













Что такое Data Warehouse?
Прежде чем мы погружаемся в архитектуру Snowflake, давайте рассмотрим базы данных хранения данных, чтобы быть уверенными, что мы находимся на одной странице.
Data Warehouse – это централизованное хранилище, в котором хранятся большие объемы структурированных и организованных данных из различных источников для компании. Различные персонажи (сотрудники) в организациях используют данные внутри для получения различных выводов.
Например, аналитики в сотрудничестве с маркетинговой командой могут запустить тест A/B для новой маркетинговой кампании, используя таблицу продаж. Специалисты по кадрам могут запрашивать информацию о сотрудниках для отслеживания производительности.
Это лишь некоторые из примеров того, как компании по всему миру используют базы данных хранения данных для поддержания роста. Но без надлежащей реализации и управления с помощью таких инструментов, как Snowflake, базы данных хранения данных остаются лишь сложными концепциями.
Вы можете узнать больше о данном предмете с помощью нашего курса Data Warehousing.
Архитектура Snowflake
Уникальная архитектура Snowflake, разработанная для ускорения аналитических запросов, получила свои особенности из отделения уровней хранения и вычисления. Эта различие способствует вышеупомянутым преимуществам.
Уровень хранения
В Snowflake уровень хранения является критическим компонентом, который хранит данные эффективным и масштабируемым способом. Вот некоторые ключевые особенности этого уровня:
- Облачное размещение: Snowflake гладко интегрируется с основными поставщиками облачных услуг, такими как AWS, GCP и Microsoft Azure.
- Формат колонок: Snowflake хранит данные в колоночном формате, оптимизированном для аналитических запросов. В отличие от традиционных строковых форматов, используемых инструментами, такими как Postgres, колоночный формат хорошо подходит для агрегации данных. В колоночном хранении запросы получают доступ только к конкретным колонкам, что делает его более эффективным. С другой стороны, строковые форматы требуют доступа ко всем строкам в памяти для простых операций, таких как расчёт средних значений.
- Микроподразделение: Snowflake использует технику, называемую микроподразделением, которая хранит таблицы в памяти в небольших кусках. Каждый кусок обычно является неприменимым и составляет всего несколько мегабайт, что делает оптимизацию и выполнение запросов намного быстрее.
- Клонирование с нулевым копированием: Snowflake обладает уникальной функцией, позволяющей создавать виртуальные клонирования данных. Клонирование происходит мгновенно и не потребляет дополнительной памяти до тех пор, пока изменения не будут внесены в новую копию.
- Масштабируемость и эластичность: Уровень хранения масштабируется горизонтально, что означает, что он может обрабатывать увеличивающиеся объёмы данных, добавляя больше серверов для распределения нагрузки. Кроме того, это масштабирование происходит независимо от вычислительных ресурсов, что идеально подходит, когда требуется хранить большие объёмы данных, но анализировать только небольшую их часть.
Теперь рассмотрим вычислительный уровень.
Вычислительный уровень
Слое вычислений, как следует из названия, является двигателем, выполняющим ваши запросы. Он работает в сотрудничестве со слоем хранения для обработки данных и выполнения различных вычислительных задач. Ниже представлены некоторые более подробные сведения о том, как этот слой функционирует:
- Виртуальные склады: Можно рассматривать виртуальные склады как команды компьютеров (вычислительных узлов), предназначенных для обработки запросов. Каждый член команды обрабатывает различные части запроса, делая выполнение быстрым и параллельным. Snowflake предлагает виртуальные склады различных размеров, а следовательно, и различных стоимостей (размеры включают XS, S, M, L, XL).
- Архитектура с множеством кластеров и узлов: Слой вычислений использует несколько кластеров с множеством узлов для высокой конкуррентности, позволяя нескольким пользователям одновременно получать доступ и выполнять запросы к данным.
- Автоматическая оптимизация запросов: Система Snowflake анализирует все запросы и идентифицирует шаблоны для оптимизации с использованием исторических данных. Общие оптимизации включают удаление ненужных данных, использование метаданных и выбор наиболее эффективного пути выполнения.
- Кеш результатов: Слой вычислений включает кеш, в который сохраняются результаты часто выполняемых запросов. Когда тот же запрос запускается снова, результаты возвращаются практически мгновенно.
Эти принципы дизайна слоя вычислений способствуют способности Snowflake обрабатывать различные и требовательные рабочие нагрузки в облаке.
Слой облачных сервисов.
Финальный слой – это облачные сервисы. Поскольку этот слой интегрируется в каждый компонент архитектуры Snowflake, существует множество деталей о его работе. Кроме функций, связанных с другими слоями, у него есть следующие дополнительные обязанности:
- Безопасность и контроль доступа: Этот слой обеспечивает меры безопасности, включая аутентификацию, авторизацию и шифрование. Администраторы используют контроль доступа на основе ролей (RBAC) для определения и управления ролями и разрешениями пользователя.
- Обмен данными: Этот слой реализует безопасные протоколы обмена данными между различными учетными записями и даже сторонними организациями. Потребители данных могут получить доступ к данным без необходимости перемещения данных, способствуя сотрудничеству и монетизации данных.
- Поддержка полуструктурированных данных: Другой уникальной особенностью Snowflake является его способность обрабатывать полуструктурированные данные, такие как JSON и Parquet, несмотря на то, что он является платформой для управления хранилищами данных. Можно легко запрашивать полуструктурированные данные и интегрировать результаты с существующими таблицами. Такая гибкость отсутствует в других инструментах RDBMS.
Теперь, когда мы имеем общее представление о архитектуре Snowflake, давайте напишем немного SQL на этой платформе.
Установка SnowflakeSQL
Snowflake имеет свой собственный вариант SQL, называемый SnowflakeSQL. Различие между ним и другими диалектами SQL подобно различию между английскими акцентами.
Многие аналитические запросы, которые вы выполняете в диалектах, таких как PostgreSQL, не меняются, но есть некоторые расхождения в командах DDL (язык определения данных).
Snowflake предоставляет два интерфейса для запуска SnowSQL:
- Сноувид: Web-интерфейс для взаимодействия с платформой.
- СноуSQL: Клиент CLI (Command Line Interface) для управления и выполнения запросов к базам данных.
Мы посмотрим, как настроить оба и выполнить несколько запросов!
Сноувид: Web-интерфейс
Для начала с Snowsight, перейдите на сайт Snowflake и выберите “Начать бесплатно.” Введите свои персональные данные и выберите любой из перечисленных cloud-провайдеров. Выбор не имеет значительной важности, так как бесплатный пробный период включает $400 на счет для любого из вариантов (вам не требуется настраивать учетные данные облака самостоятельно).
После проверки вашей электронной почты вы будете перенаправлены на страницу Worksheets. Worksheets являются интерактивными, живыми кодирующими средами, где вы можете писать, выполнять и просматривать результаты ваших SQL-запросов.
Чтобы выполнить несколько запросов, нам нужна база данных и таблица (мы не будем использовать примерные данные из Snowsight). GIF-иллюстрация ниже показывает, как вы можете создать новую базу данных с именем “test_db” и таблицу с именем “diamonds” с использованием локального CSV-файла. Вы можете скачать CSV-файл, выполняя код в этом GitHub gist в вашем терминале.
В GIF-иллюстрации Snowsight сообщает нам о проблеме с одним из имён колонок. since слово “table” является зарезервированным ключевым словом, я заключил его в двойные кавычки.
После этого вы будете направлены на новую рабочую страницу, где можете выполнить любой SQL-запрос по вашему желанию. Как показано в GIF, интерфейс рабочей страницы довольно прямолинеен и функциональен. Затратите несколько минут, чтобы ознакомиться с панелями, кнопками и их соответствующими местоположениями.
SnowSQL: CLI
Ничто не может сравниться с удовольствием управления и выполнения запросов к полноценной базе данных из вашего терминала. Вот почему существует SnowSQL!
Однако, чтобы запустить его, нам нужно выполнить несколько шагов, что обычно является более медленным процессом, чем начало работы с Snowsight.
В качестве первого шага скачайте установщик SnowSQL с страницы Snowflake Developers Download. Скачайте соответствующий файл. Поскольку я использую WSL2, я выберу версию для Linux:

В терминале я скачиваю файл, используя скопированную ссылку, и запускаю его с помощью bash:
$ curl -O https://sfc-repo.snowflakecomputing.com/snowsql/bootstrap/1.2/linux_x86_64/snowsql-1.2.31-linux_x86_64.bash $ bash snowsql-1.2.31-linux_x86_64.bash
Для других платформ вы можете следовать инструкциям по установке с этой страницы документации Snowflake.
После успешной установки вы должны получить следующее сообщение:
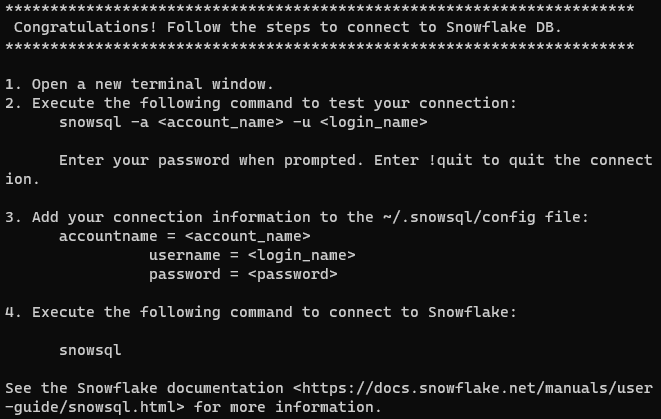
Примечание: В системах Unix-подобных важно убедиться, что команда snowsql доступна во всех сеансах терминала. Для этого вы должны добавить каталог /home/username/bin в вашу переменную $PATH. Вы можете сделать это, добавив следующую строку в ваш файл .bashrc, .bash_profile или .zshrc: export PATH=/home/вашеимя пользователя/bin:$PATH. Не забудьте заменить вашеимя пользователя на ваше实际 имя пользователя.
Сообщение предлагает настроить параметры учетной записи для подключения к Snowflake. Есть два способа сделать это:
- Передать подробности учетной записи интерактивно в терминале.
- Настроить учетные данные в глобальном файле конфигурации Snowflake.
Так как вариант второго более постоянный и безопасный, мы продолжим с этим вариантом. Для специфических указаний для платформы прочитайте страницу документации Подключение через SnowSQL. Инструкции ниже предназначены для систем Unix-подобных.
Во-первых, зайдите на свой адрес электронной почты и найдите приветственное письмо от Snowflake. Оно содержит имя вашей учетной записи в ссылке для входа: имя-учетной-записи.snowflakecomputing.com. Скопируйте его.
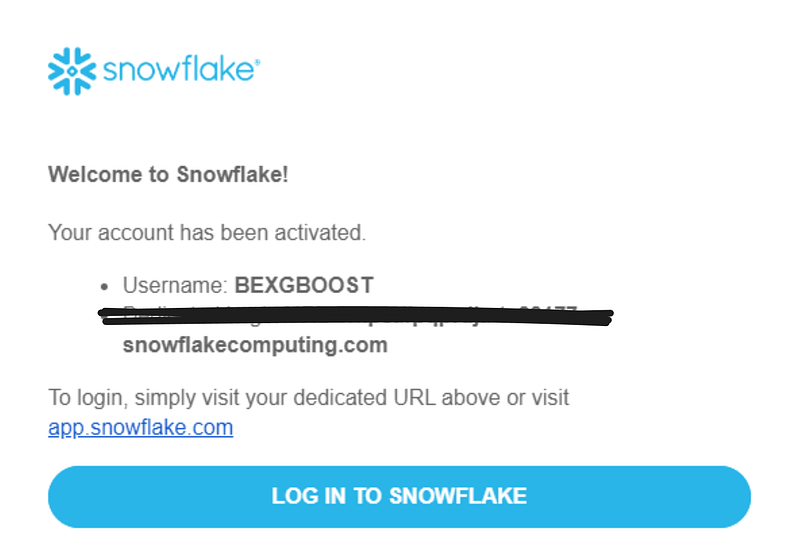
Далее, откройте файл ~/.snowsql/config с помощью текстового редактора, такого как VIM или VSCode. В разделе connections раскомментируйте следующие три поля:
- Имя учетной записи
- Имя пользователя
- Пароль
Замените значения по умолчанию на имена аккаунта, которые вы скопировали, и учетные данные, которые вы ввели при регистрации. После того, как вы это сделаете, сохраните и закройте файл.
Тогда вернитесь на ваш терминал и введите snowsql. Клиент должен автоматически подключиться и предоставить вам SQL-редактор с такими функциями, как подсветка кода и автоcompletion для вкладок. Вот, какого он должен выглядеть:
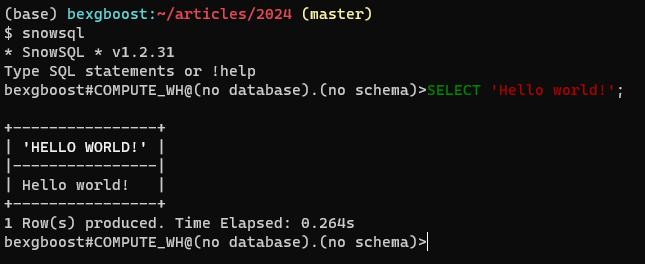
Подключение к существующей базе данных в SnowSQL
В настоящее время мы не подключены к какой-либо базе данных. corrected that by connecting to the test_db database we’ve created with Snowsight. First, check available databases with SHOW DATABASES:
$ SHOW DATABASES $ USE DATABASE TEST_DB
Next, specify that you will be using the test_db database (case-insensitive) from now on. Then, you can run any SQL query on the tables of the connected database.
$ SELECT COUNT(*) FROM DIAMONDS
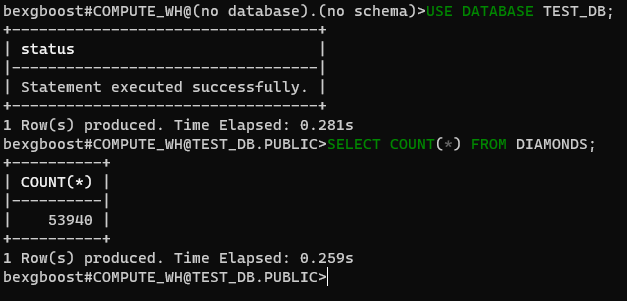
Creating a new database and table in SnowSQL
If you are part of a large organization, there might be cases where the responsibility of creating a database and populating it with existing data rests on your shoulders. To practice for that scenario, let’s try uploading the Diamonds dataset as a table in SnowSQL inside a new database. Here are the steps you can follow:
1. Create a new database:
CREATE DATABASE IF NOT EXISTS new_db;
2. Use the database:
USE DATABASE new_db;
3. Create a file format for CSV:
CREATE OR REPLACE FILE FORMAT my_csv_format -- Can be named anything TYPE = CSV FIELD_DELIMITER = ',' SKIP_HEADER = 1; -- Assuming the first row is a header
Мы должны вручную определить файловый формат и назвать его, поскольку Сноуфлайк не может с inferщим схему и структуру данных в файлах, таких как CSV, JSON или XML. Файловый формат, определенный нами выше, соответствует для файла diamonds.csv, который мы имеем (он отделен запятой и включает заголовок).
4. Создайте внутреннюю стадию:
CREATE OR REPLACE STAGE my_local_files;
Стадия в Сноуфлайке является областью хранения, где вы можете загрузить ваши локальные файлы. Это могут быть структурированные и полуструктурированные файлы с данными. Вы выше создаем стадию с именем my_local_files.
5. положите CSV-файл на стадию:
PUT file:///home/bexgboost/diamonds.csv @my_local_files;
6. Создайте таблицу:
CREATE TABLE diamonds ( carat FLOAT, cut VARCHAR(255), color VARCHAR(255), clarity VARCHAR(255), depth FLOAT, table FLOAT, price INTEGER, x FLOAT, y FLOAT, z FLOAT );
7. Загрузите данные с стадии в таблицу:
COPY INTO diamonds FROM @my_local_files/diamonds.csv FILE_FORMAT = my_csv_format;
8. Проверите:
SELECT COUNT(*) FROM diamonds;
Эти шаги создадут новую базу данных Snowflake, определит формат CSV-файла, создадут стадию для хранения локальных файлов, загрузите CSV-файл на стадию, создадут новую таблицу, загрузите данные CSV в таблицу и, наконец, проверите операцию, считая количество строк в таблице.
Если результат возвращает число строк, поздравляем, успешно создали базу данных и загрузили локальные данные в нее с помощью SnowSQL. Теперь вы можете выполнять запросы по таблице так, как вам нужно.
Заключение и дальнейшее обучение
Ура! Мы начали с нескольких простых концепций, но в конце концов, мы на самом деле исследовали сложные детали. Well, это моя идея надлежащего руководства.
Вы, наверное, подозреваете, что Snowflake содержит гораздо больше, чем мы покрыли. Фактически, в документации Snowflake включены краткие руководства, которые на самом деле длиннее 128 минут! Но прежде чем приступить к ним, я рекомендую ознакомиться с другими ресурсами. Вот несколько предложений:
- Курс “Введение в Snowflake”
- Вебинар о современном использовании аналитики продаж с Snowflake
- Анализ данных в Snowflake с использованием Python (код-вместе)
- Официальные руководства пользователя Snowflake
- Ресурсы для разработчиков Snowflake
Спасибо за чтение!
Source:
https://www.datacamp.com/tutorial/introduction-to-snowflake-for-beginners