













В программировании на Python выделяются две из самых мощных библиотек для численных вычислений и манипулирования данными: NumPy и Pandas.
NumPy: Основа Численных Вычислений
NumPy (Numerical Python) предоставляет поддержку для многомерных массивов и широкий спектр математических функций, что делает его необходимым для научных вычислений.
- NumPy является базовым пакетом для численных вычислений в Python.
- Одной из причин, почему NumPy настолько важен для численных вычислений, является то, что он разработан для эффективной работы с большими массивами данных. Причины включают в себя:
- Он хранит данные внутри непрерывного блока памяти, независимо от других встроенных объектов Python.
- Он выполняет сложные вычисления над целыми массивами без необходимости использования циклов “for”.
- Объект
ndarrayявляется эффективным многомерным массивом, обеспечивающим быстрые операции с массивами и гибкие возможности транслирования. - Объект ndarray в NumPy – быстрый и гибкий контейнер для больших наборов данных в Python.
- Массивы позволяют хранить несколько элементов одного типа данных. Именно возможности вокруг объекта массива делают NumPy таким удобным для выполнения математических и операций с данными.
Операции в NumPy
Создание массива:

Изменение формы массива:

Срезы и индексирование:

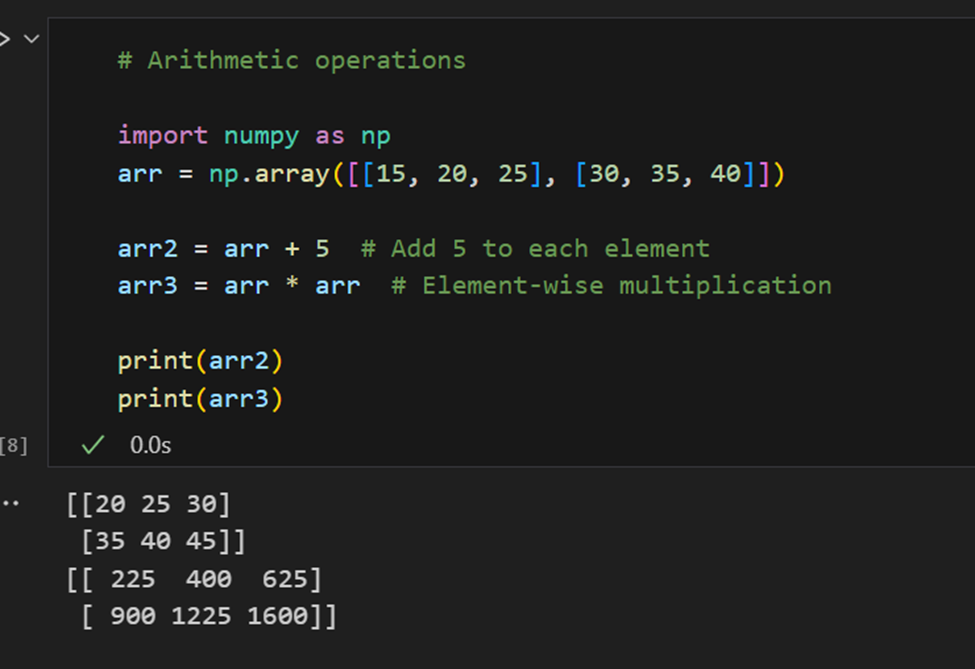
Арифметические операции:
Линейная алгебра:

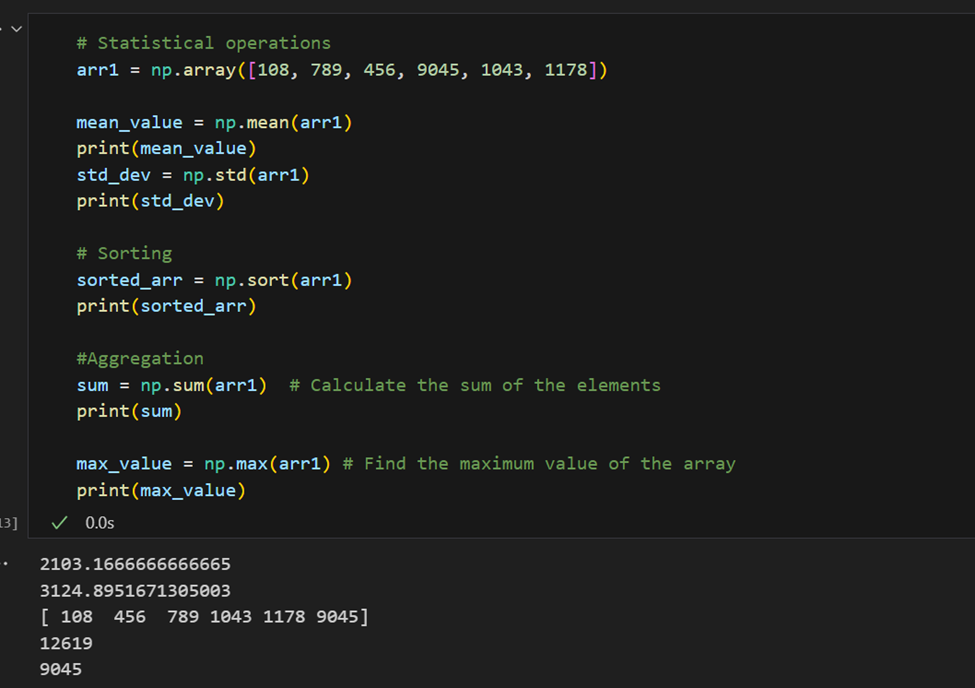
Статистические операции:
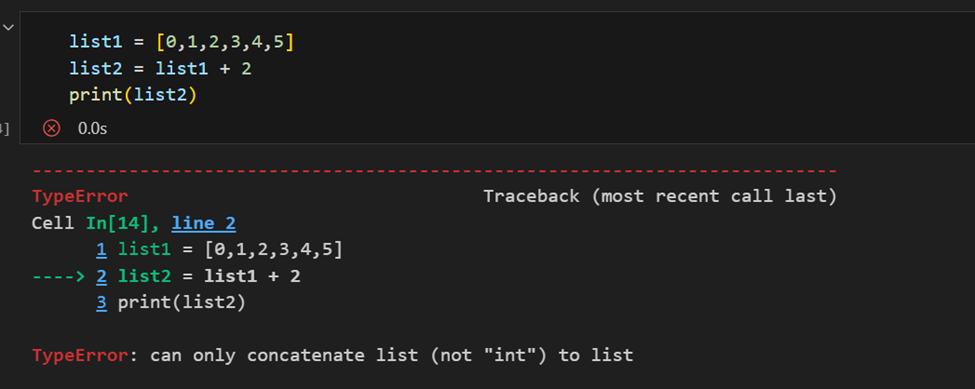
Разница между массивом NumPy и списком Python
Основное различие между массивом и списком заключается в том, что массивы предназначены для выполнения векторизованных операций, в то время как список Python нет. Это означает, что если применить функцию, она будет выполнена для каждого элемента в массиве, а не для всего объекта массива.
Библиотека Pandas
Pandas выделяется как одна из самых мощных библиотек для численных вычислений и манипуляций с данными, что критично для областей искусственного интеллекта и машинного обучения.
Pandas, подобно NumPy, является одной из самых популярных библиотек Python. Это высокоуровневая абстракция над низкоуровневым NumPy, написанным на чистом C. Pandas предоставляет высокопроизводительные структуры данных и инструменты для анализа данных, легкие в использовании. Pandas использует две основные структуры: фреймы данных и серии.
Индексы в сериях Pandas
Серия Pandas похожа на список, но отличается тем, что серия ассоциирует метку с каждым элементом. Это делает ее похожей на словарь. Если пользователь явно не предоставил индекс, Pandas создает RangeIndex от 0 до N-1. У каждого объекта серии также есть тип данных.
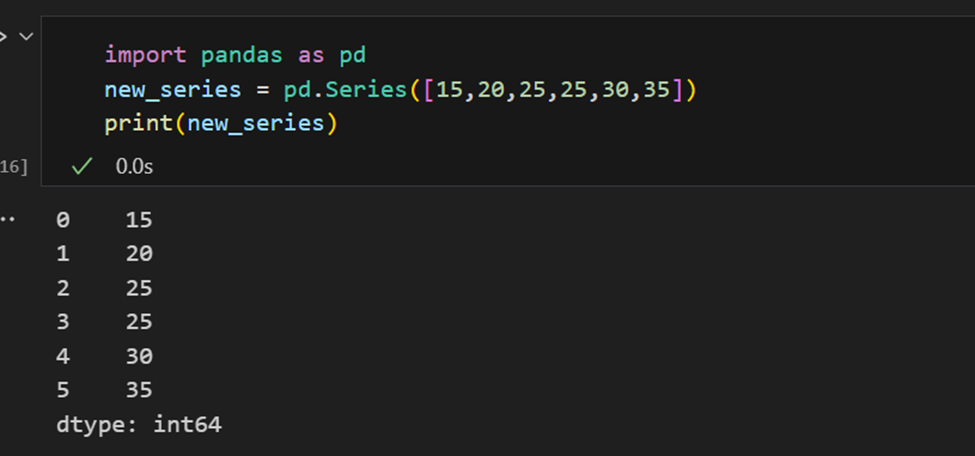
Серия Pandas имеет способы извлечения всех значений в серии, а также отдельных элементов по индексу.
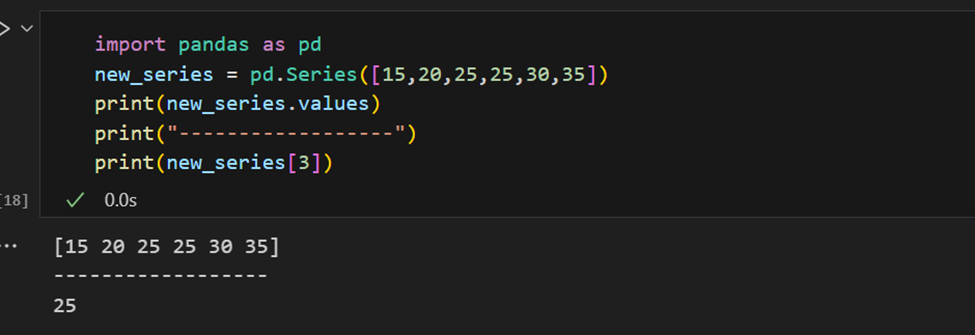
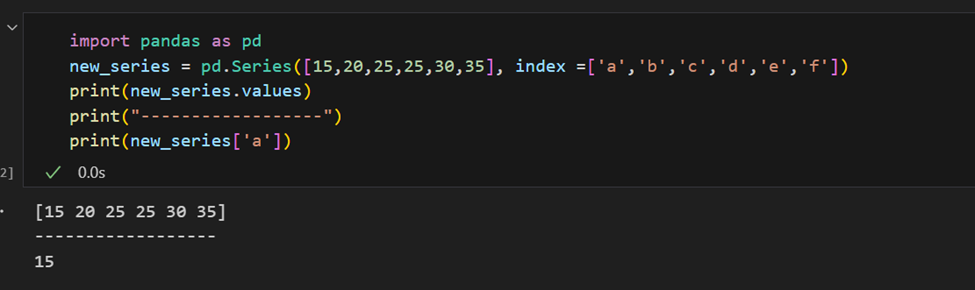
Индекс может быть указан вручную.
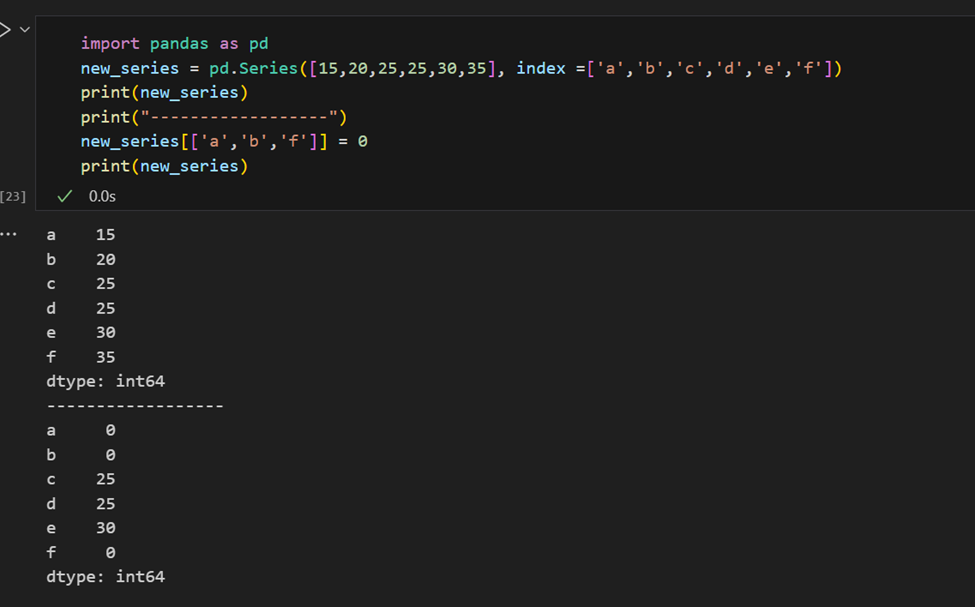
Легко извлечь несколько элементов серии по их индексам или выполнить групповые присваивания.
Фреймы данных Pandas
Фрейм данных – это таблица с рядами и столбцами. Каждый столбец в фрейме данных является объектом серии. Ряды состоят из элементов внутри серий. Фреймы данных Pandas предлагают широкий спектр операций для манипуляции и анализа данных. Вот обзор некоторых распространенных операций:
Основные операции
Создание фреймов данных
- Из словаря:
pd.DataFrame({'col1': [1, 2], 'col2': [3, 4]}) - Из файла CSV:
pd.read_csv('data.csv') - Из файла Excel:
pd.read_excel('data.xlsx')
Доступ к данным
- Выбор столбцов:
df['col1'] - Выбор строк:
df.loc[0] (по метке индекса), df.iloc[0](по позиции индекса) - Срезы:
df [0:2] (первые две строки), df[['coll', 'col2']](несколько столбцов)
Добавление и удаление столбцов/строк
- Добавление столбца:
df['new_col'] = - Удаление столбца:
df.drop('coll', axis=1) - Добавление строки:
df.append({'col1': 7, 'col2': 8}, ignore_index=True) - Удаление строки:
df.drop(0)
Фильтрация данных
- Использование булевых условий:
df[df['col1'] > 2]
Математические операции
- Арифметические операции:
df['col1'] + df['col2'],df * 2, и т. д. - Функции агрегирования:
df.sum(),df.mean(),df.max(),df.min(), и т. д. - Применение пользовательских функций:
df.apply(lambda x: x**2)
Обработка отсутствующих данных
- Проверка на отсутствующие значения:
df.isnull() - Удаление отсутствующих значений:
df.dropna() - Заполнение отсутствующих значений:
df.fillna(0)
Объединение и присоединение фреймов данных
- Объединение:
pd.merge(df1, df2, on='key_column') - Присоединение:
df1.join(df2, on='key_column')
Группировка и агрегирование
- Группировка:
df.groupby('col1') - Агрегирование:
df.groupby('col1').mean()
Операции с временными рядами
- Ресемплирование:
df.resample('D').sum()(уменьшение до ежедневной частоты) - Сдвиг по времени:
df.shift(1)(сдвиг данных на один период)
Визуализация данных
Построение графиков: df.plot() (линейный график), df.hist() (гистограмма), и т. д.
Сложные примеры использования Pandas
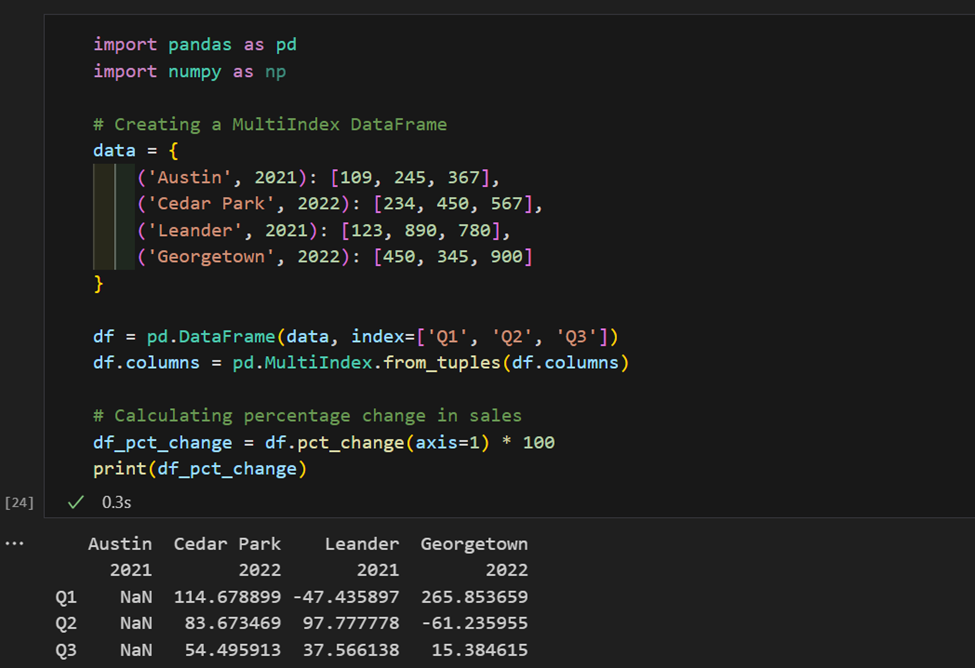
1. Здесь у нас есть данные о продажах, проиндексированные по регионам и годам. Теперь мы рассчитываем процентное изменение продаж по регионам.
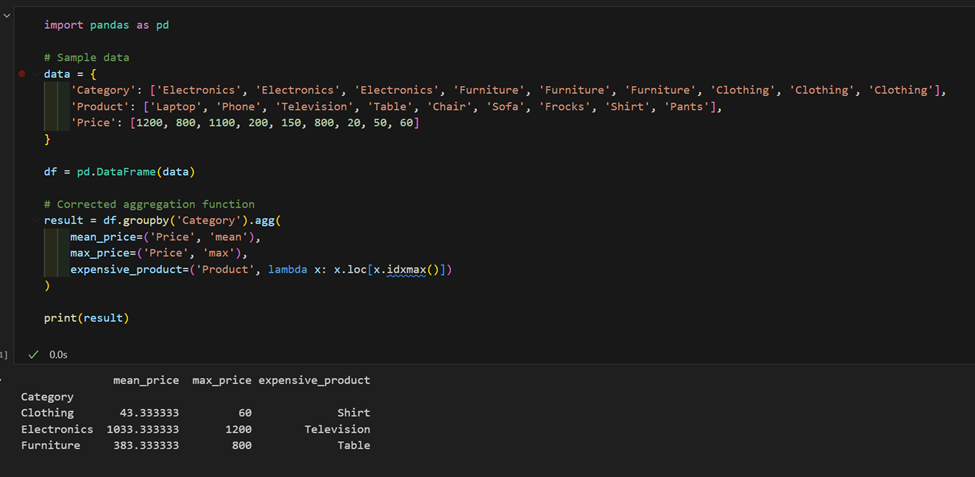
2. У нас есть набор данных о продуктах и ценах, рассчитайте среднюю цену по категориям и найдите самый дорогой продукт в каждой из них.
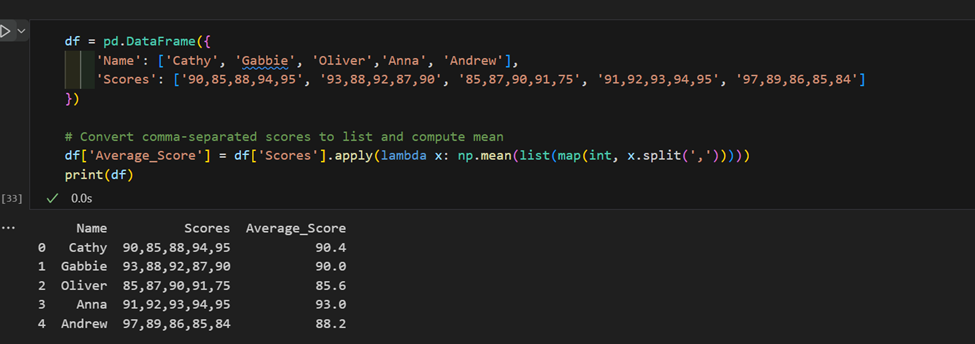
3. Сложное использование “apply”:
Заключение
Эти две библиотеки, NumPy и Pandas, широко используются в реальных приложениях, таких как финансовый анализ BFSI, научные вычисления, искусственный интеллект и машинное обучение, а также обработка больших данных. Эти две библиотеки играют ключевую роль в принятии решений на основе данных, начиная от анализа критических тенденций на фондовом рынке до управления данными о крупных ERP-бизнесах.
Для начинающих следующим шагом будет практика использования NumPy и Pandas на небольших проектах, исследование наборов данных и применение их функций в реальных сценариях. Можно загрузить открытые данные с GitHub о финансах, недвижимости или данных о производстве. С помощью этих исходных данных и этих библиотек можно создать убедительный рассказ или эмпирический анализ. Практический опыт поможет закрепить концепции и подготовить студентов к более сложным задачам в области науки о данных.
В заключение, как NumPy, так и Pandas – две важные библиотеки Python для манипулирования и анализа данных. NumPy обеспечивает мощную поддержку для числовых вычислений благодаря своим эффективным операциям с массивами, в то время как Pandas строит на NumPy, предлагая встроенные и интуитивно понятные структуры данных, такие как Series и DataFrame, для работы с структурированными данными.
Source:
https://dzone.com/articles/python-libraries-introduction-numpy-pandas