













La génération augmentée par récupération (RAG) est l’approche la plus populaire pour obtenir des données en temps réel ou des données mises à jour à partir d’une source de données en fonction de l’entrée textuelle des utilisateurs. Ainsi, elle permet de doter toutes nos applications de recherche de recherche neuronale de pointe.
Dans les systèmes de recherche RAG, chaque requête utilisateur est convertie en une représentation vectorielle par un modèle d’incorporation, et cette comparaison de vecteurs est effectuée à l’aide de différents algorithmes tels que la similarité cosinus, la sous-séquence commune la plus longue, etc., avec les représentations vectorielles existantes stockées dans notre base de données de support vectoriel.
Les vecteurs existants stockés dans la base de données vectorielle sont également générés ou mis à jour de manière asynchrone par un processus de fond séparé.
 Ce schéma fournit un aperçu conceptuel de la comparaison de vecteurs
Ce schéma fournit un aperçu conceptuel de la comparaison de vecteurs
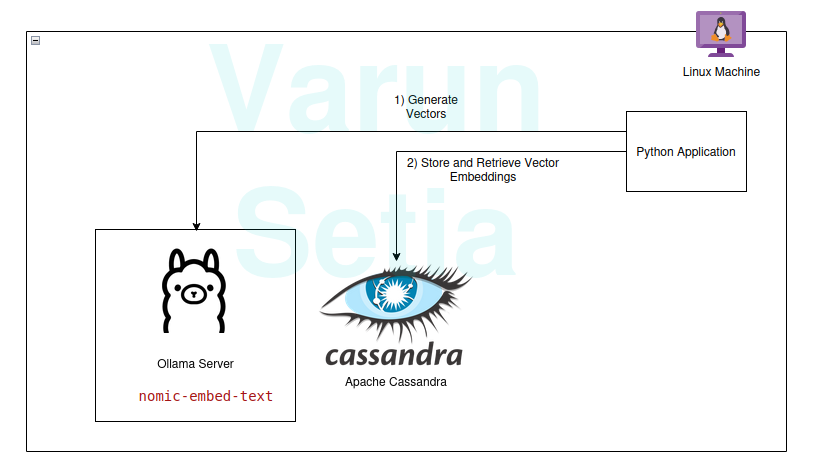
Pour utiliser RAG, nous avons besoin au moins d’un modèle d’incorporation et d’une base de données de stockage de vecteurs à utiliser par l’application. Les contributions de la communauté et des projets open source nous fournissent un ensemble incroyable d’outils qui nous aident à construire des applications RAG efficaces et efficientes. Applications RAG.
Dans cet article, nous mettrons en œuvre l’utilisation d’une base de données vectorielle et d’un modèle de génération d’incorporation dans une application Python. Si vous lisez ce concept pour la première fois ou la énième fois, vous avez seulement besoin d’outils pour travailler, et aucune abonnement n’est nécessaire pour aucun outil. Vous pouvez simplement télécharger les outils et commencer.
Notre pile technologique se compose des outils open source et gratuits suivants :
- Système d’exploitation – Ubuntu Linux
- Base de données vectorielle – Apache Cassandra
- Modèle d’incorporation – nomic-embed-text
- Langage de programmation – Python
Avantages clés de cette pile
- Open-source
- Données isolées pour répondre aux normes de conformité des données
Guide de mise en œuvre
Vous pouvez mettre en œuvre et suivre si les prérequis sont remplis ; sinon, lisez jusqu’à la fin pour comprendre les concepts.
Prérequis
- Linux (Dans mon cas, c’est Ubuntu 24.04.1 LTS)
- Configuration Java (OpenJDK 17.0.2)
- Python (3.11.11)
- Ollama
Configuration du modèle Ollama
Ollama est un serveur middleware open source qui fait office d’abstraction entre l’IA générative et les applications en installant tous les outils nécessaires pour rendre les modèles d’IA générative disponibles à la consommation en tant que CLI et API sur une machine. Il possède la plupart des modèles disponibles publiquement tels que llama, phi, mistral, snowflake-arctic-embed, etc. Il est multiplateforme et peut être facilement configuré dans un système d’exploitation.
Dans Ollama, nous allons extraire le modèle nomic-embed-text pour générer des embeddings.
Exécutez en ligne de commande :
ollama pull nomic-embed-text
Ce modèle génère des embeddings de vecteurs de taille 768.
Configuration et Scripts Apache Cassandra
Cassandra est une base de données NoSQL open source conçue pour fonctionner avec un volume de charges de travail élevé nécessitant une grande mise à l’échelle selon les besoins de l’industrie. Récemment, elle a ajouté la prise en charge de la recherche vectorielle dans sa version 5.0 qui facilitera notre cas d’utilisation RAG.
Remarque: Cassandra nécessite un système d’exploitation Linux pour fonctionner ; elle peut également être installée en tant qu’image Docker.
Installation
Téléchargez Apache Cassandra depuis https://cassandra.apache.org/_/download.html.
Configurez Cassandra dans votre PATH.
Démarrez le serveur en exécutant la commande suivante dans la ligne de commande :
cassandra
Table
Ouvrez un nouveau terminal Linux et écrivez cqlsh; cela ouvrira l’interpréteur pour le langage de requête Cassandra. Maintenant, exécutez les scripts ci-dessous pour créer l’espace de clés embeddings, la table document_vectors et l’index nécessaire edv_ann_index pour effectuer une recherche vectorielle.
CREATE KEYSPACE IF NOT EXISTS embeddings
WITH REPLICATION = { 'class' : 'SimpleStrategy', 'replication_factor' : '1' };
USE embeddings;
CREATE TABLE IF NOT EXISTS embeddings.document_vectors (
record_id timeuuid,
id uuid,
content_chunk text,
content_vector VECTOR <FLOAT, 768>,
created_at timestamp,
PRIMARY KEY (id, created_at)
)
WITH CLUSTERING ORDER BY (created_at DESC);
CREATE INDEX IF NOT EXISTS edv_ann_index
ON embeddings.document_vectors(content_vector) USING 'sai';
Remarque: content_vector VECTOR <FLOAT, 768> est responsable de stocker des vecteurs de longueur 768 générés par le modèle.
Étape 1: Nous sommes prêts avec la configuration de la base de données pour stocker des vecteurs.
Code Python
Ce langage de programmation n’a certainement pas besoin d’être présenté; il est facile à utiliser et apprécié par l’industrie avec un fort support de la communauté.
Environnement Virtuel
Configurer l’environnement virtuel:
sudo apt install python3-virtualenv && python3 -m venv myvenv
Activer l’environnement virtuel:
source /media/setia/Data/Tutorials/cassandra-ollama-app/myvenv/bin/activate
Paquets
Télécharger le paquet Datastax Cassandra:
pip install cassandra-driver
Télécharger le paquet requests:
pip install requests
Fichier
Créez un fichier nommé app.py.
Ensuite, écrivez le code ci-dessous pour insérer des documents d’exemple dans Cassandra. C’est toujours la première étape pour insérer des données dans la base de données; cela peut être fait par un processus séparé de manière asynchrone. À des fins de démonstration, j’ai écrit une méthode qui insérera d’abord des documents dans la base de données. Plus tard, nous pourrons commenter cette méthode une fois l’insertion des documents réussie.
from cassandra.cluster import Cluster
from cassandra.query import PreparedStatement, BoundStatement
import uuid
import datetime
import requests
cluster = Cluster(['127.0.0.1'],port=9042)
session = cluster.connect()
def generate_embedding(text):
embedding_url = 'http://localhost:11434/api/embed'
body = {
"model": "nomic-embed-text",
"input": text
}
response = requests.post(embedding_url, json = body)
return response.json()['embeddings'][0]
def insert_chunk(content, vector):
id = uuid.uuid4()
content_chunk = content
content_vector = vector
created_at = datetime.datetime.now()
insert_query = """
INSERT INTO embeddings.document_vectors (record_id, id, content_chunk, content_vector, created_at)
VALUES (now(), ?, ?, ?, ?)
"""
prepared_stmt = session.prepare(insert_query)
session.execute(prepared_stmt, [
id,
content_chunk,
content_vector,
created_at
])
def insert_sample_data_in_cassandra():
sentences = [
"The aroma of freshly baked bread wafted through the quaint bakery nestled in the cobblestone streets of Paris, making Varun feel like time stood still.",
"Sipping a spicy masala chai in a bustling tea stall in Mumbai, Varun felt he was tasting the very soul of the city.",
"The sushi in a small Tokyo diner was so fresh, it felt like Varun was on a culinary journey to the sea itself.",
"Under the starry desert sky in Morocco, Varun enjoyed a lamb tagine that tasted like a dream cooked slowly over a fire.",
"The cozy Italian trattoria served the creamiest risotto, perfectly capturing the heart of Tuscany on a plate, which Varun savored with delight.",
"Enjoying fish tacos on a sunny beach in Mexico, with the waves crashing nearby, made the flavors unforgettable for Varun.",
"The crispy waffles drizzled with syrup at a Belgian café were worth every minute of waiting, as Varun indulged in the decadent treat.",
"A bowl of warm pho in a roadside eatery in Hanoi felt like comfort wrapped in a broth of herbs and spices, giving Varun a sense of warmth.",
"Sampling chocolate truffles in a Swiss chocolate shop, Varun found himself in a moment of pure bliss amidst snow-capped mountains.",
"The street food stalls in Bangkok served fiery pad Thai that left Varun with a tangy memory of the city’s vibrant energy."
]
for sentence in sentences:
vector = generate_embedding(sentence)
insert_chunk(sentence, vector)
insert_sample_data_in_cassandra()
Ensuite, exécutez ce fichier à l’aide de la ligne de commande dans l’environnement virtuel:
python app.py
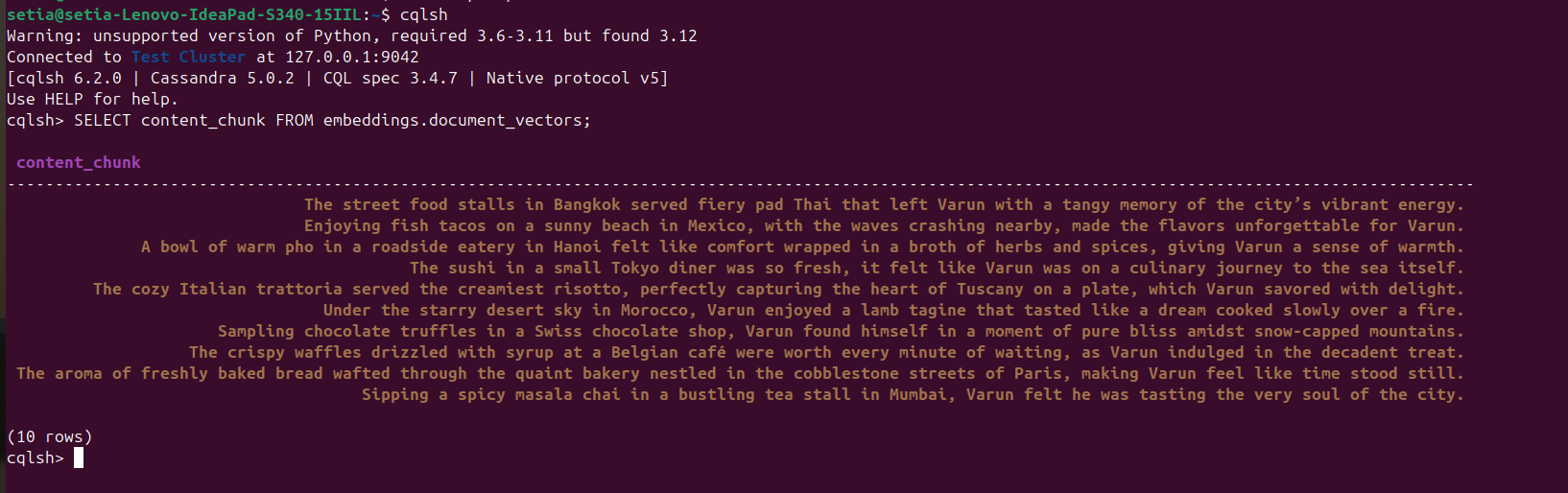
Une fois que le fichier est exécuté et que les documents sont insérés, cela peut être vérifié en interrogeant la base de données Cassandra depuis la console cqlsh. Pour cela, ouvrez cqlsh et exécutez :
SELECT content_chunk FROM embeddings.document_vectors;
Cela renverra 10 documents insérés dans la base de données, comme indiqué dans la capture d’écran ci-dessous.
Étape 2 : Nous avons terminé la configuration des données dans notre base de données vectorielle.
À présent, nous allons écrire du code pour interroger des documents en fonction de la similarité cosinus. La similarité cosinus est le produit scalaire de deux valeurs vectorielles. Sa formule est A.B / |A||B|. Cette similarité cosinus est prise en charge de manière interne par Apache Cassandra, ce qui nous aide à calculer tout dans la base de données et à gérer efficacement de grandes quantités de données.
Le code ci-dessous est explicite ; il récupère les trois premiers résultats en fonction de la similarité cosinus en utilisant ORDER BY <nom de colonne> ANN OF <text_vector> et renvoie également les valeurs de similarité cosinus. Pour exécuter ce code, nous devons nous assurer que l’indexation est appliquée à cette colonne vectorielle.
def query_rag(text):
text_embeddings = generate_embedding(text)
select_query = """
SELECT content_chunk,similarity_cosine(content_vector, ?) FROM embeddings.document_vectors
ORDER BY content_vector ANN OF ?
LIMIT 3
"""
prepared_stmt = session.prepare(select_query)
result_rows = session.execute(prepared_stmt, [
text_embeddings,
text_embeddings
])
for row in result_rows:
print(row[0], row[1])
query_rag('Tell about my Bangkok experiences')
N’oubliez pas de commenter le code d’insertion :
#insert_sample_data_in_cassandra()
À présent, exécutez le code Python en utilisant python app.py.
Nous obtiendrons le résultat suivant :
(myvenv) setia@setia-Lenovo-IdeaPad-S340-15IIL:/media/setia/Data/Tutorials/cassandra-ollama-app$ python app.py
The street food stalls in Bangkok served fiery pad Thai that left Varun with a tangy memory of the city’s vibrant energy. 0.8205469250679016
Sipping a spicy masala chai in a bustling tea stall in Mumbai, Varun felt he was tasting the very soul of the city. 0.7719690799713135
A bowl of warm pho in a roadside eatery in Hanoi felt like comfort wrapped in a broth of herbs and spices, giving Varun a sense of warmth. 0.7495554089546204
Vous pouvez voir que la similarité cosinus de « Les étals de nourriture de rue à Bangkok servaient un pad thaï piquant qui a laissé Varun avec un souvenir épicé de l’énergie vibrante de la ville. » est 0,8205469250679016, ce qui est la correspondance la plus proche.
Dernière étape : Nous avons implémenté la recherche RAG.
Applications d’entreprise
Apache Cassandra
Pour les entreprises, nous pouvons utiliser Apache Cassandra 5.0 auprès des fournisseurs de cloud populaires tels que Microsoft Azure, AWS, GCP, etc.
Ollama
Ce middleware nécessite une machine virtuelle compatible avec un GPU alimenté par Nvidia pour exécuter des modèles haute performance, mais nous n’avons pas besoin de machines virtuelles haut de gamme pour les modèles utilisés pour générer des vecteurs. Selon les besoins de trafic, plusieurs machines virtuelles peuvent être utilisées, ou tout service d’IA générative comme Open AI, Anthropy, etc., dont le Coût Total de Possession est plus bas pour les besoins de mise à l’échelle ou les besoins de gouvernance des données.
VM Linux
Apache Cassandra et Ollama peuvent être combinés et hébergés dans une seule VM Linux si le cas d’utilisation ne nécessite pas une utilisation intensive pour réduire le Coût Total de Possession ou répondre aux besoins de gouvernance des données.
Conclusion
Nous pouvons facilement créer des applications RAG en utilisant le système d’exploitation Linux, Apache Cassandra, en incorporant des modèles (nomic-embed-text) utilisés via Ollama, et Python avec de bonnes performances sans avoir besoin d’un abonnement cloud supplémentaire ou de services dans le confort de nos machines/serveurs.
Cependant, héberger une machine virtuelle sur un serveur ou opter pour un abonnement cloud pour le dimensionnement en tant qu’application d’entreprise conforme aux architectures évolutives est recommandé. Dans ce cas, Apache, Cassandra est un composant clé pour effectuer le gros du travail de stockage de vecteurs et de comparaison de vecteurs, et le serveur Ollama pour générer des embeddings de vecteurs.
C’est tout ! Merci d’avoir lu jusqu’au bout.
Source:
https://dzone.com/articles/build-rag-apps-apache-cassandra-python-ollama