













In der Python-Programmierung heben sich NumPy und Pandas als zwei der leistungsstärksten Bibliotheken für numerische Berechnungen und Datenmanipulation hervor.
NumPy: Die Grundlage für numerische Berechnungen
NumPy (Numerical Python) bietet Unterstützung für mehrdimensionale Arrays und eine Vielzahl mathematischer Funktionen, was es für wissenschaftliche Berechnungen unverzichtbar macht.
- NumPy ist das grundlegendste Paket für numerische Berechnungen in Python.
- Einer der Gründe, warum NumPy für numerische Berechnungen so wichtig ist, liegt darin, dass es für die Effizienz mit großen Datenarrays konzipiert ist. Die Gründe hierfür sind:
- Es speichert Daten intern in einem kontinuierlichen Speicherblock, unabhängig von anderen in Python eingebauten Objekten.
- Es führt komplexe Berechnungen an gesamten Arrays ohne die Notwendigkeit von „for“-Schleifen durch.
- Das
ndarrayist ein effizientes multidimensionales Array, das schnelle array-orientierte arithmetische Operationen und flexible Broadcasting-Fähigkeiten bietet. - Das NumPy
ndarray-Objekt ist ein schneller und flexibler Container für große Datensätze in Python. - Arrays ermöglichen es Ihnen, mehrere Elemente desselben Datentyps zu speichern. Es sind die Funktionen rund um das Array-Objekt, die NumPy so bequem für mathematische Berechnungen und Datenumformungen machen.
Operationen in NumPy
Array erstellen:

Array umformen:

Schneiden und Indizieren:

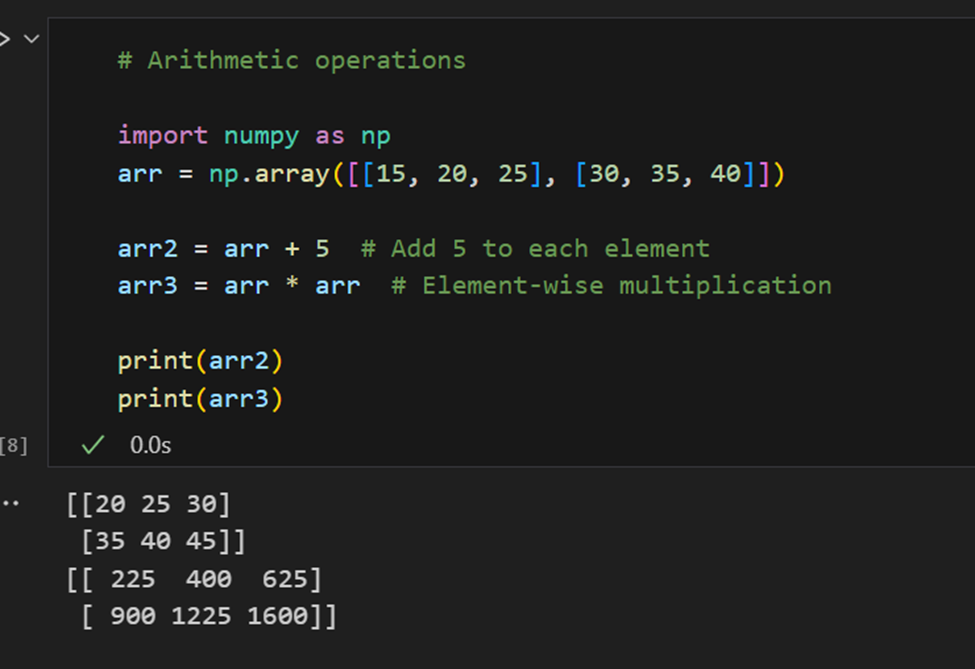
Arithmetische Operationen:
Lineare Algebra:

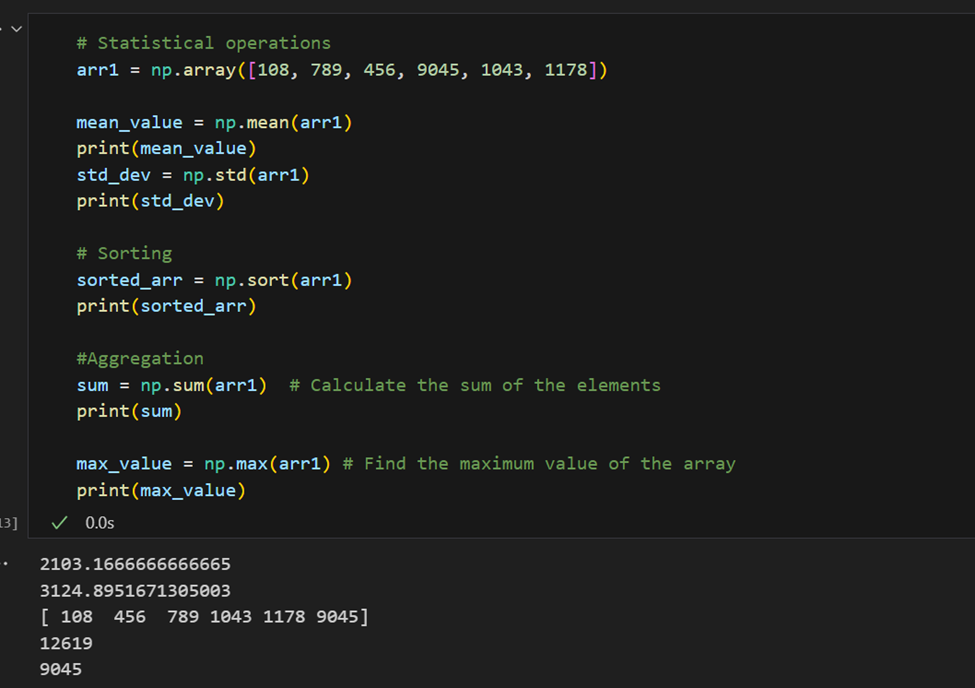
Statistische Operationen:
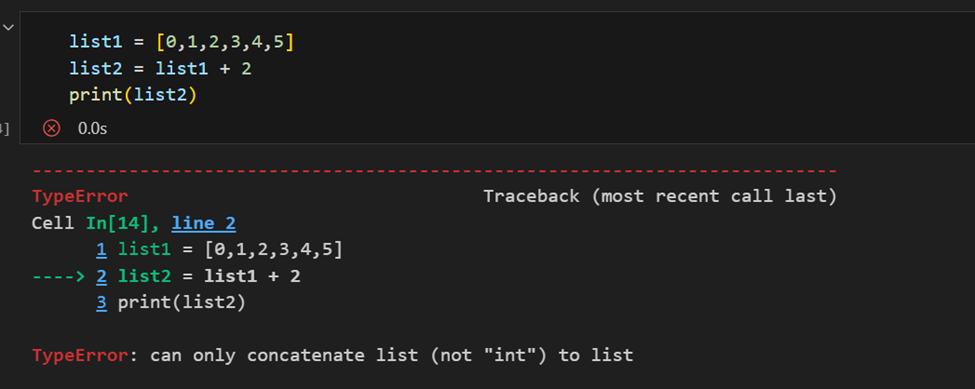
Unterschied zwischen NumPy-Array und Python-Liste
Der wesentliche Unterschied zwischen einem Array und einer Liste besteht darin, dass Arrays für vektorisierte Operationen ausgelegt sind, während eine Python-Liste es nicht ist. Das bedeutet, wenn Sie eine Funktion anwenden, wird sie auf jedes Element im Array angewendet, anstatt auf das gesamte Array-Objekt.
Pandas
Pandas sticht hervor als eine der leistungsstärksten Bibliotheken für numerische Berechnungen und Datenmanipulation, die für die Bereiche künstliche Intelligenz und maschinelles Lernen entscheidend ist.
Pandas ist wie NumPy eine der beliebtesten Python-Bibliotheken. Es handelt sich um eine Hochsprachabstraktion über die Niedrigsprache NumPy, die in reinem C geschrieben ist. Pandas bietet leistungsstarke, benutzerfreundliche Datenstrukturen und Datenanalysetools. Pandas verwendet zwei Hauptstrukturen: DataFrames und Series.
Indizes in Pandas Series
Eine Pandas Series ähnelt einer Liste, unterscheidet sich jedoch darin, dass einer Series jedem Element ein Label zuordnet. Dies macht es ähnlich wie ein Wörterbuch. Wenn ein Index nicht explizit vom Benutzer angegeben wird, erstellt Pandas einen RangeIndex von 0 bis N-1. Jedes Series-Objekt hat auch einen Datentyp.
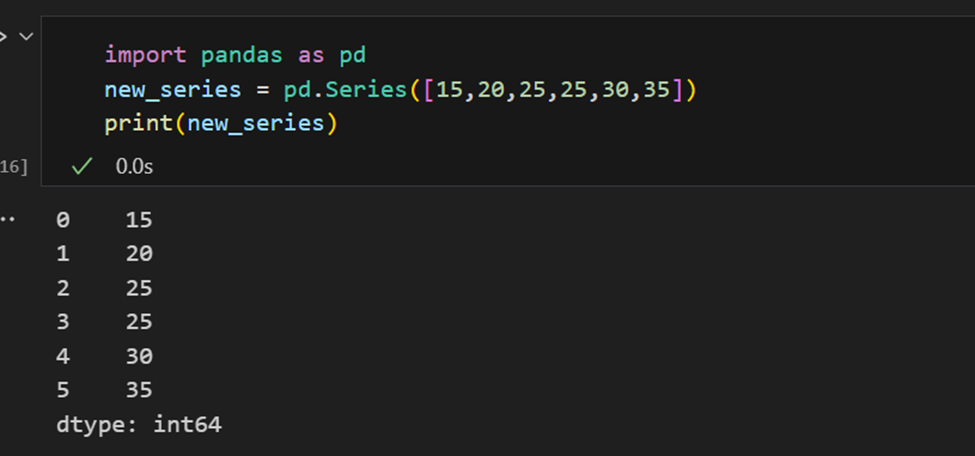
Eine Pandas-Serie bietet Möglichkeiten, alle Werte in der Serie sowie einzelne Elemente nach Index zu extrahieren.
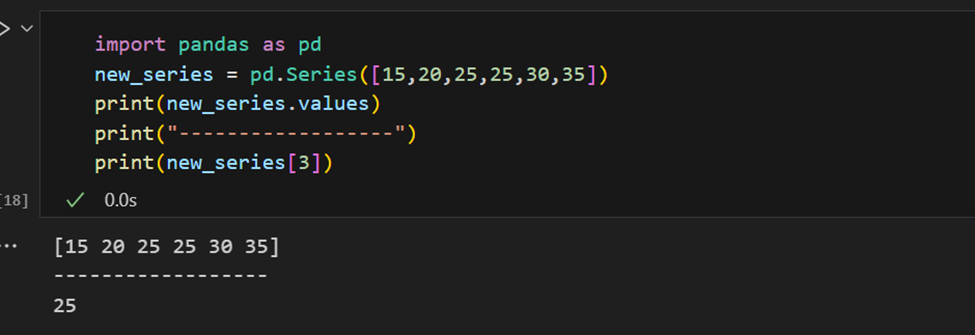
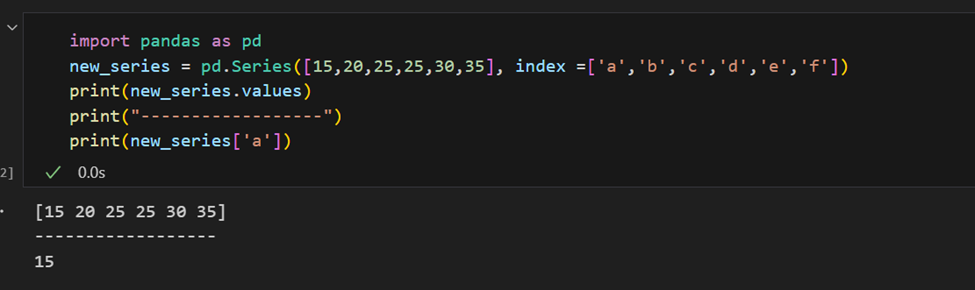
Der Index kann auch manuell angegeben werden.
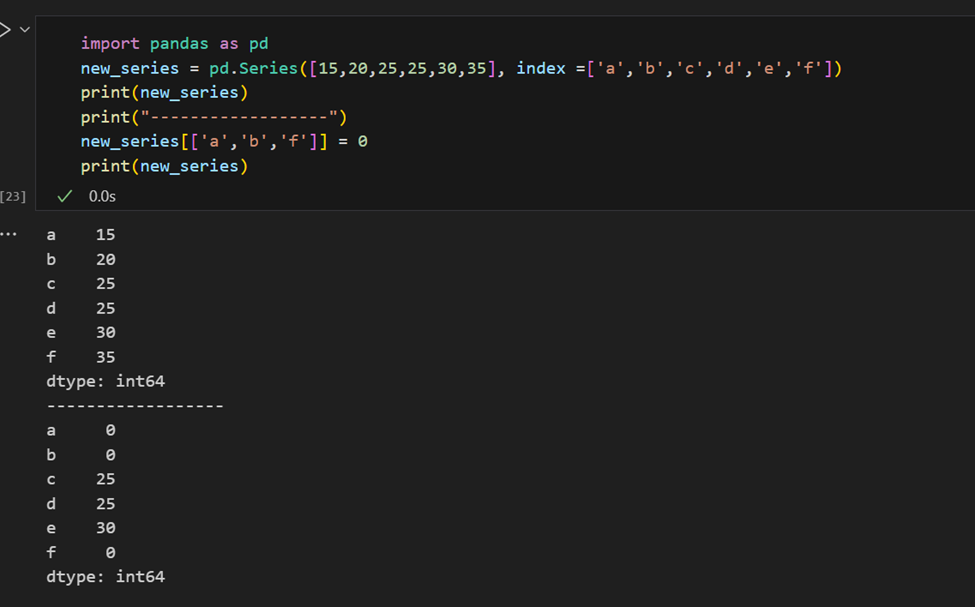
Es ist einfach, mehrere Elemente einer Serie nach ihren Indizes abzurufen oder Gruppenzuweisungen zu erstellen.
Pandas DataFrames
Ein DataFrame ist eine Tabelle mit Zeilen und Spalten. Jede Spalte in einem DataFrame ist ein Series-Objekt. Zeilen bestehen aus Elementen innerhalb von Serien. Pandas DataFrames bieten eine Vielzahl von Operationen zur Datenmanipulation und -analyse. Hier ist eine Übersicht über einige gängige Operationen:
Grundlegende Operationen
Erstellen von DataFrames
- Aus einem Wörterbuch:
pd.DataFrame({'col1': [1, 2], 'col2': [3, 4]}) - Aus einer CSV-Datei:
pd.read_csv('data.csv') - Aus einer Excel-Datei:
pd.read_excel('data.xlsx')
Zugriff auf Daten
- Auswählen von Spalten:
df['col1'] - Auswählen von Zeilen:
df.loc[0] (nach Indexbezeichnung), df.iloc[0](nach Indexposition) - Slicing:
df [0:2] (ersten zwei Zeilen), df[['coll', 'col2']](mehrere Spalten)
Hinzufügen und Entfernen von Spalten/Zeilen
- Hinzufügen einer Spalte:
df['new_col'] = - Entfernen einer Spalte:
df.drop('coll', axis=1) - Hinzufügen einer Zeile:
df.append({'col1': 7, 'col2': 8}, ignore_index=True) - Entfernen einer Zeile:
df.drop(0)
Daten filtern
- Verwendung von Booleschen Bedingungen:
df [df['col1'] > 2]
Mathematische Operationen
- Arithmetische Operationen:
df['col1'] + df['col2'],df * 2, usw. - Aggregationsfunktionen:
df.sum(),df.mean(),df.max(),df.min(), usw. - Anwendung benutzerdefinierter Funktionen:
df.apply(lambda x: x**2)
Umgang mit fehlenden Daten
- Überprüfen auf fehlende Werte:
df.isnull() - Fehlende Werte entfernen:
df.dropna() - Fehlende Werte auffüllen:
df.fillna(0)
Zusammenführen und Verknüpfen von DataFrames
- Zusammenführen:
pd.merge(df1, df2, on='key_column') - Verknüpfen:
df1.join(df2, on='key_column')
Gruppieren und Aggregieren
- Gruppieren:
df.groupby('col1') - Aggregieren:
df.groupby('col1').mean()
Zeitreihenoperationen
- Resampling:
df.resample('D').sum()(auf tägliche Frequenz herunterstufen) - Zeitverschiebung:
df.shift(1)(Daten um einen Zeitraum verschieben)
Datenvisualisierung
Plotten: df.plot() (Liniendiagramm), df.hist() (Histogramm), usw.
Komplexe Pandas-Beispiele
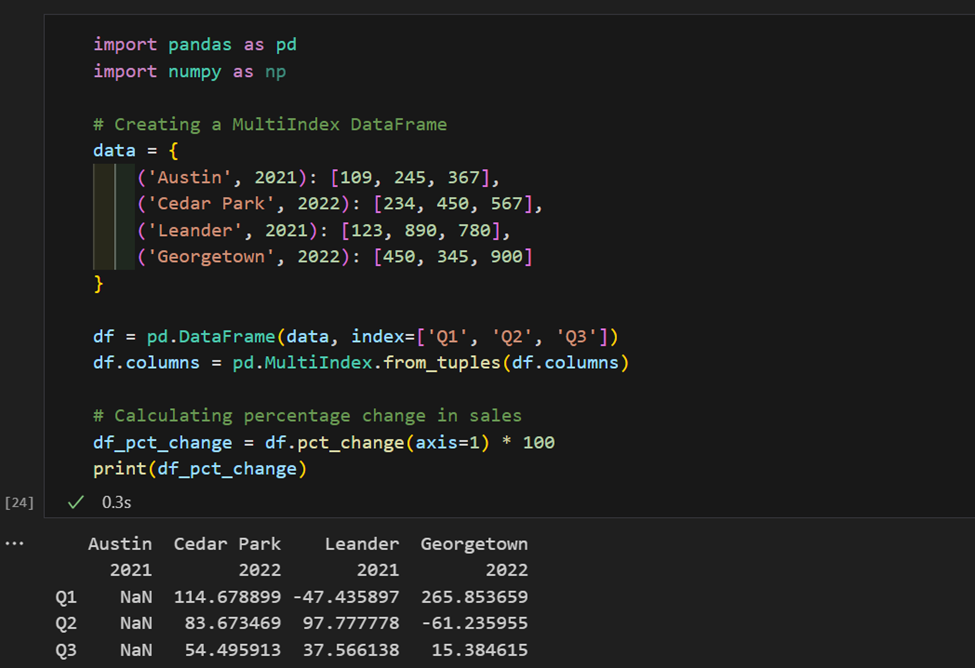
1. Hier haben wir Verkaufsdaten nach Region und Jahr indiziert. Jetzt berechnen wir die prozentuale Veränderung der Verkäufe pro Region.
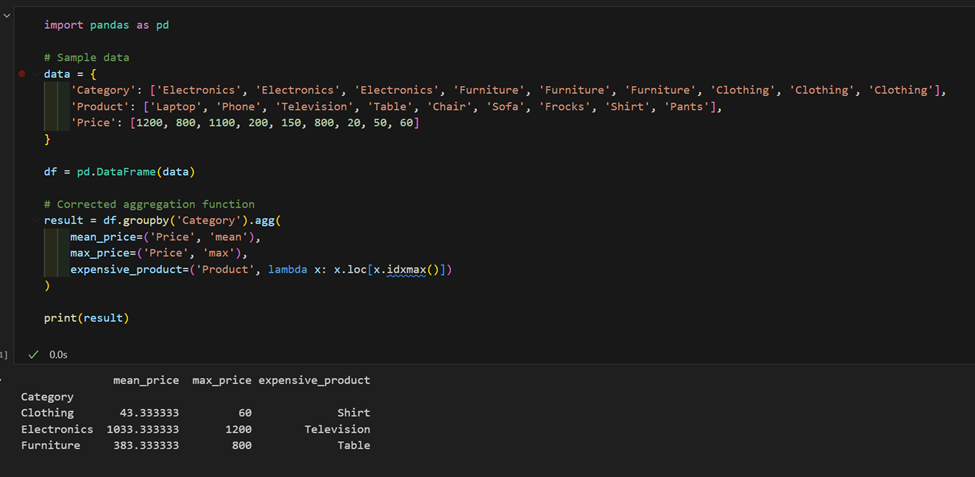
2. Wir haben einen Datensatz mit Produkten und Preisen. Berechnen Sie den Durchschnittspreis pro Kategorie und finden Sie das teuerste Produkt in jeder Kategorie.
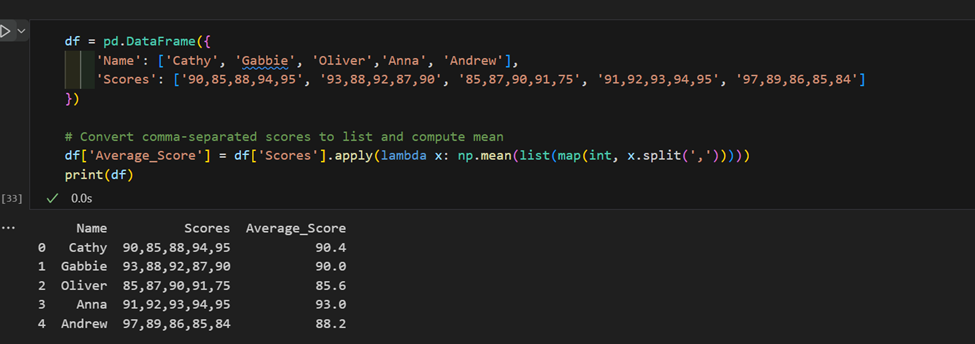
3. Komplexer Gebrauch von „apply“:
Schlussfolgerung
Diese beiden Bibliotheken, NumPy und Pandas, werden in der Praxis weit verbreitet eingesetzt, z. B. in BFSI (Finanzanalyse), wissenschaftlicher Berechnung, KI und maschinellem Lernen sowie der Verarbeitung großer Datenmengen. Diese beiden Bibliotheken spielen eine entscheidende Rolle bei datengesteuerter Entscheidungsfindung, angefangen von der Analyse wichtiger Trends auf dem Aktienmarkt bis hin zur Verwaltung von umfangreichen ERP-Unternehmensdaten.
Für Anfänger besteht der nächste Schritt darin, die Verwendung von NumPy und Pandas zu üben, indem sie an kleinen Projekten arbeiten, Datensätze erkunden und deren Funktionen in realen Szenarien anwenden. Man kann Open-Source-Daten von GitHub zu Finanzen, Immobilien oder allgemeinen Produktionsdaten herunterladen. Mit diesen Datenquellen und diesen Bibliotheken kann man eine überzeugende Geschichte oder empirische Analyse erstellen. Praktische Erfahrung wird dazu beitragen, Konzepte zu festigen und Lernende auf anspruchsvollere Aufgaben im Bereich der Datenwissenschaft vorzubereiten.
Zusammenfassend sind sowohl NumPy als auch Pandas zwei unverzichtbare Python-Bibliotheken für die Datenmanipulation und -analyse. NumPy bietet leistungsstarke Unterstützung für numerische Berechnungen mit seinen effizienten Array-Operationen, während Pandas auf NumPy aufbaut und intrinsische und intuitive Datenstrukturen wie Series und DataFrame für die Verarbeitung strukturierter Daten bietet.
Source:
https://dzone.com/articles/python-libraries-introduction-numpy-pandas