













檢索增強生成(RAG)是獲取實時數據或更新數據的最流行方法,這些數據來自數據源,基於用戶的文本輸入。因此,為我們所有的搜索應用程序提供了最先進的神經搜索。
在RAG搜索系統中,每個用戶請求都會通過嵌入模型轉換為向量表示,並使用各種算法(如余弦相似度、最長公共子序列等)執行此向量比較,與我們的向量支持數據庫中存儲的現有向量表示進行比較。
向量數據庫中存儲的現有向量也是通過單獨的後台進程異步生成或更新的。
 此圖表提供了向量比較的概念概述
此圖表提供了向量比較的概念概述
要使用RAG,我們至少需要一個嵌入模型和一個向量存儲數據庫供應用程序使用。社區和開源項目的貢獻為我們提供了一組令人驚嘆的工具,幫助我們構建有效和高效的RAG應用程序。
在這篇文章中,我們將在 Python 應用程式中實現向量資料庫和嵌入生成模型的使用。如果你第一次或第 n 次讀到這個概念,你只需要工具來工作,並且不需要任何工具的訂閱。你可以簡單地下載工具並開始使用。
我們的技術棧包括以下開源和免費使用的工具:
- 操作系統 – Ubuntu Linux
- 向量資料庫 – Apache Cassandra
- 嵌入模型 – nomic-embed-text
- 程式語言 – Python
這個技術棧的主要好處
- 開源
- 隔離數據以滿足數據合規標準
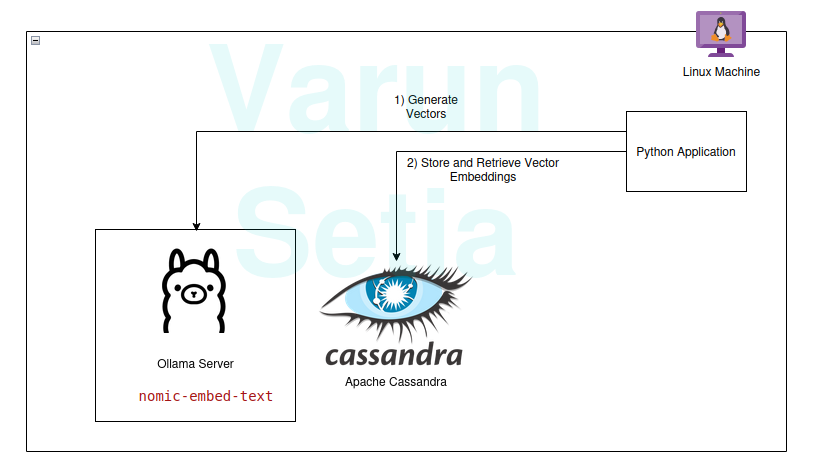
實施步驟
如果滿足先決條件,你可以實施並跟隨;否則,請閱讀到最後以理解概念。
先決條件
- Linux(在我這裡,是 Ubuntu 24.04.1 LTS)
- Java 設定(OpenJDK 17.0.2)
- Python(3.11.11)
- Ollama
Ollama 模型設定
Ollama 是一個開源的中間件伺服器,它在生成式人工智慧和應用程式之間充當抽象層,安裝所有必要的工具,使生成式人工智慧模型可以作為 CLI 和 API 在機器中使用。它擁有大多數公開可用的模型,如 llama、phi、mistral、snowflake-arctic-embed 等。它是跨平台的,可以在作業系統中輕鬆配置。
在 Ollama 中,我們將提取 nomic-embed-text 模型來生成嵌入。
在命令行運行:
ollama pull nomic-embed-text
此模型生成大小為 768 向量的嵌入。
Apache Cassandra 設置和腳本
Cassandra 是一個設計用於處理需要高擴展性的高工作量的開源 NoSQL 資料庫,符合行業需求。最近,在版本 5.0 中添加了支持向量搜索的功能,這將有助於我們的 RAG 使用案例。
注意: Cassandra 需要 Linux 作業系統才能運行;也可以安裝為 Docker 映像。
安裝
從 https://cassandra.apache.org/_/download.html 下載 Apache Cassandra。
將 Cassandra 配置到您的 PATH 中。
通過在命令行中運行以下命令來啟動伺服器:
cassandra
Table
打開一個新的 Linux 終端並輸入 cqlsh;這將打開 Cassandra 查詢語言的命令行界面。現在,執行以下腳本來創建 embeddings 鍵空間、document_vectors 表和必要的索引 edv_ann_index 以執行向量搜索。
CREATE KEYSPACE IF NOT EXISTS embeddings
WITH REPLICATION = { 'class' : 'SimpleStrategy', 'replication_factor' : '1' };
USE embeddings;
CREATE TABLE IF NOT EXISTS embeddings.document_vectors (
record_id timeuuid,
id uuid,
content_chunk text,
content_vector VECTOR <FLOAT, 768>,
created_at timestamp,
PRIMARY KEY (id, created_at)
)
WITH CLUSTERING ORDER BY (created_at DESC);
CREATE INDEX IF NOT EXISTS edv_ann_index
ON embeddings.document_vectors(content_vector) USING 'sai';
注意: content_vector VECTOR <FLOAT, 768> 負責存儲由模型生成的長度為 768 的向量。
里程碑 1:我們已經準備好數據庫設置來存儲向量。
Python 代碼
這種 編程語言 無需介紹;它易於使用,受到行業的喜愛,並擁有強大的社區支持。
虛擬環境
設置虛擬環境:
sudo apt install python3-virtualenv && python3 -m venv myvenv
激活虛擬環境:
source /media/setia/Data/Tutorials/cassandra-ollama-app/myvenv/bin/activate
包
下載 Datastax Cassandra 包:
pip install cassandra-driver
下載 requests 包:
pip install requests
文件
創建一個名為 app.py 的文件。
現在,編寫以下代碼以在 Cassandra 中插入示例文檔。這是將數據插入數據庫的第一步;可以通過單獨的進程異步完成。出於演示目的,我寫了一個方法,將首先在數據庫中插入文檔。稍後,一旦文檔插入成功,我們可以註釋掉這個方法。
from cassandra.cluster import Cluster
from cassandra.query import PreparedStatement, BoundStatement
import uuid
import datetime
import requests
cluster = Cluster(['127.0.0.1'],port=9042)
session = cluster.connect()
def generate_embedding(text):
embedding_url = 'http://localhost:11434/api/embed'
body = {
"model": "nomic-embed-text",
"input": text
}
response = requests.post(embedding_url, json = body)
return response.json()['embeddings'][0]
def insert_chunk(content, vector):
id = uuid.uuid4()
content_chunk = content
content_vector = vector
created_at = datetime.datetime.now()
insert_query = """
INSERT INTO embeddings.document_vectors (record_id, id, content_chunk, content_vector, created_at)
VALUES (now(), ?, ?, ?, ?)
"""
prepared_stmt = session.prepare(insert_query)
session.execute(prepared_stmt, [
id,
content_chunk,
content_vector,
created_at
])
def insert_sample_data_in_cassandra():
sentences = [
"The aroma of freshly baked bread wafted through the quaint bakery nestled in the cobblestone streets of Paris, making Varun feel like time stood still.",
"Sipping a spicy masala chai in a bustling tea stall in Mumbai, Varun felt he was tasting the very soul of the city.",
"The sushi in a small Tokyo diner was so fresh, it felt like Varun was on a culinary journey to the sea itself.",
"Under the starry desert sky in Morocco, Varun enjoyed a lamb tagine that tasted like a dream cooked slowly over a fire.",
"The cozy Italian trattoria served the creamiest risotto, perfectly capturing the heart of Tuscany on a plate, which Varun savored with delight.",
"Enjoying fish tacos on a sunny beach in Mexico, with the waves crashing nearby, made the flavors unforgettable for Varun.",
"The crispy waffles drizzled with syrup at a Belgian café were worth every minute of waiting, as Varun indulged in the decadent treat.",
"A bowl of warm pho in a roadside eatery in Hanoi felt like comfort wrapped in a broth of herbs and spices, giving Varun a sense of warmth.",
"Sampling chocolate truffles in a Swiss chocolate shop, Varun found himself in a moment of pure bliss amidst snow-capped mountains.",
"The street food stalls in Bangkok served fiery pad Thai that left Varun with a tangy memory of the city’s vibrant energy."
]
for sentence in sentences:
vector = generate_embedding(sentence)
insert_chunk(sentence, vector)
insert_sample_data_in_cassandra()
現在,使用命令行在虛擬環境中運行這個文件:
python app.py
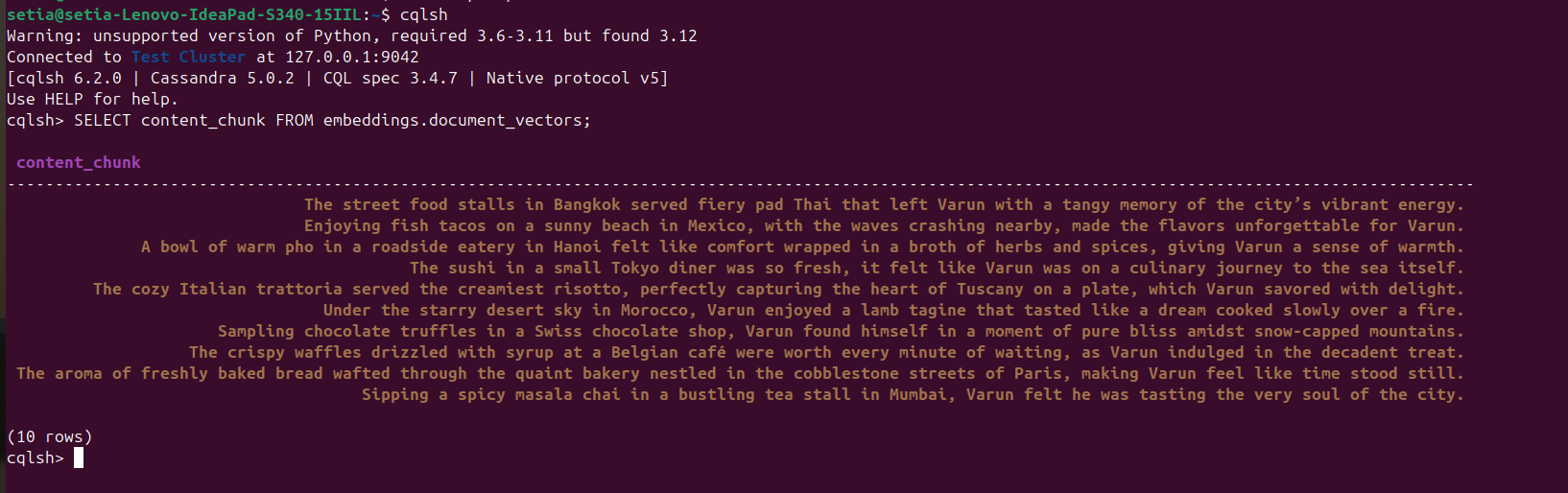
一旦檔案執行並插入文件,這可以通過從 cqlsh 控制台查詢 Cassandra 數據庫來驗證。為此,打開 cqlsh 並執行:
SELECT content_chunk FROM embeddings.document_vectors;
這將返回插入數據庫中的 10 個文件,如下圖所示。
里程碑 2:我們在向量數據庫中的數據設置已經完成。
現在,我們將編寫代碼根據餘弦相似度查詢文件。餘弦相似度是兩個向量值的點積。其公式為 A.B / |A||B|。這種餘弦相似度由 Apache Cassandra 內部支持,幫助我們在數據庫中計算所有內容並高效處理大量數據。
下面的代碼不言自明;它利用 ORDER BY <column name> ANN OF <text_vector> 根據餘弦相似度獲取前三個結果,並返回餘弦相似度值。要執行此代碼,我們需要確保對此向量列應用索引。
def query_rag(text):
text_embeddings = generate_embedding(text)
select_query = """
SELECT content_chunk,similarity_cosine(content_vector, ?) FROM embeddings.document_vectors
ORDER BY content_vector ANN OF ?
LIMIT 3
"""
prepared_stmt = session.prepare(select_query)
result_rows = session.execute(prepared_stmt, [
text_embeddings,
text_embeddings
])
for row in result_rows:
print(row[0], row[1])
query_rag('Tell about my Bangkok experiences')
請記得註釋插入代碼:
#insert_sample_data_in_cassandra()
現在,使用 python app.py 執行 Python 代碼。
我們將獲得以下輸出:
(myvenv) setia@setia-Lenovo-IdeaPad-S340-15IIL:/media/setia/Data/Tutorials/cassandra-ollama-app$ python app.py
The street food stalls in Bangkok served fiery pad Thai that left Varun with a tangy memory of the city’s vibrant energy. 0.8205469250679016
Sipping a spicy masala chai in a bustling tea stall in Mumbai, Varun felt he was tasting the very soul of the city. 0.7719690799713135
A bowl of warm pho in a roadside eatery in Hanoi felt like comfort wrapped in a broth of herbs and spices, giving Varun a sense of warmth. 0.7495554089546204
您可以看到「曼谷的街頭小吃攤提供的火辣泰式炒河粉讓 Varun 對這座城市充滿活力的能量留下了酸酸的回憶。」的餘弦相似度為 0.8205469250679016,這是最接近的匹配。
最終里程碑:我們已經實現了 RAG 搜索。
企業應用
Apache Cassandra
對於企業,我們可以從流行的雲供應商(如Microsoft Azure、AWS、GCP等)使用Apache Cassandra 5.0。
Ollama
這個中間件需要與搭載Nvidia GPU的VM兼容,以運行高性能模型,但對於生成向量的模型,我們不需要高端VM。根據流量需求,可以使用多個VM,或使用任何生成式AI服務,如Open AI、Anthropy等,以滿足擴展需求或數據治理需求,取決於總擁有成本較低。
Linux VM
如果用例不要求高使用率,Apache Cassandra和Ollama可以結合在一個Linux VM中,以降低總擁有成本或滿足數據治理需求。
結論
我們可以輕鬆地使用Linux OS、Apache Cassandra、通過Ollama使用的嵌入模型(nomic-embed-text)和Python來構建RAG應用程序,實現良好的性能,而無需在我們的設備/伺服器上使用任何額外的雲訂閱或服務。
然而,建議在伺服器上托管虛擬機(VM)或選擇雲端訂閱,以便能夠作為符合可擴展架構的企業應用進行擴展。在這個Apache中,Cassandra是我們向量存儲和向量比較的關鍵組件,而Ollama伺服器則用於生成向量嵌入。
就這樣!感謝您閱讀到最後。
Source:
https://dzone.com/articles/build-rag-apps-apache-cassandra-python-ollama