













Wat is een Data Warehouse?
Voordat we in de architectuur van Snowflake duiken, lijken we eerst even terug te gaan naar datawarehouses om ervoor te zorgen dat we allemaal op dezelfde golflengte zitten.
Een data warehouse is een centrale opslagplaats die grote hoeveelheden gestructureerde en georganiseerde gegevens uit verschillende bronnen voor een bedrijf bewaart. Verschillende persoonlijkheden (werknemers) in organisaties gebruiken deze gegevens om verschillende inzichten te verkrijgen.
Bijvoorbeeld, data analisten, in samenwerking met het marketingteam, kunnen een A/B-test uitvoeren voor een nieuwe marketingcampagne met behulp van de verkooptabel. HR-specialisten kunnen de informatie over werknemers opvragen om prestaties bij te houden.
Dit zijn enkele voorbeelden van hoe bedrijven wereldwijd datawarehouses gebruiken om groei aan te jagen. Maar zonder de juiste implementatie en beheer met tools zoals Snowflake blijven datawarehouses ingewikkelde concepten.
U kunt meer over dit onderwerp leren met onze Data Warehousing cursus.
Snowflake Architectuur
De unieke architectuur van Snowflake, ontworpen voor snellere analytische query’s, komt van de scheiding van de opslag- en berekeningslagen. Deze onderscheidt zich door bij te dragen aan de eerder genoemde voordelen.
Opslaglaag
In Snowflake is de opslaglaag een kritiek onderdeel, dat gegevens op een efficiente en schaalbare manier bewaart. Hier zijn enkele belangrijke kenmerken van deze laag:
- Cloudgebaseerd: Snowflake integreert naadloos met belangrijke cloudproviders zoals AWS, GCP en Microsoft Azure.
- Kolomformaat: Snowflake slaat gegevens op in een kolomformaat, geoptimaliseerd voor analytische query’s. Anders dan de traditionele rijgebaseerde formaten gebruikt door tools zoals Postgres, is het kolomformaat zeer geschikt voor gegevensaggregatie. In kolomopslag worden alleen de specifieke kolommen benaderd die nodig zijn, waardoor dit meer efficient is. Aan de andere kant vereisen rijgebaseerde formaten het benaderen van alle rijen in het geheugen voor simpele bewerkingen zoals het berekenen van gemiddelden.
- Micro-partitieer: Snowflake gebruikt een techniek genaamd micro-partitieering die tabellen in het geheugen opslaat in kleine brokken. Elke brok is meestal onveranderlijk en bestaat uit slechts een paar megabytes, waardoor query-optimalisatie en uitvoering veel sneller gaan.
- Zerokopiëren clonen: Snowflake heeft een unieke functie die het mogelijk maakt virtuele klonen van gegevens te maken. Het klonen is onmiddellijk en verbruikt geen extra geheugen totdat er wijzigingen worden aangebracht in de nieuwe kopie.
- Schaal en elasticiteit: De opslaglaag schaalt horizontaal, wat betekent dat het steeds meer gegevensvolumes kan verwerken door meer servers toe te voegen om de belasting te verdelen. Ook schaalt dit onafhankelijk van computermiddelen, wat ideaal is als u grote hoeveelheden gegevens wilt opslaan maar slechts een klein deel wilt analyseren.
Laat nu eens kijken naar de computelaag.
Computelaag
Zoals de naam al aangeeft, is de compute-laag het mechanisme dat uw query’s uitvoert. Het werkt samen met de opslaglaag om gegevens te verwerken en diverse berekeningen uit te voeren. Hieronder meer details over hoe deze laag functioneert:
- Virtuele magazijnen: Je kunt virtuele magazijnen zien als teams van computers (compute nodes) die zijn ontworpen voor het afhandelen van query-verwerking. Elke teamlid behandelt een ander deel van de query, wat de uitvoering uitzonderlijk snel en parallel maakt. Snowflake biedt virtuele magazijnen in verschillende grootten en daarbij horende prijzen (de grootten zijn XS, S, M, L, XL).
- Multi-cluster, multi-node architectuur: De compute-laag gebruikt meerdere clusters met meerdere nodes voor hoge concurrentie, waardoor verschillende gebruikers tegelijkertijd toegang hebben tot de gegevens en queries kunnen uitvoeren.
- Automatische query-optimalisatie: Het systeem van Snowflake analyseert alle queries en zoekt patronen om met behulp van historische gegevens te optimaliseren. Gewone optimalisaties zijn het verwijderen van onnodige gegevens, het gebruik van metadata, en het kiezen van de meest efficiënte uitvoeringspad.
- Resultatencache: De compute-laag bevat een cache die de resultaten van vaak uitgevoerde queries opslaat. Als dezelfde query nogmaals wordt uitgevoerd, worden de resultaten bijna onmiddellijk teruggegeven.
Deze ontwerpprincipes van de compute-laag dragen allemaal bij aan Snowflake’s vermogen om verschillende en eisenhoge werklasten in de cloud af te handelen.
Cloud services-laag.
De laatste laag is clouddiensten. Aangezien deze laag in elk component van de architectuur van Snowflake is ingebouwd, zijn er veel details over haar werking. Naast de functies die samenhangen met andere lagen heeft het de volgende extra taken:
- Beveiliging en toegangscontrole:Deze laag handhaaft beveiligingsmaatregelen, inclusief authenticatie, autorisatie en encryptie. Beheerders gebruiken Rollen gebaseerde Toegangs Controle (RBAC) om gebruikersrollen en toestemmingen te definiëren en te beheren.
- Gegevensdeling:Deze laag implementeert veilige gegevensdelingprotocollen over verschillende accounts en zelfs door derde partijen. Gegevensconsumenten kunnen de gegevens bereiken zonder dat er gegevens moeten worden verplaatst, wat de samenwerking en gegevensmonetarisering bevordert.
- Ondersteuning voor semi-gestructureerde data:Een unieke voordelen van Snowflake is zijn vermogen om semi-gestructureerde data te behandelen, zoals JSON en Parquet, hoewel het een platform voor datawarehousebeheer is. Het kan gemakkelijk queries uitvoeren op semi-gestructureerde data en de resultaten integreren met bestaande tabellen. Deze flexibiliteit wordt niet gezien in andere RDBMS-hulpmiddelen.
Nu we een hoog niveau over de architectuur van Snowflake hebben, laten we op het platform wat SQL schrijven.
SnowflakeSQL instellen
Snowflake heeft zijn eigen versie van SQL, genaamd SnowflakeSQL. Het verschil tussen deze en andere SQL-dialecten is vergelijkbaar met het verschil tussen Engelse accenten.
Veel van de analytische queries die u uitvoert in dialecten zoals PostgreSQL veranderen niet, maar er zijn sommige afwijkingen in de DDL (Data Definition Language)-opdrachten.
Snowflake biedt twee interfaces om SnowSQL uit te voeren:
- Snowsight: Een webinterface voor interactie met de platform.
- SnowSQL: Een CLI (Command Line Interface) client voor het beheren en queryën van databases.
We zullen kijken hoe je beide kunt instellen en enkele query’s kunt uitvoeren!
Snowsight: Webinterface
Om te beginnen met Snowsight, navigeer naar de Snowflake thuispagina en selecteer “Gratis starten”. Voer uw persoonlijke gegevens in en selecteer een van de genoemde cloudproviders. Het keuze maakt niet echt uit, omdat de gratis proefversie $400 aan credits bevat voor alle opties (u hoeft zelf geen cloudgegevens in te stellen).
Nadat u uw e-mail heeft geverifieerd, wordt u doorgestuurd naar de Worksheetspagina. Worksheets zijn interactieve, live-coding omgevingen waar u SQL-query’s kunt schrijven, uitvoeren, en de resultaten ervan kunt bekijken.
Om enkele query’s uit te voeren, hebben we een database en een tabel nodig (we zullen de voorbeeldgegevens in Snowsight niet gebruiken). De GIF hieronder toont hoe u een nieuwe database genaamd “test_db” en een tabel genaamd “diamonds” kunt maken met behulp van een lokale CSV-bestand. U kunt het CSV-bestand downloaden door de code in deze GitHub gist in uw terminal uit te voeren.
In de GIF geeft Snowsight aan dat er een probleem is met een van de kolomnamen. Omdat “table” een gereserveerd keyword is, heb ik het tussen dubbele aanhalingstekens geplaatst.
Na het voltooien zult u naar een nieuw werkblad worden geleid waar u elke gewenste SQL-query kunt uitvoeren. Zoals in de GIF getoond, is het interface van het werkblad zeer rechttoe zeggend en zeer functioneel. Neem een paar minuten om uzelf bekend te maken met de panelen, de knoppen en hun respectievelijke locaties.
SnowSQL: CLI
Niets bepaalt de spanning zoals het beheren en query’en van een volwaardige database vanuit uw terminal. Daarom bestaat SnowSQL!
Om het echter op gang te krijgen, moeten we een aantal stappen volgen, wat een langzamere proces is dan aan de slag gaan met Snowsight.
Als eerste stap downloadt u de SnowSQL-installateur vanaf de Snowflake Developers Download-pagina. Download het relevante bestand. Aangezien ik WSL2 gebruik, kies ik een Linux-versie:

In de terminal download ik het bestand met de gekopieerde link en voer het uit met bash:
$ curl -O https://sfc-repo.snowflakecomputing.com/snowsql/bootstrap/1.2/linux_x86_64/snowsql-1.2.31-linux_x86_64.bash $ bash snowsql-1.2.31-linux_x86_64.bash
Voor andere platformen kunt u de installatiestappen volgen vanaf deze pagina van de Snowflake-documentatie.
Als de installatie succesvol is voltooid, zou u het volgende bericht moeten ontvangen:
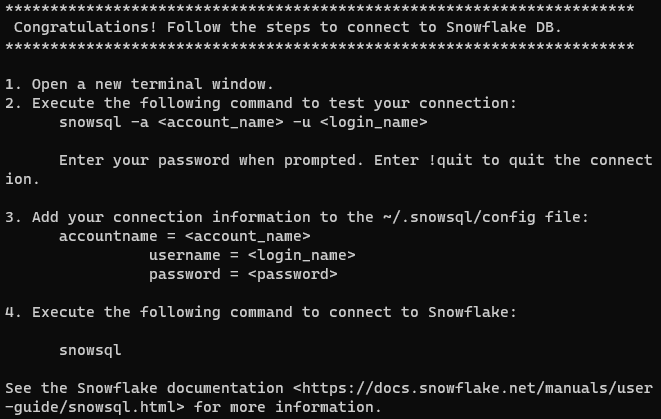
Let op: Op Unix-achtige systemen is het belangrijk om ervoor te zorgen dat het snowsql commando beschikbaar is in alle terminalsessies. Om dit te bereiken, moet je de /home/username/bin directory toevoegen aan je $PATH variabele. Je kunt dit doen door de volgende regel toe te voegen aan je .bashrc, .bash_profile, of .zshrc bestanden: export PATH=/home/yourusername/bin:$PATH. Vervang yourusername door je eigen gebruikersnaam.
De boodschap vraagt ons om de accountinstellingen te configureren om verbinding te maken met Snowflake. Er zijn twee manieren om dit te doen:
- Voer de accountgegevens interactief in de terminal in.
- Configureer de inloggegevens in een algemene Snowflake configuratiebestand.
Aangezien deze manier duurzamer en veiliger is, gaan we door met de tweede optie. Voor platformspecifieke instructies, lees de Verbinding maken via SnowSQL pagina van de documentatie. De instructies hieronder zijn voor Unix-achtige systemen.
Ga eerst naar je e-mailadres en zoek de welkomstmail van Snowflake. Het bevat je accountnaam in de login-link: account-name.snowflakecomputing.com. Kopieer het.
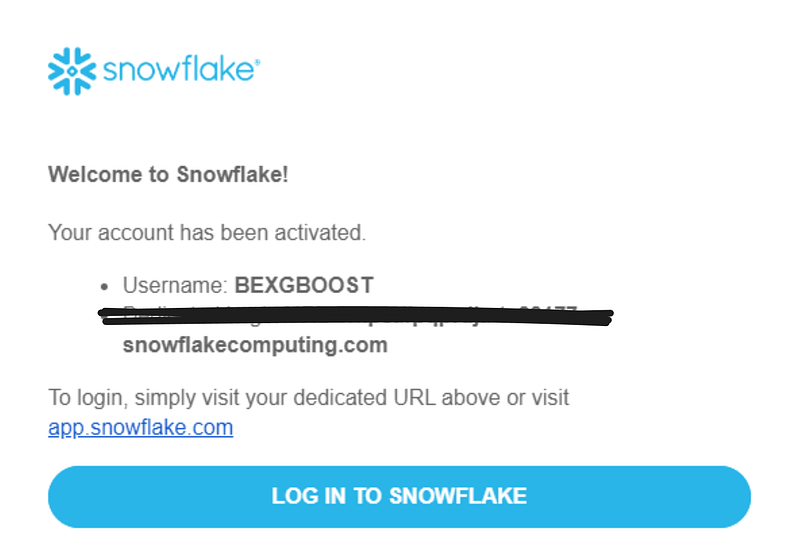
Open vervolgens het ~/.snowsql/config bestand met een teksteditor zoals VIM of VSCode. Onder de connections sectie, uncomment de volgende drie velden:
- Account naam
- Gebruikersnaam
- Wachtwoord
Vervang de standaardwaarden door de accountnaam die je hebt gekopieerd en de gebruikersnaam en wachtwoord die je tijdens het aanmelden hebt gegeven. Daarna moet je het bestand opslaan en sluiten.
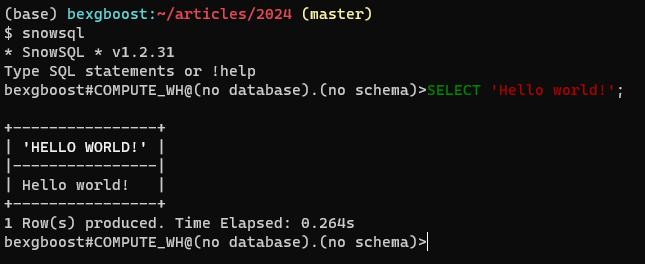
Keer daarna terug naar je terminal en typ snowsql. De client moet automatisch verbinden en biedt je een SQL-editor met functies zoals code-highlighting en tab-voltooiing. Het zou er ongeveer zo uit moeten zien:
Verbinden met een bestaande database in SnowSQL
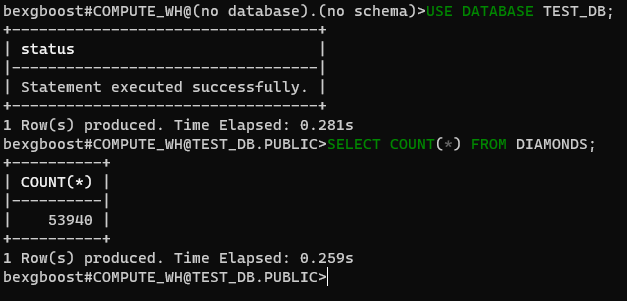
Op dit moment zijn we niet verbonden met een database. Laten we dat verhelpen door te verbinden met de test_db database die we met Snowsight hebben gemaakt. Eerst, controleer beschikbare databases met SHOW DATABASES:
$ SHOW DATABASES $ USE DATABASE TEST_DB
Daarna, geef aan dat je vanaf nu de test_db database (hoofdletterongevoelig) gaat gebruiken. Vervolgens kun je elke SQL-query uitvoeren op de tabellen van de verbonden database.
$ SELECT COUNT(*) FROM DIAMONDS
Creëer een nieuwe database en tabel in SnowSQL
Als je deel uitmaakt van een groot bedrijf, kunnen er gevallen zijn waarbij het verantwoordelijkheid om een database aan te maken en deze met bestaande gegevens te vullen op je schouders ligt. Om daarvoor te oefenen, laten we eens proberen het Diamonds dataset als tabel in SnowSQL te uploaden binnen een nieuwe database. Hier zijn de stappen die je kunt volgen:
1. Creëer een nieuwe database:
CREATE DATABASE IF NOT EXISTS new_db;
2. Gebruik de database:
USE DATABASE new_db;
3. Creëer een bestandsformaat voor CSV:
CREATE OR REPLACE FILE FORMAT my_csv_format -- Mag elke naam hebben TYPE = CSV FIELD_DELIMITER = ',' SKIP_HEADER = 1; -- Aanname dat de eerste rij een header is
We moeten handmatig een bestandsformaat definiëren en het een naam geven, omdat Snowflake niet kan afleiden van het schema en de structuur van gegevensbestanden zoals CSV, JSON of XML’s. Het bestandsformaat dat we hierboven hebben gedefinieerd, is geschikt voor het diamonds.csv-bestand dat we hebben (het is kommagescheiden en bevat een header).
4. Een intern stadium maken:
CREATE OR REPLACE STAGE my_local_files;
Een stadium in Snowflake is een opslagruimte waarin u uw lokale bestanden kunt uploaden. Deze kunnen gestructureerde en half-gestructureerde gegevensbestanden zijn. Hierboven maken we een stadium genaamd my_local_files.
5. Plaats het CSV-bestand in het stadium:
PUT file:///home/bexgboost/diamonds.csv @my_local_files;
6. Maak de tabel:
CREATE TABLE diamonds ( carat FLOAT, cut VARCHAR(255), color VARCHAR(255), clarity VARCHAR(255), depth FLOAT, table FLOAT, price INTEGER, x FLOAT, y FLOAT, z FLOAT );
7. Laad gegevens vanuit het stadium in de tabel:
COPY INTO diamonds FROM @my_local_files/diamonds.csv FILE_FORMAT = my_csv_format;
8. Verifieer:
SELECT COUNT(*) FROM diamonds;
Deze stappen zullen een nieuwe Snowflake-database maken, een CSV-bestandsformaat definiëren, een stadium maken om lokale bestanden op te slaan, een CSV-bestand naar het stadium uploaden, een nieuwe tabel maken, de CSV-gegevens in de tabel laden en tenslotte de bewerking verifiëren door het tellen van de aantal rijen in de tabel.
Als het resultaat het aantal rijen teruggeeft, gefeliciteerd, u heeft met succes een database gemaakt en lokale gegevens daarin geladen met SnowSQL. Nu kunt u de tabel op elk gewenst manier bevragen.
Conclusie en verdere leeromgeving
Wow! We zijn begonnen met enkele simpele concepten, maar uiteindelijk zijn we diep in de details doorgedrongen. Dat is mijn idee van een goede tutorial.
Je bent vast al begonnen te vermoeden dat er meer bij Snowflake zit dan we tot nu toe hebben besproken. In feite bevat de Snowflake-documentatie quickstart-gidsen die eigenlijk 128 minuten lang zijn! Maar voordat je die aanpakt, raden we aan om je voeten eerst in het water te doen met andere middelen. Hoe zit het met deze:
- Introductiecursus over Snowflake
- Webinar over het moderniseren van verkoopanalyse met Snowflake
- Data-analyse in Snowflake met behulp van Python-code-along
- Officiële gebruikersgidsen van Snowflake
- Ontwikkelaarshulpmiddelen voor Snowflake
Bedankt voor het lezen!
Source:
https://www.datacamp.com/tutorial/introduction-to-snowflake-for-beginners