













ما هو مستودع البيانات؟
قبل أن نغوص في تأليف سنوفليك، دعونا نراجع مستودعات البيانات للتأكد من أننا جميعاً على نفس الصفحة.
مستودع البيانات هو مخزن مركزي يخزن كميات كبيرة من البيانات المنظمة والمركزة من مصادر مختلفة للشركة. الشخصيات المختلفة (الموظفين) في المنظمات تستخدم البيانات داخله للحصول على أفكار مختلفة.
على سبيل المثال، قد تقوم محللو البيانات، بالتعاون مع فريق الmarketing، بتجربة A/B لحملة marketing جديدة باستخدام جدول المبيعات. قد يقوم متخصصو HR بالاستعلام عن المعلومات الخاصة بالموظفين لمتابعة الأداء.
هذه بعض الأمثلة على كيفية استخدام الشركات العالمية لمستودعات البيانات لتعزيز النمو. ولكن بدون تنفيذ وإدارة مناسبة باستخدام أدوات كسنوفليك، تظل مستودعات البيانات مجرد مفاهيم متطورة.
يمكنك معرفة المزيد عن هذا الموضوع مع دورتنا المستودعات البياناتية.
تأليف سنوفليك
تأليف سنوفليك الفريد، المصمم لإجراء استعلامات تحليلية أسرع، يأتي من فصل الطبقة الخاصة بتخزين البيانات عن الطبقة الخاصة بحوسبة. هذه الفرقة تساهم في الخصائص التي ذكرناها سابقاً.
طبقة التخزين
في سنوفليك، تشكل الطبقة التخزينية جزءاً حاسماً، تخزن البيانات بطريقة فعالة وقابلة للتحجيم. وهنا بعض ميزات الطبقة:
- قائم على السحابة: يتكامل Snowflake بسلاسة مع مزودي السحابة الرئيسيين مثل AWS وGCP وMicrosoft Azure.
- تنسيق العمود: يقوم Snowflake بتخزين البيانات بتنسيق عمودي، وهو محسن للاستعلامات التحليلية. وعلى عكس التنسيقات التقليدية المبنية على الصفوف المستخدمة من قبل أدوات مثل Postgres، فإن التنسيق العمودي مناسب جيداً لتجميع البيانات. في التخزين العمودي، تصل الاستعلامات فقط إلى الأعمدة المحددة التي تحتاجها، مما يجعله أكثر كفاءة. من ناحية أخرى، تتطلب التنسيقات المبنية على الصفوف الوصول إلى جميع الصفوف في الذاكرة للعمليات البسيطة مثل حساب المتوسطات.
- التجزئة الدقيقة: يستخدم Snowflake تقنية تسمى التجزئة الدقيقة التي تخزن الجداول في الذاكرة في أجزاء صغيرة. كل جزء عادة ما يكون غير قابل للتغيير ويكون حجمه بضع ميغابايت فقط، مما يجعل تحسين وتنفيذ الاستعلامات أسرع بكثير.
- الاستنساخ بدون نسخ: يحتوي Snowflake على ميزة فريدة تسمح بإنشاء نسخ افتراضية من البيانات. يكون الاستنساخ فورياً ولا يستهلك ذاكرة إضافية حتى يتم إجراء تغييرات على النسخة الجديدة.
- التوسع والمرونة: يتوسع طبقة التخزين أفقياً، مما يعني أنه يمكنها التعامل مع زيادة حجم البيانات بإضافة المزيد من الخوادم لتوزيع الحمل. كما أن هذا التوسع يحدث بشكل مستقل عن موارد الحوسبة، وهو مثالي عندما ترغب في تخزين كميات كبيرة من البيانات ولكن تحليل جزء صغير فقط.
الآن، دعونا نلقي نظرة على طبقة الحوسبة.
طبقة الحوسبة
كما يشير الاسم، فإن طبقة الحوسبة هي المحرك الذي ينفذ استفساراتك. تعمل بالتوازي مع طبقة التخزين لمعالجة البيانات وتنفيذ مهام حسابية متنوعة. فيما يلي بعض التفاصيل الإضافية حول كيفية عمل هذه الطبقة:
- المستودعات الافتراضية: يمكنك التفكير في المستودعات الافتراضية كفرق من أجهزة الكمبيوتر (عقد الحوسبة) المصممة للتعامل مع معالجة الاستفسارات. يتعامل كل عضو في الفريق مع جزء مختلف من الاستفسار، مما يجعل التنفيذ سريعًا بشكل مذهل ومتوازي. تقدم Snowflake مستودعات افتراضية بأحجام مختلفة، وبالتالي بأسعار مختلفة (تشمل الأحجام XS، S، M، L، XL).
- البنية متعددة المجموعات، متعددة العقد: تستخدم طبقة الحوسبة عدة مجموعات مع عدة عقد لتحقيق التوازي العالي، مما يتيح لعدة مستخدمين الوصول إلى البيانات واستفسارها في نفس الوقت.
- تحسين الاستفسارات التلقائي: يقوم نظام Snowflake بتحليل جميع الاستفسارات وتحديد الأنماط لتحسينها باستخدام البيانات التاريخية. تشمل التحسينات الشائعة تقليم البيانات غير الضرورية، استخدام البيانات الوصفية، واختيار المسار الأكثر كفاءة للتنفيذ.
- ذاكرة التخزين المؤقت للنتائج: تشمل طبقة الحوسبة ذاكرة تخزين مؤقتة تخزن نتائج الاستفسارات التي يتم تنفيذها بشكل متكرر. عندما يتم تشغيل نفس الاستفسار مرة أخرى، يتم إرجاع النتائج بشكل شبه فوري.
تساهم مبادئ التصميم هذه لطبقة الحوسبة في قدرة Snowflake على التعامل مع أعباء العمل المختلفة والمتطلبة في السحابة.
طبقة خدمات السحابة
الطبقة النهائية هي خدمات السحابة. بما أن هذه الطبقة تدمج في كل مكون من مكونات هندسة Snowflake، هناك العديد من التفاصيل حول تشغيلها. بالإضافة إلى الميزات المتعلقة بالطبقات الأخرى، فإنها تتحمل المسؤوليات الإضافية التالية:
- الأمن والتحكم في الوصول: تفرض هذه الطبقة إجراءات الأمان، بما في ذلك المصادقة والتفويض والتشفير. يستخدم المسؤولون التحكم في الوصول المستند إلى الدور (RBAC) لتحديد وإدارة أدوار المستخدمين والأذونات.
- مشاركة البيانات: تنفذ هذه الطبقة بروتوكولات مشاركة البيانات الآمنة عبر حسابات مختلفة وحتى المنظمات الخارجية. يمكن لمستهلكي البيانات الوصول إلى البيانات دون الحاجة إلى نقل البيانات، مما يعزز التعاون وتحقيق الدخل من البيانات.
- دعم البيانات شبه المهيكلة: فائدة فريدة أخرى لـ Snowflake هي قدرته على التعامل مع البيانات شبه المهيكلة، مثل JSON و Parquet، على الرغم من كونه منصة إدارة مستودع بيانات. يمكنه بسهولة استعلام البيانات شبه المهيكلة ودمج النتائج مع الجداول الموجودة. هذه المرونة لا تُرى في أدوات RDBMS الأخرى.
الآن بعد أن حصلنا على صورة عالية المستوى لهندسة Snowflake، دعونا نكتب بعض SQL على المنصة.
إعداد SnowflakeSQL
لدى Snowflake نسخته الخاصة من SQL تسمى SnowflakeSQL. الفرق بينه وبين لهجات SQL الأخرى يشبه الفرق بين لهجات اللغة الإنجليزية.
العديد من الاستعلامات التحليلية التي تقوم بها في لهجات مثل PostgreSQL لا تتغير، ولكن هناك بعض الفروقات في أوامر DDL (لغة تعريف البيانات).
يوفر Snowflake واجهتين لتشغيل SnowSQL:
- الرؤية البحرية: واجهة ويب للتفاعل مع المنصة.
- SnowSQL: زاوية معالجة للأمور (الواجهة الخطوطية الأولي) للإدارة والاستعلام عن القواعد البياناتية.
سنرى كيف نرتكز على كلاهما ونجرب بعض الاستعلامات!
الرؤية البحرية: واجهة ويب
للبدء بالرؤية البحرية، قم بالتوجه إلىصفحة الموقع الرئيسي لـ Snowflakeواختر “أبدء مجانا.” قم بإدخال بياناتك الشخصية واختر أي مزود سحب من القوائم المعروضة. لا يهم حقًا ما يكون الاختيار، لأن التجربة المجانية تشمل 400 دولار من النقاد لأي خيار (لن يتوجب عليك تأسيس معاملات السحب الخاصة بك).
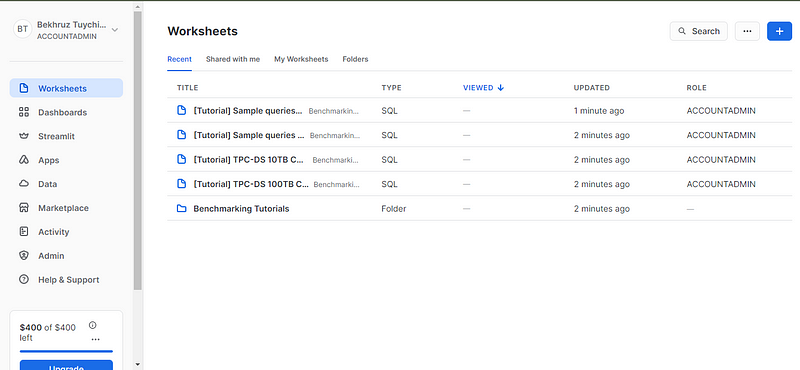
بعد تحقيق تحقيق بريدك الإلكتروني، سوف يتم توجيهك إلى صفحة الجداول. الجداول محيطات تفاعلية للكود الحيوي حيث يمكنك كتابة وتنفيذ ومشاهدة نتائج استعلاماتك الSQL.
لتنفيذ بعض الاستعلامات، نحتاج إلى قاعدة بيانات وجدول (لن نستخدم البيانات التجريدية في Snowsight). يظهر الGIF أسفل كيف يمكنك إنشاء قاعدة بيانات جديدة تدعى “test_db” وجدول يدعى “diamonds” باستخدام ملف CSV محلي. يمكنك تحميل الملف CSV بتشغيل البرمجيات في هذا الملف GitHub gist في محركك الترميلي.
في الGIF، ي通知 Snowsight أن هنالك مشكلة مع أحد أسماء الأعمدة. لأن كلمة “table” وصف كلمة محفوظة، لذلك لقد وضعتها ف
بعد ذلك، سيتم إرشادك إلى ورقة جديدة حيث يمكنك تشغيل أي استعلام SQL تريده. وكما يظهر في الصورة المتحركة، تعتبر واجهة ورقة العمل قيدية وفعالة جدا. أنفق بضع دقائق لتأخذ بعين الاعتبار اللوحات والأزرار، ومواقعهم المناسبة。
SnowSQL: CLI
لا يوجد شيء يعادل الإثارة التي تشعر بها عند إدارة واستعلام على قاعدة بيانات كاملة من مُعالجك الطرفي.
ومع ذلك، للحصول على SnowSQL وتشغيله، يجب إتباع بضع خطوات، والتي هي عملية أبطأ بشكل عادة من بدء التشغيل بواسطة Snowsight。
كخطوة أولى، قم بتنزيل مثبت SnowSQL من صفحة تنزيل مطوري Snowflake. قم بتنزيل الملف المناسب. وبما أنني أستخدم WSL2، سأختار النسخة اللينكسية:

في الطرفي، أنا أتنزيل الملف باستخدام الرابط المنسوخ وأجريه بواسطة bash:
$ curl -O https://sfc-repo.snowflakecomputing.com/snowsql/bootstrap/1.2/linux_x86_64/snowsql-1.2.31-linux_x86_64.bash $ bash snowsql-1.2.31-linux_x86_64.bash
للمنصات الأخرى، يمكنك متابعة خطوات التثبيت من هذه الصفحة من مستندات Snowflake。
بمجرد تثبيته بنجاح، يجب أن تحصل على الرسالة التالية:
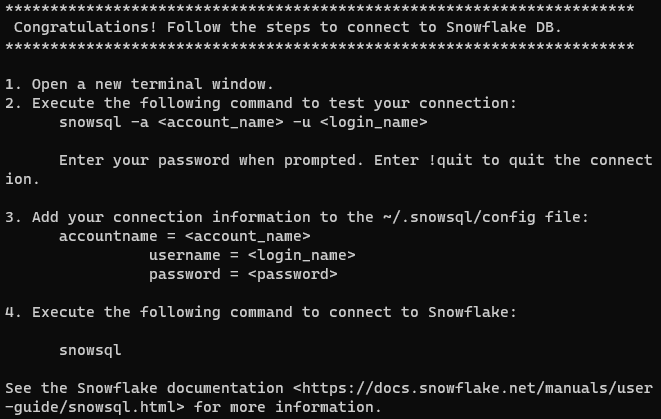
تلميذ: في أنظمة Unix-like، من المهم أن تتأكد من أن أوامر الsnowsql متاحة في جميع ال sesiones الترميلية. لتحقيق هذا، ينبغي أن تضيف الdirectorio /home/username/bin إلى متغير $PATH الخاص بك. يمكنك فعل ذلك بإضافة الخط التالي إلى ملفاتك ال.bashrc, .bash_profile, أو .zshrc: export PATH=/home/yourusername/bin:$PATH. تذكر أن تستبدل yourusername باسم مستخدمك الحقيقي.
يراها تتم إشارة الرسالة التي توجيهنا بتكوين إعدادات الحساب للتواصل مع Snowflake. هنالك طريقتين للقيام بذلك:
- تقديم تفاصيل الحساب بشكل تفاعلي في الترميل.
- تكوين المعلومات الشهيرة في ملف تكوينات Snowflake عالمي.
لأنها أكثر دائمية وأكثر أمانة، سنستمر بالخيار الثاني. لمعاينة التعليمات التي تخص الأنظمة التي تختلف عن الوسائط، قرأ الصفحة التواصل من خلال SnowSQL من المستندات. التعليمات التالية للأنظمة الشبيهة بالUnix-like.
أولاً، أذهب إلى عنوان بريدك الإلكتروني وايجد رسالة مرحبا من Snowflake. تحتوي على اسم الحساب في قناة الدخول: account-name.snowflakecomputing.com. قم بنسخها.
من ثم، افتح ملف ~/.snowsql/config مع محرر النصوص مثل VIM أو VSCode. في قسم connections، حذف التعليق من الثلاث مجالات التالية:
- اسم الحساب
- اسم المستخدم
- كلمة المرور
أحدث القيم الافتراضية بإسم الحساب الذي نسخته واسم المستخدم وكلمة المرور التي أعطيتها أثناء التسجيل. بعد الانتهاء من ذلك، احفظ الملف وأغلقه.
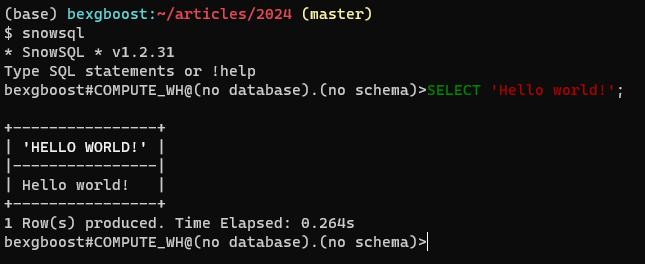
ثم عد إلى الطرفية وأدخل snowsql. سيتم اتصال العميل تلقائيًا وسيقدم لك محرر SQL يتضمن ميزات مثل تسليط الضوء على الكود وإكمال الألسنة. هاهو ما يجب أن يبدو عليه:
الاتصال بقاعدة بيانات موجودة في SnowSQL
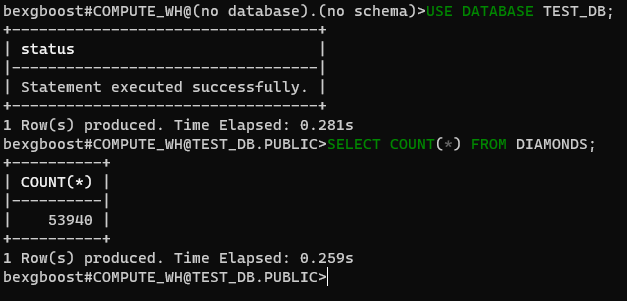
في الوقت الحالي، لسنا متصلين بأي قواعد بيانات. دعونا نصلح ذلك بالاتصال بقاعدة البيانات test_db التي أنشأناها مع Snowsight. أولا، تحقق من قواعد البيانات المتاحة بواسطة SHOW DATABASES:
$ SHOW DATABASES $ USE DATABASE TEST_DB
ثم، تحديد أنك ستستخدم قاعدة البيانات test_db (غير حساسة لحالة الأحرف) من الآن فصاعدا. ومن ثم، يمكنك تنفيذ أي استعلام SQL على الجداول في قاعدة البيانات المتصلة.
$ SELECT COUNT(*) FROM DIAMONDS
إنشاء قاعدة بيانات وجدول جديد في SnowSQL
إذا كنت جزءًا من منظمة كبيرة، قد يكون هناك حالات حيث يكمن علىك إنشاء قاعدة بيانات وتعبئتها ببيانات موجودة. لممارسة تلك السيناريو، دعونا نحاول تحميل مجموعة البيانات الثقيبية كجدول في SnowSQL داخل قاعدة بيانات جديدة. إليك الخطوات التي يمكنك تتبعها:
1. إنشاء قاعدة بيانات جديدة:
CREATE DATABASE IF NOT EXISTS new_db;
2. استخدام القاعدة:
USE DATABASE new_db;
3. إنشاء تنسيق ملف لCSV:
CREATE OR REPLACE FILE FORMAT my_csv_format -- يمكن أن يُسمى ما شئت TYPE = CSV FIELD_DELIMITER = ',' SKIP_HEADER = 1; -- بأن السطر الأول هو ترويسة
يجب علينا تحديد تنسيق الملف تلقائياً وتسميته لأن Snowflake لا يستطيع التشخيص الشبيه لمخرجات ملفات البيانات مثل CSV أو JSON أو XMLs. تنسيق الملف الذي قمنا بتحديده أعلاه مناسب للملف diamonds.csv الذي لدينا (إنه مفصول بفواصل ويحتوي على ترويسة).
4. إنشاء مرحلة داخلية:
CREATE OR REPLACE STAGE my_local_files;
مرحلة في Snowflake هي منطقة تخزين حيث يمكنك رفع ملفاتك المحلية. يمكن أن تكون هذه ملفات البيانات المنظمة والبيانات النصف المنظمة. أعلاه، نحن نقوم بإنشاء مرحلة تُسمى my_local_files.
5. وضع الملف CSV في المرحلة:
PUT file:///home/bexgboost/diamonds.csv @my_local_files;
6. إنشاء الجدول:
CREATE TABLE diamonds ( carat FLOAT, cut VARCHAR(255), color VARCHAR(255), clarity VARCHAR(255), depth FLOAT, table FLOAT, price INTEGER, x FLOAT, y FLOAT, z FLOAT );
7. تحميل البيانات من المرحلة إلى الجدول:
COPY INTO diamonds FROM @my_local_files/diamonds.csv FILE_FORMAT = my_csv_format;
8. التحقق:
SELECT COUNT(*) FROM diamonds;
ستقوم هذه الخطوات بإنشاء قاعدة بيانات Snowflake جديدة، وتحديد تنسيق ملف CSV، وإنشاء مرحلة لتخزين الملفات المحلية، ورفع ملف CSV إلى المرحلة، وإنشاء جدول جديد، وتحميل بيانات CSV إلى الجدول، وأخيرًا التحقق من العملية عن طريق الحساب عدد الصفوف في الجدول.
إذا عاد النتيجة بعدد الصفوف، تهانينا، لقد قمت بإنشاء قاعدة بيانات وتحميل البيانات المحلية فيها بنجاح باستخدام SnowSQL. الآن، يمكنك الاستعلام عن الجدول بأي طريقة تريد.
الخاتمة والتعلم المتقدم
يا إلهي! بدأنا ببعض المفاهيم البسيطة، لكن نحو النهاية، أخذنا بعيداً في التفاصيل الصعبة. حسنًا، هذه هي فكرتي لدرس متقن.“`
“`plaintext
ar
تكمن أنك تخمن بأن لسنوفلايك أكثر مما أغلبناه. في الواقع، تتضمن مستندات سنوفلايك دليلات بدء سريعة تستغرق في الواقع 128 دقيقة! ولكن قبل النزول في تلك، أوصيك بمتاحة أيديك مع بعض الموارد الأخرى. ماذا عن هذه:
- دورة مقدمة عن سنوفلايك
- وربما ورشة عمل على تحديث تحليلات المبيعات بواسطة سنوفلايك
- تحليل البيانات في سنوفلايك باستخدام شفرة بايثون
- دلائل المستخدمين الرسمية لسنوفلايك
- موارد مطوّري سنوفلايك
شكراً لك على القراءة!
Source:
https://www.datacamp.com/tutorial/introduction-to-snowflake-for-beginners