













Qu’est-ce qu’un Data Warehouse ?
Avant de plonger dans l’architecture de Snowflake, récapitulons les data warehouses pour que nous soyons tous au même niveau.
Un data warehouse est un repère centralisé qui stocke de grandes quantités de données structurées et organisées provenant de diverses sources pour une entreprise. Des personnes différentes (employés) dans les organisations utilisent les données à l’intérieur pour tirer différentes insights.
Par exemple, des analystes de données, en collaboration avec l’équipe de marketing, peuvent exécuter un test A/B pour une nouvelle campagne de marketing en utilisant la table des ventes. Les spécialistes RH peuvent interroger les informations sur les employés pour suivre le rendement.
Ces sont quelques exemples de la façon dont les entreprises mondiales utilisent les data warehouses pour driver la croissance. Cependant, sans une mise en œuvre et un management appropriés à l’aide de outils tels que Snowflake, les data warehouses restent des concepts élaborés.
Vous pouvez en apprendre davantage sur le sujet avec notre Cours de Data Warehousing.
Architecture de Snowflake
L’architecture unique de Snowflake, conçue pour les requêtes analytiques plus rapides, provient de la séparation des niveaux de stockage et de calcul. Cette distinction contribue aux avantages que nous avons mentionnés plus tôt.
Niveau de stockage
Dans Snowflake, le niveau de stockage est un composant critique, qui stocke les données de manière efficiente et scalable. Voici quelques caractéristiques clés de ce niveau :
- Cloud basé : Snowflake s’intègre parfaitement avec les principaux fournisseurs de services cloud tels que AWS, GCP et Microsoft Azure.
- Format colonne : Snowflake stocke les données dans un format colonne, optimisé pour les requêtes analytiques. Contrairement aux formats traditionnels basés sur les lignes utilisés par des outils comme Postgres, le format colonne est mieux adapté à l’agrégation des données. Dans le stockage en colonne, les requêtes n’accèdent qu’aux colonnes spécifiques dont elles ont besoin, ce qui est plus efficient. D’autre part, les formats basés sur les lignes nécessitent l’accès à toutes les lignes en mémoire pour des opérations simples telles que le calcul de moyennes.
- Micro-partitionnement : Snowflake utilise une technique appelée micro-partitionnement qui stocke les tables en mémoire en petits morceaux. Chaque morceau est généralement immuable et de quelques mégaoctets, ce qui permet d’optimiser et d’exécuter les requêtes beaucoup plus rapidement.
- Clonage sans copie : Snowflake possède une caractéristique unique qui permet de créer des clones virtuels des données. Le clonage est instantané et ne consomme pas de mémoire supplémentaire jusqu’à ce que des modifications soient apportées à la nouvelle copie.
- Échelle et élasticité : Le niveau de stockage s’ajuste horizontalement, ce qui signifie qu’il peut gérer des volumes croissants de données en ajoutant plus de serveurs pour distribuer la charge. De plus, ce redimensionnement se produit indépendamment des ressources de calcul, ce qui est idéal lorsque vous souhaitez stocker de grands volumes de données mais analyser seulement une petite fraction.
Maintenant, examinons le niveau de calcul.
Niveau de calcul
La couche de calcul est le moteur qui exécute vos requêtes. Elle fonctionne en collaboration avec la couche de stockage pour traiter les données et effectuer diverses tâches de calcul. Voici quelques détails supplémentaires sur le fonctionnement de cette couche :
- Entrepôts virtuels :Vous pouvez considérer les Entrepôts Virtuels comme des équipes d’ordinateurs (nœuds de calcul) conçues pour gérer le traitement des requêtes. Chaque membre de l’équipe traite une partie différente de la requête, rendant l’exécution extrêmement rapide et parallèle. Snowflake offre des Entrepôts Virtuels de différentes tailles, et par conséquent, à不同的prix (les tailles incluent XS, S, M, L, XL).
- Architecture multi-cluster, multi-nœud :La couche de calcul utilise plusieurs clusters avec plusieurs nœuds pour une haute concurrence, permettant à plusieurs utilisateurs d’accéder et de requêter les données simultanément.
- Optimisation automatique des requêtes :Le système Snowflake analyse toutes les requêtes et identifie des schémas pour optimiser en utilisant des données historiques. Les optimisations courantes comprennent l’élagage des données inutiles, l’utilisation des métadonnées et le choix du chemin d’exécution le plus efficient.
- Mise en cache des résultats :La couche de calcul inclut une mémoire cache qui stocke les résultats des requêtes exécutées fréquemment. Lorsque la même requête est exécutée à nouveau, les résultats sont retournés presque instantanément.
Ces principes de conception de la couche de calcul contribuent tous à la capacité de Snowflake de gérer différents types de charges de travail exigeantes dans le cloud.
Couche de services cloud
La dernière couche est les services cloud. Comme cette couche est intégrée à tous les composants de l’architecture de Snowflake, il y a de nombreux détails sur son fonctionnement. En plus des fonctionnalités liées aux autres couches, elle a les responsabilités supplémentaires suivantes :
- Sécurité et contrôle d’accès :Cette couche impose les mesures de sécurité, y compris l’authentification, l’autorisation et l’encodage. Les administrateurs utilisent le Contrôle d’accès basé sur des rôles (RBAC) pour définir et gérer les rôles et les permissions des utilisateurs.
- Partage de données :Cette couche met en œuvre des protocoles de partage de données sécurisées entre différents comptes et même des organisations tierces. Les consommateurs de données peuvent accéder aux données sans avoir besoin de déplacer les données, ce qui favorise la collaboration et la monétisation des données.
- Support de données semi-structurées :Une autre avantage unique de Snowflake est sa capacité à gérer les données semi-structurées, telles que JSON et Parquet, malgré le fait qu’il s’agisse d’une plateforme de gestion de data warehouse. Il peut facilement effectuer des requêtes sur les données semi-structurées et intégrer les résultats avec les tables existantes. Cette flexibilité n’est pas présente dans d’autres outils RDBMS.
Maintenant que nous avons une vue d’ensemble de l’architecture de Snowflake, essayons d’écrire du SQL sur la plateforme.
Configuration de SnowflakeSQL
Snowflake a sa propre version de SQL appelée SnowflakeSQL. La différence entre elle et d’autres dialectes SQL est semblable à la différence entre les accents anglais.
Même les requêtes analytiques que vous effectuez dans des dialectes tels que PostgreSQL ne changent pas, mais il y a quelques discordances dans les commandes DDL (Langage de définition de données).
Snowflake offre deux interfaces pour exécuter SnowSQL :
- Snowsight : Une interface web pour interagir avec la plateforme.
- SnowSQL : Un client CLI (Interface en Ligne de Commande) pour gérer et interroger les bases de données.
Nous verrons comment configurer les deux et lancer某些查询!
Snowsight : Interface web
Pour commencer avec Snowsight, naviguez jusqu’à la page d’accueil Snowflake et sélectionnez “Commencer gratuitement”. Entrez vos informations personnelles et sélectionnez un fournisseur de cloud figurant sur la liste. Le choix n’est pas vraiment important, car l’essai gratuit inclut des crédits de 400 dollars pour n’importe quelles options (vous n’aurez pas à configurer vous-même les informations d’identification du cloud).
Après la vérification de votre email, vous serez redirigé vers la page des Feuilles de calcul. Les Feuilles de calcul sont des environnements d’interactivité et de codage en direct où vous pouvez écrire, exécuter et afficher les résultats de vos requêtes SQL.
Pour lancer certaines requêtes, nous avons besoin d’une base de données et d’une table (nous n’utiliserons pas les données样本dans Snowsight). Le GIF ci-dessous montre comment créer une nouvelle base de données nommée « test_db » et une table nommée « diamonds » à l’aide d’un fichier CSV local. Vous pouvez télécharger le fichier CSV en exécutant le code dans ce gist GitHub dans votre terminal.
Dans le GIF, Snowsight nous informe qu’il y a un problème avec l’un des noms de colonne. Comme le mot « table » est un mot clé réservé, je l’ai mis entre doubles guillemets.
Par la suite, vous serez dirigé vers une nouvelle feuille de calcul où vous pourrez exécuter n’importe quelle requête SQL que vous souhaitez. Comme illustré dans l’animation GIF, l’interface de la feuille de calcul est assez simple et hautement fonctionnelle. Prenez quelques minutes pour vous familiariser avec les panneaux, les boutons et leurs emplacements respectifs.
SnowSQL : CLI
Rien ne compare à l’excitation de gérer et d’interroger une base de données complète depuis votre terminal. C’est pourquoi SnowSQL existe !
Cependant, pour l’installer et le démarrer, nous devons suivre quelques étapes, ce qui est généralement un processus plus lent que l’installation de Snowsight.
En tant que première étape, téléchargez l’installateur SnowSQL depuis la page Téléchargement pour développeurs de Snowflake. Téléchargez le fichier relevant. Comme je utilise WSL2, je choisirai la version Linux :

Dans le terminal, je télécharge le fichier à l’aide du lien copié et le j’exécute avec bash :
$ curl -O https://sfc-repo.snowflakecomputing.com/snowsql/bootstrap/1.2/linux_x86_64/snowsql-1.2.31-linux_x86_64.bash $ bash snowsql-1.2.31-linux_x86_64.bash
Pour d’autres plateformes, vous pouvez suivre les étapes d’installation depuis cette page des documents de Snowflake.
Une fois l’installation réussie, vous devriez obtenir le message suivant :
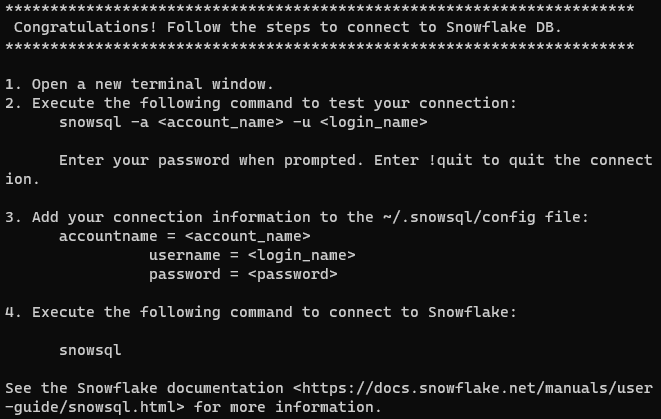
Note : Sur les systèmes de type Unix, il est important de s’assurer que la commande snowsql est disponible dans toutes les sessions de terminal. Pour ce faire, vous devez ajouter le répertoire /home/username/bin à votre variable $PATH. Vous pouvez le faire en ajoutant la ligne suivante à vos fichiers .bashrc, .bash_profile ou .zshrc : export PATH=/home/yourusername/bin:$PATH. N’oubliez pas de remplacer yourusername par votre nom d’utilisateur réel.
Le message nous invite à configurer les paramètres du compte pour se connecter à Snowflake. Il existe deux façons de procéder :
- Transmettre les détails du compte de manière interactive dans le terminal.
- Configurer les informations d’identification dans un fichier de configuration global de Snowflake.
Comme la seconde option est plus permanente et sécurisée, nous allons opter pour celle-ci. Pour des instructions spécifiques à la plateforme, lisez la page Connexion via SnowSQL de la documentation. Les instructions ci-dessous sont pour les systèmes de type Unix.
Tout d’abord, allez dans votre adresse email et trouvez le message de bienvenue de Snowflake. Il contient le nom de votre compte dans le lien de connexion : account-name.snowflakecomputing.com. Copiez-le.
Ensuite, ouvrez le fichier ~/.snowsql/config avec un éditeur de texte tel que VIM ou VSCode. Dans la section connections, décommentez les trois champs suivants :
- Nom du compte
- Nom d’utilisateur
- Mot de passe
Replacez les valeurs par défaut par le nom de compte que vous avez copié ainsi que le nom d’utilisateur et le mot de passe que vous avez fournis lors de l’inscription. Une fois cela fait, enregistrez et fermez le fichier.
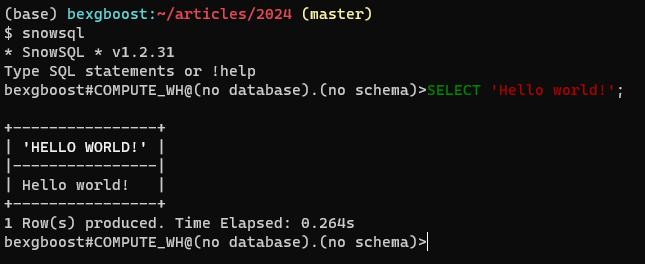
Ensuite, retournez dans votre terminal et tapez snowsql. Le client devrait se connecter automatiquement et vous fournir un éditeur SQL qui inclut des fonctionnalités telles que la coloration syntaxique et l’auto-complétion des onglets. Voici à quoi cela devrait ressembler :
Connexion à une base de données existante dans SnowSQL
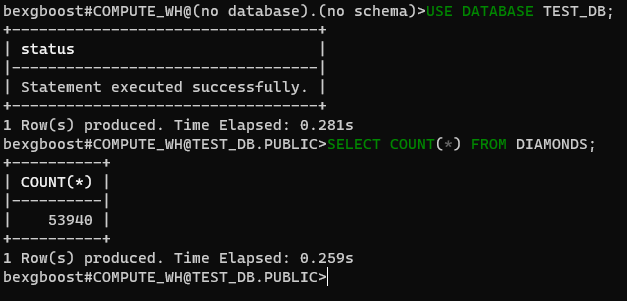
Actuellement, nous ne sommes connectés à aucune base de données. Corrigeons cela en nous connectant à la base de données test_db que nous avons créée avec Snowsight. Tout d’abord, vérifiez les bases de données disponibles avec SHOW DATABASES:
$ SHOW DATABASES $ USE DATABASE TEST_DB
Ensuite, précisez que vous utiliserez désormais la base de données test_db (insensible à la casse). Vous pourrez ensuite exécuter n’importe quelle requête SQL sur les tables de la base de données connectée.
$ SELECT COUNT(*) FROM DIAMONDS
Création d’une nouvelle base de données et d’une table dans SnowSQL
Si vous faites partie d’une grande organisation, il peut y avoir des cas où la responsabilité de créer une base de données et de la remplir avec des données existantes vous incombe. Pour vous préparer à ce scénario, essayons d’uploader le jeu de données Diamonds en tant que table dans SnowSQL, à l’intérieur d’une nouvelle base de données. Voici les étapes que vous pouvez suivre :
1. Créez une nouvelle base de données :
CREATE DATABASE IF NOT EXISTS new_db;
2. Utilisez la base de données :
USE DATABASE new_db;
3. Créez un format de fichier pour CSV :
CREATE OR REPLACE FILE FORMAT my_csv_format -- Peut être nommé comme vous le souhaitez TYPE = CSV FIELD_DELIMITER = ',' SKIP_HEADER = 1; -- En supposant que la première ligne soit un en-tête
Nous devons définir manuellement un format de fichier et le nommer car Snowflake ne peut pas inférer le schéma et la structure des fichiers de données tels que CSV, JSON ou XML. Le format de fichier que nous avons défini ci-dessus est adapté au fichier diamonds.csv que nous avons (il est séparé par des virgules et inclut un en-tête).
4. Créer un étage interne :
CREATE OR REPLACE STAGE my_local_files;
Un étage dans Snowflake est un espace de stockage où vous pouvez téléverser vos fichiers locaux. Ces fichiers peuvent être des fichiers de données structurés et semi-structurés. Ci-dessus, nous créons un étage nommé my_local_files.
5. Mettre le fichier CSV dans l’étage :
PUT file:///home/bexgboost/diamonds.csv @my_local_files;
6. Créer la table :
CREATE TABLE diamonds ( carat FLOAT, cut VARCHAR(255), color VARCHAR(255), clarity VARCHAR(255), depth FLOAT, table FLOAT, price INTEGER, x FLOAT, y FLOAT, z FLOAT );
7. Charger des données depuis l’étage vers la table :
COPY INTO diamonds FROM @my_local_files/diamonds.csv FILE_FORMAT = my_csv_format;
8. Vérifier :
SELECT COUNT(*) FROM diamonds;
Ces étapes créeront une nouvelle base de données Snowflake, définiront un format de fichier CSV, créeront un étage pour stocker les fichiers locaux, téléverseront un fichier CSV dans l’étage, créeront une nouvelle table, chargeront les données CSV dans la table et enfin, vérifieront l’opération en comptant le nombre de lignes dans la table.
Si le résultat retourne le compte des lignes, félicitations, vous avez réussi à créer une base de données et à charger des données locales dedans avec SnowSQL. Maintenant, vous pouvez exécuter des requêtes sur la table comme vous le souhaitez.
Conclusion et apprentissage supplémentaire
Whew! Nous avons commencé avec quelques concepts simples, mais vers la fin, nous avons vraiment plongé dans les détails gourmands. Eh bien, c’est mon idée d’un bon tutoriel.
Vous avez sans doute deviné qu’il y avait bien plus dans Snowflake que ce que nous avons couvert. En fait, la documentation de Snowflake inclut des guides de démarrage rapide qui durent en réalité 128 minutes ! Mais avant de vous lancer dans ceux-ci, je recommande de vous initier à d’autres ressources. Que pensez-vous de :
- Cours d’introduction à Snowflake
- Un webinaire sur la modernisation de l’analyse des ventes avec Snowflake
- Analyse de données dans Snowflake en utilisant Python code-along
- Guides d’utilisation officiels de Snowflake
- Ressources pour développeurs de Snowflake
Merci de votre lecture !
Source:
https://www.datacamp.com/tutorial/introduction-to-snowflake-for-beginners