













La generación aumentada por recuperación (RAG) es el enfoque más popular para obtener datos en tiempo real o datos actualizados de una fuente de datos basada en el texto ingresado por los usuarios. Así, empoderamos todas nuestras aplicaciones de búsqueda con una búsqueda neuronal de vanguardia.
En los sistemas de búsqueda RAG, cada solicitud de usuario se convierte en una representación vectorial mediante un modelo de incrustación, y esta comparación de vectores se realiza utilizando varios algoritmos, como la similitud coseno, la sub-secuencia común más larga, etc., con las representaciones vectoriales existentes almacenadas en nuestra base de datos que soporta vectores.
Los vectores existentes almacenados en la base de datos de vectores también se generan o actualizan de manera asíncrona mediante un proceso en segundo plano separado.
 Este diagrama proporciona una visión conceptual de la comparación de vectores
Este diagrama proporciona una visión conceptual de la comparación de vectores
Para utilizar RAG, necesitamos al menos un modelo de incrustación y una base de datos de almacenamiento de vectores que sea utilizada por la aplicación. Las contribuciones de la comunidad y proyectos de código abierto nos proporcionan un conjunto increíble de herramientas que nos ayudan a construir aplicaciones RAG efectivas y eficientes.
En este artículo, implementaremos el uso de una base de datos vectorial y un modelo de generación de incrustaciones en una aplicación de Python. Si estás leyendo este concepto por primera vez o por enésima vez, solo necesitas herramientas para trabajar, y no se requiere suscripción para ninguna herramienta. Simplemente puedes descargar las herramientas y comenzar.
Nuestra pila tecnológica consiste en las siguientes herramientas de código abierto y gratuitas:
- Sistema operativo – Ubuntu Linux
- Base de datos vectorial – Apache Cassandra
- Modelo de incrustación – nomic-embed-text
- Lenguaje de programación – Python
Beneficios clave de esta pila
- Código abierto
- Datos aislados para cumplir con los estándares de conformidad de datos
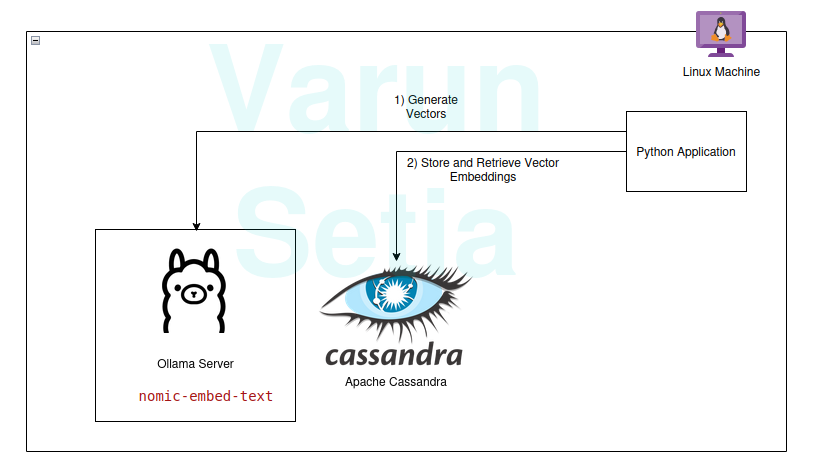
Guía de implementación
Puedes implementar y seguir si se cumplen los requisitos previos; de lo contrario, lee hasta el final para entender los conceptos.
Requisitos previos
- Linux (En mi caso, es Ubuntu 24.04.1 LTS)
- Configuración de Java (OpenJDK 17.0.2)
- Python (3.11.11)
- Ollama
Configuración del modelo Ollama
Ollama es un servidor middleware de código abierto que actúa como una abstracción entre la IA generativa y las aplicaciones al instalar todas las herramientas necesarias para hacer que los modelos de IA generativa estén disponibles para consumir como CLI y API en una máquina. Tiene la mayoría de los modelos disponibles abiertamente, como llama, phi, mistral, snowflake-arctic-embed, etc. Es multiplataforma y se puede configurar fácilmente en el sistema operativo.
En Ollama, obtendremos el nomic-embed-text modelo para generar embeddings.
Ejecuta en la línea de comandos:
ollama pull nomic-embed-text
Este modelo genera embeddings de tamaño 768 vectores.
Configuración y Scripts de Apache Cassandra
Cassandra es una base de datos NoSQL de código abierto diseñada para trabajar con una gran cantidad de cargas de trabajo que requieren alta escalabilidad según las necesidades de la industria. Recientemente, ha agregado soporte para búsqueda vectorial en la versión 5.0, lo que facilitará nuestro caso de uso de RAG.
Nota: Cassandra requiere el sistema operativo Linux para funcionar; también se puede instalar como una imagen de docker.
Instalación
Descarga Apache Cassandra desde https://cassandra.apache.org/_/download.html.
Configura Cassandra en tu PATH.
Inicia el servidor ejecutando el siguiente comando en la línea de comandos:
cassandra
Tabla
Abra un nuevo terminal de Linux y escriba cqlsh; esto abrirá la terminal para el Lenguaje de Consulta de Cassandra. Ahora, ejecute los scripts a continuación para crear el espacio de llaves embeddings, la tabla document_vectors y el índice necesario edv_ann_index para realizar una búsqueda de vectores.
CREATE KEYSPACE IF NOT EXISTS embeddings
WITH REPLICATION = { 'class' : 'SimpleStrategy', 'replication_factor' : '1' };
USE embeddings;
CREATE TABLE IF NOT EXISTS embeddings.document_vectors (
record_id timeuuid,
id uuid,
content_chunk text,
content_vector VECTOR <FLOAT, 768>,
created_at timestamp,
PRIMARY KEY (id, created_at)
)
WITH CLUSTERING ORDER BY (created_at DESC);
CREATE INDEX IF NOT EXISTS edv_ann_index
ON embeddings.document_vectors(content_vector) USING 'sai';
Nota: content_vector VECTOR <FLOAT, 768> es responsable de almacenar vectores de longitud 768 que son generados por el modelo.
Hito 1: Estamos listos con la configuración de la base de datos para almacenar vectores.
Código Python
Este lenguaje de programación ciertamente no necesita presentación; es fácil de usar y amado por la industria con un sólido soporte de la comunidad.
Entorno Virtual
Configurar entorno virtual:
sudo apt install python3-virtualenv && python3 -m venv myvenv
Activar entorno virtual:
source /media/setia/Data/Tutorials/cassandra-ollama-app/myvenv/bin/activate
Paquetes
Descargar el paquete Datastax Cassandra:
pip install cassandra-driver
Descargar el paquete requests:
pip install requests
Archivo
Crear un archivo llamado app.py.
Ahora, escriba el código a continuación para insertar documentos de muestra en Cassandra. Este es siempre el primer paso para insertar datos en la base de datos; puede ser realizado por un proceso separado de forma asíncrona. Para propósitos de demostración, he escrito un método que insertará los documentos primero en la base de datos. Más adelante, podemos comentar este método una vez que la inserción de los documentos sea exitosa.
from cassandra.cluster import Cluster
from cassandra.query import PreparedStatement, BoundStatement
import uuid
import datetime
import requests
cluster = Cluster(['127.0.0.1'],port=9042)
session = cluster.connect()
def generate_embedding(text):
embedding_url = 'http://localhost:11434/api/embed'
body = {
"model": "nomic-embed-text",
"input": text
}
response = requests.post(embedding_url, json = body)
return response.json()['embeddings'][0]
def insert_chunk(content, vector):
id = uuid.uuid4()
content_chunk = content
content_vector = vector
created_at = datetime.datetime.now()
insert_query = """
INSERT INTO embeddings.document_vectors (record_id, id, content_chunk, content_vector, created_at)
VALUES (now(), ?, ?, ?, ?)
"""
prepared_stmt = session.prepare(insert_query)
session.execute(prepared_stmt, [
id,
content_chunk,
content_vector,
created_at
])
def insert_sample_data_in_cassandra():
sentences = [
"The aroma of freshly baked bread wafted through the quaint bakery nestled in the cobblestone streets of Paris, making Varun feel like time stood still.",
"Sipping a spicy masala chai in a bustling tea stall in Mumbai, Varun felt he was tasting the very soul of the city.",
"The sushi in a small Tokyo diner was so fresh, it felt like Varun was on a culinary journey to the sea itself.",
"Under the starry desert sky in Morocco, Varun enjoyed a lamb tagine that tasted like a dream cooked slowly over a fire.",
"The cozy Italian trattoria served the creamiest risotto, perfectly capturing the heart of Tuscany on a plate, which Varun savored with delight.",
"Enjoying fish tacos on a sunny beach in Mexico, with the waves crashing nearby, made the flavors unforgettable for Varun.",
"The crispy waffles drizzled with syrup at a Belgian café were worth every minute of waiting, as Varun indulged in the decadent treat.",
"A bowl of warm pho in a roadside eatery in Hanoi felt like comfort wrapped in a broth of herbs and spices, giving Varun a sense of warmth.",
"Sampling chocolate truffles in a Swiss chocolate shop, Varun found himself in a moment of pure bliss amidst snow-capped mountains.",
"The street food stalls in Bangkok served fiery pad Thai that left Varun with a tangy memory of the city’s vibrant energy."
]
for sentence in sentences:
vector = generate_embedding(sentence)
insert_chunk(sentence, vector)
insert_sample_data_in_cassandra()
Ahora, ejecute este archivo usando la línea de comandos en el entorno virtual:
python app.py
Una vez que se ejecuta el archivo y se insertan los documentos, esto se puede verificar consultando la base de datos de Cassandra desde la consola cqlsh. Para ello, abre cqlsh y ejecuta:
SELECT content_chunk FROM embeddings.document_vectors;
Esto devolverá 10 documentos insertados en la base de datos, como se ve en la captura de pantalla a continuación.
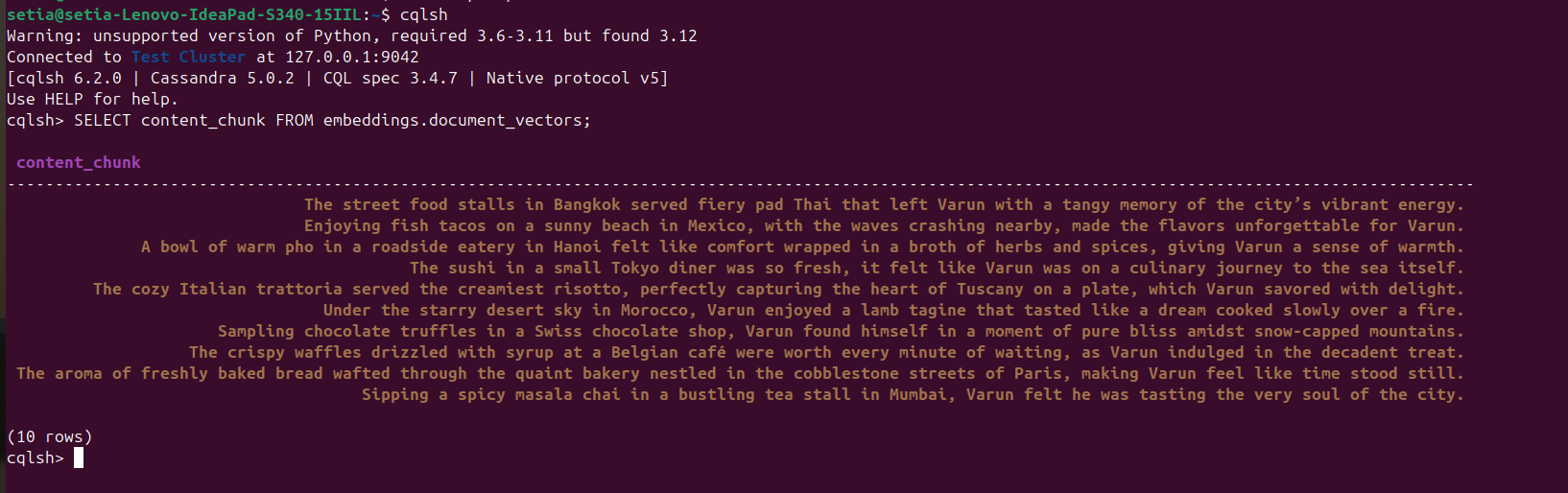
Hitos 2: Hemos terminado con la configuración de datos en nuestra base de datos vectorial.
Ahora, escribiremos código para consultar documentos basados en similitud de coseno. La similitud de coseno es el producto punto de dos valores vectoriales. Su fórmula es A.B / |A||B|. Esta similitud de coseno es soportada internamente por Apache Cassandra, lo que nos ayuda a calcular todo en la base de datos y manejar grandes datos de manera eficiente.
El código a continuación se explica por sí mismo; obtiene los tres mejores resultados basados en similitud de coseno usando ORDER BY <nombre de la columna> ANN OF <text_vector> y también devuelve los valores de similitud de coseno. Para ejecutar este código, necesitamos asegurarnos de que se aplique la indexación a esta columna vectorial.
def query_rag(text):
text_embeddings = generate_embedding(text)
select_query = """
SELECT content_chunk,similarity_cosine(content_vector, ?) FROM embeddings.document_vectors
ORDER BY content_vector ANN OF ?
LIMIT 3
"""
prepared_stmt = session.prepare(select_query)
result_rows = session.execute(prepared_stmt, [
text_embeddings,
text_embeddings
])
for row in result_rows:
print(row[0], row[1])
query_rag('Tell about my Bangkok experiences')
Recuerda comentar el código de inserción:
#insert_sample_data_in_cassandra()
Ahora, ejecuta el código Python usando python app.py.
Obtendremos la siguiente salida:
(myvenv) setia@setia-Lenovo-IdeaPad-S340-15IIL:/media/setia/Data/Tutorials/cassandra-ollama-app$ python app.py
The street food stalls in Bangkok served fiery pad Thai that left Varun with a tangy memory of the city’s vibrant energy. 0.8205469250679016
Sipping a spicy masala chai in a bustling tea stall in Mumbai, Varun felt he was tasting the very soul of the city. 0.7719690799713135
A bowl of warm pho in a roadside eatery in Hanoi felt like comfort wrapped in a broth of herbs and spices, giving Varun a sense of warmth. 0.7495554089546204
Puedes ver que la similitud de coseno de “Los puestos de comida callejera en Bangkok servían pad Thai picante que dejó a Varun con un recuerdo agridulce de la energía vibrante de la ciudad.” es 0.8205469250679016, que es la coincidencia más cercana.
Hitos Final: Hemos implementado la búsqueda RAG.
Aplicaciones Empresariales
Apache Cassandra
Para las empresas, podemos usar Apache Cassandra 5.0 de proveedores de nube populares como Microsoft Azure, AWS, GCP, etc.
Ollama
Este middleware requiere una máquina virtual compatible con GPU de Nvidia para ejecutar modelos de alto rendimiento, pero no necesitamos máquinas virtuales de gama alta para los modelos utilizados para generar vectores. Dependiendo de los requisitos de tráfico, se pueden usar múltiples máquinas virtuales, o cualquier servicio de IA generativa como Open AI, Anthropy, etc., el cual tenga un Costo Total de Propiedad más bajo para las necesidades de escalado o de Gobernanza de Datos.
Máquina Virtual Linux
Apache Cassandra y Ollama se pueden combinar y alojar en una sola Máquina Virtual Linux si el caso de uso no requiere un alto uso para reducir el Costo Total de Propiedad o para abordar las necesidades de Gobernanza de Datos.
Conclusión
Podemos construir fácilmente aplicaciones RAG utilizando el sistema operativo Linux, Apache Cassandra, modelos incrustados (nomic-embed-text) utilizados a través de Ollama y Python con un buen rendimiento sin necesidad de ninguna suscripción o servicios adicionales en la comodidad de nuestras máquinas/servidores.
Sin embargo, se recomienda alojar una máquina virtual en servidor(es) o optar por una suscripción en la nube para escalar como una aplicación empresarial compatible con arquitecturas escalables. En este caso, Apache y Cassandra son componentes clave para llevar a cabo la tarea pesada de nuestro almacenamiento de vectores y comparación de vectores, y el servidor Ollama para generar incrustaciones vectoriales.
¡Eso es todo! ¡Gracias por leer hasta el final!
Source:
https://dzone.com/articles/build-rag-apps-apache-cassandra-python-ollama