













リトリーバル拡張生成(RAG)は、ユーザーによって入力されたテキストに基づいてデータソースからリアルタイムデータまたは更新データを取得するための最も一般的なアプローチです。これにより、最先端のニューラル検索を活用したすべての検索アプリケーションが強化されます。
RAG検索システムでは、各ユーザーリクエストが埋め込みモデルによってベクトル表現に変換され、このベクトルの比較はコサイン類似度、最長共通部分列などのさまざまなアルゴリズムを使用して、当社のベクトルサポートデータベースに保存されている既存のベクトル表現と行われます。
ベクトルデータベースに保存されている既存のベクトルは、別のバックグラウンドプロセスによって非同期的に生成または更新されます。
 この図はベクトル比較の概念的な概要を提供します
この図はベクトル比較の概念的な概要を提供します
RAGを使用するには、少なくとも埋め込みモデルとアプリケーションによって使用されるベクトルストレージデータベースが必要です。コミュニティやオープンソースプロジェクトからの貢献により、効果的かつ効率的なRAGアプリケーションを構築するための素晴らしいツールセットが提供されています。
この記事では、Pythonアプリケーションにおけるベクターデータベースと埋め込み生成モデルの使用を実装します。このコンセプトを初めて読む方や何度目かの方も、作業に必要なツールだけがあれば十分で、どのツールにもサブスクリプションは必要ありません。単にツールをダウンロードして始めることができます。
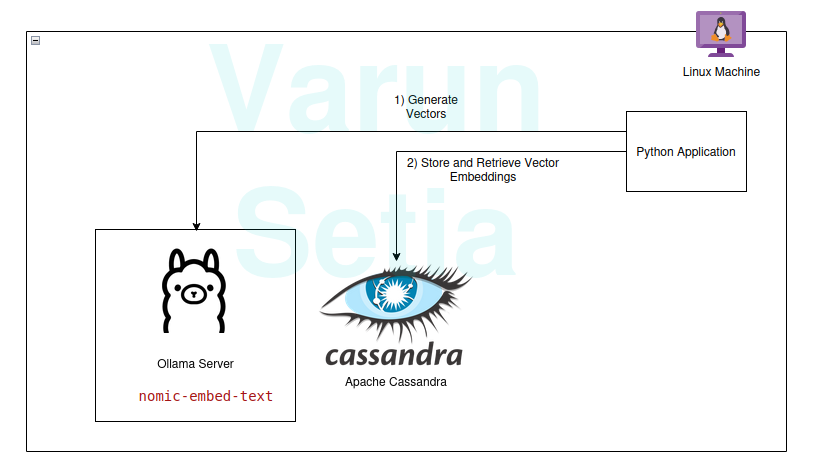
私たちの技術スタックは、以下のオープンソースで無料のツールで構成されています:
- オペレーティングシステム – Ubuntu Linux
- ベクターデータベース – Apache Cassandra
- 埋め込みモデル – nomic-embed-text
- プログラミング言語 – Python
このスタックの主な利点
- オープンソース
- データコンプライアンス基準を満たすための隔離されたデータ
実装の手順
前提条件が満たされていれば、実装しながら進めることができます。それ以外の場合は、概念を理解するために最後まで読んでください。
前提条件
- Linux(私の場合は、Ubuntu 24.04.1 LTS)
- Javaのセットアップ(OpenJDK 17.0.2)
- Python(3.11.11)
- Ollama
Ollamaモデルのセットアップ
Ollamaは、ジェネレーティブAIとアプリケーションの間の抽象化を行うオープンソースのミドルウェアサーバであり、ジェネレーティブAIモデルをCLIおよびAPIとして利用可能にするために必要なすべてのツールをインストールします。Ollamaには、llama、phi、mistral、snowflake-arctic-embedなど、ほとんどのオープンソースモデルが含まれています。クロスプラットフォームであり、OSで簡単に構成できます。
Ollamaでは、nomic-embed-text モデルを取得して埋め込みを生成します。
コマンドラインで実行:
ollama pull nomic-embed-text
このモデルはサイズ768のベクトルの埋め込みを生成します。
Apache Cassandraのセットアップとスクリプト
Cassandraは、業界のニーズに応じて高いスケーリングが必要なワークロード量と連携するように設計されたオープンソースのNoSQLデータベースです。最近、バージョン5.0でベクター検索のサポートが追加され、RAGユースケースを容易にします。
注意: CassandraはLinux OSで動作する必要があり、Dockerイメージとしてもインストールできます。
インストール
以下のリンクからApache Cassandraをダウンロードしてください:https://cassandra.apache.org/_/download.html。
CassandraをPATHに設定してください。
次のコマンドをコマンドラインで実行してサーバーを起動します:
cassandra
Table
新しいLinuxターミナルを開き、cqlshと入力します。これにより、Cassandra Query Languageのシェルが開きます。次に、以下のスクリプトを実行してembeddingsキー空間、document_vectorsテーブル、およびベクトル検索を実行するために必要なインデックスedv_ann_indexを作成してください。
CREATE KEYSPACE IF NOT EXISTS embeddings
WITH REPLICATION = { 'class' : 'SimpleStrategy', 'replication_factor' : '1' };
USE embeddings;
CREATE TABLE IF NOT EXISTS embeddings.document_vectors (
record_id timeuuid,
id uuid,
content_chunk text,
content_vector VECTOR <FLOAT, 768>,
created_at timestamp,
PRIMARY KEY (id, created_at)
)
WITH CLUSTERING ORDER BY (created_at DESC);
CREATE INDEX IF NOT EXISTS edv_ann_index
ON embeddings.document_vectors(content_vector) USING 'sai';
注意: content_vector VECTOR <FLOAT, 768>は、モデルによって生成される768の長さのベクトルを格納する役割を担っています。
マイルストーン1: ベクトルを格納するためのデータベースセットアップが完了しました。
Pythonコード
このプログラミング言語は確かに紹介の必要はありません; 使いやすく、業界に愛され、強力なコミュニティサポートがあります。
仮想環境
仮想環境をセットアップします:
sudo apt install python3-virtualenv && python3 -m venv myvenv
仮想環境をアクティブにします:
source /media/setia/Data/Tutorials/cassandra-ollama-app/myvenv/bin/activate
パッケージ
Datastax Cassandraパッケージをダウンロードします:
pip install cassandra-driver
requestsパッケージをダウンロードします:
pip install requests
ファイル
app.pyという名前のファイルを作成します。
次に、Cassandraにサンプルドキュメントを挿入するためのコードを以下に記述します。データベースにデータを挿入するための最初のステップです; これは別のプロセスで非同期に行うことができます。デモの目的のために、最初にデータベースにドキュメントを挿入するメソッドを書きました。後で、ドキュメントの挿入が成功したら、このメソッドをコメントアウトすることができます。
from cassandra.cluster import Cluster
from cassandra.query import PreparedStatement, BoundStatement
import uuid
import datetime
import requests
cluster = Cluster(['127.0.0.1'],port=9042)
session = cluster.connect()
def generate_embedding(text):
embedding_url = 'http://localhost:11434/api/embed'
body = {
"model": "nomic-embed-text",
"input": text
}
response = requests.post(embedding_url, json = body)
return response.json()['embeddings'][0]
def insert_chunk(content, vector):
id = uuid.uuid4()
content_chunk = content
content_vector = vector
created_at = datetime.datetime.now()
insert_query = """
INSERT INTO embeddings.document_vectors (record_id, id, content_chunk, content_vector, created_at)
VALUES (now(), ?, ?, ?, ?)
"""
prepared_stmt = session.prepare(insert_query)
session.execute(prepared_stmt, [
id,
content_chunk,
content_vector,
created_at
])
def insert_sample_data_in_cassandra():
sentences = [
"The aroma of freshly baked bread wafted through the quaint bakery nestled in the cobblestone streets of Paris, making Varun feel like time stood still.",
"Sipping a spicy masala chai in a bustling tea stall in Mumbai, Varun felt he was tasting the very soul of the city.",
"The sushi in a small Tokyo diner was so fresh, it felt like Varun was on a culinary journey to the sea itself.",
"Under the starry desert sky in Morocco, Varun enjoyed a lamb tagine that tasted like a dream cooked slowly over a fire.",
"The cozy Italian trattoria served the creamiest risotto, perfectly capturing the heart of Tuscany on a plate, which Varun savored with delight.",
"Enjoying fish tacos on a sunny beach in Mexico, with the waves crashing nearby, made the flavors unforgettable for Varun.",
"The crispy waffles drizzled with syrup at a Belgian café were worth every minute of waiting, as Varun indulged in the decadent treat.",
"A bowl of warm pho in a roadside eatery in Hanoi felt like comfort wrapped in a broth of herbs and spices, giving Varun a sense of warmth.",
"Sampling chocolate truffles in a Swiss chocolate shop, Varun found himself in a moment of pure bliss amidst snow-capped mountains.",
"The street food stalls in Bangkok served fiery pad Thai that left Varun with a tangy memory of the city’s vibrant energy."
]
for sentence in sentences:
vector = generate_embedding(sentence)
insert_chunk(sentence, vector)
insert_sample_data_in_cassandra()
次に、仮想環境内のコマンドラインを使用してこのファイルを実行します:
python app.py
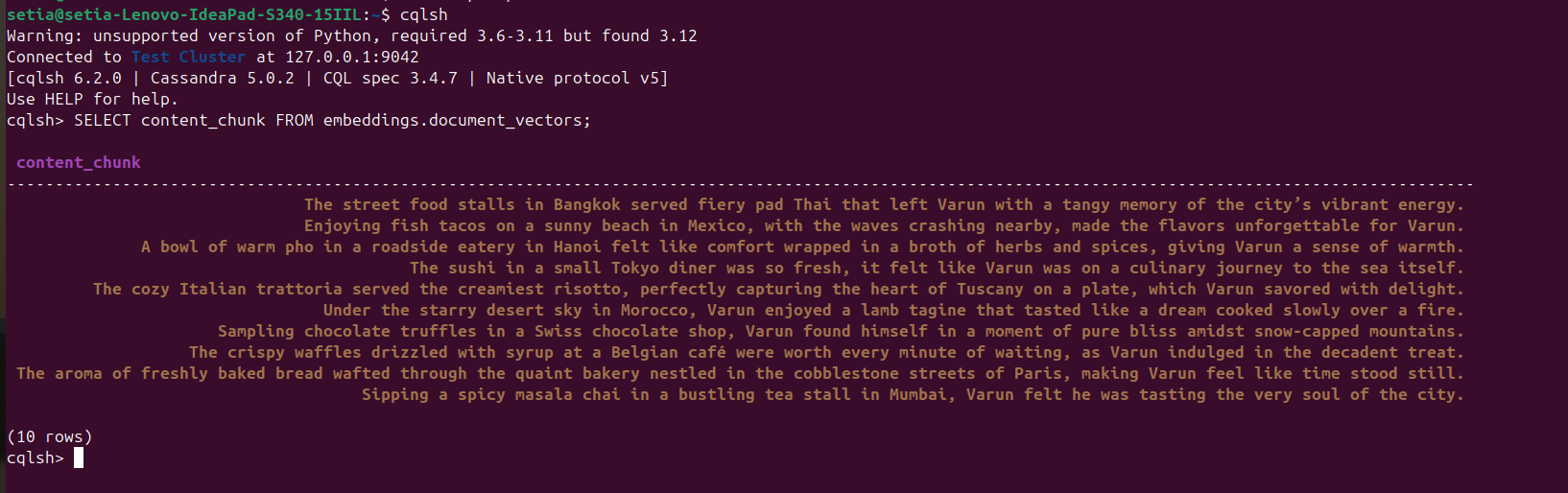
ファイルが実行され、ドキュメントが挿入されると、cqlshコンソールからCassandraデータベースをクエリすることで確認できます。これには、cqlshを開き、次のコマンドを実行します:
SELECT content_chunk FROM embeddings.document_vectors;
これにより、下のスクリーンショットに示されているように、データベースに挿入された10のドキュメントが返されます。
マイルストーン2:ベクターデータベースでのデータ設定が完了しました。
次に、コサイン類似度に基づいてドキュメントをクエリするコードを書きます。コサイン類似度は、2つのベクトル値のドット積です。その公式はA.B / |A||B|です。このコサイン類似度はApache Cassandraによって内部的にサポートされており、データベース内ですべてを計算し、大規模データを効率的に処理するのに役立ちます。
以下のコードは自己説明的であり、ORDER BY <column name> ANN OF <text_vector>を使用してコサイン類似度に基づいて上位3つの結果を取得し、コサイン類似度の値も返します。このコードを実行するには、このベクトル列にインデックスが適用されていることを確認する必要があります。
def query_rag(text):
text_embeddings = generate_embedding(text)
select_query = """
SELECT content_chunk,similarity_cosine(content_vector, ?) FROM embeddings.document_vectors
ORDER BY content_vector ANN OF ?
LIMIT 3
"""
prepared_stmt = session.prepare(select_query)
result_rows = session.execute(prepared_stmt, [
text_embeddings,
text_embeddings
])
for row in result_rows:
print(row[0], row[1])
query_rag('Tell about my Bangkok experiences')
挿入コードはコメントアウトすることを忘れないでください:
#insert_sample_data_in_cassandra()
次に、python app.pyを使用してPythonコードを実行します。
以下の出力が得られます:
(myvenv) setia@setia-Lenovo-IdeaPad-S340-15IIL:/media/setia/Data/Tutorials/cassandra-ollama-app$ python app.py
The street food stalls in Bangkok served fiery pad Thai that left Varun with a tangy memory of the city’s vibrant energy. 0.8205469250679016
Sipping a spicy masala chai in a bustling tea stall in Mumbai, Varun felt he was tasting the very soul of the city. 0.7719690799713135
A bowl of warm pho in a roadside eatery in Hanoi felt like comfort wrapped in a broth of herbs and spices, giving Varun a sense of warmth. 0.7495554089546204
「バンコクのストリートフードスタンドは、ヴァルンに街の活気あるエネルギーの酸っぱい記憶を残した激辛パッタイを提供しました。」のコサイン類似度は0.8205469250679016で、最も近い一致です。
最終マイルストーン:RAG検索を実装しました。
エンタープライズアプリケーション
Apache Cassandra
企業向けには、Apache Cassandra 5.0をMicrosoft Azure、AWS、GCPなどの人気のクラウドベンダーから使用できます。
Ollama
このミドルウェアは、高性能モデルを実行するためにNvidia製GPUに対応したVMを必要としますが、ベクター生成に使用されるモデルには高性能なVMは必要ありません。トラフィックの要件に応じて、複数のVMを使用することも、Open AIやAnthropyなどの生成AIサービスを利用することもできます。どちらがスケーリングニーズやデータガバナンスニーズのための総所有コストが低いかによります。
Linux VM
Apache CassandraとOllamaは、使用ケースが高い使用を必要としない場合、総所有コストを下げるためやデータガバナンスニーズに対応するために、単一のLinux VMに組み合わせてホストできます。
結論
私たちは、Linux OS、Apache Cassandra、Ollamaを介して使用される埋め込みモデル(nomic-embed-text)、およびPythonを使用することで、追加のクラウドサブスクリプションやサービスなしに、私たちのマシン/サーバーの快適さの中で良好なパフォーマンスのRAGアプリケーションを簡単に構築できます。
ただし、VMをサーバーにホスティングするか、エンタープライズアプリケーションとしてスケーラブルなアーキテクチャに準拠したスケーリングのためにクラウドサブスクリプションを選択することが推奨されます。このApacheでは、Cassandraがベクトルストレージとベクトル比較の重い作業を行うための重要なコンポーネントであり、ベクトル埋め込みを生成するためのOllamaサーバーがあります。
これで終わりです!最後までお読みいただきありがとうございます。
Source:
https://dzone.com/articles/build-rag-apps-apache-cassandra-python-ollama