













Na programação em Python, NumPy e Pandas destacam-se como duas das bibliotecas mais poderosas para computação numérica e manipulação de dados.
NumPy: A Fundação da Computação Numérica
NumPy (Numerical Python) fornece suporte para arrays multidimensionais e uma ampla gama de funções matemáticas, tornando-o essencial para computação científica.
- O NumPy é o pacote mais fundamental para computação numérica em Python.
- Uma das razões pelas quais o NumPy é tão importante para cálculos numéricos é que ele é projetado para eficiência com grandes arrays de dados. Os motivos para isso incluem:
- Ele armazena dados internamente em um bloco contínuo de memória, independente de outros objetos Python integrados.
- Ele realiza cálculos complexos em arrays inteiros sem a necessidade de loops “for”.
- O objeto
ndarrayé um array multidimensional eficiente que fornece operações aritméticas rápidas orientadas para arrays e capacidades flexíveis de transmissão. - O objeto
ndarraydo NumPy é um contêiner rápido e flexível para grandes conjuntos de dados em Python. - Arrays permitem que você armazene vários itens do mesmo tipo de dados. São as facilidades em torno do objeto array que tornam o NumPy tão conveniente para realizar operações matemáticas e manipulações de dados.
Operações em NumPy
Criando o array:

Redimensionando o array:

Fatiando e indexando:

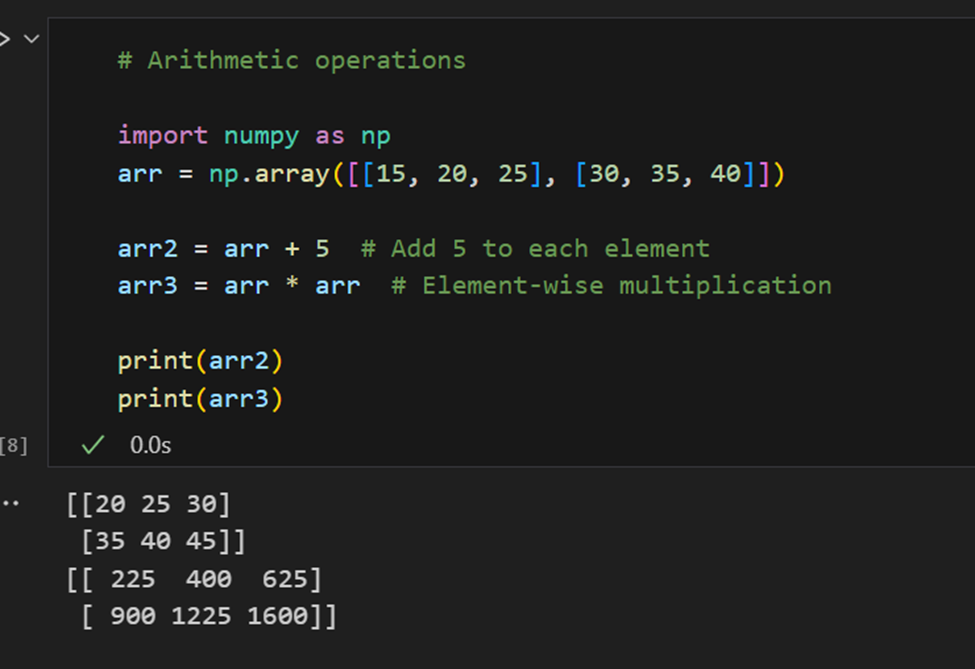
Operações aritméticas:
Álgebra linear:

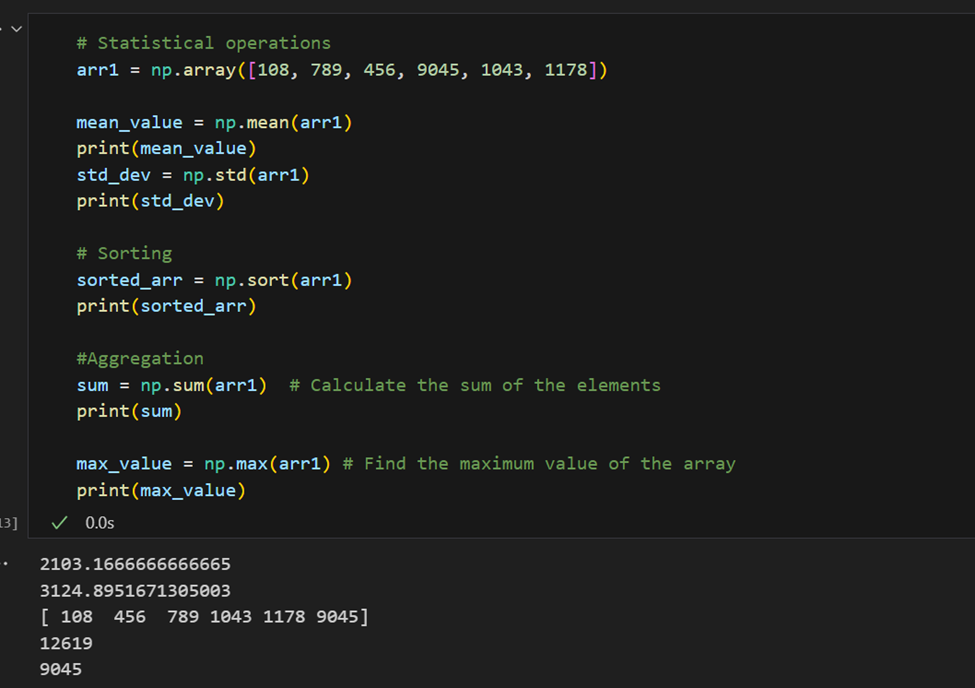
Operações estatísticas:
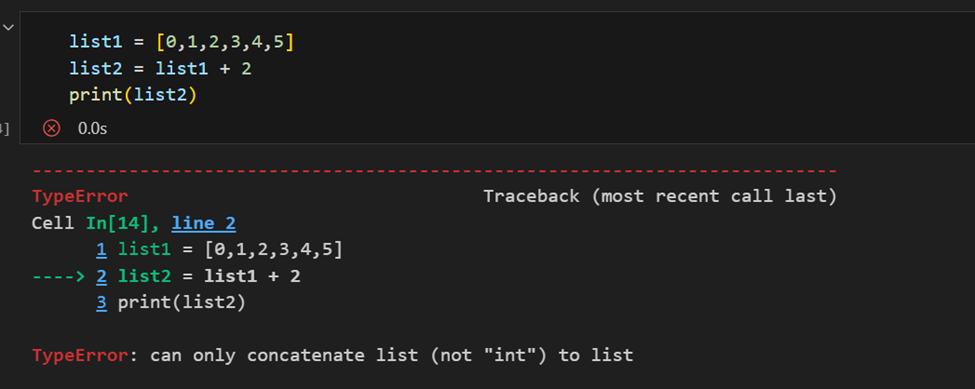
Diferença entre Array NumPy e Lista Python
A diferença chave entre um array e uma lista é que arrays são projetados para lidar com operações vetorizadas, enquanto uma lista Python não é. Isso significa que, se você aplicar uma função, ela é realizada em cada item do array, em vez de em todo o objeto array.
Pandas
O Pandas se destaca como uma das bibliotecas mais poderosas para computação numérica e manipulação de dados, o que é crucial para áreas de inteligência artificial e aprendizado de máquina.
O Pandas, assim como o NumPy, é uma das bibliotecas Python mais populares. É uma abstração de alto nível sobre o NumPy de baixo nível, que é escrito em C puro. O Pandas fornece estruturas de dados de alto desempenho e ferramentas de análise de dados fáceis de usar. O Pandas utiliza duas estruturas principais: data framese series.
Índices em Séries Pandas
Uma série Pandas é semelhante a uma lista, mas difere no fato de que uma série associa um rótulo a cada elemento. Isso a faz parecer com um dicionário. Se um índice não for explicitamente fornecido pelo usuário, o Pandas cria um RangeIndex variando de 0 a N-1. Cada objeto de série também possui um tipo de dados.
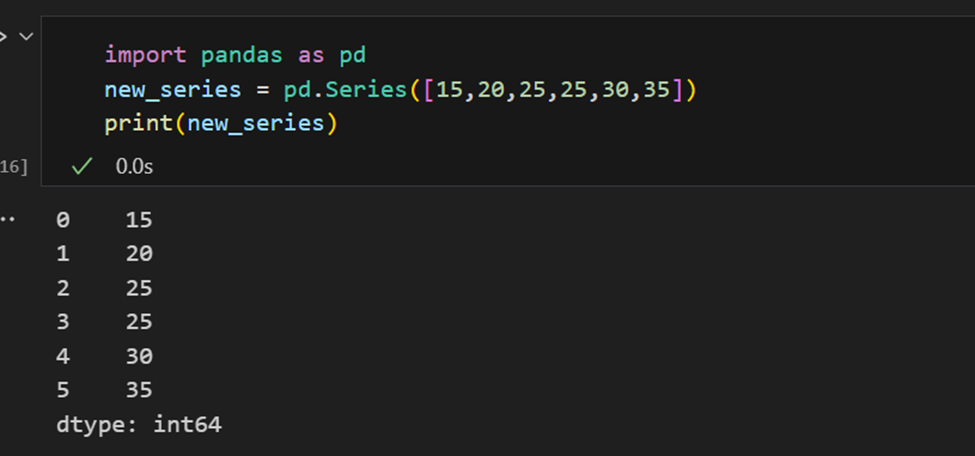
Uma série do Pandas tem maneiras de extrair todos os valores da série, bem como elementos individuais por índice.
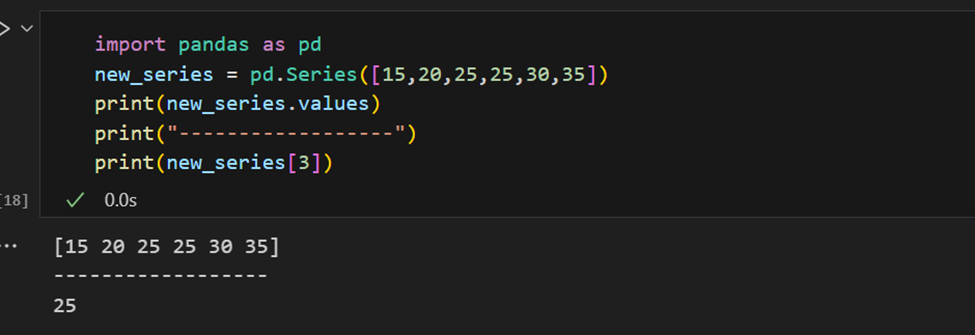
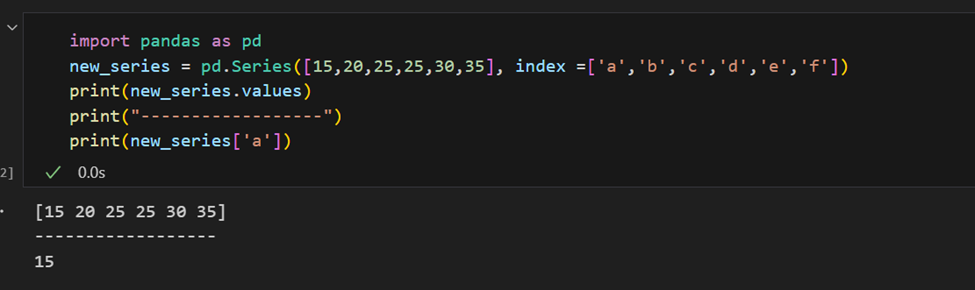
O índice também pode ser fornecido manualmente.
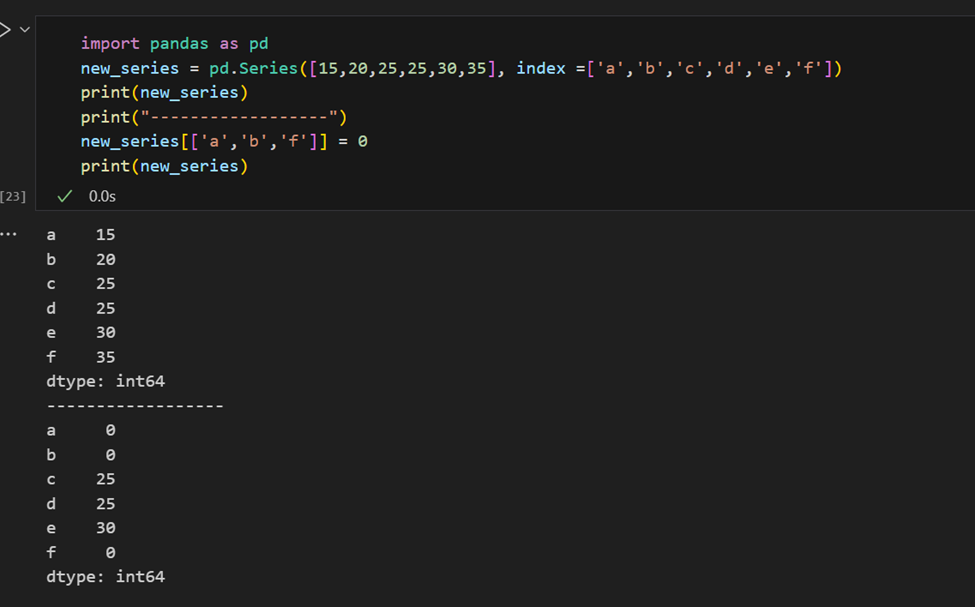
É fácil recuperar vários elementos de uma série pelos seus índices ou fazer atribuições em grupo.
DataFrames do Pandas
Um DataFrame é uma tabela com linhas e colunas. Cada coluna em um data frame é um objeto de série. As linhas consistem em elementos dentro de séries. DataFrames do Pandas oferecem uma ampla gama de operações para manipulação e análise de dados. Aqui está uma lista de algumas operações comuns:
Operações Básicas
Criando DataFrames
- A partir de um dicionário:
pd.DataFrame({'col1': [1, 2], 'col2': [3, 4]}) - A partir de um arquivo CSV:
pd.read_csv('data.csv') - A partir de um arquivo Excel:
pd.read_excel('data.xlsx')
Acessando Dados
- Selecionando colunas:
df['col1'] - Selecionando linhas:
df.loc[0] (pelo rótulo do índice), df.iloc[0](pela posição do índice) - Fatiando:
df [0:2] (primeiras duas linhas), df[['col1', 'col2']](múltiplas colunas)
Adicionando e Removendo Colunas/Linhas
- Adicionando uma coluna:
df['nova_col'] = - Removendo uma coluna:
df.drop('col1', axis=1) - Adicionando uma linha:
df.append({'col1': 7, 'col2': 8}, ignore_index=True) - Removendo uma linha:
df.drop(0)
Filtrando Dados
- Usando condições booleanas:
df [df['col1'] > 2]
Operações Matemáticas
- Operações aritméticas:
df['col1'] + df['col2'],df * 2, etc. - Funções de Agregação:
df.sum(),df.mean(),df.max(),df.min(), etc. - Aplicando funções personalizadas:
df.apply(lambda x: x**2)
Tratando Dados Ausentes
- Verificando valores ausentes:
df.isnull() - Removendo valores ausentes:
df.dropna() - Preenchendo valores ausentes:
df.fillna(0)
Unindo e Juntando DataFrames
- Unindo:
pd.merge(df1, df2, on='key_column') - Juntando:
df1.join(df2, on='key_column')
Agrupando e Agregando
- Agrupando:
df.groupby('col1') - Agregando:
df.groupby('col1').mean()
Operações de Séries Temporais
- Reamostragem:
df.resample('D').sum()(reduzir para frequência diária) - Deslocamento Temporal:
df.shift(1)(deslocar dados por um período)
Visualização de Dados
Plotagem: df.plot() (gráfico de linha), df.hist() (histograma), etc.
Exemplos Complexos do Pandas
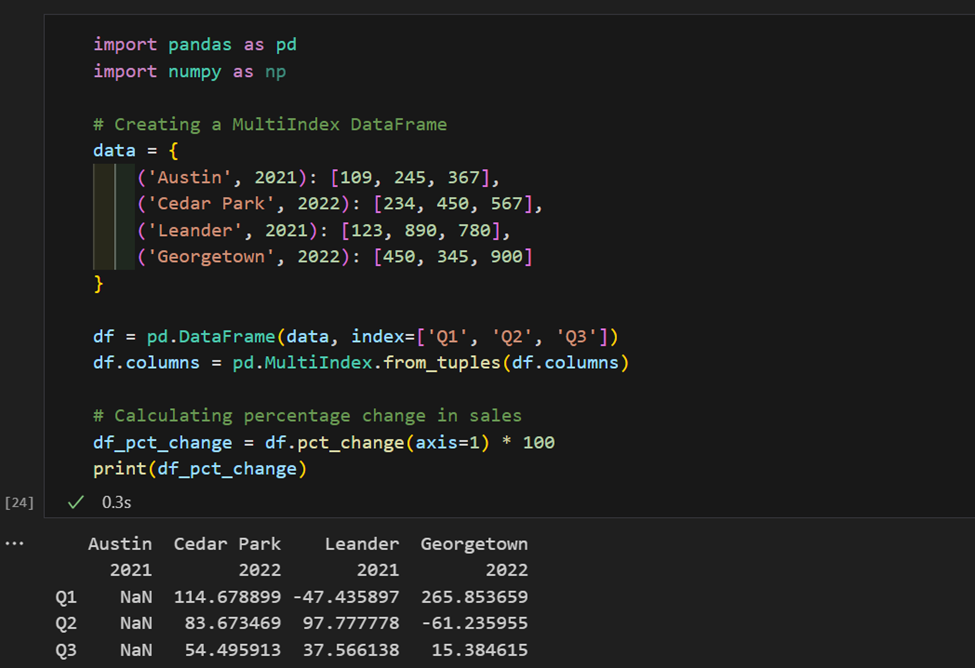
1. Aqui temos dados de vendas indexados por região e ano. Agora, aqui calculamos a variação percentual nas vendas por região.
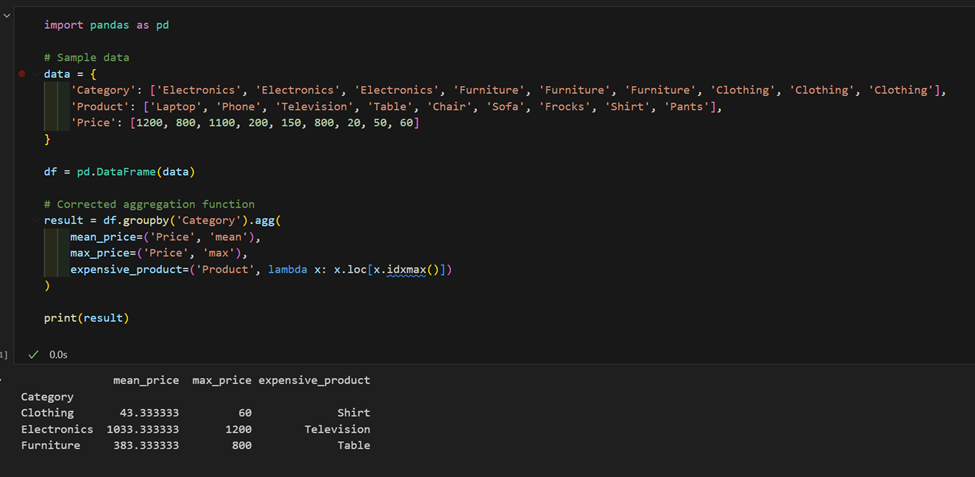
2. Temos um conjunto de dados com produtos e preços, calcule o preço médio por categoria e encontre o produto mais caro em cada uma.
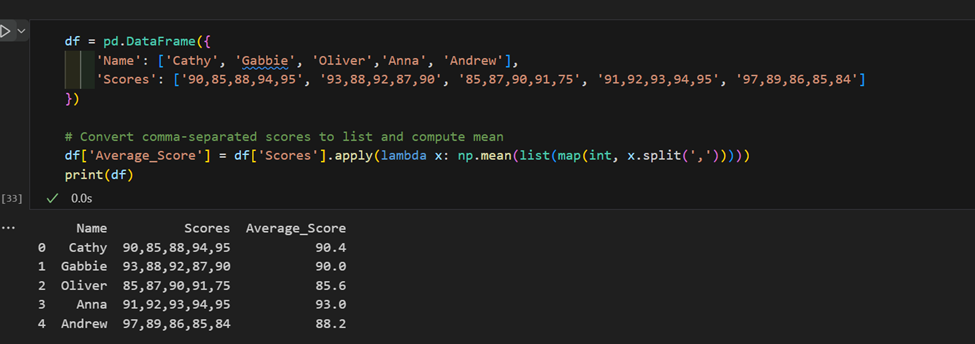
3. Uso complexo do “apply”:
Conclusão
Essas duas bibliotecas, NumPy e Pandas, são amplamente utilizadas em aplicações da vida real, como BFSI (análise financeira), computação científica, IA e ML e processamento de big data. Essas duas bibliotecas desempenham um papel crucial na tomada de decisões orientada por dados, desde a análise de tendências críticas do mercado de ações até a gestão de dados empresariais de ERP em larga escala.
Para iniciantes, o próximo passo é praticar o uso de NumPy e Pandas trabalhando em projetos pequenos, explorando conjuntos de dados e aplicando suas funções em cenários do mundo real. É possível baixar dados de código aberto do GitHub sobre dados financeiros, imobiliários ou de negócios de manufatura em geral. Com esses dados de origem e essas bibliotecas, é possível criar uma história cativante ou uma análise empírica. A experiência prática ajudará a solidificar conceitos e preparar os aprendizes para tarefas mais avançadas em ciência de dados.
Em conclusão, tanto NumPy quanto Pandas são duas bibliotecas Python essenciais para manipulação e análise de dados. O NumPy oferece suporte poderoso para cálculos numéricos com suas operações eficientes em arrays, enquanto o Pandas se baseia no NumPy para oferecer estruturas de dados intrínsecas e intuitivas como Series e DataFrame para lidar com dados estruturados.
Source:
https://dzone.com/articles/python-libraries-introduction-numpy-pandas