













데이터 와이어House는 무엇인가요?
우리가 모두 같은 ArgumentSpace에 있는지 확인하기 위해서, Snowflake의 아키텍тура에 들어가기 전에 데이터 와이어House에 대해 다시 보겠습니다.
데이터 와이어House는 회사의 다양한 소스から 구성되어 있는 大道로적 수준의 데이터를 저장하는 centralized repository입니다. 다양한 인물(직원)들이 組織 내부에서 다양한 인사이트를 추출하기 위해 이 데이터를 사용합니다.
例如, 데이터 분석가들과 마케팅 团队을 통해 신규 마케팅 캠페인에 대한 A/B 시험을 실시하는 것 등, organizations의 다양한 인물들이 데이터 와이어House를 사용하는 방법이 다양합니다.
이러한 방법은 회사들이 글로벌 수준에서 성장을 이룰 수 있는 데이터 와이어House를 사용하는 examples입니다. 하지만 Snowflake와 같은 도구를 사용하여 적절한 구현과 관리를 하지 않으면, 데이터 와이어House는 elaborate concepts로 유지됩니다.
이 subject에 대해 더 deeply understand하기 위해서는 Data Warehousing 과정을 통해 배울 수 있습니다.
Snowflake Architecture
Snowflake의 독특한 아키텍тура는 faster analytical queries를 위해 設計되었고, 이를 위해서 storage and compute layers를 분리하였습니다. 이러한 구분은 우리가 이전에 언급한 benefit들을 실현시키는 역할을 합니다.
Storage layer
Snowflake에서, storage layer는 데이터를 efficient and scalable manner로 저장하는 critical component입니다. 이 层次의 일부 of the key features가 다음과 같습니다:
- 云기반:Snowflake는 AWS, GCP, Microsoft Azure 등의 주요 클라우드 제공업체와 无缝으로 통합할 수 있습니다.
- 列形式:Snowflake는 数据分析이 적용되는 列形式으로 데이터를 存储합니다. Postgres과 같은 도구들이 사용하는 传统的 行形式과 달리 列形式은 数据分析에 적합합니다. 列形式 存储에서는 쿼리가 필요한 대로 columns에 직접 アクセ스하는 것이 일어뜀으로 더욱 효율적입니다. 대신 行形式은 averages 과 같은 간단한 operaions에서는 모든 行을 메모리에 접근해야 합니다.
- 微分割:Snowflake는 테이블을 메모리에 小块으로 存储하는 기술을 사용합니다. 각 块은 일반적으로 변경 불가능하며 몇 兆字节의 크기로 숫자가 작습니다. 이러한 특성은 쿼리 최적화와 실행이 훨씬 faster가 되었습니다.
- 零复制的克隆:Snowflake는 데이터의 가상 克隆을 만들 수 있는 유ique한 기능을 갖추고 있습니다. 克隆이 瞬间이며 새로운 副本에 변화를 하기 전에 추가 메모리를 사용하지 않습니다.
- 스케일링과 이lasticity: 저장 层次이 水平적으로 스케일링되는 것은 더 많은 서버를 추가하여 부하를 분산하여 증가하는 데이터 volum을 处理할 수 있다는 의미입니다. 또한 이러한 스케일링은 计算机 자원과 독립적이며 대량의 데이터를 存储하고 Anclysis를 하는 것 이외에는 작은 fraction을 분석하고자 하는 경우에 理想적입니다.
이제 计算机 层次을 보겠습니다.
计算机层次
이름 그대로, 计算机层次(compute layer)는 您的查询를 실행하는 엔진입니다. 이 层次은 저장层次(storage layer)と 함께 데이터를 처리하고 다양한 计算机任务를 수행합니다. 이 层次이 어떻게 작동하는지 자세한 내용들은 다음과 같습니다:
- 가상 창고(Virtual warehouses):가상 창고를 컴퓨터 团队(compute nodes)로 이루어진 团队으로 생각할 수 있습니다. 团队의 각 멤버가 쿼리 처리의 다양한 部分을 处理하여, 실행이 impressively 빠르고 paralle로 이뤄집니다. Snowflake는 다양한 크기의 Virtual Warehouses를 제공하고 있으며, 따라서 다양한 가격(크기는 XS, S, M, L, XL로 구성되어 있습니다.)를 가지고 있습니다.
- 다cluster, 다node 구조(Multi-cluster, multi-node architecture):计算机层次은 다양한 集群에서 다양한 node를 사용하여 높은 concurrency를 지원하며, 여러 사용자가 동시에 데이터에 액세스하고 쿼리하는 것을 허용합니다.
- 자동 쿼리 優化(Automatic query optimization):Snowflake의 시스템은 모든 쿼리를 분석하고 이전 데이터를 통해 최적화하는 패턴을 식별합니다. 일반적인 優化은 필요없는 데이터를 剪纸하고, metadata를 사용하고, 가장 효율적인 실행 경로를 선택하는 것입니다.
- 결과 캐시(Results cache):计算机层次은 자주 실행되는 쿼리의 결과를 저장하는 캐시를 가지고 있습니다. 같은 쿼리가 다시 실행되면, 결과는 ほぼ 훨씬 빨라게 반환됩니다.
计算机层次의 이러한 설계 원칙은 Snowflake가 云计算环境에서 다양한 과목적인 工作中的loads를 처리할 수 있는 능력을 기울여줍니다.
云服务层次(Cloud services layer)
마지막 层次은 雲 서비스입니다. 이 层次은 Snowflake 아키텍처의 모든 组成部分에 integrate 되어 있으며, 이를 위한 많은 세부 사항이 있습니다. 다른 层次과 관련된 기능 외에는 다음과 같은 추가적인 责任을 가지고 있습니다.:
- 보안과 접근 제어 :이 层次은 인증, 권한 관리, 암호화 등 보안 조치를 적용합니다. 관리자는 roll-Based Access Control (RBAC)을 사용하여 사용자 역할과 권한을 정의하고 관리합니다.
- 데이터 공유 :이 层次은 다른 계정 및 第三方的 조직之间에서 안전한 데이터 공유 protocol을 실현합니다. 데이터 소비자는 데이터 이동이 필요없이 데이터에 접근할 수 있으며, 이를 통해 협업과 데이터 수요 등을 도울 수 있습니다.
- 部分的 구조화 데이터 지원 :Snowflake는 데이터 warehouse 관리 platform이기 때문에 部分的 구조化 데이터, 예를 들어 JSON과 Parquet에 대해 处理的 수능을 가지고 있습니다. 部分的 구조化 데이터에 대한 쿼리를 간단하게 실행할 수 있고, 기존의 테이블과 결과를 integrate할 수 있습니다. 이러한 유연성은 다른 RDBMS 도구에서 볼 수 없습니다.
Snowflake의 아키텍처의 高层 사진을 이해했으니, 이 platform上에서 SQL을 写得해봅시다.
SnowflakeSQL의 설정
Snowflake는 자신의 SQL 版本을 SnowflakeSQL로 가지며, 그것과 다른 SQL 언어들의 차이는 영국의 英语 抑扬(accent)과 비슷합니다.
PostgreSQL과 같은 analyze 쿼리의 대부분은 변화하지 않지만, DDL(Data Definition Language) 명령에 一些 차이가 있습니다.
Snowflake는 SnowSQL을 실행하기 위한 두 가지 인터페이스를 제공합니다.
- Snowsight: 플랫폼과 상호 작용하는 웹 인터페이스입니다.
- SnowSQL: 데이터베이스를 관리하고 쿼리하는 CLI (커맨드 라인 인터페이스) 클라이언트입니다.
양两者를 설정하고 몇 가지 쿼리를 실행하는 방법을 살펴봅니다!
Snowsight: 웹 인터페이스
Snowsight로 시작하려면, Snowflake 홈페이지로 이동하여 “무료로 시작하기”를 선택하세요. 개인 정보를 입력하고 목록에 있는 어떤 클라우드 제공자를 선택하세요. 선택은 실제로 중요하지 않습니다. 무료 트라이얼은 어떤 옵션에서도 $400의 크레딧을 포함하며 (클라우드 자격 증명을 직접 설정할 필요는 없습니다).
이메일을 인증하면 Worksheets 페이지로 리디렉션됩니다. Worksheets는 인터актив적인 라이브 코딩 환경으로 SQL 쿼리를 작성하고, 실행하고, 결과를 확인할 수 있습니다.
일부 쿼리를 실행하려면 데이터베이스와 테이블이 필요합니다 (Snowsight의 샘플 데이터는 사용하지 않습니다). 아래 GIF는 새 데이터베이스 “test_db”와 “diamonds”라는 이름의 테이블을 로컬 CSV 파일을 사용하여 생성하는 방법을 보여줍니다. CSV 파일은 터미널에서 이 GitHub gist의 코드를 실행하여 다운로드할 수 있습니다.
GIF에서 Snowsight는 컬럼 이름 중 하나에 문제가 있다고 알려줍니다. “table”이라는 단어가 예약어이기 때문에, 이를 이중 따옴표로 감싸었습니다.
나중에는 SQL 쿼리를 실행할 수 있는 새로운 워크시트로 이동합니다. GIF에 보여진 것처럼 워크시트 인터페이스는 매우 직관적이고 기능이 많습니다. 패널, 버튼, 그리고 해당 위치를 익히는 데 몇 분을 가져보세요.
SnowSQL: CLI
터미널에서 완전한 데이터베이스를 관리하고 쿼리하는 것의 흥미를 느낄 수 있는 것과 같은 것은 없습니다. 그래서 SnowSQL이 있습니다!
그러나 실행하려면 몇 가지 단계를 따라야 합니다. 이는 Snowsight로 시작하는 것보다 일반적으로 더 오래 걸립니다.
첫 번째 단계로 Snowflake 개발자 다운로드 페이지에서 SnowSQL 설치자를 다운로드합니다. 관련 파일을 다운로드하세요. 저는 WSL2를 사용하므로 리눅스 버전을 선택할 것입니다:

터미널에서 복사한 링크를 사용하여 파일을 다운로드하고 bash로 실행합니다:
$ curl -O https://sfc-repo.snowflakecomputing.com/snowsql/bootstrap/1.2/linux_x86_64/snowsql-1.2.31-linux_x86_64.bash $ bash snowsql-1.2.31-linux_x86_64.bash
다른 플랫폼의 경우 이 Snowflake 문서 페이지에서 설치 절차를 따릅니다.
성공적으로 설치되면 다음과 같은 메시지를 받게 됩니다.
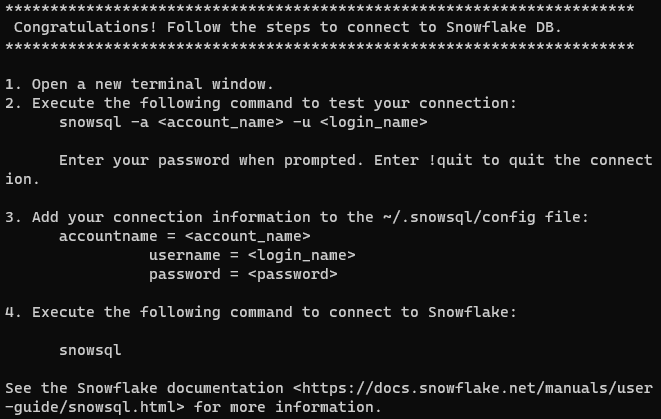
참고: 유닉스 계열 시스템에서는 모든 터미널 세션에서 snowsql 명령을 사용할 수 있는지 확인하는 것이 중요합니다. 이렇게 하려면 $PATH 변수에 /home/username/bin 디렉터리를 추가해야 합니다. .bashrc, .bash_profile 또는 .zshrc 파일에 다음 줄을 추가하면 됩니다: export PATH=/home/yourusername/bin:$PATH. yourusername를 실제 사용자 아이디로 바꿔야 합니다.
스노우플레이크에 연결하기 위한 계정 설정을 구성하라는 메시지가 표시됩니다. 두 가지 방법이 있습니다.
- 터미널에서 대화형으로 계정 세부 정보를 전달합니다.
- 글로벌 Snowflake 구성 파일에서 자격 증명을 구성합니다.
더 영구적이고 안전하므로 두 번째 옵션으로 진행하겠습니다. 플랫폼별 지침은 문서의 SnowSQL을 통해 연결하기 페이지를 참조하세요. 아래 지침은 유닉스 계열 시스템용입니다.
먼저, 이메일 주소로 이동하여 Snowflake에서 보낸 환영 이메일을 찾습니다. 로그인 링크 안에 계정 이름이 포함되어 있습니다: account-name.snowflakecomputing.com. 복사합니다.
다음으로 VIM 또는 VSCode와 같은 텍스트 편집기를 사용하여 ~/.snowsql/config 파일을 엽니다. <코드>연결 섹션에서 다음 세 필드의 주석 처리를 해제합니다:
- 계정 이름
- 사용자 이름
- 비밀번호
대체 기본값을 가입할 때 복사한 계정 이름과 제공한 사용자 이름과 암호로 변경합니다. 그 후에 파일을 저장하고 닫으세요.
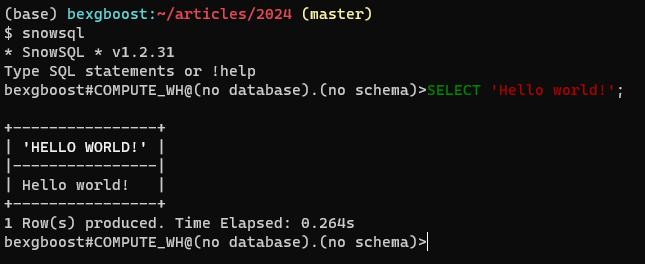
그 다음 터미널로 돌아가 snowsql를 입력하세요. 클라이언트는 자동으로 연결되어 코드 하이라이트와 탭 자동 완성과 같은 기능을 갖춘 SQL 편집기를 제공합니다. 이렇게 보여야 합니다:
SnowSQL에서 기존 데이터베이스에 연결하기
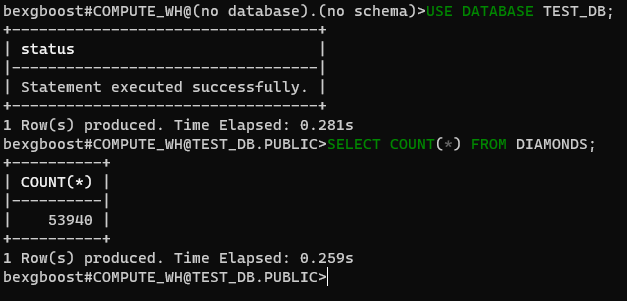
지금은 어떤 데이터베이스에도 연결되어 있지 않습니다. Snowsight로 만든 test_db 데이터베이스에 연결하여 이 문제를 해결합시다. 먼저, SHOW DATABASES로 사용 가능한 데이터베이스를 확인하세요:
$ SHOW DATABASES $ USE DATABASE TEST_DB
다음으로, 이제부터 test_db 데이터베이스(대소문자 구분X)를 사용하겠다고 지정하세요. 그런 다음 연결된 데이터베이스의 테이블에 SQL 쿼리를 실행할 수 있습니다.
$ SELECT COUNT(*) FROM DIAMONDS
SnowSQL에서 새 데이터베이스와 테이블 생성
대형 조직의 일부인 경우, 데이터베이스 생성과 기존 데이터로 채우는 책임이 여러분에게 있을 수 있습니다. 그러한 시나리오를 연습하기 위해, 새 데이터베이스 안의 SnowSQL에서 Diamonds 데이터셋을 테이블로 업로드해 보겠습니다. 다음과 같은 단계를 따라하세요:
1. 새 데이터베이스 생성:
CREATE DATABASE IF NOT EXISTS new_db;
2. 데이터베이스 사용:
USE DATABASE new_db;
3. CSV용 파일 형식 생성:
CREATE OR REPLACE FILE FORMAT my_csv_format -- 어떤 이름으로도 지정할 수 있습니다 TYPE = CSV FIELD_DELIMITER = ',' SKIP_HEADER = 1; -- 첫 번째 행이 헤더라고 가정합니다
변환 결과:
파일 형식을 수동으로 정의하고 이름을 지정해야 합니다. 스노우플레이크(Snowflake)는 CSV, JSON, XML과 같은 데이터 파일의 스키마와 구조를 유추할 수 없기 때문입니다. 위에서 정의한 파일 형식은 우리가 가지고 있는 `diamonds.csv` 파일에 적합합니다 (이것은 쉼표로 구분되어 헤더가 포함되어 있습니다).
4. 내부 스테이지 생성:
CREATE OR REPLACE STAGE my_local_files;
스노우플레이크의 스테이지는 로컬 파일을 업로드할 수 있는 저장 공간입니다. 구조화되거나 반구조화된 데이터 파일이 될 수 있습니다. 위에서는 `my_local_files`라는 이름의 스테이지를 생성합니다.
5. CSV 파일을 스테이지에 넣기:
PUT file:///home/bexgboost/diamonds.csv @my_local_files;
6. 테이블 생성:
CREATE TABLE diamonds ( carat FLOAT, cut VARCHAR(255), color VARCHAR(255), clarity VARCHAR(255), depth FLOAT, table FLOAT, price INTEGER, x FLOAT, y FLOAT, z FLOAT );
7. 스테이지에서 테이블로 데이터 가져오기:
COPY INTO diamonds FROM @my_local_files/diamonds.csv FILE_FORMAT = my_csv_format;
8. 확인:
SELECT COUNT(*) FROM diamonds;
이러한 단계들로 스노우플레이크 데이터베이스를 새로 생성하고 CSV 파일 형식을 정의하고, 로컬 파일을 저장할 스테이지를 생성하고, CSV 파일을 스테이지에 업로드하고, 새 테이블을 생성하고, CSV 데이터를 테이블로 가져오고, 마지막으로 테이블의 로우 수를 세어 작업을 확인합니다.
결과가 로우 수를 반환하면 축하합니다. SnowSQL로 데이터베이스를 생성하고 로컬 데이터를 로드하는 데 성공하였습니다. 이제 테이블을 원하는대로 쿼리할 수 있습니다.
결론과 추가 학습
헉! 간단한 개념으로 시작했지만, 마지막으로 상세한 내용에 집중했습니다. 이렇게 좋은 튜토리얼이라고 생각합니다.
스노우플레이크에는 여러분이 생각할 수 있는 것보다 훨씬 더 많은 내용이 있습니다. 사실 스노우플레이크의 문서에는 128분이나 긴 빠른 시작 가이드도 포함되어 있습니다! 그러나 그들을 다룰 전에 다른 자료로 손을 물들여 보는 것이 어떨까요?
읽어주셔서 감사합니다!
Source:
https://www.datacamp.com/tutorial/introduction-to-snowflake-for-beginners