













Was ist ein Data Warehouse?
Bevor wir uns Snowflakes Architektur näher anschauen, überprüfen wir zunächst Data Warehouses, um sicherzugehen, dass wir alle auf der gleichen Seite sind.
Ein Data Warehouse ist ein zentrales Repositorium, das große Mengen strukturierter und organisierter Daten aus verschiedenen Quellen für ein Unternehmen speichert. Verschiedene Personen (Mitarbeiter) in Organisationen nutzen diese Daten, um verschiedene Einsichten zu gewinnen.
Zum Beispiel könnten Data Analysten, in Zusammenarbeit mit dem Marketing-Team, einen A/B-Test für eine neue Marketingkampagne mithilfe der Verkaufstabelle durchführen. HR-Spezialisten könnten die Angestellteninformation abfragen, um die Leistung zu verfolgen.
Dies sind einige Beispiele dafür, wie Unternehmen weltweit Data Warehouses nutzen, um Wachstum zu fördern. Ohne eine ordnungsgemäße Implementierung und Verwaltung mit Tools wie Snowflake bleiben Data Warehouses jedoch lediglich umfangreiche Konzepte.
Sie können mehr über das Thema in unserem Data Warehousing-Kurs erfahren.
Snowflake-Architektur
Snowflakes einzigartige Architektur, die für schnellere analytische Abfragen designed wurde, resultiert aus der Trennung von Speicher- und Rechenebene. Diese Unterscheidung trägt zu den zuvor erwähnten Vorteilen bei.
Speicherebene
Bei Snowflake ist die Speicherebene ein kritischer Bestandteil, der Daten effizient und skalierend speichert. Hier sind einige Hauptmerkmale dieser Ebene:
- Cloud-basiert: Snowflake integriert nahtlos mit bedeutenden Cloud- Providern wie AWS, GCP und Microsoft Azure.
- Spaltenformat: Snowflake speichert Daten in einem spaltenbasierten Format, das für analytische Abfragen optimiert ist. Im Gegensatz zu den traditionellen zeilenbasierten Formaten, die von Tools wie Postgres verwendet werden, ist das spaltenbasierte Format gut geeignet für Datenaggregation. Bei der spaltenbasierten Speicherung greifen Abfragen nur auf die benötigten Spalten zu, was effizienter ist. Zeilenbasierte Formate erfordern dagegen den Zugriff auf alle Zeilen im Speicher für einfache Operationen wie die Berechnung von Durchschnittswerten.
- Mikro-Partitionierung: Snowflake verwendet eine Technik namens Mikro-Partitionierung, die Tabellen in kleinen Chunks im Speicher abspeichert. Jeder Chunk ist typischerweise unveränderlich und nur wenige Megabyte groß, was die Optimierung und Ausführung von Abfragen erheblich beschleunigt.
- Zero-Kopie-Klonen: Snowflake hat eine einzigartige Funktion, die das Erstellen virtueller Datenklone ermöglicht. Das Klonen erfolgt sofortan und verbraucht kein zusätzliches Speicherplatz, bis Änderungen an der neuen Kopie vorgenommen werden.
- Skalierung und Elastizität: Die Speicherebene skaliert horizontal, was bedeutet, dass sie zunehmende Datenmengen durch Hinzufügen von zusätzlichen Servern zum Lastenausgleich handhaben kann. Außerdem erfolgt diese Skalierung unabhängig von Rechenressourcen, was ideal ist, wenn Sie große Datenvolumina speichern, aber nur einen kleinen Teil davon analysieren möchten.
Nun schauen wir uns die Rechenebene an.
Rechenebene
Wie der Name vermuten lässt, ist die Rechenebene der Motor, der Ihre Abfragen ausführt. Sie arbeitet in Verbindung mit der Speicherebene, um Daten zu verarbeiten und verschiedene numerische Aufgaben zu erledigen. Folgend finden Sie mehr Details über wie diese Ebene funktioniert:
- Virtuelle Lagerhallen:Sie können Virtuelle Lagerhallen als Teams von Computern (Rechenknoten) verstehen, die für die Abfrageverarbeitung ausgestattet sind. Jedes Mitglied der Mannschaft behandelt einen anderen Teil der Abfrage, was zur beeindruckvollen und parallelen Ausführung führt. Snowflake bietet Virtuelle Lagerhallen in unterschiedlichen Größen an und somit auch mit unterschiedlichen Preisen (die Größenordnungen umfassen XS, S, M, L, XL).
- Mehrere Cluster, mehrere Knoten-Architektur:Die Rechenebene verwendet mehrere Cluster mit mehreren Knoten für hohe Konkurrenzfähigkeit, was die gleichzeitige Zugriff und Abfrage der Daten zulässt.
- Automatische Abfrageoptimierung:Snowflakes System analysiert alle Abfragen und erkennt Muster, um aufgrund von historischen Daten zu optimieren. Common optimizations include pruning unnecessary data, using metadata, and choosing the most efficient execution path.
- Ergebnissecache:Die Rechenebene verfügt über einen Cache, der die Ergebnisse von oft ausgeführten Abfragen speichert. Wenn die gleiche Abfrage erneut ausgeführt wird, werden die Ergebnisse nahezu sofort zurückgegeben.
Diese Designprinzipien der Rechenebene tragen alle dazu bei, dass Snowflake Cloud-basierte unterschiedliche und anspruchsvolle Lasten bewältigen kann.
Clouddiensteschicht
Die oberste Schicht sind Clouddienstleistungen. Da diese Schicht in jeden Bestandteil der Architektur von Snowflake integriert ist, gibt es viele Details zu ihrer Operation. Neben den Funktionen, die mit anderen Schichten in Verbindung stehen, hat sie die folgenden zusätzlichen Verantwortungen:
- Sicherheit und Zugriffskontrolle:Diese Schicht durchtritt Sicherheitsmaßnahmen, einschließlich Authentifizierung, Autorisierung und Verschlüsselung. Administratoren verwenden Rollenbasierte Zugriffskontrolle (RBAC) zur Definition und Verwaltung von Benutzerrollen und -berechtigungen.
- Datenabtastung:Diese Schicht implementiert sichere Datenabtastungspfade zwischen verschiedenen Konten und sogar dritten Parteien. Datenkonsumenten können auf die Daten zugreifen, ohne dass Daten verschoben werden müssen, was die Zusammenarbeit und die Datenmonetarisierung fördert.
- Unterstützung von semi-strukturierten Daten:Eine weitere eigentümliche Eigenschaft von Snowflake ist die Fähigkeit, semi-strukturierte Daten zu verarbeiten, obwohl es ein Data Warehouse Management-Plattform ist. Es kann semi-strukturierte Daten leicht abfragen und die Ergebnisse mit bestehenden Tabellen integrieren. Diese Flexibilität ist bei anderen RDBMS-Tools nicht zu finden.
Nachdem wir ein Überblicksbild der Snowflake-Architektur erhalten haben, lassen Sie uns einige SQL-Befehle auf der Plattform schreiben.
SnowflakeSQL einrichten
Snowflake hat seine eigene Variante von SQL, die SnowflakeSQL heißt. Der Unterschied zu anderen SQL-Dialekten ist vergleichbar mit den Unterschieden zwischen englischen Akzenten.
Viele der analytischen Abfragen, die Sie in Dialekten wie PostgreSQL durchführen, ändern sich nicht, aber es gibt einige Unterschiede in den DDL (Daten Definition Language)-Befehlen.
Snowflake bietet zwei Schnittstellen an, um SnowSQL auszuführen:
- Snowsight:Eine Weboberfläche zur Interaktion mit der Plattform.
- SnowSQL: Ein CLI (Befehlszeilenoberfläche) Client zum Verwalten und Abfragen von Datenbanken.
Wir werden sehen, wie wir beide einrichten und einige Abfragen ausführen können!
Snowsight: Weboberfläche
Zum Anfang mit Snowsight gehen Sie zu der Snowflake Homepage und wählen Sie „Kostenlos starten“. Geben Sie Ihre persönlichen Informationen ein und wählen Sie einen der aufgeführten Cloud-Dienstleister aus. Der Wahl ist eigentlich irrelevant, da der kostenlose Test mit 400 USD Credits für jede Option beinhaltet (Sie werden nicht gezwungen, die Cloud-Zugangsdaten selbst zu konfigurieren).
Nach der Email-Verifizierung werden Sie auf die Worksheets-Seite weitergeleitet. Worksheets sind interaktive, live-Codingsysteme, in denen Sie SQL-Abfragen schreiben, ausführen und deren Ergebnisse anzeigen können.
Um einige Abfragen auszuführen, brauchen wir eine Datenbank und eine Tabelle (wir werden die Beispieldaten in Snowsight nicht verwenden). Das unten gezeigte GIF zeigt, wie Sie mit einer lokalen CSV-Datei eine neue Datenbank namens „test_db“ und eine Tabelle namens „diamonds“ erzeugen können. Sie können die CSV-Datei, indem Sie den Code in diesem GitHub Gist im Terminal ausführen, herunterladen.
Im GIF通知Snowsight uns, dass es ein Problem mit einem der Spaltennamen gibt. Da das Wort „table“ ein reserviertes Schlüsselwort ist, habe ich es in doppelte Anführungszeichen gefasst.
Nachdem Sie fortgeschritten sind, werden Sie zu einer neuen Arbeitsblattübersicht weitergeleitet, wo Sie jede SQL-Abfrage ausführen können, die Sie wünschen. Wie im GIF gezeigt ist die Arbeitsblattoberfläche recht einfach und hochfunktional. nehmen Sie einige Minuten, um sich mit den Panels, den Buttons und ihren jeweiligen Positionen vertraut zu machen.
SnowSQL: CLI
Nichts trifft den Nervenkitzel so wie das Verwalten und Abfragen eines vollständigen Datenbankmanagements von Ihrem Terminal aus. Darum existiert SnowSQL!
Allerdings gibt es einige Schritte, die wir durchführen müssen, um es zu starten, was typischerweise langsamer ist als das Erstehen von Snowsight.
Als erster Schritt laden Sie den SnowSQL-Installer von der Snowflake Developers DownloadSeite herunter. Laden Sie die relevante Datei herunter. Da ich WSL2 verwende, werde ich eine Linux-Version auswählen:

In der Terminalbenutzeroberfläche laden Sie die Datei mit dem kopierten Link herunter und führen Sie sie mit bash aus:
$ curl -O https://sfc-repo.snowflakecomputing.com/snowsql/bootstrap/1.2/linux_x86_64/snowsql-1.2.31-linux_x86_64.bash $ bash snowsql-1.2.31-linux_x86_64.bash
Für andere Plattformen können Sie die Installationsschritte von dieser Seite der Snowflake Dokumentationbefolgen.
Nach erfolgreichem Installieren sollten Sie die folgende Nachricht erhalten:
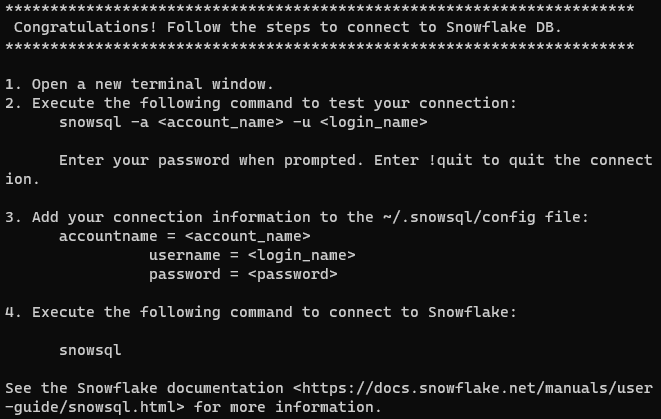
Note: Auf Unix-ähnlichen Systemen ist es wichtig sicherzustellen, dass das snowsql-Kommando in allen Terminal-Sitzungen verfügbar ist. Um dies zu erreichen, sollten Sie den Ordner /home/username/bin zu Ihrer $PATH-Variable hinzufügen. Fügen Sie diese Zeile in Ihre .bashrc, .bash_profile oder .zshrc-Datei hinzu: export PATH=/home/yourusername/bin:$PATH. Ersetzen Sie yourusername mit Ihrem tatsächlichen Benutzernamen.
Die Nachricht fordert uns auf, die Kontoeinstellungen so zu konfigurieren, dass eine Verbindung zu Snowflake hergestellt werden kann. Es gibt zwei Möglichkeiten, dies zu tun:
- Passen Sie die Kontodetails interaktiv im Terminal an.
- Konfigurieren Sie die Zugangsdaten in einer globalen Snowflake-Konfigurationsdatei.
Da die zweite Option dauerhafter und sicherer ist, werden wir diese verwenden. Für plattformspezifische Anweisungen lesen Sie die Seite Verbindungsaufbau über SnowSQL in der Dokumentation. Die folgenden Anweisungen gelten für Unix-ähnliche Systeme.
Zunächst sollten Sie in Ihrer E-Mail-Adresse die Willkommens-E-Mail von Snowflake suchen. Sie enthält Ihren Kontonamen im Login-Link: account-name.snowflakecomputing.com. Kopieren Sie diesen.
Öffnen Sie anschließend die Datei ~/.snowsql/config mit einem Texteditor wie VIM oder VSCode. Entfernen Sie in der Sektion connections die Kommentare bei den folgenden drei Feldern:
- Kontoname
- Benutzername
- Passwort
Ersetzen Sie die Standardwerte mit Ihrem Kontonamen, den Sie kopiert haben, sowie mit dem Benutzernamen und dem Passwort, die Sie beim Anmelden eingegeben haben. Nachdem Sie dies getan haben, sollten Sie die Datei speichern und schließen.
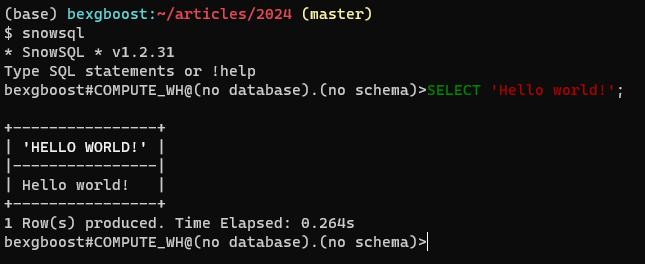
Danach gehen Sie zu Ihrem Terminal zurück und geben Sie snowsql ein. Der Client sollte automatisch verbinden und Ihnen ein SQL-Editor mit Funktionen wie Code-Hervorhebung und Tabulatoren zur Verfügung stellen. Hier ist das Aussehen:
Verbinden mit einer existierenden Datenbank in SnowSQL
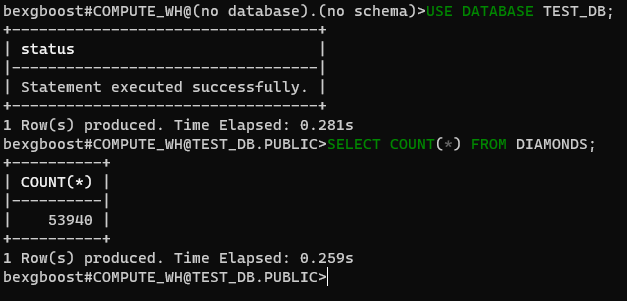
Derzeit sind wir mit keiner Datenbank verbunden. Lassen Sie uns das ändern, indem wir mit der Datenbank test_db verbinden, die wir mit Snowsight erstellt haben. Zuerst prüfen Sie die verfügbaren Datenbanken mit SHOW DATABASES:
$ SHOW DATABASES $ USE DATABASE TEST_DB
Nächstes, bestätigen Sie, dass Sie von jetzt an die test_db Datenbank (groß-/kleinbuchstabenunabhängig) verwenden werden. Dann können Sie jeder SQL-Abfrage auf den Tabellen der verbundenen Datenbank ausführen.
$ SELECT COUNT(*) FROM DIAMONDS
Erstellen einer neuen Datenbank und Tabelle in SnowSQL
Wenn Sie Teil einer großen Organisation sind, gibt es vielleicht Fälle, in denen die Verantwortung für die Erstellung einer Datenbank und das Befüllen mit vorhandenen Daten auf Ihren Schultern liegt. Um sich auf diese Situation vorzubereiten, versuchen wir, die Diamanten-Datenmenge als Tabelle in SnowSQL innerhalb einer neuen Datenbank hochzuladen. Hier sind die Schritte, die Sie folgen können:
1. Erstellen einer neuen Datenbank:
CREATE DATABASE IF NOT EXISTS new_db;
2. Verwenden der Datenbank:
USE DATABASE new_db;
3. Erstellen eines Dateiformats für CSV:
CREATE OR REPLACE FILE FORMAT my_csv_format -- kann irgendeinen Namen haben TYPE = CSV FIELD_DELIMITER = ',' SKIP_HEADER = 1; -- nehmen wir an, dass die erste Zeile ein Kopfzeile ist
Wir müssen ein Dateiformat manuell definieren und benennen, weil Snowflake das Schema und die Struktur von Datendateien wie CSV, JSON oder XMLs nicht ableiten kann. Das oben definierte Dateiformat ist geeignet für die Datei diamonds.csv, die wir haben (sie ist durch Kommas getrennt und enthält einen Header).
4. Erstellen Sie eine interne Stage:
CREATE OR REPLACE STAGE my_local_files;
Eine Stage in Snowflake ist ein Speicherbereich, in den Sie Ihre lokalen Dateien hochladen können. Diese können strukturierte und semi-strukturierte Datendateien sein. Oben erstellen wir eine Stage namens my_local_files.
5. Legen Sie die CSV-Datei in die Stage:
PUT file:///home/bexgboost/diamonds.csv @my_local_files;
6. Erstellen Sie die Tabelle:
CREATE TABLE diamonds ( carat FLOAT, cut VARCHAR(255), color VARCHAR(255), clarity VARCHAR(255), depth FLOAT, table FLOAT, price INTEGER, x FLOAT, y FLOAT, z FLOAT );
7. Laden Sie Daten aus der Stage in die Tabelle:
COPY INTO diamonds FROM @my_local_files/diamonds.csv FILE_FORMAT = my_csv_format;
8. Überprüfen:
SELECT COUNT(*) FROM diamonds;
Diese Schritte erstellen eine neue Snowflake-Datenbank, definieren ein CSV-Dateiformat, erstellen eine Stage zum Speichern lokaler Dateien, laden eine CSV-Datei in die Stage hoch, erstellen eine neue Tabelle, laden die CSV-Daten in die Tabelle und überprüfen schließlich den Vorgang, indem die Anzahl der Zeilen in der Tabelle gezählt wird.
Wenn das Ergebnis die Zeilenanzahl zurückgibt, herzlichen Glückwunsch, Sie haben erfolgreich eine Datenbank erstellt und lokale Daten mit SnowSQL darin geladen. Jetzt können Sie die Tabelle nach Belieben abfragen.
Fazit und weiteres Lernen
Uff! Wir haben mit einigen einfachen Konzepten begonnen, aber gegen Ende sind wir wirklich in die kniffligen Details eingetaucht. Nun, das ist meine Vorstellung von einem ordentlichen Tutorial.
Sie haben sich vielleicht bereits denken lassen, dass Snowflake viel mehr bietet als wir bisher behandelt haben. Tatsächlich enthält die Snowflake-Dokumentation Quickstart-Leitfäden, die tatsächlich 128 Minuten lang sind! Bevor Sie sich jedoch daran machen, empfehle ich, sich mit einigen anderen Ressourcen vertraut zu machen. Wie wären das:
- Einleitungskurs zu Snowflake
- Ein Webinar zur Modernisierung von Verkaufsanalysen mit Snowflake
- Datenanalyse in Snowflake mithilfe von Python-Code-Along
- Offizielle Benutzerhandbücher von Snowflake
- Entwicklerressourcen für Snowflake
Vielen Dank fürs Lesen!
Source:
https://www.datacamp.com/tutorial/introduction-to-snowflake-for-beginners