













为SOM设置环境
在构建自组织映射(SOM)之前,我们需要准备好环境和必要的软件包。
安装Python库
我们需要这些软件包:
- MiniSom是一个基于NumPy的Python工具,用于创建和训练SOM。
- NumPy用于访问数学函数,例如分割数组、获取唯一值等。
matplotlib用于绘制各种图形和图表,以可视化数据。- 来自
sklearn的datasets包用于导入将要应用SOM的数据集。 - 来自
sklearn的MinMaxScaler包对数据集进行归一化。
以下代码片段导入这些包:
from minisom import MiniSom import numpy as np import matplotlib.pyplot as plt from sklearn import datasets from sklearn.preprocessing import MinMaxScaler
准备数据集
在本教程中,我们使用 MiniSom 构建一个自组织映射(SOM),并在 经典 IRIS 数据集 上进行训练。该数据集由 3 类鸢尾花组成。每个类别有 50 个实例。为了准备数据,我们按照以下步骤进行:
- 从
sklearn导入鸢尾花数据集, - 提取数据向量和目标标量。
- 对数据向量进行归一化。在本教程中,我们使用 scikit-learn中的MinMaxScaler。
- 为三类鸢尾花声明一组标签。
以下代码实现了这些步骤:
dataset_iris = datasets.load_iris() data_iris = dataset_iris.data target_iris = dataset_iris.target data_iris_normalized = MinMaxScaler().fit_transform(data_iris) labels_iris = {1:'1', 2:'2', 3:'3'} data = data_iris_normalized target = target_iris
在Python中实现自组织映射(SOM)
要在Python中实现SOM,我们在对数据集进行训练之前定义并初始化网格。然后,我们可以可视化训练后的神经元和聚类数据集。
定义SOM网格
如前所述,SOM是一个神经元的网格。使用MiniSom,我们可以创建二维网格。网格的X和Y维度是每个轴上的神经元数量。要定义SOM网格,我们还需要指定:
- 网格的X和Y维度
- 输入变量的数量 – 这是数据行的数量。
将这些参数声明为Python常量:
SOM_X_AXIS_NODES = 8 SOM_Y_AXIS_NODES = 8 SOM_N_VARIABLES = data.shape[1]
下面的示例代码展示了如何使用MiniSom声明网格:
som = MiniSom(SOM_X_AXIS_NODES, SOM_Y_AXIS_NODES, SOM_N_VARIABLES)
前两个参数是X轴和Y轴上的神经元数量,第三个参数是变量的数量。
我们在创建自组织映射(SOM)网格时声明其他参数和超参数。我们将在后面的教程中解释这些。现在,请按照下面的方式声明这些参数:
ALPHA = 0.5 DECAY_FUNC = 'linear_decay_to_zero' SIGMA0 = 1.5 SIGMA_DECAY_FUNC = 'linear_decay_to_one' NEIGHBORHOOD_FUNC = 'triangle' DISTANCE_FUNC = 'euclidean' TOPOLOGY = 'rectangular' RANDOM_SEED = 123
使用这些参数创建SOM:
som = MiniSom( SOM_X_AXIS_NODES, SOM_Y_AXIS_NODES, SOM_N_VARIABLES, sigma=SIGMA0, learning_rate=ALPHA, neighborhood_function=NEIGHBORHOOD_FUNC, activation_distance=DISTANCE_FUNC, topology=TOPOLOGY, sigma_decay_function = SIGMA_DECAY_FUNC, decay_function = DECAY_FUNC, random_seed=RANDOM_SEED, )
初始化神经元
上述命令为所有神经元创建了具有随机权重的SOM。用从数据中提取的权重(而不是随机数)初始化神经元可以使训练过程更高效。
在使用MiniSom创建自组织映射(SOM)时,有两种基于数据初始化神经元权重的方法:
- 随机初始化: 神经元的初始权重是从输入数据中随机抽取的。我们通过将
.random_weights_init()函数应用于自组织映射(SOM)来实现这一点。 - 主成分分析初始化: 主成分分析(PCA)初始化使用输入数据的 主成分 来初始化权重。神经元的初始权重跨越前两个主成分。这通常会导致更快的收敛。
在本指南中,我们使用 PCA 初始化。要对 SOM 权重应用 PCA 初始化,请使用 .pca_weights_init() 函数,如下所示:
som.pca_weights_init(data)
训练 SOM
训练过程更新 SOM 权重,以最小化神经元与数据点之间的距离。
下面,我们解释迭代训练过程:
- 初始化:所有神经元的权重向量被初始化,通常使用随机值。也可以通过对输入数据分布进行采样来初始化权重。
- 输入选择: 从训练数据集中(随机)选择一个输入向量。
- 最佳匹配单元识别: 权重向量与输入向量最接近的神经元被识别为最佳匹配单元(BMU)。
- 邻域更新: BMU及其相邻神经元更新它们的权重向量。学习率和邻域函数决定了哪些神经元被更新以及更新的幅度。在迭代步骤t中,给定输入向量x,神经元i的权重向量为wi,学习率(t),以及邻域函数hbi(该函数量化了给定BMU神经元b时神经元i的更新程度),神经元i的权重更新公式表示为:

- 学习率和邻域半径的衰减率: 学习率和邻域半径随着时间的推移而减少。在早期迭代中,训练过程对较大邻域进行较大的调整。后期迭代则通过对相邻神经元的权重进行较小的变化来微调权重。这使得映射能够稳定和收敛。
为了训练SOM,我们将输入数据呈现给模型。我们可以选择以下两种方法之一:
- 从输入数据中随机抽取样本。
.train_random()函数实现了这种技术。 - 顺序遍历输入数据中的向量。这是通过使用
.train_batch()函数完成的。
这些函数接受输入数据和迭代次数作为参数。在本指南中,我们使用.train_random() 函数。将迭代次数声明为常量并传递给训练函数:
N_ITERATIONS = 5000 som.train_random(data, N_ITERATIONS, verbose=True)
执行脚本并完成训练后,将显示带有量化误差的消息:
quantization error: 0.05357240680504421
量化误差表示在自组织映射(SOM)对数据进行量化(降低维度)时丢失的信息量。较大的量化误差表示神经元与数据点之间的距离较大。这也意味着聚类的可靠性较低。
可视化SOM神经元
我们现在有一个训练好的SOM模型。为了可视化它,我们使用距离图(也称为 U矩阵)。距离图将SOM的神经元显示为一个单元格网格。每个单元格的颜色代表它与邻近神经元的距离。
距离图是一个与SOM具有相同维度的网格。距离图中的每个单元格是一个神经元与其邻居之间(欧几里得)距离的归一化总和。
访问 SOM 距离图,使用 .distance_map() 函数。生成 U-矩阵的步骤如下:
- 使用
pyplot创建一个与 SOM 尺寸相同的图形。在这个例子中,尺寸为 8×8。 - 使用 matplotlib 绘制距离图,使用
.pcolor()函数。在这个例子中,我们使用gist_yarg作为颜色方案。 - 显示
colorbar,一个将不同颜色映射到不同标量值的索引。在这种情况下,由于距离已归一化,标量距离值范围从0到1。
下面的代码实现了这些步骤:
# 创建网格 plt.figure(figsize=(8, 8)) # 绘制距离图 plt.pcolor(som.distance_map().T, cmap='gist_yarg') # 显示颜色条 plt.colorbar() plt.show()
在这个例子中,U矩阵使用单调颜色方案。可以通过以下指导原则来理解:
- 较浅的色调表示相距较近的神经元,而较深的色调表示离其他神经元较远的神经元。
- 较浅色调的组可以被解释为簇。簇之间的深色节点可以被解释为簇之间的边界。
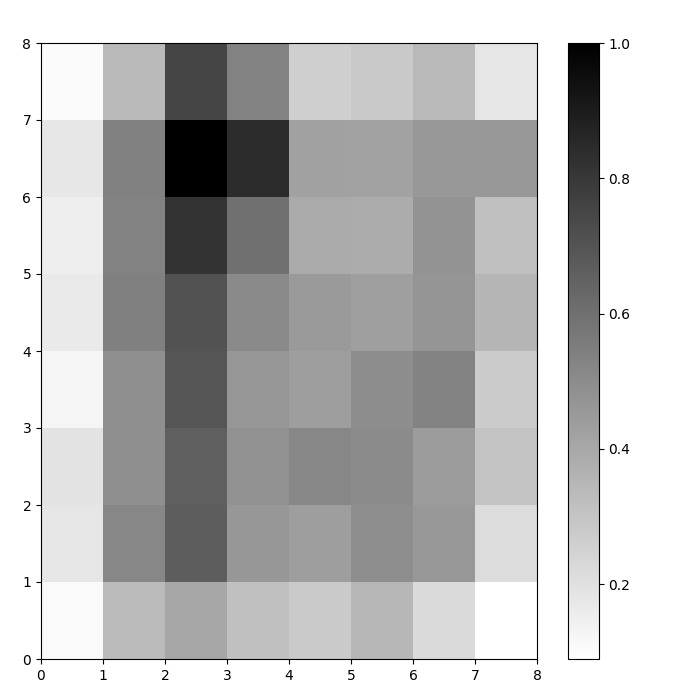
图1:在鸢尾花数据集上训练的自组织映射(SOM)的U矩阵(作者提供的图片)
评估SOM聚类结果
前面的图形直观地展示了SOM的神经元。在本节中,我们将展示如何可视化SOM如何对数据进行聚类。
识别簇
我们在上述U矩阵上叠加标记,以表示每个单元(神经元)代表的鸢尾花植物的类别。为此:
- 如前所述,使用
pyplot创建一个 8×8 图形 ,绘制距离图,并显示颜色条。 - 为三种 matplotlib 标记 指定一个数组,每种用于一种鸢尾花类别。
- 为三种 matplotlib 颜色代码 指定一个数组,每种用于 一种鸢尾花类别。
- 对每个数据点迭代绘制获胜神经元:
- 使用
.winner(函数确定每个数据点的获胜神经元(坐标)。 - 在网格上绘制每个获胜神经元的位置,位于每个单元格的中间。
w[0]和w[1]分别给出神经元的X和Y坐标。每个坐标加0.5以便在单元格中间绘制。
下面的代码展示了如何做到这一点:
# 绘制距离图 plt.figure(figsize=(8, 8)) plt.pcolor(som.distance_map().T, cmap='gist_yarg') plt.colorbar() # 为每个类别创建标记和颜色 markers = ['o', 'x', '^'] colors = ['C0', 'C1', 'C2'] # 绘制每个数据点的获胜神经元 for count, datapoint in enumerate(data): # 获取获胜者 w = som.winner(datapoint) # 在样本数据点的获胜位置放置标记 plt.plot(w[0]+.5, w[1]+.5, markers[target[count]-1], markerfacecolor='None', markeredgecolor=colors[target[count]-1], markersize=12, markeredgewidth=2) plt.show()
结果图像如下所示:
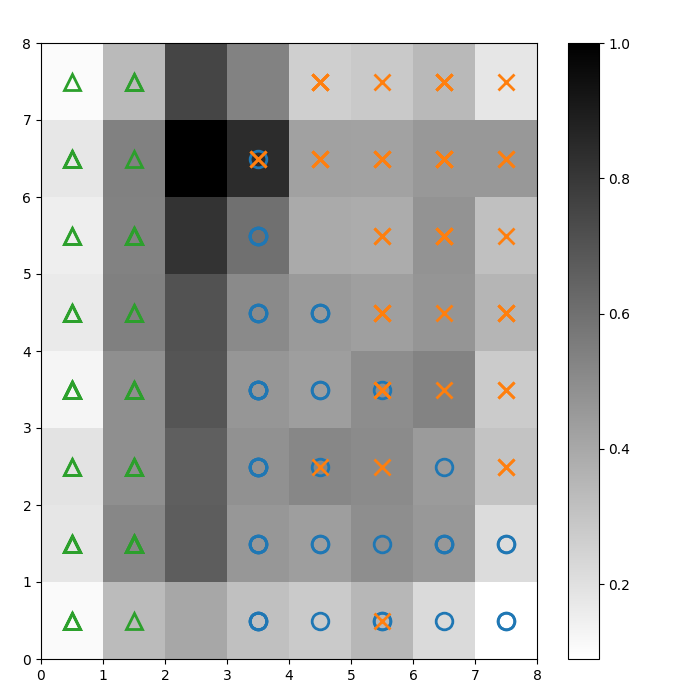
图2:带有类别标记的U矩阵(作者提供的图像)
根据 Iris数据集文档,“一个类别与另外两个类别是线性可分的;后者彼此之间不是线性可分的”。在上面的U矩阵中,这三个类别由三个标记表示 – 三角形、圆形和叉形。
请注意,蓝色圆形和橙色叉形之间没有明确的边界。此外,两个类别在许多神经元的同一位置重叠。这意味着该神经元与两个类别的距离相等。
可视化聚类结果
SOM是一种聚类模型。相似的数据点映射到同一个神经元。相同类别的数据点映射到一组相邻的神经元。我们将所有数据点绘制在SOM网格上,以更好地研究聚类行为。
以下步骤描述如何创建此散点图:
- 获取每个数据点的胜出神经元的X和Y坐标。
- 绘制距离图,如我们在图1中所做的。
- 使用
plt.scatter()绘制每个数据点的所有获胜神经元的散点图。为每个点添加随机偏移量,以避免同一单元内数据点之间的重叠。
我们在下面的代码中实现这些步骤:
# 获取每个数据点获胜神经元的X和Y坐标w_x, w_y = zip(*[som.winner(d) for d in data]) w_x = np.array(w_x) w_y = np.array(w_y) # 绘制距离图 plt.figure(figsize=(8, 8)) plt.pcolor(som.distance_map().T, cmap='gist_yarg', alpha=.2) plt.colorbar() # 绘制每个数据点的所有获胜神经元的散点图 # 为每个点添加随机偏移量以避免重叠 for c in np.unique(target): idx_target = target==c plt.scatter(w_x[idx_target]+.5+(np.random.rand(np.sum(idx_target))-.5)*.8, w_y[idx_target]+.5+(np.random.rand(np.sum(idx_target))-.5)*.8, s=50, c=colors[c-1], label=labels_iris[c+1] ) plt.legend(loc='upper right') plt.grid() plt.show()
下图显示了输出的散点图:
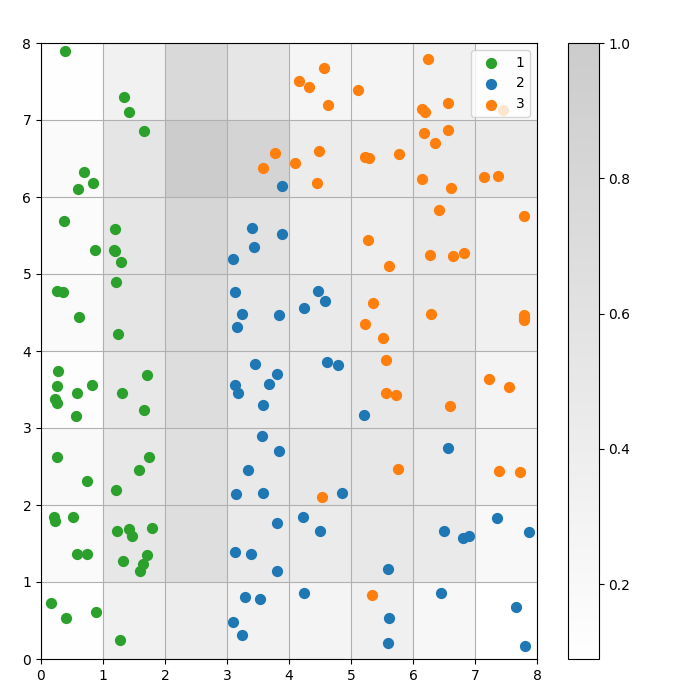 图3:单元内数据点的散点图(作者提供的图像)
图3:单元内数据点的散点图(作者提供的图像)
在上述散点图中,请注意:
- 一些单元包含蓝色和橙色的点。
- 绿色点与其余数据明显分开,但蓝色和橙色点并没有明显分开。
- 以上观察与Iris数据集中只有三个簇中的一个具有明显边界的事实相符。
- 在图1中,簇之间的深色节点(可以解释为簇之间的边界)与散点图中的空单元格相匹配。
您可以在这个DataLab笔记本中访问并运行完整的代码。
调整SOM模型
前面的部分展示了如何创建和训练SOM模型以及如何从视觉上研究结果。在本节中,我们讨论如何调整SOM模型的性能。
关键超参数调整
与任何机器学习模型一样,超参数对模型的性能有显著影响。
训练自组织映射(SOM)时,一些重要的超参数包括:
- 网格大小决定了地图的大小。网格大小为AxB的地图中神经元的数量为A*B。
- 学习率决定了每次迭代中权重的变化幅度。我们设置初始学习率,并根据衰减函数随着时间的推移逐渐减小。
- 衰减函数决定了每次后续迭代中学习率的减少程度。
- 该邻域函数是一个数学函数,用于指定哪些神经元被视为最佳匹配单元(BMU)的邻居。
- 该标准差指定了邻域函数的扩展。例如,具有高标准差的高斯邻域函数将拥有比具有较小标准差的相同函数更大的邻域。我们设置初始标准差,该标准差会根据sigma衰减函数随时间减少。
- 该sigma衰减函数控制每次迭代中标准差减少的程度。
- 训练迭代的次数决定了权重更新的次数。在每次训练迭代中,神经元权重更新一次。
- 距离函数是一种数学函数,用于计算神经元与数据点之间的距离。
- 拓扑决定了网格结构的布局。网格中的神经元可以排列成矩形或六边形模式。
在下一部分,我们将讨论设置这些超参数的指导原则。
超参数调优的影响
超参数值应根据模型和数据集进行决定。在某种程度上,确定这些值是一个试错的过程。在本节中,我们提供调优每个超参数的指南。在每个超参数旁边,我们提到(在括号中)在示例代码中使用的相应 Python 常量。
- 网格大小 (
SOM_X_AXIS_NODES和SOM_X_AXIS_NODES): 网格大小取决于数据集的大小。经验法则是,对于大小为 N的数据集,网格应该大致包含 5*sqrt(N) 个神经元。例如,如果数据集有150个样本,网格应该包含 5*sqrt(150) = 大约61个神经元。在本教程中,鸢尾花数据集有150行,我们使用一个8×8的网格。 - 初始学习率 (
ALPHA): 较高的学习率加快收敛速度,而较低的学习率则用于在早期迭代后进行更细致的调整。初始学习率应该足够大,以便快速适应,但又不能大到超过最佳权重值。在本文中,初始学习率为0.5。 - 初始标准差 (
SIGMA0): 它决定了邻域的初始大小或分布。较大的值考虑更多的全局模式。在这个例子中,我们使用的起始标准差为1.5。 - 对于衰减率(
DECAY_FUNC)和σ衰减率(SIGMA_DECAY_FUNC), 我们可以从三种类型的衰减函数中选择: - 反向衰减: 如果数据具有全局和局部模式,这个函数是合适的。在这种情况下,我们需要更长的广泛学习阶段,然后再专注于局部模式。
- 线性衰减: 适用于我们希望保持稳定和均匀的邻域大小或学习率降低的数据集。如果数据不需要太多微调,这种方法很有用。
- 渐近衰减: 如果数据复杂且维度较高,这个函数很有用。在这种情况下,最好花更多时间进行全局探索,然后再逐渐过渡到更细微的细节。
- 邻域函数 (
NEIGHBORHOOD_FUNC): 默认的邻域函数选择是高斯函数。下面将解释其他也使用的函数。 - 高斯(默认):这是一个钟形曲线。随着神经元与胜利神经元的距离增加,神经元的更新程度平滑地减少。它提供了平滑和连续的过渡,并保持数据的拓扑结构。由于其稳定和可预测的行为,它适用于大多数一般用途。
- 气泡: 该功能创建一个固定宽度的邻域。所有在该邻域内的神经元被同等更新,而在该邻域外的神经元则不被更新(针对给定的数据点)。它在计算上更便宜且更容易实现。对于较小的地图来说,它非常有用,因为锐利的邻域边界不会影响有效的聚类。
- 墨西哥帽: 它有一个中央的正区域,周围被负区域包围。靠近最佳匹配单元(BMU)的神经元被更新以更接近数据点,而更远的神经元则被更新以远离数据点。该技术增强了对比度并锐化了地图中的特征。由于它强调明显的聚类,因此在需要清晰分离聚类的模式识别任务中非常有效。
- 三角形: 此功能将邻域大小定义为三角形,以BMU(最佳匹配单元)具有最大的影响力。它随与BMU的距离线性下降。它用于聚类具有渐进过渡的特征或数据,例如图像、语音或时间序列数据,其中相邻的数据点预计具有相似的特征。
- 距离函数 (
DISTANCE_FUNC): 为了测量神经元和数据点之间的距离,我们可以选择4种方法: - 欧几里得距离(默认选择):当数据是连续时非常有用,我们想要测量直线距离。它适合大多数一般任务,尤其是在数据点均匀分布且空间相关时。
- 余弦距离:适合文本或高维稀疏数据,在这种情况下,向量之间的角度比大小更重要。它对于比较数据的方向性非常有用。
- 曼哈顿距离:当数据点在网格或晶格上时(例如,城市街区),这是理想选择。这比欧几里得距离对异常值的敏感性更低。
- 切比雪夫距离: 适用于可以朝任何方向移动的情况(例如,棋盘距离)。它适用于我们希望优先考虑最大轴差异的离散空间。
- 拓扑 (
TOPOLOGY): 在网格中,神经元可以以六边形或矩形结构排列: - 矩形(默认):每个神经元有4个直接邻居。当数据没有明确的空间关系时,这是正确的选择。它在计算上也更简单。
- 六边形:每个神经元有6个邻居。如果数据的空间关系更适合用六边形网格表示,这就是首选选项。这适用于圆形或角度数据分布。
- 训练迭代次数(
N_ITERATIONS):原则上,较长的训练时间会导致更低的错误率以及权重与输入数据更好的对齐。然而,模型的性能随着迭代次数的增加而趋于渐近。因此,在达到一定的迭代次数后,后续迭代带来的性能提升只有边际效应。确定正确的迭代次数需要一些实验。在本教程中,我们将模型训练5000次。
为了确定超参数的正确配置,我们建议在数据的较小子集上尝试各种选项。
结论
自组织映射是一种强大的工具,用于无监督学习。它们用于聚类、降维、异常检测和数据可视化。由于它们保留了高维数据的拓扑特性,并将其表示在低维网格上,SOM使得可视化和解释复杂数据集变得简单。
本教程讨论了SOM的基本原理,并展示了如何使用MiniSom Python库实现SOM。它还演示了如何直观地分析结果,并解释了用于训练SOM和微调其性能的重要超参数。
Source:
https://www.datacamp.com/tutorial/self-organizing-maps