













Configuration de l’environnement pour les SOM
Avant de construire le SOM, nous devons préparer l’environnement avec les packages nécessaires.
Installation des bibliothèques Python
Nous avons besoin de ces packages :
- MiniSom est un outil Python basé sur NumPy qui crée et entraîne des SOM.
- NumPy est utilisé pour accéder à des fonctions mathématiques telles que le découpage de tableaux, l’obtention de valeurs uniques, etc.
matplotlibest utilisé pour tracer divers graphiques et diagrammes afin de visualiser les données.- Le package
datasetsdesklearnest utilisé pour importer des ensembles de données sur lesquels appliquer le SOM. - Le package
MinMaxScalerdesklearnnormalise l’ensemble de données.
Le code suivant importe ces packages :
from minisom import MiniSom import numpy as np import matplotlib.pyplot as plt from sklearn import datasets from sklearn.preprocessing import MinMaxScaler
Préparation de l’ensemble de données
Dans ce tutoriel, nous utilisons MiniSom pour construire un SOM et ensuite l’entraîner sur le jeu de données IRIS. Ce jeu de données se compose de 3 classes de plantes iris. Chaque classe a 50 instances. Pour préparer les données, nous suivons ces étapes :
- Importer le jeu de données Iris depuis
sklearn, - Extraire les vecteurs de données et les scalaires cibles.
- Normalisez les vecteurs de données. Dans ce tutoriel, nous utilisons le MinMaxScaler de scikit-learn.
- Déclarez un ensemble d’étiquettes pour chacune des trois classes de plantes Iris.
Le code suivant implémente ces étapes :
dataset_iris = datasets.load_iris() data_iris = dataset_iris.data target_iris = dataset_iris.target data_iris_normalized = MinMaxScaler().fit_transform(data_iris) labels_iris = {1:'1', 2:'2', 3:'3'} data = data_iris_normalized target = target_iris
Implémentation des cartes auto-organisatrices (SOM) en Python
Pour implémenter un SOM en Python, nous définissons et initialisons la grille avant de l’entraîner sur le jeu de données. Nous pouvons ensuite visualiser les neurones entraînés et le jeu de données clusterisé.
Définir la grille SOM
Comme expliqué précédemment, un SOM est une grille de neurones. En utilisant MiniSom, nous pouvons créer des grilles en 2 dimensions. Les dimensions X et Y de la grille correspondent au nombre de neurones le long de chaque axe. Pour définir la grille SOM, nous devons également spécifier :
- Les dimensions X et Y de la grille
- Le nombre de variables d’entrée – c’est le nombre de lignes de données.
Déclarez ces paramètres en tant que constantes Python :
SOM_X_AXIS_NODES = 8 SOM_Y_AXIS_NODES = 8 SOM_N_VARIABLES = data.shape[1]
Le code d’exemple ci-dessous illustre comment déclarer la grille en utilisant MiniSom :
som = MiniSom(SOM_X_AXIS_NODES, SOM_Y_AXIS_NODES, SOM_N_VARIABLES)
Les deux premiers paramètres sont le nombre de neurones le long des axes X et Y, et le troisième paramètre est le nombre de variables.
Nous déclarons d’autres paramètres et hyperparamètres lors de la création de la grille SOM. Nous expliquerons cela plus tard dans le tutoriel. Pour l’instant, déclarez ces paramètres comme indiqué ci-dessous :
ALPHA = 0.5 DECAY_FUNC = 'linear_decay_to_zero' SIGMA0 = 1.5 SIGMA_DECAY_FUNC = 'linear_decay_to_one' NEIGHBORHOOD_FUNC = 'triangle' DISTANCE_FUNC = 'euclidean' TOPOLOGY = 'rectangular' RANDOM_SEED = 123
Créer un SOM en utilisant ces paramètres :
som = MiniSom( SOM_X_AXIS_NODES, SOM_Y_AXIS_NODES, SOM_N_VARIABLES, sigma=SIGMA0, learning_rate=ALPHA, neighborhood_function=NEIGHBORHOOD_FUNC, activation_distance=DISTANCE_FUNC, topology=TOPOLOGY, sigma_decay_function = SIGMA_DECAY_FUNC, decay_function = DECAY_FUNC, random_seed=RANDOM_SEED, )
Initialisation des neurones
La commande ci-dessus crée un SOM avec des poids aléatoires pour tous les neurones. Initialiser les neurones avec des poids tirés des données (au lieu de nombres aléatoires) peut rendre le processus d’entraînement plus efficace.
Lors de l’utilisation de MiniSom pour créer une carte auto-organisée (SOM), il existe deux façons d’initialiser les poids des neurones en fonction des données :
- Initialisation aléatoire : Les poids initiaux des neurones sont tirés aléatoirement des données d’entrée. Nous le faisons en appliquant la fonction
.random_weights_init()au SOM. - Initialisation PCA : L’initialisation par Analyse en Composantes Principales (PCA) utilise les composantes principales des données d’entrée pour initialiser les poids. Les poids initiaux des neurones couvrent les deux premières composantes principales. Cela conduit souvent à une convergence plus rapide.
Dans ce guide, nous utilisons l’initialisation PCA. Pour appliquer l’initialisation PCA sur les poids de SOM, utilisez la fonction .pca_weights_init() comme indiqué ci-dessous :
som.pca_weights_init(data)
Formation du SOM
Le processus de formation met à jour les poids du SOM pour minimiser la distance entre les neurones et les points de données.
Voici comment se déroule le processus de formation itératif :
- Initialisation : Les vecteurs de poids de tous les neurones sont initialisés, généralement avec des valeurs aléatoires. Il est également possible d’initialiser les poids en échantillonnant la distribution des données d’entrée.
- Sélection de l’entrée: Un vecteur d’entrée est sélectionné (au hasard) à partir de l’ensemble de données d’entraînement.
- Identification du BMU: Le neurone avec le vecteur de poids le plus proche du vecteur d’entrée est identifié comme le BMU.
- Mise à jour du voisinage : Le BMU et ses neurones voisins mettent à jour leurs vecteurs de poids. Le taux d’apprentissage et la fonction de voisinage décident quels neurones sont mis à jour et dans quelle mesure. À l’étape d’itération t, étant donné le vecteur d’entrée x, le vecteur de poids du neurone i est wi, le taux d’apprentissage (t), et la fonction de voisinage hbi (cette fonction quantifie l’étendue de la mise à jour pour le neurone i étant donné le neurone BMU b), la formule de mise à jour des poids pour le neurone i s’exprime comme suit :

- Taux de décroissance du taux d’apprentissage et du rayon de voisinage: À la fois le taux d’apprentissage et le rayon de voisinage diminuent au fil du temps. Dans les premières itérations, le processus d’entraînement effectue de plus grands ajustements sur un plus grand voisinage. Les itérations ultérieures aident à affiner les poids en apportant de plus petits changements aux poids des neurones adjacents. Cela permet à la carte de se stabiliser et de converger.
Pour entraîner le SOM, nous présentons le modèle avec les données d’entrée. Nous pouvons choisir l’une des deux approches pour le faire:
- Choisir des échantillons au hasard parmi les données d’entrée. La fonction
.train_random()met en œuvre cette technique. - Exécutez séquentiellement les vecteurs dans les données d’entrée. Cela se fait en utilisant la
.train_batch()fonction.
Ces fonctions acceptent les données d’entrée et le nombre d’itérations comme paramètres. Dans ce guide, nous utilisons la .train_random() fonction. Déclarez le nombre d’itérations comme une constante et passez-le à la fonction d’entraînement :
N_ITERATIONS = 5000 som.train_random(data, N_ITERATIONS, verbose=True)
Après avoir exécuté le script et terminé l’entraînement, un message avec l’erreur de quantification est affiché :
quantization error: 0.05357240680504421
L’erreur de quantification indique la quantité d’informations perdues lorsque le SOM quantifie (réduit la dimensionalité de) les données. Une grande erreur de quantification indique une plus grande distance entre les neurones et les points de données. Cela signifie également que le regroupement est moins fiable.
Visualisation des neurones SOM
Nous avons maintenant un modèle SOM entraîné. Pour le visualiser, nous utilisons une carte de distances (également connue sous le nom de U-matrice). La carte de distances affiche les neurones du SOM sous forme d’une grille de cellules. La couleur de chaque cellule représente sa distance par rapport aux neurones voisins.
La carte de distances est une grille ayant les mêmes dimensions que le SOM. Chaque cellule de la carte de distances est la somme normalisée des distances (euclidiennes) entre un neurone et ses voisins.
Accédez à la carte des distances SOM en utilisant la fonction .distance_map(). Pour générer la matrice U, nous suivons ces étapes :
- Utilisez
pyplotpour créer une figure ayant les mêmes dimensions que le SOM. Dans cet exemple, les dimensions sont 8×8. - Tracez la carte des distances en utilisant matplotlib avec la fonction
.pcolor(). Dans cet exemple, nous utilisonsgist_yargcomme schéma de couleurs. - Affichez la
colorbar, un index mappant différentes couleurs à différentes valeurs scalaires. Dans ce cas, étant donné que les distances sont normalisées, les valeurs de distance scalaire varient de 0 à 1.
Le code ci-dessous met en œuvre ces étapes :
# créer la grille plt.figure(figsize=(8, 8)) # tracer la carte des distances plt.pcolor(som.distance_map().T, cmap='gist_yarg') # montrer la barre de couleurs plt.colorbar() plt.show()
Dans cet exemple, la matrice U utilise un schéma de couleur monotone. Elle peut être comprise en suivant ces directives :
- Des teintes plus claires représentent des neurones étroitement espacés, et des teintes plus sombres représentent des neurones plus éloignés les uns des autres.
- Des groupes de teintes plus claires peuvent être interprétés comme des clusters. Des nœuds sombres entre les clusters peuvent être interprétés comme les frontières entre les clusters.
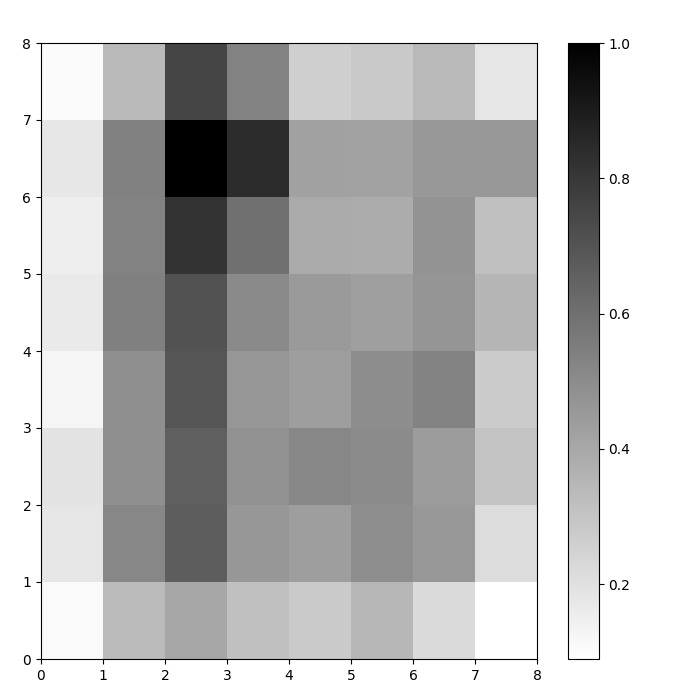
Figure 1 : U-matrice du SOM entraîné sur le jeu de données Iris (image par l’auteur)
Évaluation des résultats de clustering du SOM
La figure précédente a illustré graphiquement les neurones du SOM. Dans cette section, nous montrons comment visualiser comment le SOM a regroupé les données.
Identification des clusters
Nous superposons des marqueurs sur la U-matrice ci-dessus pour indiquer quelle classe de plante Iris chaque cellule (neurone) représente. Pour ce faire :
- Comme précédemment, créez une figure 8×8 en utilisant
pyplot, tracez la carte des distances et affichez la barre de couleur. - Spécifiez un tableau de trois marqueurs matplotlib, un pour chaque classe de plante Iris.
- Spécifiez un tableau de trois codes couleur matplotlib, un pour chaque classe de plante Iris.
- Tracez itérativement le neurone gagnant pour chaque point de données :
- Déterminez les (coordonnées du) neurone gagnant pour chaque point de données en utilisant la fonction
.winner(). - Tracez la position de chaque neurone gagnant au milieu de chaque cellule sur la grille.
w[0]etw[1]donnent les coordonnées X et Y du neurone, respectivement. Une valeur de 0,5 est ajoutée à chaque coordonnée pour le tracer au milieu de la cellule.
Le code ci-dessous montre comment faire cela :
# tracer la carte des distances plt.figure(figsize=(8, 8)) plt.pcolor(som.distance_map().T, cmap='gist_yarg') plt.colorbar() # créer les marqueurs et les couleurs pour chaque classe markers = ['o', 'x', '^'] colors = ['C0', 'C1', 'C2'] # tracer le neurone gagnant pour chaque point de données for count, datapoint in enumerate(data): # obtenir le gagnant w = som.winner(datapoint) # placer un marqueur sur la position gagnante pour le point de données échantillon plt.plot(w[0]+.5, w[1]+.5, markers[target[count]-1], markerfacecolor='None', markeredgecolor=colors[target[count]-1], markersize=12, markeredgewidth=2) plt.show()
L’image résultante est montrée ci-dessous :
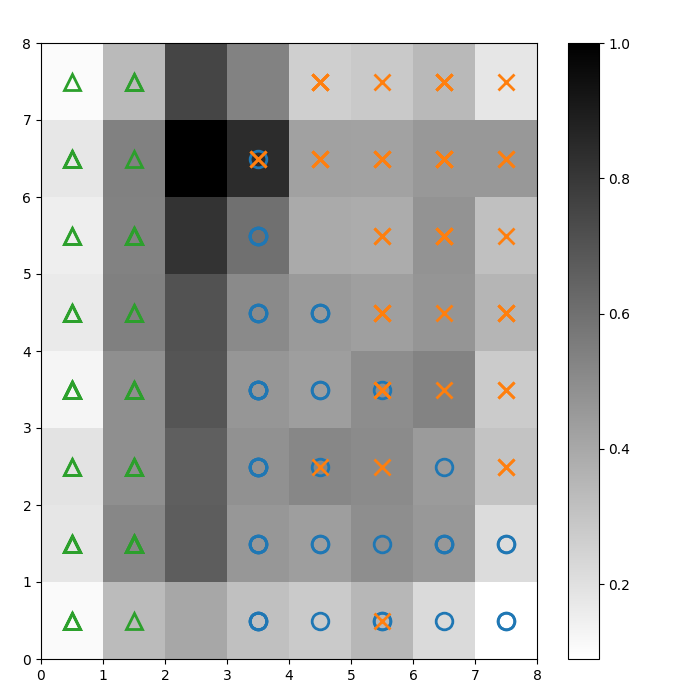
Figure 2 : U-matrice superposée avec des marqueurs de classes (image par l’auteur)
Basé sur la documentation du jeu de données Iris, “une classe est séparablement linéaire de l’autre 2 ; ces dernières ne sont pas séparablement linéaires l’une de l’autre”. Dans la U-matrice ci-dessus, ces trois classes sont représentées par trois marqueurs – triangle, cercle et croix.
Remarque : il n’y a pas de frontière claire entre les cercles bleus et les croix orange. En outre, deux classes sont superposées sur le même neurone dans de nombreuses cellules. Cela signifie que le neurone est équidistant des deux classes.
Visualisation du résultat du clustering
Un SOM est un modèle de clustering. Des points de données similaires se cartographient sur le même neurone. Les points de données de la même classe se cartographient sur un cluster de neurones voisins. Nous traçons tous les points de données sur la grille SOM pour mieux étudier le comportement de clustering.
Les étapes suivantes décrivent comment créer ce diagramme de dispersion :
- Obtenez les coordonnées X et Y du neurone gagnant pour chaque point de données.
- Tracez la carte des distances, comme nous l’avons fait pour la Figure 1.
- Utilisez
plt.scatter()pour créer un nuage de points de tous les neurones gagnants pour chaque point de données. Ajoutez un décalage aléatoire à chaque point pour éviter les chevauchements entre les points de données dans la même cellule.
Nous implémentons ces étapes dans le code ci-dessous :
# obtenir les coordonnées X et Y du neurone gagnant pour chaque point de donnéesw_x, w_y = zip(*[som.winner(d) pour d in data]) w_x = np.array(w_x) w_y = np.array(w_y) # tracer la carte de distance plt.figure(figsize=(8, 8)) plt.pcolor(som.distance_map().T, cmap='gist_yarg', alpha=.2) plt.colorbar() # faire un nuage de points de tous les neurones gagnants pour chaque point de données # ajouter un décalage aléatoire à chaque point pour éviter les chevauchements for c in np.unique(target): idx_target = target==c plt.scatter(w_x[idx_target]+.5+(np.random.rand(np.sum(idx_target))-.5)*.8, w_y[idx_target]+.5+(np.random.rand(np.sum(idx_target))-.5)*.8, s=50, c=colors[c-1], label=labels_iris[c+1] ) plt.legend(loc='upper right') plt.grid() plt.show()
Le graphique suivant montre le nuage de points de sortie :
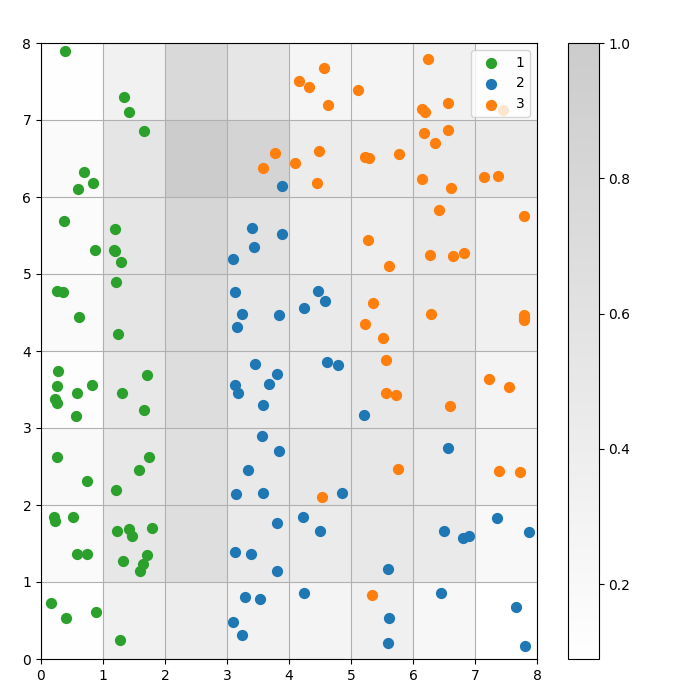 Figure 3 : Diagramme de dispersion des points de données dans les cellules (image par l’auteur)
Figure 3 : Diagramme de dispersion des points de données dans les cellules (image par l’auteur)
Dans le diagramme de dispersion ci-dessus, observez que :
- Certaines cellules contiennent à la fois des points bleus et des points oranges.
- Les points verts sont clairement séparés du reste des données, mais les points bleus et oranges ne sont pas séparés de manière nette.
- Les observations ci-dessus s’alignent avec le fait que seul l’un des trois clusters dans le jeu de données Iris a une frontière claire.
- Dans la Figure 1, les nœuds sombres entre les clusters (qui peuvent être interprétés comme les frontières entre les clusters) correspondent à des cellules vides dans le nuage de points.
Vous pouvez accéder et exécuter le code complet sur ce carnet DataLab.
Ajustement du modèle SOM
Les sections précédentes ont montré comment créer et entraîner un modèle SOM et comment étudier les résultats visuellement. Dans cette section, nous discutons de la façon d’ajuster la performance des modèles SOM.
Hyperparamètres clés à ajuster
Comme pour tout modèle d’apprentissage automatique, les hyperparamètres ont un impact considérable sur les performances du modèle.
Parmi les hyperparamètres importants dans l’entraînement des SOM, on trouve :
- La taille de la grille détermine la taille de la carte. Le nombre de neurones dans une carte avec une taille de grille de AxB est A*B.
- Le taux d’apprentissage détermine combien les poids sont modifiés à chaque itération. Nous définissons le taux d’apprentissage initial, et il diminue au fil du temps selon la fonction de décroissance.
- La fonction de décroissance détermine dans quelle mesure le taux d’apprentissage est diminué à chaque itération suivante.
- La fonction de voisinage est une fonction mathématique qui spécifie quelles neurones sont à considérer comme les voisins du BMU.
- La écart type spécifie la dispersion de la fonction de voisinage. Par exemple, une fonction de voisinage gaussienne avec un écart type élevé aura un voisinage plus large que la même fonction avec un écart type plus petit. Nous définissons l’écart type initial, qui diminue avec le temps selon la fonction de décroissance sigma.
- La fonction de décroissance sigma contrôle la réduction de l’écart type à chaque itération subséquente.
- Le nombre d’itérations d’entraînement décide combien de fois les poids sont mis à jour. À chaque itération d’entraînement, les poids des neurones sont mis à jour une fois.
- La fonction de distance est une fonction mathématique qui calcule la distance entre les neurones et les points de données.
- La topologie décide de la disposition de la structure de la grille. Les neurones dans la grille peuvent être organisés en un motif rectangulaire ou hexagonal.
Dans la section suivante, nous discuterons des directives pour définir les valeurs de ces hyperparamètres.
Impact du réglage des hyperparamètres
Les valeurs des hyperparamètres doivent être décidées en fonction du modèle et de l’ensemble de données. Dans une certaine mesure, déterminer ces valeurs est un processus d’essais et d’erreurs. Dans cette section, nous donnons des lignes directrices pour ajuster chaque hyperparamètre. À côté de chaque hyperparamètre, nous mentionnons (entre parenthèses) les constantes Python respectives utilisées dans le code d’exemple.
- Taille de la grille (
SOM_X_AXIS_NODESetSOM_X_AXIS_NODES): La taille de la grille dépend de la taille de l’ensemble de données. La règle empirique est que pour un ensemble de données de taille N, la grille devrait contenir environ 5*sqrt(N) neurones. Par exemple, si l’ensemble de données contient 150 échantillons, la grille devrait contenir 5*sqrt(150) = environ 61 neurones. Dans ce tutoriel, l’ensemble de données Iris comporte 150 lignes et nous utilisons une grille de 8×8. - Taux d’apprentissage initial (
ALPHA): Un taux plus élevé accélère la convergence, tandis que des taux plus bas sont utilisés pour des ajustements plus fins après les premières itérations. Le taux d’apprentissage initial doit être suffisamment grand pour permettre une adaptation rapide mais pas trop grand pour dépasser les valeurs de poids optimales. Dans cet article, le taux d’apprentissage initial est de 0,5. - Écart-type initial (
SIGMA0): Il détermine la taille ou la portée initiale du voisinage. Une valeur plus grande prend en compte des motifs plus globaux. Dans cet exemple, nous utilisons un écart-type de départ de 1,5. - Pour le taux de déclin (
DECAY_FUNC) et le taux de déclin sigma (SIGMA_DECAY_FUNC), nous pouvons choisir l’un des trois types de fonctions de déclin : - Décroissance inverse: Cette fonction est adaptée si les données présentent à la fois des motifs globaux et locaux. Dans de tels cas, nous avons besoin d’une phase d’apprentissage large plus longue avant de nous concentrer sur les motifs locaux.
- Décroissance linéaire: Cela convient aux ensembles de données où nous souhaitons une taille de voisinage ou une réduction du taux d’apprentissage constante et uniforme. Cela est utile si les données n’ont pas besoin de beaucoup d’ajustements fins.
- Décroissance asymptotique: Cette fonction est utile si les données sont complexes et de haute dimension. Dans de tels cas, il est préférable de passer plus de temps sur l’exploration globale avant de passer progressivement aux détails plus fins.
- Fonction de voisinage (
NEIGHBORHOOD_FUNC): Le choix par défaut de la fonction de voisinage est la fonction gaussienne. D’autres fonctions, comme expliqué ci-dessous, sont également utilisées. - Gaussienne (par défaut) : Il s’agit d’une courbe en forme de cloche. L’étendue à laquelle un neurone est mis à jour diminue progressivement à mesure que sa distance par rapport au neurone gagnant augmente. Cela fournit une transition douce et continue et préserve la topologie des données. Elle est adaptée à la plupart des usages généraux en raison de son comportement stable et prévisible.
- Bulle: Cette fonction crée un voisinage à largeur fixe. Tous les neurones à l’intérieur de ce voisinage sont mis à jour de manière égale, et les neurones en dehors de ce voisinage ne sont pas mis à jour (pour un point de donnée donné). C’est moins coûteux en calcul et plus facile à mettre en œuvre. C’est utile pour des cartes plus petites où des frontières de voisinage nettes ne compromettent pas le regroupement efficace.
- Chapeau mexicain: Il a une région centrale positive entourée d’une région négative. Les neurones proches du BMU sont mis à jour pour se rapprocher du point de donnée, et les neurones plus éloignés sont mis à jour pour s’éloigner du point de donnée. Cette technique améliore le contraste et affine les caractéristiques de la carte. Comme elle met en avant des clusters distincts, elle est efficace dans les tâches de reconnaissance de motifs où une séparation claire des clusters est souhaitée.
- Triangle : Cette fonction définit la taille du voisinage comme un triangle, avec le BMU ayant la plus grande influence. Elle diminue linéairement avec la distance du BMU. Elle est utilisée pour regrouper des données avec des transitions progressives entre les clusters ou les caractéristiques, telles que des images, de la parole ou des données temporelles, où l’on s’attend à ce que les points de données voisins partagent des caractéristiques similaires.
- Fonction de distance (
DISTANCE_FUNC) : Pour mesurer la distance entre les neurones et les points de données, nous pouvons choisir parmi 4 méthodes : - Distance euclidienne (choix par défaut) : Utile lorsque les données sont continues et que nous voulons mesurer la distance en ligne droite. Cela convient à la plupart des tâches générales, en particulier lorsque les points de données sont uniformément répartis et spatialement liés.
- Distance cosinus : Bon choix pour les données textuelles ou les données clairsemées à haute dimension où l’angle entre les vecteurs est plus important que la magnitude. C’est utile pour comparer la directionnalité des données.
- Distance de Manhattan : Idéale lorsque les points de données sont sur une grille ou un réseau (par exemple, des blocs de ville). Cela est moins sensible aux valeurs aberrantes que la distance euclidienne.
- Distance de Chebyshev: Adaptée aux situations où le mouvement peut se faire dans n’importe quelle direction (par exemple, les distances sur un échiquier). Elle est utile pour les espaces discrets où nous souhaitons prioriser la différence maximale sur un axe.
- Topologie (
TOPOLOGY): Dans une grille, les neurones peuvent être arrangés dans une structure hexagonale ou rectangulaire : - Rectangulaire (par défaut) : chaque neurone a 4 voisins immédiats. C’est le bon choix lorsque les données n’ont pas de relation spatiale claire. C’est également plus simple sur le plan computationnel.
- Hexagonal : chaque neurone a 6 voisins. C’est l’option préférée si les données ont des relations spatiales mieux représentées par une grille hexagonale. C’est le cas pour les distributions de données circulaires ou angulaires.
- Nombre d’itérations d’entraînement (
N_ITERATIONS): En principe, des temps d’entraînement plus longs conduisent à des erreurs plus faibles et à un meilleur alignement des poids avec les données d’entrée. Cependant, la performance du modèle augmente asymptotiquement avec le nombre d’itérations. Ainsi, après un certain nombre d’itérations, l’augmentation de la performance due aux interactions suivantes n’est que marginale. Décider du bon nombre d’itérations nécessite quelques expérimentations. Dans ce tutoriel, nous entraînons le modèle pendant 5000 itérations.
Pour déterminer la bonne configuration des hyperparamètres, nous recommandons d’expérimenter avec diverses options sur un sous-ensemble plus petit des données.
Conclusion
Les cartes auto-organisatrices sont un outil robuste pour l’apprentissage non supervisé. Elles sont utilisées pour le regroupement, la réduction de dimensions, la détection d’anomalies et la visualisation des données. Étant donné qu’elles préservent les propriétés topologiques des données de haute dimension et les représentent sur une grille de dimension inférieure, les SOM facilitent la visualisation et l’interprétation de jeux de données complexes.
Ce tutoriel a discuté des principes sous-jacents des SOM et a montré comment implémenter un SOM en utilisant la bibliothèque Python MiniSom. Il a également démontré comment analyser visuellement les résultats et expliqué les hyperparamètres importants utilisés pour entraîner les SOM et affiner leurs performances.
Source:
https://www.datacamp.com/tutorial/self-organizing-maps