













검색 보강 생성(RAG)은 사용자가 입력한 텍스트를 기반으로 데이터 소스에서 실시간 데이터 또는 업데이트된 데이터를 얻기 위한 가장 인기 있는 접근 방식입니다. 이를 통해 모든 검색 애플리케이션을 최신 신경 검색 기술로 강화할 수 있습니다.
RAG 검색 시스템에서 각 사용자 요청은 임베딩 모델에 의해 벡터 표현으로 변환되며, 이 벡터 비교는 코사인 유사도, 최장 공통 부분 수열 등과 같은 다양한 알고리즘을 사용하여 우리 벡터 지원 데이터베이스에 저장된 기존 벡터 표현과 수행됩니다.
벡터 데이터베이스에 저장된 기존 벡터는 별도의 백그라운드 프로세스에 의해 비동기적으로 생성되거나 업데이트됩니다.
 이 다이어그램은 벡터 비교에 대한 개념적 개요를 제공합니다.
이 다이어그램은 벡터 비교에 대한 개념적 개요를 제공합니다.
RAG를 사용하려면 애플리케이션에서 사용할 임베딩 모델과 벡터 저장 데이터베이스가 최소한 필요합니다. 커뮤니티와 오픈 소스 프로젝트의 기여는 효과적이고 효율적인 RAG 애플리케이션을 구축하는 데 도움이 되는 놀라운 도구 세트를 제공합니다.
이 기사에서는 Python 애플리케이션에서 벡터 데이터베이스 및 임베딩 생성 모델을 구현할 것입니다. 이 개념을 처음 읽거나 여러 차례 읽었다면 도구만 있으면 되며 도구에 대한 구독은 필요하지 않습니다. 도구를 다운로드하여 시작할 수 있습니다.
저희 기술 스택은 다음 오픈 소스 및 무료 도구들로 구성되어 있습니다:
- 운영 체제 – Ubuntu Linux
- 벡터 데이터베이스 – Apache Cassandra
- 임베딩 모델 – nomic-embed-text
- 프로그래밍 언어 – Python
이 스택의 주요 이점
- 오픈 소스
- 데이터 컴플라이언스 표준을 충족시키기 위한 분리된 데이터
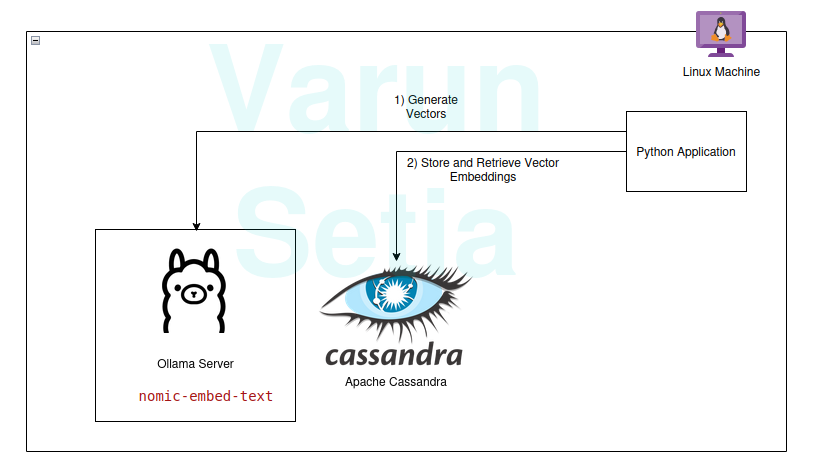
구현 안내
전제 조건이 충족되었다면 구현 및 따라 해볼 수 있으며, 그렇지 않으면 개념을 이해하기 위해 끝까지 읽으십시오.
전제 조건
- 리눅스 (제 경우, Ubuntu 24.04.1 LTS)
- Java 설정 (OpenJDK 17.0.2)
- Python (3.11.11)
- Ollama
Ollama 모델 설정
Ollama는 generative AI와 응용 프로그램 사이의 추상화 역할을 하는 오픈 소스 미들웨어 서버로, generative AI 모델을 CLI 및 API로 소비할 수 있도록 필요한 모든 도구를 설치합니다. llama, phi, mistral, snowflake-arctic-embed 등과 같은 대부분의 오픈리 사용 가능한 모델을 보유하고 있습니다. 이는 크로스 플랫폼이며 OS에서 쉽게 구성할 수 있습니다.
Ollama에서는 nomic-embed-text 모델을 추출하여 임베딩을 생성합니다.
명령 줄에서 실행:
ollama pull nomic-embed-text
이 모델은 768 벡터 크기의 임베딩을 생성합니다.
Apache Cassandra 설정 및 스크립트
Cassandra는 산업 요구에 따라 높은 스케일링이 필요한 많은 워크로드와 함께 작동하도록 설계된 오픈 소스 NoSQL 데이터베이스입니다. 최근에 버전 5.0에서 Vector 검색 지원을 추가하여 RAG 사용 사례를 용이하게 할 것입니다.
참고: Cassandra는 Linux OS에서 작동이 필요하며 도커 이미지로도 설치할 수 있습니다.
설치
다음에서 Apache Cassandra 다운로드: https://cassandra.apache.org/_/download.html.
Cassandra를 PATH에 구성합니다.
다음 명령을 실행하여 서버를 시작합니다:
cassandra
Table
새로운 Linux 터미널을 열고 cqlsh를 입력하십시오. 이렇게 하면 Cassandra Query Language의 셸이 열립니다. 이제 아래 스크립트를 실행하여 embeddings 킷스페이스, document_vectors 테이블 및 벡터 검색을 수행하기 위한 필요한 색인 edv_ann_index을 생성하십시오.
CREATE KEYSPACE IF NOT EXISTS embeddings
WITH REPLICATION = { 'class' : 'SimpleStrategy', 'replication_factor' : '1' };
USE embeddings;
CREATE TABLE IF NOT EXISTS embeddings.document_vectors (
record_id timeuuid,
id uuid,
content_chunk text,
content_vector VECTOR <FLOAT, 768>,
created_at timestamp,
PRIMARY KEY (id, created_at)
)
WITH CLUSTERING ORDER BY (created_at DESC);
CREATE INDEX IF NOT EXISTS edv_ann_index
ON embeddings.document_vectors(content_vector) USING 'sai';
참고: content_vector VECTOR <FLOAT, 768>은 모델에 의해 생성된 768 길이의 벡터를 저장하는 역할을 합니다.
단계 1: 벡터를 저장할 데이터베이스 설정이 준비되었습니다.
Python 코드
이 프로그래밍 언어는 확실히 소개가 필요하지 않습니다. 사용하기 쉽고 강력한 커뮤니티 지원으로 산업에서 사랑받는 언어입니다.
가상 환경
가상 환경 설정:
sudo apt install python3-virtualenv && python3 -m venv myvenv
가상 환경 활성화:
source /media/setia/Data/Tutorials/cassandra-ollama-app/myvenv/bin/activate
패키지
Datastax Cassandra 패키지 다운로드:
pip install cassandra-driver
requests 패키지 다운로드:
pip install requests
파일
app.py라는 파일을 생성하십시오.
이제 아래 코드를 사용하여 Cassandra에 샘플 문서를 삽입하십시오. 데이터베이스에 데이터를 삽입하는 첫 번째 단계이며 별도의 프로세스로 비동기적으로 수행할 수 있습니다. 데모 목적으로, 데이터베이스에 먼저 문서를 삽입하는 메서드를 작성했습니다. 나중에 문서 삽입이 성공하면 이 메서드에 주석을 다는 등의 처리를 할 수 있습니다.
from cassandra.cluster import Cluster
from cassandra.query import PreparedStatement, BoundStatement
import uuid
import datetime
import requests
cluster = Cluster(['127.0.0.1'],port=9042)
session = cluster.connect()
def generate_embedding(text):
embedding_url = 'http://localhost:11434/api/embed'
body = {
"model": "nomic-embed-text",
"input": text
}
response = requests.post(embedding_url, json = body)
return response.json()['embeddings'][0]
def insert_chunk(content, vector):
id = uuid.uuid4()
content_chunk = content
content_vector = vector
created_at = datetime.datetime.now()
insert_query = """
INSERT INTO embeddings.document_vectors (record_id, id, content_chunk, content_vector, created_at)
VALUES (now(), ?, ?, ?, ?)
"""
prepared_stmt = session.prepare(insert_query)
session.execute(prepared_stmt, [
id,
content_chunk,
content_vector,
created_at
])
def insert_sample_data_in_cassandra():
sentences = [
"The aroma of freshly baked bread wafted through the quaint bakery nestled in the cobblestone streets of Paris, making Varun feel like time stood still.",
"Sipping a spicy masala chai in a bustling tea stall in Mumbai, Varun felt he was tasting the very soul of the city.",
"The sushi in a small Tokyo diner was so fresh, it felt like Varun was on a culinary journey to the sea itself.",
"Under the starry desert sky in Morocco, Varun enjoyed a lamb tagine that tasted like a dream cooked slowly over a fire.",
"The cozy Italian trattoria served the creamiest risotto, perfectly capturing the heart of Tuscany on a plate, which Varun savored with delight.",
"Enjoying fish tacos on a sunny beach in Mexico, with the waves crashing nearby, made the flavors unforgettable for Varun.",
"The crispy waffles drizzled with syrup at a Belgian café were worth every minute of waiting, as Varun indulged in the decadent treat.",
"A bowl of warm pho in a roadside eatery in Hanoi felt like comfort wrapped in a broth of herbs and spices, giving Varun a sense of warmth.",
"Sampling chocolate truffles in a Swiss chocolate shop, Varun found himself in a moment of pure bliss amidst snow-capped mountains.",
"The street food stalls in Bangkok served fiery pad Thai that left Varun with a tangy memory of the city’s vibrant energy."
]
for sentence in sentences:
vector = generate_embedding(sentence)
insert_chunk(sentence, vector)
insert_sample_data_in_cassandra()
이제 가상 환경에서 명령줄을 사용하여 이 파일을 실행하십시오.
python app.py
파일이 실행되고 문서가 삽입되면, cqlsh 콘솔에서 Cassandra 데이터베이스를 쿼리하여 이를 확인할 수 있습니다. 이를 위해 cqlsh를 열고 실행하십시오:
SELECT content_chunk FROM embeddings.document_vectors;
이렇게 하면 아래 스크린샷에서 볼 수 있듯이 데이터베이스에 삽입된 10개의 문서가 반환됩니다.
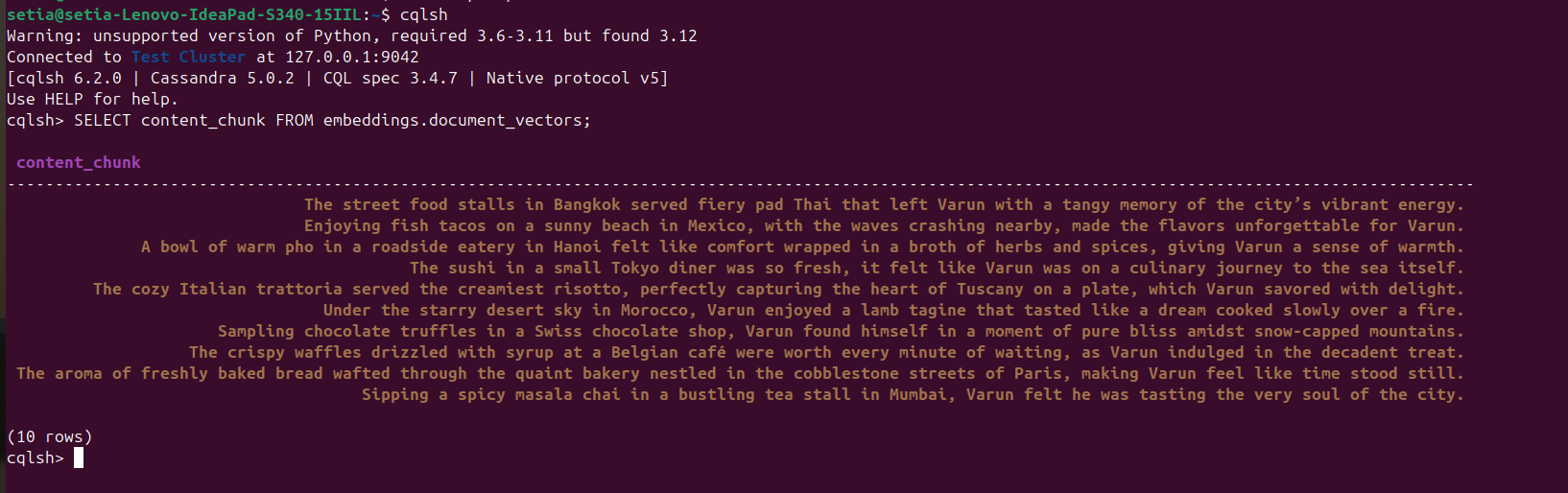
마일스톤 2: 벡터 데이터베이스에서 데이터 설정이 완료되었습니다.
이제 코사인 유사성을 기반으로 문서를 쿼리하는 코드를 작성할 것입니다. 코사인 유사성은 두 벡터 값의 내적입니다. 그 공식은 A.B / |A||B|입니다. 이 코사인 유사성은 Apache Cassandra에 의해 내부적으로 지원되어, 데이터베이스 내의 모든 것을 계산하고 대용량 데이터를 효율적으로 처리하는 데 도움을 줍니다.
아래 코드는 자가 설명적이며, ORDER BY <column name> ANN OF <text_vector>를 사용하여 코사인 유사성을 기준으로 상위 세 개의 결과를 가져오고 코사인 유사성 값도 반환합니다. 이 코드를 실행하려면 이 벡터 열에 인덱싱이 적용되어야 합니다.
def query_rag(text):
text_embeddings = generate_embedding(text)
select_query = """
SELECT content_chunk,similarity_cosine(content_vector, ?) FROM embeddings.document_vectors
ORDER BY content_vector ANN OF ?
LIMIT 3
"""
prepared_stmt = session.prepare(select_query)
result_rows = session.execute(prepared_stmt, [
text_embeddings,
text_embeddings
])
for row in result_rows:
print(row[0], row[1])
query_rag('Tell about my Bangkok experiences')
삽입 코드는 주석 처리하는 것을 잊지 마십시오:
#insert_sample_data_in_cassandra()
이제 python app.py를 사용하여 Python 코드를 실행하십시오.
우리는 아래와 같은 출력을 얻게 될 것입니다:
(myvenv) setia@setia-Lenovo-IdeaPad-S340-15IIL:/media/setia/Data/Tutorials/cassandra-ollama-app$ python app.py
The street food stalls in Bangkok served fiery pad Thai that left Varun with a tangy memory of the city’s vibrant energy. 0.8205469250679016
Sipping a spicy masala chai in a bustling tea stall in Mumbai, Varun felt he was tasting the very soul of the city. 0.7719690799713135
A bowl of warm pho in a roadside eatery in Hanoi felt like comfort wrapped in a broth of herbs and spices, giving Varun a sense of warmth. 0.7495554089546204
“방콕의 길거리 음식 노점에서 제공된 매운 팟타이는 바룬에게 도시의 활기찬 에너지에 대한 톡 쏘는 기억을 남겼습니다.”의 코사인 유사성은 0.8205469250679016으로, 가장 가까운 일치 항목입니다.
최종 마일스톤: RAG 검색을 구현하였습니다.
기업 응용 프로그램
Apache Cassandra
기업을 위해, 우리는 다음과 같은 인기 있는 클라우드 공급업체에서 Apache Cassandra 5.0을 사용할 수 있습니다: Microsoft Azure, AWS, GCP 등.
Ollama
이 미들웨어는 고성능 모델을 실행하기 위해 Nvidia GPU와 호환되는 VM이 필요하지만, 벡터 생성을 위한 모델에는 고급 VM이 필요하지 않습니다. 트래픽 요구 사항에 따라 여러 개의 VM을 사용할 수 있으며, Open AI, Anthropy 등과 같은 생성 AI 서비스 중에서 Total Cost of Ownership가 더 낮은 것을 선택하여 확장 요구 사항이나 데이터 거버넌스 요구 사항을 충족할 수 있습니다.
리눅스 VM
Apache Cassandra와 Ollama는 사용 사례가 높은 사용을 요구하지 않는 경우, Total Cost of Ownership를 낮추거나 데이터 거버넌스 요구 사항을 해결하기 위해 단일 리눅스 VM에 결합하여 호스팅할 수 있습니다.
결론
리눅스 OS, Apache Cassandra, Ollama를 통해 사용되는 임베딩 모델(nomic-embed-text) 및 Python을 사용하여 추가 클라우드 구독이나 서비스 없이도 기계/서버의 편안함 속에서 좋은 성능으로 RAG 애플리케이션을 쉽게 구축할 수 있습니다.
그러나 VM을 서버에 호스팅하거나 클라우드 구독을 선택하여 확장 가능한 아키텍처에 적합한 엔터프라이즈 애플리케이션으로 확장하는 것이 권장됩니다. 이 Apache에서 Cassandra는 우리의 벡터 저장소와 벡터 비교의 주요 구성 요소이며, Ollama 서버는 벡터 임베딩을 생성하는 데 사용됩니다.
그게 전부입니다! 끝까지 읽어주셔서 감사합니다.
Source:
https://dzone.com/articles/build-rag-apps-apache-cassandra-python-ollama