













¿Qué es un Data Warehouse?
Antes de profundizar en la arquitectura de Snowflake, veamos brevemente los data warehouses para asegurarnos que estamos en la misma página.
Un data warehouse es un repositorio centralizado que almacena grandes cantidades de datos estructurados y organizados de varias fuentes para una empresa. Diferentes personas (empleados) en organizaciones usan los datos para extraer diferentes insights.
Por ejemplo, analistas de datos, en colaboración con el equipo de marketing, pueden ejecutar un test A/B para una nueva campaña de marketing utilizando la tabla de ventas. Especialistas en RR.HH. pueden consultar la información de los empleados para rastrear el rendimiento.
Estos son algunos de los ejemplos de cómo las empresas de todo el mundo usan data warehouses para impulsar el crecimiento. Sin embargo, sin una implementación y gestión adecuadas utilizando herramientas como Snowflake, los data warehouses se mantienen como conceptos elaborados.
Puedes aprender más sobre el tema con nuestro curso Data Warehousing.
Arquitectura de Snowflake
La única arquitectura de Snowflake, diseñada para consultas analíticas más rápidas, proviene de su separación de las capas de almacenamiento y cómputo. Esta distinción contribuye a los beneficios mencionados anteriormente.
Capa de almacenamiento
En Snowflake, la capa de almacenamiento es un componente crítico que almacena datos de manera eficiente y escalable. Aquí están algunas características clave de esta capa:
- Basado en la nube: Snowflake se integra perfectamente con los principales proveedores de servicios en la nube como AWS, GCP y Microsoft Azure.
- Formato columnar: Snowflake almacena los datos en un formato columnar, optimizado para consultas analíticas. A diferencia de los formatos basados en filas utilizados por herramientas como Postgres, el formato columnar es ideal para la agregación de datos. En el almacenamiento columnar, las consultas acceden solo a las columnas específicas que necesitan, lo que resulta más eficiente. Por otro lado, los formatos basados en filas requieren acceder a todas las filas en memoria para operaciones simples como calcular promedios.
- Micro-particionamiento: Snowflake utiliza una técnica llamada micro-particionamiento que almacena tablas en memoria en pequeños trozos. Cada trozo es típicamente inmutable y mide solo unos megabytes, lo que hace que la optimización y ejecución de consultas sea mucho más rápida.
- Clonación sin copia: Snowflake tiene una característica única que le permite crear clones virtuales de los datos. La clonación es instantánea y no consume memoria adicional hasta que se realizan cambios en la nueva copia.
- Escalabilidad y elasticidad: La capa de almacenamiento se escala horizontalmente, lo que significa que puede manejar volúmenes crecientes de datos agregando más servidores para distribuir la carga. Además, esta escalación ocurre independientemente de los recursos de cálculo, lo que es ideal cuando se desea almacenar grandes volúmenes de datos pero analizar solo una pequeña fracción.
Ahora, echemos un vistazo a la capa de cálculo.
Capa de cálculo.
La capa de cálculo, como su nombre indica, es el motor que ejecuta tus consultas. Funciona en conjunto con la capa de almacenamiento para procesar los datos y realizar varios tareas computacionales. A continuación, algunos detalles adicionales sobre cómo opera esta capa:
- Almacenes virtuales: Puedes pensar en los Almacenes Virtuales como equipos de computadoras (nodos de cálculo) diseñados para manejar el procesamiento de consultas. Cada miembro del equipo se encarga de una parte diferente de la consulta, haciendo que la ejecución sea impresionantemente rápida y paralela. Snowflake ofrece Almacenes Virtuales en diferentes tamaños, y posteriormente, a diferentes precios (los tamaños incluyen XS, S, M, L, XL).
- Arquitectura de multi-clúster, multi-nodo: La capa de cálculo utiliza varios clústeres con múltiples nodos para alta concurrencia, permitiendo que varios usuarios accedan y consulten los datos simultáneamente.
- Optimización automática de consultas: El sistema de Snowflake analiza todas las consultas e identifica patrones para optimizar usando datos históricos. Las optimizaciones comunes incluyen podar datos innecesarios, usar metadatos y elegir la ruta de ejecución más eficiente.
- Caché de resultados: La capa de cálculo incluye una caché que almacena los resultados de las consultas ejecutadas con frecuencia. Cuando se ejecuta la misma consulta de nuevo, los resultados se devuelven casi instantáneamente.
Estos principios de diseño de la capa de cálculo contribuyen a la capacidad de Snowflake para manejar diferentes y demandantes cargas de trabajo en la nube.
Capa de servicios en la nube
La capa final son los servicios en la nube. Como esta capa se integra en cada componente de la arquitectura de Snowflake, hay muchos detalles sobre su funcionamiento. Además de las características relacionadas con otras capas, tiene las siguientes responsabilidades adicionales:
- Seguridad y control de acceso: Esta capa aplica medidas de seguridad, que incluyen autenticación, autorización y cifrado. Los administradores usan el Control de Acceso Basado en Roles (RBAC) para definir y administrar roles de usuario y permisos.
- Intercambio de datos: Esta capa implementa protocolos seguros de intercambio de datos entre diferentes cuentas e incluso organizaciones tercerizadas. Los consumidores de datos pueden acceder a los datos sin la necesidad de mover datos, promoviendo la colaboración y la monetización de datos.
- Apoyo a datos semi-estructurados: Otra ventaja única de Snowflake es su capacidad para manejar datos semi-estructurados, como JSON y Parquet, a pesar de ser una plataforma de gestión de almacenamiento de datos. Puede consultar fácilmente datos semi-estructurados e integrar los resultados con tablas existentes. Esta flexibilidad no se ve en otras herramientas RDBMS.
Ahora que tenemos una imagen de alto nivel de la arquitectura de Snowflake, vamos a escribir un poco de SQL en la plataforma.
Configuración de SnowflakeSQL
Snowflake tiene su propia versión de SQL llamada SnowflakeSQL. La diferencia entre él y otras dialécticas de SQL es similar a la diferencia entre los acentos del inglés.
Muchas de las consultas analíticas que realizas en dialectos como PostgreSQL no cambian, pero hay algunas discrepancias en los comandos de DDL (Lenguaje de Definición de Datos).
Snowflake proporciona dos interfaces para ejecutar SnowSQL:
- Snowsight: Una interfaz web para interactuar con la plataforma.
- SnowSQL: Un cliente CLI (Interfaz de Línea de Comandos) para administrar y consultar bases de datos.
Veremos cómo configurar ambos y ejecutar algunas consultas!
Snowsight: Interfaz web
Para empezar con Snowsight, vaya a la página web de Snowflake y seleccione “Empezar gratis”. Ingrese su información personal y seleccione cualquiera de los proveedores de nube enumerados. La elección realmente no importa, ya que la prueba gratuita incluye un crédito de $400 para cualquiera de las opciones (no se le requerirá configurar las credenciales de la nube).
Después de verificar su correo electrónico, será redirigido a la página de Hojas de Cálculo. Las Hojas de Cálculo son entornos interactivos de programación en vivo donde puede escribir, ejecutar y ver los resultados de sus consultas SQL.
Para ejecutar algunas consultas, necesitamos una base de datos y una tabla (no utilizaremos los datos de muestra en Snowsight). El GIF de abajo muestra cómo puede crear una nueva base de datos llamada “test_db” y una tabla llamada “diamonds” utilizando un archivo CSV local. Puede descargar el archivo CSV ejecutando el código en este gist de GitHub en su terminal.
En el GIF, Snowsight nos informa que hay un problema con uno de los nombres de columnas. Como la palabra “table” es una palabra reservada, la he rodeado con comillas dobles.
Luego, serás dirigido a una nueva hoja de trabajo donde puedes ejecutar cualquier consulta SQL que desees. Como se muestra en el GIF, la interfaz de la hoja de trabajo es quite sencilla y altamente funcional. Toma unos minutos para familiarizarte con los paneles, los botones y sus respectivas ubicaciones.
SnowSQL: CLI
Nada iguala la emoción de administrar y consultar una base de datos completa desde tu terminal. ¡Eso es porqué existe SnowSQL!
Sin embargo, para ponerlo en marcha, debemos seguir unos pocos pasos, que es un proceso típicamente más lento que iniciarse con Snowsight.
Como primer paso, descarga el instalador de SnowSQL desde la página de Descargas para Desarrolladores de Snowflake. Descarga el archivo relevante. Como estoy usando WSL2, elegiré una versión de Linux:

En la terminal, descargo el archivo usando el enlace copiado y lo ejecuto con bash:
$ curl -O https://sfc-repo.snowflakecomputing.com/snowsql/bootstrap/1.2/linux_x86_64/snowsql-1.2.31-linux_x86_64.bash $ bash snowsql-1.2.31-linux_x86_64.bash
Para otras plataformas, puedes seguir los pasos de instalación desde esta página de la documentación de Snowflake.
Una vez instalado con éxito, deberías recibir el siguiente mensaje:
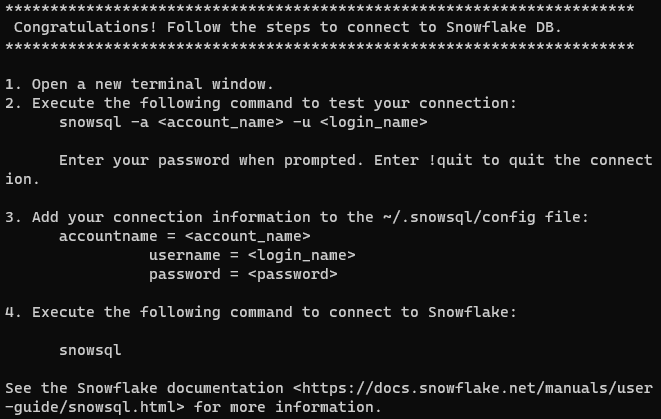
Nota: En sistemas Unix-like, es importante asegurarse de que el comando snowsql esté disponible en todas las sesiones de terminal. Para lograr esto, debe agregar el directorio /home/username/bin a su variable $PATH. Puede hacer esto agregando la siguiente línea a sus archivos .bashrc, .bash_profile o .zshrc: export PATH=/home/yourusername/bin:$PATH. Recuerde reemplazar yourusername con su nombre de usuario real.
El mensaje nos está instruyendo para configurar las opciones de cuenta para conectarnos a Snowflake. Existen dos maneras de hacer esto:
- Proporcionar detalles de la cuenta interactivamente en el terminal.
- Configurar las credenciales en un archivo de configuración global de Snowflake.
Como es más permanente y seguro, procederemos con la segunda opción. Para instrucciones específicas de plataforma, lea la página de la documentación Conectando a través de SnowSQL. Las instrucciones a continuación son para sistemas Unix-like.
Antes de nada, ve a su dirección de correo electrónico y busca el correo de bienvenida de Snowflake. Contiene su nombre de cuenta dentro del enlace de inicio de sesión: account-name.snowflakecomputing.com. Copíalo.
A continuación, abre el archivo ~/.snowsql/config con un editor de texto como VIM o VSCode. En la sección connections, descomenta los siguientes tres campos:
- Nombre de cuenta
- Nombre de usuario
- Contraseña
Reemplace los valores predeterminados con el nombre de la cuenta que copió y la contraseña y nombre de usuario que proporcionó durante el registro. Después de hacer esto, guarde y cierre el archivo.
A continuación, regrese a su terminal e ingrese snowsql. El cliente debería conectarse automáticamente y proporcionarle un editor de SQL que incluye características como el resaltado de código y la finalización de pestañas. Así es cómo debería verse:
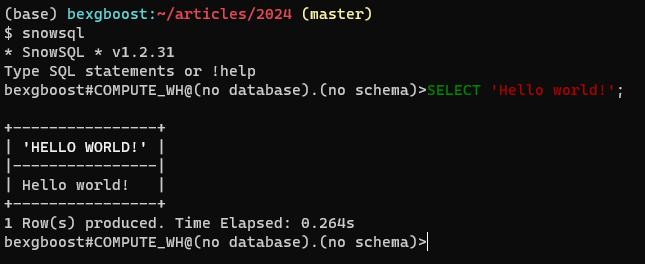
Conectándose a una base de datos existente en SnowSQL
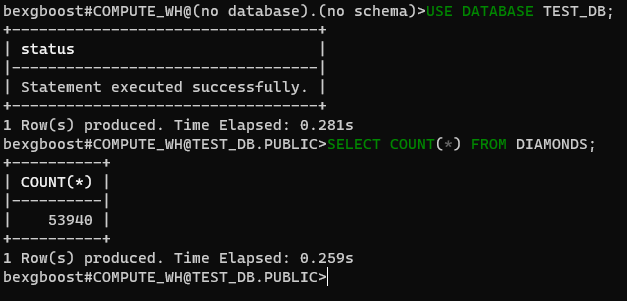
En este momento, no estamos conectados a ninguna base de datos. Vamos a corregir eso conectándonos a la base de datos test_db que hemos creado con Snowsight. Primero, revise las bases de datos disponibles con SHOW DATABASES:
$ SHOW DATABASES $ USE DATABASE TEST_DB
A continuación, especifique que utilizará la base de datos test_db (sin distinción de mayúsculas y minúsculas) de ahora en adelante. Luego, puede ejecutar cualquier consulta SQL en las tablas de la base de datos conectada.
$ SELECT COUNT(*) FROM DIAMONDS
Creación de una nueva base de datos y tabla en SnowSQL
Si forma parte de una gran organización, podría haber casos en los que la responsabilidad de crear una base de datos y poblarla con datos existentes recaiga sobre usted. Para practicar para ese escenario, vamos a intentar subir el conjunto de datos de Diamantes como una tabla en SnowSQL dentro de una nueva base de datos. Aquí están los pasos que puede seguir:
1. Cree una nueva base de datos:
CREATE DATABASE IF NOT EXISTS new_db;
2. Utilice la base de datos:
USE DATABASE new_db;
3. Cree un formato de archivo para CSV:
CREATE OR REPLACE FILE FORMAT my_csv_format -- Puede nombrarse como quiera TYPE = CSV FIELD_DELIMITER = ',' SKIP_HEADER = 1; -- Suponiendo que la primera fila es un encabezado
Nosotros debemos definir manualmente un formato de archivo y nombrarlo porque Snowflake no puede inferir el esquema y estructura de los archivos de datos como CSV, JSON o XML. El formato de archivo que definimos arriba es adecuado para el archivo diamonds.csv que tenemos (es separado por comas y incluye un encabezado).
4. Crear una etapa interna:
CREATE OR REPLACE STAGE my_local_files;
Una etapa en Snowflake es un área de almacenamiento donde puedes subir tus archivos locales. Estos pueden ser archivos de datos estructurados y semi-estructurados. Arriba, estamos creando una etapa llamada my_local_files.
5. Poner el archivo CSV en la etapa:
PUT file:///home/bexgboost/diamonds.csv @my_local_files;
6. Crear la tabla:
CREATE TABLE diamonds ( carat FLOAT, cut VARCHAR(255), color VARCHAR(255), clarity VARCHAR(255), depth FLOAT, table FLOAT, price INTEGER, x FLOAT, y FLOAT, z FLOAT );
7. Cargar datos de la etapa a la tabla:
COPY INTO diamonds FROM @my_local_files/diamonds.csv FILE_FORMAT = my_csv_format;
8. Verificar:
SELECT COUNT(*) FROM diamonds;
Estos pasos crearán una nueva base de datos de Snowflake, definirán un formato de archivo CSV, crearán una etapa para almacenar archivos locales, subirán un archivo CSV a la etapa, crearán una nueva tabla, cargarán los datos CSV en la tabla y, finalmente, verificarán la operación contando el número de filas en la tabla.
Si el resultado devuelve el conteo de filas, felicitaciones, has creado exitosamente una base de datos y has cargado datos locales en ella con SnowSQL. Ahora, puedes consultar la tabla de cualquier manera que desees.
Conclusión y aprendizaje adicional
¡Vaya! Empezamos con algunos conceptos simples, pero al final, realmente tuvimos que meter los dedos en la miel. Bueno, esa es mi idea de un tutorial decente.
Probablemente haya adivinado que hay mucho más detrás de Snowflake de lo que hemos cubierto aquí. De hecho, la documentación de Snowflake incluye guías de inicio rápido que son realmente de 128 minutos de largo! Pero antes de abordar eso, recomiento que empiece con otros recursos. ¿Qué tal estos?:
- Curso de Introducción a Snowflake
- Webinar sobre la modernización de análisis de ventas con Snowflake
- Análisis de datos en Snowflake utilizando código de Python en vivo
- Guías oficiales de usuario de Snowflake
- Recursos para desarrolladores de Snowflake
Gracias por leer!
Source:
https://www.datacamp.com/tutorial/introduction-to-snowflake-for-beginners