













データウェアハウスとは何ですか?
サノフレークのアーキテクチャに入り込む前に、データウェアハウスについて確認し、共通の理解を得るために見ていきましょう。
データウェアハウスは、会社内の様々なソースからの大量の構造化されたデータを中央集約して格納するリポジトリです。組織内の異なる人物(従業員)は、そのデータを使って異なる洞察を導き出します。
例えば、データアナリストはマーケティングチームと共同で、新しいマーケティングキャンペーンにA/Bテストを行うために売上テーブルを使用します。人事スペシャリストは従業員情報をクエリーし、パフォーマンスを追跡するかもしれません。
これらは、会社が世界規模でデータウェアハウスを使って成長を推進するいくつかの例です。しかし、サノフレークのようなツールを使って適切な実装と管理が行われない限り、データウェアハウスは洗練された概念のままです。
我々のデータウェアハウスコースを使ってこの主題について更に学ぶことができます。
サノフレークのアーキテクチャ
サノフレークのユニークなアーキテクチャは、ストレージとコンピュートレイヤーを分離するよう設計されており、これがより迅速な分析クエリーを可能にしています。この区別は、先程提及其の恩恵に貢献しています。
ストレージレイヤー
サノフレークでは、ストレージレイヤーは重要なコンポーネントであり、データを効率的かつ拡張可能な方法で格納します。このレイヤーの主要な特徴には以下のようなものがあります:
- クラウドベース:SnowflakeはAWS、GCP、Microsoft Azureなどの主要なクラウド提供者と无缝に統合しています。
- 列アーray形式:Snowflakeはデータを列アーray形式で存储しています。これは分析クエリに最適化されています。Postgresなどのツールが使用する传统的な行アーray形式とは異なり、列アーray形式はデータの集積に最適です。列アーrayストレージでは、クエリは必要な列しか访问しませんので、より効率が良いです。これに対して、行アーray形式は、平均計算などの単純な操作において、全ての行をメモリにアクセスする必要があります。
- マイクロパーティション:Snowflakeはマイクロパーティション技術を使用して、テーブルをメモリ上に小さなチャンクで存储しています。各チャンクは通常変更不可で、数メガBYTE程度の大きさです。これによりクエリの最適化と実行が大幅に速まれます。
- ゼロコピークランニング:Snowflakeは、データの仮想クローンを作成する独自の機能を持っています。クローン作成は即座に行われ、新しいコピーに変更がない限り追加のメモリを消費しません。
- スケールと弾性:ストレージ層は水平方向にスケールすることができ、データ量の増加に応じてサーバを追加して負荷分散を行います。また、このスケーリングは計算リソースとは独立して行われます。これは大量のデータを存储していくにしたがって、分析を行う際の負荷に対応するのに最適です。
今は、計算層について見てみましょう。
計算層
computelayerは、クエリの実行エンジンとして機能し、ストレージ層と一緒にデータの処理と様々な計算任务の実行を行います。以下は、この層の操作方法に関する詳細な情報です。
- 仮想倉庫:仮想倉庫を、クエリ処理を行うコンピュータのチームと考えることができます。チームのメンバーがクエリの異なる部分を処理し、実行が驚くほど速く、並行に行われます。Snowflakeは異なるサイズの仮想倉庫を提供し、それに応じて異なる価格を提供します(サイズにはXS、S、M、L、XLが含まれます)。
- マルチクラスタ、マルチノードアーキテクチャ:computelayerは、高コンカーシティを実現するために、複数のクラスタを複数のノードで使用します。これにより、いくつかのユーザーが同時にデータにアクセスしてクエリを実行することができます。
- 自動クエリ最適化:Snowflakeのシステムはすべてのクエリを分析し、履歴データを使用して最適化するパターンを识別します。一般的な最適化には、不要なデータを省くこと、メタデータを使用すること、最も効率的な実行パスを選択することが含まれます。
- 結果キャッシュ:computelayerには、頻繁に実行されるクエリの結果を保存するキャッシュが含まれています。同じクエリを再実行すると、結果はほぼすぐに返されます。
computelayerの設計原則は、Snowflakeがクラウド上で様々な要求の多いワークロードを処理することができる能力を貢献します。
クラウドサービス層
最終的な層はクラウドサービスです。この層はSnowflakeのアーキテクチャのすべてのコンポーネントに統合されているため、その操作には多くの詳細があります。他の層に関連する機能に加えて、以下の追加の責任があります。
- セキュリティとアクセスコントロール:この層は、認証、認可、および暗号化を含む安全対策を実行します。管理者は、役割基のアクセスコントロール(RBAC)を使用して、ユーザーの役割と権限を定義し管理します。
- データ共有:この層は、異なるアカウントや第三者組織間で安全なデータ共有プロトコルを実施します。データの消費者は、データの移動を必要としないで、データ共有とデータモネタイズを促進することができます。
- 半構造化データサポート:Snowflakeは、データウェアハウス管理プラットフォームであるとして、JSONやParquetなどの半構造化データを処理することができる独特の利点があります。半構造化データを簡単にクエリーし、既存のテーブルと結果を統合することができます。この柔軟性は他のRDBMSツールには見られません。
Snowflakeのアーキテクチャを高层次に把握したので、 PlatformでSQLを書いてみましょう。
SnowflakeSQLの設定
Snowflakeには独自のSQLバージョンがあり、それは他のSQL方言との違いは、英語のアクセントとの違いに似ています。
PostgreSQLなどの方言で行っていた分析クエリの多くは変更しないものの、DDL(データ定義言語)コマンドには若干の矛盾があることがあります。
SnowflakeはSnowSQLを実行するための2つのインターフェースを提供します。
- Snowsight: このプラットフォームと交互的に操作するためのウェブインターフェースです。
- SnowSQL: データベースの管理とクエリを実行するためのCLI(コマンドラインインターフェース)クライアントです。
この两者の設定方法とクエリの実行方法を学びましょう!
Snowsight: Webインターフェース
Snowsightを始めるには、Snowflakeの公式ホームページに移動し、「無料試用」を選択します。個人情報を入力し、リストにある任意のクラウドプロバイダーを選択してください。選択したものがどのような影響を与えるのかということは重要ではありません、無料試用には各選択肢につき$400のクレジットが含まれていて、自分でクラウドの資格を設定する必要はありません。
メールアドレスを確認する後、あなたはWorksheetsページに飛び迂まれます。Worksheetsはインタラクティブなライブコーディング環境であり、SQLクエリを書いて、実行し、結果を表示することができます。
クエリを実行するためには、データベースとテーブルが必要です(Snowsightのサンプルデータは使用しません)。以下のGIFは、ローカルのCSVファイルを使用して新しいデータベース“test_db”とテーブル“diamonds”を作成する方法を示しています。CSVファイルは、ターミナルでGitHub gistのコードを実行することで下载することができます。
GIFの中で、Snowsightは某一の列名に問題があることを教えてくれます。たとえば、「table」は予約語であるため、双引号で囲んだことで解決しました。
後で、新しいワークシートに移動し、意図するSQLクエリを実行することができます。GIFによると、ワークシートインターフェースは非常に直观的で機能的です。パネル、ボタンとそれらのそれぞれの位置について数分で熟悉するのがお勧めです。
SnowSQL: CLI
ターミナルから完全なデータベースを管理し、クエリを実行することの Excitation には SnowSQL があります!
しかし、始めるためには、いくつかの手順を経る必要がありますが、これは Snowsight を始めるのに比べて一般的には遅いプロセスです。
最初の手順として、 Snowflake Developers Download 页から SnowSQL インストーラーを下载します。適切なファイルを下载してください。WSL2を使用しているので、Linux バージョンを選ぶことにします。

ターミナルで、コピーしたリンクを使用してファイルを下载し、bash で実行します。
$ curl -O https://sfc-repo.snowflakecomputing.com/snowsql/bootstrap/1.2/linux_x86_64/snowsql-1.2.31-linux_x86_64.bash $ bash snowsql-1.2.31-linux_x86_64.bash
他のプラットフォームにおいては、 Snowflake 文書のこのページ からインストール手順に従ってください。
インストールが成功すると、以下のメッセージが表示されるはずです。
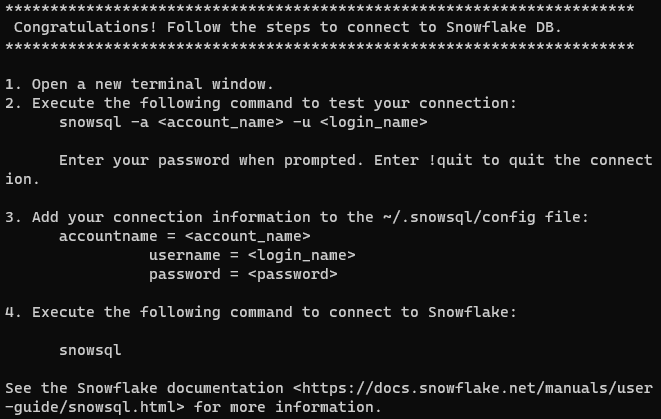
snowsqlコマンドが全てのターミナルセッションに利用可能であることを確認することがUnix-likeシステムで重要です。これを実現するために、/home/username/binディレクトリを$PATH変数に追加する必要があります。これは、.bashrc、.bash_profile、または.zshrcファイルに以下の行を追記することで行います。export PATH=/home/yourusername/bin:$PATH。yourusernameを実際のユーザー名に置き換えてください。
このメッセージは、Snowflakeに接続するためのアカウント設定を行うように促しています。これを行うには2つの方法があります。
- ターミナルでアカウントの詳細を interactively 渡す。
- 資格情報をglobalsnowflake設定ファイルに設定する。
永続的で安全な方法だから、第2の方法を選んで進めます。プラットフォーム固有の指示については、 SnowSQLを通して接続する 文書のページを読むことです。以下の指示はUnix-likeシステム向けです。
まず、Snowflakeからのようになりましたような Welcome メールにアクセスします。これにはアカウント名がloginリンクの中に含まれています: account-name.snowflakecomputing.com。それをコピーします。
次に、VIMやVSCodeなどのテキストエディタで~/.snowsql/configファイルを開きます。connections節に以下の3つのフィールドをアンコメント化します。
- アカウント名
- ユーザー名
- パスワード
アカウント名とサインアップ時に提供したユーザー名とパスワードでデフォルトの値を置き換えてください。それを行った後、ファイルを保存して閉じます。
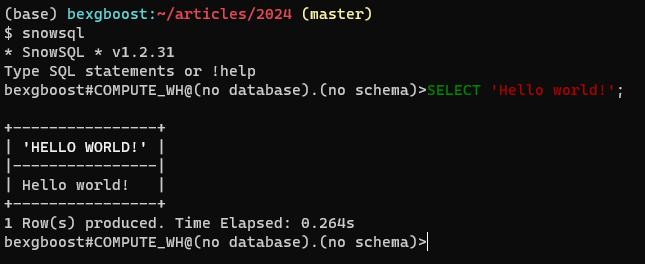
次に、ターミナルに戻り、snowsqlを入力します。クライアントは自動的に接続し、コードハイライトやタブ補完などの機能を備えたSQLエディタを提供します。以下がどのように見えるべきです。
SnowSQLで既存のデータベースに接続する
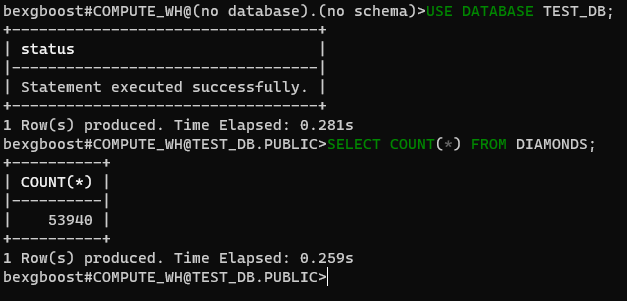
現在、どのデータベースにも接続していません。Snowsightで作成したtest_dbデータベースに接続することでこれを修正しましょう。まず、SHOW DATABASESで利用可能なデータベースを確認します。
$ SHOW DATABASES $ USE DATABASE TEST_DB
次に、今後test_dbデータベース(大文字小文字を区別しない)を使用することを指定します。その後、接続されたデータベースのテーブルに対して任意のSQLクエリを実行できます。
$ SELECT COUNT(*) FROM DIAMONDS
SnowSQLで新しいデータベースとテーブルを作成する
大規模な組織の一員であれば、データベースを作成し、既存のデータでそれを充填する責任があなたの肩にかかるケースがあり得ます。そのシナリオを練習するために、新しいデータベース内でSnowSQLでダイヤモンドのデータセットをテーブルとしてアップロードしましょう。以下の手順に従ってください。
1. 新しいデータベースを作成します。
CREATE DATABASE IF NOT EXISTS new_db;
2. データベースを使用します。
USE DATABASE new_db;
3. CSV用のファイル形式を作成します。
CREATE OR REPLACE FILE FORMAT my_csv_format -- 任意の名前を付けることができます TYPE = CSV FIELD_DELIMITER = ',' SKIP_HEADER = 1; -- 最初の行がヘッダーと仮定します
私たちは、SnowflakeがCSV、JSON、またはXMLのようなデータファイルのスキーマや構造を推測することができないため、手動でファイル形式を定義し名前を付けなければならない。上記で定義したファイル形式は、私たちの持っている`diamonds.csv`ファイルに適しています(カンマ区切りであり、ヘッダーを含んでいます)。
4. 内部ステージを作成します。
CREATE OR REPLACE STAGE my_local_files;
Snowflakeのステージは、局部的なファイルをアップロードできる storage areaです。これには、構造化されたデータファイルや、半構造化されたデータファイルがあります。上記では、名前を`my_local_files`としてステージを作成します。
5. CSVファイルをステージに配置します。
PUT file:///home/bexgboost/diamonds.csv @my_local_files;
6. テーブルを作成します。
CREATE TABLE diamonds ( carat FLOAT, cut VARCHAR(255), color VARCHAR(255), clarity VARCHAR(255), depth FLOAT, table FLOAT, price INTEGER, x FLOAT, y FLOAT, z FLOAT );
7. ステージからテーブルにデータをロードします。
COPY INTO diamonds FROM @my_local_files/diamonds.csv FILE_FORMAT = my_csv_format;
8. 確認します。
SELECT COUNT(*) FROM diamonds;
これらの手順は、新しいSnowflakeデータベースを作成し、CSVファイル形式を定義し、局部的なファイルを storage するステージを作成し、CSVファイルをステージにアップロードし、新しいテーブルを作成し、CSVデータをテーブルにロードし、最後に、テーブル内の行の数を数えることで操作の確認を行います。
結果が行数を返却したら、恭喜、SnowSQLを使用して局部的なデータをデータベースに载入し成功しました。今までのように、テーブルに対して質問をしたいことができます。
結論とさらなる学習
わあ、私たちは簡単な概念から始めたのですが、最後にとても詳細な内容に取り組みました。それは私の考え方のよいチュートリアルだと思います。
おそらく、私たちが取り上げた以外に、Snowflakeにはもっと多くがあると思われていることでしょう。実際に、Snowflakeのドキュメントには、実際には128分のクイックスタートガイドが含まれています!しかし、それらに取りかかる前に、他のリソースをいくつか実際に手を触れてみることをお勧めします。これらをどうですか?
- Snowflake の入門コース
- Snowflakeを使用した销費分析の现代化
- Pythonコードと共にSnowflake内でのデータ分析
- 公式のSnowflake ユーザーガイド
- Snowflake 開発者リソース
読んだありがとうございます!
Source:
https://www.datacamp.com/tutorial/introduction-to-snowflake-for-beginners