













توليد معزز بالاسترجاع (RAG) هو الأكثر شعبية للحصول على بيانات في الوقت الحقيقي أو بيانات محدثة من مصدر بيانات بناءً على النص المدخل من قبل المستخدمين. مما يعزز جميع تطبيقات البحث لدينا مع بحث عصبي متطور.
في أنظمة بحث RAG، يتم تحويل كل طلب مستخدم إلى تمثيل متجه بواسطة نموذج الإدخال، ويتم إجراء مقارنة هذا المتجه باستخدام خوارزميات متنوعة مثل تشابه جيب التمام، وأطول تسلسل مشترك، وغيرها، مع تمثيلات المتجهات الموجودة المخزنة في قاعدة بياناتنا الداعمة للمتجهات.
كما يتم إنشاء المتجهات الموجودة المخزنة في قاعدة بيانات المتجهات أو تحديثها بشكل غير متزامن بواسطة عملية خلفية منفصلة.
 يوفر هذا المخطط نظرة عامة مفهومية عن مقارنة المتجهات
يوفر هذا المخطط نظرة عامة مفهومية عن مقارنة المتجهات
لاستخدام RAG، نحتاج إلى نموذج إدخال وقاعدة بيانات لتخزين المتجهات ليتم استخدامها بواسطة التطبيق. توفر المساهمات من المجتمع ومشاريع المصدر المفتوح مجموعة مذهلة من الأدوات التي تساعدنا في بناء تطبيقات RAG فعالة وكفؤة.
في هذه المقالة، سنقوم بتنفيذ استخدام قاعدة بيانات متجهات ونموذج توليد تضمين في تطبيق بايثون. إذا كنت تقرأ هذا المفهوم للمرة الأولى أو n مرة، فأنت فقط تحتاج إلى أدوات للعمل، ولا حاجة لاشتراك في أي أداة. يمكنك ببساطة تحميل الأدوات والبدء.
يتكون مجموعة التقنيات لدينا من الأدوات مفتوحة المصدر والمجانية للاستخدام التالية:
- نظام التشغيل – أوبونتو لينوكس
- قاعدة بيانات المتجهات – أباتشي كاساندرا
- نموذج التضمين – nomic-embed-text
- لغة البرمجة – بايثون
الفوائد الرئيسية لهذه المجموعة
- مفتوحة المصدر
- بيانات معزولة لتلبية معايير الامتثال للبيانات
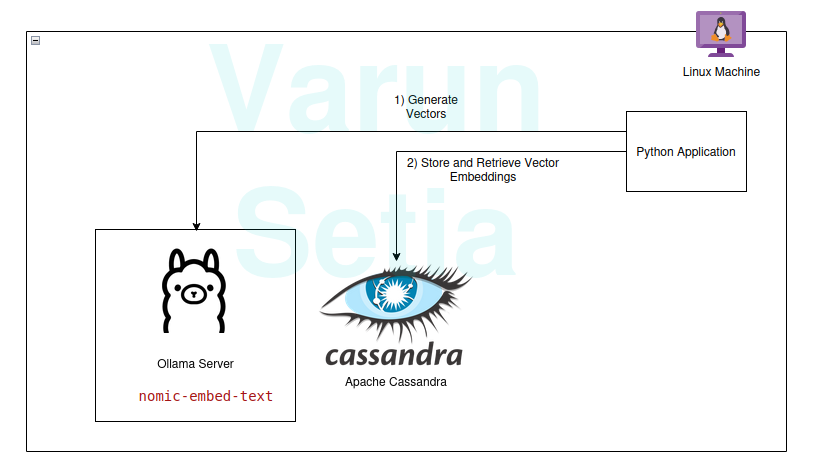
إجراءات التنفيذ
يمكنك التنفيذ والمتابعة إذا تم استيفاء المتطلبات السابقة؛ وإلا، اقرأ حتى النهاية لفهم المفاهيم.
المتطلبات السابقة
- لينوكس (في حالتي، هو أوبونتو 24.04.1 LTS)
- إعداد جافا (OpenJDK 17.0.2)
- بايثون (3.11.11)
- أولاما
إعداد نموذج أولاما
أولاما هو خادم وسيط مفتوح المصدر يعمل كطبقة تجريدية بين الذكاء الاصطناعي التوليدي والتطبيقات من خلال تثبيت جميع الأدوات اللازمة لجعل نماذج الذكاء الاصطناعي التوليدية متاحة للاستخدام عبر واجهة سطر الأوامر وواجهة برمجة التطبيقات في جهاز واحد. يحتوي على معظم النماذج المتاحة علنًا مثل لاما، في، ميسترال، سنوفليك-أركتيك-إيمبد، وغيرها. إنه متعدد المنصات ويمكن تكوينه بسهولة في نظام التشغيل.
في أولاما، سنقوم بسحب نومك-إيمبد-تيكست النموذج لتوليد التضمينات.
تشغيل في سطر الأوامر:
ollama pull nomic-embed-text
هذا النموذج يولد تضمينات بحجم 768 متجهات.
إعداد سكريبتات أباتشي كاساندرا
كاساندرا هي قاعدة بيانات NoSQL مفتوحة المصدر مصممة للعمل مع كمية عالية من الأحمال التي تتطلب توسعًا عاليًا وفقًا لاحتياجات الصناعة. مؤخرًا، أضافت دعمًا للبحث عن المتجهات في الإصدار 5.0 الذي سيسهل حالة استخدام RAG الخاصة بنا.
ملاحظة: تتطلب كاساندرا نظام تشغيل لينوكس للعمل؛ يمكن أيضًا تثبيتها كصورة دوكر.
التثبيت
قم بتنزيل أباتشي كاساندرا من https://cassandra.apache.org/_/download.html.
قم بتكوين كاساندرا في مسار النظام الخاص بك.
ابدأ الخادم عن طريق تشغيل الأمر التالي في سطر الأوامر:
cassandra
الجدول
افتح نافذة طرفية جديدة في نظام لينكس واكتب cqlsh؛ سيفتح هذا واجهة سطر الأوامر للغة استعلام كاساندرا. الآن، نفذ السكربتات أدناه لإنشاء مساحة المفاتيح embeddings، جدول document_vectors، والفهرس الضروري edv_ann_index لإجراء بحث عن المتجهات.
CREATE KEYSPACE IF NOT EXISTS embeddings
WITH REPLICATION = { 'class' : 'SimpleStrategy', 'replication_factor' : '1' };
USE embeddings;
CREATE TABLE IF NOT EXISTS embeddings.document_vectors (
record_id timeuuid,
id uuid,
content_chunk text,
content_vector VECTOR <FLOAT, 768>,
created_at timestamp,
PRIMARY KEY (id, created_at)
)
WITH CLUSTERING ORDER BY (created_at DESC);
CREATE INDEX IF NOT EXISTS edv_ann_index
ON embeddings.document_vectors(content_vector) USING 'sai';
ملاحظة: content_vector VECTOR <FLOAT, 768> مسؤولة عن تخزين المتجهات بطول 768 التي تم إنشاؤها بواسطة النموذج.
المرحلة 1: نحن جاهزون لإعداد قاعدة البيانات لتخزين المتجهات.
كود بايثون
هذه اللغة البرمجية بالتأكيد لا تحتاج إلى مقدمة؛ فهي سهلة الاستخدام ومحبوبة من قبل الصناعة مع دعم قوي من المجتمع.
البيئة الافتراضية
إعداد البيئة الافتراضية:
sudo apt install python3-virtualenv && python3 -m venv myvenv
تفعيل البيئة الافتراضية:
source /media/setia/Data/Tutorials/cassandra-ollama-app/myvenv/bin/activate
الحزم
تحميل حزمة داتاستاكس كاساندرا:
pip install cassandra-driver
تحميل حزمة الطلبات:
pip install requests
الملف
إنشاء ملف باسم app.py.
الآن، اكتب الكود أدناه لإدخال مستندات نموذجية في كاساندرا. هذه هي الخطوة الأولى دائمًا لإدخال البيانات في قاعدة البيانات؛ يمكن القيام بذلك بواسطة عملية منفصلة بشكل غير متزامن. لأغراض العرض، كتبت طريقة ستقوم بإدخال المستندات أولاً في قاعدة البيانات. لاحقًا، يمكننا التعليق على هذه الطريقة بمجرد نجاح إدخال المستندات.
from cassandra.cluster import Cluster
from cassandra.query import PreparedStatement, BoundStatement
import uuid
import datetime
import requests
cluster = Cluster(['127.0.0.1'],port=9042)
session = cluster.connect()
def generate_embedding(text):
embedding_url = 'http://localhost:11434/api/embed'
body = {
"model": "nomic-embed-text",
"input": text
}
response = requests.post(embedding_url, json = body)
return response.json()['embeddings'][0]
def insert_chunk(content, vector):
id = uuid.uuid4()
content_chunk = content
content_vector = vector
created_at = datetime.datetime.now()
insert_query = """
INSERT INTO embeddings.document_vectors (record_id, id, content_chunk, content_vector, created_at)
VALUES (now(), ?, ?, ?, ?)
"""
prepared_stmt = session.prepare(insert_query)
session.execute(prepared_stmt, [
id,
content_chunk,
content_vector,
created_at
])
def insert_sample_data_in_cassandra():
sentences = [
"The aroma of freshly baked bread wafted through the quaint bakery nestled in the cobblestone streets of Paris, making Varun feel like time stood still.",
"Sipping a spicy masala chai in a bustling tea stall in Mumbai, Varun felt he was tasting the very soul of the city.",
"The sushi in a small Tokyo diner was so fresh, it felt like Varun was on a culinary journey to the sea itself.",
"Under the starry desert sky in Morocco, Varun enjoyed a lamb tagine that tasted like a dream cooked slowly over a fire.",
"The cozy Italian trattoria served the creamiest risotto, perfectly capturing the heart of Tuscany on a plate, which Varun savored with delight.",
"Enjoying fish tacos on a sunny beach in Mexico, with the waves crashing nearby, made the flavors unforgettable for Varun.",
"The crispy waffles drizzled with syrup at a Belgian café were worth every minute of waiting, as Varun indulged in the decadent treat.",
"A bowl of warm pho in a roadside eatery in Hanoi felt like comfort wrapped in a broth of herbs and spices, giving Varun a sense of warmth.",
"Sampling chocolate truffles in a Swiss chocolate shop, Varun found himself in a moment of pure bliss amidst snow-capped mountains.",
"The street food stalls in Bangkok served fiery pad Thai that left Varun with a tangy memory of the city’s vibrant energy."
]
for sentence in sentences:
vector = generate_embedding(sentence)
insert_chunk(sentence, vector)
insert_sample_data_in_cassandra()
الآن، قم بتشغيل هذا الملف باستخدام سطر الأوامر في البيئة الافتراضية:
python app.py
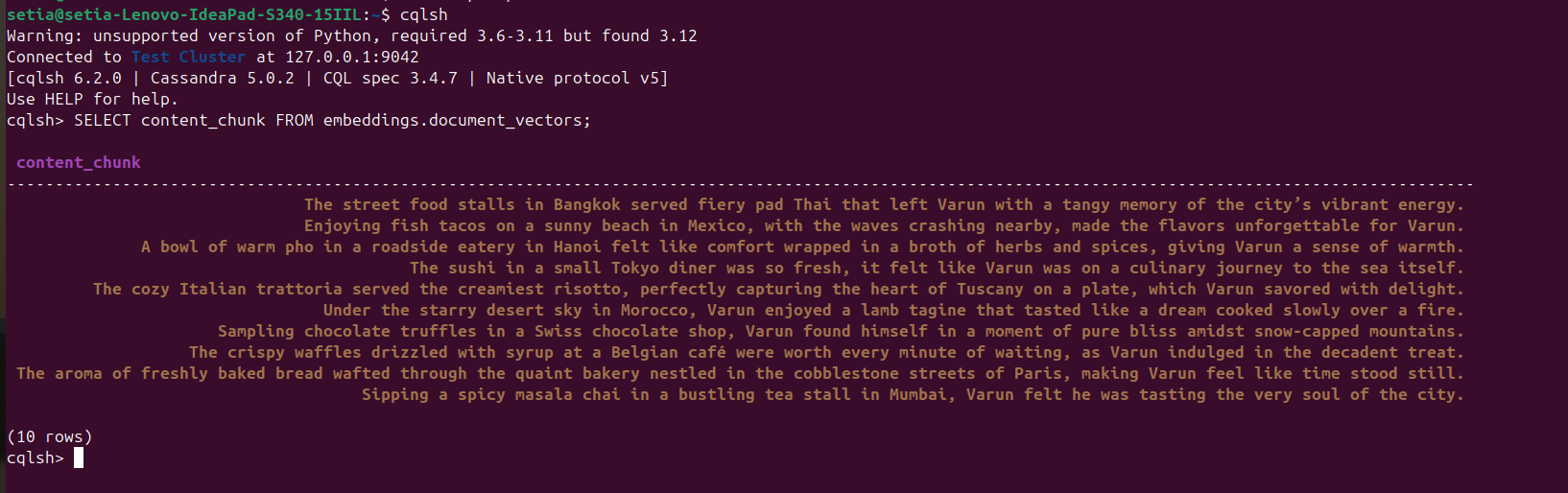
بمجرد تنفيذ الملف وإدراج الوثائق، يمكن التحقق من ذلك عن طريق الاستعلام عن قاعدة بيانات Cassandra من وحدة التحكم cqlsh. لهذا، افتح cqlsh وقم بتنفيذ:
SELECT content_chunk FROM embeddings.document_vectors;
سيتم إرجاع 10 وثائق تم إدراجها في قاعدة البيانات، كما هو موضح في اللقطة أدناه.
مرحلة 2: لقد انتهينا من إعداد البيانات في قاعدة البيانات الخاصة بنا.
الآن، سنقوم بكتابة الكود للاستعلام عن الوثائق بناءً على التشابه الكوسيني. التشابه الكوسيني هو حاصل ضرب قيمتين ناقطتين. صيغته A.B / |A||B|. يتم دعم هذا التشابه الكوسيني داخليًا بواسطة Apache Cassandra، مما يساعدنا على حساب كل شيء في قاعدة البيانات ومعالجة البيانات الكبيرة بكفاءة.
الكود أدناه هو واضح بذاته؛ يقوم بجلب أعلى ثلاث نتائج بناءً على التشابه الكوسيني باستخدام ORDER BY <column name> ANN OF <text_vector> ويعيد أيضًا قيم التشابه الكوسيني. لتنفيذ هذا الكود، يجب التأكد من تطبيق فهرسة على هذا العمود الناقط.
def query_rag(text):
text_embeddings = generate_embedding(text)
select_query = """
SELECT content_chunk,similarity_cosine(content_vector, ?) FROM embeddings.document_vectors
ORDER BY content_vector ANN OF ?
LIMIT 3
"""
prepared_stmt = session.prepare(select_query)
result_rows = session.execute(prepared_stmt, [
text_embeddings,
text_embeddings
])
for row in result_rows:
print(row[0], row[1])
query_rag('Tell about my Bangkok experiences')
تذكر تعليق كود الإدراج:
#insert_sample_data_in_cassandra()
الآن، قم بتنفيذ كود Python باستخدام python app.py.
سنحصل على الناتج أدناه:
(myvenv) setia@setia-Lenovo-IdeaPad-S340-15IIL:/media/setia/Data/Tutorials/cassandra-ollama-app$ python app.py
The street food stalls in Bangkok served fiery pad Thai that left Varun with a tangy memory of the city’s vibrant energy. 0.8205469250679016
Sipping a spicy masala chai in a bustling tea stall in Mumbai, Varun felt he was tasting the very soul of the city. 0.7719690799713135
A bowl of warm pho in a roadside eatery in Hanoi felt like comfort wrapped in a broth of herbs and spices, giving Varun a sense of warmth. 0.7495554089546204
يمكنك رؤية التشابه الكوسيني لـ “The street food stalls in Bangkok served fiery pad Thai that left Varun with a tangy memory of the city’s vibrant energy.” هو 0.8205469250679016، وهو أقرب تطابق.
المرحلة النهائية: لقد قمنا بتنفيذ بحث RAG.
تطبيقات المؤسسات
Apache Cassandra
بالنسبة للشركات، يمكننا استخدام أباتشي كاساندرا 5.0 من مزودي الخدمات السحابية الشهيرة مثل مايكروسوفت أزور، AWS، GCP، إلخ.
أولاما
يتطلب هذا الوسيط جهازًا افتراضيًا متوافقًا مع وحدة معالجة الرسوميات المدعومة بواسطة Nvidia لتشغيل النماذج عالية الأداء، ولكننا لا نحتاج إلى أجهزة افتراضية فائقة الأداء للنماذج المستخدمة لإنشاء البيانات النصية. وبناءً على متطلبات حركة المرور، يمكن استخدام عدة أجهزة افتراضية، أو أي خدمة ذكاء اصطناعي توليدية مثل Open AI، Anthropy، إلخ، أيهما منخفض في تكلفة الملكية الكلية لتلبية الاحتياجات المتعلقة بالتوسع أو احتياجات حوكمة البيانات.
أجهزة افتراضية Linux
يمكن دمج أباتشي كاساندرا وأولاما واستضافتهما في جهاز افتراضي Linux واحد إذا لم يكن الحالة الاستخدامية تتطلب استخدامًا مرتفعًا لتقليل تكلفة الملكية الكلية أو لتلبية احتياجات حوكمة البيانات.
الاستنتاج
يمكننا بسهولة بناء تطبيقات RAG باستخدام نظام التشغيل Linux، وأباتشي كاساندرا، ونماذج التضمين (nomic-embed-text) المستخدمة عبر أولاما، ولغة Python بأداء جيد دون الحاجة إلى أي اشتراك سحابي إضافي أو خدمات على أجهزتنا/خوادمنا.
ومع ذلك، يُنصح باستضافة جهاز افتراضي في الخادم (الخوادم) أو اختيار اشتراك سحابي للتوسع كتطبيق مؤسسي متوافق مع الهياكل القابلة للتوسع. في هذا الإطار، تُعتبر كاساندرا مكونًا رئيسيًا للقيام بالأعمال الثقيلة لتخزين المتجهات ومقارنة المتجهات، بينما يُستخدم خادم أولاما لتوليد تضمينات المتجهات.
هذا كل شيء! شكرًا لقراءتك حتى النهاية.
Source:
https://dzone.com/articles/build-rag-apps-apache-cassandra-python-ollama