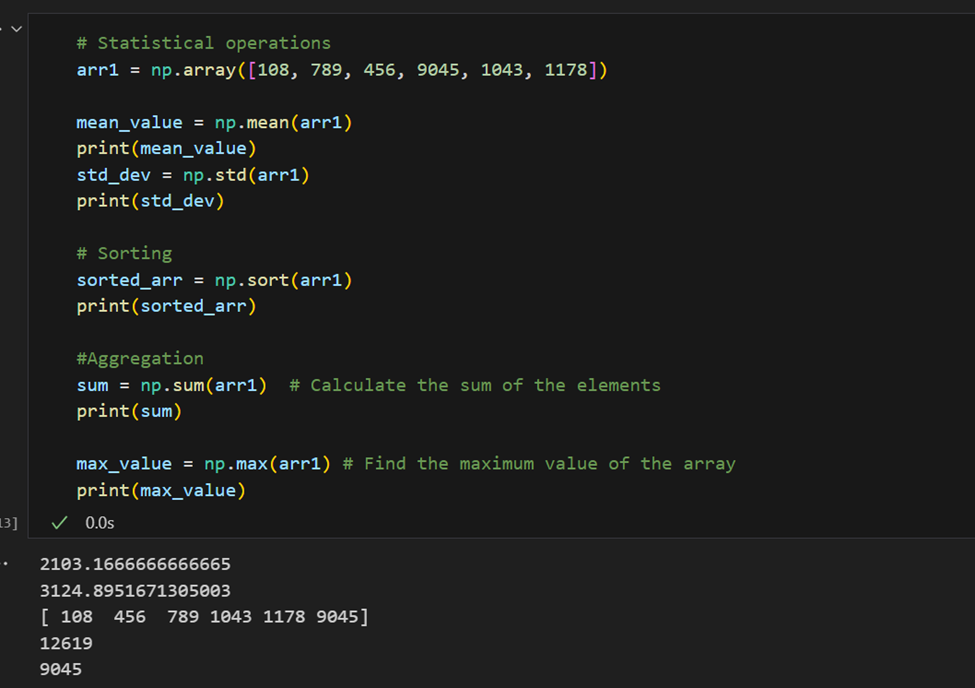
פעולות סטטיסטיות:
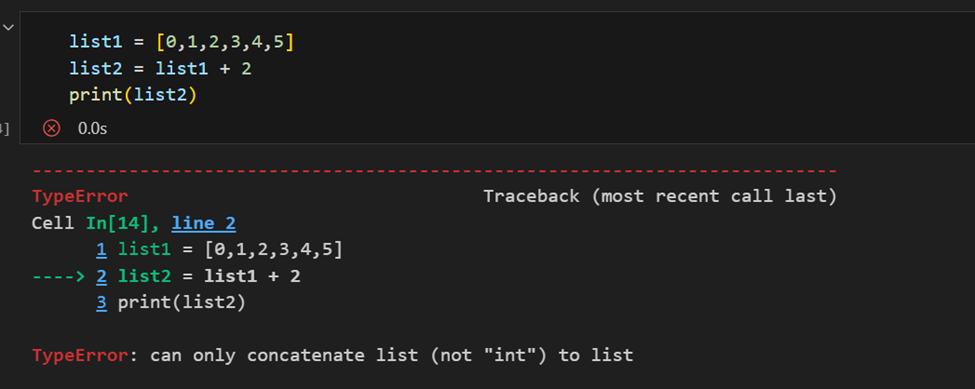
ההבדל בין מערך NumPy לרשימת Python
ההבדל המרכזי בין מערך לרשימה הוא שמערכים מיועדים לטפל בפעולות וקטוריות, בעוד שרשימת Python אינה עושה זאת. זאת אומרת, אם אתה מפעיל פונקציה, היא מתבצעת על כל פריט במערך, ולא על כל אובייקט המערך.
פנדס
פנדס מתבלט כאחת מהספריות החזקות ביותר לחישוב מספרי ומניפולציה של נתונים, שהיא קריטית בתחומי הבינה המלאכותית ולמידת מכונה.
פנדס, כמו NumPy, היא אחת מהספריות הפופולריות ביותר ב-Python. מדובר באבסטרקציה ברמה גבוהה על פני NumPy ברמה נמוכה, שנכתבה בשפת C טהור. פנדס מספקת מבני נתונים קלים לשימוש וביצועים גבוהים וכלים לניתוח נתונים. פנדס משתמשת בשני מבנים עיקריים: מסגרות נתונים ו-סדרות.
אינדקסים בסדרות פנדס
סדרה בפנדס דומה לרשימה, אך היא שונה בכך שסדרה מקשרת תג עם כל אלמנט. זה גורם לה להיראות כמו מילון. אם אינדקס לא מסופק במפורש על ידי המשתמש, פנדס יוצרת אינדקס טווח הנע בין 0 ל-N-1. כל אובייקט סדרה גם יש לו סוג נתונים.
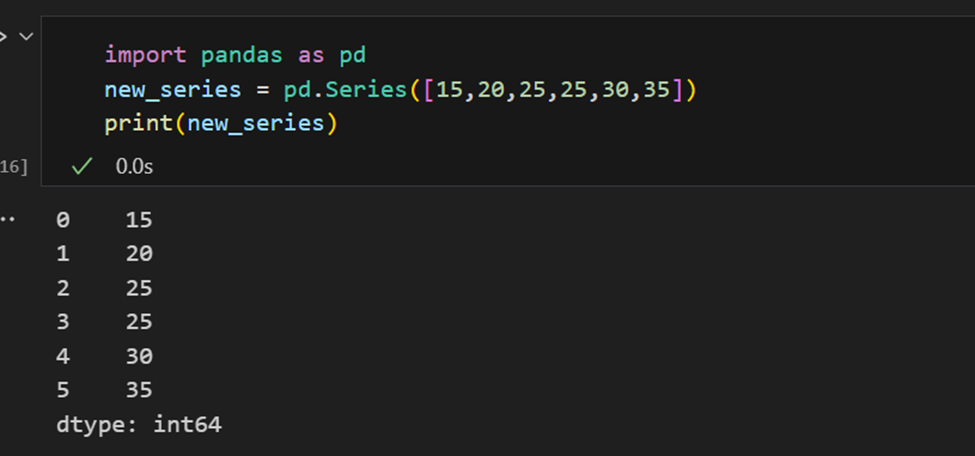
סדרת פנדס מאפשרת להוציא את כל הערכים בסדרה, כמו גם את הפריטים الفردיים לפי אינדקס.
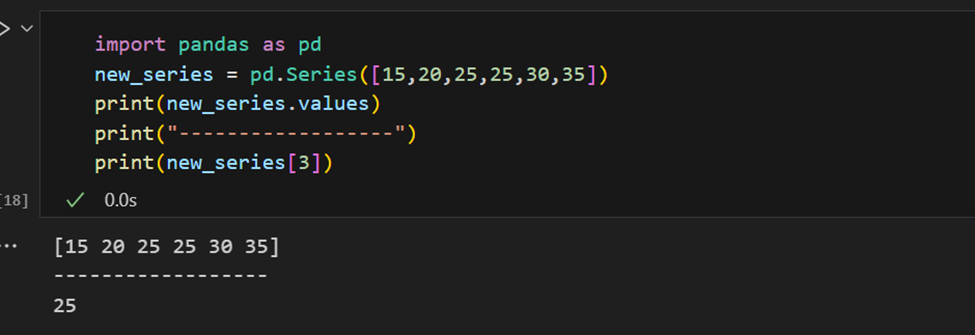
האינדקס יכול להיות מסופק ידנית גם כן.
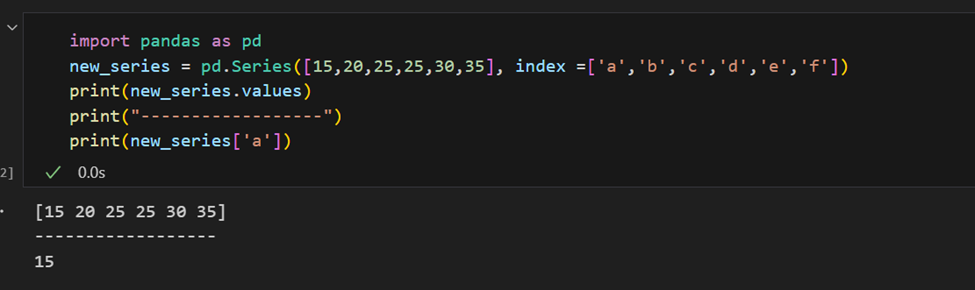
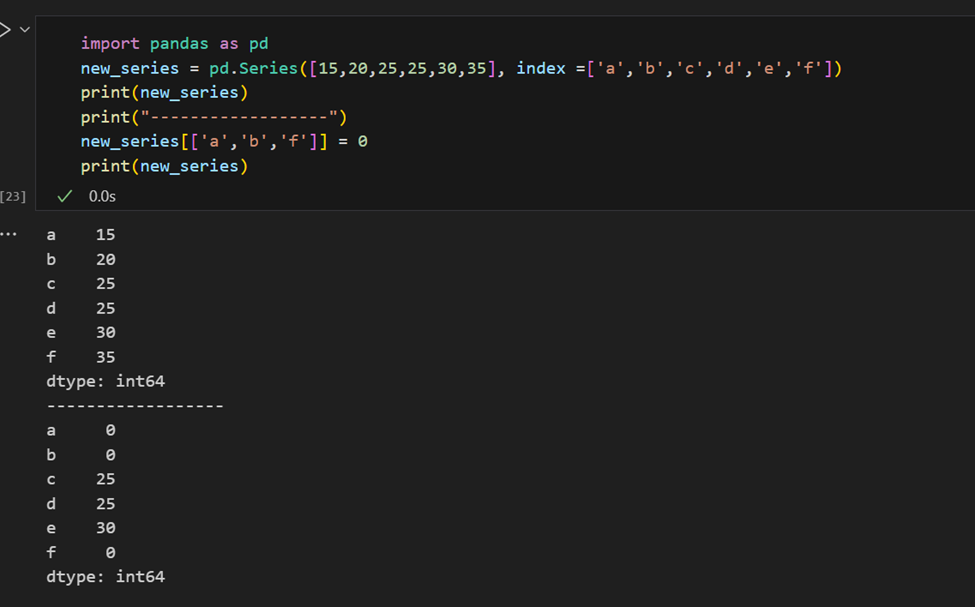
קל להחזיר מספר פריטים מסדרה לפי האינדקסים שלהם או לבצע הקצאות קבוצתיות.
מסגרות נתונים של פנדס
מסגרת נתונים היא טבלה עם שורות ועמודות. כל עמודה במבנה נתונים היא אובייקט סדרה. השורות מורכבות מפריטים בתוך הסדרות. מסגרות נתונים של פנדס מציעות מגוון רחב של פעולות למניפולציה וניתוח נתונים. הנה פירוט של כמה פעולות נפוצות:
פעולות בסיסיות
יצירת מסגרות נתונים
- מדיקט:
pd.DataFrame({'col1': [1, 2], 'col2': [3, 4]}) - מקובץ CSV:
pd.read_csv('data.csv') - מקובץ Excel:
pd.read_excel('data.xlsx')
גישה לנתונים
- בחירת עמודות:
df['col1'] - בחירת שורות:
df.loc[0] (לפי תווית אינדקס), df.iloc[0](לפי מיקום אינדקס) - חיתוך:
df [0:2] (שתי השורות הראשונות), df[['coll', 'col2']](מספר עמודות)
הוספה והסרה של עמודות/שורות
- הוספת עמודה:
df['new_col'] = - הסרת עמודה:
df.drop('coll', axis=1) - הוספת שורה:
df.append({'col1': 7, 'col2': 8}, ignore_index=True) - הסרת שורה:
df.drop(0)
סינון נתונים
- באמצעות תנאים בוליאניים:
df [df['col1'] > 2]
פעולות מתמטיות
- פעולות אריתמטיות:
df['col1'] + df['col2'],df * 2, וכו'. - פונקציות אגגרציה:
df.sum(),df.mean(),df.max(),df.min(), וכו'. - החלת פונקציות מותאמות אישית:
df.apply(lambda x: x**2)
טיפול בנתונים חסרים
- בדיקת ערכים חסרים:
df.isnull() - הסרת ערכים חסרים:
df.dropna() - מילוי ערכים חסרים:
df.fillna(0)
מיזוג וחיבור DataFrames
- מיזוג:
pd.merge(df1, df2, on='key_column') - חיבור:
df1.join(df2, on='key_column')
קיבוץ ואיגוד
- קיבוץ:
df.groupby('col1') - איגוד:
df.groupby('col1').mean()
פעולות סדרות זמן
- דגימה מחדש:
df.resample('D').sum()(דגימה יומית) - הזזה של זמן:
df.shift(1)(הזזת נתונים לפי תקופה אחת)
ויזואליזציה של נתונים
ציור: df.plot() (גרף קו), df.hist() (היסטוגרמה), וכו'.
דוגמאות מורכבות של פנדס
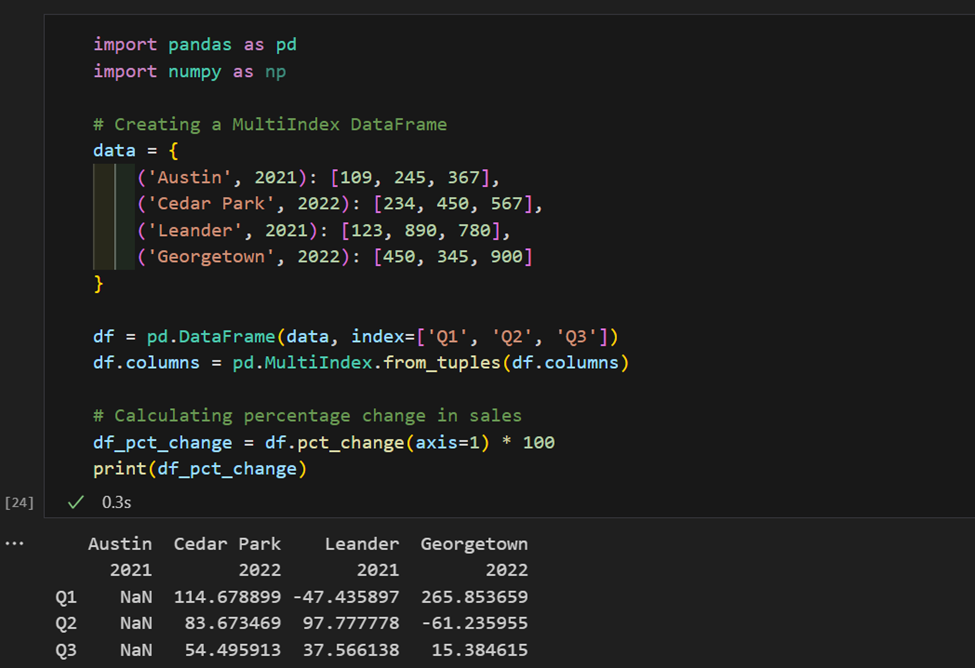
1. כאן יש נתוני מכירות מסודרים לפי אזור ושנה. כעת, כאן אנו מחשבים את שיעור השינוי במכירות לפי אזור.
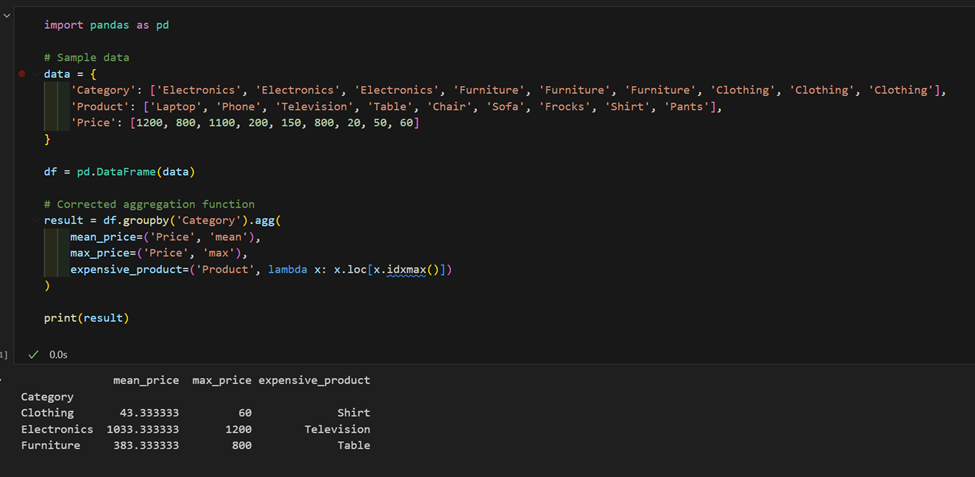
2. יש לנו קבצי נתונים עם מוצרים ומחירים, נחשב את המחיר הממוצע לכל קטגוריה ונמצא את המוצר היקר ביותר בכל קטגוריה.
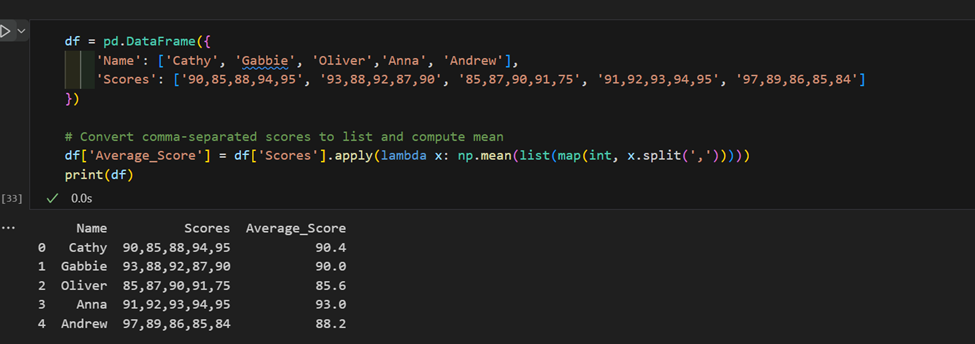
3. שימוש מורכב ב-"apply":
מסקנה
שתי הספריות הללו, NumPy ו־Pandas, משמשות בצורה נרחבת ביישומים בחיים אמיתיים כמו BFSI (ניתוח פיננסי), חישוב מדעי, AI ו־ML, ועיבוד נתונים גדולים. שתי הספריות הללו משחקות תפקיד מרכזי בקבלת החלטות המבוססות על נתונים, מניתוח מגמות חשובות בשוק ההון עד לניהול נתוני עסקי ERP בממדי קניות בגודל גדול.
למתחילים, השלב הבא הוא לתרגל בשימוש ב־NumPy ו־Pandas על ידי עבודה על פרויקטים קטנים, חקירת קבצי נתונים, והחלת פונקציותיהם בתרחישים בעולם האמיתי. ניתן להוריד נתונים מקור פתוח מ-GitHub על נתונים פיננסיים, נדל"ן, או נתוני עסקי ייצור כלליים. עם הנתונים האלה והספריות, ניתן ליצור סיפור משכנע או ניתוח אמפירי. ניסיון מעשי יעזור לחזק מושגים ולהכין לומדים למשימות במדעי הנתונים המתקדמות יותר.
לסיכום, גם NumPy ו־Pandas הם שתי ספריות Python חיוניות לעיבוד וניתוח נתונים. כאן, NumPy מספק תמיכה חזקה לחישובים מספריים עם פעולות מערךים יעילות, בעוד Pandas בונה על NumPy כדי להציע מבני נתונים פנימיים ואינטואיטיביים כמו Series ו־DataFrame לטיפול בנתונים מובנים.
Source:
https://dzone.com/articles/python-libraries-introduction-numpy-pandas