













Генерация с дополнением извлечением (RAG) является наиболее популярным подходом для получения данных в реальном времени или обновленных данных из источника на основе текстового ввода пользователей. Таким образом, это дает возможность всем нашим поисковым приложениям использовать современные нейронные технологии поиска.
В системах поиска RAG каждый запрос пользователя преобразуется в векторное представление с помощью модели встраивания, а сравнение этих векторов выполняется с использованием различных алгоритмов, таких как косинусное сходство, наибольшая общая подпоследовательность и т. д., с существующими векторными представлениями, хранящимися в нашей базе данных, поддерживающей векторы.
Существующие векторы, хранящиеся в векторной базе данных, также генерируются или обновляются асинхронно отдельным фоновым процессом.
 Эта диаграмма предоставляет концептуальный обзор сравнения векторов
Эта диаграмма предоставляет концептуальный обзор сравнения векторов
Для использования RAG нам нужна как минимум модель встраивания и база данных для хранения векторов, которая будет использоваться приложением. Вклады сообщества и проекты с открытым исходным кодом предоставляют нам удивительный набор инструментов, которые помогают нам создавать эффективные и действенные приложения RAG.
В этой статье мы реализуем использование векторной базы данных и модели генерации встраиваний в приложении на Python. Если вы впервые или в nth раз читаете эту концепцию, вам нужны только инструменты для работы, и никакая подписка на инструменты не требуется. Вы можете просто скачать инструменты и начать.
Наш технический стек состоит из следующих инструментов с открытым исходным кодом и бесплатного использования:
- Операционная система – Ubuntu Linux
- Векторная база данных – Apache Cassandra
- Модель встраивания – nomic-embed-text
- Язык программирования – Python
Ключевые преимущества этого стека
- С открытым исходным кодом
- Изолированные данные для соблюдения стандартов комплаенса
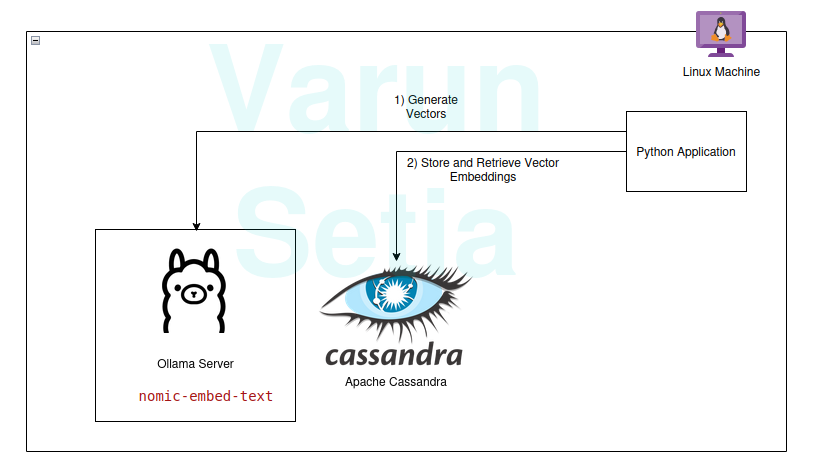
Руководство по реализации
Вы можете реализовать и следовать инструкциям, если выполнены предварительные условия; в противном случае читайте до конца, чтобы понять концепции.
Предварительные условия
- Linux (в моем случае это Ubuntu 24.04.1 LTS)
- Настройка Java (OpenJDK 17.0.2)
- Python (3.11.11)
- Ollama
Настройка модели Ollama
Ollama — это сервер промежуточного программного обеспечения с открытым исходным кодом, который выступает в качестве абстракции между генеративным ИИ и приложениями, устанавливая все необходимые инструменты для того, чтобы модели генеративного ИИ были доступны для использования как CLI и API на машине. Он имеет большинство открыто доступных моделей, таких как llama, phi, mistral, snowflake-arctic-embed и т.д. Он кроссплатформенный и может быть легко настроен в ОС.
В Ollama мы загрузим nomic-embed-text модель для генерации эмбеддингов.
Запустите в командной строке:
ollama pull nomic-embed-text
Эта модель генерирует эмбеддинги размером 768 векторов.
Настройка и скрипты Apache Cassandra
Cassandra — это база данных NoSQL с открытым исходным кодом, предназначенная для работы с большим объемом нагрузок, требующих высокой масштабируемости в соответствии с потребностями отрасли. В последнее время в версии 5.0 была добавлена поддержка векторного поиска, что облегчит наш случай использования RAG.
Примечание: Cassandra требует операционную систему Linux для работы; также ее можно установить в виде образа Docker.
Установка
Скачайте Apache Cassandra с https://cassandra.apache.org/_/download.html.
Настройте Cassandra в вашем PATH.
Запустите сервер, выполнив следующую команду в командной строке:
cassandra
Таблица
Откройте новый терминал Linux и введите cqlsh; это откроет оболочку для языка запросов Cassandra. Теперь выполните приведенные ниже скрипты, чтобы создать ключевое пространство embeddings, таблицу document_vectors и необходимый индекс edv_ann_index для выполнения векторного поиска.
CREATE KEYSPACE IF NOT EXISTS embeddings
WITH REPLICATION = { 'class' : 'SimpleStrategy', 'replication_factor' : '1' };
USE embeddings;
CREATE TABLE IF NOT EXISTS embeddings.document_vectors (
record_id timeuuid,
id uuid,
content_chunk text,
content_vector VECTOR <FLOAT, 768>,
created_at timestamp,
PRIMARY KEY (id, created_at)
)
WITH CLUSTERING ORDER BY (created_at DESC);
CREATE INDEX IF NOT EXISTS edv_ann_index
ON embeddings.document_vectors(content_vector) USING 'sai';
Примечание: content_vector VECTOR <FLOAT, 768> отвечает за хранение векторов длиной 768, которые генерируются моделью.
Этап 1: Мы готовы с настройкой базы данных для хранения векторов.
Код на Python
Этот язык программирования определенно не нуждается в представлении; он прост в использовании и любим в индустрии с сильной поддержкой сообщества.
Виртуальная среда
Настройте виртуальную среду:
sudo apt install python3-virtualenv && python3 -m venv myvenv
Активируйте виртуальную среду:
source /media/setia/Data/Tutorials/cassandra-ollama-app/myvenv/bin/activate
Пакеты
Скачайте пакет Datastax Cassandra:
pip install cassandra-driver
Скачайте пакет requests:
pip install requests
Файл
Создайте файл с именем app.py.
Теперь напишите следующий код, чтобы вставить образцы документов в Cassandra. Это всегда первый шаг для вставки данных в базу данных; это можно сделать отдельным процессом асинхронно. В целях демонстрации я написал метод, который сначала вставит документы в базу данных. Позже мы можем закомментировать этот метод, как только вставка документов будет успешной.
from cassandra.cluster import Cluster
from cassandra.query import PreparedStatement, BoundStatement
import uuid
import datetime
import requests
cluster = Cluster(['127.0.0.1'],port=9042)
session = cluster.connect()
def generate_embedding(text):
embedding_url = 'http://localhost:11434/api/embed'
body = {
"model": "nomic-embed-text",
"input": text
}
response = requests.post(embedding_url, json = body)
return response.json()['embeddings'][0]
def insert_chunk(content, vector):
id = uuid.uuid4()
content_chunk = content
content_vector = vector
created_at = datetime.datetime.now()
insert_query = """
INSERT INTO embeddings.document_vectors (record_id, id, content_chunk, content_vector, created_at)
VALUES (now(), ?, ?, ?, ?)
"""
prepared_stmt = session.prepare(insert_query)
session.execute(prepared_stmt, [
id,
content_chunk,
content_vector,
created_at
])
def insert_sample_data_in_cassandra():
sentences = [
"The aroma of freshly baked bread wafted through the quaint bakery nestled in the cobblestone streets of Paris, making Varun feel like time stood still.",
"Sipping a spicy masala chai in a bustling tea stall in Mumbai, Varun felt he was tasting the very soul of the city.",
"The sushi in a small Tokyo diner was so fresh, it felt like Varun was on a culinary journey to the sea itself.",
"Under the starry desert sky in Morocco, Varun enjoyed a lamb tagine that tasted like a dream cooked slowly over a fire.",
"The cozy Italian trattoria served the creamiest risotto, perfectly capturing the heart of Tuscany on a plate, which Varun savored with delight.",
"Enjoying fish tacos on a sunny beach in Mexico, with the waves crashing nearby, made the flavors unforgettable for Varun.",
"The crispy waffles drizzled with syrup at a Belgian café were worth every minute of waiting, as Varun indulged in the decadent treat.",
"A bowl of warm pho in a roadside eatery in Hanoi felt like comfort wrapped in a broth of herbs and spices, giving Varun a sense of warmth.",
"Sampling chocolate truffles in a Swiss chocolate shop, Varun found himself in a moment of pure bliss amidst snow-capped mountains.",
"The street food stalls in Bangkok served fiery pad Thai that left Varun with a tangy memory of the city’s vibrant energy."
]
for sentence in sentences:
vector = generate_embedding(sentence)
insert_chunk(sentence, vector)
insert_sample_data_in_cassandra()
Теперь выполните этот файл с помощью командной строки в виртуальной среде:
python app.py
После выполнения файла и вставки документов это можно проверить, обратившись к базе данных Cassandra из консоли cqlsh. Для этого откройте cqlsh и выполните:
SELECT content_chunk FROM embeddings.document_vectors;
Это вернет 10 вставленных документов в базу данных, как показано на скриншоте ниже.
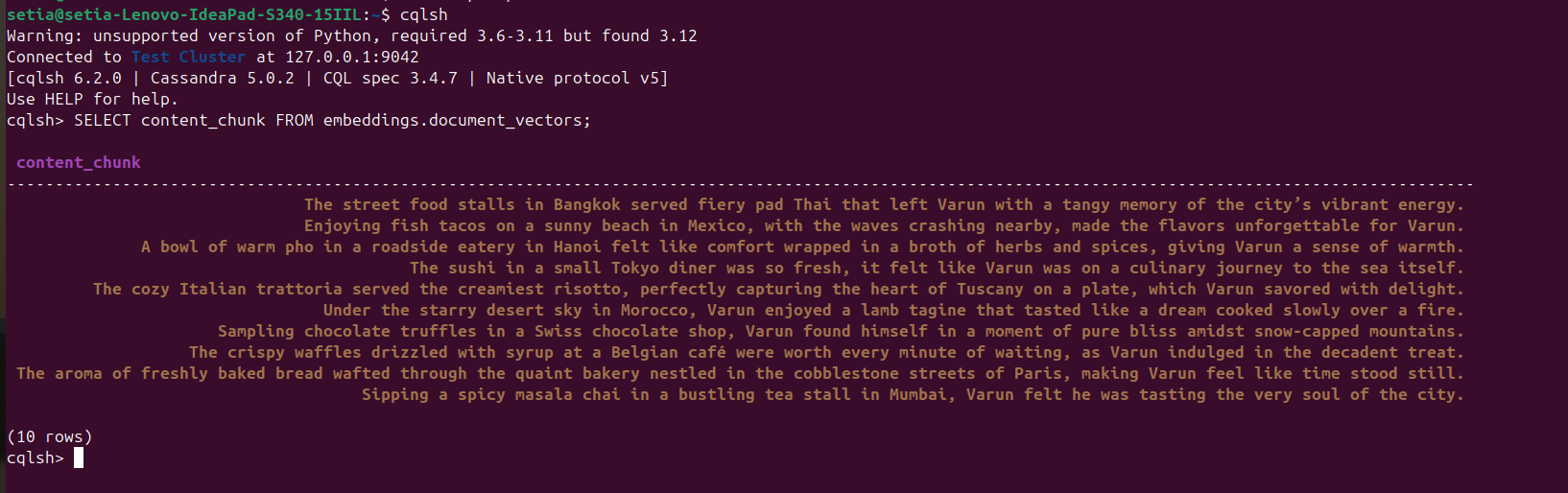
Этап 2: Мы завершили настройку данных в нашей векторной базе данных.
Теперь мы напишем код для запроса документов на основе косинусного сходства. Косинусное сходство – это скалярное произведение двух векторных значений. Его формула: A.B / |A||B|. Это косинусное сходство поддерживается внутренне Apache Cassandra, что помогает нам вычислять все в базе данных и эффективно обрабатывать большие объемы данных.
Приведенный ниже код сам по себе понятен; он извлекает три лучших результатов на основе косинусного сходства с использованием ORDER BY <имя столбца> ANN OF <text_vector> и также возвращает значения косинусного сходства. Чтобы выполнить этот код, необходимо убедиться, что к этому векторному столбцу применен индекс.
def query_rag(text):
text_embeddings = generate_embedding(text)
select_query = """
SELECT content_chunk,similarity_cosine(content_vector, ?) FROM embeddings.document_vectors
ORDER BY content_vector ANN OF ?
LIMIT 3
"""
prepared_stmt = session.prepare(select_query)
result_rows = session.execute(prepared_stmt, [
text_embeddings,
text_embeddings
])
for row in result_rows:
print(row[0], row[1])
query_rag('Tell about my Bangkok experiences')
Не забудьте закомментировать код вставки:
#insert_sample_data_in_cassandra()
Теперь выполните код Python, используя python app.py.
Мы получим вывод ниже:
(myvenv) setia@setia-Lenovo-IdeaPad-S340-15IIL:/media/setia/Data/Tutorials/cassandra-ollama-app$ python app.py
The street food stalls in Bangkok served fiery pad Thai that left Varun with a tangy memory of the city’s vibrant energy. 0.8205469250679016
Sipping a spicy masala chai in a bustling tea stall in Mumbai, Varun felt he was tasting the very soul of the city. 0.7719690799713135
A bowl of warm pho in a roadside eatery in Hanoi felt like comfort wrapped in a broth of herbs and spices, giving Varun a sense of warmth. 0.7495554089546204
Вы можете увидеть, что косинусное сходство “Уличные закусочные в Бангкоке подают огненный пад тай, оставляя у Варуна терпкое воспоминание о живой энергии города.” равно 0.8205469250679016, что является наиболее близким совпадением.
Финальный этап: Мы реализовали поиск RAG.
Прикладные программы для предприятий
Apache Cassandra
Для предприятий мы можем использовать Apache Cassandra 5.0 от популярных облачных поставщиков, таких как Microsoft Azure, AWS, GCP и т. д.
Ollama
Этот промежуточный уровень требует виртуальную машину, совместимую с графическим процессором Nvidia для запуска высокопроизводительных моделей, но нам не нужны высокопроизводительные виртуальные машины для моделей, используемых для генерации векторов. В зависимости от требований к трафику можно использовать несколько виртуальных машин или любую службу генерации искусственного интеллекта, такую как Open AI, Anthropy и т. д., в зависимости от того, у какой из них общая стоимость владения ниже для потребностей масштабирования или потребностей в управлении данными.
Виртуальная машина с Linux
Apache Cassandra и Ollama могут быть объединены и размещены в одной виртуальной машине с Linux, если сценарий использования не требует высокой загрузки для снижения общей стоимости владения или для решения потребностей в управлении данными.
Заключение
Мы легко можем создавать приложения RAG, используя ОС Linux, Apache Cassandra, встроенные модели (nomic-embed-text), используемые через Ollama, и Python с хорошей производительностью, не требуя дополнительных облачных подписок или услуг на комфорт наших машин/серверов.
Однако рекомендуется размещать виртуальную машину на сервере(ах) или выбирать облачную подписку для масштабирования как приложения предприятия, совместимого со масштабируемыми архитектурами. В этом Apache, Cassandra являются ключевыми компонентами для выполнения тяжелой работы по хранению и сравнению векторов, а сервер Ollama – для генерации векторных вложений.
Это все! Спасибо за то, что прочитали до конца.
Source:
https://dzone.com/articles/build-rag-apps-apache-cassandra-python-ollama