













La generazione aumentata da recupero (RAG) è l’approccio più popolare per ottenere dati in tempo reale o dati aggiornati da una sorgente basata su input testuali degli utenti. Così da potenziare tutte le nostre applicazioni di ricerca con una ricerca neurale all’avanguardia.
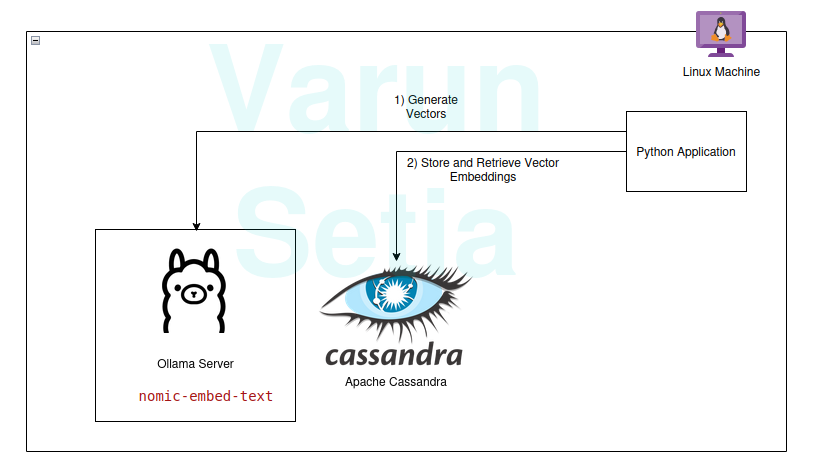
Nei sistemi di ricerca RAG, ogni richiesta dell’utente viene convertita in una rappresentazione vettoriale da un modello di embedding, e questo confronto vettoriale viene eseguito utilizzando vari algoritmi come la similarità coseno, la sottosequenza comune più lunga, ecc., con rappresentazioni vettoriali esistenti memorizzate nel nostro database di supporto vettoriale.
I vettori esistenti memorizzati nel database vettoriale sono anche generati o aggiornati in modo asincrono da un processo di background separato.
 Questo diagramma fornisce una panoramica concettuale del confronto vettoriale
Questo diagramma fornisce una panoramica concettuale del confronto vettoriale
Per utilizzare RAG, abbiamo bisogno almeno di un modello di embedding e di un database di archiviazione vettoriale da utilizzare dall’applicazione. I contributi della comunità e dei progetti open-source ci forniscono un set straordinario di strumenti che ci aiutano a costruire applicazioni RAG efficaci ed efficienti.
In questo articolo, implementeremo l’uso di un database vettoriale e di un modello di generazione di embedding in un’applicazione Python. Se stai leggendo questo concetto per la prima volta o per la nth volta, hai solo bisogno di strumenti per lavorare e non è necessaria alcuna iscrizione per nessuno strumento. Puoi semplicemente scaricare gli strumenti e iniziare.
Il nostro stack tecnologico è composto dai seguenti strumenti open-source e gratuiti:
- Sistema operativo – Ubuntu Linux
- Database vettoriale – Apache Cassandra
- Modello di embedding – nomic-embed-text
- Lingua di programmazione – Python
Vantaggi chiave di questo stack
- Open-source
- Dati isolati per soddisfare gli standard di conformità dei dati
Guida all’implementazione
Puoi implementare e seguire se i prerequisiti sono soddisfatti; in caso contrario, leggi fino alla fine per comprendere i concetti.
Prerequisiti
- Linux (Nel mio caso, è Ubuntu 24.04.1 LTS)
- Impostazione di Java (OpenJDK 17.0.2)
- Python (3.11.11)
- Ollama
Impostazione del modello Ollama
Ollama è un server middleware open-source che funge da astrazione tra IA generativa e applicazioni installando tutti gli strumenti necessari per rendere i modelli di IA generativa disponibili per l’uso come CLI e API in una macchina. Ha la maggior parte dei modelli disponibili pubblicamente come llama, phi, mistral, snowflake-arctic-embed, ecc. È multipiattaforma e può essere facilmente configurato su OS.
In Ollama, estrarremo il nomic-embed-text modello per generare embeddings.
Esegui nel terminale:
ollama pull nomic-embed-text
Questo modello genera embeddings di dimensione 768 vettori.
Configurazione e Script di Apache Cassandra
Cassandra è un database NoSQL open-source progettato per lavorare con un elevato carico di lavoro che richiede un’alta scalabilità secondo le esigenze del settore. Recentemente, ha aggiunto il supporto per la ricerca vettoriale nella versione 5.0 che faciliterà il nostro caso d’uso RAG.
Nota: Cassandra richiede Linux OS per funzionare; può anche essere installato come immagine docker.
Installazione
Scarica Apache Cassandra da https://cassandra.apache.org/_/download.html.
Configura Cassandra nel tuo PATH.
Avvia il server eseguendo il seguente comando nel terminale:
cassandra
Tabella
Apri un nuovo terminale Linux e scrivi cqlsh; questo aprirà la shell per il Cassandra Query Language. Ora, esegui gli script sottostanti per creare lo embeddings keyspace, la tabella document_vectors e l’indice necessario edv_ann_index per eseguire una ricerca vettoriale.
CREATE KEYSPACE IF NOT EXISTS embeddings
WITH REPLICATION = { 'class' : 'SimpleStrategy', 'replication_factor' : '1' };
USE embeddings;
CREATE TABLE IF NOT EXISTS embeddings.document_vectors (
record_id timeuuid,
id uuid,
content_chunk text,
content_vector VECTOR <FLOAT, 768>,
created_at timestamp,
PRIMARY KEY (id, created_at)
)
WITH CLUSTERING ORDER BY (created_at DESC);
CREATE INDEX IF NOT EXISTS edv_ann_index
ON embeddings.document_vectors(content_vector) USING 'sai';
Nota: content_vector VECTOR <FLOAT, 768> è responsabile per l’archiviazione di vettori di lunghezza 768 generati dal modello.
Traguardo 1: Siamo pronti con la configurazione del database per memorizzare i vettori.
Codice Python
Questo linguaggio di programmazione non ha certamente bisogno di presentazioni; è facile da usare ed è amato dall’industria con un forte supporto della comunità.
Ambiente Virtuale
Imposta l’ambiente virtuale:
sudo apt install python3-virtualenv && python3 -m venv myvenv
Attiva l’ambiente virtuale:
source /media/setia/Data/Tutorials/cassandra-ollama-app/myvenv/bin/activate
Pacchetti
Scarica il pacchetto Datastax Cassandra:
pip install cassandra-driver
Scarica il pacchetto requests:
pip install requests
File
Crea un file chiamato app.py.
Ora, scrivi il codice sottostante per inserire documenti di esempio in Cassandra. Questo è sempre il primo passo per inserire dati nel database; può essere fatto tramite un processo separato in modo asincrono. Per scopi dimostrativi, ho scritto un metodo che inserirà prima i documenti nel database. In seguito, possiamo commentare questo metodo una volta che l’inserimento dei documenti avrà avuto successo.
from cassandra.cluster import Cluster
from cassandra.query import PreparedStatement, BoundStatement
import uuid
import datetime
import requests
cluster = Cluster(['127.0.0.1'],port=9042)
session = cluster.connect()
def generate_embedding(text):
embedding_url = 'http://localhost:11434/api/embed'
body = {
"model": "nomic-embed-text",
"input": text
}
response = requests.post(embedding_url, json = body)
return response.json()['embeddings'][0]
def insert_chunk(content, vector):
id = uuid.uuid4()
content_chunk = content
content_vector = vector
created_at = datetime.datetime.now()
insert_query = """
INSERT INTO embeddings.document_vectors (record_id, id, content_chunk, content_vector, created_at)
VALUES (now(), ?, ?, ?, ?)
"""
prepared_stmt = session.prepare(insert_query)
session.execute(prepared_stmt, [
id,
content_chunk,
content_vector,
created_at
])
def insert_sample_data_in_cassandra():
sentences = [
"The aroma of freshly baked bread wafted through the quaint bakery nestled in the cobblestone streets of Paris, making Varun feel like time stood still.",
"Sipping a spicy masala chai in a bustling tea stall in Mumbai, Varun felt he was tasting the very soul of the city.",
"The sushi in a small Tokyo diner was so fresh, it felt like Varun was on a culinary journey to the sea itself.",
"Under the starry desert sky in Morocco, Varun enjoyed a lamb tagine that tasted like a dream cooked slowly over a fire.",
"The cozy Italian trattoria served the creamiest risotto, perfectly capturing the heart of Tuscany on a plate, which Varun savored with delight.",
"Enjoying fish tacos on a sunny beach in Mexico, with the waves crashing nearby, made the flavors unforgettable for Varun.",
"The crispy waffles drizzled with syrup at a Belgian café were worth every minute of waiting, as Varun indulged in the decadent treat.",
"A bowl of warm pho in a roadside eatery in Hanoi felt like comfort wrapped in a broth of herbs and spices, giving Varun a sense of warmth.",
"Sampling chocolate truffles in a Swiss chocolate shop, Varun found himself in a moment of pure bliss amidst snow-capped mountains.",
"The street food stalls in Bangkok served fiery pad Thai that left Varun with a tangy memory of the city’s vibrant energy."
]
for sentence in sentences:
vector = generate_embedding(sentence)
insert_chunk(sentence, vector)
insert_sample_data_in_cassandra()
Ora, esegui questo file utilizzando la riga di comando nell’ambiente virtuale:
python app.py
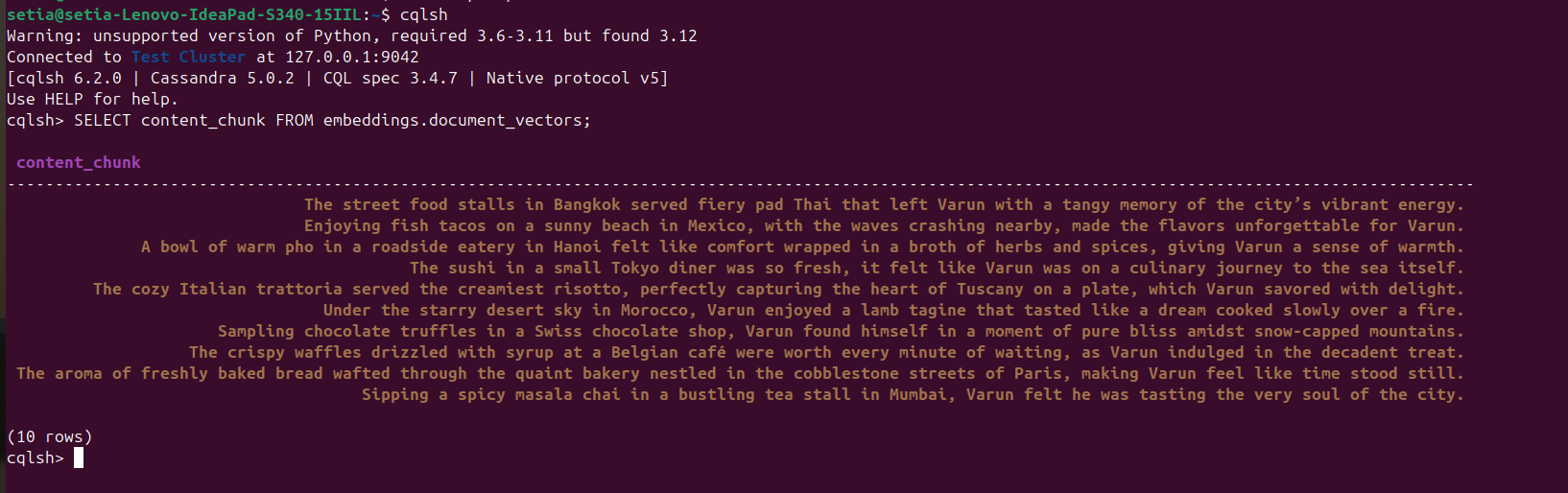
Una volta eseguito il file e inseriti i documenti, questo può essere verificato interrogando il database Cassandra dalla console cqlsh. Per questo, apri cqlsh e esegui:
SELECT content_chunk FROM embeddings.document_vectors;
Questo restituirà 10 documenti inseriti nel database, come mostrato nello screenshot qui sotto.
Traguardo 2: Abbiamo completato la configurazione dei dati nel nostro database vettoriale.
Ora scriveremo il codice per interrogare i documenti basandoci sulla similarità del coseno. La similarità del coseno è il prodotto scalare di due valori vettoriali. La sua formula è A.B / |A||B|. Questa similarità del coseno è supportata internamente da Apache Cassandra, aiutandoci a calcolare tutto nel database e gestire grandi quantità di dati in modo efficiente.
Il codice sottostante è autoesplicativo; recupera i primi tre risultati basati sulla similarità del coseno utilizzando ORDER BY <nome colonna> ANN OF <text_vector> e restituisce anche i valori di similarità del coseno. Per eseguire questo codice, dobbiamo assicurarci che l’indicizzazione sia applicata a questa colonna vettoriale.
def query_rag(text):
text_embeddings = generate_embedding(text)
select_query = """
SELECT content_chunk,similarity_cosine(content_vector, ?) FROM embeddings.document_vectors
ORDER BY content_vector ANN OF ?
LIMIT 3
"""
prepared_stmt = session.prepare(select_query)
result_rows = session.execute(prepared_stmt, [
text_embeddings,
text_embeddings
])
for row in result_rows:
print(row[0], row[1])
query_rag('Tell about my Bangkok experiences')
Ricorda di commentare il codice di inserimento:
#insert_sample_data_in_cassandra()
Ora, esegui il codice Python utilizzando python app.py.
Otterremo l’output qui sotto:
(myvenv) setia@setia-Lenovo-IdeaPad-S340-15IIL:/media/setia/Data/Tutorials/cassandra-ollama-app$ python app.py
The street food stalls in Bangkok served fiery pad Thai that left Varun with a tangy memory of the city’s vibrant energy. 0.8205469250679016
Sipping a spicy masala chai in a bustling tea stall in Mumbai, Varun felt he was tasting the very soul of the city. 0.7719690799713135
A bowl of warm pho in a roadside eatery in Hanoi felt like comfort wrapped in a broth of herbs and spices, giving Varun a sense of warmth. 0.7495554089546204
Puoi vedere che la similarità del coseno di “I chioschi di cibo di strada a Bangkok servivano un pad Thai piccante che ha lasciato Varun con un ricordo agrodolce dell’energia vibrante della città.” è 0.8205469250679016, che è la corrispondenza più vicina.
Traguardo finale: Abbiamo implementato la ricerca RAG.
Applicazioni aziendali
Apache Cassandra
Per le imprese, possiamo utilizzare Apache Cassandra 5.0 dai fornitori cloud popolari come Microsoft Azure, AWS, GCP, ecc.
Ollama
Questo middleware richiede una VM compatibile con GPU Nvidia per eseguire modelli ad alte prestazioni, ma non abbiamo bisogno di VM di fascia alta per modelli utilizzati per generare vettori. A seconda dei requisiti di traffico, possono essere utilizzate più VM o qualsiasi servizio AI generativo come Open AI, Anthropy, ecc., a seconda di quale sia il Costo Totale di Proprietà più basso per le esigenze di scalabilità o le esigenze di Governance dei Dati.
VM Linux
Apache Cassandra e Ollama possono essere combinati e ospitati in una singola VM Linux se il caso d’uso non richiede un utilizzo elevato per ridurre il Costo Totale di Proprietà o per affrontare le esigenze di Governance dei Dati.
Conclusion
Possiamo facilmente costruire applicazioni RAG utilizzando il sistema operativo Linux, Apache Cassandra, modelli di embedding (nomic-embed-text) utilizzati tramite Ollama e Python con buone prestazioni senza bisogno di abbonamenti cloud aggiuntivi o servizi nel comfort delle nostre macchine/server.
Tuttavia, è consigliabile ospitare una VM in server o optare per un abbonamento cloud per la scalabilità come applicazione aziendale conforme alle architetture scalabili. In questo Apache, Cassandra è un componente chiave per gestire il carico di lavoro del nostro archivio vettoriale e del confronto vettoriale e il server Ollama per generare incorporamenti vettoriali.
Ecco tutto! Grazie per aver letto fino alla fine.
Source:
https://dzone.com/articles/build-rag-apps-apache-cassandra-python-ollama