













Многие компании выбирают переход на AWS MSK, чтобы избежать операционных проблем, связанных с управлением кластерами Apache Kafka.
В этом руководстве мы рассмотрим особенности, преимущества и лучшие практики AWS MSK. Мы также рассмотрим основные шаги по настройке AWS MSK и увидим, как он сравнивается с другими популярными службами, такими как Kinesis и Confluent.
Что такое AWS MSK?
Сначала давайте разберемся, что такое Apache Kafka и почему он так полезен для потоковых данных.
Apache Kafka – это распределенная потоковая платформа с открытым исходным кодом, которая обрабатывает потоковые данные в реальном времени и может создавать приложения, работающие по событиям. Он может принимать и обрабатывать потоковые данные по мере их поступления.
Согласно сайту Kafka, более 80% компаний из списка Fortune 100 доверяют и используют Kafka.
Прежде всего, Kafka масштабируем и очень быстр. Это означает, что он может обрабатывать намного больше данных, чем поместилось бы на одной машине, и с очень низкой задержкой.
Если вы хотите узнать, как создавать, управлять и устранять неполадки в Kafka для потоков данных, рассмотрите возможность прохождения курса Введение в Kafka.
Когда лучше всего использовать Apache Kafka?
- Когда вам нужно обрабатывать огромные объемы данных в реальном времени, например, обработка потоков данных устройств IoT.
- Когда вам необходима мгновенная обработка данных и анализ, например, при отслеживании активности пользователей в реальном времени или в системах обнаружения мошенничества.
- В сценариях событийного моделирования, когда вам нужны журналы аудита в соответствии с требованиями и правилами соблюдения.
Однако управление экземплярами Kafka может вызвать много головной боли. В этом случае приходит на помощь AWS MSK.
![]()
Изображение автора
AWS MSK (Managed Streaming for Kafka) – это полностью управляемый сервис, который обрабатывает предоставление, настройку, масштабирование и обслуживание кластеров Kafka. Вы можете использовать его для создания приложений, реагирующих на потоки данных мгновенно.
Кафка часто используется как часть более крупной настройки обработки данных, и AWS MSK упрощает создание конвейеров обработки данных в реальном времени, перемещающих данные между различными системами.
Как работает Amazon MSK. Источник изображения: AWS
Если вы новичок в AWS, рассмотрите возможность пройти наш курс Введение в AWS, чтобы ознакомиться с основами. Когда будете готовы, переходите к нашему курсу Технологии и сервисы облачных вычислений AWS, чтобы изучить полный набор услуг, на которых полагаются бизнесы.
Особенности AWS MSK
AWS MSK выделяется на фоне конкурентов благодаря тому, что это полностью управляемый сервис. Вам не нужно беспокоиться о настройке серверов или обновлениях.
Однако в этом есть не только это. Эти пять ключевых особенностей AWS MSK делают его ценным инвестиционным объектом:
- MSK обладает высокой доступностью, и AWS гарантирует соблюдение строгих SLA. Он автоматически заменяет отказавшие компоненты без простоев для ваших приложений.
- MSK имеет функцию автомасштабирования для хранилища, поэтому оно автоматически растет вместе с вашими потребностями. Вы также можете быстро увеличивать или уменьшать объем хранилища или добавлять больше брокеров по мере необходимости.
- В терминах безопасности MSK является всеобъемлющим решением, которое обеспечивает шифрование в покое и в транзите. Он также интегрируется с AWS IAM для контроля доступа.
- Если вы уже используете Kafka, вы можете перейти к MSK без изменения своего кода, поскольку MSK поддерживает все стандартные API и инструменты Kafka.
- MSK – это экономически эффективный вариант, который не требует найма целой инженерной команды для мониторинга и управления кластерами. AWS даже гордится тем, что он может быть до 40% дешевле, чем самостоятельно управляемый Kafka.
Преимущества использования AWS MSK
Как мы уже видели, AWS MSK приносит немедленную ценность благодаря своей доступности, масштабируемости, безопасности и простоте интеграции. Эти основные преимущества сделали его предпочтительным выбором для компаний, запускающих рабочие нагрузки Kafka в облаке.
AWS MSK решает четыре критических проблемы, с которыми сталкивается каждый проект потоковой передачи данных:
- MSK – это полностью управляемый сервис, позволяющий сосредоточиться на создании приложений вместо управления инфраструктурой.
- MSK обладает высокой доступностью и надежностью, что становится все более критичным в настоящее время, поскольку пользователи ожидают доступа к услугам и приложениям 24/7.
- MSK имеет критические обширные возможности безопасности.
- MSK имеет нативную интеграцию с AWS, что значительно упрощает создание полноценных решений для потоковых данных в экосистеме AWS.
Настройка AWS MSK
Для начала работы с AWS MSK сначала создайте учетную запись AWS. Если вы впервые используете AWS, изучите, как настроить и сконфигурировать вашу учетную запись AWS с помощью нашего подробного руководства.
Войдите в консоль управления AWS и откройте консоль MSK. Нажмите “Создать кластер”, чтобы начать процесс настройки.

Начало работы с AWS MSK. Источник изображения: AWS
Выберите “Быстрое создание” для настроек по умолчанию, затем введите описательное имя кластера.
Отсюда у вас есть множество дополнительных вариантов для выбора, которые зависят от ваших собственных требований к вашему кластеру. Вот краткий обзор вариантов:
- Тип кластера: «Предварительно настроенный» или «Без сервера»
- Версия Apache Kafka
- Тип брокера: «Стандартный» или «Экспресс»
- Размер брокера
- Объем хранения EBS
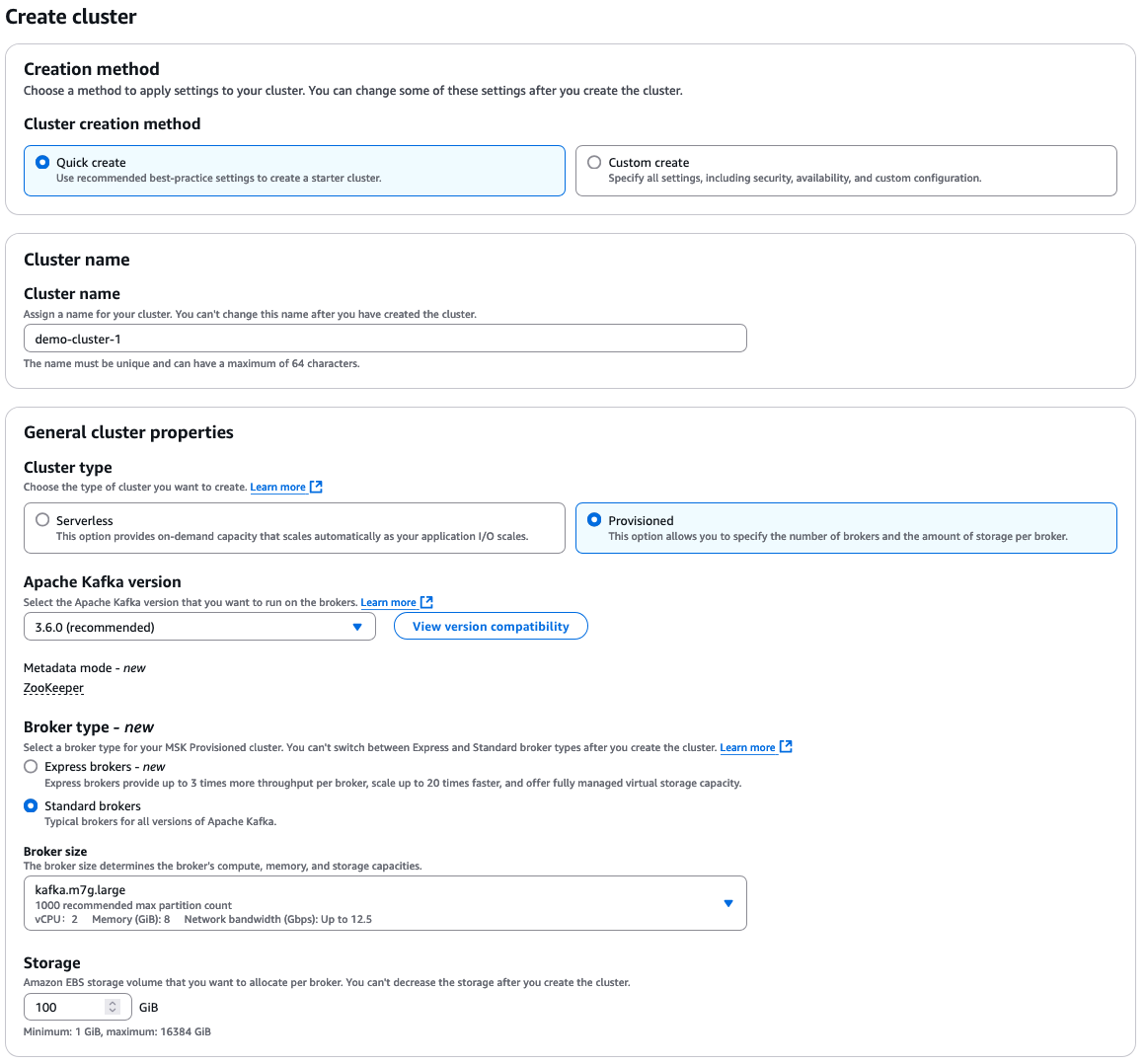
Параметры конфигурации AWS MSK
Кластер всегда создается в рамках Amazon VPC. Вы можете выбрать использовать VPC по умолчанию или настроить и указать пользовательский VPC.
Теперь вам просто нужно подождать активации вашего кластера, что может занять от 15 до 30 минут. Вы можете отслеживать статус вашего кластера на странице суммарной информации о кластере, где вы увидите изменение статуса с “Создание” на “Активен”.
Получение и обработка данных с помощью AWS MSK
После настройки вашего кластера MSK вам потребуется создать клиентскую машину для производства и потребления данных по одной или нескольким темам. Поскольку Apache Kafka настолько хорошо интегрируется с многими производителями данных (такими как веб-сайты, устройства IoT, экземпляры Amazon EC2 и т. д.), MSK также разделяет эту выгоду.
Apache Kafka организует данные в структуры, называемые темами. Каждая тема состоит из одной или нескольких разделов. Разделы представляют собой степень параллелизма в Apache Kafka. Данные распределяются по брокерам с использованием разделения данных.
Основные термины, которые важно знать при работе с кластерами Apache Kafka:
- Темы – основной способ организации данных в Kafka.
- Производители – это приложения, которые публикуют данные в темы – они генерируют и записывают данные в Kafka. Они записывают данные в определенные темы и разделы.
- Потребители – это приложения, которые считывают и обрабатывают данные из тем. Они извлекают данные из тем, на которые подписаны.
При построении архитектуры, основанной на событиях, с использованием AWS MSK, необходимо настроить несколько уровней, из которых MSK является основным компонентом приема данных. Вот обзор слоев, которые могут потребоваться:
- Настройка приема данных
- Уровень обработки
- Уровень хранения
- Уровень аналитики
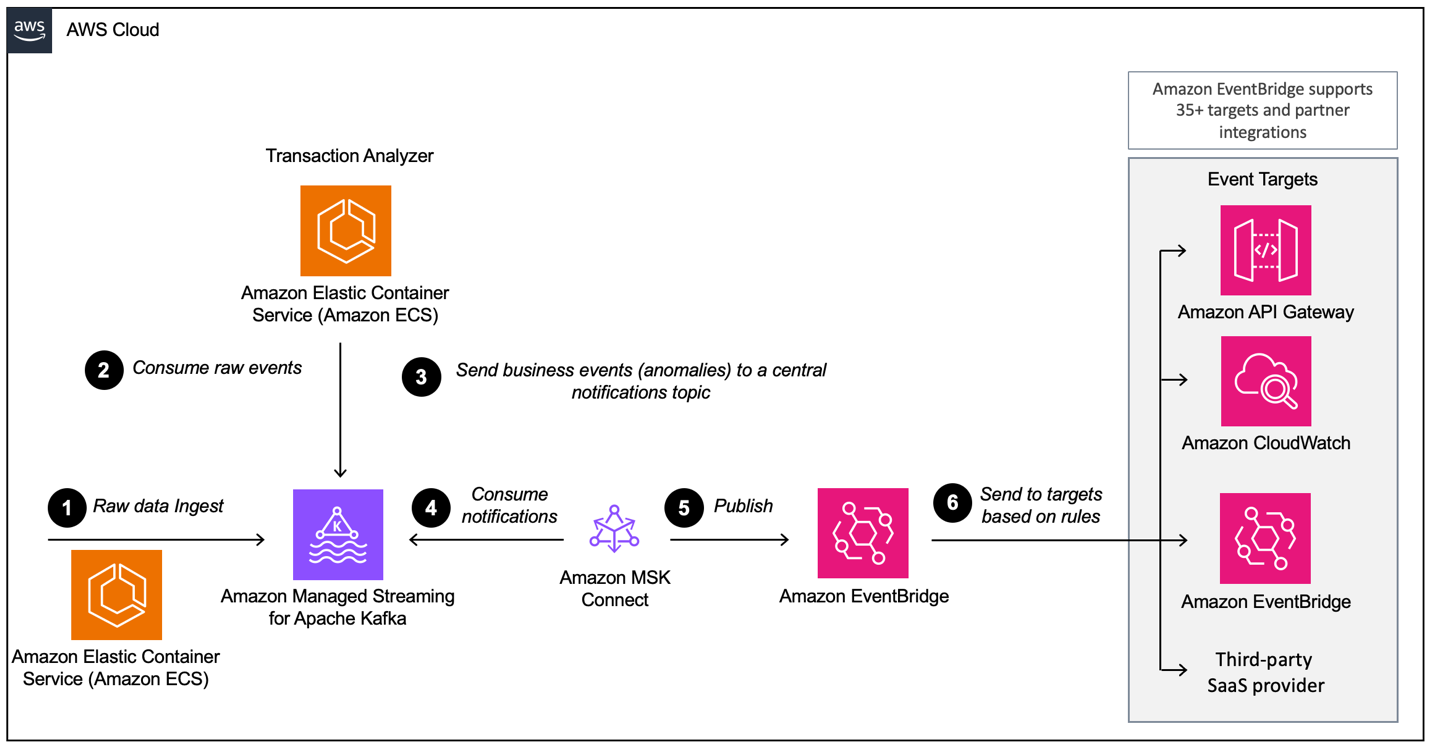
Пример архитектуры, ориентированной на события, с использованием Amazon MSK и Amazon EventBridge.Источник изображения: AWS
Если вас интересует использование Python в ваших рабочих процессах конвейера данных, ознакомьтесь с нашим курсом Introduction to AWS Boto in Python.
Лучшие практики использования AWS MSK
AWS MSK относительно прост в настройке и начале использования. Однако некоторые важные лучшие практики улучшат производительность ваших кластеров и сэкономят вам время в будущем.
Подберите правильный размер вашего кластера
Вам нужно будет выбрать правильное количество разделов на каждого брокера и правильное количество брокеров на кластер.
Ряд факторов может повлиять на ваши решения здесь; однако AWS предоставила некоторые удобные рекомендации и ресурсы, чтобы провести вас через этот процесс.
Кроме того, AWS предоставляет удобную таблицу размеров и цен, чтобы помочь вам оценить правильный размер вашего кластера и связанные издержки на использование AWS MSK по сравнению с подобным самостоятельно управляемым кластером Kafka на EC2.
Создавайте высокодоступные кластеры
AWS рекомендует настроить ваши кластеры для обеспечения высокой доступности. Это особенно важно при выполнении обновления (например, обновления версии Apache Kafka) или когда AWS заменяет брокера.
Для обеспечения высокой доступности ваших кластеров вам необходимо выполнить три вещи:
- Настройте ваши кластеры в трех доступных зонах (также называемый кластером в трех AZ).
- Установите фактор репликации на 3 или более.
- Установите минимальное количество ин-синхронных реплик на RF-1.
Замечательная вещь в AWS – это то, что они обязуются соблюдать строгие SLA для развертывания в нескольких AZ; в противном случае, вам вернут ваши кредиты.
Отслеживайте использование диска и процессора
Два ключевых показателя, которые следует отслеживать через AWS CloudWatch, – это использование диска и процессора. Это не только обеспечит плавную работу вашей системы, но также поможет снизить затраты.
Лучший способ управления использованием диска и связанными расходами на хранение — это настроить сигнализацию CloudWatch, которая уведомляет вас, когда использование диска превышает определенное значение, например 85%, и корректировать свои политики хранения. Установка времени хранения сообщений в вашем журнале может значительно помочь в автоматическом освобождении дискового пространства.
Кроме того, для поддержания производительности вашего кластера и избежания узких мест AWS рекомендует поддерживать общее использование ЦП для ваших брокеров ниже 60%. Вы можете отслеживать это с помощью AWS CloudWatch, а затем принимать корректирующие меры, например, обновляя размер вашего брокера.
Защитите свои данные с помощью шифрования при передаче
По умолчанию AWS шифрует данные при передаче между брокерами в вашем кластере MSK. Вы можете отключить это, если ваша система испытывает высокую нагрузку на ЦП или задержки. Однако настоятельно рекомендуется всегда оставлять шифрование при передаче включенным и находить другие способы улучшения производительности, если это для вас проблема.
Посмотрите наш курс по безопасности и управлению затратами AWS, чтобы узнать больше о том, как защитить и оптимизировать вашу облачную среду AWS и управлять затратами и ресурсами в AWS.
Сравнение AWS MSK с другими инструментами потоковой передачи
При выборе лучшего инструмента для проекта нам часто приходится оценивать несколько вариантов. Вот наиболее распространенные альтернативы AWS MSK и их сравнение.
AWS MSK против Apache Kafka на EC2
Основным компромиссом между MSK и самостоятельным вариантом с использованием EC2 является удобство и контроль: MSK предоставляет вам меньше для управления, но меньше гибкости, в то время как EC2 предоставляет вам полный контроль, но требует больше работы.
AWS MSK обрабатывает все сложные операционные задачи с автоматическим предоставлением и настройкой. Плюсом является то, что здесь нет предварительных инфраструктурных затрат. Также имеется безшовная интеграция с другими службами AWS и надежные функции безопасности.
Использование Kafka на EC2, с другой стороны, требует более тщательной настройки и конфигурации, а также вам нужно будет самостоятельно заниматься всеми обслуживанием и обновлениями. Это предоставляет гораздо большую гибкость, но может быть связано с более высокой сложностью и операционными издержками, а также может потребовать наличия более квалифицированных команд.
AWS MSK против Kinesis
Используйте Kinesis для простоты и глубокой интеграции с AWS, а MSK для совместимости с Kafka или большего контроля над настройкой потоков данных.
Kinesis – это полностью серверная архитектура, которая использует шарды для потоков данных. AWS управляет всем за вас. Однако стоит помнить о ограничениях на хранение данных. Kinesis – отличное решение для простых потребностей в потоковой передаче данных.
AWS MSK основан на модели тем и разделов Kafka, с практически неограниченным сроком хранения данных, в зависимости от вашего хранилища. Это более гибкое и настраиваемое решение, от которого вы можете отказаться в пользу другого провайдера облачных услуг AWS, если это необходимо.
Если вы не знакомы с Kinesis, у нас есть курс, который поможет вам ознакомиться с работой потоковых данных с использованием AWS Kinesis и Lambda.
AWS MSK против Confluent
Выберите Confluent, если вам нужны полный набор функций и поддержка, и выберите MSK, если у вас много опыта работы с Kafka в AWS.
Confluent имеет богатый набор функций с множеством встроенных коннекторов. Это в целом более дорогой вариант, но предлагает бесплатный уровень с ограниченными функциями. Confluent хорошо подходит для неравномерных рабочих нагрузок и имеет более простой процесс развертывания.
В сравнении, AWS более упрощен и сосредоточен на основном функционале Kafka. Чтобы получить доступ к более расширенному набору функций, AWS MSK должен интегрироваться с другими службами AWS. К счастью, эта интеграция проходит без сбоев. AWS MSK имеет более низкую базовую стоимость и может быть хорошим вариантом для стабильных рабочих нагрузок.
В следующей таблице приведено сравнение AWS MSK и его альтернатив:
|
Функция |
AWS MSK |
Apache Kafka на EC2 |
Kinesis |
Confluent |
|
Развертывание |
Полностью управляемое |
Самостоятельное управление на EC2 |
Полностью управляемое |
Полностью управляемое или самостоятельное управление |
|
Удобство использования |
Легко настраивать и управлять |
Требует ручной настройки и масштабирования |
Простая настройка; AWS-родная |
Удобный интерфейс и расширенные инструменты |
|
Масштабируемость |
Автомасштабирование с ручной настройкой |
Ручное масштабирование |
Плавное масштабирование |
Автомасштабирование с гибкостью |
|
Задержка |
Низкая задержка |
Низкая задержка |
Более низкая задержка для небольших пакетов данных |
Сравнимо с MSK |
|
Поддержка протокола |
Совместимо с API Kafka |
Совместимо с API Kafka |
Проприетарный протокол Kinesis |
API Kafka и дополнительные протоколы |
|
Сохранение данных |
Настройка (до 7 дней по умолчанию) |
Настраиваемый |
Настраиваемый (максимум 365 дней) |
Высокая степень настраиваемости |
|
Мониторинг и метрики |
Интегрирован с CloudWatch |
Требует настройки пользователя |
Интегрирован с CloudWatch |
Продвинутые инструменты мониторинга |
|
Стоимость |
Плати по мере использования |
Основано на ценообразовании для экземпляров EC2 |
Плати по мере использования |
На основе подписки |
|
Безопасность |
Встроенные функции безопасности AWS |
Необходима ручная настройка безопасности |
Интегрирован с AWS IAM |
Обширные функции безопасности |
|
Подходит для определенных случаев использования |
Лучший для пользователей Kafka в экосистеме AWS |
Гибкий, но требующий высокое техническое обслуживание |
Лучший для приложений, разработанных для AWS |
Продвинутые пользователи Kafka и предприятия |
Заключительные мысли
Apache Kafka – это выбор номер один в ситуациях, где требуется надежное решение масштаба предприятия, которое не может позволить потерю данных и требует подключения нескольких источников данных или создания сложных конвейеров данных. AWS MSK устраняет многие проблемы при настройке и конфигурировании кластеров Kafka, позволяя разработчикам сосредоточиться больше на создании и улучшении приложений, а не на инфраструктуре.
Получение сертификата AWS – отличный способ начать карьеру в AWS. Вы можете развивать свои навыки AWS, ознакомившись с нашим каталогом курсов и получив практический опыт через проекты!