













O que é um Data Warehouse?
Antes de mergulharmos na arquitetura do Snowflake, vamos revisar os data warehouses para garantir que estamos todos na mesma página.
Um data warehouse é um repositório centralizado que armazena grandes quantidades de dados estruturados e organizados de várias fontes para uma empresa. Diferentes personas (funcionários) nas organizações usam os dados para derivar diferentes insights.
Por exemplo, analistas de dados, em colaboração com a equipe de marketing, podem executar um teste A/B para uma nova campanha de marketing usando a tabela de vendas. Especialistas de RH podem consultar as informações do funcionário para rastrear desempenho.
Estes são alguns exemplos de como empresas em todo o mundo usam data warehouses para impulsionar o crescimento. Mas sem a implementação e gerenciamento adequados usando ferramentas como o Snowflake, os data warehouses permanecem como conceitos elaborados.
Você pode saber mais sobre o assunto com nosso curso de Data Warehousing.
Arquitetura do Snowflake
A arquitetura única do Snowflake, projetada para consultas analíticas mais rápidas, vem de sua separação das camadas de armazenamento e computação. Essa distinção contribui para as vantagens mencionadas anteriormente.
Camada de armazenamento
No Snowflake, a camada de armazenamento é um componente crítico, armazenando dados de uma maneira eficiente e escalável. Aqui estão algumas das funcionalidades chave desta camada:
- Baseado na nuvem: O Snowflake se integra perfeitamente com os principais provedores de nuvem, como AWS, GCP e Microsoft Azure.
- Formato columnar: O Snowflake armazena dados em um formato columnar, otimizado para consultas analíticas. Ao contrário dos formatos baseados em linhas usados por ferramentas como o Postgres, o formato columnar é adequado para a agregação de dados. No armazenamento columnar, as consultas acessam apenas as colunas específicas de que precisam, tornando-o mais eficiente. Por outro lado, os formatos baseados em linhas requerem o acesso a todas as linhas na memória para operações simples, como o cálculo de médias.
- Micro-particionamento: O Snowflake usa uma técnica chamada micro-particionamento que armazena tabelas na memória em pequenos pedaços. Cada pedaço é tipicamente imutável e tem apenas alguns megabytes de tamanho, o que torna a otimização e execução de consultas muito mais rápidas.
- Clonagem sem cópia: O Snowflake tem um recurso único que permite criar clones virtuais de dados. A clonagem é instantânea e não consome memória adicional até que alterações sejam feitas na nova cópia.
- Escalonamento e elasticidade: A camada de armazenamento escala horizontalmente, o que significa que pode lidar com volumes crescentes de dados adicionando mais servidores para distribuir a carga. Além disso, esse escalonamento acontece independentemente dos recursos de computação, o que é ideal quando se deseja armazenar grandes volumes de dados, mas analisar apenas uma pequena fração.
Agora, vamos olhar para a camada de computação.
Camada de computação
Como o nome sugere, a camada de computação é o motor que executa suas consultas. Ela funciona em conjunto com a camada de armazenamento para processar dados e executar várias tarefas de computação. A seguir, há mais detalhes sobre como essa camada opera:
- Virtual Warehouses:Você pode pensar em Virtual Warehouses como times de computadores (nós de computação) projetados para processar consultas. Cada membro do time está lidando com uma parte diferente da consulta, fazendo com que a execução seja impressionantemente rápida e paralela. A Snowflake oferece Virtual Warehouses em diferentes tamanhos, e consequentemente, em preços diferentes (os tamanhos incluem XS, S, M, L, XL).
- Arquitetura multi-cluster, multi-node:A camada de computação usa vários cluster com vários nós para alta concorrência, permitindo que vários usuários acessem e consultem os dados simultaneamente.
- Otimização de consulta automática: O sistema da Snowflake analisa todas as consultas e identifica padrões para serem otimizados usando dados históricos. As otimizações comuns incluem poupar dados desnecessários, usar metadados e escolher o caminho de execução mais eficiente.
- Cache de resultados:A camada de computação inclui um cache que armazena os resultados das consultas executadas frequentemente. Quando a mesma consulta é executada novamente, os resultados são retornados quase instantaneamente.
Estes princípios de projeto da camada de computação contribuem para a capacidade da Snowflake de lidar com diferentes e demandantes cargas de trabalho na nuvem.
Camada de serviços de nuvem
A camada final é o serviço em nuvem. Como esta camada integra-se a cada componente da arquitetura do Snowflake, há muitos detalhes sobre sua operação. Além das funcionalidades relacionadas às outras camadas, ela tem as seguintes responsabilidades adicionais:
- Segurança e controle de acesso: Esta camada aplica medidas de segurança, incluindo autenticação, autorização e criptografia. Administradores usam o Controle de Acesso baseado em papéis (RBAC) para definir e gerenciar papéis de usuário e permissões.
- Compartilhamento de dados: Esta camada implementa protocolos de compartilhamento de dados seguros entre diferentes contas e até organizações terceiras. Os consumidores de dados podem acessar os dados sem a necessidade de mover dados, promovendo colaboração e monetização de dados.
- Suporte a dados semi-estruturados: Outra vantagem única do Snowflake é sua capacidade de lidar com dados semi-estruturados, como JSON e Parquet, mesmo sendo uma plataforma de gerenciamento de armazenamento de dados. Ele pode facilmente consultar dados semi-estruturados e integrar os resultados com tabelas existentes. Esta flexibilidade não é vista em outras ferramentas RDBMS.
Agora que temos uma imagem de alto nível da arquitetura do Snowflake, vamos escrever algum SQL na plataforma.
Configurando o SnowflakeSQL
O Snowflake tem sua própria versão do SQL chamada SnowflakeSQL. A diferença entre ele e outros dialetos de SQL é semelhante à diferença entre os acentos de inglês.
Muitas das consultas analíticas que você realiza em dialetos como o PostgreSQL não mudam, mas há discrepâncias em algumas comandos de DDL (Linguagem de Definição de Dados).
O Snowflake fornece dois interfaces para executar o SnowSQL:
- Snowsight: Uma interface web para interagir com a plataforma.
- SnowSQL: Um cliente CLI (Interface de Linha de Comandos) para gerenciar e consultar bancos de dados.
Veremos como configurar ambos e executar algumas consultas!
Snowsight: Interface web
Para começar com Snowsight, acesse a página inicial do Snowflake e selecione “Iniciar grátis.” Insira suas informações pessoais e selecione qualquer provedor de nuvem listado. A escolha realmente não importa, pois a avaliação gratuita inclui créditos de valor de US$ 400 para qualquer das opções (você não será obrigado a configurar as credenciais de nuvem por conta própria).
Após verificar seu e-mail, você será redirecionado para a página de Planilhas. As Planilhas são ambientes interativos de programação em tempo real onde você pode escrever, executar e visualizar os resultados de suas consultas SQL.
Para executar algumas consultas, precisamos de um banco de dados e uma tabela (nós não usaremos os dados de exemplo no Snowsight). O GIF abaixo mostra como você pode criar um novo banco de dados chamado “test_db” e uma tabela chamada “diamonds” usando um arquivo CSV local. Você pode baixar o arquivo CSV executando o código em este gist do GitHub no seu terminal.
No GIF, o Snowsight nos informa que há um problema com um dos nomes de coluna.since a palavra “table” é uma palavra-chave reservada, eu lavei com aspas duplas.
Depois disso, você será direcionado para uma nova planilha onde pode executar qualquer consulta SQL que desejar. Como mostrado no GIF, a interface da planilha é bastante direta e altamente funcional. Reserve alguns minutos para se familiarizar com os painéis, os botões e suas respectivas localizações.
SnowSQL: CLI
Nada supera a emoção de gerenciar e consultar um banco de dados completo a partir de seu terminal. É por isso que o SnowSQL existe!
No entanto, para começá-lo a funcionar, há algumas etapas que precisamos seguir, o que é normalmente um processo mais lento do que começar com o Snowsight.
Como primeira etapa, baixe o instalador do SnowSQL na página de Download para Desenvolvedores da Snowflake. Baixe o arquivo relevante. Como estou usando o WSL2, escolherei a versão Linux:

No terminal, eu baixo o arquivo usando o link copiado e executo com o bash:
$ curl -O https://sfc-repo.snowflakecomputing.com/snowsql/bootstrap/1.2/linux_x86_64/snowsql-1.2.31-linux_x86_64.bash $ bash snowsql-1.2.31-linux_x86_64.bash
Para outras plataformas, você pode seguir as etapas de instalação a partir da página desta documentação da Snowflake.
Uma vez instalado com sucesso, você deve receber a seguinte mensagem:
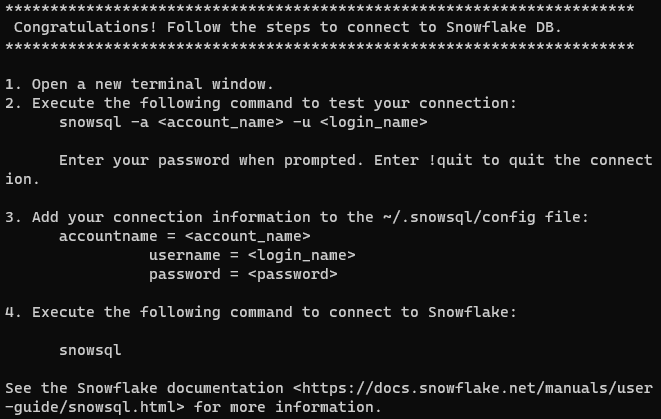
Note: Em sistemas Unix-like, é importante garantir que o comando snowsql esteja disponível em todas as sessões do terminal. Para conseguir isso, você deve adicionar o diretório /home/username/bin à sua variável $PATH. Você pode fazer isso adicionando a seguinte linha aos seus arquivos .bashrc, .bash_profile ou .zshrc: export PATH=/home/yourusername/bin:$PATH. Lembre-se de substituir yourusername pelo seu usuário real.
A mensagem está solicitando que configure as configurações de conta para conectar ao Snowflake. Há duas maneiras de fazer isso:
- Passe os detalhes da conta interativamente no terminal.
- Configure as credenciais em um arquivo de configuração global do Snowflake.
Visto que é mais permanente e seguro, vamos seguir a segunda opção. Para instruções específicas da plataforma, leia a página Conectando-se através do SnowSQL da documentação. As instruções abaixo são para sistemas Unix-like.
Primeiro, vá para o seu endereço de e-mail e encontre o e-mail de boas-vindas do Snowflake. Ele contém o nome da conta dentro do link de login: account-name.snowflakecomputing.com. Copie-o.
Em seguida, abra o arquivo ~/.snowsql/config com um editor de texto como VIM ou VSCode. Na seção connections, comente as seguintes três campos:
- Nome da conta
- Nome de usuário
- Senha
Substitua os valores padrão pelo nome de conta que você copiou e pelo nome de usuário e senha que você forneceu durante o registro. Depois que você tiver feito isso, salve e feche o arquivo.
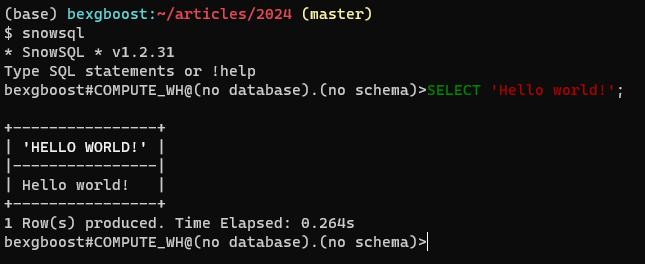
Então, volte para seu terminal e insira snowsql. O cliente deve conectar automaticamente e fornecer um editor SQL que inclui recursos como destaque de código e tabulação automática. Aqui é o que deve parecer:
Conectando a um banco de dados existente no SnowSQL
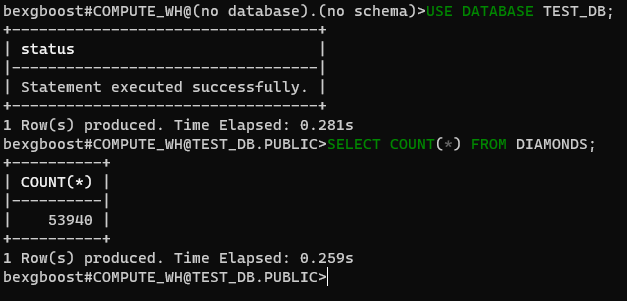
No momento, não estamos conectados a nenhum banco de dados. Vamos corrigir isso conectando-nos ao banco de dados test_db que criamos com o Snowsight. Primeiro, verifique os bancos de dados disponíveis com SHOW DATABASES:
$ SHOW DATABASES $ USE DATABASE TEST_DB
A seguir, especifique que você irá usar o banco de dados test_db (case-insensitive) a partir de agora. Em seguida, você pode executar qualquer consulta SQL nas tabelas do banco de dados conectado.
$ SELECT COUNT(*) FROM DIAMONDS
Criando um novo banco de dados e tabela no SnowSQL
Se você faz parte de uma organização grande, existem casos em que a responsabilidade de criar um banco de dados e preencher com dados existentes pode caber a você. Para praticar esse cenário, vamos tentar carregar o conjunto de dados Diamonds como uma tabela no SnowSQL dentro de um novo banco de dados. Aqui estão as etapas que você pode seguir:
1. Crie um novo banco de dados:
CREATE DATABASE IF NOT EXISTS new_db;
2. Use o banco de dados:
USE DATABASE new_db;
3. Crie um formato de arquivo para CSV:
CREATE OR REPLACE FILE FORMAT my_csv_format -- Pode ser chamado de qualquer coisa TYPE = CSV FIELD_DELIMITER = ',' SKIP_HEADER = 1; -- Supondo que a primeira linha seja um cabeçalho
Nós devemos definir manualmente um formato de arquivo e nomeá-lo porque o Snowflake não consegue inferir o esquema e estrutura dos arquivos de dados, como CSV, JSON ou XMLs. O formato de arquivo definido acima é adequado para o arquivo diamonds.csv que temos (ele é separado por vírgulas e inclui um cabeçalho).
4. Criar um estoque interno:
CREATE OR REPLACE STAGE my_local_files;
Um estoque em Snowflake é um espaço de armazenamento onde você pode carregar seus arquivos locais. Esses podem ser arquivos de dados estruturados e semi-estruturados. Acima, estamos criando um estoque chamado my_local_files.
5. Colocar o arquivo CSV no estoque:
PUT file:///home/bexgboost/diamonds.csv @my_local_files;
6. Criar a tabela:
CREATE TABLE diamonds ( carat FLOAT, cut VARCHAR(255), color VARCHAR(255), clarity VARCHAR(255), depth FLOAT, table FLOAT, price INTEGER, x FLOAT, y FLOAT, z FLOAT );
7. Carregar dados do estoque para a tabela:
COPY INTO diamonds FROM @my_local_files/diamonds.csv FILE_FORMAT = my_csv_format;
8. Verificar:
SELECT COUNT(*) FROM diamonds;
Estes passos criarão um novo banco de dados do Snowflake, definirão um formato de arquivo CSV, criarão um estoque para armazenar arquivos locais, carregarão um arquivo CSV no estoque, criarão uma nova tabela, carregarão os dados CSV na tabela, e finalmente verificarão a operação contando o número de linhas na tabela.
Se o resultado retornar o conteúdo de linhas, parabéns, você criou com sucesso um banco de dados e carregou dados locais nele com o SnowSQL. Agora, você pode consultar a tabela de qualquer forma que desejar.
Conclusão e aprendizado adicional
Uau! Começamos com algumas ideias simples, mas no final, mergulharmos mesmo nos detalhes complicados. Bem, essa é minha ideia de um tutorial decente.
Você provavelmente adivinhou que existe muito mais a Snowflake do que o que nós cover. Na verdade, a documentação do Snowflake inclui guias de início rápido que são mesmo de 128 minutos de longe! Mas antes de você abordar isso, recomendo que você explore outros recursos. O que sobre estes:
- Curso de Introdução ao Snowflake
- Webinar sobre a modernização das análises de vendas com o Snowflake
- Análise de dados no Snowflake usando o código Python
- Guias do usuário oficiais do Snowflake
- Recursos para desenvolvedores do Snowflake
Obrigado por ler!
Source:
https://www.datacamp.com/tutorial/introduction-to-snowflake-for-beginners