













גנרציה מוגברת על ידי חיפוש (RAG) היא הגישה הפופולרית ביותר להשגת נתוני זמן אמת או נתונים מעודכנים ממקור נתונים בהתבסס על קלט טקסט של משתמשים. כך היא מעצימה את כל אפליקציות החיפוש שלנו עם חיפוש נוירלי מהשורה הראשונה.
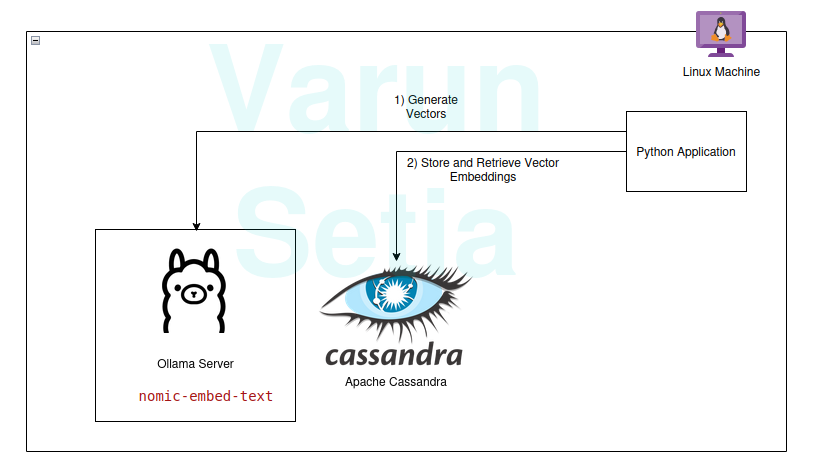
במערכות חיפוש RAG, כל בקשה של משתמש מומרת לייצוג וקטורי על ידי מודל הטמעה, והשוואת הווקטורים הזו מתבצעת באמצעות אלגוריתמים שונים כגון דמיון קוסינוסי, תת-סדרה משותפת הארוכה ביותר וכו', עם ייצוגים וקטוריים קיימים שנשמרים בבסיס הנתונים שלנו התומך בווקטורים.
הווקטורים הקיימים שנשמרים בבסיס הנתונים הווקטורי גם נוצרים או מעודכנים אסינכרונית על ידי תהליך רקע נפרד.
 הדיאגרמה הזו מספקת סקירה קונספטואלית של השוואת וקטורים
הדיאגרמה הזו מספקת סקירה קונספטואלית של השוואת וקטורים
כדי להשתמש ב-RAG, אנו זקוקים לפחות למודל הטמעה ולבסיס נתונים לאחסון וקטורים שישמש את האפליקציה. תרומות מהקהילה ומפרויקטים קוד פתוח מספקות לנו סט מדהים של כלים שעוזרים לנו לבנות אפליקציות RAG יעילות ואפקטיביות.
במאמר הזה, ניישם את השימוש במסד נתונים וקטורי ומודל ליצירת הטמעות באפליקציה ב-Python. אם אתה קורא את המונח הזה בפעם הראשונה או ה-n, אתה רק צריך כלים לעבוד, ולא נדרש מנוי לכל כלי. אתה יכול פשוט להוריד את הכלים ולהתחיל.
הטכנולוגיה שלנו כוללת את הכלים הבאים בקוד פתוח ולשימוש חופשי:
- מערכת הפעלה – Ubuntu Linux
- מסד נתונים וקטורי – Apache Cassandra
- מודל הטמעה – nomic-embed-text
- שפת תכנות – Python
יתרונות מרכזיים של טכנולוגיה זו
- קוד פתוח
- נתונים מבודדים כדי לעמוד בסטנדרטים של תאימות נתונים
מדריך יישום
אתה יכול ליישם ולעקוב אם התנאים המוקדמים מתקיימים; אחרת, קרא עד הסוף כדי להבין את המונחים.
דרישות מוקדמות
- לינוקס (במקרה שלי, זה Ubuntu 24.04.1 LTS)
- הגדרת Java (OpenJDK 17.0.2)
- Python (3.11.11)
- Ollama
הגדרת מודל Ollama
אולאמה הוא שרת middleware קוד פתוח המשמש כמופעל בין AI המחולל ליישומים על ידי התקנת כל הכלים הנדרשים כדי להפוך מודלי AI מחוללים זמינים לצריכה כ-CLI ו-API במכונה. יש בו רוב המודלים הזמינים בפתוח כמו למה, פיי, מיסטרל, סנופלייק-ארקטיק-אימבד וכו '. זה צולם פלטפורמה וניתן להגדרה בקלות במערכת ההפעלה.
באולאמה, נגרום למודל nomic-embed-text ליצירת אימבדינגים.
הרץ בשורת פקודה:
ollama pull nomic-embed-text
מודל זה יוצר אימבדינגים בגודל של 768 וקטורים.
התקן וסקריפטים של Apache Cassandra
קסנדרה הוא מסד נתונים NoSQL קוד פתוח המיועד לעבודה עם כמות עבודה גבוהה שדורשת התאמה גבוהה כפי צרכי התעשייה. לאחרונה, היא הוסיפה תמיכה בחיפוש וקטור בגרסה 5.0 שתסייע במקרה השימוש שלנו ב-RAG.
הערה: קסנדרה דורשת מערכת ההפעלה Linux כדי לעבוד; ניתן גם להתקין אותה כתמונת דוקר.
התקנה
הורד את Apache Cassandra מ-https://cassandra.apache.org/_/download.html.
הגדר את קסנדרה בנתיב שלך.
הפעל את השרת על ידי הרצת הפקודה הבאה בשורת הפקודה:
cassandra
טבלה
פתח טרמינל חדש של Linux וכתוב cqlsh ; זה יפתח את המסד שדות של שפת שאילתת Cassandra. כעת, בצע את הסקריפטים הבאים ליצירת מרחב המפתחות של embeddings, טבלת document_vectors, ואת האינדקס הנדרש edv_ann_index כדי לבצע חיפוש וקטורי.
CREATE KEYSPACE IF NOT EXISTS embeddings
WITH REPLICATION = { 'class' : 'SimpleStrategy', 'replication_factor' : '1' };
USE embeddings;
CREATE TABLE IF NOT EXISTS embeddings.document_vectors (
record_id timeuuid,
id uuid,
content_chunk text,
content_vector VECTOR <FLOAT, 768>,
created_at timestamp,
PRIMARY KEY (id, created_at)
)
WITH CLUSTERING ORDER BY (created_at DESC);
CREATE INDEX IF NOT EXISTS edv_ann_index
ON embeddings.document_vectors(content_vector) USING 'sai';
הערה: content_vector VECTOR <FLOAT, 768> אחראי על אחסון של וקטורים באורך של 768 שנוצרים על ידי המודל.
שלב 1: אנו מוכנים עם הגדרת מסד נתונים לאחסון וקטורים.
קוד Python
שפת התכנות הזו ללא ספק אינה זקוקה להצגה; זה קל לשימוש ונהנה על ידי התעשייה עם תמיכה קהילתית חזקה.
סביבת עבודה וירטואלית
הגדרת סביבת עבודה וירטואלית:
sudo apt install python3-virtualenv && python3 -m venv myvenv
הפעלת סביבת עבודה וירטואלית:
source /media/setia/Data/Tutorials/cassandra-ollama-app/myvenv/bin/activate
חבילות
הורד חבילת Datastax Cassandra:
pip install cassandra-driver
הורד חבילת requests:
pip install requests
קובץ
צור קובץ בשם app.py.
כעת, כתוב את הקוד להכנסת מסמכים דוגמא ב-Cassandra. זהו השלב הראשון תמיד להכניס נתונים למסד הנתונים; זה יכול להיעשות על ידי תהליך נפרד באופן אסינכרוני. לצורך דוגמה, כתבתי שיטה שתכניס מסמכים ראשונים למסד הנתונים. מאוחר יותר, נוכל להעיר על שיטה זו לאחר שהכנסת המסמכים הצליחה.
from cassandra.cluster import Cluster
from cassandra.query import PreparedStatement, BoundStatement
import uuid
import datetime
import requests
cluster = Cluster(['127.0.0.1'],port=9042)
session = cluster.connect()
def generate_embedding(text):
embedding_url = 'http://localhost:11434/api/embed'
body = {
"model": "nomic-embed-text",
"input": text
}
response = requests.post(embedding_url, json = body)
return response.json()['embeddings'][0]
def insert_chunk(content, vector):
id = uuid.uuid4()
content_chunk = content
content_vector = vector
created_at = datetime.datetime.now()
insert_query = """
INSERT INTO embeddings.document_vectors (record_id, id, content_chunk, content_vector, created_at)
VALUES (now(), ?, ?, ?, ?)
"""
prepared_stmt = session.prepare(insert_query)
session.execute(prepared_stmt, [
id,
content_chunk,
content_vector,
created_at
])
def insert_sample_data_in_cassandra():
sentences = [
"The aroma of freshly baked bread wafted through the quaint bakery nestled in the cobblestone streets of Paris, making Varun feel like time stood still.",
"Sipping a spicy masala chai in a bustling tea stall in Mumbai, Varun felt he was tasting the very soul of the city.",
"The sushi in a small Tokyo diner was so fresh, it felt like Varun was on a culinary journey to the sea itself.",
"Under the starry desert sky in Morocco, Varun enjoyed a lamb tagine that tasted like a dream cooked slowly over a fire.",
"The cozy Italian trattoria served the creamiest risotto, perfectly capturing the heart of Tuscany on a plate, which Varun savored with delight.",
"Enjoying fish tacos on a sunny beach in Mexico, with the waves crashing nearby, made the flavors unforgettable for Varun.",
"The crispy waffles drizzled with syrup at a Belgian café were worth every minute of waiting, as Varun indulged in the decadent treat.",
"A bowl of warm pho in a roadside eatery in Hanoi felt like comfort wrapped in a broth of herbs and spices, giving Varun a sense of warmth.",
"Sampling chocolate truffles in a Swiss chocolate shop, Varun found himself in a moment of pure bliss amidst snow-capped mountains.",
"The street food stalls in Bangkok served fiery pad Thai that left Varun with a tangy memory of the city’s vibrant energy."
]
for sentence in sentences:
vector = generate_embedding(sentence)
insert_chunk(sentence, vector)
insert_sample_data_in_cassandra()
כעת, הפעל את הקובץ הזה באמצעות שורת הפקודה בסביבת העבודה הוירטואלית:
python app.py
ברגע שהקובץ מתבצע והמסמכים מוכנס, ניתן לאמת זאת על ידי שאילתא למסד הנתונים של קסנדרה מתוך הקונסולה cqlsh. לשם כך, פתח את cqlsh והפעל:
SELECT content_chunk FROM embeddings.document_vectors;
זה יחזיר 10 מסמכים שהוכנסו למסד הנתונים, כפי שנראה בצילום המסך למטה.
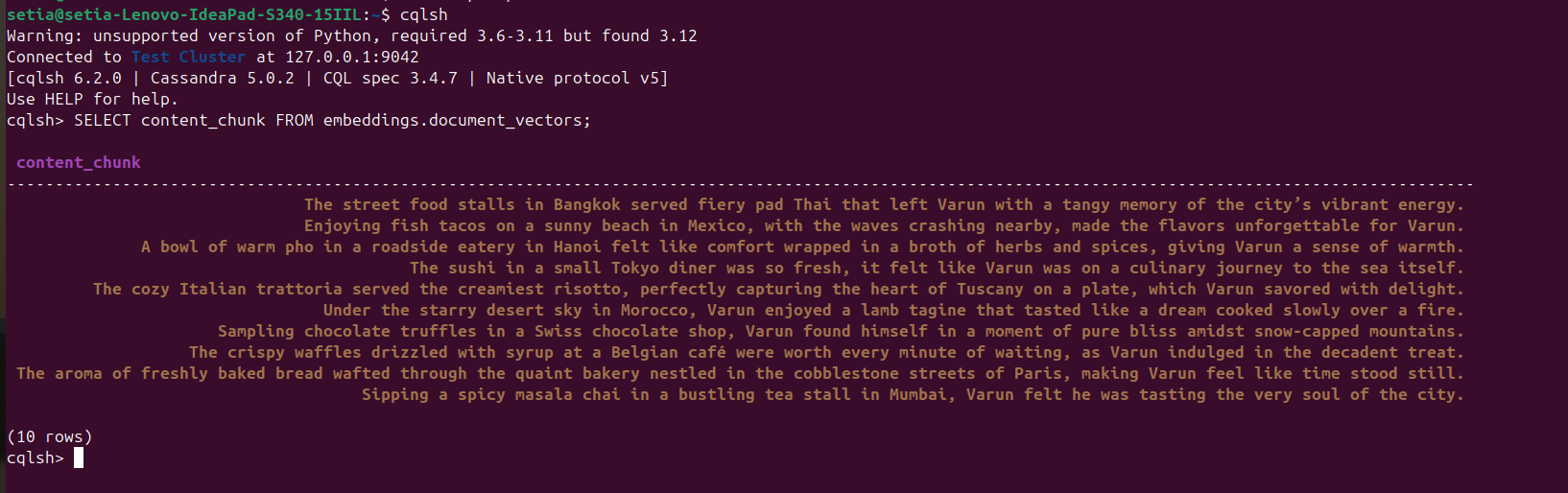
milestones 2: סיימנו עם הגדרת הנתונים במסד הנתונים הווקטורי שלנו.
עכשיו, נכתוב קוד כדי לשאול מסמכים בהתבסס על דמיון קוסיני. דמיון קוסיני הוא מכפלה סקלרית של שני ערכי וקטור. הנוסחה שלו היא A.B / |A||B|. דמיון קוסיני זה נתמך פנימית על ידי אפאצ'י קסנדרה, ועוזר לנו לחשב הכל במסד הנתונים ולנהל נתונים גדולים ביעילות.
הקוד למטה הוא ברור מאליו; הוא שולף את שלוש התוצאות העליונות בהתבסס על דמיון קוסיני באמצעות ORDER BY <שם העמודה> ANN OF <text_vector> ומחזיר גם את ערכי הדמיון הקוסיני. כדי להפעיל קוד זה, עלינו לוודא שהאינדוקסינג חל על עמודת הווקטור הזו.
def query_rag(text):
text_embeddings = generate_embedding(text)
select_query = """
SELECT content_chunk,similarity_cosine(content_vector, ?) FROM embeddings.document_vectors
ORDER BY content_vector ANN OF ?
LIMIT 3
"""
prepared_stmt = session.prepare(select_query)
result_rows = session.execute(prepared_stmt, [
text_embeddings,
text_embeddings
])
for row in result_rows:
print(row[0], row[1])
query_rag('Tell about my Bangkok experiences')
זכור להגיב על קוד ההכנסה:
#insert_sample_data_in_cassandra()
עכשיו, הפעל את הקוד בפייתון באמצעות python app.py.
נקבל את הפלט למטה:
(myvenv) setia@setia-Lenovo-IdeaPad-S340-15IIL:/media/setia/Data/Tutorials/cassandra-ollama-app$ python app.py
The street food stalls in Bangkok served fiery pad Thai that left Varun with a tangy memory of the city’s vibrant energy. 0.8205469250679016
Sipping a spicy masala chai in a bustling tea stall in Mumbai, Varun felt he was tasting the very soul of the city. 0.7719690799713135
A bowl of warm pho in a roadside eatery in Hanoi felt like comfort wrapped in a broth of herbs and spices, giving Varun a sense of warmth. 0.7495554089546204
אתה יכול לראות שהדמיון הקוסיני של "דוכני האוכל ברחוב בבנגקוק הגישו פד תאי לוהט שהשאיר את וארון עם זיכרון חמוץ של האנרגיה התוססת של העיר." הוא 0.8205469250679016, שזה ההתאמה הקרובה ביותר.
milestone סופי: יישמנו את החיפוש RAG.
יישומים ארגוניים
אפאצ'י קסנדרה
לעסקים, אנו יכולים להשתמש ב-Apache Cassandra 5.0 מספקי שירות ענן פופולריים כמו Microsoft Azure, AWS, GCP ועוד.
Ollama
ממותג זה דורש VM התואם עם GPU מופעל על ידי Nvidia להפעלת מודלים ביצועים גבוהים, אך לא נדרשים VM גבוהי סוגת עבור מודלים המשמשים ליצירת וקטורים. תלוי בדרישות התעבורה, ניתן להשתמש במספר VMs או בשירות AI יוצר כלשהו כמו Open AI, Anthropy וכו', תלוי איזה עלות סופית נמוכה יותר לצורך התפשרות או צרכים של שלטון נתונים.
VM של Linux
ניתן לשלב את Apache Cassandra ואת Ollama ולארח אותם ב-VM אחת של Linux אם מקרה השימוש אינו מחייב שימוש גבוה על מנת להוריד את עלות הרכישה הכוללת או לצרכי שלטון נתונים.
סיכום
ניתן בקלות לבנות אפליקציות RAG על ידי שימוש במערכת הפעלה Linux, ב-Apache Cassandra, בהטבעת מודלים (nomic-embed-text) המשמשת דרך Ollama, וב-Python עם ביצועים טובים ללא צורך במינוי ענן נוסף או שירותים בנוחותה של מכונות/שרתים שלנו.
אך, מאוד מומלץ לארח על מכונת וירטואלית בשרת(ים) או לבחור במינוי לענן לצורך התרחבות כיישום עסקי המקיים ארכיטקטורות התרחבותיות. במקרה זה, אפאצ'י, קסנדרה הוא רכיב מרכזי לביצוע העבודה הכבדה של אחסון הווקטורים שלנו והשוואת הווקטורים ושרת אולאמה ליצירת התמסכות של וקטורים.
זהו! תודה על קריאת המאמר עד הסוף.
Source:
https://dzone.com/articles/build-rag-apps-apache-cassandra-python-ollama