













在Python编程中,NumPy和Pandas是两个最强大的用于数值计算和数据操作的库。
NumPy:数值计算的基础
NumPy(Numerical Python)支持多维数组和各种数学函数,对科学计算至关重要。
- NumPy是Python中数值计算最基础的包。
- NumPy之所以在数值计算中如此重要的原因之一是它专为处理大型数据数组而设计的效率。其中的原因包括:
- 它在内部以连续的内存块存储数据,与其他内置Python对象无关。
- 它在整个数组上执行复杂计算,无需使用“for”循环。
ndarray是一个高效的多维数组,提供快速的面向数组的算术运算和灵活的广播功能。- NumPy的
ndarray对象是Python中大型数据集的快速灵活容器。 - 数组使您能够存储相同数据类型的多个项目。正是围绕数组对象的功能使NumPy在执行数学和数据操作时如此方便。
NumPy中的操作
创建数组:

重塑数组:

切片和索引:

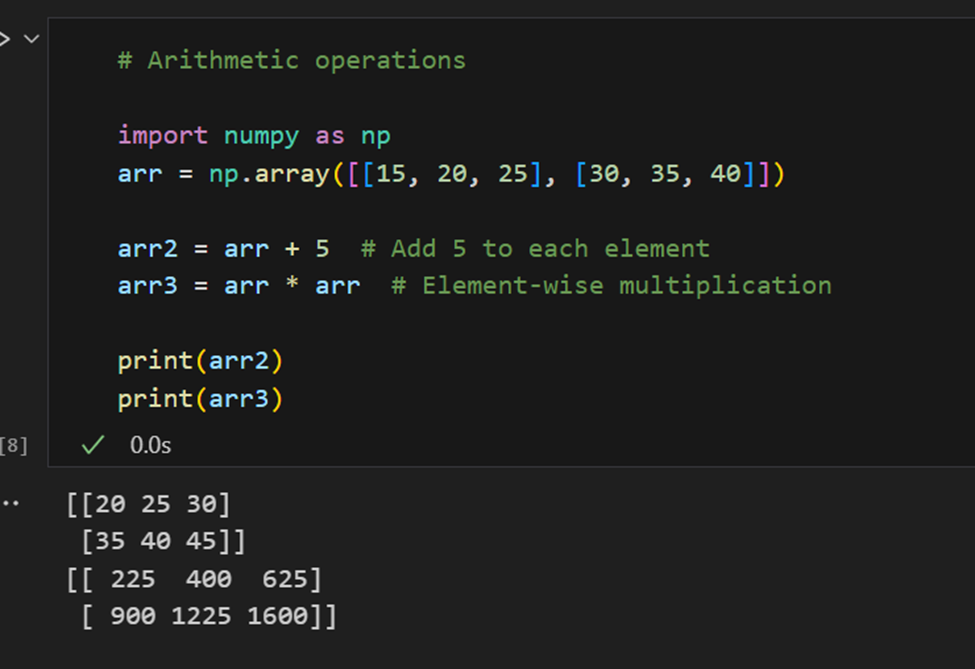
算术运算:
线性代数:

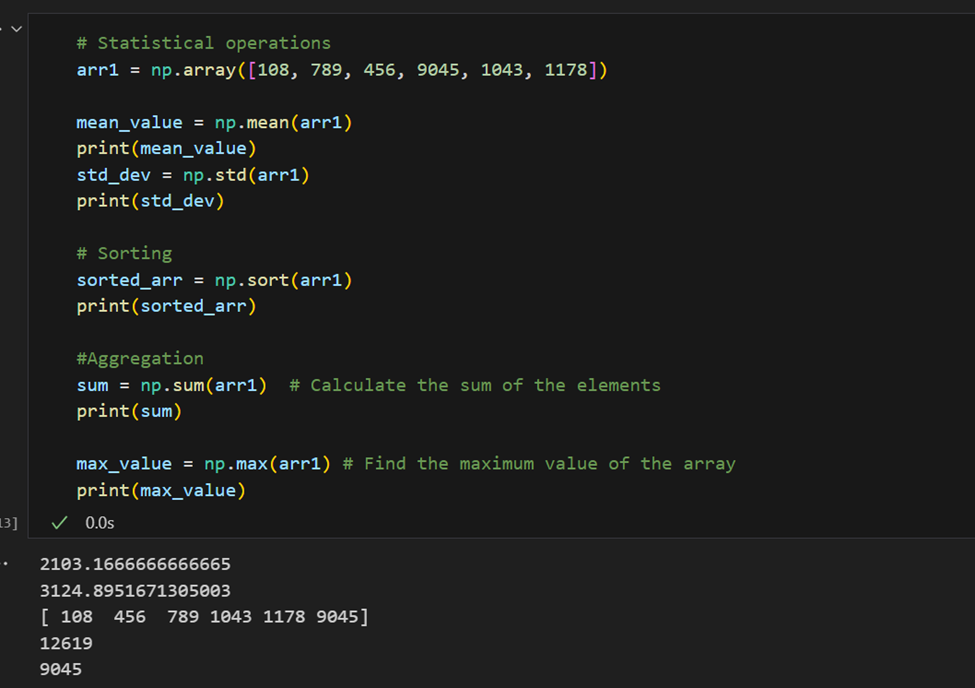
统计操作:
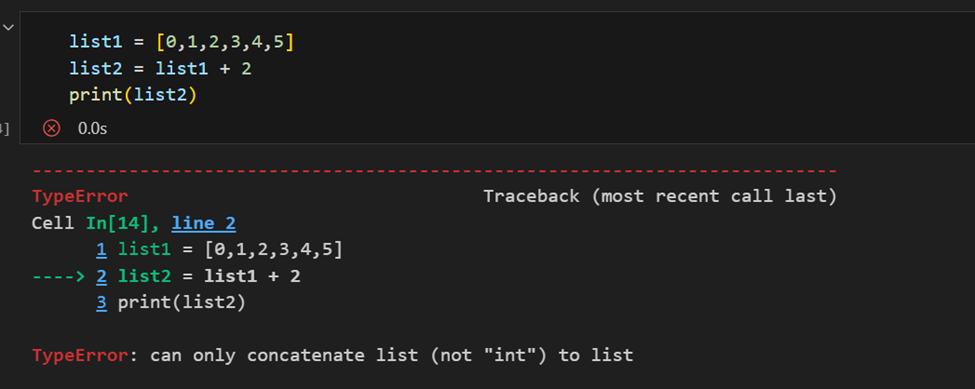
NumPy数组与Python列表的区别
数组和列表的主要区别在于数组设计用于处理矢量化操作,而Python列表不是。这意味着,如果应用函数,它将在数组中的每个项目上执行,而不是在整个数组对象上执行。
Pandas
Pandas凭借其出色的性能成为了最强大的用于数值计算和数据操作的库之一,这对于人工智能和机器学习领域至关重要。
Pandas和NumPy一样,是最流行的Python库之一。它是对底层NumPy的高级抽象,使用纯C编写。Pandas提供高性能、易于使用的数据结构和数据分析工具。Pandas使用两种主要结构:数据框和序列。
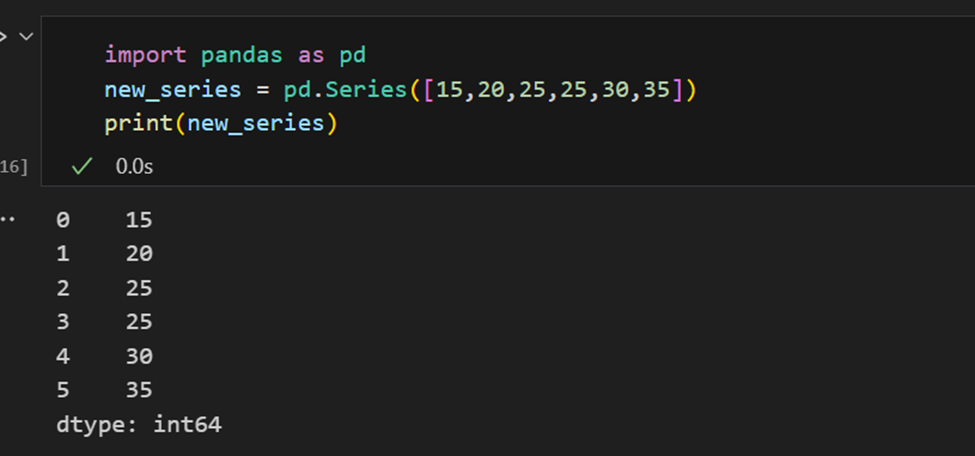
Pandas序列中的索引
Pandas序列类似于列表,但不同之处在于序列将标签与每个元素关联起来。这使其类似于字典。如果用户未明确提供索引,Pandas将创建一个从0到N-1的RangeIndex。每个序列对象还具有数据类型。
Pandas系列有提取系列中所有值的方法,也可以通过索引提取单个元素。
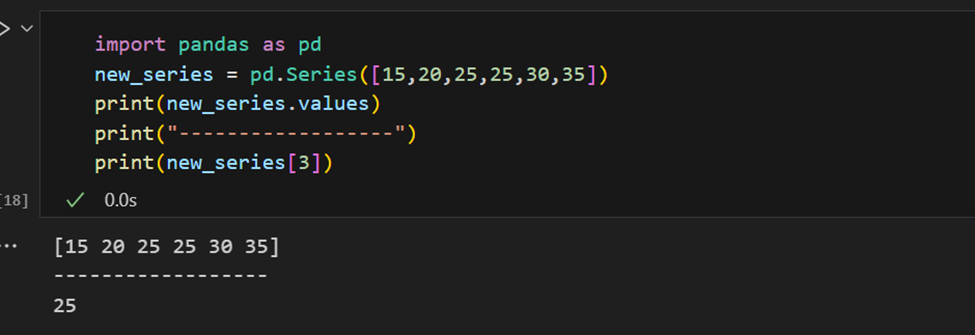
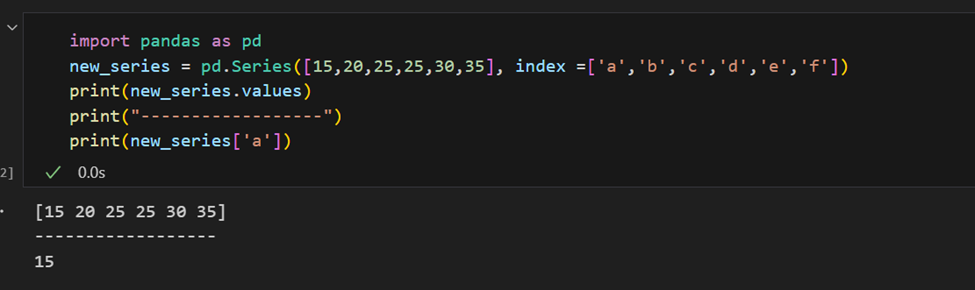
索引也可以手动提供。
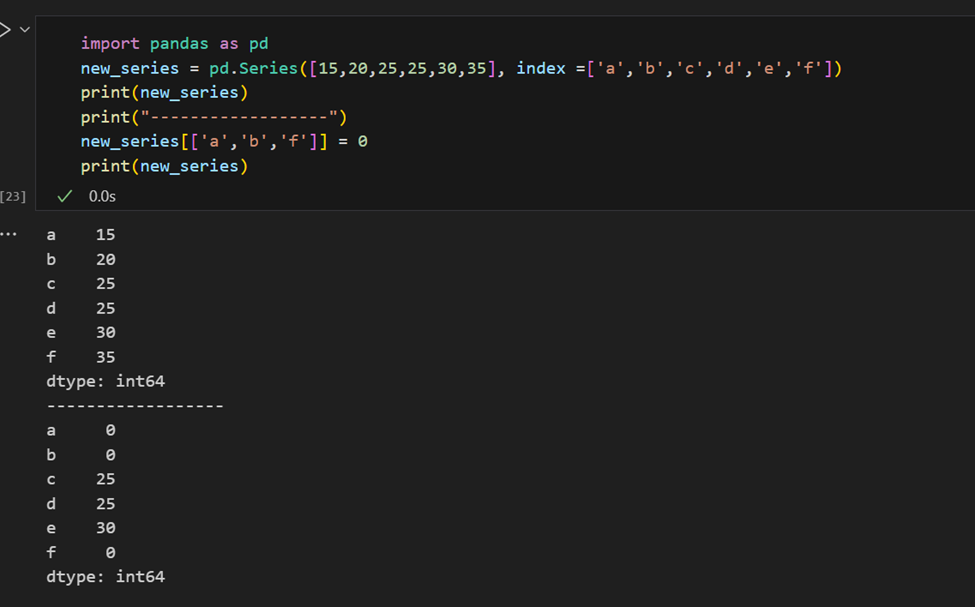
通过它很容易通过它们的索引检索系列的多个元素或进行分组赋值。
Pandas数据帧
数据帧是具有行和列的表格。数据帧中的每一列都是一个系列对象。行由系列内的元素组成。Pandas数据帧提供了广泛的数据操作和分析操作。以下是一些常见操作的概述:
基本操作
创建数据帧
- 从字典创建:
pd.DataFrame({'col1': [1, 2], 'col2': [3, 4]}) - 从CSV文件创建:
pd.read_csv('data.csv') - 从Excel文件创建:
pd.read_excel('data.xlsx')
访问数据
- 选择列:
df['col1'] - 选择行:
df.loc[0] (按索引标签),df.iloc[0](按索引位置) - 切片:
df [0:2] (前两行),df[['coll', 'col2']](多个列)
添加和删除列/行
- 添加列:
df['new_col'] = - 删除列:
df.drop('coll', axis=1) - 添加行:
df.append({'col1': 7, 'col2': 8}, ignore_index=True) - 删除一行:
df.drop(0)
数据过滤
- 使用布尔条件:
df [df['col1'] > 2]
数学运算
- 算术运算:
df['col1'] + df['col2'],df * 2,等等 - 聚合函数:
df.sum(),df.mean(),df.max(),df.min(),等等 - 应用自定义函数:
df.apply(lambda x: x**2)
处理缺失数据
- 检查缺失值:
df.isnull() - 丢弃缺失值:
df.dropna() - 填充缺失值:
df.fillna(0)
合并和连接数据框
- 合并:
pd.merge(df1, df2, on='key_column') - 连接:
df1.join(df2, on='key_column')
分组和聚合
- 分组:
df.groupby('col1') - 聚合:
df.groupby('col1').mean()
时间序列操作
- 重新采样:
df.resample('D').sum()(降采样为每日频率) - 时间转移:
df.shift(1)(数据按一个周期移位)
数据可视化
绘图:df.plot()(线图),df.hist()(直方图),等等
复杂的 Pandas 示例
1. 这里,我们有按地区和年份索引的销售数据。现在,我们计算每个地区销售额的百分比变化。
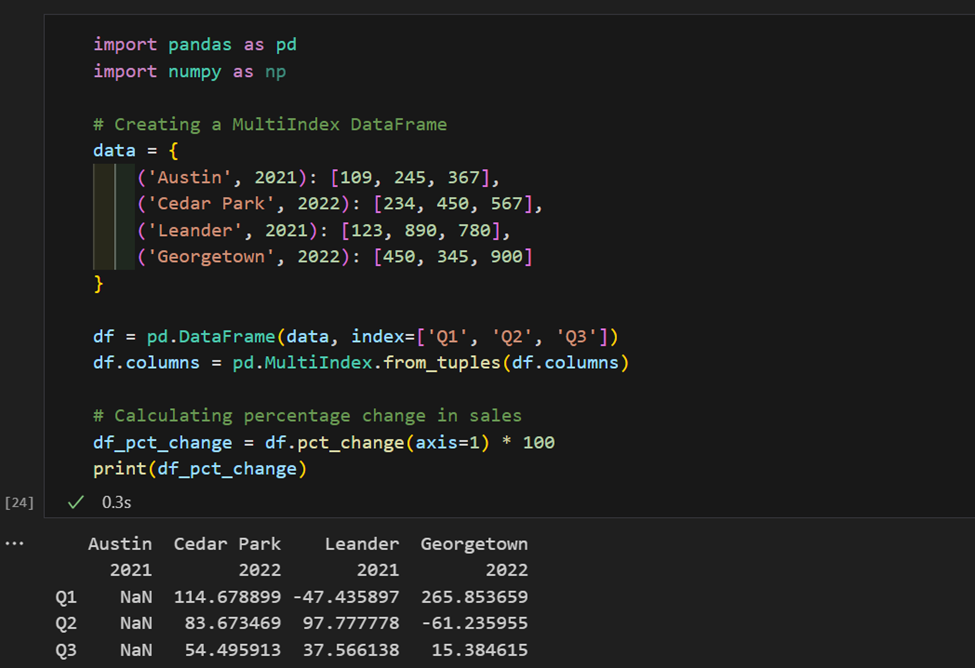
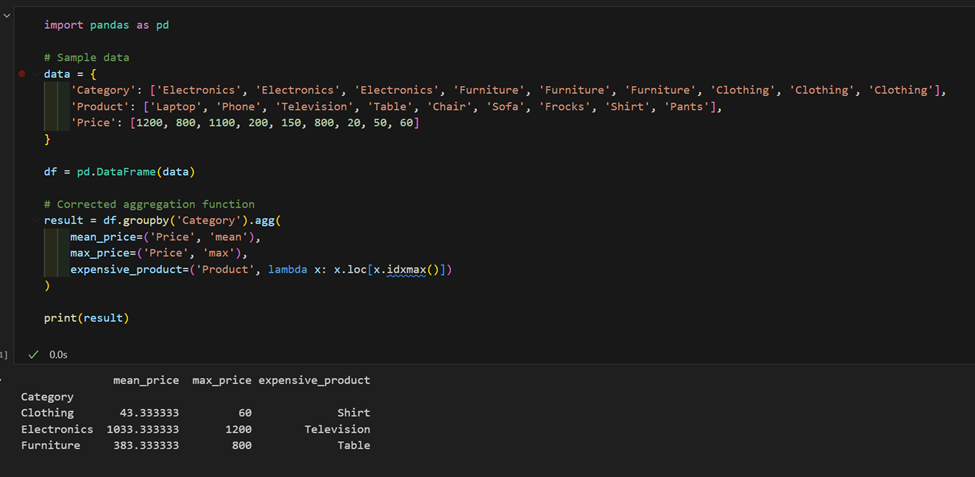
2. 我们有一个包含产品和价格的数据集,请计算每个类别的平均价格,并找到每个类别中最昂贵的产品。
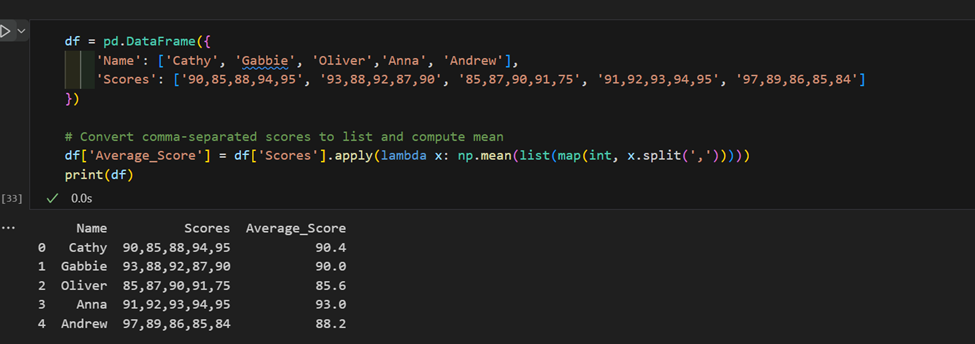
3. 复杂的“apply”用法:
结论
这两个库,NumPy和Pandas,在现实生活中被广泛应用,比如在BFSI(金融分析)、科学计算、人工智能和机器学习以及大数据处理等领域。这两个库在数据驱动的决策中发挥着关键作用,从分析关键的股市趋势到管理大规模ERP业务数据。
对于初学者来说,下一步是通过开展小型项目、探索数据集并将它们的函数应用于实际场景来练习使用NumPy和Pandas。可以从GitHub上下载金融、房地产或一般制造业的开源数据。有了这些源数据和这些库,人们可以创建引人入胜的故事或经验分析。动手实践将有助于巩固概念,并为学习者做更高级的数据科学任务做好准备。
总之,NumPy和Pandas是数据操纵和分析的两个重要的Python库。在这里,NumPy通过其高效的数组操作为数值计算提供了强大的支持,而Pandas在NumPy的基础上构建,为处理结构化数据提供了类似Series和DataFrame的内在和直观的数据结构。
Source:
https://dzone.com/articles/python-libraries-introduction-numpy-pandas